本文介绍目前SOTA的语法纠错算法GECToR,并且简要的介绍其代码。
目录
论文解读
Introduction
这篇论文的核心从标题就能看出来。其标题是”GECToR – Grammatical Error Correction: Tag, Not Rewrite”,也就是使用给序列打标签来替代主流的Seq2Seq模型。由于Seq2Seq在机器翻译等领域的成功应用,把这种方法用到类似的语法纠错问题上也是非常自然的想法。机器翻译的输入是源语言(比如英语),输出是另外一个目标语言(比如法语)。而语法纠错的输入是有语法错误的句子,输出是与之对应的语法正确的句子,区别似乎只在于机器翻译的输入输出是不同的语言而语法纠错的输入输出是相同的语言。随着Transformer在机器翻译领域的成功,主流的语法纠错也都使用了Transformer来作为Seq2Seq模型的Encoder和Decoder。当然随着BERT等Pretraining模型的出现,机器翻译和语法纠错都使用了这些Pretraining的Transformer模型来作为初始化参数,并且使用领域的数据进行Fine-Tuning。由于领域数据相对Pretraining的无监督数据量太少,最近合成的(synthetic)数据用于Fine-tuning变得流行起来。查看一下nlpprogress的GEC任务,排行榜里的方法大多都是使用了BERT等Pretraining的Seq2Seq模型。
但是Seq2Seq模型有如下缺点:
- 解码速度慢
- 因为解码不能并行计算
- 需要大量训练数据
- 因为输出的长度不定,相对本文的序列标签模型需要更多的数据
- 不可解释
- 输入了错误的句子,输出只是正确的句子,不能直接知道到底是什么类型的语法错误,通常还需要使用其它工具来分析错误,比如errant。
本文可以解决这三个问题,思路是使用序列标签模型替代生成模型。注意:我这里使用的是序列标签而不是更常见的序列标注来翻译Sequence Tagging,原因在于它和用来解决NER等问题的序列标注不同。序列标注的标签通常是有关联的,比如以”BIO”三标签为例,I只能出现在B或者I后面,它们的组合是有意义的。而本文的给每一个Token打的标签和前后的标签没有关联,当然给当前Token打标签需要参考上下文,但这只是在输入层面,而在标签层面是无关的。本文的训练分为三个阶段:在合成数据上的Pretraining;在错误-正确的句对上的fine-tuning;在同时包含错误-正确和正确-正确句对数据上的fine-tuning。
数据集
- 合成数据
- 在第一个阶段,使用了来自这里的9百万合成的语法错误-语法正确句对。
- 训练数据,用于二三阶段的fine-tuning
- 测试数据
Token级别的变换
原理
怎么把纠错问题用序列标注来解决呢?我们的数据是有语法错误和语法正确的两个句子。和机器翻译不同,语法纠错的两个句子通常非常相似,只是在某些局部会有不同的地方。因此类似于比较两个句子的diff,我们可以找到一系列编辑操作,从而把语法错误的句子变成语法正确的句子,这和编辑距离的编辑很类似。编辑操作怎么变成序列打标签呢?我们可以把编辑映射某个Token上,认为是对这个Token的操作。但是这里还有一个问题,有时候需要对同一个Token进行多个编辑操作,因为序列打标签的输出只能是一个,那怎么办呢?本文采取了一种迭代的方法,也就是通过多次(其实最多也就两三次)序列打标签。说起来有点抽象,我们来看一个例子。

