本系列文章是Tensor2Tensor的代码阅读,主要关注中英翻译的实现。本文是第二篇,介绍训练数据生成的代码。
目录
注意:这是作者的代码阅读笔记,因为函数的调用非常复杂,所以读者一定跟着执行路径,最好有IDE的帮助,才能比较好的理解。
生成训练数据
我们从如下的两行代码开始跟踪,请读者使用IDE增加断点,然后跟着作者单步调试代码。
PROBLEM = 'translate_enzh_wmt8k' # registry.list_models() # Show all registered models
MODEL = 'transformer' # Hyperparameters for the model by default
# start with "transformer_base" or 'transformer_base_single_gpu'
# if training on a single GPU
HPARAMS = 'transformer_base_single_gpu'
t2t_problem = problems.problem(PROBLEM)
t2t_problem.generate_data(DATA_DIR, TMP_DIR)
generate_data函数的代码位置在/home/lili/tf1/lib/python3.6/site-packages/tensor2tensor/data_generators/text_problems.py。
def generate_data(self, data_dir, tmp_dir, task_id=-1):
# self.training_filepaths是一个函数,调用后会得到训练数据的路径。
filepath_fns = {
problem.DatasetSplit.TRAIN: self.training_filepaths,
problem.DatasetSplit.EVAL: self.dev_filepaths,
problem.DatasetSplit.TEST: self.test_filepaths,
}
# 如果是上面的例子,self.dataset_splits被子类重写了。
split_paths = [(split["split"], filepath_fns[split["split"]](
data_dir, split["shards"], shuffled=self.already_shuffled))
for split in self.dataset_splits]
all_paths = []
for _, paths in split_paths:
all_paths.extend(paths)
if self.is_generate_per_split:
# 这里的例子是走这条路径
for split, paths in split_paths:
generator_utils.generate_files(
self.generate_encoded_samples(data_dir, tmp_dir, split), paths)
else:
generator_utils.generate_files(
self.generate_encoded_samples(
data_dir, tmp_dir, problem.DatasetSplit.TRAIN), all_paths)
generator_utils.shuffle_dataset(all_paths, extra_fn=self._pack_fn())
然后进入generate_encoded_samples:
def generate_encoded_samples(self, data_dir, tmp_dir, dataset_split):
train = dataset_split == problem.DatasetSplit.TRAIN
train_dataset = self.get_training_dataset(tmp_dir)
datasets = train_dataset if train else _NC_TEST_DATASETS
source_datasets = [[item[0], [item[1][0]]] for item in train_dataset]
target_datasets = [[item[0], [item[1][1]]] for item in train_dataset]
source_vocab = generator_utils.get_or_generate_vocab(
data_dir,
tmp_dir,
self.source_vocab_name,
self.approx_vocab_size,
source_datasets,
file_byte_budget=1e8,
max_subtoken_length=self.max_subtoken_length)
target_vocab = generator_utils.get_or_generate_vocab(
data_dir,
tmp_dir,
self.target_vocab_name,
self.approx_vocab_size,
target_datasets,
file_byte_budget=1e8,
max_subtoken_length=self.max_subtoken_length)
tag = "train" if train else "dev"
filename_base = "wmt_enzh_%sk_tok_%s" % (self.approx_vocab_size, tag)
data_path = translate.compile_data(tmp_dir, datasets, filename_base)
return text_problems.text2text_generate_encoded(
text_problems.text2text_txt_iterator(data_path + ".lang1",
data_path + ".lang2"),
source_vocab, target_vocab)
然后进入generator_utils.get_or_generate_vocab:
def get_or_generate_vocab(data_dir, tmp_dir, vocab_filename, vocab_size,
sources, file_byte_budget=1e6,
max_subtoken_length=None):
"""Generate a vocabulary from the datasets in sources."""
vocab_generator = generate_lines_for_vocab(tmp_dir, sources, file_byte_budget)
return get_or_generate_vocab_inner(data_dir, vocab_filename, vocab_size,
vocab_generator, max_subtoken_length)
这个函数的作用是采样部分训练数据(file_byte_budget)来生成词典(Token或者subword)。max_subtoken_length默认200,实际很少有那么长的单词,可以改小一些,get_or_generate_vocab_inner通常需要比较长的时间。
generate_lines_for_vocab函数返回的是一个生成器(generator),它的代码为:
def generate_lines_for_vocab(tmp_dir, sources, file_byte_budget=1e6):
"""Generate lines for vocabulary generation."""
