This article introduces the method of compiling PyTorch source code and explains how to use VS Code to debug both PyTorch Python and C++ code simultaneously.
Contents
Compilation
The compilation process mainly refers to the [official documentation].(https://github.com/pytorch/pytorch?tab=readme-ov-file#from-source)。
Prerequisites
If you are installing from source, you will need:
- Python 3.8 or later (for Linux, Python 3.8.1+ is needed)
- A compiler that fully supports C++17, such as clang or gcc (gcc 9.4.0 or newer is required)
This article covers the compilation process on Linux (tested on Ubuntu 18.04 and Ubuntu 20.04). If you are using a different system, please refer to the official documentation.
I am using Python 3.9. If your system’s package manager cannot provide Python version 3.8.1 or later, you can refer to Installing Python 3.9 from source on Ubuntu 18.04 to compile and install it manually.
If your system’s gcc version is too low, please refer to Is there a PPA that always has the latest gcc version (including g++)? for information on updating GCC on Ubuntu to avoid using an outdated gcc for compilation.
As per the official documentation, I will use Miniconda to create a virtual environment. Refer to Installing Miniconda for installation instructions.
For compiling PyTorch, I am using CUDA 12.1. Please refer to the official documentation for downloading and installing CUDA 12.1. Additionally, for CUDNN 8.6, refer to the official documentation for download and installation instructions. We will also use the nvcc compiler included with CUDA 12.1 for compilation.
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
On Ubuntu 18.04, the installed CUDA Driver version is 535.104.12, while on Ubuntu 20.04, it is 545.29.06. For compatibility between CUDA Toolkit and Driver versions, please refer to NVIDIA CUDA Toolkit Release Notes. Since we will need magma-cuda, if using a different CUDA version (e.g., 12.2), it may require manual building, which can be cumbersome. Therefore, if possible, it is recommended to use CUDA 12.1 (a machine can have only one version of CUDA Driver installed, but multiple versions of CUDA Toolkit and CUDNN can be installed without conflicts).
If multiple versions of CUDA and CUDNN are installed and the default (/usr/local/cuda symlink) is not CUDA 12.1, you can set the CUDA_HOME environment variable:
export CUDA_HOME=/usr/local/cuda-12.1
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="$CUDA_HOME/lib64:$LD_LIBRARY_PATH"
Note: For compilation, only CUDA_HOME is required. However, to use the CUDA 12.1 version that comes with nvcc, I also set the PATH variable. Setting LD_LIBRARY_PATH may not be necessary, but there is generally no harm in setting it.
Download cuSPARSELt, I installed version 0.6.0. Choose the version that corresponds to your system and architecture, download it, and extract it to a location. I placed it in ~/libcusparse_lt-linux-x86_64-0.6.0.6-archive. This is a library for sparse matrix multiplication and is not required for building PyTorch, but it can be useful if needed.
Install Dependencies
conda create -n torchbuild python=3.9
conda activate torchbuild
conda install cmake ninja
git clone --recursive https://github.com/pytorch/pytorch.git
pip install -r requirements.txt
The following installation steps are for Linux environments. If you are using a different system, please refer to the official documentation.
conda install intel::mkl-static intel::mkl-include
conda install -c pytorch magma-cuda121
If your CUDA version is not 12.1, please check here to see if there is a corresponding version available. If not, you can refer to [Build PyTorch from Source with CUDA 12.2.1 with Ubuntu 22.04]https://medium.com/repro-repo/build-pytorch-from-source-with-cuda-12-2-1-with-ubuntu-22-04-b5b384b47ac) to compile magma-cuda on your own.
Additionally, if you need triton support, you can install it using “make triton”. However, I haven’t had time to study triton yet, so I haven’t tried it myself.
Build
export _GLIBCXX_USE_CXX11_ABI=1
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
DEBUG=1 MAX_JOBS=96 python setup.py develop
The first environment variable instructs gcc to use the new C++ ABI; the second environment variable tells CMAKE where to install libtorch and other components; the last one is the standard (deprecated) method of installing Python, where DEBUG=1 tells CMAKE to build a debug version, and MAX_JOBS specifies the number of compiler (default is ninja) tasks, which should be set based on the number of CPU cores on your machine. The default value is num_sockets * cores_per_socket * threads_per_core.
Since CMAKE output is extensive, we can redirect the output to a file using tee. Additionally, to compile cuSPARSELt, we need to set:
CUSPARSELT_ROOT_DIR=/home/ubuntu/libcusparse_lt-linux-x86_64-0.6.0.6-archive/lib CUSPARSELT_INCLUDE_PATH=/home/ubuntu/libcusparse_lt-linux-x86_64-0.6.0.6-archive/include DEBUG=1 MAX_JOBS=96 python setup.py develop 2>&1 |tee build.log
If your system doesn’t have MPI or the built MPI doesn’t support CUDA, you can disable it using “USE_MPI=0”.
Compilation can take a significant amount of time, depending on the machine configuration, it may take several minutes to several hours. If there are errors during the compilation process, carefully review the error messages in build.log. I will also briefly introduce setup.py and CMakeLists.txt later, readers can use the CMAKE output to diagnose issues.
test installation
(torchbuild) ubuntu@VM-4-3-ubuntu:~/miniconda3/envs/torchbuild/lib$ python
Python 3.9.18 (main, Sep 11 2023, 13:41:44)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/nas/lili/codes/pt/torchsrc/pytorch/torch/__init__.py", line 237, in <module>
from torch._C import * # noqa: F403
ImportError: /home/ubuntu/miniconda3/envs/torchbuild/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.30' not found (required by /nas/lili/codes/pt/torchsrc/pytorch/torch/lib/libtorch_python.so)
>>>
When I tried to import torch, I encountered the “GLIBCXX_3.4.30 not found” issue. According to GLIBCXX 3.4.30 not found in conda environment, we just need to add a symbolic link:
$ ln -sf /usr/lib/x86_64-linux-gnu/libstdc++.so.6 /home/ubuntu/miniconda3/envs/torchbuild/bin/../lib/libstdc++.so.6
docker build
If your environment is too old or you don’t have permission to update gcc and CUDA, you can consider using PyTorch’s DevContainer](https://github.com/pytorch/pytorch/blob/main/.devcontainer/README.md). Additionally, you can refer to PyTorch Official VSCode DevContainer and Build and Develop PyTorch for more information.
Pytorch source code structure
$ tree -d -L 1
.
├── android
├── aten
├── benchmarks
├── binaries
├── build
├── c10
├── caffe2
├── cmake
├── docs
├── functorch
├── ios
├── modules
├── mypy_plugins
├── scripts
├── test
├── third_party
├── tools
├── torch
├── torch.egg-info
└── torchgen
torch
This directory mainly includes Python code, and the “import torch” command loads many modules from the torch package.
csrc
All the C/C++ source code is in this directory, along with the Python bindings for C++ code. It also contains some wrappers for the PyTorch core library. The files torch/csrc/stub.c and Module.cpp that we will see during debugging are located in this directory.
_C
The C extension torch module contains pyi files that define the interfaces that Python can use.
other
We won’t list other directories one by one, as basically, we use these modules in these packages when using PyTorch. Some functionalities are entirely implemented in Python, while others are implemented in C++ through extension modules. We will see them when we discuss setup.py later on.
aten
a tensor library, designed primarily to serve tensors without support for autograd.
$ tree aten/src -L 2 -d
aten/src
├── ATen
│ ├── benchmarks
│ ├── core
│ ├── cpu
│ ├── cuda
│ ├── cudnn
│ ├── detail
│ ├── functorch
│ ├── hip
│ ├── metal
│ ├── miopen
│ ├── mkl
│ ├── mps
│ ├── native
│ ├── nnapi
│ ├── ops
│ ├── quantized
│ ├── templates
│ ├── test
│ ├── vulkan
│ └── xpu
└── THC
- src/Aten/core: The core foundational library of ATen. Currently, the code in this library is gradually being migrated to the c10 directory.
- src/Aten/native: PyTorch’s operator library, containing operators for CPU. Specialized CPU instruction optimized operators are located in subdirectories within this directory.
