本文整理了Huggingface transformers文本生成相关的资料。
目录
- 文本生成策略
- 参考资料
文本生成策略
文本生成对于许多自然语言处理(NLP)任务至关重要,例如开放式文本生成、摘要、翻译等。它还在许多混合模态应用中发挥作用,这些应用以文本作为输出,如语音转文字和视觉转文字。一些能够生成文本的模型包括GPT2、XLNet、OpenAI GPT、CTRL、TransformerXL、XLM、Bart、T5、GIT、Whisper。
请注意,generate方法的输入取决于模型的模态性。这些输入由模型的预处理器类(如AutoTokenizer或AutoProcessor)返回。如果模型的预处理器创建了多种类型的输入,请将所有输入传递给generate()。您可以在相应模型的文档中了解有关各个模型预处理器的更多信息。
选择生成文本的输出token的过程称为解码,您可以自定义generate()方法将使用的解码策略。修改解码策略不会更改任何可训练参数的值。然而,它可能会显著影响生成输出的质量,有助于减少文本中的重复并使其更连贯。
默认文本生成策略
模型的解码策略是在其生成配置中定义的。在使用预训练模型用pipeline进行生成时,模型调用PreTrainedModel.generate()方法,在幕后应用默认的生成配置。当没有使用自定义配置保存模型时,也会使用默认配置。
当您显式加载一个模型时,您可以通过model.generation_config检查生成配置:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
model.generation_config
输出:
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256,
}
打印model.generation_config只显示与默认生成配置不同的值,而不列出任何默认值。
默认生成配置新生成的最大token为20,以避免遇到资源限制【这对大部分应用来说显然不够】。默认解码策略是贪婪搜索,这是一种最简单的解码策略,选择具有最高概率的token作为下一个token。对于许多任务和小的输出尺寸,这种方法效果良好。然而,当用于生成较长的输出时,贪婪搜索可能开始产生高度重复的结果。
定制文本生成
您可以通过直接将参数及其值传递给generate方法来覆盖任何generation_config:
my_model.generate(**inputs, num_beams=4, do_sample=True)
即使默认的解码策略对您的任务大多数情况下有效,您仍然可以微调一些参数。一些常常调整的参数包括:
max_new_tokens:生成的最大token数。换句话说,输出序列的大小,不包括提示中的token。作为使用输出长度作为停止标准的替代方法,您可以选择在完整生成超过一定时间量时停止生成。要了解更多信息,请查看StoppingCriteria。
num_beams:通过指定高于1的beam数,您实际上是从贪婪搜索切换到beam搜索。此策略在每个时间步评估多个假设,最终选择具有整个序列最高概率的假设。这有利于识别以较低概率初始token开头的高概率序列,而这些序列在贪婪搜索中可能会被忽略。
do_sample:如果设置为True,此参数启用解码策略,如多项式采样、beam搜索多项式采样、Top-K采样和Top-p采样。所有这些策略都从整个词汇表的概率分布中选择下一个token,具有各种特定于策略的调整。
num_return_sequences:每个输入返回的序列候选数。此选项仅适用于支持多个序列候选的解码策略,例如beam搜索和采样的变体。像贪婪搜索和对比搜索这样的解码策略返回单个输出序列。
保存自定义解码策略与您的模型
如果你训练了自己的模型,并且想把默认的生成配置保存下来,那么可以执行以下步骤:
- 创建一个GenerationConfig类实例。
- 指定解码策略参数。
- 使用GenerationConfig.save_pretrained()保存您的生成配置,确保将其config_file_name参数留空。
- 将push_to_hub设置为True,以将您的配置上传到模型的仓库。
from transformers import AutoModelForCausalLM, GenerationConfig
model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
generation_config = GenerationConfig(
max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
)
generation_config.save_pretrained("my_account/my_model", push_to_hub=True)
您还可以将多个生成配置存储在单个目录中,利用GenerationConfig.save_pretrained()中的config_file_name参数。然后,您可以使用GenerationConfig.from_pretrained()实例化它们。如果您希望为单个模型存储多个生成配置(例如,一个用于采样的创造性文本生成,另一个用于带有beam搜索的摘要),这将非常有用。您必须具有适当的Hub权限才能将配置文件添加到模型。
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
translation_generation_config = GenerationConfig(
num_beams=4,
early_stopping=True,
decoder_start_token_id=0,
eos_token_id=model.config.eos_token_id,
pad_token=model.config.pad_token_id,
)
# Tip: add `push_to_hub=True` to push to the Hub
translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
# You could then use the named generation config file to parameterize generation
generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
outputs = model.generate(**inputs, generation_config=generation_config)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
Streaming
generate() 支持流式传输,通过其streamer输入。streamer输入与具有以下方法的类的任何实例兼容:put() 和 end()。在内部,put() 用于推送新的token,而end() 用于标记文本生成的结束。
流式传输类的 API 仍在开发中,未来可能会发生更改。
在实践中,您可以为各种目的创建自己的流式传输类!我们还为您准备了基本的流式传输类供您使用。例如,您可以使用TextStreamer类将generate()的输出流式传输到您的屏幕,逐词显示:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tok = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
streamer = TextStreamer(tok)
