本文介绍开放域(Open Domain)聊天机器人的最新进展。
目录
背景介绍
随着BERT和XLNet等大规模无监督语料上预训练模型在很多NLU任务上的成功应用,在NLG任务上也越来越多的开始使用这些模型,包括机器翻译、摘要和语法纠错等等。而开放域的聊天机器人的研究也逐渐从分模块的PipeLine系统往end to end方向发展。为了更好的训练e2e模型,大规模闲聊语料库如pushshift.io收集的Reddit也开始出现,另外也出现了专注于个性化的ConvAI2语料库、专注于展现机器人渊博知识的Wizard of Wikipedia语料库、表现同情心和同理心的EmpatheticDialogues数据集以及整合了上面三个特点的Blended Skill Talk语料库。
这些大规模和特定特点的公开语料库的出现也极大推动了开放域聊天机器人的快速发展。本文会分析几篇代表性的论文和开源的代码,因为这些论文大都使用Transformer模型以及Bert/XLNet等预训练方法,所以不熟悉的读者可以先阅读BERT课程、XLNet原理等文章学习相关基础知识。
DialoGPT
简介
DialoGPT的论文可以在这里下载。GPT2使用大量wiki和book corpus的语料预训练的Transformer语言模型在很多生成类任务中变现了极好的效果,但是wiki等语料并不是聊天的对话数据,因此当更像聊天对话数据的Reddit数据集发布后,利用Reddit数据集进行训练复杂的Transformer模型就是非常自然的过程。
对话和机器翻译、摘要等任务不同,它被认为是一个一对多(one to many)的任务,也就是一个上下文(context)下有很多合理的响应(response),而且机器人在整个对话过程中要一致(consitent),避免无意义的万金油式的回答(比如”ok”)。如果从完全e2e的解决方案来看,模型就需要更加复杂,能够考虑更多的上下文信息(解决一致性问题),而针对无信息的response,本文使用了Mutual Information Maximization(MMI)来选择更加具体的回复。
数据集
数据抓取自2005年到2017年reddit的评论。一个reddit的帖子可以看成一棵树,对某个评论的回复可以看出它的孩子节点。那么从根节点到叶子节点的一条路径就是一个对话,因此一个帖子对应多个对话。另外作者对数据进行了如下的过滤:
- 包含url
- respone里重复词超过3个
- top50高频词一个都不包含
- 包含特殊符号(比如[])
- source加target超过200词的
- target包含敏感内容的
通过除了后,最终的数据包含147,116,725个对话,共18亿Token。
模型结构
模型结构基本就是参考GPT2的Transformer模型,把整个对话的Token拼接在一起,得到一个序列$x_1, …, x_N$。对话历史记为$S = x_1, …,x_m$,目标序列$T=x_{m+1},…,x_N$。则条件概率$P(T \vert S)$可以写成:
\[P(T|S)=\prod_{n=m+1}^Np(x_n|x_1,...,x_{n-1})\]对于多轮的对话$T_1,…,T_K$,我们可以拆分成K个S和T的pair。
MMI
机器人很容易生成乏味的(bland)和无信息的(uninformative)的回复,本文实现了一个Maximum Mutual Information(MMI)打分函数。MMI会训练一个反向的概率模型$P(Source \vert Target)$。我们首先Top-K采样的算法使用模型生成K个候选Hypothesis,然后使用MMI函数$P(Source \vert Hypothesis)$选择得分最高的Hypothesis。从直觉上来说,MMI会惩罚那些无信息的回复,因为这些回复在很多Context(Source)下都会出现,因此很多Source的$P(Source \vert Hypothesis)$都有不低的概率,从而每个$P(Source \vert Hypothesis)$都很小。
实验结果
实验细节
本文训练了3个模型,参数分别为117M、345M和762M,模型参数配置如下图:
 图:DialoGPT的参数
图:DialoGPT的参数
