本系列文章是Tensor2Tensor的代码阅读,主要关注中英翻译的实现。本文是第一篇,介绍阅读代码前的准备工作。
目录
前面的文章介绍了怎么安装并且把Tensor2Tensor的中英翻译示例跑起来,但是如果想深入了解这个框架,比如对其进行修改或者增强,那就必须从代码的层次了解它。本系列文章就是代码阅读整理的笔记,希望对感兴趣的读者有帮助。
为什么是Tensor2Tensor
而且Tensor2Tensor也慢慢的不再被支持,未来会切换到trax。不过就目前来看,trax还非常不成熟,而Tensor2Tensor的框架非常完善,我们的实践经验发现Tensor2Tensor在中英翻译上的默认参数设置非常合理,用我们自己收集的几千万数据训练的效果非常好。我们也尝试过OpenNMT等其它框架,但是默认的参数效果差很远。基于这些原因,我们还是继续使用Tensor2Tensor。
理论预备知识
阅读本系列文章需要不少预备知识,下面列举一些可以参考的资料。
- NMT机器翻译基础
- TensorFlow的NMT教程
- PyTorch的翻译教程
- 实战 | 手把手教你搭一个机器翻译模型 作者18年的文章。
- 统计机器翻译 ,作者的文章,介绍统计机器翻译,不是必须
- Neural Machine Translation Philipp Koehn的新书,推荐想深入了解翻译的读者仔细阅读。
- 机器翻译:基础与模型 下载地址 免费开源中文书籍,同时介绍统计机器翻译和NMT,强烈推荐。
- Transformer模型
- Transformer图解 作者介绍Transformer的文章
- Transformer代码阅读
工具准备
理论上我们有了前面的理论知识就可以开始代码阅读了,但是如果读者习惯用VIM编写或者阅读代码,那没有问题。不过对于作者来说,更加习惯在IDE里阅读和修改代码。个人认为阅读代码最好的方式是单点跟踪代码的每一行运行路径,因为Tensor2Tensor的代码量非常大,直接阅读所有的代码很难理解并且把它们的逻辑串起来。另外因为TensorFlow的静态图的方式,相比PyTorch的代码更加难以阅读。所以借助更好的工具会让你的阅读效率更高。
安装Tensor2Tensor
由于TensorFlow版本的不断升级,最新版的TensorFlow是无法支持Tensor2Tensor的(作者测试的结果)。读者可以参考使用Tensor2Tensor实现英中翻译安装合适的Tensorflow版本和Tensor2Tensor版本。
设置PyCharm
作者习惯PyCharm,下面介绍怎么在PyCharm下调试代码。我们首先假设按照使用Tensor2Tensor实现英中翻译的流程建立好了一个VirtualEnv的环境,并且路径是在~/tf1。那么只需要设置点击菜单”File”->”Setting”里设置”Project Intereter”,然后选择这个环境的python解析器:
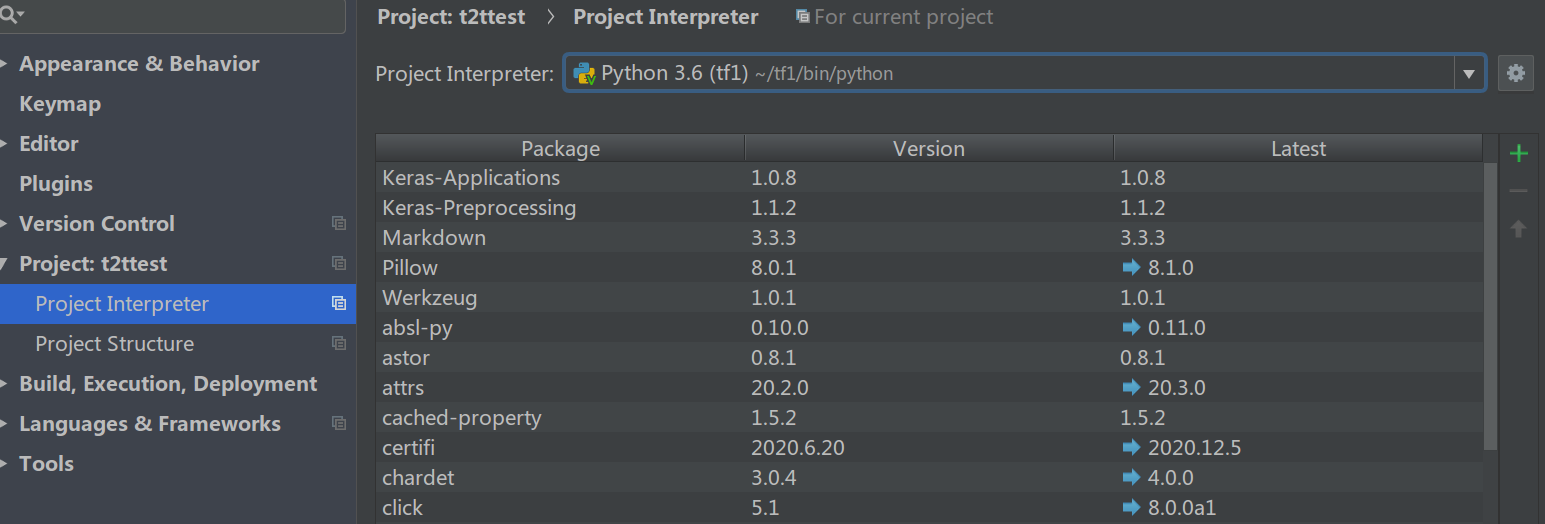 图:设置环境
图:设置环境
如果这个虚拟环境没有加到过PyCharm里,那么需要点击右上角那个像轮子的东西,选择add,进入下面的页面:
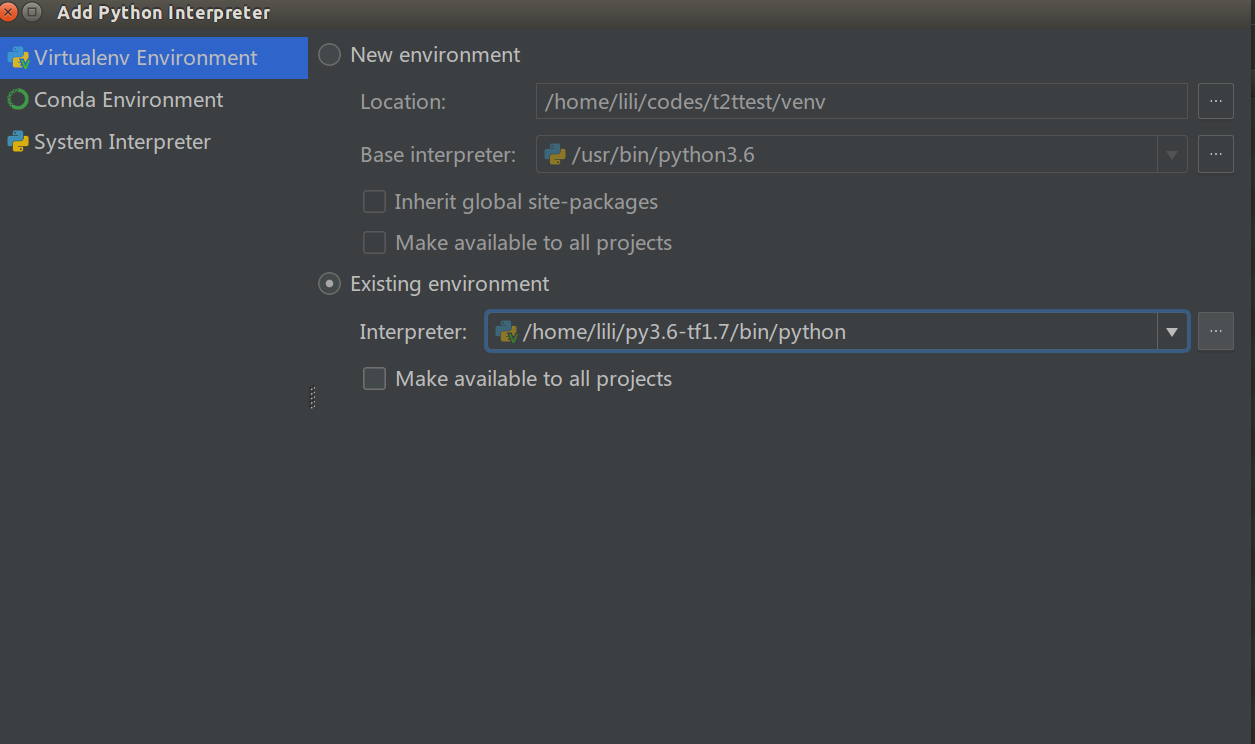 图:添加解释器
图:添加解释器
选择”Existing environment”,然后通过”…“选择到你安装的python解释器。最后记得勾选”Make available to all projects”,这样下次新建项目也可以使用这个解释器了。
设置好了IDE就可以调试了,右键点击python文件就可以debug了。 我们这里会有两个文件,训练的代码和预测的代码,完整的代码如下:
import os
import tensorflow as tf
import tensor2tensor.models
from tensor2tensor import problems
from tensor2tensor.utils.trainer_lib import (create_hparams,
create_run_config,
create_experiment)
Modes = tf.estimator.ModeKeys