# Despite returning the usual output, the streamer will also print the generated text to stdout.
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
解码策略
generate()参数的某些组合,最终会修改generation_config,可以用于启用特定的解码策略。如果您对这个概念不太了解,我们建议阅读这篇博客文章【后面会介绍这篇博客】,详细说明了常见解码策略的工作原理。
在这里,我们将展示一些控制解码策略的参数,并说明您如何使用它们。
贪婪搜索(Greedy Search)
默认情况下,generate 使用贪婪搜索解码,因此您无需传递任何参数来启用它。这意味着num_beams被设置为1,而do_sample被设置为False。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "I look forward to"
checkpoint = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
对比搜索(Contrastive search)
对比搜索解码策略是在2022年的论文《A Contrastive Framework for Neural Text Generation》中提出的。该策略在生成非重复但连贯的长文本输出方面表现出卓越的结果。要了解对比搜索的工作原理,请查阅这篇博客文章。启用和控制对比搜索行为的两个主要参数是penalty_alpha和top_k:
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Hugging Face Company is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
多项式采样(Multinomial sampling)
与总是选择具有最高概率的token作为下一个token的贪婪搜索相反,多项式采样根据模型给出的整个词汇表上的概率分布随机选择下一个token。具有非零概率的每个token都有被选择的机会,从而降低了重复的风险。
要启用多项式采样,请设置do_sample=True和num_beams=1。
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(0) # For reproducibility
checkpoint = "gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Today was an amazing day because"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Beam搜索解码(Beam-search decoding)
与贪婪搜索不同,beam搜索解码在每个时间步保留多个假设,最终选择整个序列中具有最高概率的假设。这有利于识别以较低概率初始token开头的高概率序列,而这些序列在贪婪搜索中可能会被忽略。
要启用此解码策略,请指定大于1的num_beams。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "It is astonishing how one can"
checkpoint = "gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
Beam搜索多项式采样(Beam-search multinomial sampling)
正如其名称所示,这种解码策略将beam搜索与多项式采样相结合。您需要指定大于1的num_beams,并设置do_sample=True以使用此解码策略。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
set_seed(0) # For reproducibility
prompt = "translate English to German: The house is wonderful."
checkpoint = "t5-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, do_sample=True)
tokenizer.decode(outputs[0], skip_special_tokens=True)
多样性beam搜索(Diverse beam search decoding)
多样性beam搜索解码策略是beam搜索策略的扩展,允许生成一个更多样化的beam序列集合供选择。要了解其工作原理,请参阅《Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models》。该方法有三个主要参数:num_beams、num_beam_groups和diversity_penalty。多样性惩罚确保在组间输出是不同的,而在每个组内使用beam搜索。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
checkpoint = "google/pegasus-xsum"
prompt = (
"The Permaculture Design Principles are a set of universal design principles "
"that can be applied to any location, climate and culture, and they allow us to design "
"the most efficient and sustainable human habitation and food production systems. "
"Permaculture is a design system that encompasses a wide variety of disciplines, such "
"as ecology, landscape design, environmental science and energy conservation, and the "
"Permaculture design principles are drawn from these various disciplines. Each individual "
"design principle itself embodies a complete conceptual framework based on sound "
"scientific principles. When we bring all these separate principles together, we can "
"create a design system that both looks at whole systems, the parts that these systems "
"consist of, and how those parts interact with each other to create a complex, dynamic, "
"living system. Each design principle serves as a tool that allows us to integrate all "
"the separate parts of a design, referred to as elements, into a functional, synergistic, "
"whole system, where the elements harmoniously interact and work together in the most "
"efficient way possible."
