本文介绍使用Tensor2Tensor实现一个简单的英中翻译的Demo,主要解决Tensor2Tensor安装的问题。
目录
Tensor2Tensor是Google Brain团队开发的一个深度学习库,从名字也能看出,它主要提供Seq2Seq的解决方案(当然Image2Text这种输入图片并不是序列,所以这也许是为什么名字用更加通用的Tensor2Tensor的原因)。该项目目前不再更新,Google Brain团队计划迁移到trax项目。不过目前trax还没有那么成熟,Tensor2Tensor的文档更加完善,代码示例也更多。
在Tensor2Tensor开发时,主要使用TensorFlow 1.X,后来TensorFlow 2.X出来后,最新版本的Tensor2Tensor也增加了对它的支持。但是我感觉对2.X的支持并不好,存在很多问题。
由于最新版(1.15.7)默认依赖安装的是TensorFlow 2,作者发现解码的脚本会出现奇怪的问题。经过了无数的尝试之后还是无法在2.X下正确的训练和预测,所以只好退回到TensorFlow 1.15。但是因为pip的依赖很多包并没有精确的定义是哪个版本,可能在一年前直接用pip install还能安装兼容的版本,但是到今天,这些依赖的最新版本已经发生了很大的变化。经过数天的不断尝试和hack,终于跑通了英中的翻译,记录下来更大家参考。对于探索历程不敢兴趣的读者可以直接跳到解决办法部分。
官方文档安装
安装官方文档安装非常简单,一种是自己先安装TensorFlow,然后再安装Tensor2Tensor:
pip install tensor2tensor
另一种是安装Tensor2Tensor的同时安装TensorFlow:
pip install tensor2tensor[tensorflow_gpu]
作者安装后的相关包的版本如下:
$ pip freeze|grep tensor
mesh-tensorflow==0.1.16
tensor2tensor==1.15.7
tensorboard==2.2.2
tensorboard-plugin-wit==1.6.0.post3
tensorboardX==2.0
tensorflow==2.2.0
tensorflow-addons==0.11.2
tensorflow-datasets==3.2.1
tensorflow-estimator==2.2.0
tensorflow-gan==2.0.0
tensorflow-hub==0.9.0
tensorflow-metadata==0.22.2
tensorflow-probability==0.7.0
训练的时候没有问题,但是在用t2t_decoder解码的时候会出现类似这个Issue的问题,按照大家的讨论,加了tf.disable_v2_behavior()也不好使。
后来又尝试使用程序的方式解码,但是又发现文档给出的例子使用了tfe.restore_variables_on_create,这是tf.contrib里的API,找了很久也没找到2.X里等价的API,在Tensor2Tensor创建了一个Issue,截止到今天也没得到回答。
安装TensorFlow 1.15
无奈之下作者只好尝试TensorFlow 1.X,自己在virtualenv里安装了TensorFlow 1.15后安装Tensor2Tensor:
pip install tensor2tensor
但是这个命令在安装tensor2tensor最新版本(1.15.7)时会找TensorFlow 2.X的依赖,一看没有就自己安装TensorFlow 2.X并且把1.X给卸载了。
解决办法
现在的问题是Tensor2Tensor会在安装依赖时自动安装TensorFlow 2.X,那么有没有办法不安装呢?上网搜索了一下,可以使用–no-dependencies禁止安装依赖。但这又带来一个新的问题,Tensor2Tensor除了依赖TensorFlow,还有很多其它依赖。没办法,只好一个一个手动安装。我的笨办法是:运行程序,发现哪个包缺就装哪个。但是很多包装最新的还不行,真实崩溃!通过无数次尝试,终于找到了能够运行翻译任务的所有依赖。下面是安装步骤。
首先安装TensorFlow 1.15,我这里安装的是最新的1.15.4的GPU版本。由于1.15官方的包依赖CUDA 10.0,但是我的CUDA是10.1,无法兼容,所以自己从源代码编译了一下。如果读者不需要GPU或者用的是CUDA 10.0或者其它和CUDA兼容的1.X版本(但是作者没有试过1.14或者更早的版本是否可以),可以参考下面的命令安装:
pip install "tensorflow-gpu>=1.15,<2"
接着安装Tensor2Tensor:
pip install tensor2tensor --no-dependencies
接着安装必要的依赖:
pip install requests gym tensorflow-gan mesh-tensorflow tensorflow-datasets sympy pypng matplotlib scipy
pip install tensorflow-probability==0.7.0
pip install tensorflow-datasets==3.2.1
这里需要主要的是tensorflow-probability最新版本0.8不兼容,必须安装0.7.0,类似的tensorflow-datasets也必须安装3.2.1。
安装的过程可能出现如下的警告:
tensor2tensor 1.15.7 requires bz2file, which is not installed.
