本文介绍TensorFlow 2.X和TensorFlow 1.X的主要区别和改进点,帮助TensorFlow 1.X的用户快速了解TensorFlow 2.X的新特性。
目录
TensorFlow 2.X的改进
TensorFlow 2.X的很多改进都让用户更加高效,比如移除冗余API、让API更加一致(统一的RNN API,统一的Optimizer API)和Eager execution。下面我们来看一下主要的改动。
API清理
很多API在TensorFlow 2.X被去掉或者被移动到不同的地方了。最重要的包括去掉了tf.app、tf.flags和tf.logging,它们的功能都移到了absl-py。tf.contrib的内容都从TensorFlow的代码库移到了其它地方,比如tensorflow-addons,如果大家老的代码使用了tf.contrib包的东西,可以在tensorflow-addons找一找。tf.*下面的内容也做了清理,很多不常用的函数都移到了tf.math下。另外一些函数被2.X等价的所替代,tf.summary、tf.keras.metrics和tf.keras.optimizers替代了原来的一些TensorFlow Board和tf.train.optimizers里的API。
Eager execution
TensorFlow 1.X需要用户使用tf.*里的API手动构建计算图。然后用session.run()传入输入tensor并且计算某些输出tensor。TensorFlow 2.X默认是Eager执行模式,我们在定义一个Operation的时候会动态构造计算图并且马上计算。这样的好处就是我们的代码就像在执行普通的Python代码,Graph和Session等实现细节概念都被隐藏在后面了。
Eager执行的另外一个好处就是不再需要tf.control_dependencies了(如果不知道也没有关系,以后不会再用到了),因为Tensorflow的计算图是按照Python代码的顺序执行。
无全局变量
TensorFlow 1.X严重依赖隐式的全局命名空间。当我们调用tf.Variable()创建一个变量时,它会放到一个默认的Graph里,即使对应的Python变量超出了它的生命周期(被垃圾回收)了,这个变量依然在Graph里。你可以从图中恢复出这个变量,但是你必须得知道它的名字。这通常很困难,因为很多变量并不是你手动创建的,而是诸如tf.layers.conv2d之类的API帮你创建的,你并不知道它是怎么命名变量的(除非去看源代码)。为了解决这个问题搞出了很多复杂的东西:variable_scope,全局的集合,以及tf.get_global_step()和tf.global_variables_initializer()等工具类函数,optimzier隐式的对所有”可训练”的变量计算梯度,等等。TensorFlow 2.X把这些都抛弃掉了,你只需要跟踪(track)你的Python变量就可以了,如果你不再引用你的tf.Variable,它就会被回收,对应的计算图里就不会再有它。
当然要跟踪变量也会有一些额外的工作,但是像Keras这样的框架里定义的对象(比如Layer或者Model)会自动帮我们除了变量的跟踪。
使用函数替代Session
session.run()很像函数调用:你通过feed dict传入输入,调用后就会得到输出。不过它和普通函数还是很不相同,普通函数的输入和输出是提前定义好的,而session.run可以在调用的时候指定输入和输出,当然输入输出只能是计算图中提前定义好的。在TensorFlow 2.X里,我们可以用tf.function来装饰(decorate)某个普通函数,则TensorFlow会使用JIT把这个普通的Python函数编译成一个计算图。编译后可以获得原来计算图的所有好处,包括:
- 性能
- 就像编译器和解释器的区别,编译后的代码运行效率更高,编译时可以做很多性能优化
- 可移植性
- 函数(计算图)可以导入或者导出,这样即使没有原来的(Python)代码,依然可以使用它。
下面的代码片段展示的就是TensorFlow 1.X的session.run和TensorFlow 2.X的函数:
# TensorFlow 1.X
outputs = session.run(f(placeholder), feed_dict={placeholder: input})
# TensorFlow 2.0
outputs = f(input)
通过随意的交替使用Python代码和TensorFlow代码,用户可以利用Python语言的表达能力。而在一些没有Python解释器的环境,比如移动设备、网页上,也可以运行TensorFlow。这一点是为什么TensorFlow比其它框架在移动设备上更容易移植的原因,因为最终执行的还是TensorFlow的执行引擎的C++代码,比如TensorFlow Lite,我们就是把计算图导出,然后用TensorFlow Lite的解释器在终端设备上运行。而其它很多框架在预测时离不开Python解释器。通过在Python函数上使用@tf.function,TensorFlow可以用AutoGraph自动把Python代码(当然不是全部,毕竟TensorFlow不是通用编程语言)转换成TensorFlow的等价Operation。比如:
