本文介绍通过百度的文字识别API来进行OCR,把前面用Pdfbox得到的图片变成文字。
目录
前面我们已经把PDF的每一页都变成了图片,接下来就是要使用OCR技术从图片中识别文字了。我们首先使用最简单的方式——调用API。目前有很多AI的云服务提供OCR,我们这里使用百度的API。
注册
第一步是注册账号。可以在这里注册。登录后还需要创建一个应用,可以在这里创建,创建的时候记得选上OCR的API,当然还有很多其它API,比如语音识别与合成的、图像识别的和自然语言处理的。创建后有APP_ID,API_KEY和SECRET_KEY,这3个值在调用api时会用到。如下图所示。
 图:百度API的账号
图:百度API的账号
API简介
完整的API文档在这里,有兴趣的读者了解一些就行,这些都是REST的接口,调用前还需要先获得Token,另外传递图片参数还要BASE64编码等等,这比较繁琐和容易出错。因此我们通常使用百度提供的SDK(client),不同的语言都有相应的client,我们这里介绍Java SDK怎么调用OCR接口。
在使用前需要了解一下调用的限制,免费的调用是有限制的。目前的免费限额如下图所示:
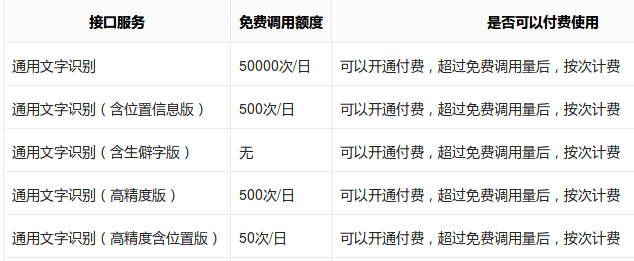 图:百度API的限额
图:百度API的限额
【通用文字识别】的调用限制是每天5万次,但是作者试了一下,通用文字识别的效果不是太好(但还凑合,肉眼看大概80%左右的准确率)。
【通用文字识别(高精度版)】的效果好很多,但是每天只能调用500次。不过对于作者来说也差不多了,跑个十来天就可以了。
但是作者还需要每一行文字的位置和字体大小等信息,因为后续处理需要对文字进行分析,提取标题。提取标题很重要的特征就是位置和大小,因为标题的文字通常比正文大,而且通常出现在某页的靠上的位置。
【通用文字识别(高精度含位置版)】包含位置信息,但是每天只能调用50次,作者像转换的文字大概在三四千页,用这个太慢。
【通用文字识别(含位置信息版)】的效果和通用文字识别一样,但是包含位置信息,每天的限额也是500次。因此可以把【通用文字识别(含位置信息版)】+ 【通用文字识别(高精度版)】结合起来。它们的次数都是500次,前者不准确但是包含位置信息,后者准确但是没有位置信息,结合起来就可以得到比较准确而且有位置信息的结果。
Java SDK的用法
我们只需要在maven的依赖里加入:
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.10.0</version>
</dependency>
public class TestOcr {
public static final String APP_ID = "你的APP_ID";
public static final String API_KEY = "你的APP_KEY";
public static final String SECRET_KEY = "你的SECRET_KEY";
public static void main(String[] args) {
AipOcr client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
//client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
//client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 可选:设置log4j日志输出格式,若不设置,则使用默认配置
// 也可以直接通过jvm启动参数设置此环境变量
//System.setProperty("aip.log4j.conf", "path/to/your/log4j.properties");
// 调用接口
String path = "/home/lili/data/test2-10.png";
// 这是【通用文字识别】接口
//JSONObject res = client.basicGeneral(path, new HashMap<String, String>());
// 这是【通用文字识别(高精度版)】
//JSONObject res=client.basicAccurateGeneral(path, new HashMap<>());
// 这是【通用文字识别(高精度含位置版)】,每天50次
//JSONObject res=client.accurateGeneral(path, new HashMap<>());
// 这是【通用文字识别(含位置信息版)】
JSONObject res=client.general(path, new HashMap<>());
System.out.println(res.toString(2));
}
}
【通用文字识别(含位置信息版)】的结果如下,它包含位置信息,但是识别效果一般,这里我们看到”时间”识别成了”寸间”。
{
"words": "我写小说,是断断续续的,一阵一阵的。开始写作的",
"location": {
"top": 635,
"left": 227,
"width": 855,
"height": 45
}
},
{
"words": "寸间倒是颇早的。第一篇作品大约是一九四(年发表",
"location": {
"top": 687,
"left": 169,
"width": 913,
"height": 41
}
},
下面是【通用文字识别(高精度版)】识别结果,我们可以看到”时间”被正确识别了。
{"words": "我写小说,是断断续续的,一阵一阵的。开始写作的"},
{"words": "时间倒是颇早的。第一篇作品大约是一九四年发表"},
因此我们可以把这两者结合起来,使用前者的位置信息和后者的文字。这样每天可以调用500次。
- 显示Disqus评论(需要科学上网)