)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
tokenizer.decode(outputs[0], skip_special_tokens=True)
本指南阐明了启用各种解码策略的主要参数。generate方法还存在更高级的参数,它们让您对generate方法的行为有更进一步的控制。有关所有可用参数的完整列表,请参阅API文档。
辅助解码(Assisted Decoding)
辅助解码是对上述解码策略的修改,它使用具有相同分词器的辅助模型模型(理想情况下是一个更小的模型)贪婪生成几个候选token。然后,主模型在单个前向传递中验证候选token,从而加速解码过程。目前,辅助解码仅支持贪婪搜索和采样,并且不支持批处理输入。要了解有关辅助解码的更多信息,请查阅此博客文章。
要启用辅助解码,请使用assistant_model参数设置一个模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
相关代码
上面的解码策略选择,可以通过transformers/generation/utils.py里的代码来验证:
def _get_generation_mode(
self, generation_config: GenerationConfig, assistant_model: Optional["PreTrainedModel"]
) -> GenerationMode:
"""
Returns the generation mode triggered by a [`GenerationConfig`] instance.
"""
if generation_config.constraints is not None or generation_config.force_words_ids is not None:
generation_mode = GenerationMode.CONSTRAINED_BEAM_SEARCH
elif generation_config.num_beams == 1:
if generation_config.do_sample is False:
if (
generation_config.top_k is not None
and generation_config.top_k > 1
and generation_config.penalty_alpha is not None
and generation_config.penalty_alpha > 0
):
generation_mode = GenerationMode.CONTRASTIVE_SEARCH
else:
generation_mode = GenerationMode.GREEDY_SEARCH
else:
generation_mode = GenerationMode.SAMPLE
else:
if generation_config.num_beam_groups > 1:
generation_mode = GenerationMode.GROUP_BEAM_SEARCH
elif generation_config.do_sample is True:
generation_mode = GenerationMode.BEAM_SAMPLE
else:
generation_mode = GenerationMode.BEAM_SEARCH
# Assisted generation may extend some generation modes
if assistant_model is not None:
if generation_mode in ("greedy_search", "sample"):
generation_mode = GenerationMode.ASSISTED_GENERATION
else:
raise ValueError(
