本文翻译DeepSeek Explained 5: DeepSeek-V3-Base。
这是一个关于 DeepSeek 系列的第五篇文章,也是第一篇聚焦 DeepSeek-V3 [1, 2] 训练过程的文章。
如下图所示,DeepSeek-V3 的训练分为多个阶段,包括:
- 预训练阶段 此阶段产出 DeepSeek-V3-Base。
- 基于 DeepSeek-V3-Base 的训练 DeepSeek-R1-Zero 和 DeepSeek-R1 是在 DeepSeek-V3-Base 的基础上训练而成的,它们探索了大规模强化学习,其中 DeepSeek-R1 采用了有监督微调作为冷启动。
- 后续阶段 DeepSeek-R1 随后被用于在 DeepSeek-V3 的有监督微调阶段生成推理数据,紧接着是一个图中未描绘的强化学习阶段。
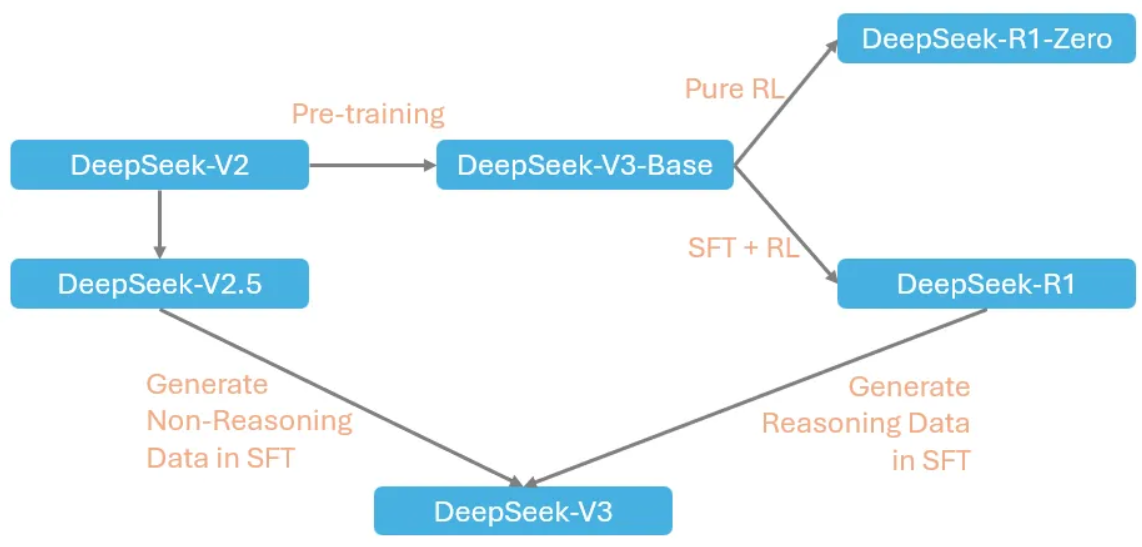 图 1. DeepSeek-V3 训练工作流。图片由作者提供。
图 1. DeepSeek-V3 训练工作流。图片由作者提供。
本文将特别关注产出 DeepSeek-V3-Base 的预训练阶段,解释该阶段所涉及的关键技术,以使预训练既有效又高效。
之后,我们将转向其他主题,包括分组相对策略优化 (GRPO) [7]、DeepSeek-R1-Zero 和 DeepSeek-R1 的训练方式,最后回到 DeepSeek-V3 的后期训练阶段,即有监督微调阶段和强化学习阶段。
目录
背景
在本节中,我们将介绍 DeepSeek-V3 预训练中使用的几种技术,包括文档打包(document packing)、中间填充(Fill-in-the-Middle, FIM)以及使用 YaRN 进行长上下文扩展。
文档打包
要理解为什么我们需要文档打包,让我们回顾一下 Transformer 模型是如何构建其输入序列令牌的。
Transformer 模型默认要求固定长度的令牌序列作为输入,然而同一批次中的输入文本通常长度不同。为了适应这种情况,文本输入通常需要经过以下预处理步骤:
- 分词:将每个原始文本输入转换为一个令牌序列。
- 截断或填充:截断或填充到预定义的固定长度(max_seq_len)。如果原始序列过长,则截断它;否则,用特殊的
[PAD]令牌填充。 - 生成掩码 ID:以便模型在训练期间可以忽略填充令牌。
为了更清楚地说明这一点,下面是一个示例,我们使用 GPT-2 [10] 分词器处理两个句子:
from transformers import AutoTokenizer
# Load a tokenizer (GPT-2 example)
tokenizer = AutoTokenizer.from_pretrained("gpt2", padding_side="right")
# Manually set a padding token (GPT-2 does not have one by default)
tokenizer.pad_token = tokenizer.eos_token
# Example input sequences
prompt = ["The cat sat on a mat",
"I love machine learning but do not have time to read papers"
]
# Tokenize and pad to max length of 10
tokenized = tokenizer(prompt, return_tensors="pt", padding="max_length", truncation=True, max_length=10)
