本文是论文wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations的解读。
目录
Abstract
我们首次展示了仅从语音音频中学习强大的表示,然后在转录的语音上进行微调,可以胜过最佳的半监督方法,同时在概念上更简单。wav2vec 2.0在潜在空间中掩盖(mask)了语音输入,并解决了一个在共同学习的潜在表示的量化上定义的对比任务。在使用Librispeech的所有标注数据的实验中,在clean/other的测试集上实现了1.8/3.3的词错误率(WER)。当将标注数据的数量降低到一小时时,wav2vec 2.0在使用100倍少的标注数据的情况下,胜过了之前的100小时子集的最新技术水平。仅使用十分钟的标注数据,并在53k小时的未标注数据上进行预训练,仍然实现了4.8/8.2的WER。这表明了在有限的标注数据情况下进行语音识别的可行性。
1 Introduction
神经网络受益于大量的标注训练数据。然而,在许多情况下,标注数据比未标注数据更难获取:当前的语音识别系统需要数千小时的转录语音才能达到可接受的性能,而这对于全球近7,000种语言中的绝大多数来说是不可用的。纯粹从标注示例中学习并不类似于人类的语言习得过程:婴儿通过倾听周围的成年人来学习语言 - 这个过程需要学习良好的语音表示。在机器学习中,自监督学习已经成为一种从未标注示例中学习通用数据表示并在标注数据上微调模型的范式。这在自然语言处理方面取得了特别成功,并且是计算机视觉的一个活跃研究领域。
在本文中,我们提出了一个从原始音频数据中进行自监督学习表示的框架。我们的方法通过多层卷积神经网络对语音音频进行编码,然后对结果的潜在语音表示进行部分掩盖,类似于掩盖语言建模。潜在表示被输入到Transformer网络中以构建上下文化表示,并通过对比任务进行训练,其中要区分真实的潜在表示和干扰物。
作为训练的一部分,我们通过Gumbel softmax来学习离散语音单元来表示对比任务中的潜在表示(图1),我们发现这比非量化目标更有效。在未标注语音上进行预训练后,模型通过连接主义时间分类损失对标注数据进行微调,以用于下游语音识别任务。
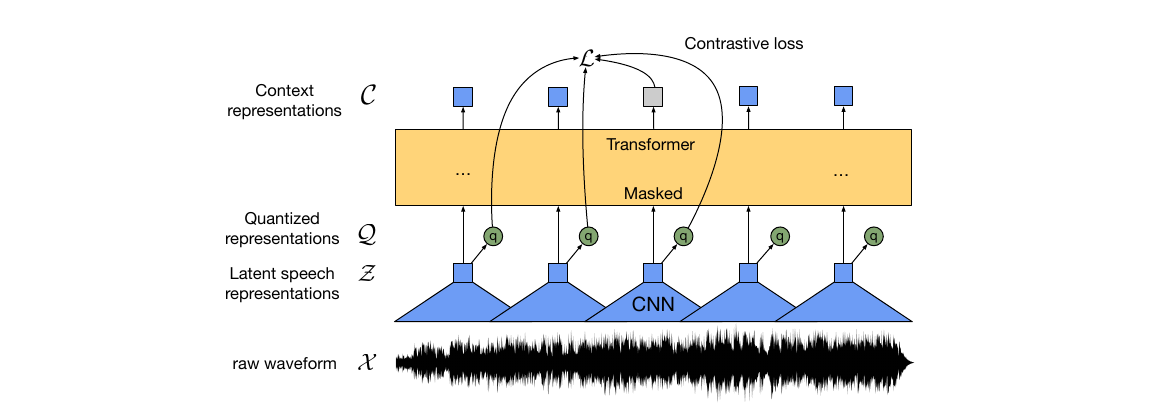 图1:我们的框架示意图,同时学习上下文化的语音表示和固定数量的离散化语音单元。
图1:我们的框架示意图,同时学习上下文化的语音表示和固定数量的离散化语音单元。
【译注:这个图大概可以说明wav2vec2的思想。