模型词典的大小是50,257,使用了16个Nvidia v100的GPU使用NVLink进行训练。使用Noam learning rate scheduler,有16000个warm-up steps。learning rate是根据验证集的loss来选择的。当验证集上的loss没有下降时停止训练。对于中小规模的模型,训练了5个Epoch,对于大的模型训练了3个Epoch。
DSTC-7对话生成任务
DSTC-7是一个end to end的对话生成任务,它的目的是生成闲聊(chitchat)之外的对话,它会提供外部的知识。但是这个任务和传统的Task-oriented/Goal-oriented的任务不同,它没有一个明确的目标(比如订机票这样的)。它的对话是没有什么特别明确的目标,比如一个头脑风暴的对话。
DSTC-7的测试数据来自reddit,选择了回复数超过6的帖子。对比的baseline系统是PERSONALITY CHAT,这是用Twitter数据训练的seq2seq模型,并被用于微软Azure的Cognitive Service。评测使用在自动指标包括BLEU、METEOR和NIST,此外也使用了Entropy和DIST-n来评判词汇的多样性。在DSTC-7上的结果如下所示:
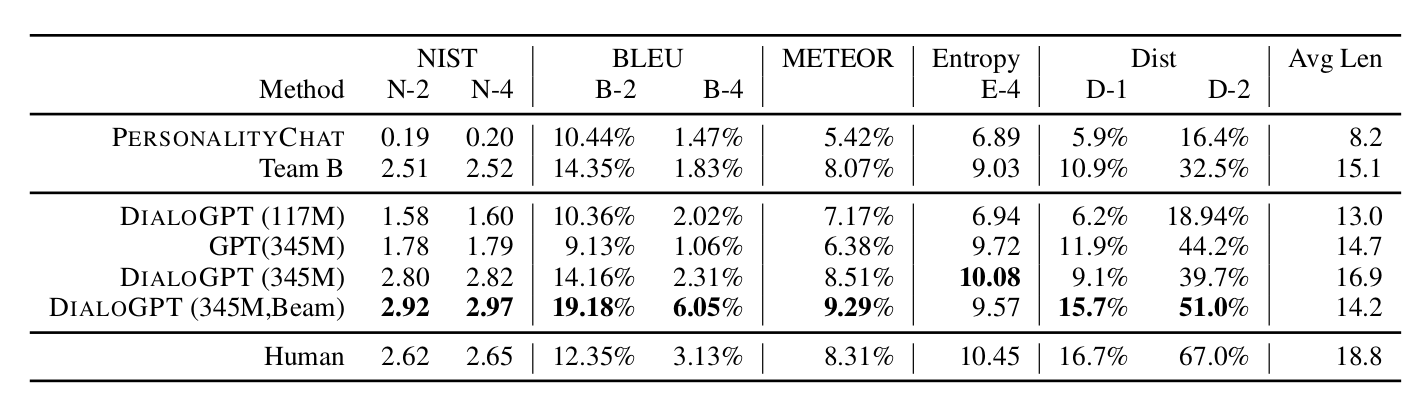 图:DSTC-7数据集的测试结果
图:DSTC-7数据集的测试结果
其中Team B是DSTC-7的冠军,Human代表预留的参考答案(一个context存在多个合理回复)。注意:在NIST和BLEU等指标上模型超过了人类(参考答案),这并不代表模型的结果要比人类的好。因为和机器翻译类似,对话系统是没有标准并且唯一正确答案的。这些自动评测指标只是会计算字面上的重合程度,通常任务重合度越高,模型就越好,但是不与参考答案一样的答案并不见到就是不好的。
Reddit测试集
在这个测试集合上对比了从零开始用Reddit训练的模型以及使用OpenAI GPT2预训练的模型再在Reddit上训练的结果:
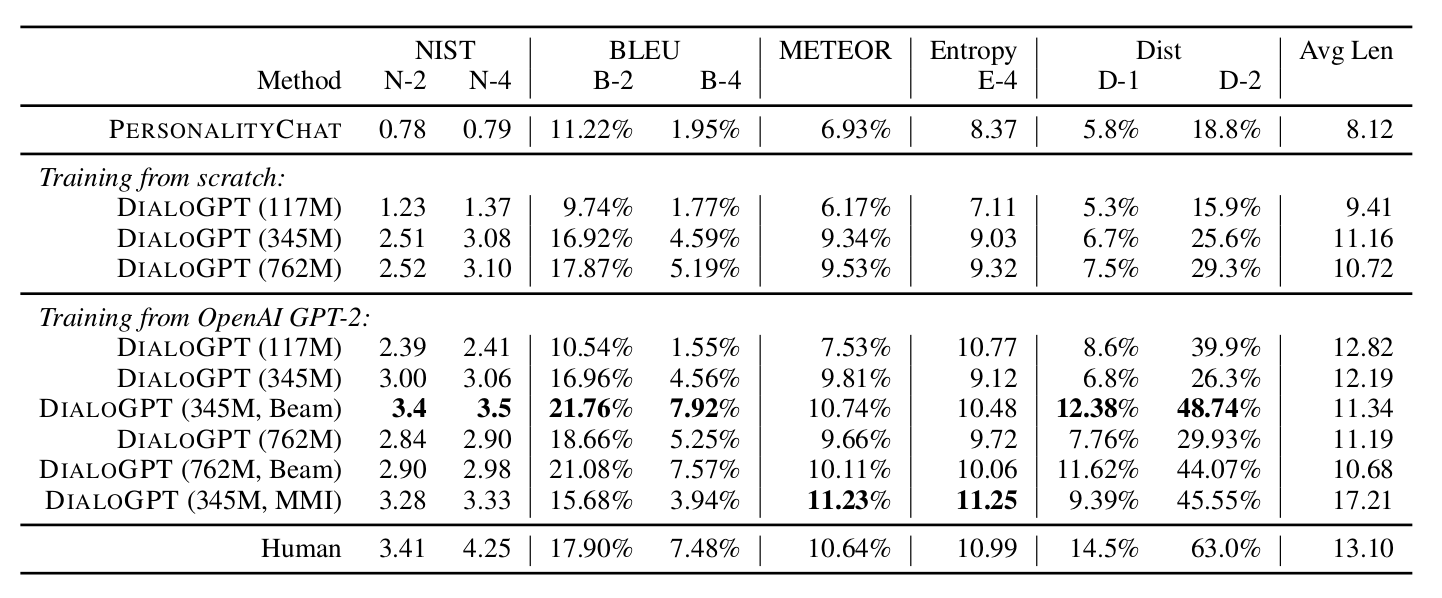 图:Reddit数据集的结果
图:Reddit数据集的结果
可以看出,基于GPT2的模型训练会更好,而且对于小的模型提升更为明显。
另外,通过Top-K采样然后使用MMI进行排序的模型DIALOGPT(345M, MMI)会比baseline DIALOGPT(345M)在NIST和METEOR上有所提高,但是在BLEU上却是稍微下降的。
代码
代码在这里下载,这里也提供了Hugging Face的模型(但是没有反向的MMI)。
如果要测试的话,可以先下载大、中和小三个版本的训练好的模型。进入这些页面后点击**List all files in model **就可以下载所有文件,如果不提前下载也可以通过模型名字自动下载。
测试代码如下:
from transformers import AutoModelWithLMHead, AutoTokenizer
import torch
path="/home/lili/data/huggface/DialoGPT-large"
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelWithLMHead.from_pretrained(path)
for step in range(10):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
#bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
bot_input_ids = new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
测试结果如下:
>> User:hello
DialoGPT: Hiya
>> User:what's your favorite sports?
DialoGPT: I like baseball and football.
>> User:I like basketball.
DialoGPT: I like basketball.