- src/Aten/native/cuda: Implementation of CUDA operators.
c10
caffe2 aten, the core library of PyTorch, supporting both server-side and mobile platforms.
tree c10/ -d -L 2
c10/
├── benchmark
├── core
│ └── impl
├── cuda
│ ├── impl
│ └── test
├── hip
├── macros
├── mobile
├── test
│ ├── core
│ └── util
├── util
└── xpu
├── impl
└── test
What’s the difference between aten and c10?
ATen: This is the tensor library in PyTorch. It’s a namespace where the tensor operations and functions of PyTorch are defined. It’s built on top of the C++ standard library and is designed to be a replacement for Torch’s TH library. The name “ATen” might be a play on words, since it’s a ten-sor library.
c10: This is the core library for PyTorch. It contains the basic building blocks that PyTorch uses, including things like TensorImpl, the tensor metadata structure, and the dispatcher, which is responsible for routing operator calls to the correct kernel implementation. The name “c10” is short for “caffe2”, the deep learning framework that PyTorch merged with.
As for the differences between ATen and c10, as mentioned above, ATen is the tensor library, where all tensor operations are defined, whereas c10 is the core library, responsible for routing operator calls to the correct kernel implementation.
tools
Many similar source codes in PyTorch are generated automatically through scripts using templates. This folder contains scripts for generating automatically generated code.
caffe2
caffe2 In the current version, it is not compiled by default, and most readers are unlikely to be interested. If you need to compile it, you can add the environment variable “BUILD_CAFFE2=1”.
cmake
cmake scripts.
functorch
functorch. It is a composable function transformation tool similar to JAX, used for PyTorch.
android
Android related codes.
ios
ios related codes.
modules
$ tree modules -L 1
modules
├── CMakeLists.txt
├── detectron
├── module_test
├── observers
└── rocksdb
Not quite familiar with its purpose; it’s likely that very few people will use it.
third_party
Third-party libraries that PyTorch depends on.
setup.py
About setup.py, readers can refer to Building and Distributing Packages with Setuptools. Here, we will introduce PyTorch’s setup.py.
This file is quite long, with over 1400 lines, but it is not overly complicated.
main function
# the list of runtime dependencies required by this built package
install_requires = [
"filelock",
"typing-extensions>=4.8.0",
"sympy",
"networkx",
"jinja2",
"fsspec",
'mkl>=2021.1.1,<=2021.4.0; platform_system == "Windows"',
]
# Parse the command line and check the arguments before we proceed with
# building deps and setup. We need to set values so `--help` works.
dist = Distribution()
dist.script_name = os.path.basename(sys.argv[0])
dist.script_args = sys.argv[1:]
try:
dist.parse_command_line()
except setuptools.distutils.errors.DistutilsArgError as e:
print(e)
sys.exit(1)
mirror_files_into_torchgen()
if RUN_BUILD_DEPS:
build_deps()
(
extensions,
cmdclass,
packages,
entry_points,
extra_install_requires,
) = configure_extension_build()
install_requires += extra_install_requires
extras_require = {
"optree": ["optree>=0.9.1"],
"opt-einsum": ["opt-einsum>=3.3"],
}
# Read in README.md for our long_description
with open(os.path.join(cwd, "README.md"), encoding="utf-8") as f:
long_description = f.read()
version_range_max = max(sys.version_info[1], 12) + 1
torch_package_data = [
"py.typed",
"bin/*",
"test/*",
"*.pyi",
"_C/*.pyi",
"cuda/*.pyi",
# ..........
]
if get_cmake_cache_vars()["BUILD_CAFFE2"]:
torch_package_data.extend(
[
"include/caffe2/**/*.h",
"include/caffe2/utils/*.h",
"include/caffe2/utils/**/*.h",
]
)
if get_cmake_cache_vars()["USE_TENSORPIPE"]:
torch_package_data.extend(
[
"include/tensorpipe/*.h",
"include/tensorpipe/channel/*.h",
"include/tensorpipe/channel/basic/*.h",
"include/tensorpipe/channel/cma/*.h",
"include/tensorpipe/channel/mpt/*.h",
"include/tensorpipe/channel/xth/*.h",
"include/tensorpipe/common/*.h",
"include/tensorpipe/core/*.h",
"include/tensorpipe/transport/*.h",
"include/tensorpipe/transport/ibv/*.h",
"include/tensorpipe/transport/shm/*.h",
"include/tensorpipe/transport/uv/*.h",
]
)
torchgen_package_data = [
# Recursive glob doesn't work in setup.py,
# https://github.com/pypa/setuptools/issues/1806
# To make this robust we should replace it with some code that
# returns a list of everything under packaged/
"packaged/ATen/*",
"packaged/ATen/native/*",
"packaged/ATen/templates/*",
"packaged/autograd/*",
"packaged/autograd/templates/*",
]
setup(
name=package_name,
version=version,
description=(
"Tensors and Dynamic neural networks in "
"Python with strong GPU acceleration"
),
long_description=long_description,
long_description_content_type="text/markdown",
ext_modules=extensions,
cmdclass=cmdclass,
packages=packages,
entry_points=entry_points,
install_requires=install_requires,
extras_require=extras_require,
package_data={
"torch": torch_package_data,
"torchgen": torchgen_package_data,
"caffe2": [
"python/serialized_test/data/operator_test/*.zip",
],
},
url="https://pytorch.org/",
download_url="https://github.com/pytorch/pytorch/tags",
author="PyTorch Team",
author_email="packages@pytorch.org",
python_requires=f">={python_min_version_str}",
# PyPI package information.
classifiers=[
"Development Status :: 5 - Production/Stable",
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: BSD License",
"Topic :: Scientific/Engineering",
"Topic :: Scientific/Engineering :: Mathematics",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
"Topic :: Software Development",
"Topic :: Software Development :: Libraries",
"Topic :: Software Development :: Libraries :: Python Modules",
"Programming Language :: C++",
"Programming Language :: Python :: 3",
]
+ [
f"Programming Language :: Python :: 3.{i}"
for i in range(python_min_version[1], version_range_max)
],
license="BSD-3",
keywords="pytorch, machine learning",
)
The code is quite long, but the logic is relatively simple. The main part of the code is:
if RUN_BUILD_DEPS:
build_deps()
(
extensions,
cmdclass,
packages,
entry_points,
extra_install_requires,
) = configure_extension_build()
....
setup(
name=package_name,
version=version,
description=(
"Tensors and Dynamic neural networks in "
"Python with strong GPU acceleration"
),
.....
build_deps
Building dependencies from the third_party directory using CMAKE. Although implemented in Python, the Python code is only for integration purposes, and the final calls are still made to CMAKE.
cmake -GNinja -DBUILD_PYTHON=True -DBUILD_TEST=True -DCMAKE_BUILD_TYPE=Debug -DCMAKE_INSTALL_PREFIX=/nas/lili/codes/pt/torchsrc/pytorch/torch -DCMAKE_PREFIX_PATH=/home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages -DNUMPY_INCLUDE_DIR=/home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages/numpy/core/include -DPYTHON_EXECUTABLE=/home/ubuntu/miniconda3/envs/torchbuild/bin/python -DPYTHON_INCLUDE_DIR=/home/ubuntu/miniconda3/envs/torchbuild/include/python3.9 -DPYTHON_LIBRARY=/home/ubuntu/miniconda3/envs/torchbuild/lib/libpython3.9.a -DTORCH_BUILD_VERSION=2.4.0a0+git8168338 -DUSE_NUMPY=True /nas/lili/codes/pt/torchsrc/pytorch
cmake --build . --target install --config Debug -- -j 96
configure_extension_build
The key part of this function is the following code:
C = Extension(
"torch._C",
libraries=main_libraries,
sources=main_sources,
language="c",
extra_compile_args=main_compile_args + extra_compile_args,
include_dirs=[],
library_dirs=library_dirs,
extra_link_args=extra_link_args
+ main_link_args
+ make_relative_rpath_args("lib"),
)
extensions.append(C)
cmdclass = {
"bdist_wheel": wheel_concatenate,
"build_ext": build_ext,
"clean": clean,
"install": install,
"sdist": sdist,
}
The array composed of Extensions is the ext_modules parameter in the setup function. The cmdclass extends setuptools with custom commands to implement a customized installation process. The most important part of this is build_ext, which we will discuss later.