我们可以与NLP对比,文本的word/token数量是有限的,而语音的wave或者频谱是连续无穷的,这就无法像BERT或者GPT那样进行mask的预测。为了可以做到mask的训练,就需要把连续的特征变成有限的token。那怎么办呢?我们可以假设某种语言有$G_1 \times G_2$中语音单元,比如英语有$G_1$个元音,$G_2$个辅音,那么组合起来最多就是$G_1 \times G_2$个。这个比喻可能不是那么恰当,但是读者应该可以大致理解它的意思。
通过CNN把一帧变成一个隐向量之后,我们希望把这个隐向量对应的一个语音单元上。最简单的方法可能就是聚类,但问题是聚类不是可微分的计算,无法融合到整个Pretraining里,当然可以使用两步的方法。但是本文希望采用一种端到端的解决方案。
因此本文使用了一个量化模块(Quantization module)先用Gumbel-Softmax把连续特征变成one-hot表示(这就离散化了),然后再用一个Embedding来表示每一个离散化的语音单元,这样就类似于把相似的语音特征聚类到一个中心点特征。后文会详细介绍量化模块,这是本文主要的贡献。
接下来就比较简单了,对于隐向量,我们对其中50%进行mask,然后让Transformer来预测(输出一个向量表示)。但是和BERT有一点差别就是,我们不仅期望模型预测的向量和量化后的向量比较接近,同时还借鉴了对比学习的思想,从同一个句子随机采样一些不是这个位置(这一帧)的其它量化后向量,如果它们比较接近,就要惩罚。这样就可以迫使模型把不同的语音单元的Embedding搞的不一样,否则模型就会简单的让每一个语音单元的Embedding都一样来作弊。
】
先前的工作学习了数据的量化,然后使用自注意模型进行上下文化表示,而我们的方法端到端地解决了这两个问题。使用Transformer网络对语音的输入进行部分掩盖已经被探索过,但先前的工作要么依赖于一个两步流程,要么他们的模型是通过重建滤波器组输入特征进行训练的。其他相关工作包括通过自动编码输入数据来学习表示,或直接预测未来的时间步长。
我们的结果表明,与在先前步骤中学习的固定单元相比,共同学习离散语音单元和上下文化表示可以取得更好的结果。我们还证明了超低资源语音识别的可行性:当仅使用10分钟的标注数据时,我们的方法在Librispeech的清晰/其他测试集上达到了4.8/8.2的词错误率。我们在TIMIT音素识别以及Librispeech的100小时清晰子集上建立了新的技术水平。此外,当我们将标注数据的数量降低到只有一小时时,我们仍然胜过了之前的技术水平自训练方法,同时使用了100倍少的标注数据和相同数量的未标注数据。当我们使用来自Librispeech的全部960小时的标注数据时,我们的模型在清晰/其他测试集上达到了1.8/3.3的词错误率。
2 Model