tensor2tensor 1.15.7 requires dopamine-rl, which is not installed.
tensor2tensor 1.15.7 requires flask, which is not installed.
tensor2tensor 1.15.7 requires gevent, which is not installed.
tensor2tensor 1.15.7 requires google-api-python-client, which is not installed.
tensor2tensor 1.15.7 requires gunicorn, which is not installed.
tensor2tensor 1.15.7 requires kfac, which is not installed.
tensor2tensor 1.15.7 requires oauth2client, which is not installed.
tensor2tensor 1.15.7 requires opencv-python, which is not installed.
tensor2tensor 1.15.7 requires tensorflow-addons, which is not installed.
tensor2tensor 1.15.7 requires tf-slim, which is not installed.
这些依赖我都没有安装,但是并不影响翻译任务的执行。如果执行其它任务发现缺少了包,可以自行安装。下面是作者的virtualenv的完整信息:
$ pip freeze
absl-py==0.10.0
astor==0.8.1
attrs==20.2.0
cached-property==1.5.2
certifi==2020.6.20
chardet==3.0.4
click==5.1
cloudpickle==1.6.0
cycler==0.10.0
dataclasses==0.7
decorator==4.4.2
dill==0.3.3
dm-tree==0.1.5
future==0.18.2
gast==0.4.0
gin-config==0.3.0
google-pasta==0.2.0
googleapis-common-protos==1.52.0
grpcio==1.33.2
gym==0.17.3
h5py==3.0.0
idna==2.10
importlib-metadata==2.0.0
importlib-resources==3.3.0
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.2
kiwisolver==1.2.0
Markdown==3.3.3
matplotlib==3.3.2
mesh-tensorflow==0.1.17
mpmath==1.1.0
numpy==1.18.5
opt-einsum==3.3.0
Pillow==8.0.1
pkg-resources==0.0.0
promise==2.3
protobuf==3.13.0
pyglet==1.5.0
pyparsing==2.4.7
pypng==0.0.20
pystack-debugger==0.9.0
python-dateutil==2.8.1
requests==2.24.0
scipy==1.5.3
six==1.15.0
sympy==1.6.2
tensor2tensor==1.15.7
tensorboard==1.15.0
tensorflow @ file:///home/lili/soft/tensorflow-1.15.4-cp36-cp36m-linux_x86_64.whl
tensorflow-datasets==3.2.1
tensorflow-estimator==1.15.1
tensorflow-gan==2.0.0
tensorflow-hub==0.10.0
tensorflow-metadata==0.24.0
tensorflow-probability==0.7.0
termcolor==1.1.0
tqdm==4.51.0
urllib3==1.25.11
Werkzeug==1.0.1
wrapt==1.12.1
zipp==3.4.0
英汉翻译的训练
代码主要参考了翻译示例文档和这篇文章,后一篇文章还可视化了Attention。
训练
训练代码为:
import os
import tensorflow as tf
import tensor2tensor.models
from tensor2tensor import problems
from tensor2tensor.utils.trainer_lib import (create_hparams,
create_run_config,
create_experiment)
Modes = tf.estimator.ModeKeys
DATA_DIR = os.path.expanduser("~/t2tcn2/data") # This folder contain the data
TMP_DIR = os.path.expanduser("~/t2tcn2/tmp")
TRAIN_DIR = os.path.expanduser("~/t2tcn2/train") # This folder contain the model