setup
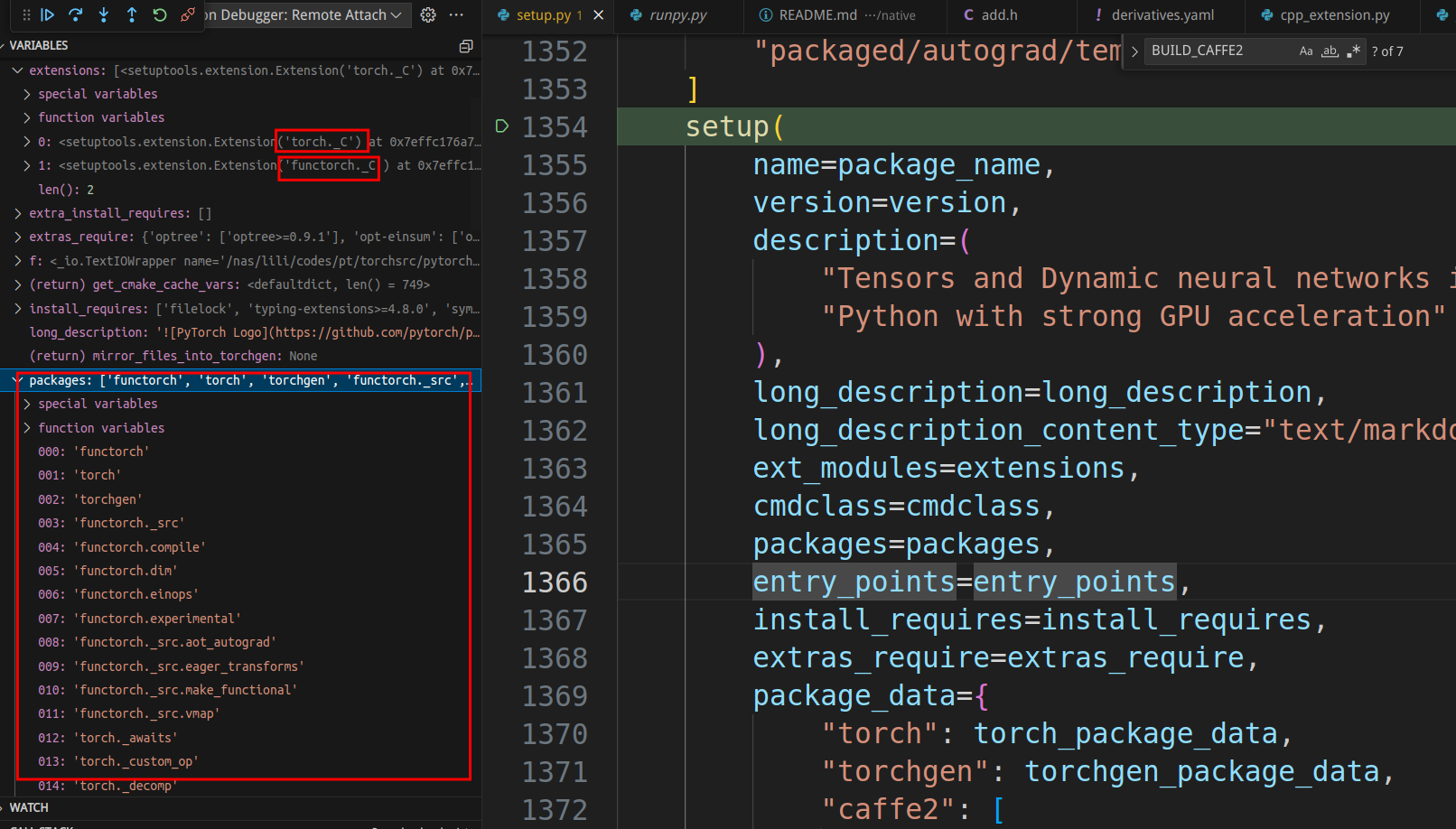
We can see that the main job of setup is to install modules from the torch package. The debug window on the left shows a small number of package names, but the current version has a total of 299 packages! As for ext_modules, it only includes “torch._C” and “functorch._C”, but we know that behind them are all third-party dependency codes as well as core C++ codes such as aten and c10.
build_ext
This class will invoke run to perform the extension build. The code is quite long, so we can refer to the log output below to understand it better.
class build_ext(setuptools.command.build_ext.build_ext):
def run(self):
# Report build options. This is run after the build completes so # `CMakeCache.txt` exists and we can get an
# accurate report on what is used and what is not.
cmake_cache_vars = defaultdict(lambda: False, cmake.get_cmake_cache_variables())
if cmake_cache_vars["USE_NUMPY"]:
report("-- Building with NumPy bindings")
else:
report("-- NumPy not found")
if cmake_cache_vars["USE_CUDNN"]:
report(
"-- Detected cuDNN at "
+ cmake_cache_vars["CUDNN_LIBRARY"]
+ ", "
+ cmake_cache_vars["CUDNN_INCLUDE_DIR"]
)
else:
report("-- Not using cuDNN")
if cmake_cache_vars["USE_CUDA"]:
report("-- Detected CUDA at " + cmake_cache_vars["CUDA_TOOLKIT_ROOT_DIR"])
else:
report("-- Not using CUDA")
if cmake_cache_vars["USE_XPU"]:
report("-- Detected XPU runtime at " + cmake_cache_vars["SYCL_LIBRARY_DIR"])
else:
report("-- Not using XPU")
if cmake_cache_vars["USE_MKLDNN"]:
report("-- Using MKLDNN")
if cmake_cache_vars["USE_MKLDNN_ACL"]:
report("-- Using Compute Library for the Arm architecture with MKLDNN")
else:
report(
"-- Not using Compute Library for the Arm architecture with MKLDNN"
)
if cmake_cache_vars["USE_MKLDNN_CBLAS"]:
report("-- Using CBLAS in MKLDNN")
else:
report("-- Not using CBLAS in MKLDNN")
else:
report("-- Not using MKLDNN")
if cmake_cache_vars["USE_NCCL"] and cmake_cache_vars["USE_SYSTEM_NCCL"]:
report(
"-- Using system provided NCCL library at {}, {}".format(
cmake_cache_vars["NCCL_LIBRARIES"],
cmake_cache_vars["NCCL_INCLUDE_DIRS"],
)
)
elif cmake_cache_vars["USE_NCCL"]:
report("-- Building NCCL library")
else:
report("-- Not using NCCL")
if cmake_cache_vars["USE_DISTRIBUTED"]:
if IS_WINDOWS:
report("-- Building without distributed package")
else:
report("-- Building with distributed package: ")
report(
" -- USE_TENSORPIPE={}".format(cmake_cache_vars["USE_TENSORPIPE"])
)
report(" -- USE_GLOO={}".format(cmake_cache_vars["USE_GLOO"]))
report(" -- USE_MPI={}".format(cmake_cache_vars["USE_OPENMPI"]))
else:
report("-- Building without distributed package")
if cmake_cache_vars["STATIC_DISPATCH_BACKEND"]:
report(
"-- Using static dispatch with backend {}".format(
cmake_cache_vars["STATIC_DISPATCH_BACKEND"]
)
)
if cmake_cache_vars["USE_LIGHTWEIGHT_DISPATCH"]:
report("-- Using lightweight dispatch")
if cmake_cache_vars["BUILD_EXECUTORCH"]:
report("-- Building Executorch")
if cmake_cache_vars["USE_ITT"]:
report("-- Using ITT")
else:
report("-- Not using ITT")
# Do not use clang to compile extensions if `-fstack-clash-protection` is defined
# in system CFLAGS
c_flags = str(os.getenv("CFLAGS", ""))
if (
IS_LINUX
and "-fstack-clash-protection" in c_flags
and "clang" in os.environ.get("CC", "")
):
os.environ["CC"] = str(os.environ["CC"])
# It's an old-style class in Python 2.7...
setuptools.command.build_ext.build_ext.run(self)
if IS_DARWIN and package_type != "conda":
self._embed_libomp()
# Copy the essential export library to compile C++ extensions.
if IS_WINDOWS:
build_temp = self.build_temp
ext_filename = self.get_ext_filename("_C")
lib_filename = ".".join(ext_filename.split(".")[:-1]) + ".lib"
export_lib = os.path.join(
build_temp, "torch", "csrc", lib_filename
).replace("\\", "/")
build_lib = self.build_lib
target_lib = os.path.join(build_lib, "torch", "lib", "_C.lib").replace(
"\\", "/"
)
