本文是论文Efficient Memory Management for Large Language Model Serving with PagedAttention的解读。
目录
Abstract
高吞吐量的LLM的serving需要batch多个请求。但是现存系统的问题是由于KV cache非常巨大并且是动态伸缩的,因为显存管理不善,导致碎片和重复,造成显存的巨大浪费,从而限制了batch的大小和吞吐量。为了解决这个问题,本文解决操作系统的分页内存管理方法,提出了PagedAttention。基于这个方法,实现了vLLM,它能够实现:1) 接近零的KV cache浪费;2) 同一请求内和不同请求间KV cache的灵活共享。实验证明本方法的吞吐量是SOTA系统的2-4倍。
Introduction
目前大模型被广泛使用,但是据估计处理LLM的请求要比传统的关键词检索贵10倍以上,因此LLM的serving系统就变得至关重要。LLM的核心是自回归的Transformer模型。这个模型每次基于prompt和之前生成的token,一次一个的方式生成下一个token,直到
为了提高吞吐量,我们需要把多个请求batch到一起,但这需要有效的内存管理。比如下图是13B的LLM,它在A100 40GB显卡上运行时的内存分布:

大约65%的(显卡)内存分配给了模型的参数,这些参数是不会改变的。接近30%的内存用于请求的动态状态。对于Transformer模型来说,这些状态包括attention机制的key和value向量(它们在多次计算中保持不变,所以可以缓存,后面还会讲到),这些缓存的key和value向量通常被叫做KV cache。另外一小部分用于其它数据,包括激活——这是LLM计算时的临时tensor。
因为模型参数是固定的,而激活只占用很少一部分内存,因此内存管理的核心就是KV cache。如果管理不善,那么将会极大的影响LLM的吞吐量。下图是本论文的vLLM和其它一些系统的对比:
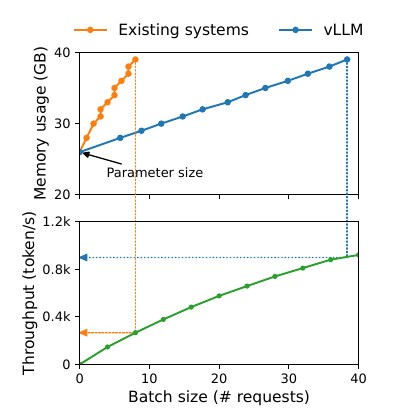
可以看到vLLM随着batch的增加,内存使用量几乎是线性增长,而吞吐量也解决线性。但是其它的系统batch不到10就崩掉了。上面的图在一开始时的内存都是26GB(参数),显卡总的内存是40GB。
作者认为,传统的LLM serving系统没有很好的管理内存。因为深度学习框架要求Tensor连续的存放在内存中,所以这些系统也把KV cache存放在连续的内存空间里。但是和深度学习训练大部分参数都是不动的(其实也是需要变动的,后面介绍Zero-Offload和PatrikStar时可以对比一下,可以发现现在深度学习系统的内存管理还是做得不够好)不同,KV cache有它独特的地方:它在解码时会动态变化,并且输出长度和生命周期也是不能提前知道的。这些特性导致现存系统的如下问题:
首先,现存系统会存在大量内部(internal)和外部(external)碎片(fragment)。为了把KV cache存放在连续的空间,这些系统会为一个请求提前分配(pre-allocate)最大可能长度的cache,这会导致内部碎片,因为实际长度可能远远小于最大长度。而这些内部内存碎片白白浪费了,只有等等这个请求结束才能释放。而且即使我们可以提前预料到生成结果的长度,比如512。我们在一开始(比较解码第一个输出token)就预留了512个token的cache空间,这些空间也不能被其它请求使用。此外,由于每个输入请求的长度不同,也会导致大量的外部碎片。下图显示了在现存系统中,只有20.4% - 38.2%的KV cache内存是真正被用于存储有用的token。
