本文翻译DeepSeek Explained 4: Multi-Token Prediction。
这是我们 DeepSeek-V3 系列的第四篇文章,我们将解释 DeepSeek [1], [2] 模型中的最后一项主要架构创新:多 token 预测(multi-token prediction)。
本文我们将探讨 DeepSeek 如何在文本生成方面,在效率和质量之间取得另一个平衡。
目录
背景
要理解 DeepSeek 的多令牌预测,我们首先来仔细看看大型语言模型 (LLM) 是如何生成文本的。
下一令牌预测
大型语言模型通常遵循自回归方法生成文本,即,给定一个先前令牌序列,新令牌将通过预测最有可能的下一令牌以“逐令牌”的方式生成。
例如,给定文本“The cat sat”,它将被分词为以下令牌序列:
"The cat sat" -> ["The", "cat", "sat"]
每个令牌都有一个对应的令牌 ID,该 ID 是其在词汇表中的索引,并通过使用该索引在嵌入矩阵中查找来映射到密集向量。在大多数情况下,一个位置嵌入将被添加到这个密集向量中,以形成大型语言模型将接收的嵌入:
Emb("The") = vector("The") + PositionalEncoding(1)
Emb("cat") = vector("cat") + PositionalEncoding(2)
Emb("sat") = vector("sat") + PositionalEncoding(3)
在经过大型语言模型中的 Transformer 层之后,最后一层通常是一个线性投影,将每个嵌入向量映射回词汇表空间,然后是一个 Softmax 层,输出词汇表上的概率。在我们这里的小例子中,概率最高的令牌可能是:
P("on") = 0.7
P("under") = 0.3
...