tf.logging.info("Generating vocab from: %s", str(sources))
for source in sources:
url = source[0]
filename = os.path.basename(url)
compressed_file = maybe_download(tmp_dir, filename, url)
for lang_file in source[1]:
tf.logging.info("Reading file: %s" % lang_file)
filepath = os.path.join(tmp_dir, lang_file)
# Extract from tar if needed.
if not tf.gfile.Exists(filepath):
read_type = "r:gz" if filename.endswith("tgz") else "r"
with tarfile.open(compressed_file, read_type) as corpus_tar:
corpus_tar.extractall(tmp_dir)
# For some datasets a second extraction is necessary.
if lang_file.endswith(".gz"):
new_filepath = os.path.join(tmp_dir, lang_file[:-3])
if tf.gfile.Exists(new_filepath):
tf.logging.info(
"Subdirectory %s already exists, skipping unpacking" % filepath)
else:
tf.logging.info("Unpacking subdirectory %s" % filepath)
gunzip_file(filepath, new_filepath)
filepath = new_filepath
with tf.gfile.GFile(filepath, mode="r") as source_file:
file_byte_budget_ = file_byte_budget
counter = 0
countermax = int(source_file.size() / file_byte_budget_ / 2)
for line in source_file:
if counter < countermax:
counter += 1
else:
if file_byte_budget_ <= 0:
break
line = line.strip()
file_byte_budget_ -= len(line)
counter = 0
yield line
file_byte_budget参数用来控制用多大数据来生成词典。如果它很大,那就可能用整个训练数据来生成,这通常很慢且没有必要。比如训练文件的大小是10GB,而file_byte_budget是1GB,那么我们可以每隔十行采样一行。当然每行的长度并不完全相同,如果隔十行采样一行可能最终不够1GB,因此实际会每五行采样一行。当然如果没有遍历完文件就采样了1GB,就可以提前结束。这个逻辑代码是使用couter和coutermax来实现的:
counter = 0
countermax = int(source_file.size() / file_byte_budget_ / 2)
for line in source_file:
if counter < countermax:
counter += 1
else:
if file_byte_budget_ <= 0:
break
line = line.strip()
file_byte_budget_ -= len(line)
counter = 0
yield line
coutermax在我们上面的例子里是10GB/1GB/2=5,也就是每5行采样一行(couter每行加一,知道counter==countermax才执行else),采样后file_byte_budget_减去实际采样的字符个数。如果file_byte_budget_<=0里,说明够了,就退出。
def get_or_generate_vocab_inner(data_dir, vocab_filename, vocab_size,
generator, max_subtoken_length=None,
reserved_tokens=None):
"""Inner implementation for vocab generators.
Args:
data_dir: 训练数据(data)和词典(vocab)文件的存储目录。如果空,则不保存。这里是/home/lili/t2tcn2/data
vocab_filename: 词典文件的名字,这里是'vocab.translate_enzh_wmt8k.8192.subwords.en'
vocab_size: 期望构造出来的词典大小,算法只能尽力构造这么大的词典,但不会完全相等,这里是8192
generator: 生成词典的generator,前面介绍过的代码
max_subtoken_length: 最大的subtoken的长度。本函数和这个参数成平方关系。
reserved_tokens: 保留token列表。`text_encoder.RESERVED_TOKENS`必须是`reserved_tokens`的前缀。如果`None`, 默认是`RESERVED_TOKENS`.
Returns:
A SubwordTextEncoder vocabulary object.
"""
if data_dir and vocab_filename:
vocab_filepath = os.path.join(data_dir, vocab_filename)
if tf.gfile.Exists(vocab_filepath):
tf.logging.info("Found vocab file: %s", vocab_filepath)
return text_encoder.SubwordTextEncoder(vocab_filepath)
else:
vocab_filepath = None
tf.logging.info("Generating vocab file: %s", vocab_filepath)
vocab = text_encoder.SubwordTextEncoder.build_from_generator(
generator, vocab_size, max_subtoken_length=max_subtoken_length,
reserved_tokens=reserved_tokens)
if vocab_filepath:
tf.gfile.MakeDirs(data_dir)
vocab.store_to_file(vocab_filepath)
return vocab
它的核心是text_encoder.SubwordTextEncoder.build_from_generator。
@classmethod
def build_from_generator(cls,
generator,
target_size,
max_subtoken_length=None,
reserved_tokens=None):
"""Builds a SubwordTextEncoder from the generated text.
Args:
generator: yields text.
target_size: int, approximate vocabulary size to create.
max_subtoken_length: Maximum length of a subtoken. If this is not set,
then the runtime and memory use of creating the vocab is quadratic in
the length of the longest token. If this is set, then it is instead
O(max_subtoken_length * length of longest token).
reserved_tokens: List of reserved tokens. The global variable
`RESERVED_TOKENS` must be a prefix of `reserved_tokens`. If this
argument is `None`, it will use `RESERVED_TOKENS`.
Returns:
SubwordTextEncoder with `vocab_size` approximately `target_size`.
"""
token_counts = collections.defaultdict(int)
for item in generator:
for tok in tokenizer.encode(native_to_unicode(item)):
token_counts[tok] += 1
encoder = cls.build_to_target_size(
target_size, token_counts, 1, 1e3,
max_subtoken_length=max_subtoken_length,
reserved_tokens=reserved_tokens)
return encoder
这个函数首先用token_counts来统计token(不是subword)的计数,然后用cls.build_to_target_size构造特定词典大小的encoder。我们先看分词,也就是tokenizer.encode()函数:
def encode(text):
"""Encode a unicode string as a list of tokens.