DATA_DIR = os.path.expanduser("~/t2tcn2/data") # This folder contain the data
TMP_DIR = os.path.expanduser("~/t2tcn2/tmp")
TRAIN_DIR = os.path.expanduser("~/t2tcn2/train") # This folder contain the model
EXPORT_DIR = os.path.expanduser("~/t2tcn2/export") # This folder contain the exported model for production
TRANSLATIONS_DIR = os.path.expanduser("~/t2tcn2/translation") # This folder contain all translated sequence
EVENT_DIR = os.path.expanduser("~/t2tcn2/event") # Test the BLEU score
USR_DIR = os.path.expanduser("~/t2tcn2/user") # This folder contains our data that we want to add
import pathlib
pathlib.Path(DATA_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TMP_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TRAIN_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(EXPORT_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(TRANSLATIONS_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(EVENT_DIR).mkdir(parents=True, exist_ok=True)
pathlib.Path(USR_DIR).mkdir(parents=True, exist_ok=True)
# problems.available() # Show all problems
# this is a English-Chinese dataset with 8192 vocabulary
PROBLEM = 'translate_enzh_wmt8k' # registry.list_models() # Show all registered models
MODEL = 'transformer' # Hyperparameters for the model by default
# start with "transformer_base" or 'transformer_base_single_gpu'
# if training on a single GPU
HPARAMS = 'transformer_base_single_gpu'
t2t_problem = problems.problem(PROBLEM)
t2t_problem.generate_data(DATA_DIR, TMP_DIR)
train_steps = 20000 # Total number of train steps for all Epochs
eval_steps = 100 # Number of steps to perform for each evaluation
batch_size = 1000
save_checkpoints_steps = 1000 # Save checkpoints every 1000 steps
ALPHA = 0.1 # Learning rate
schedule = "continuous_train_and_eval"# Init Hparams object
hparams = create_hparams(HPARAMS)
