本文介绍用Docker、Jupyter notebook和VSCode搭建深度学习开发环境的过程。
目录
概述
我们经常会碰到版本和环境的问题,很多开源代码并不那么完善,切换一个Tensorflow或者Pytorch的版本可能就不能运行。对于其中的第三方库的依赖也是这样。另外我们本地开发的服务器和实际生产的服务器也存在操作系统、显卡驱动以及CUDA版本不一致的问题。经常遇到的问题就是在本地开发没有问题,把代码放到服务器上就会出现各种奇怪的问题。
为了解决这个问题,我们通常使用docker来屏蔽系统之间的差异。因为同样一个镜像,理论上在所有支持它的环境上都是可以一键运行的。
但是这又带来一个问题:开发调试不方便。比如我的习惯通常是使用Pycharm逐行调试Python代码(所以我喜欢PyTorch而不是Tensorflow),但是如果我的开发环境基于docker的话,就没有办法在docker容器里运行一个pycharm(或者其它的ide,我一点不喜欢命令行调试,好像除了c/c++开发,很少用人用命令行调试python代码,实在不行都是用print大法)。很多人用Jupyter notebook,因为可以执行单个Cell,而且随时可以在某个Cell里打印一些需要调试的变量。但是即使这样,也不能单步调试,比如一个for循环,无法用Cell实现(你说每行都打印出来,直接屏幕就炸掉了,而且无法实现不修改代码的情况下实现条件断点)。
最近调研了一下,发现VsCode可以远程调试Jupyter notebook(Pycharm也可以,但是要Professional的收费版本),所以找到了这样一种开发方式:
- 使用Docker搭建深度学习环境
- 使用Jupyter notebook进行开发
- 使用VsCode对Jupyter notebook的代码进行调试
为了示例,我们会安装PyTorch和Huggingface Transformer来作为示例。
用Docker搭建环境
拉取基础镜像
根据服务器和开发机的情况选择一个合适的cuda版本,cuda的选择主要取决于显卡的驱动。10.x及其之前的版本是无法实现cuda小版本的前向兼容(二进制的后向兼容总是支持的),而11.x可以。这就意味着:我用cuda11.3编译的代码是可以用libcuda11.1.so运行的(前提是显卡驱动高于最低版本),而以前是肯定不行的。当然cuda11.1编译的代码在libcuda11.3.so上运行是没有问题的。详细细节可以参考这篇文章和官方文档。
我的开发机的driver是470.103.01,所以我们选择了如下的cuda基础镜像:
docker pull nvidia/cuda:11.2.2-cudnn8-devel-ubuntu18.04
安装python和pytorch
docker run -it --name myimg nvidia/cuda:11.2.2-cudnn8-devel-ubuntu18.04 bash
apt-get update
apt-get install python3.8 python3.8-dev python3.8-distutils python3.8-venv
python3.8 -m venv /env
source /env/bin/activate
pip install --upgrade pip
然后去pytorch官网选择合适的安装url,我这里选择了cuda11.3,因为11.x的前向兼容特性,我们是可以放心在11.2.2的镜像上运行的:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
到这一步,我们的基础pytorch就安装好了,我们可以保存成一个基础镜像:
docker commit myimg pytorchimg:v1
因为保存了镜像,所以我们就可以放心的退出这个容器。
安装transformers
用pytorchimg:v1重新运行一个容器来安装Transformer:
docker run -it --name mytorch -v /media/lili/mydisk/dockerdata:/dockerdata --gpus '"device=0"' pytorchimg:v1 bash
因为我需要测试GPU,所以需要在docker run加上–gpus参数。接着安装transformers:
source /env/bin/activate
pip install transformers
同样我们保存成一个镜像:
docker commit mytorch mytransformer:v1
然后退出容器。
在镜像里安装juypter notebook
发现没有安装notebook,所以再加一步,读者也可以把这一步合并到上面去。
source /env/bin/activate
pip install notebook
pip install ipywidgets
保存镜像:
docker commit mytorch mytransformer:v2
退出容器。然后我们最终得到的mytransformer:v2就是我们要用的开发镜像。
测试
测试docker
我们首先测试一些docker能不能跑Transformers的pipeline:
docker run -it --name mytorch -v /media/lili/mydisk/dockerdata:/dockerdata --gpus '"device=0"' -p 3344:3344 mytransformer:v2 bash
我们这里把本地的/media/lili/mydisk/dockerdata目录挂载到容器的/dockerdata。这样我就可以用我喜欢的pycharm直接在/media/lili/mydisk/dockerdata下编写代码,然后镜像可以在/dockerdata下看到,我们编辑一个简单的测试代码test.py:
import os
import torch
cache_dir = '/dockerdata/.cache/'
os.environ['TRANSFORMERS_CACHE'] = cache_dir + 'transformers'
os.environ['HF_DATASETS_CACHE'] = cache_dir + 'transformers-data'
from transformers import pipeline
classifier = pipeline("text-classification")
text = """Dear Amazon, last week I ordered an Optimus Prime action figure
from your online store in Germany. Unfortunately, when I opened the package,
I discovered to my horror that I had been sent an action figure of Megatron
instead! As a lifelong enemy of the Decepticons, I hope you can understand my
dilemma. To resolve the issue, I demand an exchange of Megatron for the
Optimus Prime figure I ordered. Enclosed are copies of my records concerning
this purchase. I expect to hear from you soon. Sincerely, Bumblebee."""