Args:
text: a unicode string
Returns:
a list of tokens as Unicode strings
"""
if not text:
return []
ret = []
token_start = 0
# Classify each character in the input string
is_alnum = [c in _ALPHANUMERIC_CHAR_SET for c in text]
for pos in range(1, len(text)):
if is_alnum[pos] != is_alnum[pos - 1]:
token = text[token_start:pos]
if token != u" " or token_start == 0:
ret.append(token)
token_start = pos
final_token = text[token_start:]
ret.append(final_token)
return ret
我们以输入text = ‘Today, the mood is much grimmer, with references to 1929 and 1931 beginning to abound, even if some governments continue to behave as if the crisis was more classical than exceptional.’ 为例子来看看分词的结果。
encode函数首先判断text的每一个字符(unicode)是否“字符”,这是通过字符是否包含在_ALPHANUMERIC_CHAR_SET这个set里来判断的,_ALPHANUMERIC_CHAR_SET是这么构造的:
_ALPHANUMERIC_CHAR_SET = set(
six.unichr(i) for i in range(sys.maxunicode)
if (unicodedata.category(six.unichr(i)).startswith("L") or
unicodedata.category(six.unichr(i)).startswith("N")))
关于unicode可以参考Unicode & Character Encodings in Python: A Painless Guide。关于unicode的category可以参考这里。_ALPHANUMERIC_CHAR_SET包含字母和数字,但是不包含标点。
所以上面的句子’Today, the ….’对应的is_alnum=[True, True, True, True, True, False, False, True, True, True, …],也就是逗号和空格是False(不是字母数字)。
这里的分词算法非常简单,把连续的alphanum或者非alphanum合并在一起。比如前面的例子,’T o d a y’五个都是字母数字,而后面的逗号不是,所以第一个词是’Today’,然后逗号和空格是第二个词,’the’是第三个词,…。具体的算法就是记录开始位置token_start,如果当前位置pos和前一个不同,则说明开始了一个新的词,所以text[token_start:pos]就是一个词。当然要记得处理最后一个词。另外这个算法会去掉单独的空格(但是开头初的空格保留)。
最终分词的结果为 [‘Today’, ‘, ‘, ‘the’, ‘mood’, ‘is’, ‘much’, ‘grimmer’, ‘, ‘, ‘with’, ‘references’, ‘to’, ‘1929’, ‘and’, ‘1931’, ‘beginning’, ‘to’, ‘abound’, ‘, ‘, ‘even’, ‘if’, ‘some’, ‘governments’, ‘continue’, ‘to’, ‘behave’, ‘as’, ‘if’, ‘the’, ‘crisis’, ‘was’, ‘more’, ‘classical’, ‘than’, ‘exceptional’, ‘.’]
接下来就是构造词典的过程。
@classmethod
def build_to_target_size(cls,
target_size,
token_counts,
min_val,
max_val,
max_subtoken_length=None,
reserved_tokens=None,
num_iterations=4):
"""Builds a SubwordTextEncoder that has `vocab_size` near `target_size`.
Uses simple recursive binary search to find a minimum token count that most
closely matches the `target_size`.
Args:
target_size: Desired vocab_size to approximate.
token_counts: A dictionary of token counts, mapping string to int.
min_val: An integer; lower bound for the minimum token count.
max_val: An integer; upper bound for the minimum token count.
max_subtoken_length: Maximum length of a subtoken. If this is not set,
then the runtime and memory use of creating the vocab is quadratic in
the length of the longest token. If this is set, then it is instead
O(max_subtoken_length * length of longest token).
reserved_tokens: List of reserved tokens. The global variable
`RESERVED_TOKENS` must be a prefix of `reserved_tokens`. If this
argument is `None`, it will use `RESERVED_TOKENS`.
num_iterations: An integer; how many iterations of refinement.
Returns:
A SubwordTextEncoder instance.
Raises:
ValueError: If `min_val` is greater than `max_val`.
"""
if min_val > max_val:
raise ValueError("Lower bound for the minimum token count "
"is greater than the upper bound.")
if target_size < 1:
raise ValueError("Target size must be positive.")
if reserved_tokens is None:
reserved_tokens = RESERVED_TOKENS
def bisect(min_val, max_val):
"""Bisection to find the right size."""
present_count = (max_val + min_val) // 2
tf.logging.info("Trying min_count %d" % present_count)
subtokenizer = cls()
subtokenizer.build_from_token_counts(
token_counts, present_count, num_iterations,
max_subtoken_length=max_subtoken_length,
reserved_tokens=reserved_tokens)
# Being within 1% of the target size is ok.
is_ok = abs(subtokenizer.vocab_size - target_size) * 100 < target_size
# If min_val == max_val, we can't do any better than this.
if is_ok or min_val >= max_val or present_count < 2:
return subtokenizer
if subtokenizer.vocab_size > target_size:
other_subtokenizer = bisect(present_count + 1, max_val)
else:
other_subtokenizer = bisect(min_val, present_count - 1)
if other_subtokenizer is None:
return subtokenizer
if (abs(other_subtokenizer.vocab_size - target_size) <
abs(subtokenizer.vocab_size - target_size)):
return other_subtokenizer
return subtokenizer
return bisect(min_val, max_val)
reserved_tokens=<class ‘list’>: [‘
最终是通过二分搜索的方法来实现。也就是通过去掉token_counts里词频小于min_count的词来构造subwords词典。词典大小和target_size的误差在10%以内,则返回。如果生成的词典太大,则提高min_count从而减少词的数量。
def build_from_token_counts(self,
token_counts,
min_count,
num_iterations=4,
reserved_tokens=None,
max_subtoken_length=None):
"""Train a SubwordTextEncoder based on a dictionary of word counts.