因此,模型将选择最有可能的令牌“on”,所以生成的文本将是:
"The cat sat on"
这种逐令牌的过程将一直持续,直到达到最大长度或遇到 EOS(句子结束)令牌。由于它每一步只生成一个令牌,因此通常被称为“下一令牌预测”,并且可以更正式地描述为:
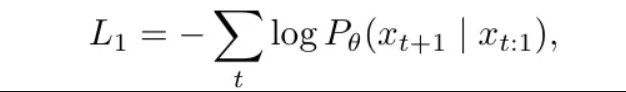
其中:
- $t$ 代表第 $t$ 个时间步。
- $x_{t:1}$ 代表从 $x_1$ 到 $x_t$ 的过去令牌序列。
- $x_{t+1}$ 是下一个未来令牌。
从建模的角度来看,下一令牌预测听起来非常自然,但它有一些局限性:
- 首先,它无法并行化,因为它需要每次顺序处理一个令牌。
- 此外,每次预测都需要一个完整的正向传播,这使得训练和推理效率非常低,特别是对于长文本的实时生成。
为了缓解这些局限性,提出了多令牌预测。
之前的多令牌预测
在 [3] 中,作者将下一令牌预测扩展到多令牌预测机制:
其中,给定相同的输入序列,模型将通过一次前向传播生成从 $x_{t+1}$ 到 $x_{t+n}$ 的 $n$ 个令牌。
请注意,这并不意味着在由单个 Softmax 产生的概率之上同时选择 $n$ 个令牌,因为 Softmax 不支持从单个概率分布中同时选择 $n$ 个令牌。
这是因为 Softmax 是为分类分布设计的,它模拟了在多个互斥选择中单个离散事件的概率。因此,Softmax 在每个时间步只能生成一个令牌,为了预测多个令牌,我们需要多个 Softmax 层,每个层专门用于生成一个单独的令牌。 因此,上述多令牌预测损失将首先分解为一系列单令牌预测操作头,然后每个单令牌预测头将运行一个单独的 Softmax 来选择相应的令牌。
更具体地说,引入了一个中间潜在表示 $z_{t:1}$ 来表示 LLM 中的隐藏表示,如下列方程所示:
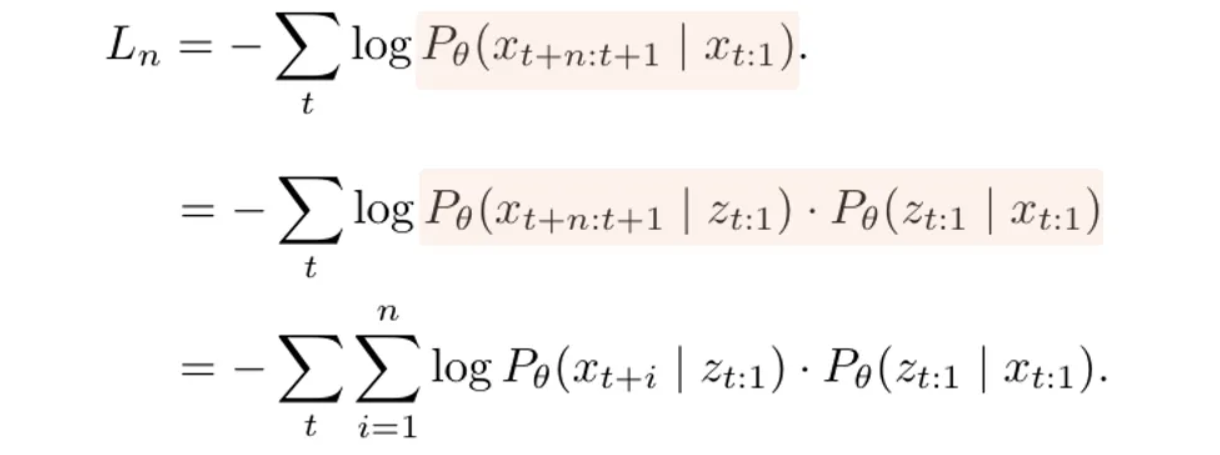 根据 [3] 中的公式,由作者创建的图片。
根据 [3] 中的公式,由作者创建的图片。
这解耦了输入序列 $x_{t:1}$ 和输出序列,使得模型能够通过一次前向传播将 $x_{t:1}$ 编码为 $z_{t:1}$,并将其用于所有后续生成过程。
之后,$x_{t+n:t+1}$ 和 $z_{t:1}$ 之间的条件概率被进一步分解为 $n$ 个独立的单步条件,每个条件代表一个单令牌生成步骤,如蓝色部分所示:
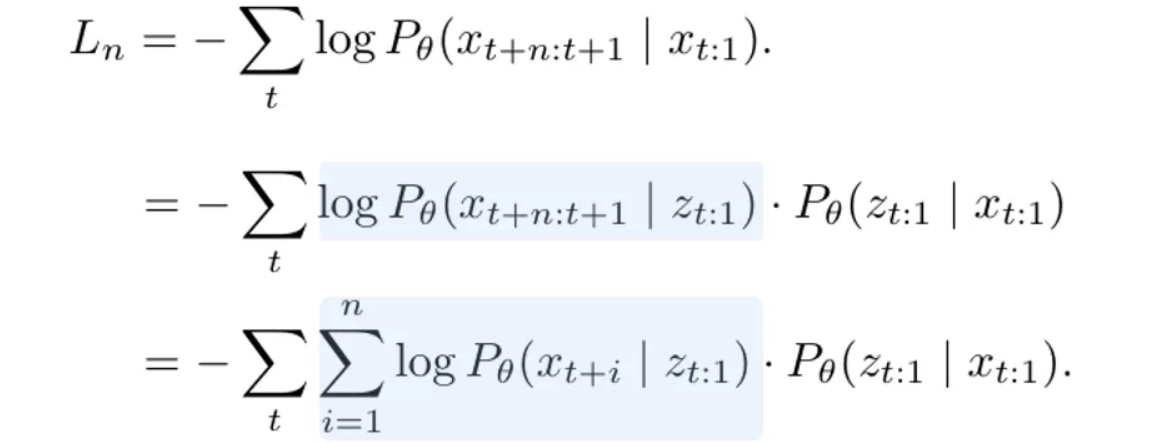 根据 [3] 中的公式,由作者创建的图片。
根据 [3] 中的公式,由作者创建的图片。
在 [3] 中,这个过程是根据以下公式实现的:
 根据 [3] 中的公式,由作者创建的图片。
根据 [3] 中的公式,由作者创建的图片。
下图也对此进行了说明:
- 一个共享的 Transformer $f_s$ 通过一次前向传播将 $x_{t:1}$ 编码为 $z_{t:1}$。
- $n$ 个独立的输出头 $f_{h_i}$,实现为 Transformer 层,用于将中间隐藏表示 $z_{t:1}$ 映射到 $x_{t+i}$。特别是,第一个输出头(当 $i==1$ 时)的输出可以认为是下一令牌预测头。
- 一个共享的解嵌入矩阵 $f_u$ 用于将 $x$ 映射到词汇表大小的维度,在此之上应用 Softmax 以获得每个令牌的概率。
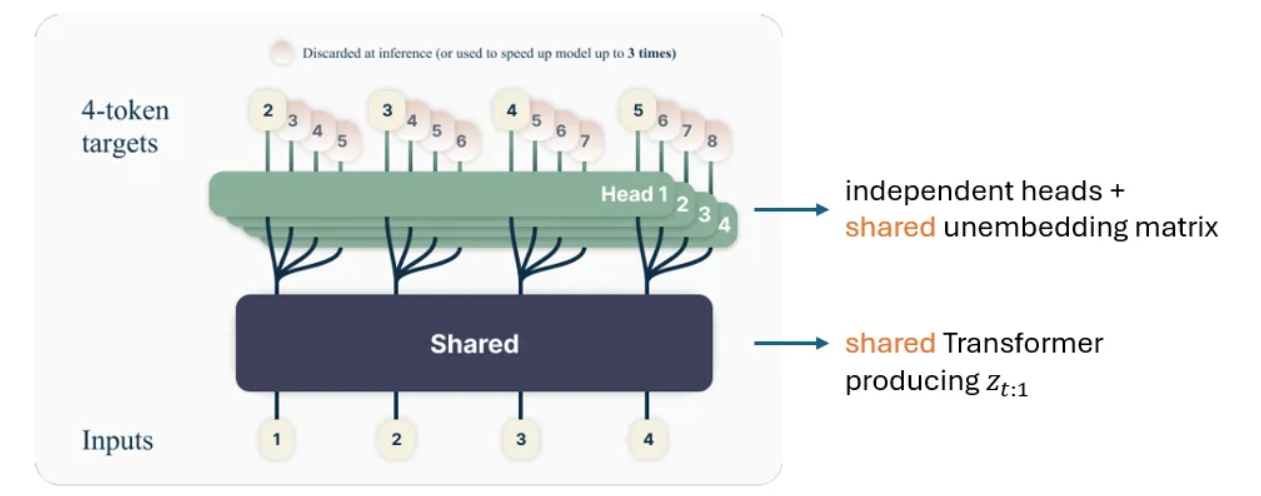 图 1. [3] 中的多令牌预测架构。图片来自 [3]。
图 1. [3] 中的多令牌预测架构。图片来自 [3]。
现在,让我们更深入地研究这个架构,特别是其共享和独立组件背后的设计选择:
- 共享 $f_s$:正如我们之前提到的,这使得我们能够通过一次前向传播获得 $z_{t:1}$ 以生成 $n$ 个令牌,从而比下一令牌预测具有更高的计算效率。
- 共享解嵌入矩阵 $f_u$:这在不严重影响性能的情况下节省了参数预算,因为解嵌入矩阵的维度非常大,为 $d \times V$,其中 $d$ 是隐藏层维度,$V$ 是词汇表大小(通常为 50K~200K)。
- 独立的头部:这是此架构中唯一独立的部分。正如我们之前提到的,每个令牌都需要一个单独的 Softmax,因此我们无法共享所有组件。
使用独立的输出头解耦了 $n$ 个令牌的生成过程,使它们相互独立。一方面,这使得令牌可以并行生成,并可能提高训练效率。然而,独立生成令牌可能导致不连贯或不一致的输出。此外,模型可能遭受模式崩溃,即它倾向于生成通用、频繁的词,而不是细致入微的响应,从而降低了输出的多样性和丰富性。
在下一节中,我们将看到 DeepSeek 的多令牌预测技术如何解决这个问题。
DeepSeek 的多令牌预测
正如我们之前解释的,[3] 中的多令牌预测方法是独立生成 $n$ 个令牌的,这可能导致输出不连贯甚至模式崩溃。为了解决这个问题,DeepSeek 通过为每个令牌的预测保留完整的因果链来实现其多令牌预测,如下图所示:
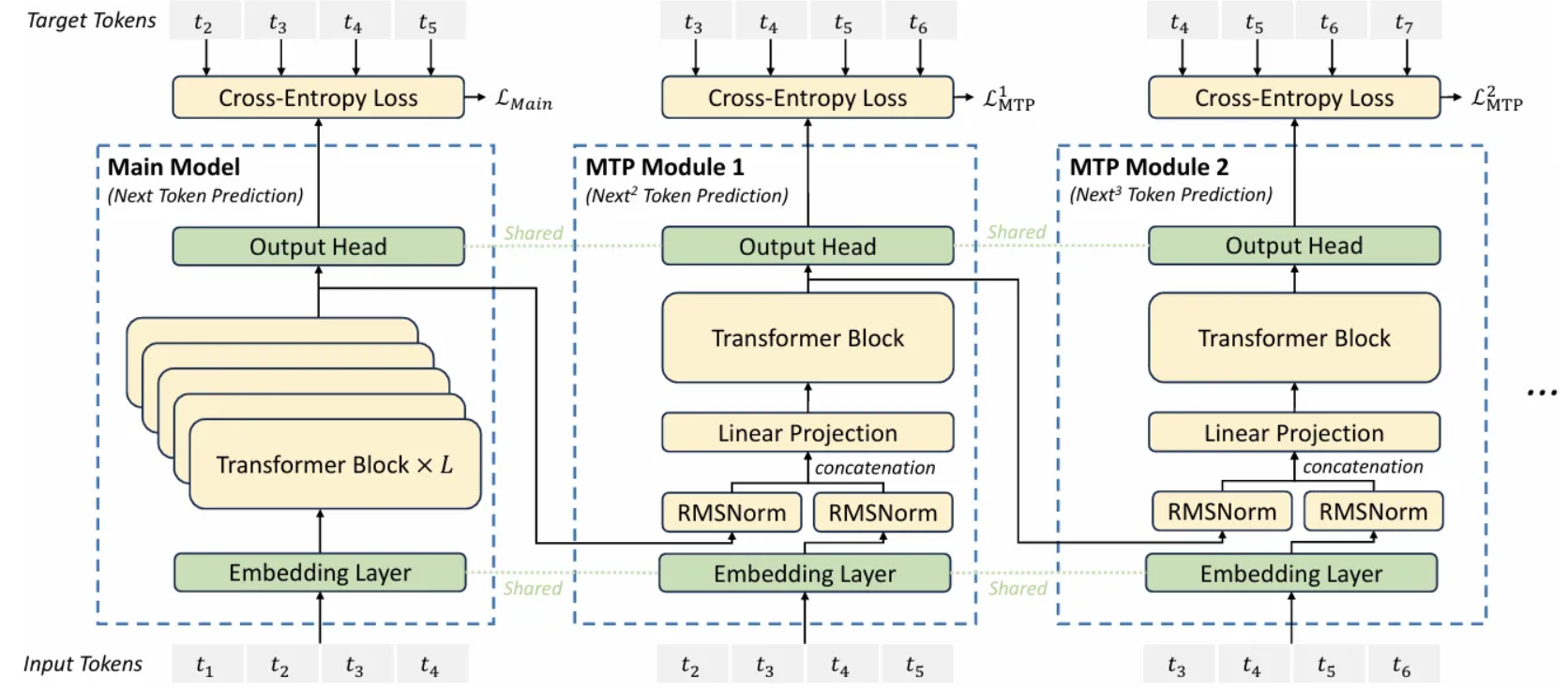 图 2. DeepSeek 中的多令牌预测。图片来自 [2]。
图 2. DeepSeek 中的多令牌预测。图片来自 [2]。
上图展示了三个生成步骤,分别被称为主模型、MTP 模块 1 和 MTP 模块 2。
主模型的架构与我们在 [3] 中看到的非常相似,也包含三个主要构建模块:
- 一个共享嵌入层。
- 一个独立的 Transformer 块。
- 一个共享线性输出头,类似于 [3] 中的解嵌入矩阵。