"You've set `assistant_model`, which triggers assisted generate. Currently, assisted generate "
"is only supported with Greedy Search and Sample."
)
return generation_mode
1. 约束的Beam搜索(Constrained Beam Search)
如果constraints或者force_words_ids非空,函数返回CONSTRAINED_BEAM_SEARCH。约束的Beam搜索可以强制解码的结果包含某些token或者更复杂的约束(如短语约束),详细介绍可以参考Guiding Text Generation with Constrained Beam Search in 🤗 Transformers。
2. 贪婪搜索
num_beams==1并且do_sample==False时执行这个算法。贪婪算法在每个时刻都选择概率(logit)最大的那个token,这是最简单的算法。
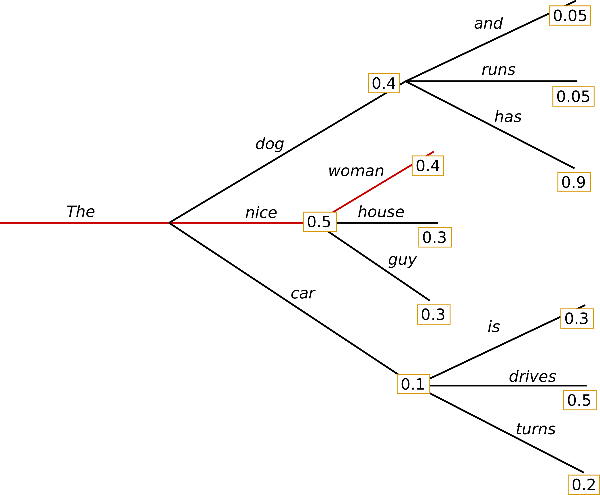
比如上图,prompt是”The”,然后第一个时刻概率最大的是”nice”、”dog”和”car”,贪婪算法选择概率最大的nice。后面也是类似的。所以贪婪算法是一种确定性的算法。
3. 对比搜索
penalty_alpha>0并且top_k>1时执行这个算法。这个算法详细介绍请参考Generating Human-level Text with Contrastive Search in Transformers,这里简单介绍一下它的思想。这个算法的解码算法如下式子所示:
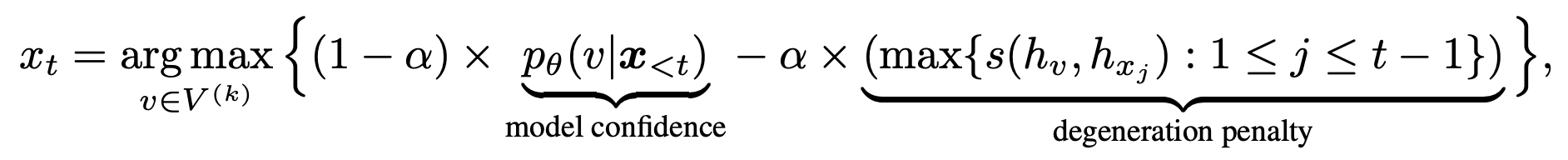
其中,$V^{(k)}$ 是语言模型概率分布$p_\theta(v | x_{<t})$的概率排在top-k的k个token。第一项,即模型置信度,是语言模型对候选 v 的预测概率。第二项,退化惩罚,表示了候选 v 相对于先前上下文$x_{<t}$和函数$s(⋅,⋅)$计算的余弦相似度。具体而言,退化惩罚定义为候选 v 的token的隐向量$h_v$ 与先前上下文 $x_{<t}$中所有token的隐向量之间的最大余弦相似度。直观地说,候选 v 的较大退化惩罚意味着它在表示空间中更类似于上下文,因此更有可能导致模型退化问题。超参数$\alpha$调节这两个组成部分的重要性。当$\alpha=0$时,对比搜索变为基本的贪婪搜索。
4. 多项式采样
num_beams==1并且do_sample==True时执行。每次根据softmax(logits)的多项式概率进行采样。为了防止概率特别低的词被采样,可以使用top_p或者top_k进行过滤。
top_k比较简单,只保留概率最大的k个token,然后重新用softmax计算其概率。但是这有一个问题,因为top_k是固定的,有的时候,某些token其实概率很低,但是因一定要凑够k个,也会被留下来。与之相反,有的时候,由于概率分布很均匀,排在top_k+1的token也可能概率还不小,但是不能留下来。为了解决这个问题,top_p这个参数派上用场,比如top_p=0.92,那么只有某个token的概率是最大概率token的92%以上都会被保留下来。这两个参数可以同时使用,那么就是一种逻辑与的关系,也就是一个条件不满足就会被扔掉。
除了这两个参数,还有一个temperature参数,这个参数越小,那么采样越倾向于概率大的token。极端情况如果temperature趋近于零(这里不能为零,但是像vLLM可以设置为零),它就等价于贪心算法。
5. Beam搜索
num_beams>1并且do_sample=False。贪心算法的问题是有的时候前面某个词的概率挺高,但是后面就没有好的token了。就像人生,开局好不见得全局好。贪心算法会把一些全局较优但是一开始不好的路径淘汰掉,为了避免这个问题,Beam搜索会在每个时刻同时保留最优的num_beams条路径。当然你说一上来的排名倒数第一,后面逆袭成为第一,这种事情也不是没有,但是概率太小了,而且从计算的角度来说保留所有路径基本是不可能的。Beam搜索的一个示例如下图:
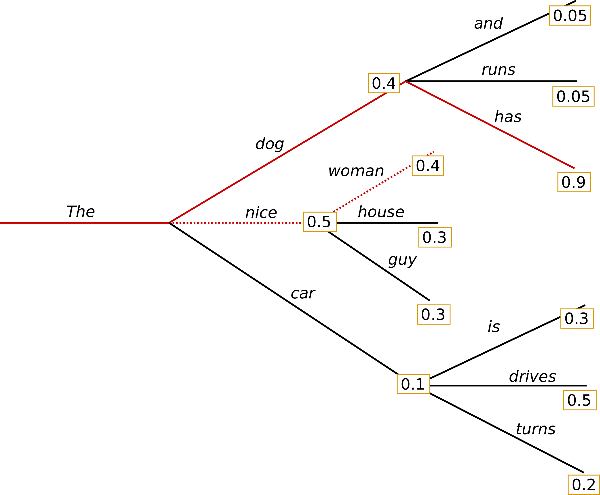
这个示例beam为2,第一次选择时排在第2的”dog”也被保留下来。最后全局最优的是得分0.9的路径成为最终结果。我们可以看到,Beam搜索也是确定性的算法,它相比贪心算法更可能找到全局最优,但是由于每次保留和展开多条路径,因此其速度比贪心算法慢。num_beams越大,速度越慢,找到全局最优的可能性越大。
6. 多样性Beam搜索(Group Beam Search)
`条件为num_beams>1并且num_beam_groups>1。多样性Beam搜索任务普通的Beam搜索虽然会保留多条路径,但是这些路径的相似度都很高(比如”the book is mine”把mine改成his。为了解决这个问题,多样性beam搜索把num_beams分成num_beam_groups个组,每个组num_beams/num_beam_groups条路径,每个组使用普通的beam搜索解码。但是从第二个组开始,除了用LLM计算生成token的概率,还会增加一个所谓的不相似项:
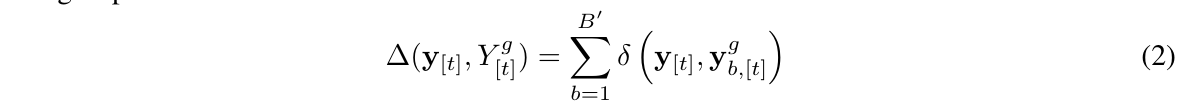
这个公式用自然语言描述就是:它定义了一个序列$y_{[t]}$和第g组的所有序列$Y_{[t]}^g$的不相似度。我们希望这个越大越好,这样就能有多样性。
因此第g组的beam搜索目标变成:
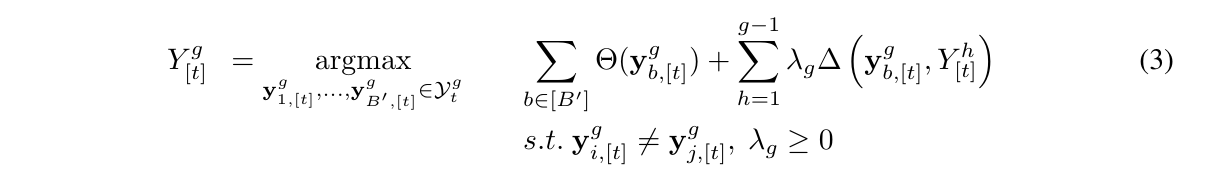
看起来这个公式很复杂,仔细分析其实它表达的就是:除了LLM的生成概率(第一项),还需要考虑第二项那个sum求和,它计算当前解码序列$y^g_{b,[t]}$和之前的1~g-1个组的不相似度。
我们看一个例子:
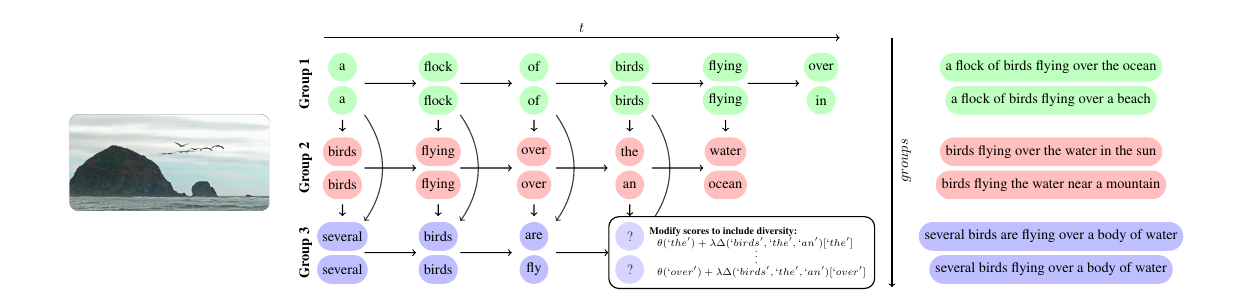
比如在第4个时刻,解码gruop3的时候,”several birds are”会避免之前group出现过的”birds, the , an”这些词。大概原理就是这样,更多细节请参考论文。使用的方法,除了参数num_beams和num_beam_groups,细心的读者可能会问怎么控制超参数$\lambda_g$呢?这个参数越大,那么组之间的差异越大。另外不相似度是怎么定义的呢?Huggingface实现的是HammingDiversityLogitsProcessor,具体原理不介绍了。感兴趣的读者自己看论文和阅读代码吧。用法就是通过参数diversity_penalty控制:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
# Initialize the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
# A long text about the solar system
text = (
"The Solar System is a gravitationally bound system comprising the Sun and the objects that orbit it, "
"either directly or indirectly. Of the objects that orbit the Sun directly, the largest are the eight "
"planets, with the remainder being smaller objects, such as the five dwarf planets and small Solar System "
"bodies. The Solar System formed 4.6 billion years ago from the gravitational collapse of a giant "
"interstellar molecular cloud."