EXPORT_DIR = os.path.expanduser("~/t2tcn2/export") # This folder contain the exported model for production
TRANSLATIONS_DIR = os.path.expanduser("~/t2tcn2/translation") # This folder contain all translated sequence
EVENT_DIR = os.path.expanduser("~/t2tcn2/event") # Test the BLEU score
USR_DIR = os.path.expanduser("~/t2tcn2/user") # This folder contains our data that we want to add
import pathlib
pathlib.Path(DATA_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TMP_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TRAIN_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(EXPORT_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TRANSLATIONS_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(EVENT_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(USR_DIR).mkdir(parents=True, exist_ok=True)
# problems.available() # Show all problems
# this is a English-Chinese dataset with 8192 vocabulary
PROBLEM = 'translate_enzh_wmt8k' # registry.list_models() # Show all registered models
MODEL = 'transformer' # Hyperparameters for the model by default
# start with "transformer_base" or 'transformer_base_single_gpu'
# if training on a single GPU
HPARAMS = 'transformer_base_single_gpu'
t2t_problem = problems.problem(PROBLEM)
t2t_problem.generate_data(DATA_DIR, TMP_DIR)
train_steps = 20000 # Total number of train steps for all Epochs
eval_steps = 100 # Number of steps to perform for each evaluation
batch_size = 1000
save_checkpoints_steps = 1000 # Save checkpoints every 1000 steps
ALPHA = 0.1 # Learning rate
schedule = "continuous_train_and_eval"# Init Hparams object
hparams = create_hparams(HPARAMS)
# Make Changes to Hparams
hparams.batch_size = batch_size
hparams.learning_rate = ALPHA
# train the model
RUN_CONFIG = create_run_config(
model_dir=TRAIN_DIR,
model_name=MODEL,
save_checkpoints_steps=save_checkpoints_steps,
keep_checkpoint_max=5
)
tensorflow_exp_fn = create_experiment(
run_config=RUN_CONFIG,
hparams=hparams,
model_name=MODEL,
problem_name=PROBLEM,
data_dir=DATA_DIR,
train_steps=train_steps,
eval_steps=eval_steps,
#schedule=schedule
)
#tensorflow_exp_fn.continuous_train_and_eval()
tensorflow_exp_fn.train_and_evaluate()
使用TensorBoard可以看到训练的BLEU大概在0.9左右,loss在2.4左右。
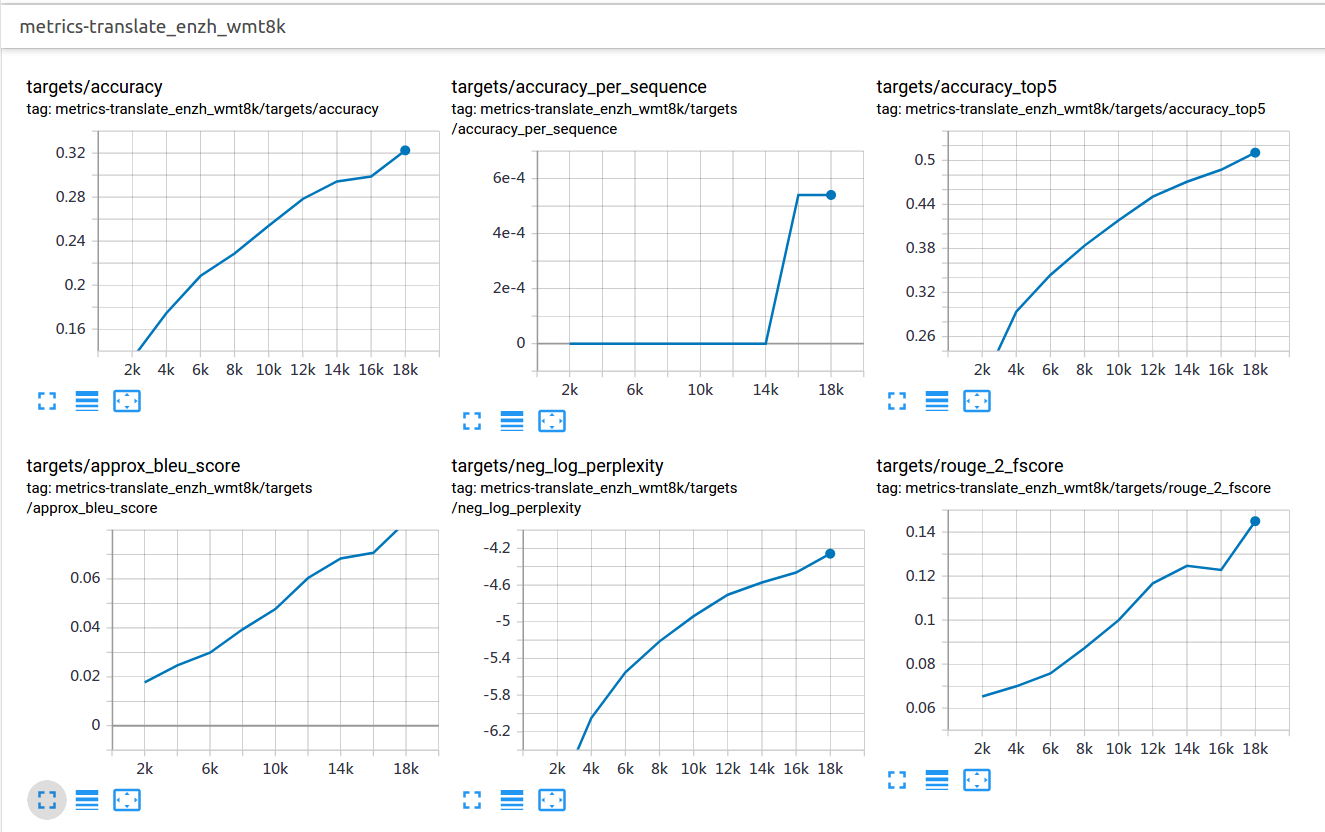
测试
import tensorflow as tf
from tensor2tensor import models
from tensor2tensor import problems
from tensor2tensor.utils import trainer_lib