然而,从 MTP 模块 1 开始,差异变得明显,因为 Transformer 块的输入依赖于前一个令牌的表示。
更具体地说,第 $i$ 个令牌的 Transformer 输入如下获得:
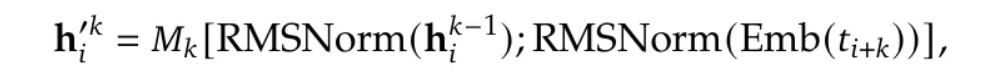
其中:
- $k$ 是 MTP 模块的索引。
- $h^{k-1}_{i}$ 是前一步的表示。
- $\text{Emb}(t_{i+k})$ 是第 $(i+k)$ 个令牌的嵌入层输出。
RMSNorm 运算符对两个表示向量进行归一化,使其值更具可比性,并允许它们被拼接。之后是一个拼接运算符 $[ \cdot ; \cdot ]$,它生成一个 $2d$ 维的表示。
最后,应用一个线性投影矩阵 $M_k$ 将维度从 $2d$ 映射回 $d$,使其可以被 Transformer 消费。
在 MTP 模块之间引入依赖关系打破了 [3] 中的并行性,但也使得文本生成更加连贯,使其更适合对话和推理等场景。
多令牌预测主要用于 DeepSeek 模型的训练中,每个 MTP 模块都应用了交叉熵损失,如下所示:
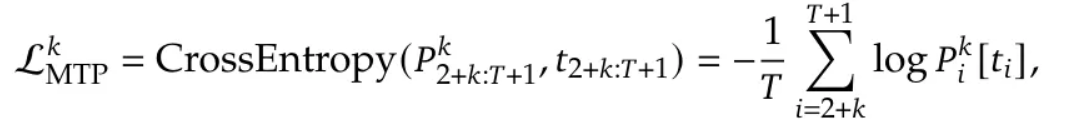
其中 $t_i$ 代表第 $i$ 个位置的真实(ground-truth)令牌,而 $p^k_i[t_i]$ 则是第 $k$ 个 MTP 模块给出的 $t_i$ 的预测概率。
所有 MTP 损失的组合随后被用作一个额外的训练目标:
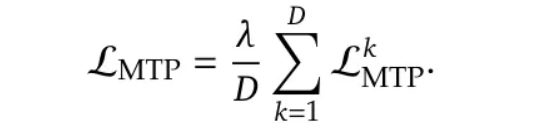
在推理阶段,所有的 MTP 模块都会被丢弃,只使用主模型进行令牌预测。然而,在 [2] 中,作者也提到他们的 MTP 技术可以与推测解码(speculative decoding)结合使用来加速推理。
那么,它是如何工作的呢?