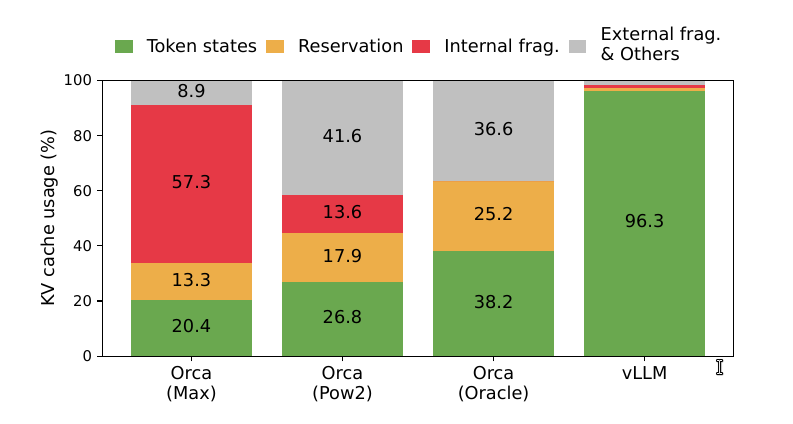
上图显示了当前(写论文时)最好的Orca系统的KV cache利用率,使用MAX分配策略的利用率只有20.4%,而即使它能够猜测请求的输出长度(实际是不可能的),它的利用率最多也就38.2%。中间的图是使用2的幂增长的策略。
其次,现存系统没有很好的利用内存共享的机会。LLM通常有一些高级的解码算法,比如并行采样(parallel sampling)和beam search。这些算法会在一个时刻生成多个输出。在这些常见中,同一个请求的多条解码路径可以部分的共享KV cache。但是由于不同序列的KV cache连续的存放在不同的空间,因此这种部分共享变得不可能。
为了解决这些问题,本文作者提出了PagedAttention,这种方法借鉴了操作系统的分页存储管理——分页虚拟内存。PagedAttention把请求的KV cache划分成固定大小的block,每个block存储固定数量token的key和value。在PagedAttention里,同一个请求的不同Block不需要连续存放。我们可以把block类比成分页,把token类比成字节(byte),把请求类比成进程(Process)。这样每个请求只有实际用到的block才被真正放到内存里,这就避免的内部碎片。另外block相对一个request的所有cache来说很小,而且是相同大小的,这不会产生很多外部碎片。最后,由于一个请求的cache被切分成了很多block,因此在不同请求间共享block也变得可能。
本文根据PagedAttention,实现了vLLM系统,它是目前的SOTA系统的吞吐量的2-4倍。本问题的主要贡献:
- 识别出(identify)LLM serving的内存分配调整并且量化了它们对性能的影响。
- 提出了PagedAttention
- 实现了vLLM
- 通过实验验证了vLLM的性能
Background
基于Transformer的大语言模型(LLM)
语言模型的目标是建模token序列$ (x_1 , … , x_n )$的概率。我们可以把这个概率使用条件概率进行分解(也叫自回归分解):
\[P(x_1, ..., x_n)=P(x_1)P(x_2 | x_1)...P(x_n | x_1,...,x_{n-1})\]Transformer是最流行的语言模型,它最重要的组件是self-attention。给定输入隐向量序列$(x_1,…,x_n) \in R^{n \times d}$,self-attention首先用三个变换矩阵把每一个$x_i$变成query,key和value三个向量:
\[q_i=W_qx_i \;\;k_i=W_kx_i \;\; v_i=W_vx_i\]接着计算self-attention的得分$a_{ij}$和输出$o_i$:
\[a_{ij}=\frac{exp(q_i^Tk_j/\sqrt(d))}{\sum_{t=1}^iexp(q_i^Tk_t/\sqrt(d))} \\ o_i=\sum_{j=1}^ia_{ij}v_j\]LLM服务和自回归生成