for/while -> tf.while_loop (支持break和continue)
if -> tf.cond
for _ in dataset -> dataset.reduce
AutoGraph支持任意嵌套的控制流,这让它非常适合实现很复杂的模型,比如序列模型、强化学习和自定义循环等等。
TensorFlow 2.X推荐用法
重构为小的函数
在TensorFlow 1.X里,我们通常把所有的操作从头到尾加到计算图中,然后通过session.run来选择某些tensor作为输出(还有feed进输入),从而让TensorFlow自动根据图计算它的所有依赖。而在TensorFlow 2.X里,更好的做法是把代码封装到很小的函数里。我们不需要对每一个函数都使用tf.function从而用AutoGraph构建计算图;我们只需要对最上层的函数进行装饰就行了,比如对一次训练的一次前向计算。
使用Keras的Layer或者Model来管理变量
Keras的Layer或者Model会用variables和trainable_variables这些属性来自己管理变量,如果它的成员变量有Layer或者Model,它也会递归的管理它们的变量。比如自己管理变量:
def dense(x, W, b):
return tf.nn.sigmoid(tf.matmul(x, W) + b)
@tf.function
def multilayer_perceptron(x, w0, b0, w1, b1, w2, b2 ...):
x = dense(x, w0, b0)
x = dense(x, w1, b1)
x = dense(x, w2, b2)
虽然我们上面使用了函数,让封装代码尽量变得紧凑,但是我们还是需要自己在某个地方创建这些变量,合适的管理变量的生命周期。而如果我们使用Keras:
# 每个Layer都是callable
layers = [tf.keras.layers.Dense(hidden_size, activation=tf.nn.sigmoid) for _ in range(n)]
perceptron = tf.keras.Sequential(layers)
# layers[3].trainable_variables => returns [w3, b3]
# perceptron.trainable_variables => returns [w0, b0, ...]
Keras的Layer或者Model继承了tf.train.Checkpointable并且能够和@tf.function集成,这可以方便的对变量进行checkpoint或者用SavedModel保存整个模型的计算图。即使我们不用Keras的fit()这样的API也可以使用它来帮我们管理变量和进行tf.function的集成。
下面的Transfer Learning的示例代码展示了使用Keras来选择少部分变量进行训练是多么方便。假设我们训练的是一个多头的(multi-headed)模型,它们共享一个主干网络:
trunk = tf.keras.Sequential([...])
head1 = tf.keras.Sequential([...])
head2 = tf.keras.Sequential([...])
path1 = tf.keras.Sequential([trunk, head1])
path2 = tf.keras.Sequential([trunk, head2])
# 在主数据集上训练
for x, y in main_dataset:
with tf.GradientTape() as tape:
prediction = path1(x, training=True)
loss = loss_fn_head1(prediction, y)
gradients = tape.gradient(loss, path1.trainable_variables)
optimizer.apply_gradients(zip(gradients, path1.trainable_variables))
# 使用第二个数据集进行fine-tune,重用主干网络
for x, y in small_dataset:
with tf.GradientTape() as tape:
prediction = path2(x, training=True)
loss = loss_fn_head2(prediction, y)
gradients = tape.gradient(loss, head2.trainable_variables)
optimizer.apply_gradients(zip(gradients, head2.trainable_variables))
# 保存模型
tf.saved_model.save(trunk, output_path)
如果对tf.GradientTape()不清楚也没有关系,核心是我们首先定义trunk和两个头head1和head2,然后把它们拼接成path1和path2两个网络。我们在主数据集上遍历每一个mini-batch,然后使用path1进行前向计算,然后计算loss,然后计算梯度,最后用梯度更新参数。这样的代码是不是非常简单?