outputs = classifier(text)
print(outputs)
这段代码使用transformers的pipeline实现文本情感分类。注意:为了避免模型的cache在退出容器后丢失,我设置了环境变量TRANSFORMERS_CACHE和HF_DATASETS_CACHE到/dockerdata/.cache/,这样容器退出后这些文件也是存在的。而且如果我要在host调试,也是可以设置cache路径为/media/lili/mydisk/dockerdata/.cache/,从而共享同一份数据(不过需要注意:docker生成的文件是root的,在host使用是要确保有权限读取)。
让我们来运行一下,先进入virtualenv:
source /env/bin/activate
cd /dockerdata/
然后运行:
(env) root@833a110a1182:/dockerdata# python test.py
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english and revision af0f99b (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english).
Using a pipeline without specifying a model name and revision in production is not recommended.
[{'label': 'NEGATIVE', 'score': 0.9015460014343262}]
我们看到了正确的输出,我这里是第二次运行了,所以使用了cache的模型,如果是第一次运行,需要花一些时间下载模型。
测试jupyter notebook
进入/dockerdata
(env) root@833a110a1182:/dockerdata# pwd
/dockerdata
启动jupyter notebook:
jupyter notebook --ip=0.0.0.0 --port=3344 --no-browser --allow-root
注意上面的启动参数,–ip设置为所有的ip,这样host机器才有可能访问到,另外我们设置了端口为3344。由于要在host(非本机)访问,所以需要加上–allow-root。