这里没有MMI,看起来效果一般。Github上还有一些第三方Decoder,感兴趣的读者可以试试。
Meena
Meena的论文可以在这里下载。这篇文章在模型结构上没有什么太大特点,就是在大量的社交媒体数据集上训练了一个end-to-end系统,当然2.6B的参数要比DialoGPT大的多。不过针对开放领域对话系统很难自动评估的问题,本文提出了一个SSA的人工评估指标。而且实验还发现SSA和语言模型的perplexity(PPL)是强相关的,这个结论如果成立的话,我们就可以简单的用语言模型的PPL来自动评估就够了。
简介
开放域聊天机器人一直是大家想解决的一个问题,但是和封闭域聊天机器人(Closed Domain Chatbot)有一个预定义的问题域不同,开放域聊天机器人可以聊任何话题。MILABOT、Mitsuku、小冰和Cleverbot等机器人都有非常复杂的框架,需要使用基于知识库、检索和规则等多种方法实现。而End-to-end的方法虽然简单,但是目前还有较大的缺点:它经常答非所问或者回答一些模糊的答案。
本文用40B的数据集训练了一个end-to-end的模型,这是一个Evolved Transformer模型,Evolved Transformer是通过Neural Architecture Search(NAS)的方法来自动搜索合适的网络结构,关于NAS感兴趣的读者可以参考Lil的博客文章。搜索最好的模型用2.6B参数,在测试集上的PPL是10.2。
为了评估Meena的效果,本文还提出了一个简单的人类评估指标Sensibleness and Specificity Average(SSA)。Sensibleness要求机器人的回复是合理的,合乎逻辑的;而Specificity要求回复是具体有信息量的,这是为了避免”I don’t know”这种万金油似的无意义的回复。最后的Average就是把这两个指标平均起来。
实验
实验之一静态(Static)评估,也就是人工标注了1,477个对话,这些对话都是1到3轮。然后处理得到315个单轮的context,500个两轮的context和662个三轮的context,让模型来输出一个response(如果是评估人就是用原始对话的response)。这些(context,response)对交给评估人员来判断它是否Sensibleness和Specificity,从而平均可以得到SSA。
首先我们需要判断SSA指标本身是否合理,为了评判这一点,文章作者实现了不同SSA的机器人,然后让人来评判这些机器人的对话是否像人类(human-like),结果如下图:
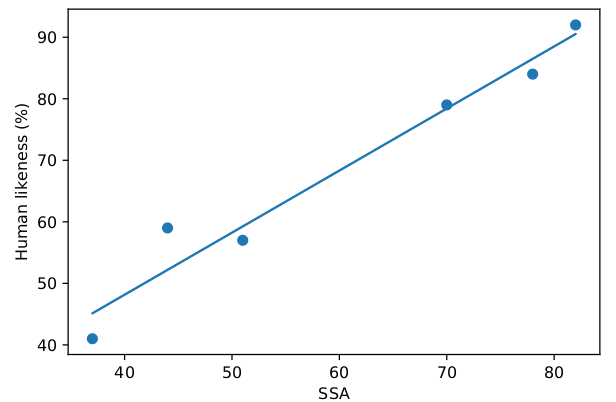 图:SSA和Human-like的关系
图:SSA和Human-like的关系
最右上角的那个点是人类的表现,而其它点是机器人。可以计算得出Human-like和SSA的相关系数是0.96,说明我们用SSA这个指标来评估机器人是合理的。
接着为了评估SSA和PPL的关系,本文训练了很多不同PPL的模型(从10~18),得出如下图结果:
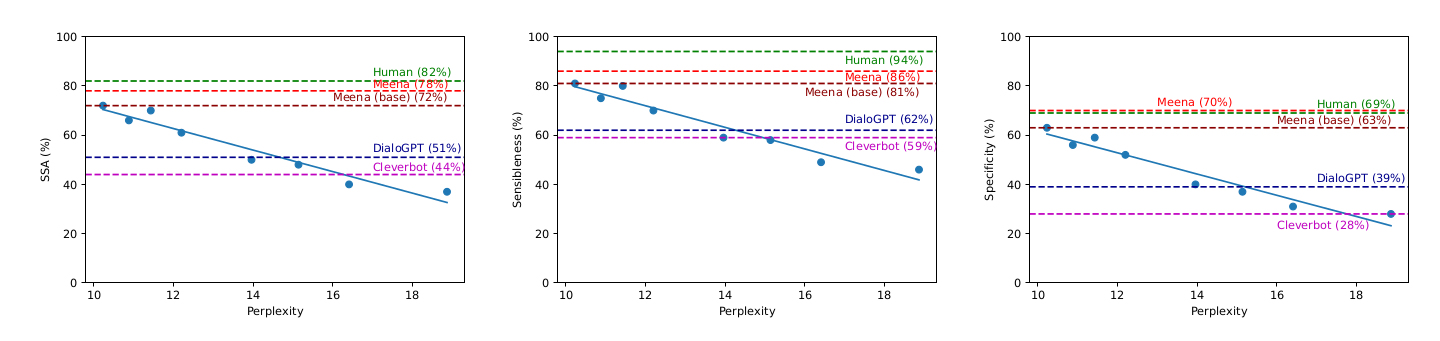 图:静态评估SSA和PPL的关系
图:静态评估SSA和PPL的关系
可以看到,PPL越低,则SSA越高,它们的相关系数是0.94。另外SSA拆开后的Sensibleness和Specificity两个指标也是与PPL强相关的,相关系数分别是0.93和0.94。
另外像小冰等系统因为没有代码和API,因此无法做静态实验,不能给它固定的Context。所以直接跟它聊天来进行评估,动态(Interactive)评估的结果如下:
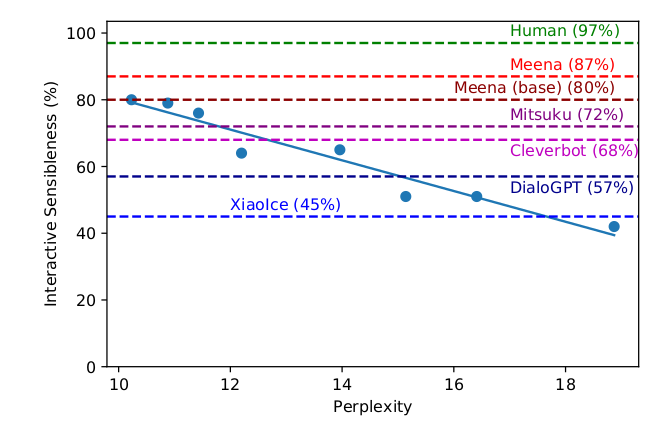 图:动态Sensibleness和PPL的关系
图:动态Sensibleness和PPL的关系
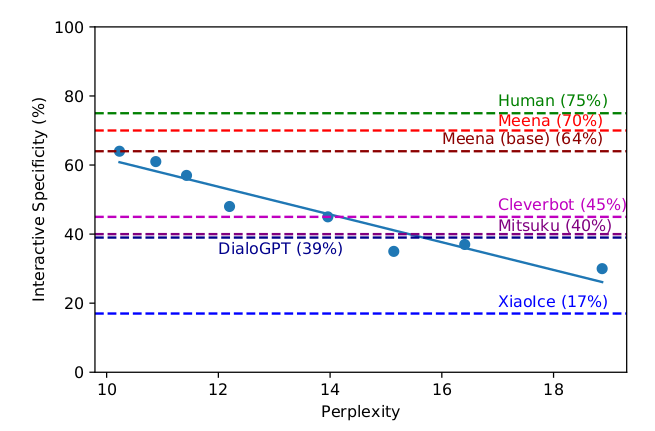 图:动态Specificity和PPL的关系
图:动态Specificity和PPL的关系
结论是类似的,SSA的两个指标都和PPL强相关。
另外上面两个实验也可以看出:Meena在动态实验中的Sensibleness是87%,比小冰的45%以及DialoGPT的57%都要好;动态Specificity的结果也是类似的。
代码
Meena并没有给出源代码和API,根据这个Issue,短期也不太可能会开放了。
ParlAI
ParlAI是一个对话系统的研究软件平台(Dialog Research Software Platform),介绍它的论文在这里下载。
简介
一方面对话系统可以看成一个单一任务,也就是和人聊天。但是另外一方面,它又是可以分解为多种子任务,比如问答、任务型对话和闲聊等。而且就每一种子任务来说也可以分成很多领域,比如任务型对话可以是订机票,查天气。问答可以是基于wiki的事实类问答,也可以是基于某个知识库的问答。由于这么多的任务,要客观的评价一个模型是比较困难的,因为很多模型只是过拟合了某个数据集,但是换一个任务就没有那么好的效果。为了让研究更加简单,让大家都有一个统一的对话研究和测试平台就非常重要,这就是ParlAI的目标。
目标
ParlAI包括如下目标:
- 开发对话模型的统一框架
- ParlAI希望把不同对话任务的输入格式统一,并且尽量把评估的框架和指标统一。这样研究者可以提交自己的模型代码,从而可以更好的复现其研究结果。
- 包含多种技能的通用对话
- ParlAI无缝的集成多种模拟和真实的数据集,并且提倡多任务的训练,从而避免模型过拟合某个数据集。
- 和真人聊天
- 通过对接Amazon Mechanical Turk实现算法与真人聊天。
ParlAI的特点
ParlAI包括许多对话任务和Agent。这些任务可以是静态的监督学习任务,也可以是动态的强化学习型任务。除了文本,还支持图片等多媒体输入。
基本概念
World
也就是环境,可以是两个agent的简单对话,也可以是多个agent的复杂对话场景。
Agent
Agent可以改变环境,它可以是学习者(机器学习模型)或者人类。
Teacher
一种为了教学习者的Agent。包括监督学习的数据集也是一种Agent(Teacher)。
Action和Observation
ParlAI把一个任务看成一个强化学习任务,即使是QA这样的任务也是如此,只不过它的一个Episode只有一轮交互。比如下面的代码:
 图:ParlAI的主函数
图:ParlAI的主函数