比如上图的例子,红色的句子是语法错误的句子:”A ten years old boy go school”。
我们先经过一次序列打标签,找到了需要对ten和go进行操作,也就是把ten和years合并成ten-years,把go变成goes。注意:这里的用连字符”-“把两个词合并的操作定义在前面的Token上。
接着再进行一次序列打标签,发现需要对ten-years和goes进行操作,把ten-years变成ten-year然后与old合并,在goes后面增加to。
最后一次序列打标签在school后面增加句号”.”。
变换
上述的编辑操作被定义为对某个Token的变换(Transform),如果词典是5000的话,则总共包含4971个基本变换(Basic Transform)和29个g-变换。
基本变换
基本变化包括两类:与Token无关的和与Token相关的变换。与Token无关的包括\$KEEP(不做修改)、\$DELETE(删除当前Token)。与Token相关的有1167个\$APPEND_t1变换,也就是在当前Token后面可以插入1167个常见词t1(5000个词并不是所以的词都可以被插入,因为有些词很少会遗漏);另外还有3802个$REPLACE_t2,也就是把当前Token替换成t2。
g-变换
前面的替换只是把当前词换成另一个词,但是英语有很多时态和单复数的变化,如果把不同的形态的词都当成一个新的词,则词的数量会暴增,而且也不利于模型学习到这是一种时态的变化。所以这里定义了g-变换,也就是对当前Token进行特殊的变换。完整的g-变换包括:
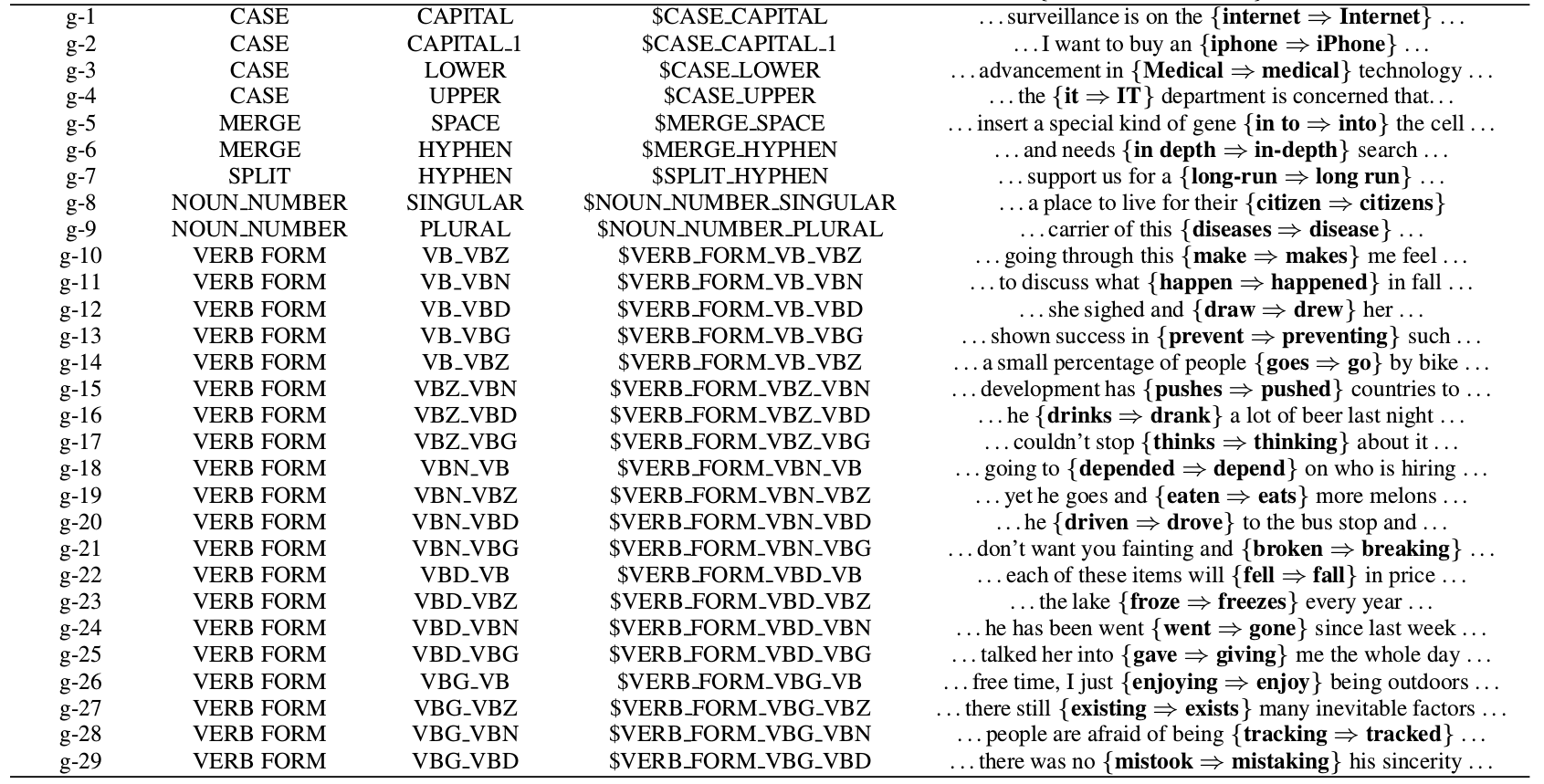 g-变换
g-变换
- CASE
- CASE类的变化包括字母大小写的纠错,比如$CASE_CAPITAL_1就是把第2(下标0开始)个字母变成对象,因此它会把iphone纠正为iPhone。
- MERGE
- 把当前Token和下一个合并,包括$MERGE_SPACE和$MERGE_HYPHEN,分别是用空格和连字符”-“合并两个Token。
- SPLIT
- $SPLIT-HYPHEN把包含连字符的当前Token分开成两个。
- NOUN_NUMBER
- 把单数变成复数或者复数变成单数。
- VERB_FORM
- 动词的时态变化,这是最复杂的,我们只看一个例子。比如VERB_FORM_VB_VBZ可以把go纠正成goes。
因为时态变化很多是不规则的,需要有一个变换词典,本文使用了Word Forms提供的词典。
获得训练数据
通过上面的方法,我们可以把纠错问题转换成多次迭代的序列打标签问题。但是我们的训练数据只是错误-正确的句对,没有我们要的VERB_FORM_VB_VBZ标签,因此需要有一个预处理的过程把句对变成Token上的变换标签。本文使用了如下的步骤来进行运处理:
步骤1
把源句子(语法错误句子)的每一个Token映射为目标句子(语法正确句子)的零个(删除)或者多个Token。比如”A ten years old boy go school”->”A ten-year-old boy goes to school.”,会得到如下的映射:
A → A
ten → ten, -
years → year, -
old → old
boy → boy
go → goes, to
school → school, .
这是一种对齐算法,但是不能直接用基于连续块(Span)的对齐,因为这可能会把源句子的多个Token映射为目标句子的一个Token。我们要求每个Token有且仅有一个标签,所以这里使用了修改过的编辑距离的对齐算法。这个问题的形式化描述为:假设源句子为$x_1,…,x_N$,目标句子为$y_1,…,y_M$,对于源句子的每一个Token $x_i$($1 \le i \le N$),我们需要找到与之对齐的子序列$y_{j_1},…,y_{j_2}$,其中$1 \le j_1 \le j_2 \le M$,使得修改后的编辑距离最小。这里的编辑距离的cost函数经过了修改,使得g-变换的代价为零。
步骤2
通过前面的对齐,我们可以找到每个Token的变换,因为是一对多的,所以可能一个Token会有多个变换。比如上面的例子,会得到如下的变换:
[A → A] : $KEEP
[ten → ten, -]: $KEEP, $MERGE_HYPHEN
[years → year, -]: $NOUN_NUMBER_SINGULAR, $MERGE_HYPHEN
[old → old]: $KEEP
[boy → boy]: $KEEP
[go → goes, to]: $VERB_FORM_VB_VBZ, $APPEND_to
[school → school, .]: $KEEP, $APPEND_{.}
步骤3
只保留一个变换,因为一个Token只能有一个Tag。但是有读者可能会问,这样岂不是纠错没完全纠对?是的,所以这种算法需要多次的迭代纠错。最后的一个问题就是,多个变换保留哪个呢?论文说优先保留$KEEP之外的,因为这个Tag太多了,训练数据足够。如果去掉$KEEP还有多个,则保留第一个。所以最终得到的标签为:
[A → A] : $KEEP
[ten → ten, -]: $MERGE_HYPHEN
[years → year, -]: $NOUN_NUMBER_SINGULAR
[old → old]: $KEEP
[boy → boy]: $KEEP
[go → goes, to]: $VERB_FORM_VB_VBZ
[school → school, .]: $APPEND_{.}
模型结构
模型就是类似BERT的Transformer模型,在最上面加两个全连接层和一个softmax。根据不同的Pretraining模型选择不同的subword切分算法:RoBERTa使用BPE;BERT使用WordPiece;XLNet使用SentencePiece。因为我们需要在Token上而不是在subword进行Tag,因此我们只把每个Token的第一个subword的输出传给全连接层。