组合使用tf.data.Datasets和@tf.function
如果数据不大可以放到内存里,那么直接使用常规的Python迭代器会非常简单。否则,tf.data.Dataset是流式从磁盘获取数据的最佳方式(如果学过tf.queue就尽快忘掉吧)。Dataset是可迭代的(是iterable不是iterator),在Eager模式下就和普通的Python可迭代对象一样。把Dataset放到tf.funtion里可以很好的利用计算图的异步流式和预取(prefetch)等功能来提高效率。比如下面的代码片段:
@tf.function
def train(model, dataset, optimizer):
for x, y in dataset:
with tf.GradientTape() as tape:
prediction = model(x, training=True)
loss = loss_fn(prediction, y)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
上面的函数会把输入的dataset(假设是tf.data.Dataset对象)使用AutoGraph对它进行优化。如果使用Keras的fit()函数,那么就更不用操心了,Dataset的迭代它都帮助我们处理好了:
model.compile(optimizer=optimizer, loss=loss_fn)
model.fit(dataset)
Python的控制流会利用AutoGraph
AutoGraph会把Python的if-else和while等依赖于数据的条件/循环语句编译成Graph的诸如tf.cond或者tf.while_loop等等价操作。
在序列模型中通常会出现依赖于数据的控制流。tf.keras.layers.RNN封装了一个RNN单元(cell),这运行你静态或者动态的进行递归展开(unroll)。为了展示(实际不要这样用),我们可以自己来实现动态的展开:
class DynamicRNN(tf.keras.Model):
def __init__(self, rnn_cell):
super(DynamicRNN, self).__init__(self)
self.cell = rnn_cell
def call(self, input_data):
# [batch, time, features] -> [time, batch, features]
input_data = tf.transpose(input_data, [1, 0, 2])
outputs = tf.TensorArray(tf.float32, input_data.shape[0])
state = self.cell.zero_state(input_data.shape[1], dtype=tf.float32)
for i in tf.range(input_data.shape[0]):
output, state = self.cell(input_data[i], state)
outputs = outputs.write(i, output)
return tf.transpose(outputs.stack(), [1, 0, 2]), state
简单的解释一下上面的代码(不懂的读者可以参考RNN的一些文章,我们一般不需要了解细节):假设输入是(batch, time, features)=(8, 10, 12)。为了方便处理,首先reshape成(10, 8, 12),这样可以对第一个维度(时间)进行遍历。接着定义outputs,这是tf.TensorArray,它的大小是10(time),也就是每个时刻会产生一个输出。接着初始化RNN的状态state,它的shape是(batch, hidden_size)。接下来遍历10个时刻,用self.cell计算当前输出output和更新state,把output(shape是(batch,hidden_size))放到outputs里。