# Make Changes to Hparams
hparams.batch_size = batch_size
hparams.learning_rate = ALPHA
# train the model
RUN_CONFIG = create_run_config(
model_dir=TRAIN_DIR,
model_name=MODEL,
save_checkpoints_steps=save_checkpoints_steps,
keep_checkpoint_max=5
)
tensorflow_exp_fn = create_experiment(
run_config=RUN_CONFIG,
hparams=hparams,
model_name=MODEL,
problem_name=PROBLEM,
data_dir=DATA_DIR,
train_steps=train_steps,
eval_steps=eval_steps,
#schedule=schedule
)
#tensorflow_exp_fn.continuous_train_and_eval()
tensorflow_exp_fn.train_and_evaluate()
import tensorflow as tf
from tensor2tensor import models
from tensor2tensor import problems
from tensor2tensor.utils import trainer_lib
from tensor2tensor.utils import t2t_model
from tensor2tensor.utils import registry
from tensor2tensor.utils.trainer_lib import create_hparams
import os
import numpy as np
PROBLEM = 'translate_enzh_wmt8k' # registry.list_models() # Show all registered models
MODEL = 'transformer' # Hyperparameters for the model by default
# start with "transformer_base" or 'transformer_base_single_gpu'
# if training on a single GPU
HPARAMS = 'transformer_base_single_gpu'
DATA_DIR = os.path.expanduser("~/t2tcn2/data")
TRAIN_DIR = os.path.expanduser("~/t2tcn2/train")
t2t_problem = problems.problem(PROBLEM)
tfe = tf.contrib.eager
tfe.enable_eager_execution()
Modes = tf.estimator.ModeKeys
hparams = create_hparams(HPARAMS, data_dir=DATA_DIR, problem_name=PROBLEM)
translate_model = registry.model(MODEL)(hparams, Modes.PREDICT)
# Get the encoders (fixed pre-processing) from the problem
encoders = t2t_problem.feature_encoders(DATA_DIR)
def encode(input_str, output_str=None):
"""Input str to features dict, ready for inference"""
inputs = encoders["inputs"].encode(input_str) + [1] # add EOS
batch_inputs = tf.reshape(inputs, [1, -1, 1]) # Make it 3D
return {"inputs": batch_inputs}
