本文介绍。
目录
概述
为了进行分布式训练,我们通常需要多台机器。比如大模型训练通常需要多机多卡的训练(几千甚至上万张GPU)。如果只是几台机器给固定的几个人使用,那么可以简单的协商:”同学们好,我要用16张卡训练一周,这两台机器归我了!”。但是如果机器几百上千台,这就没法管理了,而且涉及到资源分配的优先级,搞不好是要打架的。在传统的高性能计算(HPC)领域,大部分超算都使用了Slurm来做集群管理。在人工智能领域,因为使用GPU,服务器(节点)数量相对CPU时较少(HPC使用上千个计算节点非常常见),所以很多时候还是靠人肉管理。但是随着集群规模的扩大,也开始需要专门的集群管理。
相关系统
提到集群管理,互联网从业者可能会想起Yarn(Hadoop)和Spark,它们主要是大数据相关应用。另外也会想起K8S这样的集群管理。下面我们来简单的介绍一下它们各自的缘起和解决的核心问题。
Yarn
提起hadoop,大家想到的肯定是大数据、map/reduce和推荐算法这些。hadoop通过map/reduce的分布式计算范式,解决了互联网应用的一个重要问题——半结构化的日志数据分析。除了企业的核心内部数据(比如电商平台的商品/商家),这些数据一般存储在关系型数据库中,互联网应用和传统应用的一个重要区别是有大量的用户行为数据(用户搜索、浏览/点击/收藏)。这些用户行为数据的量级非常大,而且每天都会产生。而且相对于核心内部数据来说没有那么关键(想象一下电商平台的商品数据丢失和日志数据丢失的区别),所以这些数据都是保存日志中。它不像关系数据库那么有结构,而且存在大量冗余。
日志数据和商业数据另外一个重要的区别是处理方式,用数据库的术语,商业数据一般都是OLTP(Online Transaction Processing)。也就是说我们通常使用sql从大量数据中筛选少量数据展示给用户。比如我们浏览商品,会使用某些条件进行筛选。OLTP需要解决的是延迟的问题,也就是怎么尽快找到这些少量数据,比如使用索引。另外OLTP会涉及比较多的数据写入和更新,因此ACID特性需要考虑。而日志数据分析对应的是OLAP(Online analytical processing),我们需要读取大量数据,进行大量的计算然后得出商业洞察。在这里主要考虑的是吞吐量而不是延迟。当然,数据库里的OLAP是Online的,也就是说数据一旦改动,分析结果实时更改。而hadoop分析的日志(一般)是不变的,如果数据源发生改变,那么久需要同步数据,也许仍然可以叫OLAP,不过O是Offline的缩写了。
传统的数据库,尤其是Oracle这样的商用数据库也提供了强大的OLAP功能。但是它分析的数据的存储还是B-Tree这种针对OLTP优化的数据结构,所以它不太适用于用户行为数据的分析。想象一下,如果我们要把海量的用户行为数据保存到关系型数据库里,这是多么低效。我们不太可能用sql查询某一条日志,那么我们为它建立的索引就完全没有必要。另外日志通常只是顺序写一次,而且损坏了也没有那么严重,我们设计的复杂算法实现的ACID特性也是没有必要的。
Hadoop通过如下三个组件解决了上面的这些问题。