Args:
token_counts: a dictionary of Unicode strings to int.
min_count: an integer - discard subtokens with lower counts.
num_iterations: an integer. how many iterations of refinement.
reserved_tokens: List of reserved tokens. The global variable
`RESERVED_TOKENS` must be a prefix of `reserved_tokens`. If this
argument is `None`, it will use `RESERVED_TOKENS`.
max_subtoken_length: Maximum length of a subtoken. If this is not set,
then the runtime and memory use of creating the vocab is quadratic in
the length of the longest token. If this is set, then it is instead
O(max_subtoken_length * length of longest token).
Raises:
ValueError: if reserved is not 0 or len(RESERVED_TOKENS). In this case, it
is not clear what the space is being reserved for, or when it will be
filled in.
"""
if reserved_tokens is None:
reserved_tokens = RESERVED_TOKENS
else:
# There is not complete freedom in replacing RESERVED_TOKENS.
for default, proposed in zip(RESERVED_TOKENS, reserved_tokens):
if default != proposed:
raise ValueError("RESERVED_TOKENS must be a prefix of "
"reserved_tokens.")
# Initialize the alphabet. Note, this must include reserved tokens or it can
# result in encoding failures.
alphabet_tokens = chain(six.iterkeys(token_counts),
[native_to_unicode(t) for t in reserved_tokens])
self._init_alphabet_from_tokens(alphabet_tokens)
# Bootstrap the initial list of subtokens with the characters from the
# alphabet plus the escaping characters.
self._init_subtokens_from_list(list(self._alphabet),
reserved_tokens=reserved_tokens)
# We build iteratively. On each iteration, we segment all the words,
# then count the resulting potential subtokens, keeping the ones
# with high enough counts for our new vocabulary.
if min_count < 1:
min_count = 1
for i in range(num_iterations):
tf.logging.info("Iteration {0}".format(i))
# Collect all substrings of the encoded token that break along current
# subtoken boundaries.
subtoken_counts = collections.defaultdict(int)
for token, count in six.iteritems(token_counts):
iter_start_time = time.time()
escaped_token = _escape_token(token, self._alphabet)
subtokens = self._escaped_token_to_subtoken_strings(escaped_token)
start = 0
for subtoken in subtokens:
last_position = len(escaped_token) + 1
if max_subtoken_length is not None:
last_position = min(last_position, start + max_subtoken_length)
for end in range(start + 1, last_position):
new_subtoken = escaped_token[start:end]
subtoken_counts[new_subtoken] += count
start += len(subtoken)
iter_time_secs = time.time() - iter_start_time
if iter_time_secs > 0.1:
tf.logging.info(u"Processing token [{0}] took {1} seconds, consider "
"setting Text2TextProblem.max_subtoken_length to a "
"smaller value.".format(token, iter_time_secs))
# Array of sets of candidate subtoken strings, by length.
len_to_subtoken_strings = []
for subtoken_string, count in six.iteritems(subtoken_counts):
lsub = len(subtoken_string)
if count >= min_count:
while len(len_to_subtoken_strings) <= lsub:
len_to_subtoken_strings.append(set())
len_to_subtoken_strings[lsub].add(subtoken_string)
# Consider the candidates longest to shortest, so that if we accept
# a longer subtoken string, we can decrement the counts of its prefixes.
new_subtoken_strings = []
for lsub in range(len(len_to_subtoken_strings) - 1, 0, -1):
subtoken_strings = len_to_subtoken_strings[lsub]
for subtoken_string in subtoken_strings:
count = subtoken_counts[subtoken_string]
if count >= min_count:
# Exclude alphabet tokens here, as they must be included later,
# explicitly, regardless of count.
if subtoken_string not in self._alphabet:
new_subtoken_strings.append((count, subtoken_string))
for l in range(1, lsub):
subtoken_counts[subtoken_string[:l]] -= count
# Include the alphabet explicitly to guarantee all strings are encodable.
new_subtoken_strings.extend((subtoken_counts.get(a, 0), a)
for a in self._alphabet)
new_subtoken_strings.sort(reverse=True)
# Reinitialize to the candidate vocabulary.
new_subtoken_strings = [subtoken for _, subtoken in new_subtoken_strings]
if reserved_tokens:
escaped_reserved_tokens = [
_escape_token(native_to_unicode(t), self._alphabet)
for t in reserved_tokens
]
new_subtoken_strings = escaped_reserved_tokens + new_subtoken_strings
self._init_subtokens_from_list(new_subtoken_strings)
tf.logging.info("vocab_size = %d" % self.vocab_size)
首先检查RESERVED_TOKENS must be a prefix of reserved_tokens,然后把token_counts的key(词)和reserved_token拼起来得到所有的token放到alphabet_tokens里。
self._init_alphabet_from_tokens(alphabet_tokens)
def _init_alphabet_from_tokens(self, tokens):
"""Initialize alphabet from an iterable of token or subtoken strings."""