# Create "torch/lib" directory if not exists.
# (It is not created yet in "develop" mode.)
target_dir = os.path.dirname(target_lib)
if not os.path.exists(target_dir):
os.makedirs(target_dir)
self.copy_file(export_lib, target_lib)
def build_extensions(self):
self.create_compile_commands()
# The caffe2 extensions are created in
# tmp_install/lib/pythonM.m/site-packages/caffe2/python/
# and need to be copied to build/lib.linux.... , which will be a
# platform dependent build folder created by the "build" command of
# setuptools. Only the contents of this folder are installed in the
# "install" command by default.
# We only make this copy for Caffe2's pybind extensions
caffe2_pybind_exts = [
"caffe2.python.caffe2_pybind11_state",
"caffe2.python.caffe2_pybind11_state_gpu",
"caffe2.python.caffe2_pybind11_state_hip",
]
i = 0
while i < len(self.extensions):
ext = self.extensions[i]
if ext.name not in caffe2_pybind_exts:
i += 1
continue
fullname = self.get_ext_fullname(ext.name)
filename = self.get_ext_filename(fullname)
report(f"\nCopying extension {ext.name}")
relative_site_packages = (
sysconfig.get_path("purelib")
.replace(sysconfig.get_path("data"), "")
.lstrip(os.path.sep)
)
src = os.path.join("torch", relative_site_packages, filename)
if not os.path.exists(src):
report(f"{src} does not exist")
del self.extensions[i]
else:
dst = os.path.join(os.path.realpath(self.build_lib), filename)
report(f"Copying {ext.name} from {src} to {dst}")
dst_dir = os.path.dirname(dst)
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
self.copy_file(src, dst)
i += 1
# Copy functorch extension
for i, ext in enumerate(self.extensions):
if ext.name != "functorch._C":
continue
fullname = self.get_ext_fullname(ext.name)
filename = self.get_ext_filename(fullname)
fileext = os.path.splitext(filename)[1]
src = os.path.join(os.path.dirname(filename), "functorch" + fileext)
dst = os.path.join(os.path.realpath(self.build_lib), filename)
if os.path.exists(src):
report(f"Copying {ext.name} from {src} to {dst}")
dst_dir = os.path.dirname(dst)
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
self.copy_file(src, dst)
setuptools.command.build_ext.build_ext.build_extensions(self)
The output of running the above code on my machine is:
running build_ext
-- Building with NumPy bindings
-- Detected cuDNN at ,
-- Detected CUDA at /usr/local/cuda-12.1
-- Not using XPU
-- Using MKLDNN
-- Not using Compute Library for the Arm architecture with MKLDNN
-- Not using CBLAS in MKLDNN
-- Building NCCL library
-- Building with distributed package:
-- USE_TENSORPIPE=True
-- USE_GLOO=True
-- USE_MPI=False
-- Building Executorch
-- Using ITT
Copying functorch._C from functorch/functorch.so to /nas/lili/codes/pt/torchsrc/pytorch/build/lib.linux-x86_64-cpython-39/functorch/_C.cpython-39-x86_64-linux-gnu.so
Creating /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages/torch.egg-link (link to .)
torch 2.4.0a0+git8168338 is already the active version in easy-install.pth
Installing convert-caffe2-to-onnx script to /home/ubuntu/miniconda3/envs/torchbuild/bin
Installing convert-onnx-to-caffe2 script to /home/ubuntu/miniconda3/envs/torchbuild/bin
Installing torchrun script to /home/ubuntu/miniconda3/envs/torchbuild/bin
Installed /nas/lili/codes/pt/torchsrc/pytorch
Processing dependencies for torch==2.4.0a0+git8168338
Searching for fsspec==2024.3.1
Best match: fsspec 2024.3.1
Adding fsspec 2024.3.1 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for Jinja2==3.1.3
Best match: Jinja2 3.1.3
Adding Jinja2 3.1.3 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for networkx==3.2.1
Best match: networkx 3.2.1
Adding networkx 3.2.1 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for sympy==1.12
Best match: sympy 1.12
Adding sympy 1.12 to easy-install.pth file
Installing isympy script to /home/ubuntu/miniconda3/envs/torchbuild/bin
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for typing-extensions==4.9.0
Best match: typing-extensions 4.9.0
Adding typing-extensions 4.9.0 to easy-install.pth file
Using /home/ubuntu/.local/lib/python3.9/site-packages
Searching for filelock==3.13.1
Best match: filelock 3.13.1
Adding filelock 3.13.1 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for MarkupSafe==2.1.5
Best match: MarkupSafe 2.1.5
Adding MarkupSafe 2.1.5 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Searching for mpmath==1.3.0
Best match: mpmath 1.3.0
Adding mpmath 1.3.0 to easy-install.pth file
Using /home/ubuntu/miniconda3/envs/torchbuild/lib/python3.9/site-packages
Finished processing dependencies for torch==2.4.0a0+git8168338
build_extensions
def build_extensions(self):
self.create_compile_commands()
create_compile_commands generates the commands that Ninja will execute:
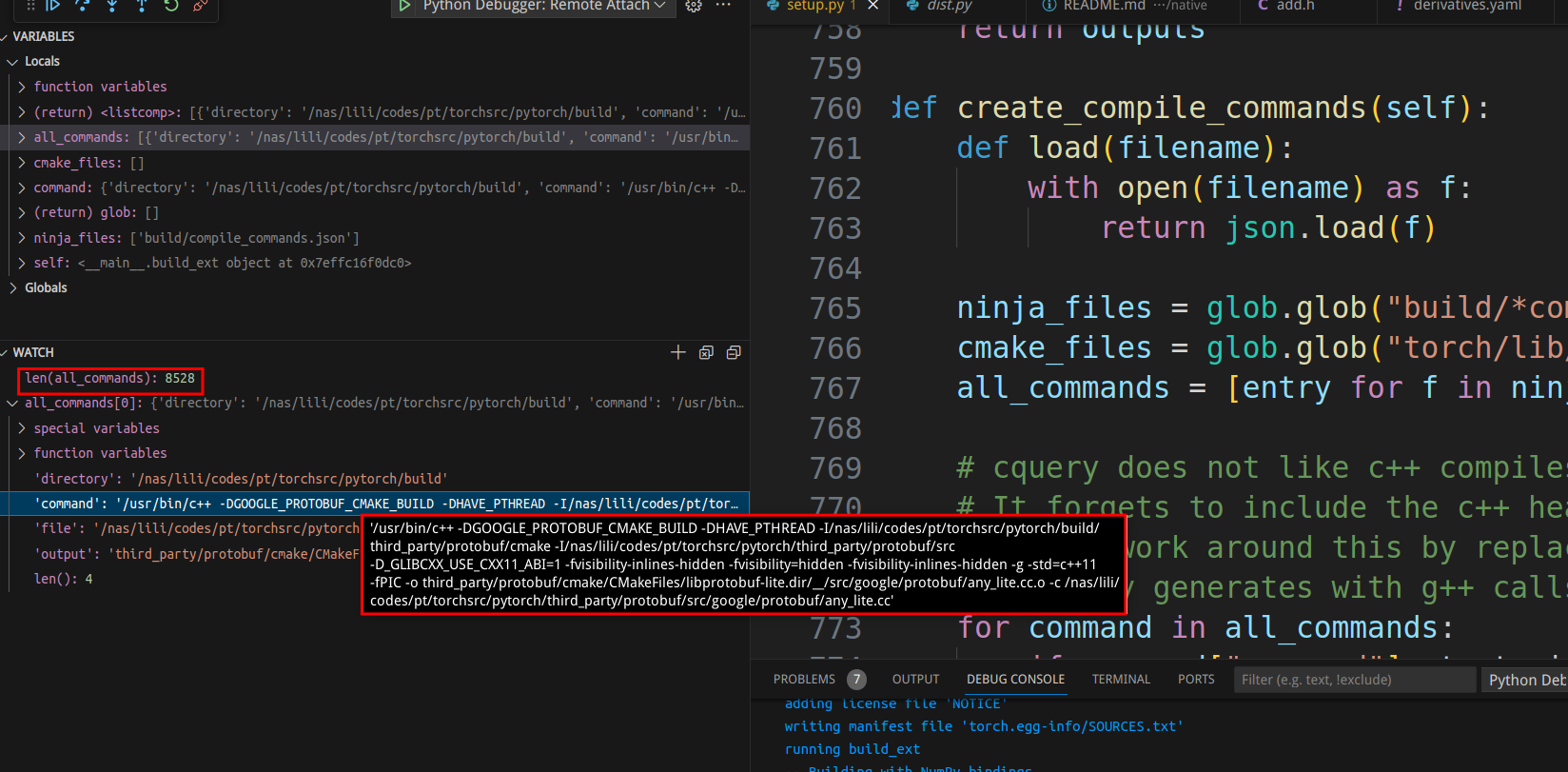
We can see that a total of 8528 cpp files need to be compiled, and the image shows the compilation command for one of them.