我们的模型由一个多层卷积特征编码器 $f:\mathcal{X} \mapsto \mathcal{Y}$ 组成,它以原始音频 X 作为输入,并输出了 T 个时间步的潜在语音表示 $z_1, . . . , z_T$。然后将它们馈送到一个 Transformer $g:\mathcal{Z} \mapsto \mathcal{C}$ 中,以构建表示 $c_1, … , c_T$,捕获了整个序列的信息。特征编码器的输出通过量化模块 $f:\mathcal{Z} \mapsto \mathcal{Q}$ 进行离散化,以表示自监督目标中的目标。与 vq-wav2vec 相比,我们的模型在连续语音表示上构建了上下文表示,并且自注意力在整个潜在表示序列中捕获了依赖关系。
特征编码器。编码器由几个块组成,包含了一个时间卷积,后跟层归一化(layer normalization)和 GELU 激活函数。输入到编码器的原始波形被归一化为零均值和单位方差。编码器的总步幅(stride)确定了输入到 Transformer 中的时间步数 T。
Transformer 的上下文化表示。特征编码器的输出被馈送到一个遵循 Transformer 架构的上下文网络。我们使用一个类似于的卷积层来代替固定的位置嵌入(positional embedding),该层作为相对位置嵌入。我们将卷积的输出和 GELU 后的输入相加,然后应用层归一化。
量化模块。对于自监督训练,我们通过乘积量化(product quantization)将特征编码器的输出 z 离散化为一组有限的语音表示。乘积量化在先前的工作中取得了良好的结果,该工作首先学习了离散单元,然后学习了上下文化表示。乘积量化相当于从多个 V 个码本(codebook)中选择量化表示并将它们串联起来。给定 G 个码本或组,其中每个码本有 V 个条目 $e \in \mathbb{R}^{V \times d/G}$,我们从每个码本中选择一个条目并将生成的向量 $e_1, . . . , e_G$ 进行串联,并应用线性变换将其转换为 $q \in R^f$。
Gumbel softmax 以全可微的方式选择离散码本条目。我们使用直通估计器(straight-through)和设置了 G 个硬(hard) Gumbel softmax 操作。特征编码器的输出 z 被映射到 $l \in \mathbb{R}^{G \times V}$ 个逻辑值,用于选择第 g 组的第 v 个码本条目的概率为:
\[p_{g,v} = \frac{\exp(l_{g,v} + n_v )/\tau}{\sum_{k=1}^V \exp(l_{g,k} + n_k )/\tau}\]其中 $\tau$ 是一个非负温度,$n = − \log(− \log(u))$,u 是来自 U(0, 1) 的均匀样本。在前向传递期间,通过 $i = argmax_j p_{g,j}$ 选择码字 i,在反向传递期间,使用 Gumbel softmax 输出的真梯度。