LLM服务的输入请求有一个input prompt $(x_1,…,x_n)$,然后LLM输出T个新的Token:$x_{n+1},…,x_{n+T}$。我们把prompt和输出加在一起叫做sequence。在自回归生成的过程中,每次只能生成一个新的token,然后把之前的token加上这个新的token作为当前的输入。因此这个过程无法并行。另外在上面attention的计算中我们可以发现key和value向量是不变的。举个例子,假设开始是i时刻:
\[q_i=W_qx_i \;\;k_i=W_kx_i \;\; v_i=W_vx_i \\ a_{ij}=\frac{exp(q_i^Tk_j/\sqrt(d))}{\sum_{t=1}^iexp(q_i^Tk_t/\sqrt(d))} \\ o_i=\sum_{j=1}^ia_{ij}v_j\]接着我们计算i+1时刻:
\[q_{i+1}=W_qx_{i+1} \;\;k_{i+1}=W_kx_{i+1} \;\; v_i=W_vx_{i+1} \\ a_{i+1,j}=\frac{exp(q_{i+1}^Tk_j/\sqrt{d})}{\sum_{t=1}^{i+1}exp(q_{i+1}^Tk_t/\sqrt(d))} \\ o_{i+1}=\sum_{j=1}^{i+1}a_{i+1,j}v_j\]仔细对比这两个公式,我们发现$k_1,…,k_i$和$v_1,…,v_i$在之前都算过了,没有必要重新计算。可以用空间换时间,把它们缓存起来。同样的道理,到了i+2时刻,前面的k和v都是可以复用的。这些缓存就叫KV cache。
给定一个prompt,生成可以分为两个过程:
prompt阶段
给定完整的prompt $ (x_1, . . . , x_n )$,我们可以计算$P(x_{n+1}|x_1,…,x_n)$。并且可以把$k_1,..,k_n$和$v_1,..,v_n$缓存起来。这个过程的输入是n个token,可以充分的并行。
自回归生成阶段
这个阶段每次生成一个新的token,在第t个迭代,计算$P(x_{n+t}|x_1,…,x_n,..,x_{n+t-1})$。注意:1到n + t − 1时刻的key和value向量都在缓存里,只需要计算$k_{n+t}$和$v_{n+t}$就可以了,而且计算完了之后也可以缓存起来。这个阶段会一直进行直到输出
LLM的batching技术
为了提升serving的效率,可以把多个请求batch起来。因为模型的参数是固定的,处理多个请求只需要移动一次,这样效率会比较高。但是LLM的batching有两个问题。第一个是:不同的请求到底时间不同,最简单的方法时先来的等待一个最长时间,然后把这一批一起处理。这里存在的问题是时间太长,则先到的请求处理时间过长,等待时间太短,则batch不起来。第二个问题就是请求的长度不一样,如果用最长的来batch,则会造成内存浪费。
为了解决这个问题,更细粒度的batch策略被提了出来,比如cellular batching(没有读过相关论文,因为与本论文无关,暂时不讨论)和迭代粒度的batching(本文使用的方法)。在传统的方法中,如果第一个请求的输入是100个token,输出是100个token,假设现在处理它,那么后面来的请求要等到200个token都处理完了才能排上队。但是前面介绍过,除了第一个阶段会用100个prompt的token生成第一个token,后面都是一次一个的方式自回归生成,迭代粒度的方法不用等后面输出的99个token,而是直接把第二个请求在生成第一个请求第二个新token时就一起batching。这样的batch的粒度变成了token级别的,因此不会排队太久,从而也共容易组成比较大的batch。