推测解码
推测解码是一种旨在通过草稿-验证范式来加速自回归生成过程的技术 [4, 5]:它首先并行生成多个候选令牌,然后使用原始的自回归(AR)模型验证或纠正这些令牌,如下图所示:
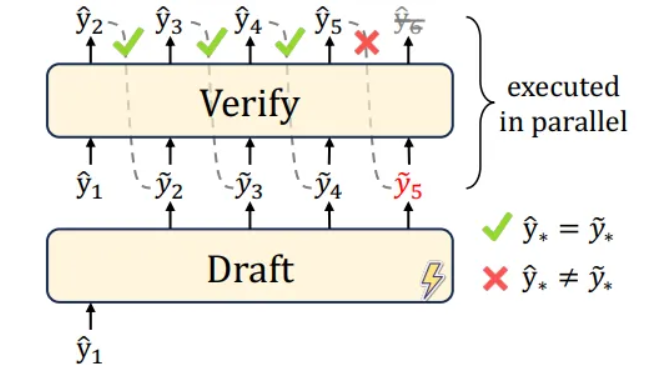 图 3. 推测解码的草稿-验证图。图片来自 [5]。
图 3. 推测解码的草稿-验证图。图片来自 [5]。
更具体地说,推测解码包括两个阶段:
- 并行草稿生成(Parallel drafting):推测解码不使用原始的自回归(AR)模型逐一生成令牌,而是并行生成令牌。
- 批量验证(Batch verification):原始的 AR 模型用于通过一次前向传播验证生成的草稿令牌,并在需要时接受或纠正它们。
由于草稿令牌可以被接受或拒绝,实际的加速主要取决于接受率:
- 在理想情况下,所有 K 个草稿令牌都被接受,允许模型在一次前向传播中向前移动 K 步,实现 K 倍的加速。
- 如果一些草稿令牌被拒绝,生成过程仍然会受益于一定的加速,因为只需要重新生成被拒绝的令牌,而不是整个序列。
换句话说,更高的接受率可以带来更大的加速。在下一节中,我们将看到 DeepSeek 如何在推理中利用这项技术的更多细节。
评估
在 [2] 中,作者评估了他们的多令牌预测策略对训练和推理阶段的影响。
对训练性能的影响
为了评估他们的多令牌预测策略是否能有利于模型训练,[2] 的作者在两个不同规模的 MoE 模型上进行了实验:
- 一个较小的 15.7B 模型,激活参数为 2.4B,在下表中以蓝色突出显示;
- 一个较大的 228.7B 模型,激活参数为 20.9B,在下表中以绿色突出显示。
 图 4. 多令牌预测对训练性能的影响。图片由作者根据 [2] 中的表格创建。
图 4. 多令牌预测对训练性能的影响。图片由作者根据 [2] 中的表格创建。
【译注:原文的图不对,这是我从论文中截取的图。】
在这两个模型上,他们比较了原始模型和额外增加了 MTP 模块的变体之间的模型性能,并保持其他设置相同。在这个实验中,MTP 模块在推理时被简单地丢弃,因此推理时间没有差异。
根据上表中的结果,在两种设置下,添加 MTP 都能在多个任务中带来整体更好的性能,这证明了所提出的 MTP 策略的有效性。
对推理效率的影响
正如我们之前提到的,在推理时,除了完全丢弃 MTP 模块外,我们还可以将它们与推测解码结合使用以加速推理过程。
在 [2] 中,作者通过 MTP 技术实验性地预测了接下来的 2 个令牌,并将其与推测解码相结合,他们观察到第二个令牌预测的接受率约为 85% 到 90%,这表明他们的 MTP 策略的生成质量始终可靠。
更重要的是,在如此高的接受率下,将 MTP 与推测解码相结合,可以使推理速度提高 1.8 倍(以每秒令牌数 TPS 衡量)。
总结
本文探讨了多令牌预测,这是 DeepSeek 的另一个关键架构创新,着重介绍了它在文本生成中平衡效率与质量的方法。
所有这些架构创新构成了 DeepSeek 模型的基础,使其既高效又强大:
- 多头潜在注意力(Multi-head Latent Attention):优化内存使用,同时在解码过程中保持模型性能。
- DeepSeekMoE:在专家混合(MoE)架构中,在知识共享和专家专业化之间取得了更好的平衡。
- 无辅助损失负载均衡(Auxiliary-Loss-Free Load Balancing):确保有效的负载均衡,而不会损害主要的训练目标。
主要收获:
- 大型语言模型训练仍然存在许多开放性问题,引入新技术往往会导致意想不到的负面影响。
- 应对这些挑战需要对现象进行彻底分析,并深入理解其内部机制。
- 解决方案不一定总是复杂的——有时,简单的策略也能出奇制胜。
这也结束了我们对架构创新的讨论。在下一篇文章中,我们将探讨 DeepSeek 模型的训练策略,深入研究预训练、微调和对齐阶段的关键设计选择。
参考文献
- [1] DeepSeek
- [2] DeepSeek-V3 Technical Report
- [3] Better & Faster Large Language Models via Multi-token Prediction
- [4] Fast Inference from Transformers via Speculative Decoding
- [5] Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation
- 显示Disqus评论(需要科学上网)