3 Training
为了预训练模型,我们在潜在特征编码器空间的一定比例的时间步骤上进行掩码处理(§3.1),类似于BERT中的掩码语言建模[9]。训练目标要求在一组干扰项中为每个掩码时间步骤识别出正确的量化潜在音频表示(§3.2),最终模型在标记数据上进行微调(§3.3)。
3.1 掩码处理
我们对特征编码器的输出或时间步骤的一部分进行掩码处理,然后将它们输入到上下文网络中,并用在所有掩码时间步骤之间共享的训练特征向量替换它们;我们不对量化模块的输入进行掩码处理。为了对编码器输出的潜在语音表示进行掩码处理,我们随机地从所有时间步骤中抽取一定比例p的起始索引,然后对每个抽样索引掩码处理后续的M个连续时间步骤;这些跨度可能会重叠。
3.2 目标
在预训练期间,我们通过解决一个对比任务Lm来学习语音音频的表示,该任务要求在一组干扰项中为掩码时间步骤识别出真实的量化潜在语音表示。这通过一个代码本的多样性损失Ld来增强,以鼓励模型同样频繁地使用代码本条目。
\[\mathcal{L} = \mathcal{L}_m + \alpha \mathcal{L}_d\]其中$\alpha$是调优的超参数。
对比损失(Contrastive Loss)。给定以掩码时间步骤t为中心的上下文网络输出$c_t$,模型需要在包括$q_t$和K个干扰项在内的K + 1个量化候选表示$\tilde{q} \in Q_t$中识别出真实的量化潜在语音表示$q_t$[23, 54]。干扰项是从同一话语的其他掩码时间步骤中均匀抽样得到的。损失定义如下:
\[\mathcal{L}_m = -\log \frac{\exp(sim(c_t , q_t )/κ)}{\sum_{\tilde{q} \sim Q_t}\exp(sim(c_t , \tilde{q} )/κ)}\]多样性损失(Diversity Loss)。对比任务依赖于码本来表示正负样本,多样性损失\(\mathcal{L}_d\)的设计旨在增加量化码本表示的使用[10]。我们通过最大化每个码本\(\bar{p}_{g}\)中一批话语的平均softmax分布l上的码本条目的熵来鼓励在每个G码本中均匀使用V条目;softmax分布不包含gumbel噪声或温度:
\[\mathcal{L}_d = \frac{1}{GV} \sum_{g=1}^G -H(\bar{p}_{g}) = \frac{1}{GV} \sum_{g=1}^G \sum_{v=1}^V \bar{p}_{gv} \log \bar{p}_{gv}\]【译注:多样性损失是期望模型能够在“聚类”时尽量均匀,而不是把所有的特征都聚集到少数语音单元上。】
3.3 微调