迭代纠错
前面介绍过,有的时候需要对一个Token进行多次纠错。比如前面的go先要变成goes,然后在后面增加to。因此我们的纠错算法需要进行多次,理论上会一直迭代直到没有发现新的错误。但是最后设置一个上限,因此论文做了如下统计:
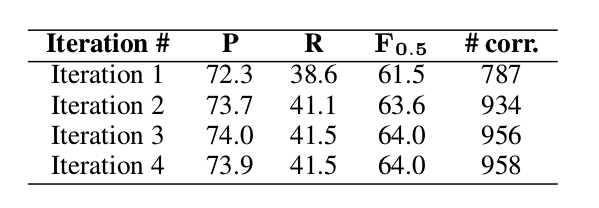 迭代次数对结果的影响(CoNLL-2014测试集)
迭代次数对结果的影响(CoNLL-2014测试集)
基本上两次迭代就能达到比较好的效果,如果不在意纠错速度,可以到三次或者四次。
实验
训练
- 大量实验合成的只包含语法错误-语法正确的句对进行Pretraining
- 使用少量的(非合成的)语法错误-语法正确的句对进行Fine-tuning
- 使用少量的(非合成的)同时有语法错误-语法正确和语法正确-语法正确(不纠错)进行Fine-tuning
为什么要再来一个第三步的训练呢?因为如果没有第三步,模型输入的都是语法错误的句子,但实际输入是包含没有语法错误的句子的。下面的实验数据也能说明没有第三步效果会差很多:
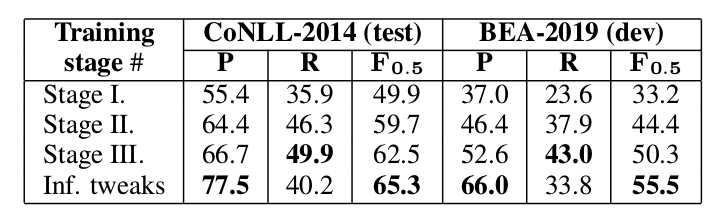 不同训练阶段的结果
不同训练阶段的结果
最后一行Inf.tweak是对推理过程的一些trick技巧,后面会讲到。
接下来的实验是尝试不同的Pretraining模型的效果:
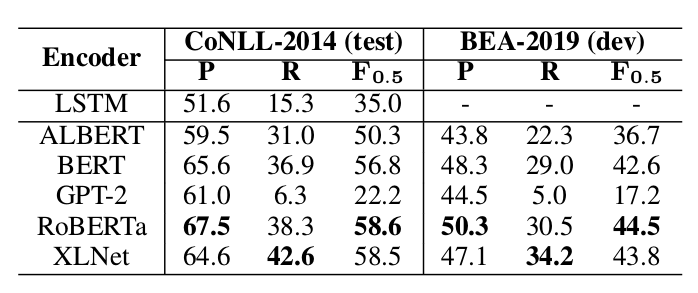 不同Pretraining模型的结果
不同Pretraining模型的结果
可以发现RoBERTa和XLNet比较好,BERT居中,GPT-2和ALBERT较差。作者认为GPT-2和ALBERT因为是生成模型,因此对于这个认为不如BERT等非生成模型。
推理的trick
- 给$KEEP增加一个bias
- 因为大部分的句子错误较少,而训练时错误的却居多,所以要给它加一个bias
- 增加最小的错误概率阈值
- 因为模型会尽量纠错,即使概率很少。这里增加一个句子基本的概率值,如果小于它则不纠错。
这两个值是使用验证集找到的。从上图的结果可以看出,使用了推理trick后效果提升不少。
本论文单一的最佳模型是GECToR (XL-Net)在CoNLL-2014(test)上的$F_{0.5}$是65.3%,BEA-2019(test)是72.4%。而使用了模型融合之后最好的结果在CoNLL-2014(test)上是66.5%,在BEA-2019(test)是73.6%。详细结果如下图所示:
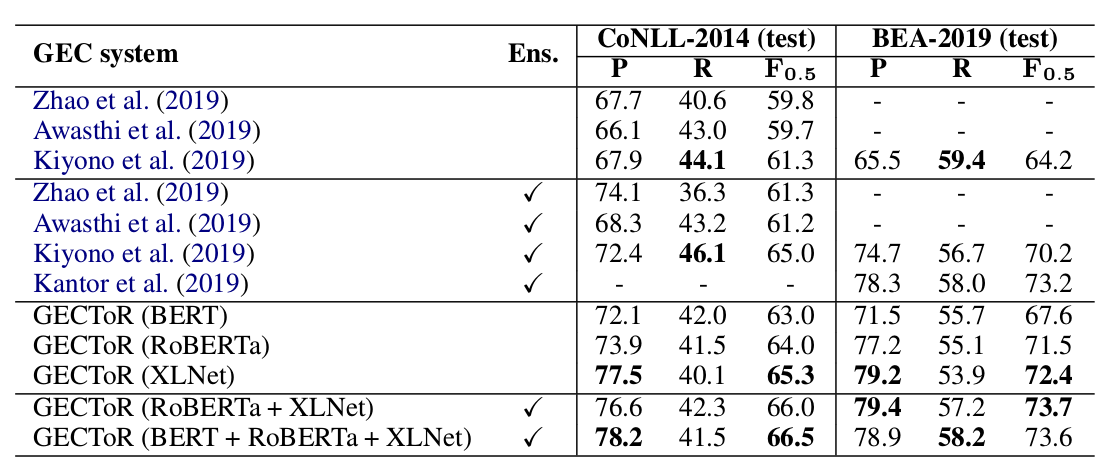 单个模型以及模型ensembling的对比
单个模型以及模型ensembling的对比
推理速度对比
相比Seq2Seq,Tagging模型的优势之一就是速度快,下面是实验对比:
 CoNLL-2014 (test)的速度对比
CoNLL-2014 (test)的速度对比
代码
安装
git clone https://github.com/grammarly/gector.git