Debug
Debug python codes
Assuming that the PyTorch code we want to debug is running on a remote server, please refer to Remote Python Debugging with VSCode. Debugging PyTorch Python code is no different from debugging any other Python code.
Let’s write the simplest PyTorch code to debug:
# testdebug.py
import torch
d = torch.randn(2, 3)
print(d)
lauch.json:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger: Remote Attach",
"type": "debugpy",
"request": "attach",
"connect": {
"host": "remote server ip address",
"port": 5678
},
"justMyCode": false
}
]
On the server side, start the debugging interface.
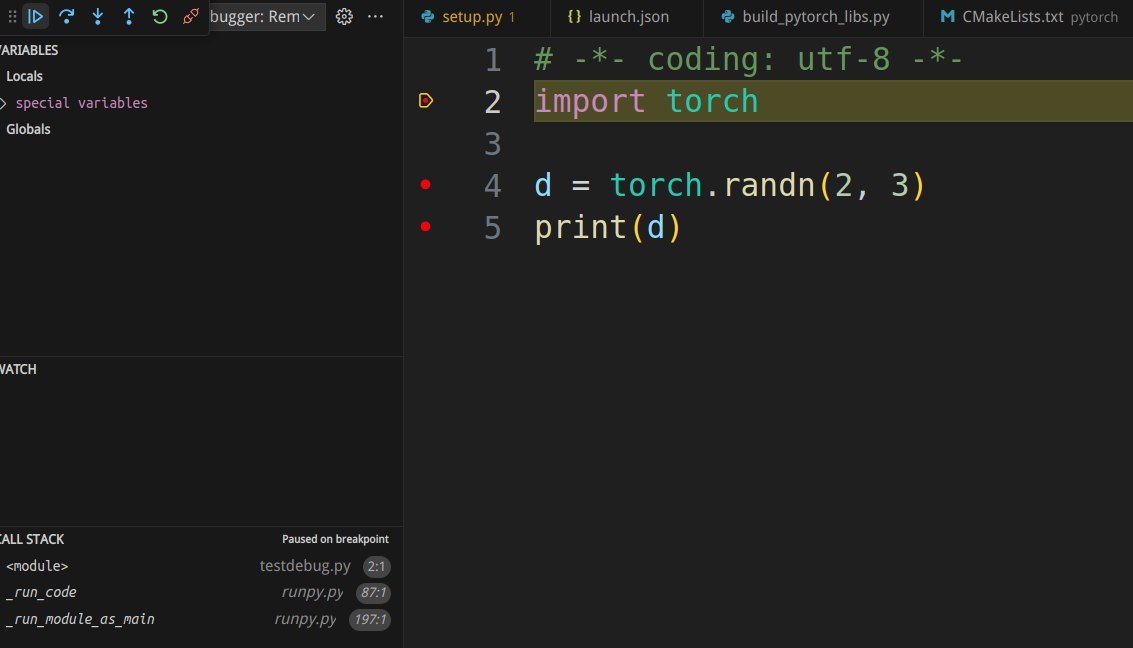
python -Xfrozen_modules=off -m debugpy --listen 0.0.0.0:5678 --wait-for-client testdebug.py
The debugging interface looks like the following image:
Debug c++ codes
Firstly, we need to clarify a concept: the so-called PyTorch C++ code refers to C extensions. Therefore, we are actually debugging the PyTorch C extensions inside CPython. Here, our Python interpreter (CPython) is a release version and cannot be debugged. However, our goal is not to debug the Python interpreter but rather to debug PyTorch C extensions. If you need to debug Python itself, please refer to Python Debug Build.
We will use gdb for debugging. If it is not installed, please refer to online resources for installation. For example, on Ubuntu, you can use:
sudo apt update
sudo apt install gdb
Next, we need to add gdb debugging in the launch.json file:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger: Remote Attach",
"type": "debugpy",
"request": "attach",
"connect": {
"host": "server ip",
"port": 5678
},
"justMyCode": false
},
{
"name": "Torch Debugger",
"type": "cppdbg",
"request": "attach",
"program": "/home/ubuntu/miniconda3/envs/torchbuild/bin/python",
"processId": "${command:pickProcess}",