预训练模型通过在上下文网络顶部添加一个随机初始化的线性投影来微调,表示任务词汇的C类[4]。对于Librispeech,我们有29个字符目标标记加上一个词边界标记。模型通过最小化CTC损失[14]进行优化,并且我们应用了SpecAugment的修改版本[41],在训练过程中对时间步和通道进行屏蔽,这可以延迟过拟合并显著改善最终的错误率,特别是在有少量标记示例的Libri-light子集上。
补充材料
上面是论文的核心部分,但是论文讲得比较简洁,因为它假设读者对背景知识比较了解,从而只介绍本文的创新点。这对于这个领域很熟悉的研究者来说没有问题,但是对于不熟悉的读者可能会比较困难。这里参考了An Illustrated Tour of Wav2vec 2.0对论文进行详细展开。
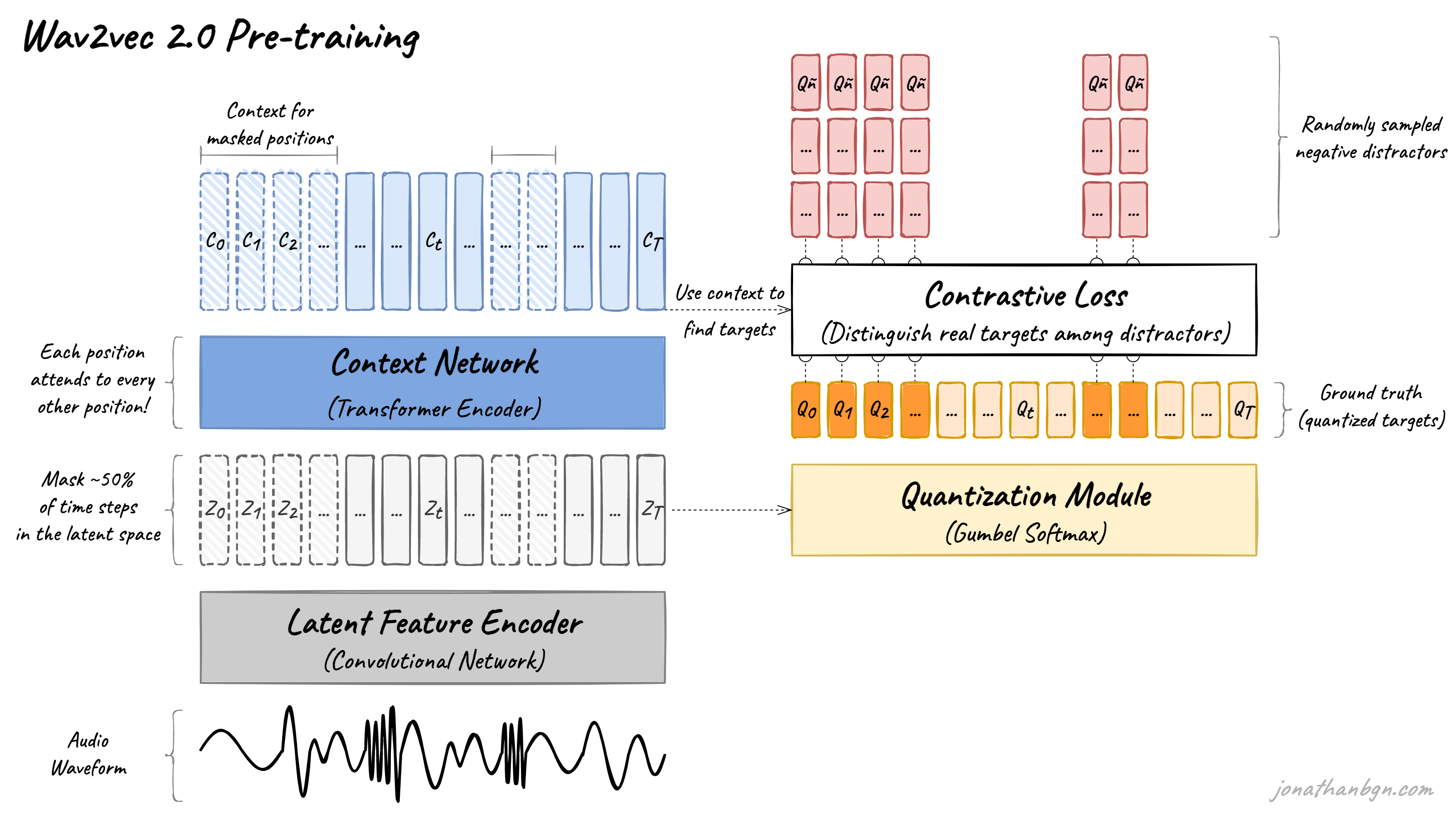
上面是wav2vec 2.0架构及其预训练过程的概述。此图中有四个重要元素:特征编码器、上下文网络、量化模块和对比损失(预训练目标)。我们将打开引擎盖,详细查看每个元素。
特征编码器(Feature encoder)
特征编码器的工作是降低音频数据的维度,将原始波形转换为一系列特征向量$Z_0、Z_1、Z_2、…、Z_T$,每个间隔20毫秒。它的架构很简单:一个具有512个通道的7层卷积神经网络(单维度)在每一层。
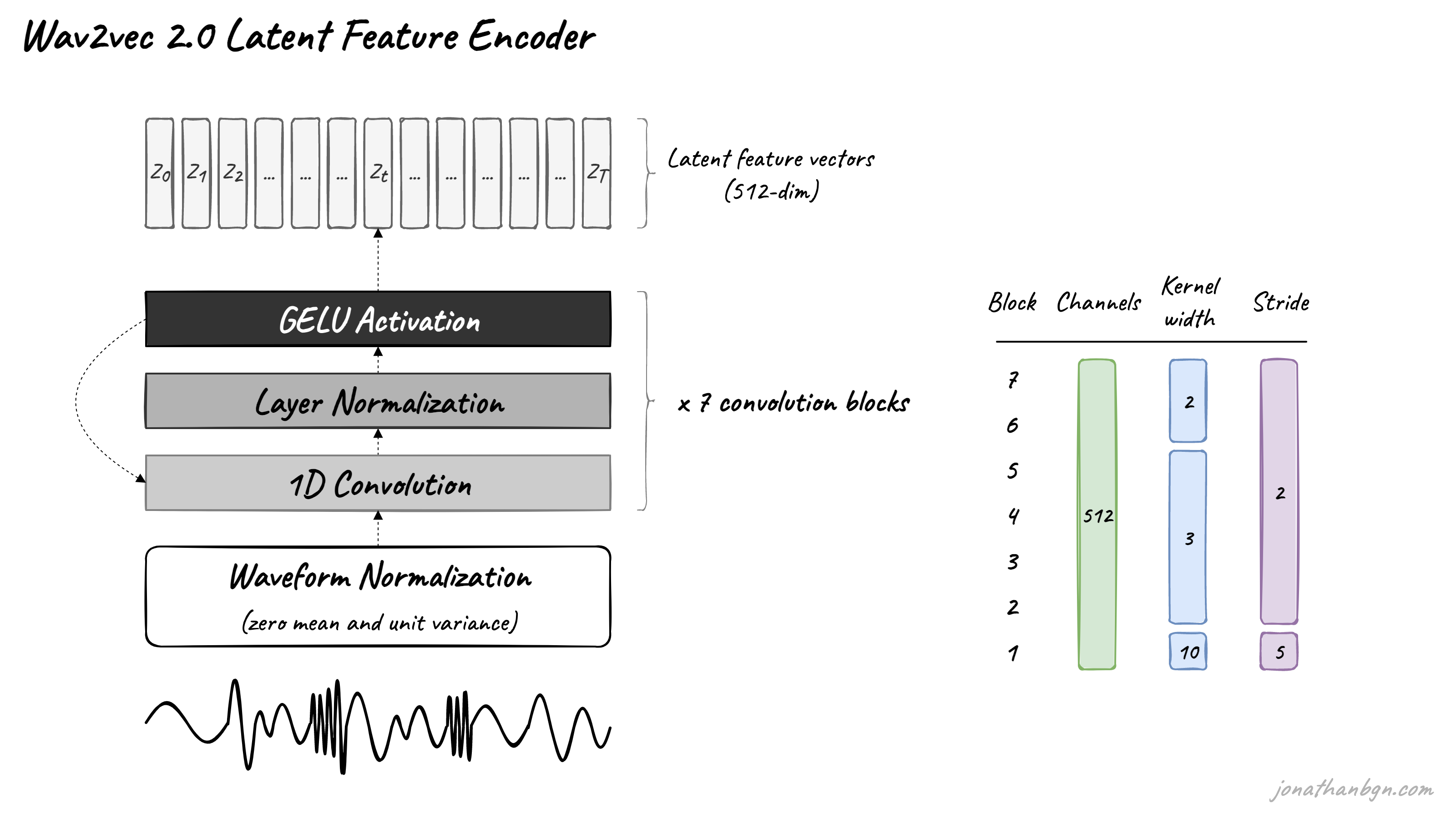
波形在发送到网络之前进行了归一化处理,卷积层的卷积核宽度和步幅随着网络的层数增加而减小。特征编码器的总感受野为400个样本或25毫秒的音频(音频数据以16 kHz的采样率编码)。
量化模块(Quantization module)
使用Transformer进行语音处理的主要障碍之一是语音的连续性。书面语言可以自然地离散化为单词或子词,因此创建了一个有限的离散单元词汇。语音没有这样的自然子单位。我们可以将音素用作离散系统,但是那样我们就需要人类首先在整个数据集上进行标记,因此我们无法在未标记的数据上进行预训练。
Wav2vec 2.0建议通过从Gumbel-Softmax分布中采样来自动学习离散语音单元。可能的单元由从码本(组)中采样的码字组成。然后将码字连接起来形成最终的语音单元。Wav2vec使用2组,每组有320个可能的单词,因此理论上最多可以有320 x 320 = 102,400个语音单元。
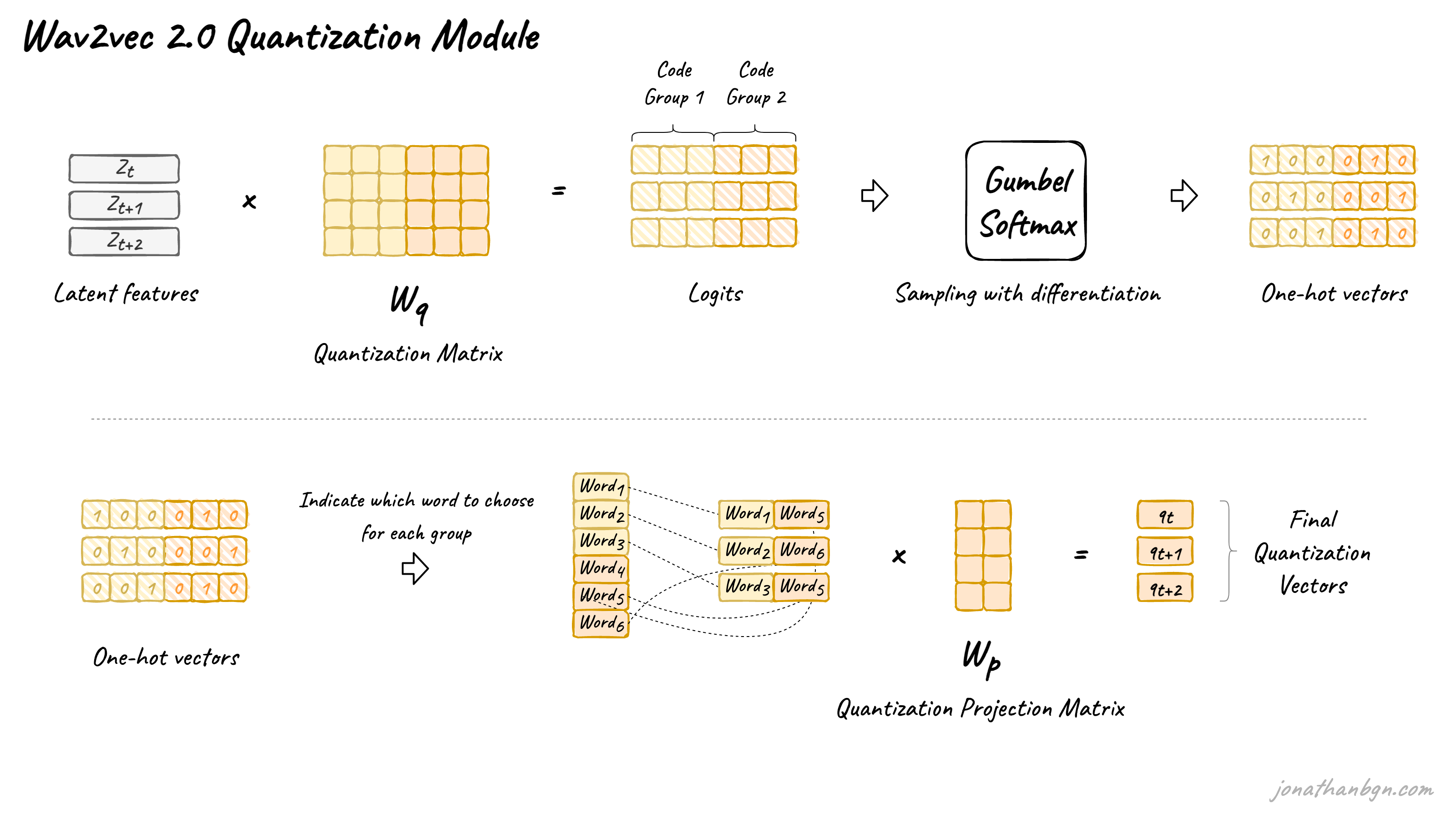
潜在特征被乘以量化矩阵以产生logits:每个码本中每个可能码字的一个分数。Gumbel-Softmax技巧允许从每个码本中抽样一个单一码字,将这些logits转换为概率。这类似于取argmax,只是该操作是完全可微的。此外,引入了一个由温度参数控制其效果的小随机效应,以在采样过程中促进训练和码字的利用。