最后把outputs stack成(time, batch, hidden_size)的tensor然后transpose成(batch, time, hidden_size)的输出返回。我们可以用下面的代码来测试一下:
rnn_cell = tf.compat.v1.nn.rnn_cell.BasicRNNCell(4)
rnn = DynamicRNN(rnn_cell)
inputs = np.random.random([8, 10, 12]).astype(np.float32)
outputs, last_hidden = rnn(inputs)
print(outputs.shape) -> (8, 10, 4)
print(last_hidden.shape) -> (8, 4)
注意:我们这里要使用兼容TensorFlow 1.X的tf.compat.v1.nn.rnn_cell.BasicRNNCell,因为原来的tf.nn.rnn_cell.BasicRNNCell都挪到tf.compat.v1里了。TensorFlow 2.X没有了这些RNNCell,等价的都封装到了tf.keras.layers里,它们的API完全不同,没有zero_state这些函数,因此是不能用到这里的。
使用tf.metrics和tf.summary
为了log,使用tf.summary.scalar或者tf.summary.histogram等函数,这需要把它们放到writer的context里,这样这些函数产生的log会直接写到writer里。如果我们没有在任何context下调用tf.summary.scalar则不会产生任何效果。这和TensorFlow 1.X不同,在1.X里我们需要add_summary和merge等op把它加到计算图里。因为2.X里是直接调用,所以我们需要告诉TensorFlow当前的step(而1.X里step是放到全局变量里的)。
summary_writer = tf.summary.create_file_writer('/tmp/summaries')
with summary_writer.as_default():
tf.summary.scalar('loss', 0.1, step=42)
为了在log之前聚合数据,可以使用tf.metrics。Metric对象是有状态的,用update_state()更新状态,调用result()会得到最新的聚合结果。如果要清除当前的状态需要调用reset_states()函数。
def train(model, optimizer, dataset, log_freq=10):
avg_loss = tf.keras.metrics.Mean(name='loss', dtype=tf.float32)
for images, labels in dataset:
loss = train_step(model, optimizer, images, labels)
avg_loss.update_state(loss)
if tf.equal(optimizer.iterations % log_freq, 0):
tf.summary.scalar('loss', avg_loss.result(), step=optimizer.iterations)
avg_loss.reset_states()
def test(model, test_x, test_y, step_num):
loss = loss_fn(model(test_x, training=False), test_y)
tf.summary.scalar('loss', loss, step=step_num)