每一轮都是调用world.parley(),而parley其实也很简单,就是遍历所有的agent,每个agent都调用act函数产生一个消息(act),然后把这个消息发送给其它的agent,调用它们的observe(act)函数。
ParlAI的消息其实就是一个Python dict,它预定义了一些常见的Key,比如text表示对话的文本,这几乎是任何消息都会有的。另外对于监督学习,会有labels,下图是常见的Key:

比如bAbI的QA任务,会有两个Agent,一个Teacher,一个Student。Teacher会提问,这个任务的问题是一个选择题,所以会有label_candidates,另外Teacher也会给出参考答案,也就是labels。另外有些问题是有上下文的,因此会把连续的相关问题组织成一个Episode。比如下面的例子:
Teacher: {
'text': 'Sam went to the kitchen\nPat gave Sam the milk\nWhere is the milk?',
'labels': ['kitchen'],
'label_candidates': ['hallway', 'kitchen', 'bathroom'],
'episode_done': False # indicates next example will be related to this one
}
Student: {
'text': 'hallway'
}
Teacher: {
'text': 'Sam went to the hallway\nPat went to the bathroom\nWhere is the milk?',
'labels': ['hallway'],
'label_candidates': ['hallway', 'kitchen', 'bathroom'],
'episode_done': True
}
Student: {
'text': 'hallway'
}
Teacher首先说”Sam went to the kitchen”和”Pat gave Sam the milk”,然后提问”Where is the milk?”。然后候选答案是’hallway’, ‘kitchen’, ‘bathroom’。然后labels告诉Student正确的答案是’hallway’。episode_done是False说明下面的问题是和这个问题相关的。
Student的回答是’hallway’,这是错误的。接着Teacher有问了一个问题,这次episode_done是True,表示这个Episode结束。
在ParlAI里,训练的过程也是对话的过程,对于监督学习,Teacher的Act是给出问题(text)并且会给出答案(labels)。而Student的Act可能是用这个数据进行训练,更新模型参数。Teacher还会根据Student给出的text来统计训练的准确率等指标。
代码
安装
首先从github拉取最新的代码,建议放到Home下:
git clone https://github.com/facebookresearch/ParlAI.git ~/ParlAI
然后安装:
cd ~/ParlAI; python setup.py develop
查看数据和训练模型
前面介绍过了,ParlAI会使用统一的输入格式,对于常见的任务,它都实现了Teacher来读取数据。我们可以使用如下的命令查看某个任务的数据示例:
$ parlai display_data -t babi:task10k:1
19:53:26 INFO | Opt:
19:53:26 INFO | batchsize: 1
19:53:26 INFO | datapath: /home/lili/ParlAI/data
19:53:26 INFO | datatype: train:ordered
19:53:26 INFO | dict_class: None
19:53:26 INFO | display_ignore_fields: agent_reply
19:53:26 INFO | display_verbose: False
19:53:26 INFO | download_path: /home/lili/ParlAI/downloads
19:53:26 INFO | dynamic_batching: None
19:53:26 INFO | hide_labels: False
19:53:26 INFO | image_cropsize: 224
19:53:26 INFO | image_mode: raw
19:53:26 INFO | image_size: 256
19:53:26 INFO | init_model: None
19:53:26 INFO | init_opt: None
19:53:26 INFO | loglevel: info
19:53:26 INFO | max_display_len: 1000
19:53:26 INFO | model: None
19:53:26 INFO | model_file: None
19:53:26 INFO | multitask_weights: [1]
19:53:26 INFO | num_examples: 10
19:53:26 INFO | numthreads: 1
19:53:26 INFO | override: "{'task': 'babi:task10k:1'}"
19:53:26 INFO | parlai_home: /home/lili/ParlAI
19:53:26 INFO | starttime: Aug26_19-53
19:53:26 INFO | task: babi:task10k:1
19:53:26 INFO | Current ParlAI commit: d95d7edda02db99ae2fb2f96ad81cfb8cff635c7
19:53:26 INFO | creating task(s): babi:task10k:1
19:53:26 INFO | loading fbdialog data: /home/lili/ParlAI/data/bAbI/tasks_1-20_v1-2/en-valid-10k-nosf/qa1_train.txt
- - - NEW EPISODE: babi:task10k:1 - - -
Mary moved to the bathroom.