关于Gumbel-Softmax,可以参考Gumbel-Softmax 完全解析。
上下文网络(Context network)
wav2vec 2.0的核心是其Transformer编码器,它将潜在特征向量作为输入,并通过12个Transformer块(BASE版本)或24个块(LARGE版本)进行处理。为了匹配Transformer编码器的内部维度,输入序列首先需要通过一个特征投影层,将维度从512(CNN的输出)增加到768(BASE)或1024(LARGE)。我在这里不会进一步描述Transformer架构,并邀请您阅读《Illustrated Transformer》以获取详细信息。
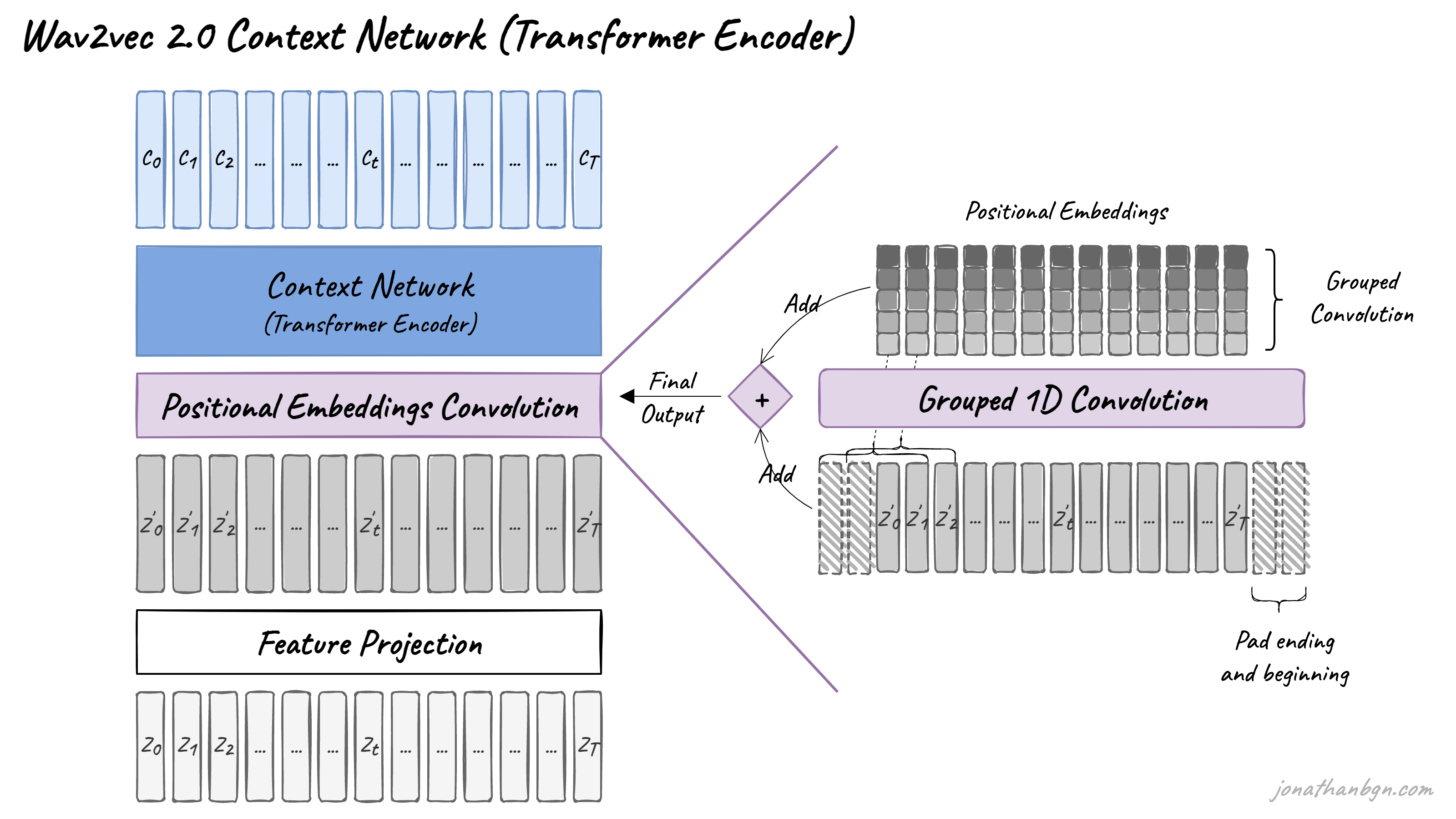
与原始Transformer架构的一个不同之处在于如何将位置信息添加到输入中。由于Transformer的自注意力操作不保留输入序列的顺序,因此在原始实现中,固定的预生成位置嵌入被添加到输入向量中。wav2vec模型使用一个新的分组卷积层来学习相对位置嵌入。
预训练与对比损失(Pre-training & contrastive loss)
预训练过程使用对比任务在未标记的语音数据上进行训练。首先在潜在空间中随机应用掩码,其中约50%的投影潜在特征向量被掩盖。然后,掩盖位置被替换为相同的训练向量Z’M,然后再馈送到Transformer网络中。
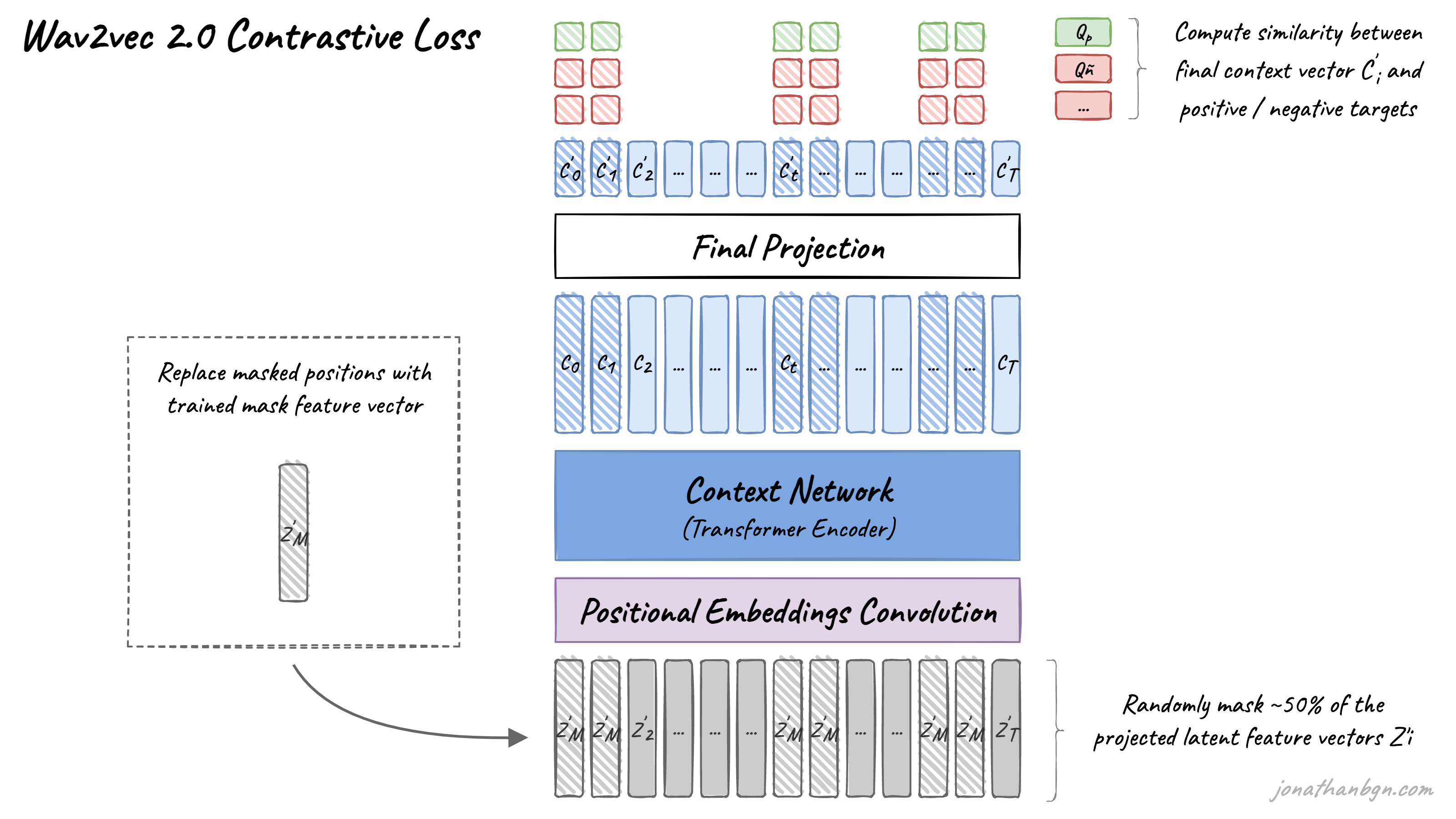
最终的上下文向量然后通过最后一个投影层,以匹配量化语音单元Qt的维度。对于每个掩码位置,从同一句子中的其他位置中均匀地随机采样100个负样本。然后,模型比较投影上下文向量C’t与真实正样本目标Qp以及所有负样本分散者Qñ之间的相似度(余弦相似度)。对比损失随后鼓励与真实正样本目标的高相似度,并惩罚与负样本分散者的高相似度分数。
多样性损失(Diversity loss)
在预训练期间,除了对比损失之外,还添加了另一个损失,以鼓励模型同等频繁地使用所有码字。这通过最大化Gumbel-Softmax分布的熵来实现,防止模型总是从所有可用码本条目的一个小子组中进行选择。您可以在原始论文中找到更多细节。
4 实验设置
数据集
作为未标记的数据,我们考虑了不包含转录的Librispeech语料库[40],包含960小时的音频(LS-960)或来自LibriVox的音频数据(LV-60k)。对于后者,我们遵循[27]的预处理,结果得到53.2k小时的音频。我们在五个标记数据设置上进行微调:960小时的转录Librispeech,包括100小时的train-clean-100子集(100小时标记),以及最初从Librispeech提取的Libri-light有限资源训练子集,这些是train-10h(10小时标记)、train-1h(1小时标记)和train-10min(10分钟标记)。