本文解释MLA的代码。
前面的文章翻译:DeepSeek-V3 Explained 1: Multi-head Latent Attention解释了MLA的原理,本文介绍一下实现MLA的代码。
目录
开发环境
因为我只有CPU的机器(内存倒还行),由于DeepSeek-V3参数较大,我无法在本地用huggingface transformers跑起来。如果用llama.cpp或者ik_llama.cpp跑量化后的版本,倒也没有问题,但是我的目的是运行和调试代码。它们都是c++实现的不依赖pytorch的代码,虽然效率比较高,但是目前我的目的是学习,所以还是想看pytorch的代码。k-transformers虽然是pytorch,但是目前没有GPU。
所以最后找到了DeepSeek-V2-Lite,这个只需要100GB内存,不需要GPU就能跑起来。虽然很慢,但是对于学习和调试代码已经够了。
测试代码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Lite-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
MLA代码
通过阅读和调试代码,MLA的代码在modeling_deepseek.py。我们只看MLA相关的代码,MLA相关的代码都在类DeepseekV2Attention里面。
DeepSeek-V2-Lite和DeepSeek-V2的区别
DeepSeek-V2-Lite 拥有 27 层,隐藏维度为 2048。它还采用了 MLA(多头线性注意力),并有 16 个注意力头,每个头的维度为 128。其 KV 压缩维度为 512,但与 DeepSeek-V2 略有不同的是,它不压缩查询(queries)。对于解耦的查询和键,其每个头的维度为 64。DeepSeek-V2-Lite 也采用了 DeepSeekMoE,并且除了第一层之外,所有 FFN(前馈网络)都替换为 MoE 层。每个 MoE 层包含 2 个共享专家和 64 个路由专家,其中每个专家中间隐藏维度为 1408。在路由专家中,每个 token 将激活 6 个专家。在此配置下,DeepSeek-V2-Lite 总参数为 157 亿,其中每个 token 激活 24 亿参数。
我diff了一下模型的配置:DeepSeek-V2和DeepSeek-V2-Lite。它们的区别是:
- hidden_size 5120 -> 2048
- intermediate_size 12288 -> 10944
- moe_intermediate_size 1536 -> 1408
- n_group 8 -> 1
- n_routed_experts 160 -> 64
- num_attention_heads 128 -> 16
- num_hidden_layers 60 -> 27
- num_key_value_heads 128 -> 16
- q_lora_rank 1536 -> null
- routed_scaling_factor 16 -> 1
- topk_group 3 -> 1
- topk_method “group_limited_greedy” -> “greedy”
- transformers_version 4.39.3 -> 4.33.1
参数(尤其是num_attention_heads、num_key_value_heads和num_hidden_layers)变小的效果使得模型变小,对于我们阅读代码来说没有任何影响,这里唯一的重要区别就是q_lora_rank 1536 -> null。这个导致DeepSeek-V2-Lite不压缩query,后面的代码分析我们会看到。
构造函数
def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
if layer_idx is None:
logger.warning_once(
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
"when creating this class."
)
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.q_lora_rank = config.q_lora_rank
self.qk_rope_head_dim = config.qk_rope_head_dim
self.kv_lora_rank = config.kv_lora_rank
self.v_head_dim = config.v_head_dim
self.qk_nope_head_dim = config.qk_nope_head_dim
self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.is_causal = True
if self.q_lora_rank is None:
self.q_proj = nn.Linear(
self.hidden_size, self.num_heads * self.q_head_dim, bias=False
)
else:
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
self.o_proj = nn.Linear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=config.attention_bias,
)
self._init_rope()
self.softmax_scale = self.q_head_dim ** (-0.5)
if self.config.rope_scaling is not None:
mscale_all_dim = self.config.rope_scaling.get("mscale_all_dim", 0)