我们会看到类似如下的输出:
http://127.0.0.1:3344/?token=mytoken..........................
token参数是一个随机的很长的参数。
然后我们打开浏览器进入这个url就可以创建一个notebook,比如叫testnotebook,那么我们在dockerdata下会看到一个testnotebook.ipynb文件。如果在host下可以看到创建者是root。 我们同样来测试一些test2.py的代码:
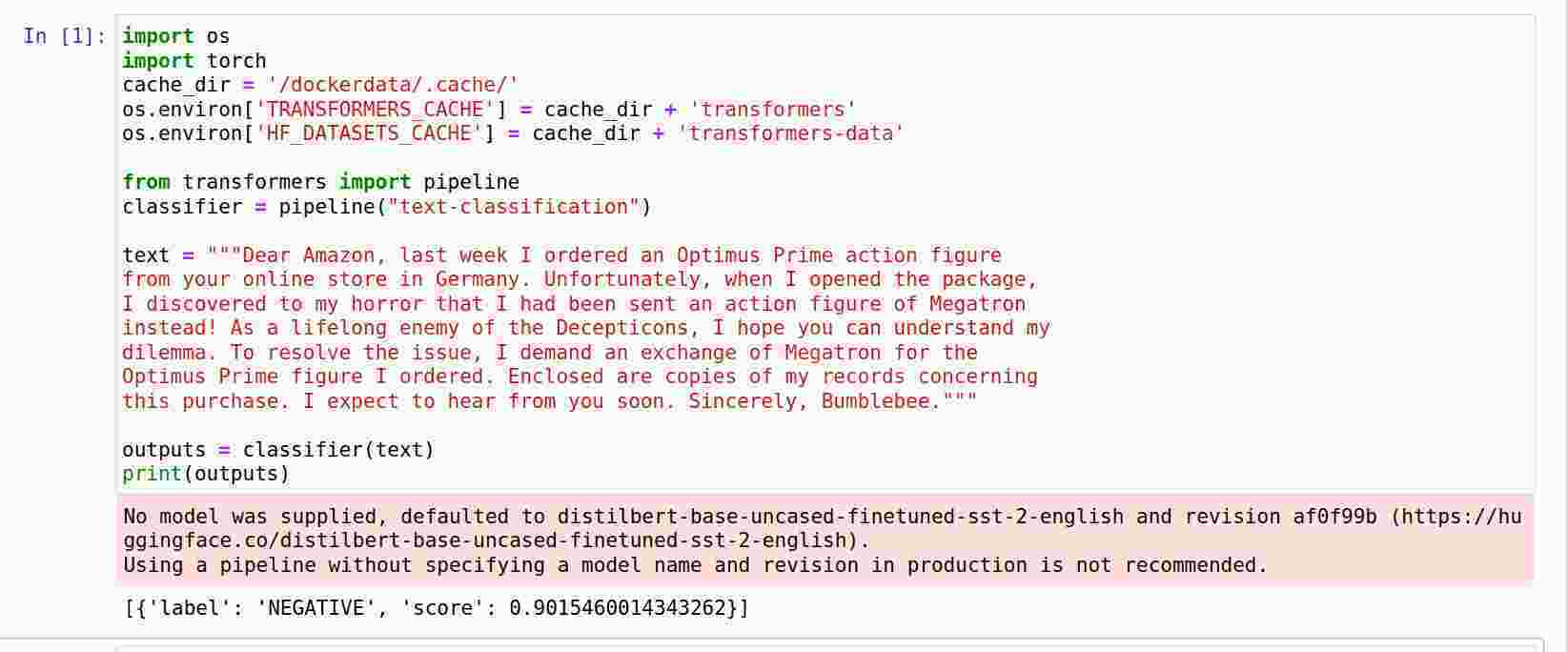 图:浏览器上运行容器里的jupyter notebook
图:浏览器上运行容器里的jupyter notebook
用vscode调试
用浏览器通过jupyter notebook做简单的开发或者调试是没有问题的,但是我们希望编写代码时有自动补全,我们希望能够单步调试。如果是调试本机(host)的python代码,用Pycharm的免费社区版就够用了,但是要调试远程的jupyter notebook,就需要收费的Pycharm专业版。对于我们这种没钱的人来说当然是不能接受的!那么现在就是VSCode大显身手的时候到了。