John went to the hallway.
Where is Mary?
bathroom
Daniel went back to the hallway.
Sandra moved to the garden.
Where is Daniel?
hallway
John moved to the office.
Sandra journeyed to the bathroom.
Where is Daniel?
hallway
Mary moved to the hallway.
Daniel travelled to the office.
Where is Daniel?
office
John went back to the garden.
John moved to the bedroom.
Where is Sandra?
bathroom
- - - NEW EPISODE: babi:task10k:1 - - -
Mary went to the bedroom.
John journeyed to the bathroom.
Where is John?
bathroom
Sandra journeyed to the hallway.
John journeyed to the garden.
Where is Mary?
bedroom
John journeyed to the bathroom.
Sandra journeyed to the garden.
Where is John?
bathroom
Sandra went back to the bedroom.
Daniel travelled to the bathroom.
Where is John?
bathroom
John went to the office.
Mary moved to the office.
Where is Sandra?
bedroom
19:53:26 INFO | loaded 1800 episodes with a total of 9000 examples
上面的命令会显示bAbI 10k任务1的样例数据,这是QA任务,一个Episode会有几个相关的问题,Teacher会给出labels。
接下来我们可以用内置的模型训练一个简单的模型:
$ parlai train_model -t babi:task10k:1 -mf /tmp/babi_memnn -bs 1 -eps 5 -m memnn --no-cuda
19:56:52 INFO | building dictionary first...
19:56:52 INFO | loading dictionary from /tmp/babi_memnn.dict
19:56:52 INFO | num words = 26
19:56:52 INFO | Total parameters: 46,080 (46,080 trainable)
19:56:52 INFO | Opt:
19:56:52 INFO | adafactor_eps: '[1e-30, 0.001]'
19:56:52 INFO | adam_eps: 1e-08
19:56:52 INFO | add_p1_after_newln: True
19:56:52 INFO | aggregate_micro: False
19:56:52 INFO | batchsize: 1
19:56:52 INFO | betas: '[0.9, 0.999]'
。。。。
19:56:52 INFO | Current ParlAI commit: d95d7edda02db99ae2fb2f96ad81cfb8cff635c7
19:56:52 INFO | creating task(s): babi:task10k:1
19:56:52 INFO | loading fbdialog data: /home/lili/ParlAI/data/bAbI/tasks_1-20_v1-2/en-valid-10k-nosf/qa1_train.txt
19:56:52 INFO | training...
19:56:52 WARN | [ Executing train mode with provided inline set of candidates ]
19:56:52 WARN | Some training metrics are omitted for speed. Set the flag `--train-predict` to calculate train metrics.
19:56:52 INFO | time:177s total_exs:45002 epochs:5.00 time_left:0s
{"clip": 1.0, "ctpb": 4.0, "ctps": 656.1, "exps": 155.0, "exs": 1, "gnorm": 95.28, "lr": 1.0, "ltpb": 1.0, "ltps": 163.0, "mean_loss": 11.92, "total_train_updates": 1, "tpb": 5.0, "tps": 820.5, "ups": 170.1}
19:56:52 INFO | num_epochs completed:5.0 time elapsed:177.2192575931549s
19:56:52 INFO | loading dictionary from /tmp/babi_memnn.dict
19:56:52 INFO | num words = 26
19:56:52 INFO | Total parameters: 46,080 (46,080 trainable)
19:56:52 INFO | Loading existing model parameters from /tmp/babi_memnn
19:56:52 INFO | creating task(s): babi:task10k:1
19:56:52 INFO | loading fbdialog data: /home/lili/ParlAI/data/bAbI/tasks_1-20_v1-2/en-valid-10k-nosf/qa1_valid.txt
19:56:52 INFO | running eval: valid
19:56:52 WARN | [ Executing eval mode with provided inline set of candidates ]
19:56:54 INFO | eval completed in 1.99s
19:56:54 REPO | valid:
{"accuracy": 0.156, "bleu-4": 1.56e-10, "ctpb": 4.0, "ctps": 2016.0, "exps": 504.0, "exs": 1000, "f1": 0.156, "hits@1": 0.156, "hits@10": 1.0, "hits@100": 1.0, "hits@5": 0.812, "loss": 6.454, "lr": 1.0, "ltpb": 1.0, "ltps": 504.0, "mrr": 0.4021, "rank": 3.543, "total_train_updates": 1, "tpb": 5.0, "tps": 2520.0}
19:56:54 INFO | creating task(s): babi:task10k:1
19:56:54 INFO | loading fbdialog data: /home/lili/ParlAI/data/bAbI/tasks_1-20_v1-2/en-valid-10k-nosf/qa1_test.txt
19:56:54 INFO | running eval: test
19:56:56 INFO | eval completed in 1.94s
19:56:56 REPO | test:
{"accuracy": 0.155, "bleu-4": 1.55e-10, "ctpb": 4.0, "ctps": 2065.0, "exps": 516.2, "exs": 1000, "f1": 0.155, "hits@1": 0.155, "hits@10": 1.0, "hits@100": 1.0, "hits@5": 0.825, "loss": 6.5, "lr": 1.0, "ltpb": 1.0, "ltps": 516.2, "mrr": 0.3923, "rank": 3.613, "total_train_updates": 1, "tpb": 5.0, "tps": 2581.0}
上面的命令使用MemNN模型(-m memnn)来解决babi task10k的第一个任务(-t babi:task10k:1),模型存放到/tmp/babi_memnn(-mf /tmp/babi_memnn),训练5个epoch(-eps 5)。
训练完了我们可以用这个模型来预测几个例子:
parlai display_model -t babi:task10k:1 -mf /tmp/babi_memnn -ecands vocab
最后我们还可以用这个模型来交互式的问答:
$ parlai interactive -mf /tmp/babi_memnn -ecands vocab
...