我们遵循Libri-light的评估协议进行这些拆分,并在标准Librispech的dev-other/clean和test-clean/other集上进行评估。我们将预训练模型用于TIMIT数据集[13]的音素识别。它包含五小时的音频录音,并带有详细的音素标签。我们使用标准的训练、开发和测试分割,并遵循将电话标签折叠到39个类别的标准协议。
预训练
模型使用fairseq [39]实现。对于掩码,我们采样p = 0.065的所有时间步作为起始索引,并掩盖随后的M = 10个时间步。这导致大约49%的所有时间步被掩盖,平均跨度长度为14.7,或299毫秒(有关掩盖的更多细节,请参见附录A)。特征编码器包含七个块,每个块中的时间卷积具有512个通道,步幅为(5,2,2,2,2,2,2),核宽度为(10,3,3,3,3,2,2)。这导致编码器输出频率为49赫兹,在每个样本之间大约有20毫秒的步幅,并且具有400个输入样本或25毫秒的音频的感受野。建模相对位置嵌入的卷积层具有内核大小128和16组。我们尝试了两种模型配置,它们使用相同的编码器架构,但在Transformer设置上有所不同:B ASE包含12个Transformer块,模型维度为768,内部维度(FFN)为3,072,具有8个注意力头。批次由每个示例裁剪250k音频样本或15.6秒组成。将裁剪的批次一起形成,以不超过每个GPU的1.4m样本,并且我们在总共64个V100 GPU上进行训练,持续1.6天[38];总批次大小为1.6h。L ARGE模型包含24个Transformer块,模型维度为1,024,内部维度为4,096,具有16个注意力头。我们裁剪320k音频样本或20秒,每个GPU限制为1.2m样本,并且在128个V100 GPU上训练,持续2.3天用于Librispeech和5.2天用于LibriVox;总批次大小为2.7h。我们在Transformer的输出、特征编码器的输出和量化模块的输入处使用0.1的dropout。对于B ASE,以0.05的速率丢弃层,对于L ARGE,以0.2的速率丢弃层[22, 12];LV-60k不使用层丢弃。我们使用Adam [29]进行优化,首先将学习率在更新的前8%进行预热,达到峰值5 × 10^−4(B ASE)和3 × 10^−4(L ARGE),然后线性衰减。L ARGE进行250k次更新,B ASE进行400k次更新,L ARGE在LV-60k上进行600k次更新。我们在多样性损失方程2中使用权重α = 0.1。对于量化模块,我们使用G = 2和V = 320,对于两个模型,结果为102.4k个码字的理论最大值。