- HDFS解决了日志类文件的存储问题,并且通过冗余和分块实现了高效的读写(一次性写和追加写,不能像sql那样就地update)。
- Map/Reduce技术范式解决了一大类日志分类需求
- Yarn提供了一个用于支持Map/Reduce(或更多其它范式)的资源管理器(集群管理)
在最早的hadoop版本里,上面三个组件是不分家的,只是为了扩展到Map/Reduce范式之外,才把资源管理器独立出来。
从上面的历史发展可以看出,Yarn虽然是一个独立的资源管理器,我们理论上可以用它来管理通用目的的集群,但是实际上它的使用范围很少扩展到大数据领域之外。
Spark
Hadoop的Map/Reduce范式限制了它做更复杂的数据处理,尤其是机器学习,另外Hadoop的计算都是基于文件,速度也是个问题。Spark通过RDD的抽象,提出了一种基于内存的更加通用的计算范式。因为本文讨论的焦点是集群管理,我们这里不再详细介绍Spark的功能,只是简单的讨论一下它的集群管理。Spark可以部署在如下环境:
- Standalone
- Yarn
- Mesos
- K8s
Spark虽然也可以用于机器学习甚至深度学习的训练,但是它主要还是一个数据分析平台,大数据的标签和特征非常明显。即使是做机器学习的训练,它的核心卖点还是RDD,也就是处理海量的日志数据。所以在用户行为相关的机器学习模型中应用较多,比如搜索/广告/推荐系统。
Kubernetes(k8s)
k8s是一个容器编排系统,是一个用于自动化部署、扩展和管理容器化应用的开源系统。在讨论k8s之前,我们先需要讨论一下容器(container)。
提到容器,大家首先想到的肯定是docker。docker主要解决的是部署的问题。有过开发经验的读者肯定遇到过环境的问题——明明在我的开发环境能跑的程序到了另外一个环境怎么就跑不了?可以把容器看出一个轻量级的虚拟机,但是它们的实现方法和成本是有差异的。
对于互联网应用来说,微服务是很流行的架构(过度教条化的拆分微服务导致的问题也让大家思考拆分的必要性以及颗粒度),这么多的微服务存在复杂的依赖关系,我们需要管理它们。这些微服务部署到哪些机器上,服务之间的通信、服务发现、自动扩缩容、分布式日志和安全等等功能也是k8s及其生态需要考虑的问题。
Ray
Ray是一个开源的统一计算框架,它可以轻松扩展AI和Python工作负载,从强化学习到深度学习再到调优和模型服务。它的作者和Spark是同一拨人。
在大数据领域,由于Hadoop/Spark的先发优势,主流的语言是java/scala。但是在机器学习和深度学习领域,Python是绝对的王者。
虽然Spark上也可以跑机器学习甚至深度学习模型,但是Spark的优势还是处理海量数据。因此它更适合数据密集型的任务,比如海量用户行为日志数据。
而机器学习尤其是深度学习,它更多的是计算计算密集型任务。即使是训练LLM,它的训练数据也就是几TB的文本,而且训练的时候也不需要复杂的join之类的操作,数据之间也没有任何依赖关系。
在深度学习尤其是大模型场景,Ray更多的是一个封装和整合的作用:
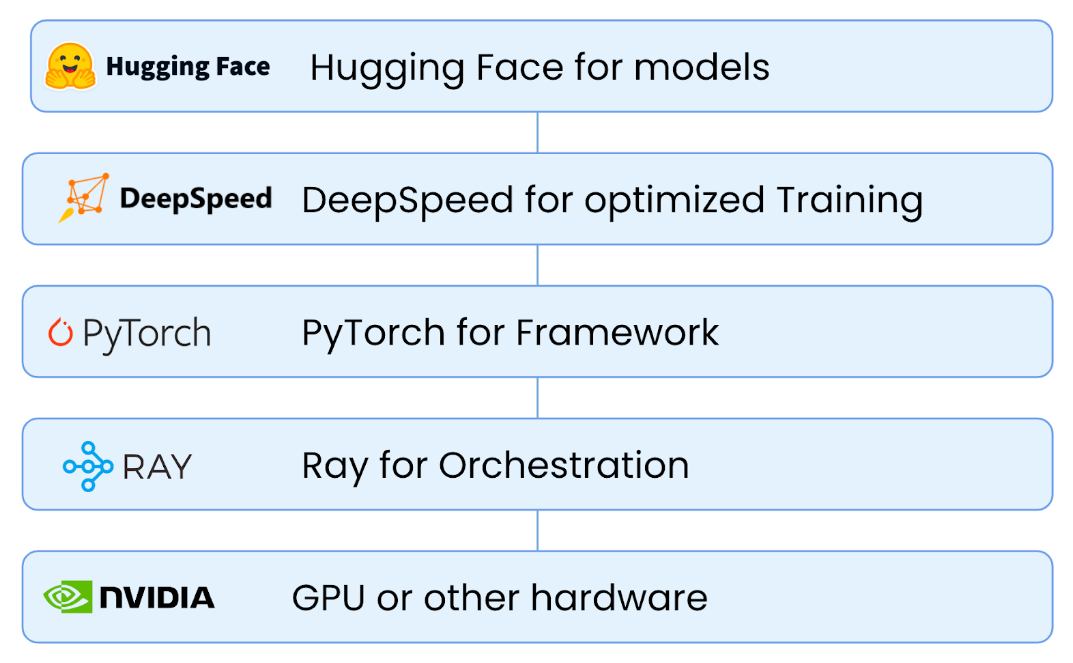
Ray除了有自己的集群管理功能,也可以部署在k8s或者GCP/AWS上。
Slurm
对HPC了解的读者对于Slurm一定不会陌生,目前世界上很多超级计算机(一般都是集群)都是用Slurm来管理其集群。Slurm是一个开源、容错性强、高度可扩展的集群管理和作业调度系统,适用于大型和小型Linux集群。
Slurm本身只是一个集群管理和作业调度系统,它没有提出任何计算范式。不过实际上在深度学习出现之前,大部分技术密集型任务都是在学术界,用于模拟、计算和分析复杂的科学问题,如天气预报、气候模拟、宇宙学研究、分子建模、地震模拟等。 比如天气预报,我们需要通过物理方法对大气进行建模,通常是一些偏微分方程,然后通过数值差分方法对其进行计算。在这些领域,通过MPI编程把多台机器集合起来解决一个数学问题是非常常见的做法。
适合深度学习的集群管理系统
深度学习的计算通常可以分为训练和预测(服务/serving)两个不同阶段。前者更大考虑训练的效率,而后者要考虑延时以及高可用/自动扩缩容等。
Slurm vs k8s
下面是k8s的特点:
- k8s用于长期运行的任务(如果不是业务变动,一个微服务会运行几年)
- 以微服务为单位支持动态扩缩容
- 云原生的系统,通常假设资源是无限的,只要不缺钱,随时增加资源
- 不用考虑优先级,所有的微服务地位都是对等的
- 资源调度的单位是节点级别(通过扩展也可以到更细粒度的gpu)
- 没有针对CPU核心亲和性的模型(不能保证一个pod独占一个核)
- 默认只能跑容器里的任务
- 系统的使用通常是通过像Terraform这样的工具进行编程化的。
- 机器的操作系统可能是不同的,通过容器屏蔽其差异
下面是slurm的特点:
- 系统的资源总量通常是固定的
- 短期运行(虽然也有运行几年的任务,但一般是几天到几个月,大部分没那么长耐心)
- 批处理任务,不涉及用户输入,一个任务时间较长(相对于微服务一个请求几秒甚至几百毫秒)
- 默认只支持Linux环境
- 优先级和排队非常重要
- 资源使用和计费功能
- 集群中的机器(尤其是同一个分区的计算节点)通常是完全相同的硬件和软件(操作系统/gcc和mpi环境等)构成
适用场景
因此我们可以发现,slurm是比较适合深度学习训练的,因为训练不需要那么复杂的功能。而深度学习的服务相比传统微服务更依赖于GPU,而且大模型的推理往往需要多卡甚至多机多卡(比如张量并行),目前还没有特别成熟的方案。在很多细分的领域,比如LLM,有一些专用的推理一起,比如Huggingface TGI、vLLM和Nvidia的TensorRT-LLM等。它们有些可能在容器来跑,但是涉及多机通信就会比较复杂。
对于训练来说,如果机器很少,也不太需要管理。如果很多的话slurm还是个不错的选择(但是看起来ai领域的人不太熟悉这个工具和生态系统)。对于推理来说,目前还没有特别成熟的方案。当然目前深度学习还在快速发展,像ray/kubeflow或者类似的平台会不会一统训练/推理整个市场还很难说。我们也会持续关注。
- 显示Disqus评论(需要科学上网)