def decode(integers):
"""List of ints to str"""
integers = list(np.squeeze(integers))
if 1 in integers:
integers = integers[:integers.index(1)]
return encoders["targets"].decode(np.squeeze(integers))
# Get the latest checkpoint
ckpt_path = tf.train.latest_checkpoint(TRAIN_DIR)
print('Latest Checkpoint: ', ckpt_path)
def translate(inputs):
encoded_inputs = encode(inputs)
with tfe.restore_variables_on_create(ckpt_path):
model_output = translate_model.infer(encoded_inputs)["outputs"]
return decode(model_output)
inputs = ["I think they will never come back to the US.",
"Human rights is the first priority.",
"Everyone should have health insurance.",
"President Trump's overall approval rating dropped 7% over the past month"]
for sentence in inputs:
output = translate(sentence)
print("\33[34m Inputs:\33[30m %s" % sentence)
print("\033[35m Outputs:\33[30m %s" % output)
print()
训练代码说明
请读者在继续下面的代码阅读之前保证这两个文件的代码可以运行,并且预测的输出是没有问题的。因为每次训练都会有随机性,不会完全一样,但是测试的那几个例子应该翻译的基本正确。在有GPU的机器上训练应该需要几个小时候,另外第一次训练是需要下载数据和生成词典,也需要不少时间。因为需要多次训练,下面简单介绍一下常见的目录
训练时数据会下载到tmp目录下,比较大的是tmp/training-parallel-nc-v13.tgz,有100+M。
data目录是生成的中间数据,包括词典和tfrecord文件,这些文件通常只需要生成一次。
data
├── translate_enzh_wmt8k-dev-00000-of-00001
├── translate_enzh_wmt8k-train-00000-of-00010
├── translate_enzh_wmt8k-train-00001-of-00010
├── translate_enzh_wmt8k-train-00002-of-00010
├── translate_enzh_wmt8k-train-00003-of-00010
├── translate_enzh_wmt8k-train-00004-of-00010
├── translate_enzh_wmt8k-train-00005-of-00010
├── translate_enzh_wmt8k-train-00006-of-00010
├── translate_enzh_wmt8k-train-00007-of-00010
├── translate_enzh_wmt8k-train-00008-of-00010
├── translate_enzh_wmt8k-train-00009-of-00010
├── vocab.translate_enzh_wmt8k.8192.subwords.en
└── vocab.translate_enzh_wmt8k.8192.subwords.zh
最后就是train目录,每次运行时可以把这个目录清空。最终的模型也是存放在这里。
- 显示Disqus评论(需要科学上网)