LLM serving的内存挑战
虽然细粒度的batching技术可以解决batching的效率问题,但是由于KV cache的动态特性,LLM的serving还是会受到内存的限制,从而导致不能使用太大的batch。换句话说,LLM serving是内存受限的任务。
KV cache非常大
比如13B的OPT模型,一个token的KV cache就需要800KB。具体计算为:2(key和value) × 5120(hidden size) × 40(层数) × 2(fp 16)。如果输入加输出总长2048,那么一个请求的KV cache就需要1.6GB。
复杂的解码算法
不同的应用场景和解码算法会有不同的共享效率。比如在代码生成应用中,为了结果的多样性,通常使用并行随机采样。在作者的实验中prompt占据12%的KV cache空间,而后面的生成部分很难共享。而像beam search这样的算法,由于得分较高的路径往往有很多相同的路径,所以会有很多KV Cache可以共享(最多可以节约55%)。
不同的输入和输出长度
由于输入和输出都是不定长的,因此需要内存管理算法能够处理这些情况。而且当内存不足的时候,系统需要像操作系统那样灵活的把一些暂时不用的页面换到磁盘上。LLM的serving系统也需要把暂时不用的KV Cache从GPU显存换到CPU内存。而在合适的时间又把它们从CPU内存换到GPU显存。
现存系统的问题
由于深度学习框架要求tensor连续存储,现存系统把一个请求的所有cache都连续存储,因此无法共享。而且由于长度未知,很多系统都简单的申请最大的长度,这就会导致内部碎片。同样是因为长度未知,即使使用动态的方式申请内存(比如类似python list的自动扩容),也会导致大量外部碎片。比如下图所示的例子:

注意:相同的token在不同的序列中是不能共享的,因为隐状态(除了第一层的输入)是依赖整个序列的。
Method
为了解决上述问题,本文提出了一种新的attention算法——PagedAttention,并且构建了vLLM系统。vLLM的架构如下图所示:
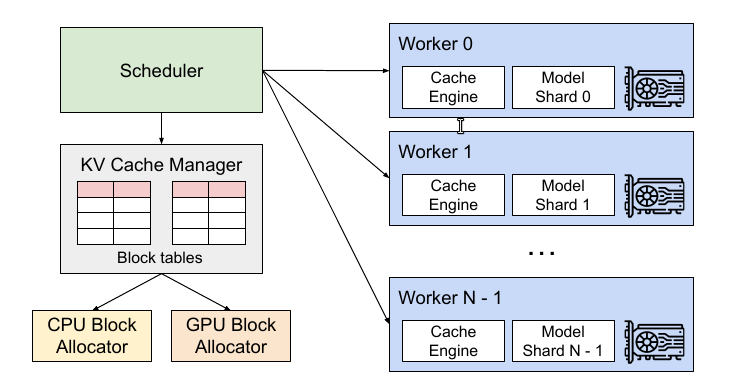
vLLM采用了中心化的调度器来协调分布式的GPU的执行。KV Cache manager以分页的方式管理KV Cache。具体来说,KV cache manager通过中心化的调度器下发指令来管理位于GPU上的worker,从而管理GPU上的物理内存。
PagedAttention
PagedAttention算法把每个序列(每个请求的prompt+response)的KV cache切分成一系列KV block。每个block包含固定大小的token的KV Cache。假设block的大小是B。定义第j个块中的B个key向量为$K_j=(k_{(j-1)B+1},…,k_{jB})$,B个value向量为$V_j=(v_{(j-1)B+1},…,v_{jB})$。那么我们可以一次计算token i对整个第j块的B个token的attention:
\[A_{ij}=\frac{exp(q_i^TK_j/\sqrt{d})}{\sum_{t=1}^{\left\lceil i/B \right\rceil}exp(q_i^TK_t/\sqrt{d})\textbf{1}} \\ o_i=\sum_{j=1}^{\left\lceil i/B \right\rceil} V_jA^T_{ij}\]其中$A_{ij}=(a_{i,(j-1)B+1},…,a_{i,jB}$是第i个token对第j个块中B个token的attention得分的向量。我们还是举一个简单的例子,假设B=2,i=7(这里假设下标从1开始),j=3。那么$A_{7,3}$是序列中第7个token对第3个Block(也就是第5-6个token)的attention。我们把具体的值代入公式:
\[A_{7,3}=\frac{exp(q_7^TK_3/\sqrt{d})}{\sum_{t=1}^4 exp(q_7^TK_t/\sqrt{d})\textbf{1}}\]我们先看分子,这比较简单。因为向量的维度是d,所以$q_i \in R^{d \times 1}$,$K_3=(k_5,k_6) \in R^{d \times 2}$,因此$q_i^TK_3 \in R^{1 \times 2}$。没错,这正是一个query(i=3)对2个key(5,6)的内积。分母呢?看起来比较复杂,如果不用PagedAttention,那么根据自回归生成的方式,第7个token只能注意到第1~7个token,那么分母就是:
\[\sum_{j=1}^7exp(q_7^Tk_j/\sqrt{d})\]而我们对比一些PagedAttention的分母:
\[\sum_{t=1}^4exp(q_7^TK_t/\sqrt{d})\textbf{1}\]首先我们需要注意$\textbf{1} \in R^{B \times 1}=[1, …, 1]^T$。所以上式展开就是:
\[exp(q_7^T[k_1, k_2]/\sqrt{d})\times [1,1]^T + exp(q_7^T[k_3, k_4]/\sqrt{d})\times[1,1]^T \\ +exp(q_7^T[k_5, k_6]/\sqrt{d})\times[1,1]^T +exp(q_7^T[k_7, k_8]/\sqrt{d})\times[1,1]^T\]exp是逐个元素进行的:
\[=[exp(q_7^Tk_1/\sqrt{d}),exp(q_7^Tk_2/\sqrt{d})] \times [1,1]^T + [exp(q_7^Tk_3/\sqrt{d}),exp(q_7^Tk_4/\sqrt{d})] \times [1,1]^T + ...\\ =exp(q_7^Tk_1/\sqrt{d}) + exp(q_7^Tk_2/\sqrt{d}) + exp(q_7^Tk_3/\sqrt{d}) + exp(q_7^Tk_4/\sqrt{d}) + ... \\ =\sum_{j=1}^8exp(q_7^Tk_j/\sqrt{d})\]是不是和上面的一样呢?细心的读者可能会说:不对!前面是$\sum_1^7$,后面是$\sum_1^8$。没错。不过我们想一下,在计算第7个token的时候,第8个token的key和value还没有呢(后面我们会看到),没有计算的可以认为是0,因此它们是没有区别的。