)
inputs = tokenizer("summarize: " + text, return_tensors="pt")
# Generate diverse summary
outputs_diverse = model.generate(
**inputs,
num_beam_groups=2,
diversity_penalty=10.0,
max_length=100,
num_beams=4,
num_return_sequences=2,
)
summaries_diverse = tokenizer.batch_decode(outputs_diverse, skip_special_tokens=True)
# Generate non-diverse summary
outputs_non_diverse = model.generate(
**inputs,
max_length=100,
num_beams=4,
num_return_sequences=2,
)
summary_non_diverse = tokenizer.batch_decode(outputs_non_diverse, skip_special_tokens=True)
# With `diversity_penalty`, the resulting beams are much more diverse
print(summary_non_diverse)
print(summaries_diverse)
参数diversity_penalty最终会传给transformers.HammingDiversityLogitsProcessor。
7. 多项式采样Beam搜索
需要满足的条件是num_beams>1和do_sample=True。这是ChatGPT和GPT-4使用的搜索方法。有人认为ChatGPT使用了多项式采样的Beam搜索,比如reddit: chatGPT uses beam search。我认为不太可能,原因有二。一是在论文中InstructGPT里提到过用的是top_p采样,reddit回帖中有人有提到过。第二个原因是beam搜索是无法实现流式(streaming)输出的,因为它每次保留多个结果,之前较优的结果可能到最后就不是最优了。很多实时语音识别系统也会有流式解码,但是我们仔细观察会发现最终结果的前缀可能并不是之前的部分结果。但是ChatGPT第一个字输出后是永远不会改变的。当然理论上也可能用beam搜索解码N个字,然后一次输出,然后基于它(前N个字不变)再进行beam搜索。不过我认为这种可能性不大。
beam搜索最简单就是top_k,当然也可以用top_p。另外就是temperature参数,如果temperature趋近于0,则beam搜索接近于贪心算法。
8. 辅助搜索
这个搜索和前面不一样,它不能单独运行,而是作为另外一个模型的辅助。详细原理参考Assisted Generation: a new direction toward low-latency text generation。这里只做简单的介绍。
8.1 语言模型解码回顾
在文本生成过程中,典型的迭代包括模型接收最新生成的token作为输入,再加上所有其他先前输入的缓存内部计算,然后返回下一个token的logits。缓存用于避免冗余计算,从而加速前向传递,但这并非强制性(可以部分使用)【关于KV cache读者可以参考PagedAttention论文解读】。当禁用缓存时,输入包含到目前为止生成的所有token序列,输出包含与序列中所有位置对应的下一个token的logits!在位置N处的logits对应于如果输入包含前N个token,则下一个token的分布,忽略序列中的所有后续token。在贪婪解码的特定情况下,如果将生成的序列作为输入传递,并对生成的logits应用argmax运算符,您将获得生成的序列。
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("distilgpt2")
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
inputs = tok(["The"], return_tensors="pt")
generated = model.generate(**inputs, do_sample=False, max_new_tokens=10)
forward_confirmation = model(generated).logits.argmax(-1)