"MIMode": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
]
}
]
}
The “program” field needs to be changed to the path of the Python interpreter in the conda virtual environment. When using gdb for attachment, root permissions are typically required by default. If the user has sudo privileges, a window will pop up asking for the password. However, remote debugging cannot pop up a window, so there may be issues. It might prompt “Authentication is needed to run /usr/bin/gdb’ as the super user”. The solution can be found in Troubleshoot attaching to processes using GDB](https://github.com/Microsoft/MIEngine/wiki/Troubleshoot-attaching-to-processes-using-GDB), and the simplest method is:
echo 0| sudo tee /proc/sys/kernel/yama/ptrace_scope
Next, let’s attach to the Python interpreter we just started. We select “Torch Debugger” to start, and a window will pop up asking us to choose the process to attach to. We can use keywords related to the process we started for searching.
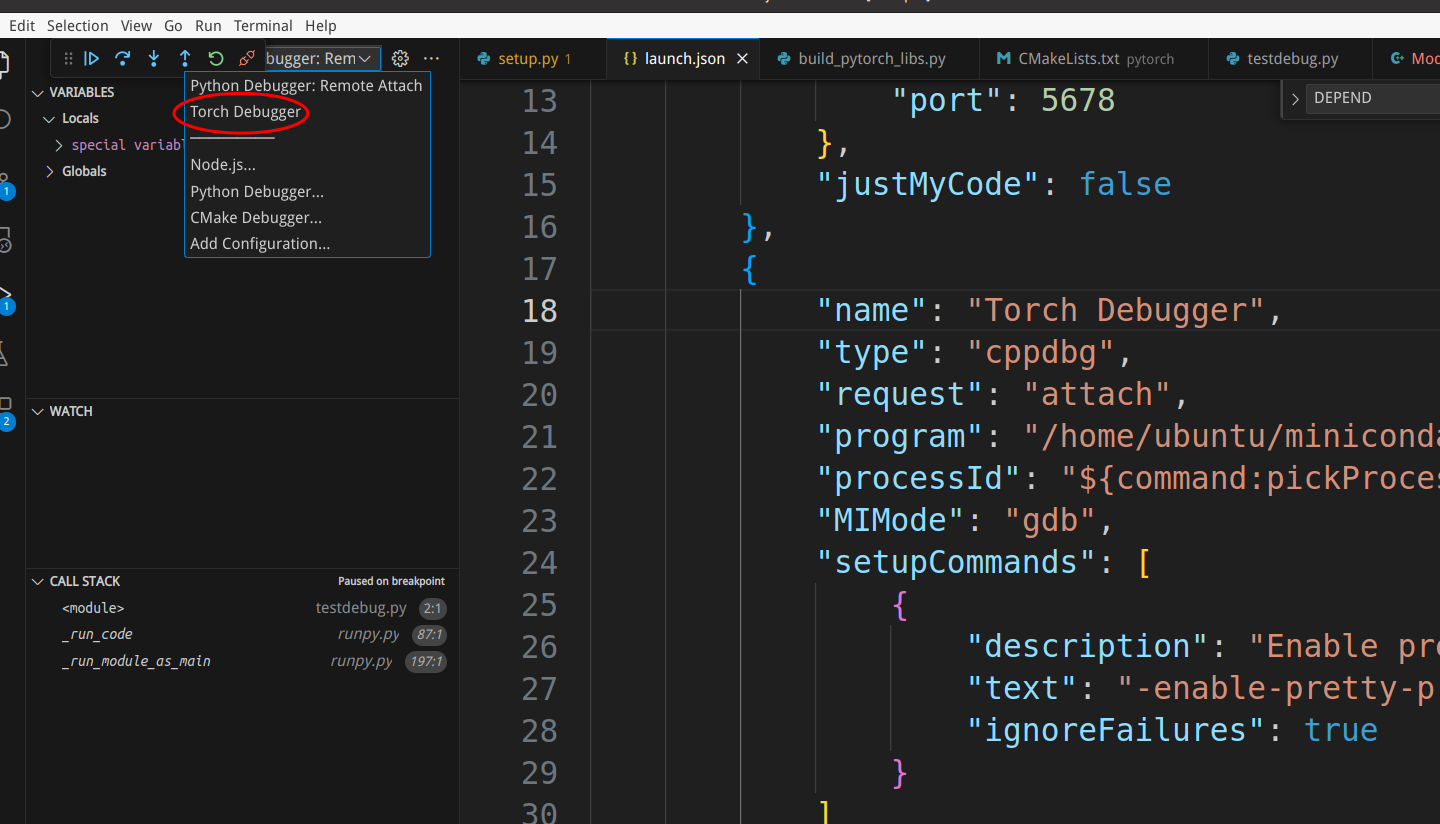
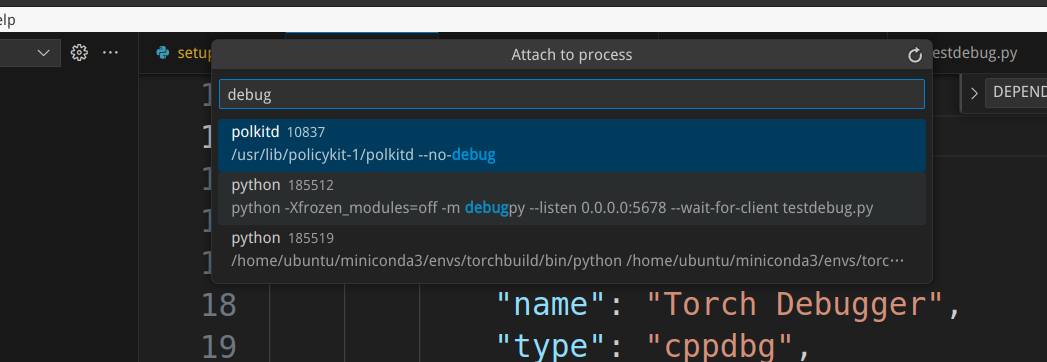
We can add breakpoints in the static PyObject* THPModule_initExtension function in torch/csrc/Module.cpp, which is called when initializing the torch._C module. Additionally, we can add a breakpoint in the randn function in aten/src/ATen/native/TensorFactories.cpp.
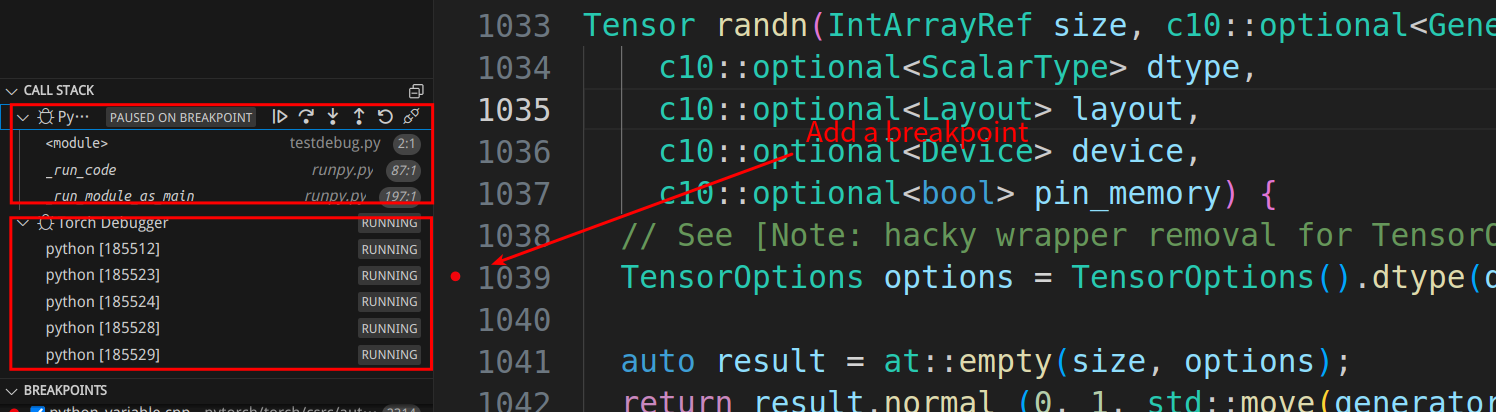
We can see on the left side that the callstack shows two debuggings. The Python debugging is in a paused state, while the PyTorch debugging is still running. We can click on the Python callstack and find that the Python code is stopped at the “import torch” statement.
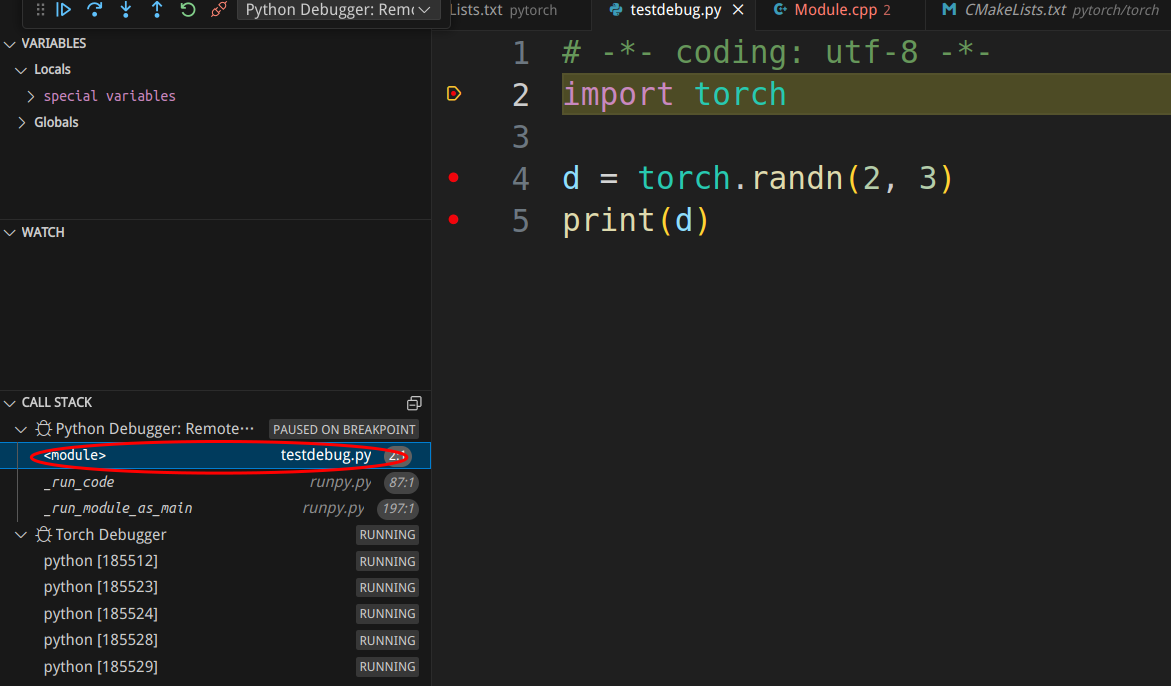
Next, we press F10 to step through the Python code and execute the import statement, at which point the PyTorch debugging will enter the breakpoint (importing torch may take a few minutes).