KV cache manager
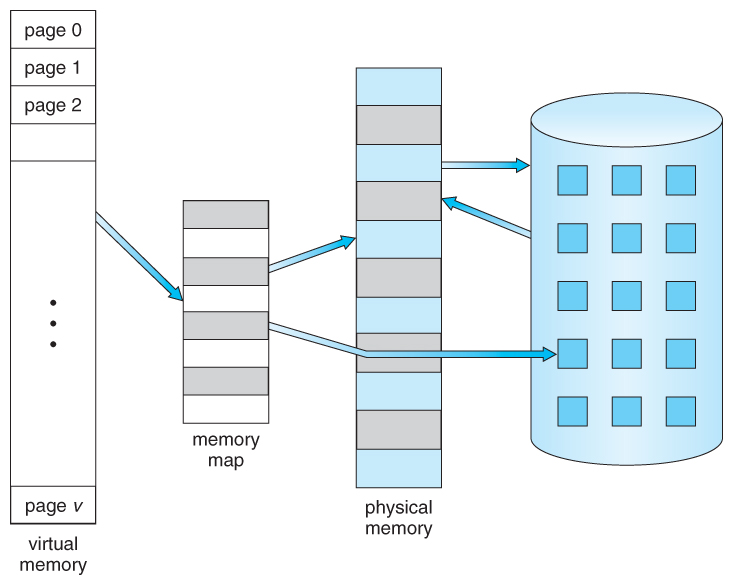
vLLM的内存管理借鉴了操作系统虚拟内存的idea。操作系统把内存划分成固定大小的分页(page),一个进程的虚拟内存就是一系列分页。在用户(进程)看来,它的地址空间是连续的,但实际不然。操作系统会把每个分页和物理的分页建立映射。比如一个页面32k,进程的虚拟内存是320k(实际当然远大于此,比如4GB),也就是10个分页。目前进程在使用前3个页面,那么操作系统就会把这3个页面真正的加载到物理内存里,剩下那7个页面可能缓存在磁盘里。当进程访问第4个页面时,会发生缺页中断,然后去缓存里找到这个页面放到内存,并且建立虚拟内存和物理内存的映射。如果物理内存不够用了,操作系统也会把暂时不用的分页换到磁盘缓存里。这个过程如下图所示,不熟悉的读者可以找本操作系统的书看看。
vLLM把一个请求的KV cache表示为一系列逻辑的KV block。比如block的大小是4,则把前4个token放在第一个逻辑block,5~8个token放在第二个逻辑block里。只有最后一个block可能没有填满,这些没有填满位置用于存放后面生成的token的KV cache。在GPU的worker里,block引擎会在GPU的DRAM(HBM而不是SRAM,不清楚的读者可以参考FlashAttention)里申请和管理一块连续的空间,并且把这些空间切分成物理的KV block来实际存放一个逻辑block(为了能缓存,也会在CPU内存里申请一块内存)。KV block manager也会维护block table——它记录逻辑KV block和物理KV block的映射。
PagedAttention和vLLM的解码
下面我们结合一个例子来看一下vLLM具体是怎么利用PagedAttention和Cache Manager来解码的。
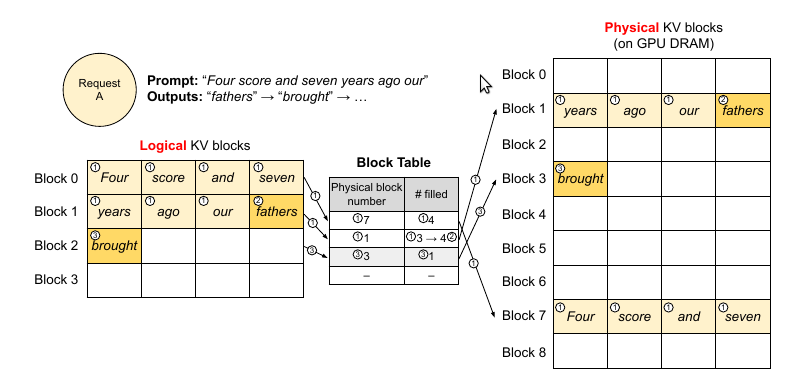
第一步
图中用①表示。和操作系统的虚拟内存一样,vLLM不需要为请求预留(最大的)内存,它只保留当前生成的所以KV cache。在上图的例子里,prompt有7个token,因此vLLM把前两个逻辑KV block(0和1)映射到两个物理block(7和1)。在生成的第一个阶段,vMM一次输入7个token,得到7个token的KV cache。这一步使用的是普通的Attention算法(不需要PagedAttention)。前4个token的cache放到第一个逻辑block,接下来3个token放到第二个逻辑block,第二个逻辑block还空了一个位置,这可以用于下一个生成的输出token。
第二步
接着是自回归解码,生成新的token “fathers”,这个时候第二个逻辑block填充的数量从3变成4(满了)。
第三步
接着第二次自回归解码,生成”brought”,因为第二个逻辑块满了所以在block table新建一项,并且用物理block 3来真正存储它,这是filled=1。