scaling_factor = self.config.rope_scaling["factor"]
if mscale_all_dim:
mscale = yarn_get_mscale(scaling_factor, mscale_all_dim)
self.softmax_scale = self.softmax_scale * mscale * mscale
下面我们对照MLA的计算公式来看看代码。
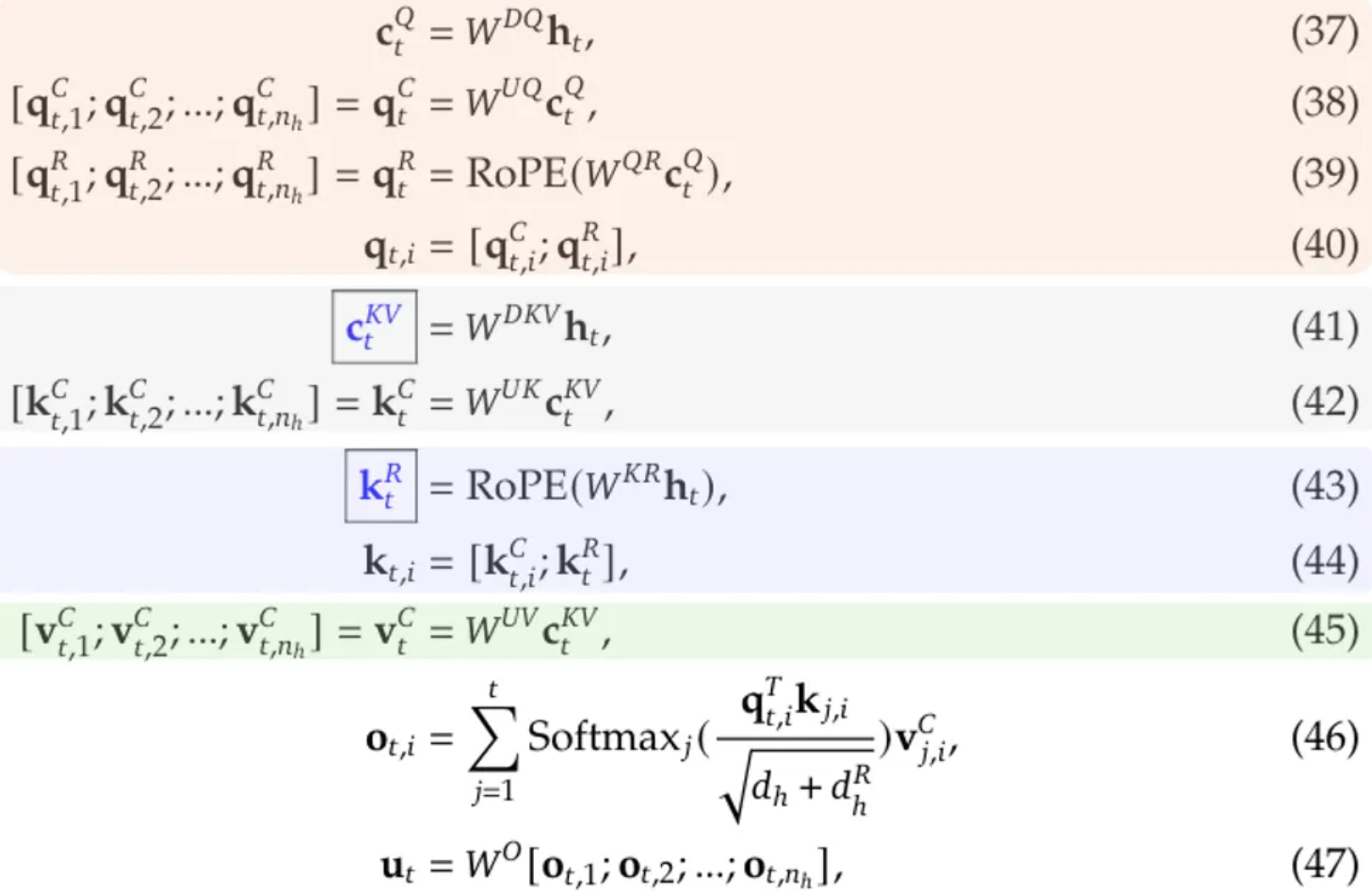
query
if self.q_lora_rank is None:
self.q_proj = nn.Linear(
self.hidden_size, self.num_heads * self.q_head_dim, bias=False
)
else:
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
注意:前面提到的DeepSeek-V2-Lite没有对Query进行压缩,而是直接用一个矩阵self.q_lora_rank变换query。self.q_lora_rank $\in R^{3072 \times 2048}$,直接把输入从2048 -> 3072。而如果是DeepSeek-V2,则其代码只有else的部分:
self.q_a_proj = nn.Linear(
self.hidden_size, config.q_lora_rank, bias=config.attention_bias
)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(
config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False
)
这里self.q_a_proj对应论文的$W^{DQ}$,它把输入从5120压缩到1536。self.q_b_proj用于解压。注意:这个q_b_proj是$W^{UQ}$和$W^{QR}$的合并。
key和value
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
注意,这里把公式的$W^{DKV}$和$W^{KR}$合并在这个self.kv_a_proj_with_mqa里了,因为根据公式(41)和(43),它们都是需要乘以$h_t$,合并后可以一次矩阵乘法搞定。所以我们看到它的输出维度是config.kv_lora_rank + config.qk_rope_head_dim,也就是$c_t^{KV}$和$k_t^R$的维度。所以self.kv_a_proj_with_mqa的维度是576 = 512 + 64。
仔细比较公式(39)和(43),我们发现$q_t^R$是可以拆分成$[q_{t,1}^R; q_{t,2}^R; …; q_{t,n_h}^R]$;而$k_t^R$没有展开,所有的head都是用这一个。
这里注意一下config.qk_rope_head_dim,对于query的所有head,位置编码向量是共享的。所以这里没有用self.num_heads乘以它。但是把这个起名为mqa(Multi-Query Attention)感觉不太合适,因为Multi-Query Attention是多个query一个key/value,而这里是一个query多个key/value。
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads
* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
self.kv_b_proj合并了$W^{UK}$和$W^{UV}$,这里key的输出维度不包括RoPE,所以单个head是self.q_head_dim - self.qk_rope_head_dim = 192 - 64;value的输出维度是128。所以最终self.kv_b_proj的输出维度是16 * (192 - 64 + 128) = 4096。
输出投影矩阵
self.o_proj = nn.Linear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=config.attention_bias,
)
最终的self.o_proj把attention的输出投影到hidden_size,这里它的输入和输出的维度正好相等,都是2048。
_init_rope
这里为了扩大context window,使用了YaRN: Efficient Context Window Extension of Large Language Models。关于RoPE的一些变种如NTK、DynamicNTK和YARN,和MLA关系不大。后面有空我们单独介绍。
forward方法
完整代码如下,后面我们还是一步步对照公式来看。
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. Please make sure use `attention_mask` instead.`"
)
bsz, q_len, _ = hidden_states.size()
if self.q_lora_rank is None:
q = self.q_proj(hidden_states)
else:
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
kv_seq_len = value_states.shape[-2]
if past_key_value is not None:
if self.layer_idx is None:
raise ValueError(