from tensor2tensor.utils import t2t_model
from tensor2tensor.utils import registry
from tensor2tensor.utils.trainer_lib import create_hparams
import os
import numpy as np
PROBLEM = 'translate_enzh_wmt8k' # registry.list_models() # Show all registered models
MODEL = 'transformer' # Hyperparameters for the model by default
# start with "transformer_base" or 'transformer_base_single_gpu'
# if training on a single GPU
HPARAMS = 'transformer_base_single_gpu'
DATA_DIR = os.path.expanduser("~/t2tcn2/data")
TRAIN_DIR = os.path.expanduser("~/t2tcn2/train")
t2t_problem = problems.problem(PROBLEM)
tfe = tf.contrib.eager
tfe.enable_eager_execution()
Modes = tf.estimator.ModeKeys
hparams = create_hparams(HPARAMS, data_dir=DATA_DIR, problem_name=PROBLEM)
translate_model = registry.model(MODEL)(hparams, Modes.PREDICT)
# Get the encoders (fixed pre-processing) from the problem
encoders = t2t_problem.feature_encoders(DATA_DIR)
def encode(input_str, output_str=None):
"""Input str to features dict, ready for inference"""
inputs = encoders["inputs"].encode(input_str) + [1] # add EOS
batch_inputs = tf.reshape(inputs, [1, -1, 1]) # Make it 3D
return {"inputs": batch_inputs}
def decode(integers):
"""List of ints to str"""
integers = list(np.squeeze(integers))
if 1 in integers:
integers = integers[:integers.index(1)]
return encoders["targets"].decode(np.squeeze(integers))
# Get the latest checkpoint
ckpt_path = tf.train.latest_checkpoint(TRAIN_DIR)
print('Latest Checkpoint: ', ckpt_path)
def translate(inputs):
encoded_inputs = encode(inputs)
with tfe.restore_variables_on_create(ckpt_path):
model_output = translate_model.infer(encoded_inputs)["outputs"]
return decode(model_output)
inputs = ["I think they will never come back to the US.",
"Human rights is the first priority.",
"Everyone should have health insurance.",
"President Trump's overall approval rating dropped 7% over the past month"]
for sentence in inputs:
output = translate(sentence)
print("\33[34m Inputs:\33[30m %s" % sentence)
print("\033[35m Outputs:\33[30m %s" % output)
print()
翻译的结果为:
Inputs: I think they will never come back to the US.
Outputs: 我认为永远不会回到美国。
Inputs: Human rights is the first priority.
Outputs: 人权是首要任务。
Inputs: Everyone should have health insurance.
Outputs: 所有人都应该有医疗保险。
Inputs: President Trump's overall approval rating dropped 7% over the past month
Outputs: 特朗普总统总体支持率在过去月中下跌7%。
- 显示Disqus评论(需要科学上网)