# Include all characters from all tokens in the alphabet to guarantee that
# any token can be encoded. Additionally, include all escaping characters.
self._alphabet = {c for token in tokens for c in token}
self._alphabet |= _ESCAPE_CHARS
把所有的token里出现的字符都放到self._alphabet这个set里,同时加入_ESCAPE_CHARS
# Regular expression for unescaping token strings.
# '\u' is converted to '_'
# '\\' is converted to '\'
# '\213;' is converted to unichr(213)
_UNESCAPE_REGEX = re.compile(r"\\u|\\\\|\\([0-9]+);")
_ESCAPE_CHARS = set(u"\\_u;0123456789")
_ESCAPE_CHARS包含0-9,反斜杠,下划线,分号和u。
def _init_subtokens_from_list(self, subtoken_strings, reserved_tokens=None):
"""Initialize token information from a list of subtoken strings.
Args:
subtoken_strings: a list of subtokens
reserved_tokens: List of reserved tokens. We must have `reserved_tokens`
as None or the empty list, or else the global variable `RESERVED_TOKENS`
must be a prefix of `reserved_tokens`.
Raises:
ValueError: if reserved is not 0 or len(RESERVED_TOKENS). In this case, it
is not clear what the space is being reserved for, or when it will be
filled in.
"""
if reserved_tokens is None:
reserved_tokens = []
if reserved_tokens:
self._all_subtoken_strings = reserved_tokens + subtoken_strings
else:
self._all_subtoken_strings = subtoken_strings
# we remember the maximum length of any subtoken to avoid having to
# check arbitrarily long strings.
self._max_subtoken_len = max([len(s) for s in subtoken_strings])
self._subtoken_string_to_id = {
s: i + len(reserved_tokens)
for i, s in enumerate(subtoken_strings) if s
}
# Initialize the cache to empty.
self._cache_size = 2 ** 20
self._cache = [(None, None)] * self._cache_size
self._all_subtoken_strings = reserved_tokens + subtoken_strings,通过这个语句使得初始化的subtoken只包含字符和保留词(
self._subtoken_string_to_id = {
s: i + len(reserved_tokens)
for i, s in enumerate(subtoken_strings) if s
}
上面的代码用dict记录subtoken和id的映射关系。主要第一个开始的id是2,因为0和1被保留词占用。
def _escape_token(token, alphabet):
"""Escape away underscores and OOV characters and append '_'.
This allows the token to be expressed as the concatenation of a list
of subtokens from the vocabulary. The underscore acts as a sentinel
which allows us to invertibly concatenate multiple such lists.
Args:
token: A unicode string to be escaped.
alphabet: A set of all characters in the vocabulary's alphabet.
Returns:
escaped_token: An escaped unicode string.
Raises:
ValueError: If the provided token is not unicode.
"""
if not isinstance(token, six.text_type):
raise ValueError("Expected string type for token, got %s" % type(token))
token = token.replace(u"\\", u"\\\\").replace(u"_", u"\\u")
ret = [c if c in alphabet and c != u"\n" else r"\%d;" % ord(c) for c in token]
return u"".join(ret) + "_"
这个函数会把非字母替换成它对应的unicode 的code point的数字比如123,然后变成”\123;”。另外因为反斜杠和下划线是有特殊含义的,所以把反斜杠变成两个反斜杠,下划线变成”\u”。测试它们的代码如下:
import six
import re
_UNESCAPE_REGEX = re.compile(r"\\u|\\\\|\\([0-9]+);")
_ESCAPE_CHARS = set(u"\\_u;0123456789")
def _escape_token(token, alphabet):
"""Escape away underscores and OOV characters and append '_'.
This allows the token to be expressed as the concatenation of a list
of subtokens from the vocabulary. The underscore acts as a sentinel
which allows us to invertibly concatenate multiple such lists.
Args:
token: A unicode string to be escaped.
alphabet: A set of all characters in the vocabulary's alphabet.
Returns:
escaped_token: An escaped unicode string.
Raises:
ValueError: If the provided token is not unicode.
"""
if not isinstance(token, six.text_type):
raise ValueError("Expected string type for token, got %s" % type(token))
token = token.replace(u"\\", u"\\\\").replace(u"_", u"\\u")
ret = [c if c in alphabet and c != u"\n" else r"\%d;" % ord(c) for c in token]
return u"".join(ret) + "_"
def _unescape_token(escaped_token):
"""Inverse of _escape_token().