条目的大小为d/G = 128(对于B ASE)和d/G = 384(对于L ARGE)。Gumbel softmax温度τ在每次更新时以0.999995的因子从2退火到最小值0.5(对于B ASE)和0.1(对于L ARGE)。对比损失(方程3)中的温度设为κ = 0.1。对于较小的Librispeech数据集,我们通过将L2惩罚应用于特征编码器的最后一层的激活,并将编码器的梯度缩小10倍来对模型进行正则化。我们还使用了一个稍微不同的编码器架构,其中我们不使用层归一化,而是对原始波形的第一层编码器输出进行归一化。在对比损失中,我们使用K = 100个负样本。我们选择验证集上具有最低Lm的训练检查点。
微调
在预训练之后,我们对标记的数据进行微调,并在Transformer的顶部添加一个随机初始化的输出层来预测字符(Librispeech/Libri-light)或音素(TIMIT)。对于Libri-light,我们对所有子集使用两种不同的学习率(2e-5和3e-5)进行三个种子的训练,并选择在用官方的4-gram语言模型(LM)解码的dev-other子集上具有最低WER的配置(LM权重2,单词插入惩罚-1)。对于标记的960h子集上的B ASE,我们使用学习率1e-4。我们使用Adam进行优化,并使用三态速率表,在前10%的更新中预热学习率,接下来的40%保持不变,然后线性衰减。B ASE使用每个GPU的3.2m样本批处理,我们在8个GPU上进行微调,总批处理大小为1,600秒。L ARGE在每个GPU上批处理1.28m样本,并在24个GPU上微调,从而得到有效的批处理大小为1,920秒。在前10k次更新中,只训练输出分类器,之后也更新Transformer。特征编码器在微调过程中不进行训练。我们对特征编码器表示进行掩码,掩盖策略类似于SpecAugment [41],详细说明见附录B。
语言模型和解码
我们考虑两种类型的语言模型(LM):一个4-gram模型和一个在Librispeech LM语料库上训练的Transformer[3]。Transformer LM与[51]相同,包含20个块,模型维度为1,280,内部维度为6,144,具有16个注意力头。我们通过贝叶斯优化调整语言模型的权重(间隔[0, 5])和单词插入惩罚([-5, 5]):我们对4-gram LM运行128个试验,使用beam 500,对Transformer LM运行128个试验,使用beam 50,并根据dev-other上的性能选择最佳的权重组合。测试性能使用n-gram LM的beam 1,500和Transformer LM的beam 500进行测量。我们使用[44]的beam搜索解码器。
实验结果,省略,请读者阅读原文。
- 显示Disqus评论(需要科学上网)