# We exclude the opposing tips from each sequence: the forward pass returns
# the logits for the next token, so it is shifted by one position.
print(generated[0, 1:].tolist() == forward_confirmation[0, :-1].tolist()) # True
这意味着您可以将模型的前向传递用于不同的目的:除了提供一些token以预测下一个token之外,还可以将一个序列传递给模型,然后双重检查模型是否会生成相同的序列(或其中的一部分)。
8.2 使用辅助搜索的贪心解码算法
您希望辅助模型能够快速生成候选序列,同时尽可能准确。如果辅助模型的质量较差,您将付出使用辅助模型模型的成本,却几乎没有任何好处。另一方面,优化候选序列的质量可能意味着使用较慢的辅助模型,导致净减速。虽然我们不能为您自动选择辅助模型模型,但我们已经包含了一个额外的要求和一个启发式方法,以确保与辅助模型一起花费的时间得到控制。
首先,要求辅助模型必须具有与您的模型完全相同的分词器。如果没有这个要求,就必须添加昂贵的token解码和重新编码步骤。此外,这些额外的步骤必须在CPU上执行,这反过来可能需要慢速的设备间数据传输。快速使用辅助模型对于实现辅助生成的好处至关重要。
最后,启发式方法。到这一点,您可能已经注意到辅助生成与电影《盗梦空间》之间的相似之处——毕竟,您正在文本生成中运行文本生成。每个候选token都会有一个辅助模型模型的前向传递,而我们知道前向传递是昂贵的。虽然您无法预先知道辅助模型模型将正确获取的token数量,但您可以跟踪此信息并使用它来限制请求给辅助模型的候选token的数量 - 输出的某些部分比其他部分更容易预测。
算法的具体步骤为:
- 使用贪婪解码生成助手模型的一定数量的候选token,产生候选项。第一次调用辅助生成时,生成的候选token数量初始化为5。
- 使用我们的模型对候选项进行前向传递,获取logits。
- 使用token选择方法(对于贪婪搜索使用.argmax(),对于采样使用.multinomial())从logits中获取next_tokens。
- 将next_tokens与候选token进行比较,并获取匹配token的数量。请记住,此比较必须按照从左到右的因果关系进行:在第一次不匹配后,所有候选项都无效。
- 使用匹配token的数量来切分数据,并丢弃与未确认的候选token相关的变量。实质上,在next_tokens中保留匹配token以及第一个不同的token(我们的模型从有效的候选子序列中生成)。
- 调整下一次迭代中要生成的候选token的数量。我们的原始启发式方法,如果所有token都匹配,则增加2,否则减少1。
我们可以看一下一个示例,如果播放有问题可以另存为下载观看,下载地址。
在上面的例子,比如prompt是”The quick brown”,我们首先让辅助模型用贪心算法生成5个token,假设它生成的是”fox jumps into the”。然后我们把它们拼起来变成”The quick brown fox jumps into the”给大的生成模型,它的预测是”fox jumps over a”。我们发现两个模型的预测相同的前缀是”fox jumps”,到第3个token就不相同了。我们当然更信任大模型的结果,因此预测是”The quick brown fox jumps over”。接着把这个序列再交给辅助模型。循环上面的过程直到生成结束。当然这个过程可能会调节候选token的数量,比如使用简单的启发:如果所有token都匹配,加2,否则减少1,这里的例子就是减1变成4,也就是说下一次把”The quick brown fox jumps over”给辅助模型,它只需要输出4个token。
我们分析一下,最好的情况是两个模型的预测完全一样,这个时候只需要大的模型进行一次forward就能生成5个token(而原来只能生成一个,当然小模型还得forward 5次,不过我们一般选择的小模型速度比大模型快一个数量级)。最坏的情况呢?两个模型从第一个token开始预测结果就不相同,那么大模型forward一次输出5个token,只有一个是有用的(因为第2到第5个token的输入不是自回归产生,而是小模型给的,因为第一个就不能用,所以后面的计算都作废了)。
参考资料
-
How to generate text: using different decoding methods for language generation with Transformers
-
Guiding Text Generation with Constrained Beam Search in 🤗 Transformers
-
Assisted Generation: a new direction toward low-latency text generation
- 显示Disqus评论(需要科学上网)