Args:
escaped_token: a unicode string
Returns:
token: a unicode string
"""
def match(m):
if m.group(1) is None:
return u"_" if m.group(0) == u"\\u" else u"\\"
try:
return six.unichr(int(m.group(1)))
except (ValueError, OverflowError) as _:
return u"\u3013" # Unicode for undefined character.
trimmed = escaped_token[:-1] if escaped_token.endswith("_") else escaped_token
return _UNESCAPE_REGEX.sub(match, trimmed)
tokens=["abcdefg","hijklmn","1234567890"]
_alphabet = {c for token in tokens for c in token}
_alphabet |= _ESCAPE_CHARS
for s in ["abc", "\\a\U0001F929\nc"]:
print(s)
escaped = _escape_token(s, _alphabet)
print(escaped)
unescaped = _unescape_token(escaped)
print(unescaped)
所以输入token=”1929”,则输出为”1929_“。因此下划线结束的就是真正的token,否则是一个token中间的部分。所以go_表示”go”,而go可能是good里的go。
对于1929,我们先切成subword,变成[1,9,2,9,]代码如下:
def _escaped_token_to_subtoken_strings(self, escaped_token):
"""Converts an escaped token string to a list of subtoken strings.
Args:
escaped_token: An escaped token as a unicode string.
Returns:
A list of subtokens as unicode strings.
"""
# NOTE: This algorithm is greedy; it won't necessarily produce the "best"
# list of subtokens.
ret = []
start = 0
token_len = len(escaped_token)
while start < token_len:
for end in range(
min(token_len, start + self._max_subtoken_len), start, -1):
subtoken = escaped_token[start:end]
if subtoken in self._subtoken_string_to_id:
ret.append(subtoken)
start = end
break
else: # Did not break
# If there is no possible encoding of the escaped token then one of the
# characters in the token is not in the alphabet. This should be
# impossible and would be indicative of a bug.
assert False, "Token substring not found in subtoken vocabulary."
return ret
上面的算法很简单,就是最大正向分词,里面有一个优化,就是从start到end的时候我们知道_max_subtoken_len,所以从最长的subtoken长度往下扫描。接着我们可以统计subword的频率subtoken_counts。假设1929_出现72次,则:
1 19 192 1929 1929_出现72次
9 92 929 929_出现72次
2 29 29_出现72次
9出现72次
累计下来就是9出现144次,其余的72次。这就是下面这段代码的逻辑:
for token, count in six.iteritems(token_counts):
iter_start_time = time.time()
escaped_token = _escape_token(token, self._alphabet)
subtokens = self._escaped_token_to_subtoken_strings(escaped_token)
start = 0
for subtoken in subtokens:
last_position = len(escaped_token) + 1
if max_subtoken_length is not None:
last_position = min(last_position, start + max_subtoken_length)
for end in range(start + 1, last_position):
new_subtoken = escaped_token[start:end]
subtoken_counts[new_subtoken] += count
start += len(subtoken)
iter_time_secs = time.time() - iter_start_time
if iter_time_secs > 0.1:
tf.logging.info(u"Processing token [{0}] took {1} seconds, consider "
"setting Text2TextProblem.max_subtoken_length to a "
"smaller value.".format(token, iter_time_secs))
len_to_subtoken_strings是一个list,其中的每个元素是个set,我们把长度为1的放到len_to_subtoken_strings[1]的那个set里。 其实用dict会更容易理解一点,这里用list来表示这种映射关系。
# Array of sets of candidate subtoken strings, by length.
len_to_subtoken_strings = []
for subtoken_string, count in six.iteritems(subtoken_counts):
lsub = len(subtoken_string)
if count >= min_count:
while len(len_to_subtoken_strings) <= lsub:
len_to_subtoken_strings.append(set())
len_to_subtoken_strings[lsub].add(subtoken_string)
这段代码执行后的结果为:

接下来从长到短变量它,比如长度最长的16只有一个’competitiveness_‘。判断它的频次是否超过min_count(5),这里是超过了,所以把它加到new_subtoken_strings里,并且subtoken_counts里对于’c’、’co’、’com、…、’competitiveness’都要减去count,因为competitiveness_是一个subword了,那么以后切分时就不应该再把competitiveness_里的’c’、’co’等算在里面了。
# Consider the candidates longest to shortest, so that if we accept
# a longer subtoken string, we can decrement the counts of its prefixes.
new_subtoken_strings = []
for lsub in range(len(len_to_subtoken_strings) - 1, 0, -1):
subtoken_strings = len_to_subtoken_strings[lsub]
for subtoken_string in subtoken_strings:
count = subtoken_counts[subtoken_string]
if count >= min_count:
# Exclude alphabet tokens here, as they must be included later,
# explicitly, regardless of count.
if subtoken_string not in self._alphabet:
new_subtoken_strings.append((count, subtoken_string))
for l in range(1, lsub):
subtoken_counts[subtoken_string[:l]] -= count
下面两行把字符也加进去,并且按照频次降序排列:
# Include the alphabet explicitly to guarantee all strings are encodable.
new_subtoken_strings.extend((subtoken_counts.get(a, 0), a)
for a in self._alphabet)
new_subtoken_strings.sort(reverse=True)
然后生成新的subword(原来长度都是1,现在有更长的subword了!)