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
"with a layer index."
)
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
key_states, value_states = past_key_value.update(
key_states, value_states, self.layer_idx, cache_kwargs
)
attn_weights = (
torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale
)
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
f" {attn_weights.size()}"
)
assert attention_mask is not None
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
# upcast attention to fp32
attn_weights = nn.functional.softmax(
attn_weights, dim=-1, dtype=torch.float32
).to(query_states.dtype)
attn_weights = nn.functional.dropout(
attn_weights, p=self.attention_dropout, training=self.training
)
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.v_head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.v_head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.num_heads * self.v_head_dim)
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
计算query
if self.q_lora_rank is None:
q = self.q_proj(hidden_states)
else:
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
因为是Lite版本,query没有压缩,self.q_proj 2048 -> 3072,因此q的shape是3072。如果是标准版本,先用q_a_proj压缩再用q_b_proj解压,这对应公式(37)和(38)以及(39)的RoPE之前的部分。注意:q_b_proj是$W^{UQ}$和$W^{QR}$的合并。
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
首先把q从[17, 3072]reshape成[1, 16, 17, 192]代表(batch, head, len, q_head_dim)。 然后用split把$q_t^C$和$q_t^R$(RoPE前)分开得到q_nope, q_pe(还没有RoPE)。它们的shape分别是[1, 16, 17, 128]和[1, 16, 17, 64]。
计算key和value
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2)
self.kv_a_proj_with_mqa合并了$W^{DKV}$和$W^{KR}$,所以第一行得到的compressed_kv是$c_t^{KV}$和$k_t^R$(RoPE前)。然后第二行把$c_t^{KV}$和$k_t^R$拆分出来得到compressed_kv, k_pe,shape分别是[1, 17, 512]和[1, 17, 64]。最后把k_pe的shape变成[1, 1, 17, 64],代表(batch, 1, len, rope_dim)。
kv = (
self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2)
)
k_nope, value_states = torch.split(
kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1
)
前面说过self.kv_b_proj合并了$W^{UK}$和$W^{UV}$,所以第一行实现了公式(42)和(45),同时计算$k_t^C$和$v_t^C$。然后下面再split出来得到k_nope和value_states,它们的shape分别是[1, 16, 17, 128]和[1, 16, 17, 128]。
关于KV-cache的代码和MLA无关,我们跳过。
计算RoPE
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
这里是对q_pe, k_pe计算RoPE,它们的shape保持不变,分别是[1, 16, 17, 64]和[1, 1, 17, 64]。
注意:k_pe的num_head是1,所以对于所有的head,key和value都是共享的。仔细比较公式(39)和(43),我们可以发现$q_t^R$是可以拆分成$[q_{t,1}^R; q_{t,2}^R; …; q_{t,n_h}^R]$;而$k_t^R$没有展开,所有的head都是用这一个。
拼接query和key
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
把q_nope和q_pe拼成完整的query,类似的把k_nope和k_pe拼接成key。
再后面就是标准的attention的计算,代码就不介绍了。
- 显示Disqus评论(需要科学上网)