安装vscode
这个就不说了,大家直接去官网安装最新的版本吧,我使用的是当前最新的1.17.2。
安装python和jupyter插件
jupyter插件安装这个:
 图:安装插件
图:安装插件
远程调试
manage -> Command Palette
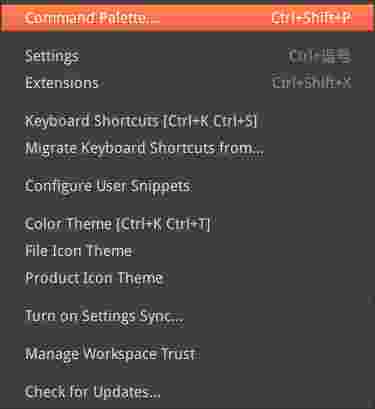
在弹出的框里输入”jupyter server”进行搜索,然后点击Specify Jupyter Server for Connection,然后输入”http://127.0.0.1:3344/?token=mytoken”,如下图所示:
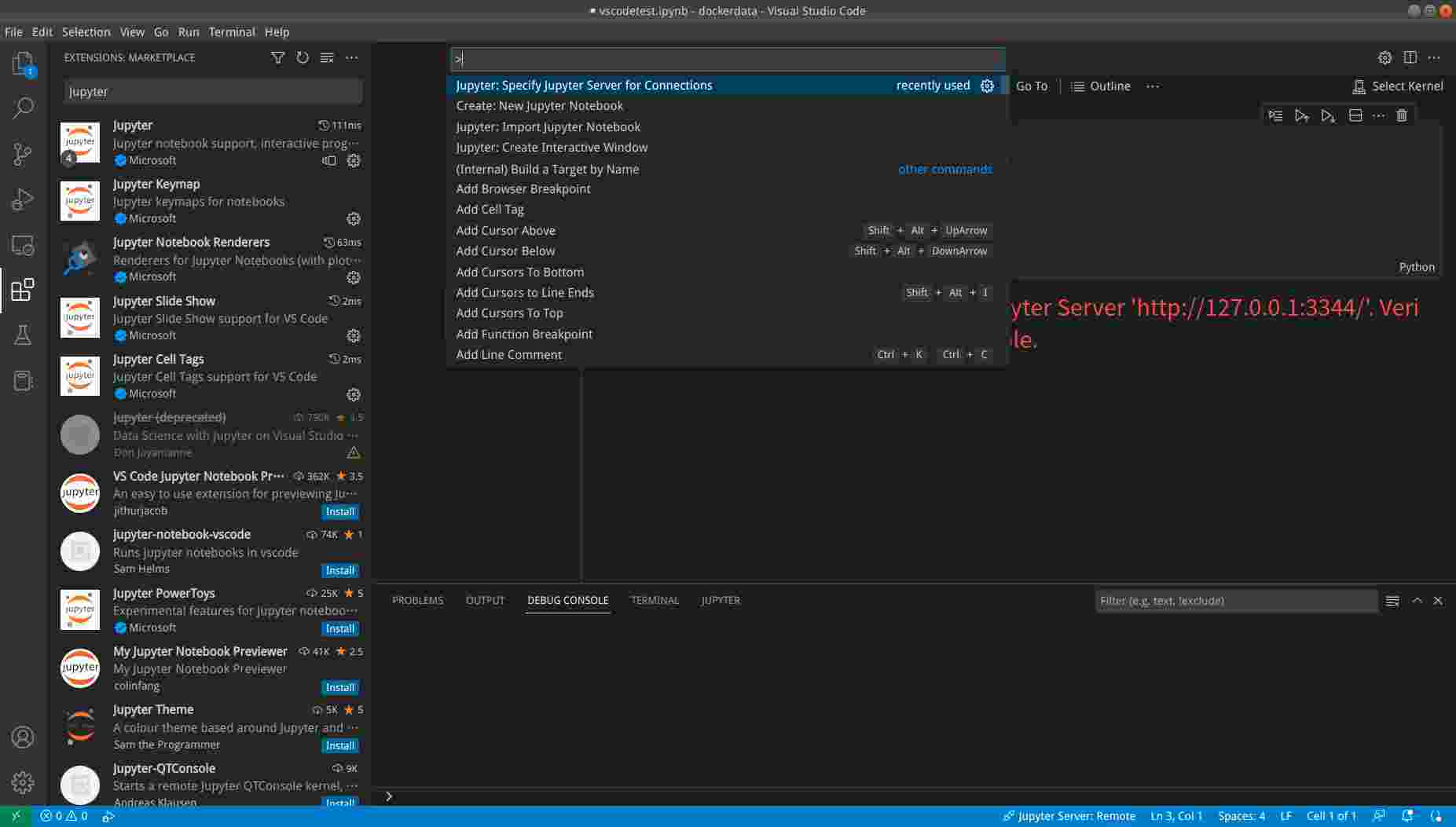
然后是创建一个notebook,同样在Command Palette里输入”New Jupyter Notebook”,这样可以创建一个notebook,然后保存到host的某个地方。
在VSCode里,我们可以用类似浏览器的方式新建Cell,运行Cell,如下图所示:
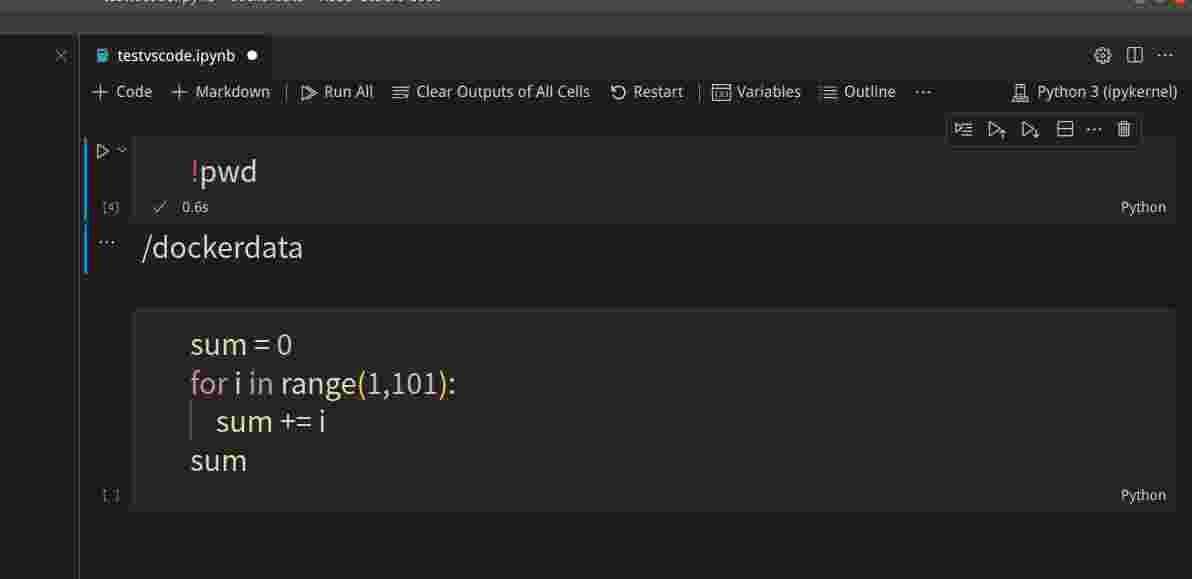
从上图可以看到,我们运行pwd返回的是容器里的当前路径,从而确定是docker容器里的notebook。
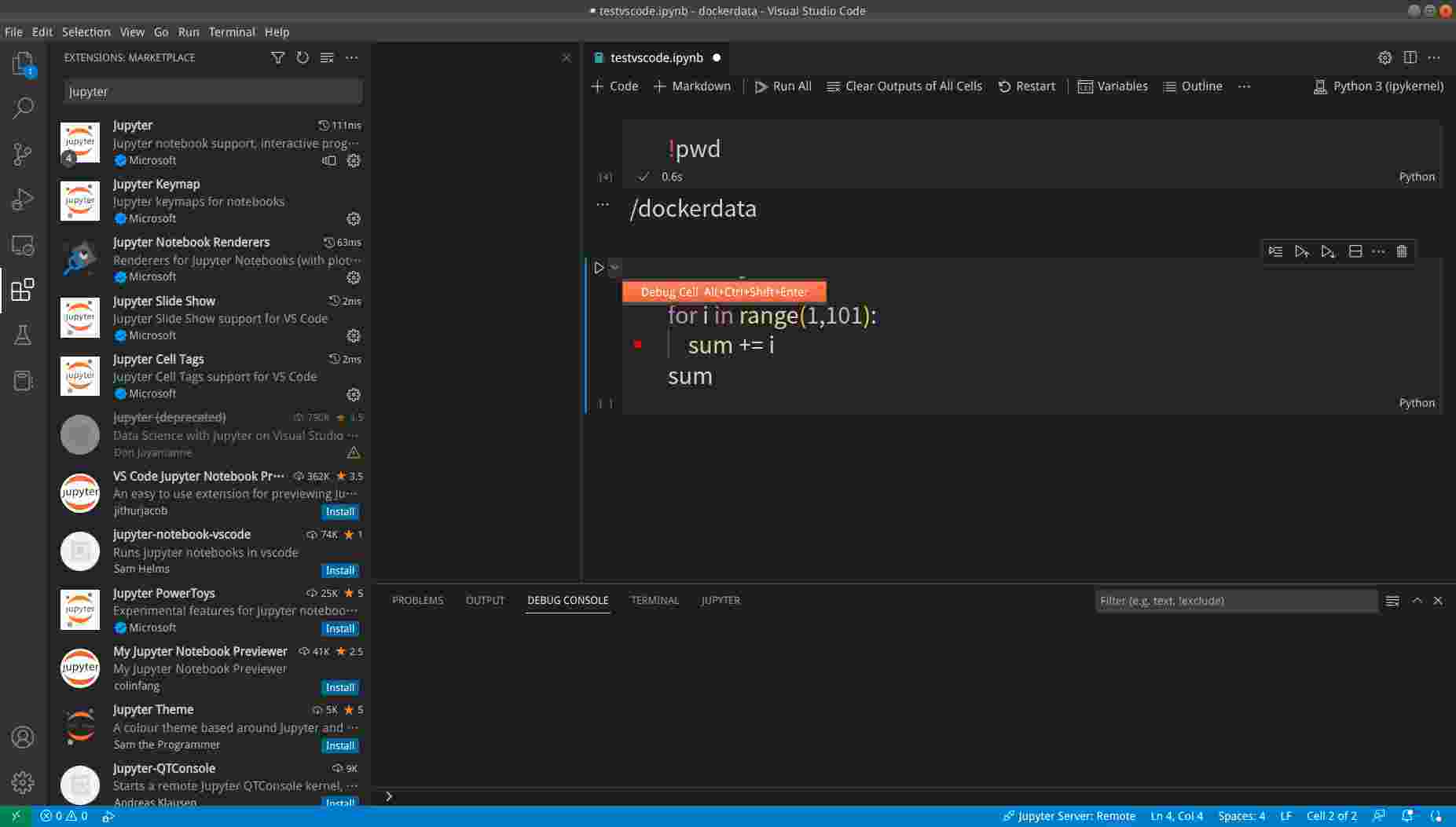
我们可以点击小红点的区域增加或者取消断点,然后用Debug Cell来调试:
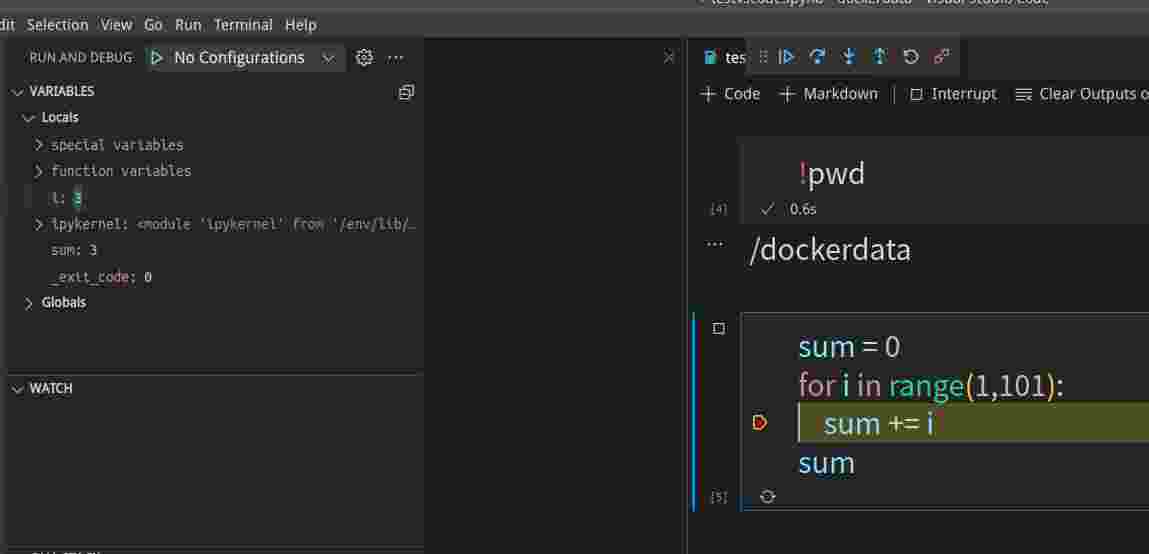
调试是左边可以看到变量的值,上方有step over和step into等功能,如下图所示:
总结
通过docker+jupyter notebook和vscode,我们就可以保证本地开发和服务器使用同样的镜像,并且调试容器里运行的notebook,这样确保环境的一致性。
如果我们远程服务器是可以直接ssh连接的,我们还可以用ssh -D设置socks代理,然后浏览器使用这个代理来调试远程服务器上的代码。但是VSCode的Jupyter插件怎么使用socks代理我们还没找到方法,上网搜索到了这个页面,并且提了一个Issue。如果读者找到了解决办法,请在文后留言。
- 显示Disqus评论(需要科学上网)