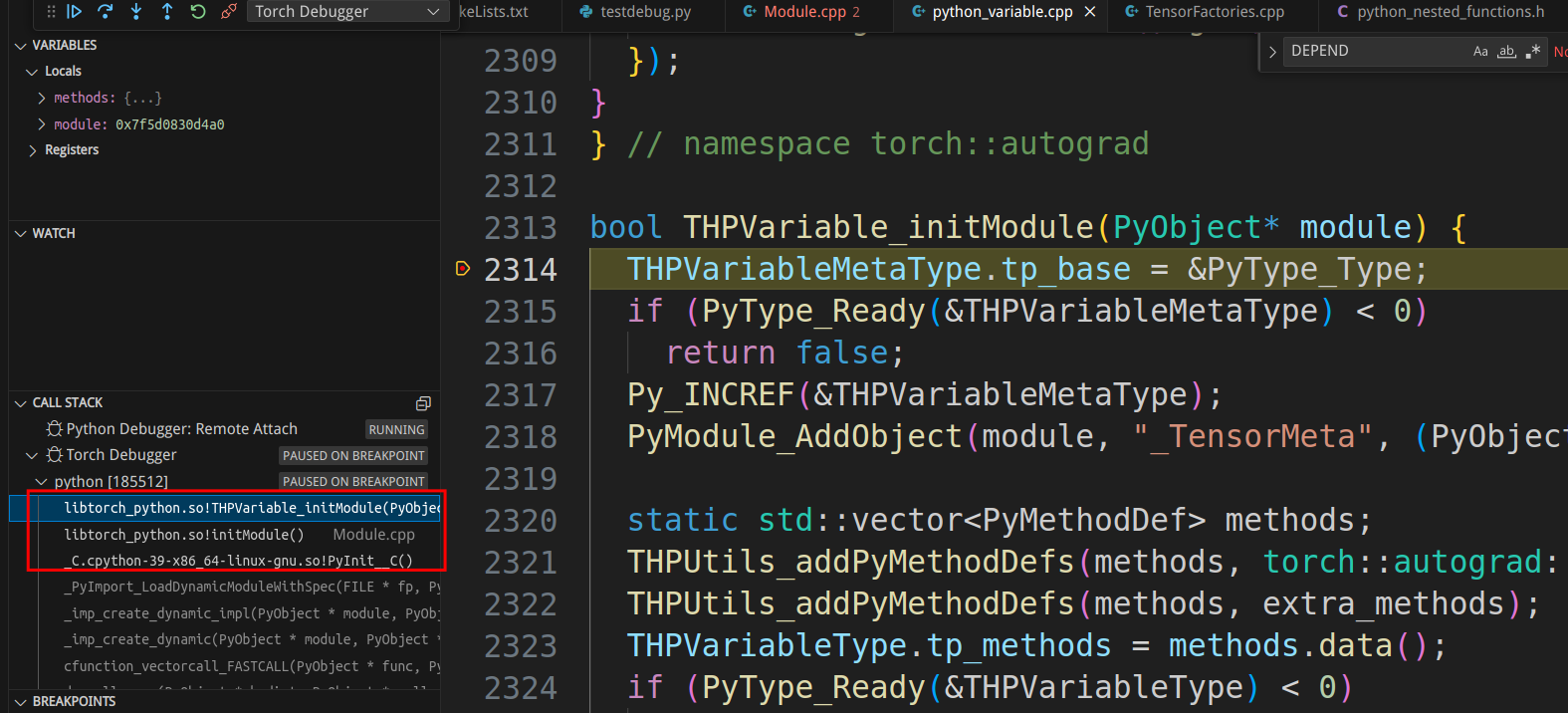
Indeed, it stops at “bool THPVariable_initModule(PyObject* module) {“ and we can also view the call stack. For instance, clicking on the third line can take us to torch/csrc/stub.c
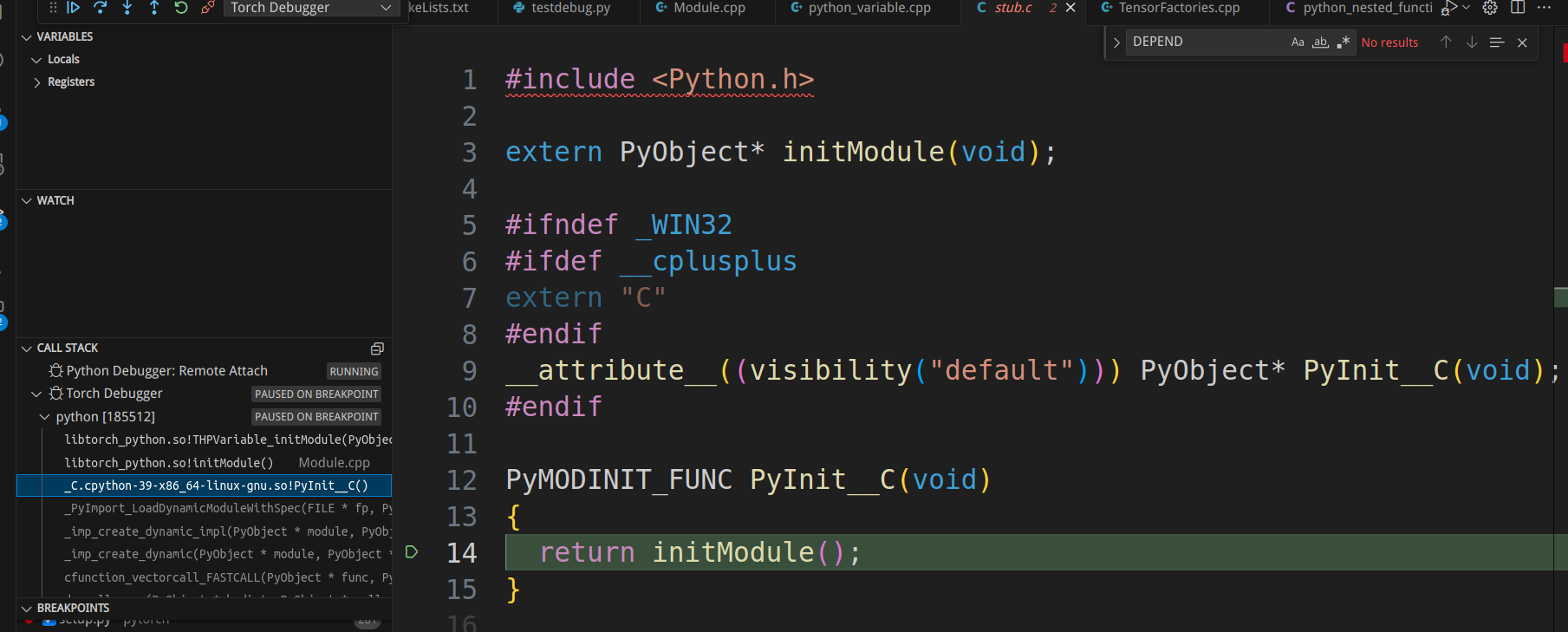
, which is where Python initializes C extension modules. Readers interested in a deeper understanding can refer to Building a Python C Extension Module, Python/C API Reference Manual and Extending and Embedding the Python Interpreter.
To continue running the Python interpreter, we press F5 to resume execution. After a while, the execution of “import torch” is completed, and the breakpoint returns to the Python code.
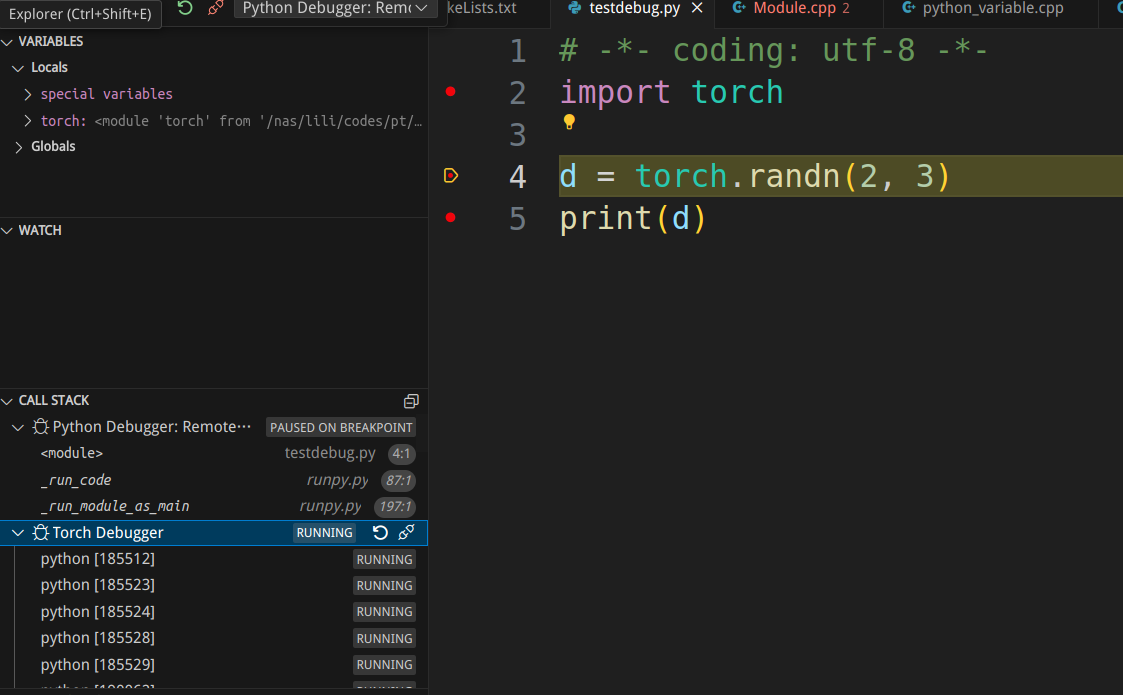
Next, we press F10 to step through “d = torch.randn(2, 3)”, and the breakpoint goes back to PyTorch.