# Reinitialize to the candidate vocabulary.
new_subtoken_strings = [subtoken for _, subtoken in new_subtoken_strings]
if reserved_tokens:
escaped_reserved_tokens = [
_escape_token(native_to_unicode(t), self._alphabet)
for t in reserved_tokens
]
new_subtoken_strings = escaped_reserved_tokens + new_subtoken_strings
self._init_subtokens_from_list(new_subtoken_strings)
tf.logging.info("vocab_size = %d" % self.vocab_size)
再次调用_init_subtoken_strings,这个时候会包括competitiveness_,并且self._max_subtoken_len也变成了16。这样后面在对word进行subword切分时,也会尝试最大长度为16的切分。当然也会程序更新_subtoken_string_to_id。
接下来就是第二次迭代,这个时候subword有了变化,但是算法是一样的。这里举一个例子,假设token是’deepens’,切分成subword后变成<class ‘list’>: [‘deepe’, ‘ns_’]。这个时候会统计’d’、’de’、’dee’、’deep’、’deepe’、’deepen’、….’deepens_‘,那这和第一次有什么不同呢?关键的区别就在于后面的枚举,也就是start的区别。第一次deepens_会切分成
d de dee deep deepe deepen deepens deepens_
e ee eep eepe eepen eepens eepens_
e ep epe epen epens epens_
...
n ns ns_
s s_
而第二次只会切分成:
d de dee deep deepe deepen deepens deepens_
n ns ns_
中文的处理也是类似。我还是以一个例子来看。比如输入是’1929年还是1989年?’。分词的结果是<class ‘list’>: [‘1929年还是1989年’, ‘?’] 这似乎有些问题,不过通过subword的切分,最终基本都是到词或者字的粒度。
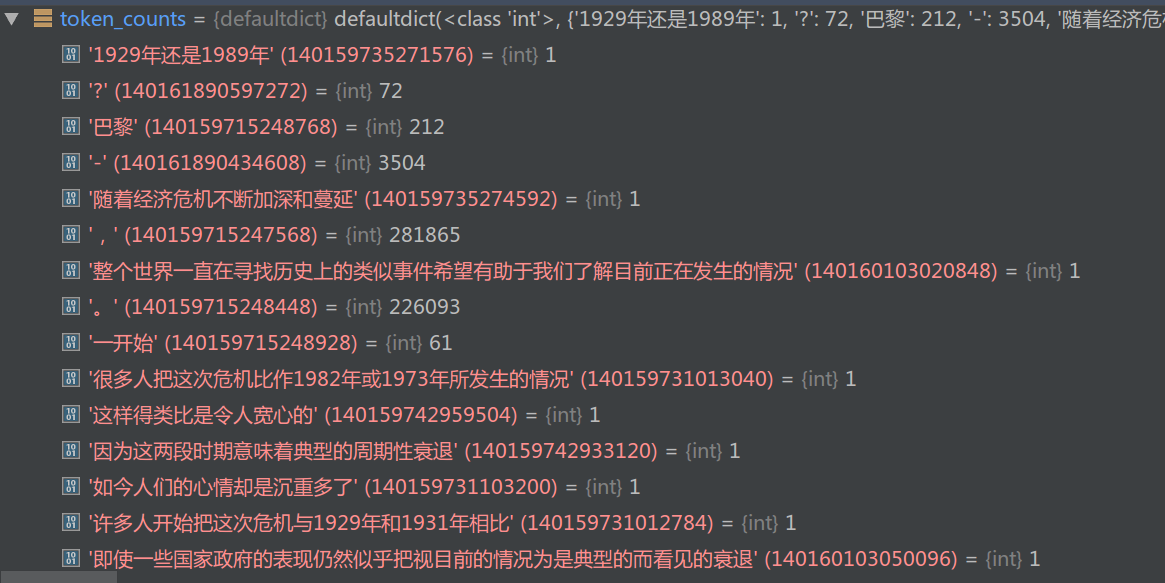 图:token_counts
图:token_counts
英文的字符(alphabeta)只有193个符号,而中文有几千个:
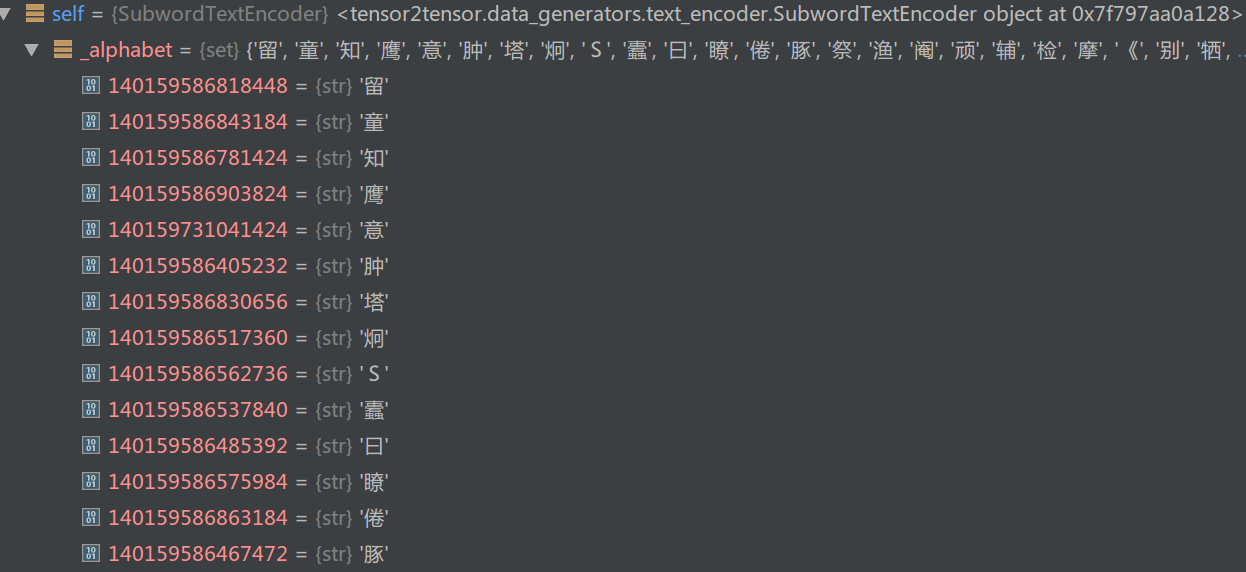 图:英文SubwordTextEncoder._alphabet
图:英文SubwordTextEncoder._alphabet
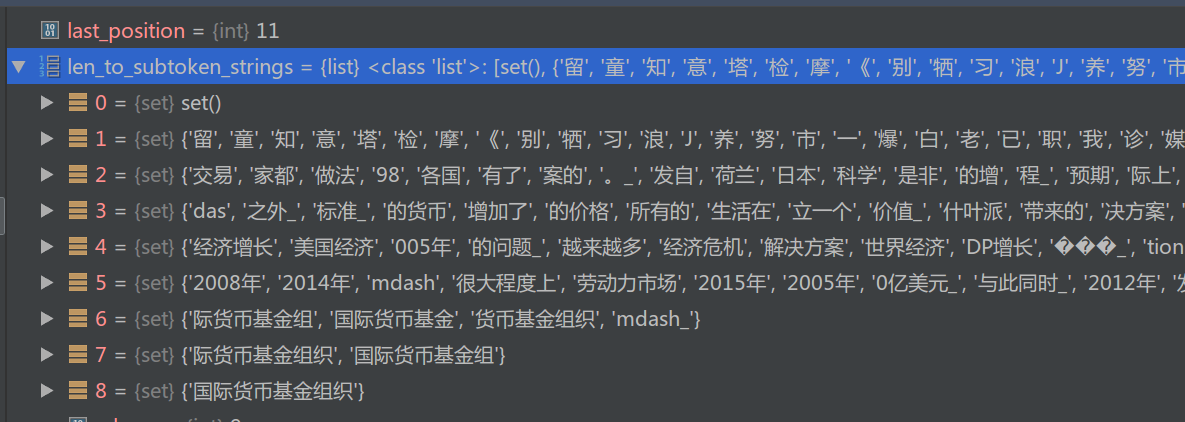 图:第一次调用结束时的len_to_subtoken_strings
图:第一次调用结束时的len_to_subtoken_strings
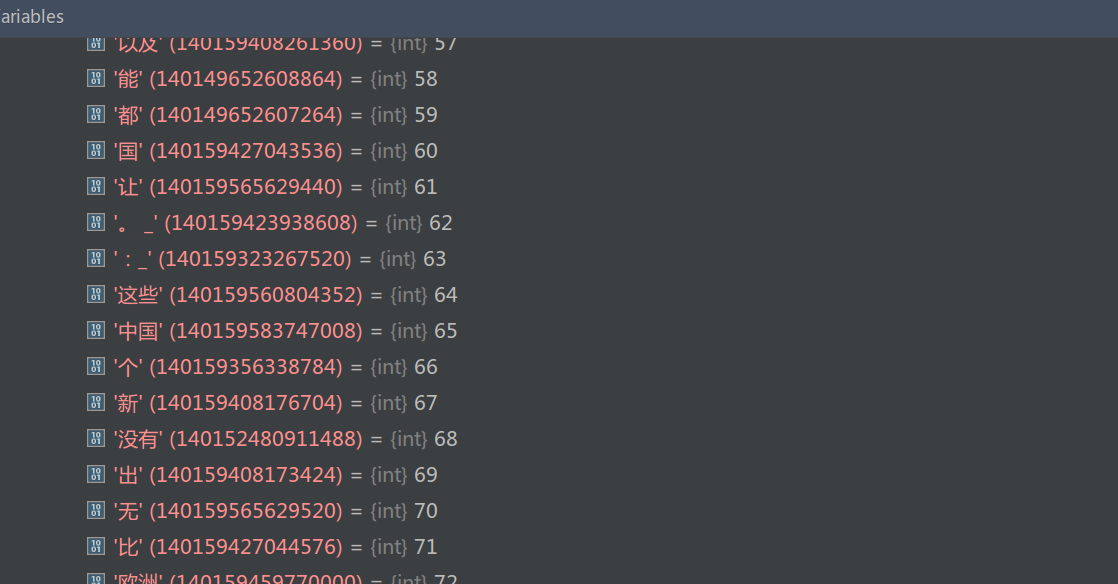 图:中文SubwordTextEncoder._alphabet
图:中文SubwordTextEncoder._alphabet
- 显示Disqus评论(需要科学上网)