#git clone https://github.com/fancyerii/gector.git
原始的代码是使用pip安装的pytorch 1.3.0,运行后出现如下问题:
pytorch Process finished with exit code 139 (interrupted by signal 11: SIGSEGV)
搜索好像是老版本在gpu有个bug,我卸载后在pytorch官网安装了1.5.0之后就正常了。
训练
暂未研究,待补充。
预测
我这里使用了单一的效果最好的XLNet模型进行预测,默认是设置是去网上下载预训练的模型。由于众所周知的原因,基本会失败。而且即使下载到本地缓存之后,它也会定期去服务器获取etag以判断是否更新,这也很麻烦。所以我hack了一下代码(目前没时间改的更优雅一点,只能hard code了一下)。
我提前把模型上传到百度网盘。链接: https://pan.baidu.com/s/19h00PuGxqrA64f_Z2XN2tg 提取码: puw2。下载后的目录应该是xlnetmodel,然后需要hack一下代码的路径,需要把gector/wordpiece_indexer.py的第412行改成你的绝对路径:
+ #hack
+ model_path = pretrained_model
+ if model_path == 'xlnet-base-cased':
+ model_path='/home/lili/codes/gector/xlnetmodel'
+
bert_tokenizer = AutoTokenizer.from_pretrained(
- pretrained_model, do_lower_case=do_lowercase, do_basic_tokenize=False)
+ model_path, do_lower_case=do_lowercase, do_basic_tokenize=False)
上面是代码的diff,读者需要把model_path改成自己的绝对路径。
这是我们要纠错的文件内容:
$ cat test
I have book.
I likes to swimming.
I am fine.
Iliketo swim.
运行:
$ python predict.py --model_path xlnetmodel/xlnet_0_gector.th --input_file test --output_file out --transformer_model xlnet --special_tokens_fix 0
输出为:”Produced overall corrections: 2”。
纠错的结果在out文件里,我们来看一下:
$ cat out
I have a book.
I like swimming.
I am fine.
Iliketo swim.
我们看到前两个句子的错误都纠正过来了,第三个句子是正确的,第四个句子由于ocr问题连着一起,它并没有纠正,因为它的训练数据没有这种情况。
- 显示Disqus评论(需要科学上网)