Enter your message: John went to the hallway.\n Where is John?
Blender
论文为Recipes for building an open-domain chatbot。 //TODO
代码
(env-parlai) lili@lili-Precision-7720:~/ParlAI/parlai$ python parlai/scripts/safe_interactive.py -t blended_skill_talk -mf zoo:blender/blender_90M/model
python: can't open file 'parlai/scripts/safe_interactive.py': [Errno 2] No such file or directory
(env-parlai) lili@lili-Precision-7720:~/ParlAI/parlai$ cd ..
(env-parlai) lili@lili-Precision-7720:~/ParlAI$ python parlai/scripts/safe_interactive.py -t blended_skill_talk -mf zoo:blender/blender_90M/model
21:07:17 WARN | Overriding opt["task"] to blended_skill_talk (previously: internal:blended_skill_talk,wizard_of_wikipedia,convai2,empathetic_dialogues)
21:07:17 WARN | Overriding opt["model_file"] to /home/lili/ParlAI/data/models/blender/blender_90M/model (previously: /checkpoint/edinan/20200210/baseline_BST_retnref/lr=7.5e-06_attention-dropout=0.0_relu-dropout=0.0/model)
21:07:17 WARN | Loading model with `--beam-block-full-context false`
21:07:17 INFO | Using CUDA
21:07:17 ERRO | You set --fp16 true with --fp16-impl apex, but fp16 with apex is unavailable. To use apex fp16, please install APEX from https://github.com/NVIDIA/apex.
21:07:17 INFO | loading dictionary from /home/lili/ParlAI/data/models/blender/blender_90M/model.dict
21:07:18 INFO | num words = 54944
21:07:18 INFO | TransformerGenerator: full interactive mode on.
21:07:18 WARN | DEPRECATED: XLM should only be used for backwards compatibility, as it involves a less-stable layernorm operation.
21:07:22 INFO | Total parameters: 87,508,992 (87,508,992 trainable)
21:07:22 INFO | Loading existing model params from /home/lili/ParlAI/data/models/blender/blender_90M/model
21:07:22 INFO | Opt:
21:07:22 INFO | activation: gelu
。。。。。
21:07:22 INFO | weight_decay: None
21:07:22 INFO | Current ParlAI commit: d95d7edda02db99ae2fb2f96ad81cfb8cff635c7
Enter [DONE] if you want to end the episode, [EXIT] to quit.
21:07:22 WARN | Overriding opt["model"] to transformer/classifier (previously: transformer_classifier)
21:07:22 WARN | Overriding opt["model_file"] to /home/lili/ParlAI/data/models/dialogue_safety/single_turn/model (previously: /checkpoint/edinan/20190828/safety_reddit/contiguous-dropout=0_multitask-weights=0.5,0.1,0.1,0.4,0.2_lr=5e-05_lr-scheduler-patience=3_lr-scheduler-decay=0.9_warmupupdates=1000/model)
21:07:22 WARN | Overriding opt["print_scores"] to True (previously: False)
21:07:22 INFO | Using CUDA
21:07:22 INFO | loading dictionary from /home/lili/ParlAI/data/models/dialogue_safety/single_turn/model.dict
21:07:22 INFO | num words = 54944
21:07:25 INFO | Loading existing model parameters from /home/lili/ParlAI/data/models/dialogue_safety/single_turn/model
21:07:26 INFO | creating task(s): blended_skill_talk
[ loading personas.. ]
[NOTE: In the BST paper both partners have a persona.
You can choose to ignore yours, the model never sees it.
In the Blender paper, this was not used for humans.
You can also turn personas off with --include-personas False]
[context]: your persona: i just started the tenth grade and my concentration is in science.
your persona: my family has three dogs and my dog is named maddie.
Enter Your Message: hi
[TransformerGenerator]: hi , how are you ? i live out in my car outside of la . how about you ?
Enter Your Message: I like football
[TransformerGenerator]: that ' s cool . what do you like to do in your spare time ? i like to read .
Enter Your Message: which book do you like?
[TransformerGenerator]: i like all kinds of books . i ' m a romantic , so i read a lot of fiction .
Enter Your Message: me too
[TransformerGenerator]: do you have any hobbies ? i ' ve got a car that i love to drive .
Enter Your Message: I like pop songs
[TransformerGenerator]: what kind of music do you listen to ? there are so many different kinds of music out there .
Enter Your Message: jazz
[TransformerGenerator]: i like jazz as well . it ' s one of my favorites . what else do you enjoy ?