上面的例子演示的是一个请求的解码过程。实际的情况是每一步vLLM都会从后续队列里选择一些请求来batching(怎么选择效率最高后面会讨论),并且为新的逻辑block分配物理block。然后把多个请求的prompt和最近生成的tokens拼成一个大的sequence给到vLLM的kernel(GPU的kernel)。这个实现了PagedAttention算法的kernel会访问这些逻辑block的cache并且为每一个请求都生成一个新的token,并且把这一步的KV cache也保存到物理block里。如果block大小越大,那么这个kernel读取的次数就会越小,但是内部碎片也会越大。
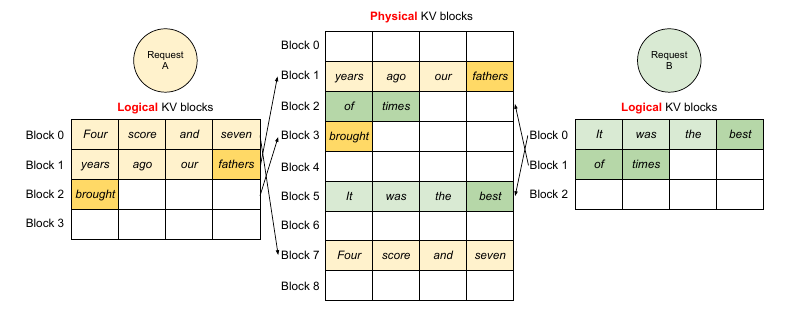
在上图的例子里,有两个请求。我们可以看到两个逻辑相邻的block物理上并不需要相邻。相反,两个请求最后一个物理块(3和2)是相邻的,这反而可以让kernel的效率更高。
其它解码场景
并行采样(Parallel sampling)
在代码生成等常见,为了结果的多样性,对于同一个prompt,我们可能会在每一步都随机采样多个(而不是一个)token。
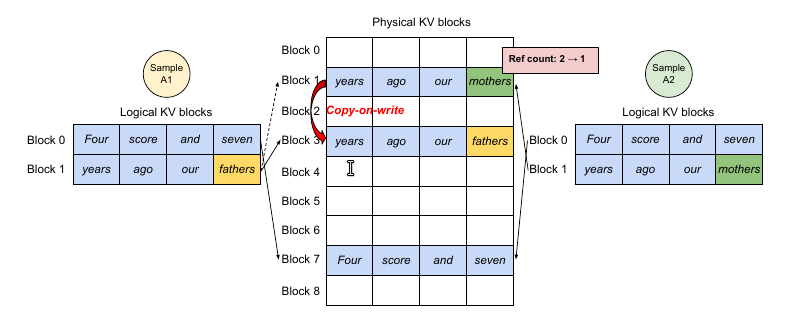
上图是一个例子,由于两个结果的prompt是相同的,因此KV cache可以共享。为了实现共享,我们在block table里的每个block里增加一个引用计数,比如这里的第7个物理block和第1个物理block都映射到两个逻辑block。现在假设第1个sample先执行,那么它需要在物理block1写入token “father”,因为这个物理block被多于1个人用到,所以vLLM把block1复制一份到物理block3,然后修改sample1的映射为block3,然后再把”father”的cache写入,同时减少block1的引用计数。接着第2个sample执行,这个时候block1的引用计数为1,也就是它独享,所以可以放心写入。这就是所谓的CopyOnWrite机制——也就是多个使用者共享一个资源,大家可以共享读,但是如果某人要写,那么它就需要Copy一份,然后在它自己的那份上修改。
如果Prompt很长,则这种共享会非常有价值。
beam search
beam search是在每一个时刻都保留k个(有时候k会变,比如topp,但是不影响原理)最优路径。比如下图:
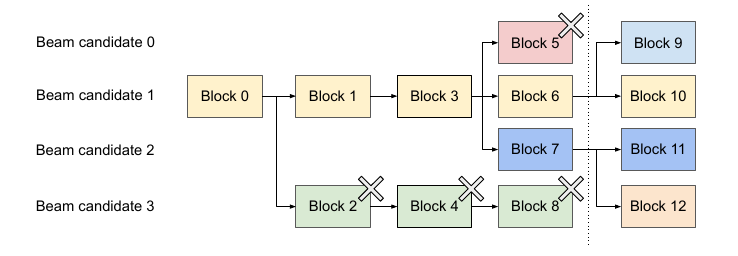
这里beam size是2,也就是每次保留最好的两条路径。一开始的prompt是相同的,假设是block 0,接着它展开为block 1和block 2,接着展开为3和4,这几步只有2个候选路径,没啥好说。接着block 3展开为block 567,block 4展开为block8,最优的是block 6和7。这就是图中虚线之前的情况。这个时候我们要保留路径6和7的KV cache,我们发现它们的路径有很大一部分是重合的(block 013)。
前面也说过,beam search的top路径会有很多相似的子路径,因此PagedAttention能够充分利用这一点来提高共享比例。
共享前缀
在很多应用中,比如In-context learning,我们会增加很长的few-shot examples。比如:
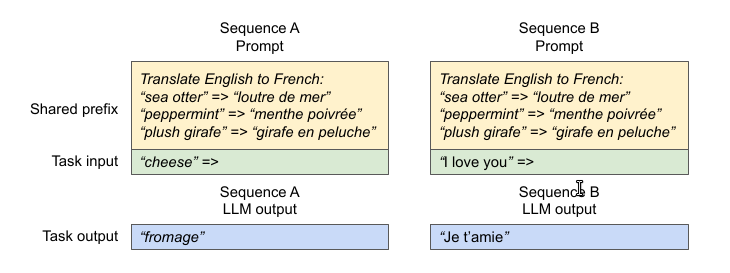
上面是一个机器翻译的例子,在input之前有很长的前缀。另外包括chatbot,我们也会设置system角色的prompt。这些都是可以共享的。