train_summary_writer = tf.summary.create_file_writer('/tmp/summaries/train')
test_summary_writer = tf.summary.create_file_writer('/tmp/summaries/test')
with train_summary_writer.as_default():
train(model, optimizer, dataset)
with test_summary_writer.as_default():
test(model, test_x, test_y, optimizer.iterations)
上面的train函数实现训练,它通过变量dataset的每一个mini-batch,调用一次train_step得到loss。为了计算平均loss,我们在最外面定义了tf.keras.metrics.Mean,然后在每次mini-batch后用update_state()更新平均loss。如果迭代次数是log_freq的倍数,则把当前的平均loss(avg_loss.result())写到scalar loss里。写完之后用reset_states()清除状态,所以这里会每过log_freq输出一次平均loss。
注意:调用scalar的时候需要把它放在一个writer的context下,否则tf.summary.scalar不会产生任何效果:
with train_summary_writer.as_default():
train(model, optimizer, dataset)
运行上面的训练程序会输出TensorBoard的log,我们可以这样查看:
tensorboard --logdir /tmp/summaries
使用tf.config.experimental_run_functions_eagerly()进行调试
在TensorFlow 2.X里,Eager执行让我们可以单步调试代码。但是某些API比如tf.function或者tf.keras为了性能和移植性会使用计算图。为了调试它们,可以用tf.config.experimental_run_functions_eagerly(True),这样就可以单步调试了。
比如:
@tf.function
def f(x):
if x > 0:
import pdb
pdb.set_trace()
x = x + 1
return x
tf.config.experimental_run_functions_eagerly(True)
f(tf.constant(1))
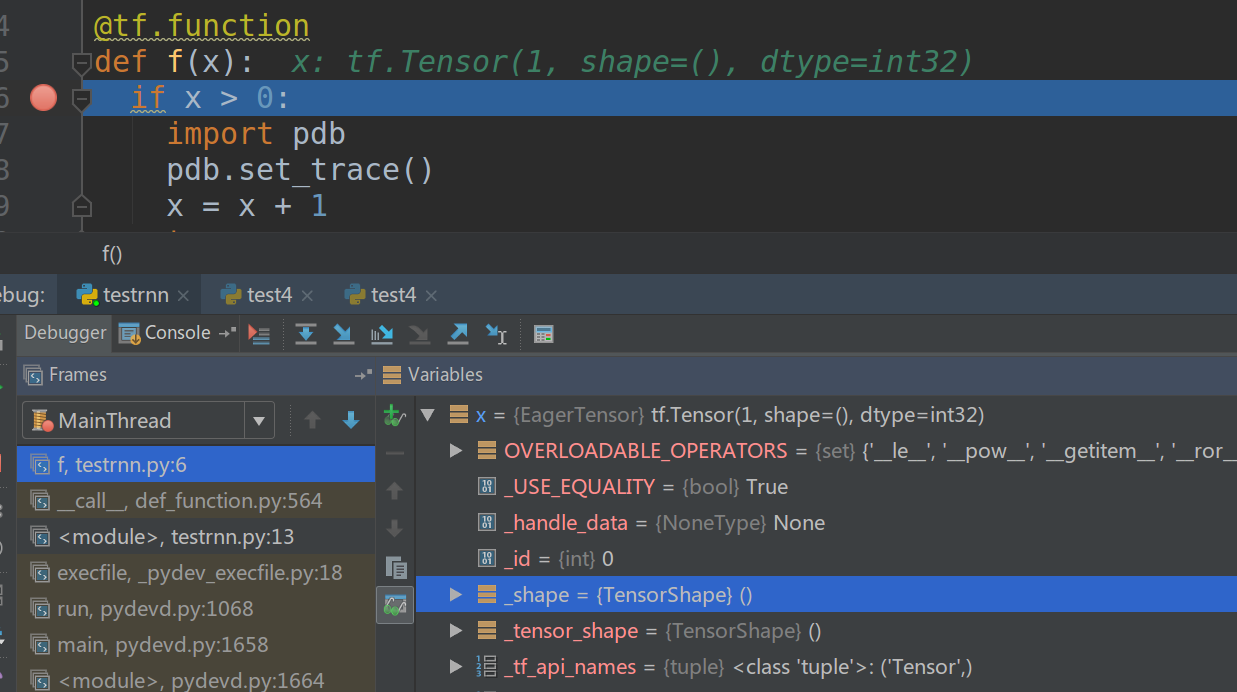 图:tf.function的调试
图:tf.function的调试
我们可以加断点调试,如果没有tf.config.experimental_run_functions_eagerly(True)则断点不会生效。tf.keras也是类似的:
class CustomModel(tf.keras.models.Model):
@tf.function
def call(self, input_data):
if tf.reduce_mean(input_data) > 0:
return input_data
else:
import pdb
pdb.set_trace()
return input_data // 2
tf.config.experimental_run_functions_eagerly(True)
model = CustomModel()
model(tf.constant([-2, -4]))
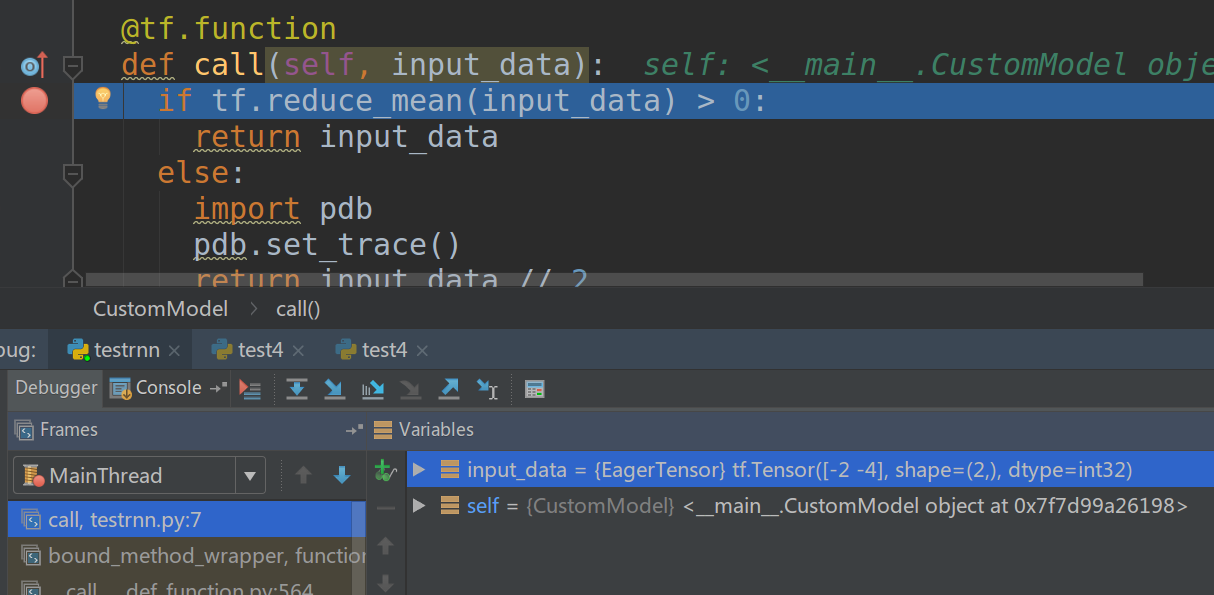 图:tf.keras的调试
图:tf.keras的调试
- 显示Disqus评论(需要科学上网)