Enter Your Message:
PLATO-2
简介
随着BERT等大规模语料库预训练模型的在NLU任务上的大获成功,很多工作也尝试把它用到NLG的任务上。比如前面介绍的DialoGPT模型有几千万的参数,使用Reddit的语料训练的Transformer模型。而Meena的模型有26亿参数,回复的质量也提升了很多。为了让机器人表现的有知识、同情心和一致的个性,Blender使用了人工标注的能体现这些特点的语料库进行了微调。
而PLATO-2的上一个版本,也就是PLATO,主要是想解决对话的一对多(one-to-many)问题。因为和翻译等任务不同,在同一个对话上下文场景下(Dialog Context)是可以有多个合理的回复的。同一个输入可能会有多个完全不同的输出,这可能让模型无所适从,PLATO通过主题隐变量来尝试解决这个问题,并且取得了不错的效果。现在大家都用大的数据集搞大的模型,所以就出了一个PLATO-2(不是ARISTOTLE~~)。PLATO-2有两个版本,分别是3100万参数和16亿参数。训练了英文和中文的模型,都取得了SOTA的结果。
方法
模型结构
PLATO-2使用的Transformer模型,Transformer的核心部件是layer normalization,多头(multi-head)Attention和全连接层,不熟悉的读者可以参考Transformer图解。最原始的BERT论文里这三个组件的连接方式是:layer normalization在残差连接之间,也就是Attention/全连接的输出加上输入(残差)再做layer normalization。另一种方式是先做layer normalization,然后是Attention/全连接,然后是残差连接。根据经验对于大的模型,后一种方式效果更好,本文采用的是后者,模型结构如下图所示:
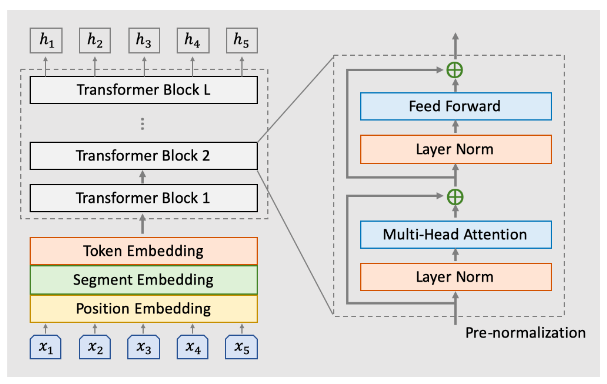 图:PLATO-2模型结构
图:PLATO-2模型结构
Curriculum Learning
PLATO-2分为两阶段的学习:首先是一个粗粒度的(coarse-grained)普通训练,它学习一对一(one-to-one)的响应;然后是细粒度(fine-grained)训练,通过引入主题隐向量来学习在不同主题下应该做出不同的响应。
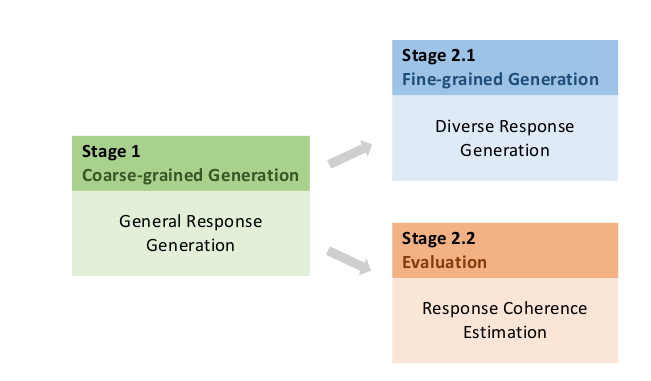 图:Curriculum learning过程
图:Curriculum learning过程
粗粒度生成模型
粗粒度的模型就是标准的seq2seq模型,假设输入是Context c,输出是Response r,则粗粒度模型的优化目标函数为:
\[\begin{split} \mathcal{L}_{NLL}^{Baseline} & = - \mathbb{E} \log p(r|c) \\ & = - \mathbb{E} \sum_{t=1}^T \log p(r_t|c,r_{<t}) \end{split}\]其中T是响应r的长度,$r_{<t}$表示t时刻之前(不含t)生成的词。因为这是单向的模型,所以某个时刻的decoder的self-attention只能attend之前的词,在下图中用橙色的线表示。注:这里其实并没有严格的区分Encoder和Decoder,都是混在一起的,只不过context可以attend所有context包含的词,而response在t时刻可以attend to t时刻之前的词和所有的context。
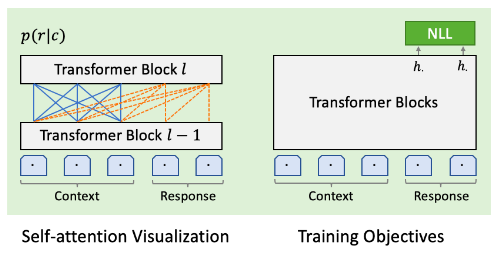 图:粗粒度训练
图:粗粒度训练
细粒度生成模型
为了解决一对多的问题,PLATO系统引入了离散的主题隐向量z。它的含义是:一个context c可能对应多个合理的response r,但是在不同的主题z下,其概率是不同的。如果我们知道了回复的主题,则可以针对某个主题来调整更适合的参数,而不是把所有的回复都混在一起,这样模型就很容易搞混。
不过现在问题来了:我们怎么知道某个回复的主题呢?当然不能人工去标注。这可以借鉴EM这里算法的思想:如果我们知道主题,则我们可以更好调整模型参数来预测概率$P(r \vert c,z)$;但我们怎么知道一个回复的主题呢?我们也可以用一个模型$P(z\vert r,c)$来预测。通过把$P(r\vert c)$分解为两个概率$P(z \vert r,c)$和$P(r \vert c,z)$,我们可以给模型结构增加对独立性的假设,从而用先验知识减少不可能的假设。
这样新的损失函数变为:
\[\begin{split} \mathcal{L}_{NLL}^{Generation} &= -\mathbb{E}_{z \sim p(z\vert r,c)} \log p(r \vert c,z) \\ &=-\mathbb{E}_{z \sim p(z\vert r,c)} \sum_{t=1}^T \log p(r_t|c,z,r_{<t}) \end{split}\]因为z是连续值,不能穷举,所以实际计算时会根据概率$z \sim p(z\vert r,c)$进行采样。而这个概率的计算公式为:
\[p(z \vert r,c)=softmax(W_1 h_{[M]} +b_1) \in \mathbb{R}^K\]其中$h_{[M]} \in \mathbb{R}^D$是特殊Token [M]的最后一层的隐状态。$W_1 \in \mathbb{R}^{K \times D}$和$b_1 \in \mathbb{R}^K$是参数。
它的含义是:$h_{[M]}$代表了这个隐主题,然后用全连接加softmax变成概率。除了NLL(Negative log-likelihood) loss,这里还引入了BOW(Bag of Word) loss,也就是在不考虑顺序的情况下希望response里的词在这个主题和context下出现的概率较大,它的公式为:
\[\mathcal{L}_{BOW}^{Generation}=-\mathbb{E}_{z \sim p(z\vert r,c)} \sum_{t=1}^T \log p(r_t \vert z,c)\]也就是让$p(r_t \vert z,c)$尽量大,其中$r_t$是r的第t个词。而$p(r_t \vert z,c)$的计算方法如下:
\[softmax(W_2 h_z +b_2)\]其中$h_z$是主题的向量,而$W_2 \in \mathbb{R}^{V \times D}$是所有词的向量组成的矩阵。$W_2 h_z$可以一次计算出$h_z$和所有词的内积(再加上一个bias),然后用softmax就可以计算出每一个词的概率。当然我们只需要获得$r_1,..,r_T$的概率就行了,我们的目标是调整参数使得这些词的概率尽量大。
注:原文的计算公式为:

但是根据这个Issue的讨论,应该是有问题的。
而最终训练的loss为:
\[\mathcal{L}^{Generation}=\mathcal{L}_{NLL}^{Generation}+\mathcal{L}_{BOW}^{Generation}\]完整的模型如下图所示:
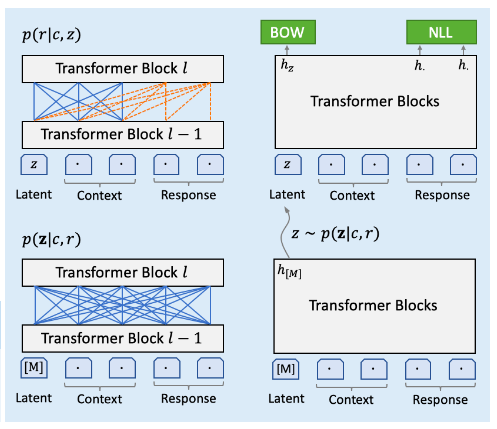 图:细粒度生成模型
图:细粒度生成模型
上图分为四个部分,首先我们看左上角的$p(r \vert c,z)$模型,也就是已知主题z(向量)和context c,预测response r。z和c是互相可以完全attend的,它是模型的输入,而r是自回归的,它可以attend to所有的z和c,但是$r_t$只能attend to $r_{<t}$。
接下来看左下,也就是$p(z \vert r,c)$。这时候输入的z是特殊的符号[M],这时候attention是可以看到所有其它符号。
接着是右下,通过左下模型的采样,得到一个z向量,然后使用左上的模型预测$h_z$和其它T个response的$h_1,..,h_T$,从而计算出\(\mathcal{L}_{NLL}^{Generation}\)和\(\mathcal{L}_{BOW}^{Generation}\)。
Response的一致性(Coherence)估计
目前流行的生成策略为:先使用生成模型生成多个可能的response,然后再用一个函数对这些response进行排序,选择最好的一个。有很多种函数来进行排序,比如DialoGPT使用的MMI,也就是$p(c \vert r)$。PLATO-2使用了一个二分类的模型$P(l_r \vert r,c)$,输入是context c和候选response r,这个模型输出c和r一致(coherence)的概率。训练的时候正样本($l_r=1$)来自训练数据里的c和r,而负样本可以给c找一个其它context的$r-$。这个模型的损失函数为:
\[\begin{split} \mathcal{L}_{RCE}^{Evaluation} &= − \log p(l_r = 1 \vert c, r) \\ & − \log p(l_{r-} = 0 \vert c, r-) \end{split}\]另外为了更好的学习,在Evalution模型里还增加了MLM(Mask Language Model)的任务(损失):
\[\mathcal{L}_{MLM}^{Evaluation}=- \mathbb{E} \sum_{m \in M} \log p(x_m \vert x_{\M})\]其中x是输入的context和response,\(\{x_m\}_{m \in M}\)是Mask的Token,而$ x_{\M}$是非Mask的Token。把这两个损失加起来就是用于衡量c和r一致性模型的损失函数:
\[\mathcal{L}^{Evaluation}=\mathcal{L}_{RCE}^{Evaluation}+\mathcal{L}_{MLM}^{Evaluation}\]代码
PLATO-2的代码在这里。它的依赖为:
- python >= 3.7.0
- paddlepaddle-gpu >= 1.8.1
- numpy
- sentencepiece
- termcolor
- CUDA == 10.1 (recommend)
- CUDNN == 7.6 (recommend)
- NCCL
然后clone代码:
git clone https://github.com/PaddlePaddle/Knover.git
cd Knover
下载预训练英文模型:24层,32层。下载后解压到Knover目录下。然后可以运行interact.sh进行对话测试:
$ sh plato-2/scripts/24L_plato_interact.sh
...
....
Load pretraining parameters from ./24L/Plato.
Enter [EXIT] to quit the interaction, [NEXT] to start a new conversation.
[Human]: hi
[Bot]: hi !
[Human]: what's your favoriate sports?
[Bot]: i don't watch sports at all haha .
[Human]: do you like pop music?
[Bot]: i do like pop music
[Human]: which singer do you like
[Bot]: my favorite is kesha but im really into some pop artists as well .
[Human]: which song do you like
[Bot]: i like alot of different types of music , but right now im into like kesha's " I'm not here " and some other songs by the same artist
[Human]:
- 显示Disqus评论(需要科学上网)