调度和抢占(Preemption)
当前请求量超过系统的处理能力时,VLLM需要决定优先处理部分请求。vLLM使用的是先来先服务策略(FCFS)。由于输入的prompt是不定长的,而且输出长度也是未知的,因此存在物理block被用光的情况。这首,vLLM需要解决两个问题:(1) 哪些block被弹出(evict)?(2) 当需要时这些被弹出的block怎么重新恢复?通常的弹出策略会根据启发规则来预测哪些block会在最久的将来才被用到并弹出这些block。不过在LLM的情况下,我们知道一个序列(请求)的所有block是同时(不)被访问的,因此本文实现了all-or-nothing的弹出策略,也就是说,要么保留以序列的所有block,要么弹出它的所有block,因此弹出的最小单位是属于同一个序列的所有block。此外同一个请求的多个序列(比如beam search的多条路径)被作为一个序列组(sequence group)被一起调度。为了解决第二个问题,通常有两种策略:
交换(swapping)
这是操作系统虚拟内存管理的方法,把不用的分页从物理内存交互到磁盘缓存,需要的时候在从磁盘读入。因为换出的内存是不可能超过实际物理内存的,因此不管虚拟地址空间多大,用于交互的磁盘缓存都不会超过物理内存的大小。而vLLM也类似,只不过是从GPU的显存(DRAM)交换到CPU的内存。
重计算
除了缓存,另外的策略就是重新计算。这是用计算时间换取存储空间的办法。这种大模型里很常见。那么这两种哪个比较好呢,这取决于block的大小,后面实验会讨论。
分布式执行
很多LLM的尺寸会超过单个GPU的显存。因此即使在serving(而不是训练)的时候也有必要进行分布式推理。vLLM采用的是类似Megatron-LM的tensor并行。这里先不介绍,后面介绍分布式训练时再讨论,我们只需要知道模型的同一层的参数会被切分到不同的GPU上就可以了。
作者发现即使使用了模型并行,同一个模型分片(shard)也会处理输入token的很多相同部分,因此vLLM采用了全局的KV cache manager,这样可以实现更多共享。vLLM的不同GPU worker共享这个manager,以及逻辑block到物理block的映射表。只不过每个GPU worker保存这个KV cache的一部分,比如共有8个attention head,有4个GPU,那么每个GPU保存两个attention head的KV cache。
在每一步自回归生成时,调度器首先把需要用到的token id的映射关系都读取出来,然后把这些通过广播发送给GPU worker。
比如现在需要处理第一个sequence,之前缓存了9个token,通过映射表发现就是上图的713这三个物理block。接着GPU worker就读取这3个block,因为每个GPU都保存了2个attention head的KV cache,因此它们也只需要计算这两个attention head,最后通过all-reduce操作进行结果同步,然后接着往上一层传递。这样的话,除了两层之间GPU worker需要同步,它们是不需要再和调度器发生通信的。
实现
因为我还没有时间读vLLM的代码,暂不介绍。
实验
总之都是vLLM很牛逼的结果,我就不贴图了,感兴趣的读者自行阅读论文吧。
- 显示Disqus评论(需要科学上网)