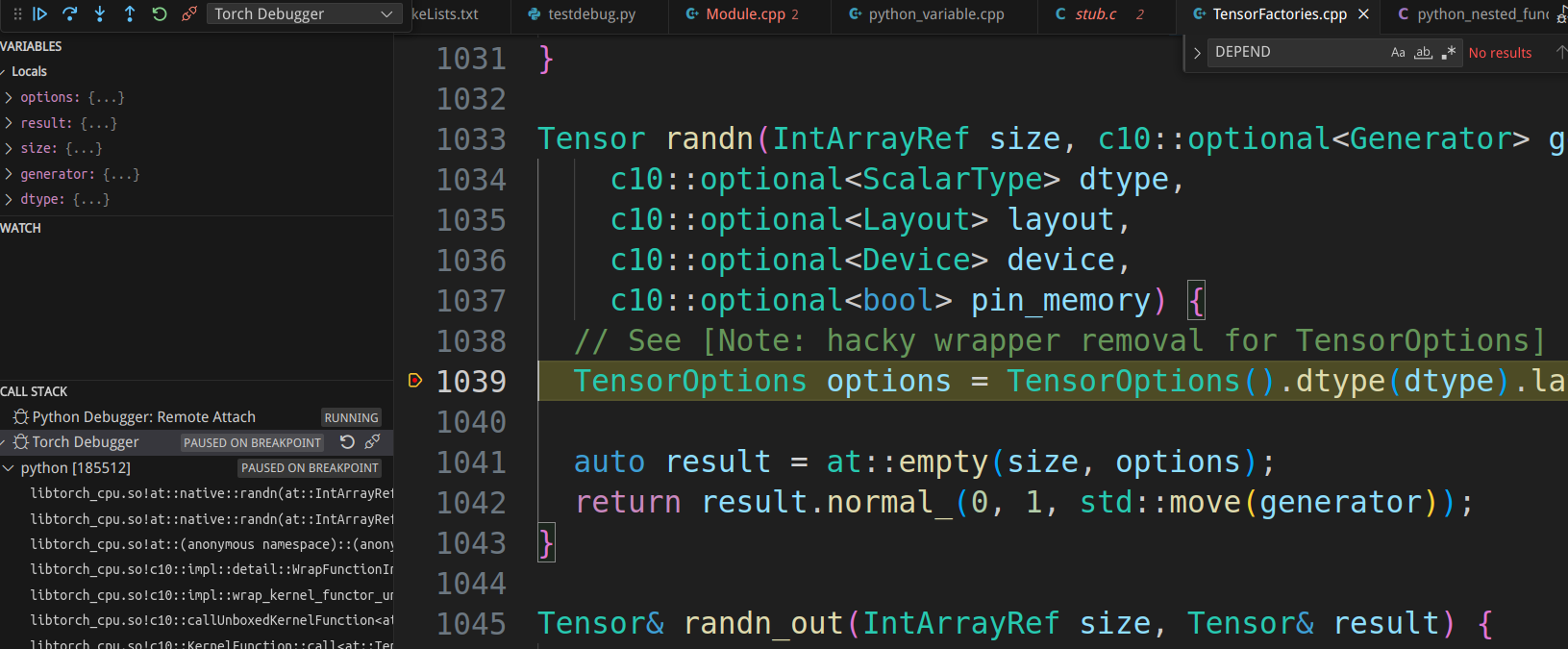
Pressing F5 continues the execution of randn in PyTorch, and the breakpoint returns to Python.
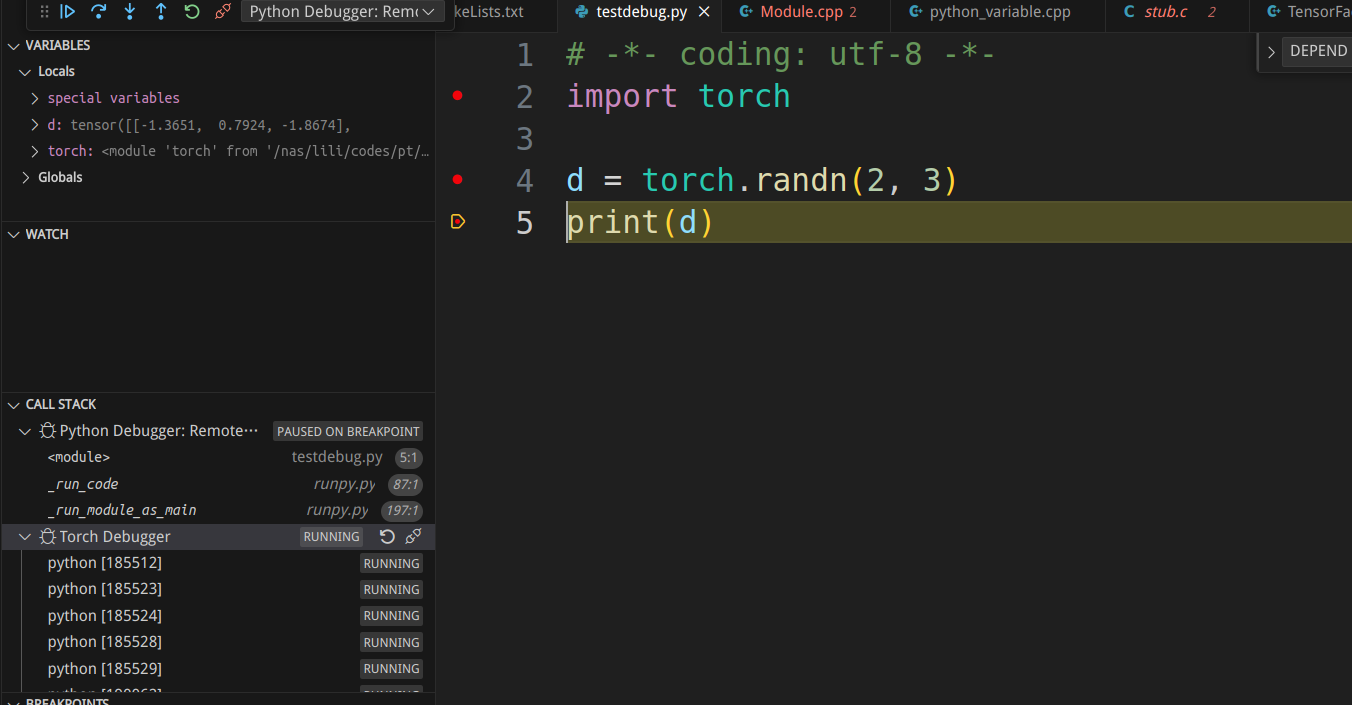
Reference Materials
- pytorch source code
- A Tour of PyTorch Internals (Part I)
- PyTorch Internals Part II - The Build System
- PyTorch – Internal Architecture Tour
- 小白学习pytorch源码(一)
- where can I find the source code for torch.unique()?
- PyTorch 2 Internals – Talk
- What’s the difference between aten and c10?
- PyTorch源码学习系列 - 1.初识
- 显示Disqus评论(需要科学上网)