# Print tokenized input
print("Input IDs:\n", tokenized["input_ids"])
print("Attention Mask:\n", tokenized["attention_mask"])
运行上述脚本后,我们会得到以下输出,其中:
- 第一句话被填充了 4 个额外的填充令牌,这在
input_ids和mask_ids中都可以看到; - 第二句话被截断了,所以没有添加填充令牌。
 图 2. 填充示例。图片由作者创建。
图 2. 填充示例。图片由作者创建。
上述截断和填充方法使模型能够处理不同长度的输入,但当输入序列长度差异过大时(这在 LLM 训练中相当常见)也会导致问题:
- 对于过长的序列,有用的信息可能会因截断而丢失;
- 对于短序列,用过多的额外令牌填充是计算资源的浪费。
因此,LLM 训练通常采用文档打包(document packing)技术来处理输入序列。
更具体地说,给定几个不同长度的文档,我们首先将它们分割成更小的块,如下图所示,其中每个文档用不同的颜色表示:
 图 3. 文档分割。图片根据 [3] 编辑。
图 3. 文档分割。图片根据 [3] 编辑。
然后,我们将来自不同文档的块连接起来,以避免长文档被截断和短文档被填充:
 图 4. 传统拼接。图片根据 [3] 编辑。
图 4. 传统拼接。图片根据 [3] 编辑。
在上面的例子中:
- 第一个输入只包含来自文档 1 的令牌。
- 第二个输入是文档 1 和文档 2 的令牌拼接。
- 第三个输入是文档 2 和文档 3 的令牌拼接。
- 第四个输入是文档 3、文档 4 和文档 5 的令牌拼接。
虽然这种方法在一定程度上消除了填充和截断的需要,但它只是根据文档在数据中的相对顺序简单地拼接来自不同文档的块,因此无法控制最终输入序列的构建方式。
例如,文档 3(紫色)被截断成了两部分,而实际上它的长度可以完全适应 max_seq_len,从而导致不必要的截断。
为了解决这个问题,[3] 提出了一种最佳拟合打包(Best-fit Packing)技术,可以通过以下两个步骤完全消除不必要的截断,如下图所示:
步骤 1:将每个文档分割成更小的块。 步骤 2:以智能方式将块分组到训练序列中,从而生成最少数量的序列,而无需进一步拆分任何块。
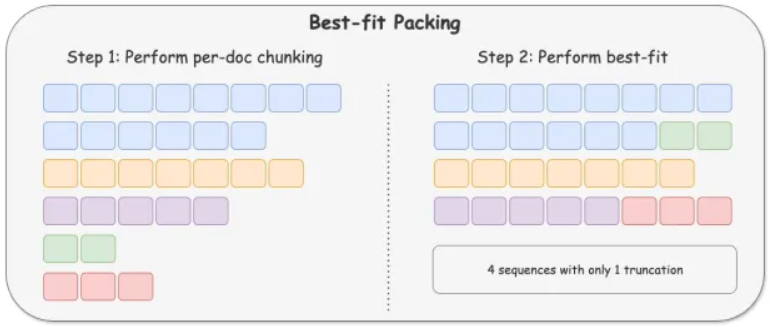 图 5. 最佳拟合打包。图片根据 [3] 编辑。
图 5. 最佳拟合打包。图片根据 [3] 编辑。
中间填充(Fill-in-the-Middle, FIM)
传统的自回归生成模型只以从左到右的方式进行训练,这意味着它们只能根据之前的令牌预测下一个令牌。然而,在许多实际应用中,模型可能需要在给定上下文的中间生成缺失的内容。
这在代码生成中尤其有用,因为我们经常向大型语言模型提供输入/输出以及一些代码片段,并要求它填充中间的逻辑,如下例所示:
def calculate_area(radius):
// calculate circle area given radius
return area
radius = 5
print(calculate_area(radius))
为了适应这种需求,[4] 提出了一种直接而有效的方法,称为中间填充(fill-in-the-middle)。它通过随机将文档分成三部分:前缀(prefix)、中间(middle)和后缀(suffix),然后将中间部分移到末尾:
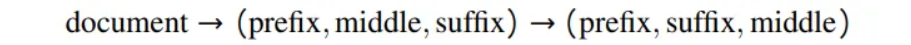
由于数据将组织成 Prefix-Suffix-Middle 的形式,这通常被称为 PSM 框架。这通常通过添加一组特殊令牌来标记每个组件的边界来实现:
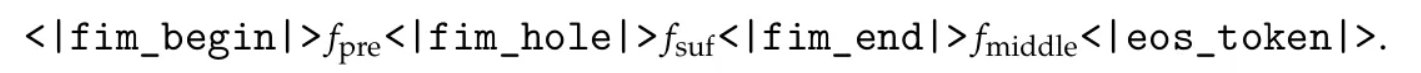
其中:
<|fim_begin|>和<|fim_hole|>标记前缀。<|fim_hole|>和<|fim_end|>标记后缀。<|fim_end|>和<|eos_token|>标记中间。
以以下输入为例:
def calculate_area(radius):
area = 3.14 * radius ** 2
return area
radius = 5
print(calculate_area(radius))
如果我们想让模型预测第二行,我们可以将该行作为中间部分,并构建 FIM 输入,如下所示:
 图 6. PSM 框架示意图。图片由作者创建。
图 6. PSM 框架示意图。图片由作者创建。
模型预期的输出应该是:
area = 3.14 * radius ** 2
使用 YaRN 扩展长上下文
现代大型语言模型(LLMs)通常需要处理极长的提示,例如整个代码仓库,但使用 128K 等长上下文窗口进行预训练是不切实际的。
相反,许多 LLMs 采用的常见策略是:首先在较小的上下文窗口上预训练模型,然后通过多个阶段逐步扩展到显著更长的上下文窗口。这可以显著减少训练工作量。
例如,在 DeepSeek-V3 中,模型首先使用 4K 的上下文窗口进行预训练,然后分两个阶段扩展到 128K:
- 从 4K 扩展到 32K,历时 1000 步。
- 从 32K 扩展到 128K,再历时 1000 步。
值得一提的是,这不能通过简单地将上下文窗口配置为更大的值来实现,相反,我们需要使用一种称为 Yet another RoPE extensioN (YaRN) 的技术对位置编码进行一些修改,该技术建立在旋转位置编码(Rotary Position Encoding, RoPE)之上。
关于 RoPE 的更详细介绍,请参阅我们之前的文章《DeepSeek-V3 解释 1:多头潜在注意力》。
RoPE 是一种相对位置编码方法,其核心思想是使用复杂的旋转嵌入修改 Query 和 Key,使它们的内积依赖于它们的相对位置:
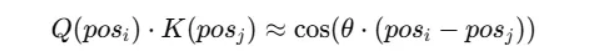
然而,在 $\theta$ 固定不变的情况下,一个用 1K 令牌预训练的模型在测试远超预训练上下文窗口的位置(例如 5K 或 10K)时可能会出现混淆,因为余弦和正弦函数是周期性的,$(pos_i, pos_j)$ 之间的内积可能与 $(pos_i, pos_k)$ 的内积相似。
这还会导致余弦值接近零的位置对的注意力分数衰减,使模型难以保持长距离的连贯性。
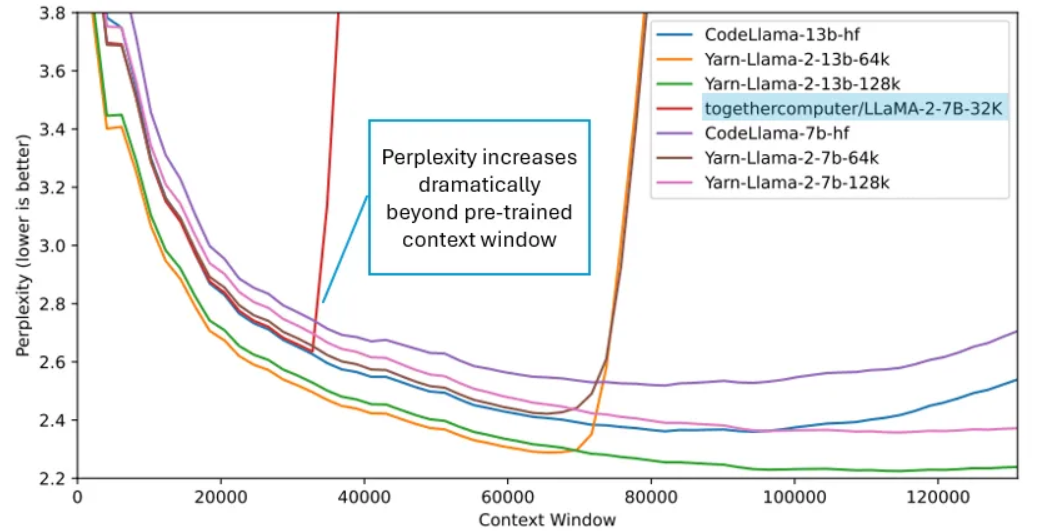
如下图所示,用 32K 上下文窗口预训练的模型在测试超出该窗口时,困惑度显著增加。
那么 YaRN 是如何应对这个挑战的呢?
由于外推法效果不佳,YaRN 采取了一种替代方法:内插频率。
假设我们有一个在 4 个令牌上训练的模型,并希望将其扩展到 8 个令牌,且基础频率 $\theta$ 为 0.5。
对于普通的 RoPE,我们简单地使用 $\cos(\theta \times \text{pos})$ 和 $\sin(\theta \times \text{pos})$ 来旋转 Query 和 Key。
然而,使用 YaRN 时:
- 我们首先使用扩展上下文长度除以原始长度来计算一个比例因子,在我们的例子中这个因子将是 2。
- 然后,我们得到一个新的频率,表示为 $\theta’$ = $\theta$ / 2 = 0.25。
- 接着,我们用这个新频率旋转 Query 和 Key,即使用 $\cos(\theta’ \times \text{pos})$ 和 $\sin(\theta’ \times \text{pos})$。
下图分别展示了 RoPE 和 YaRN 下的余弦和正弦值。
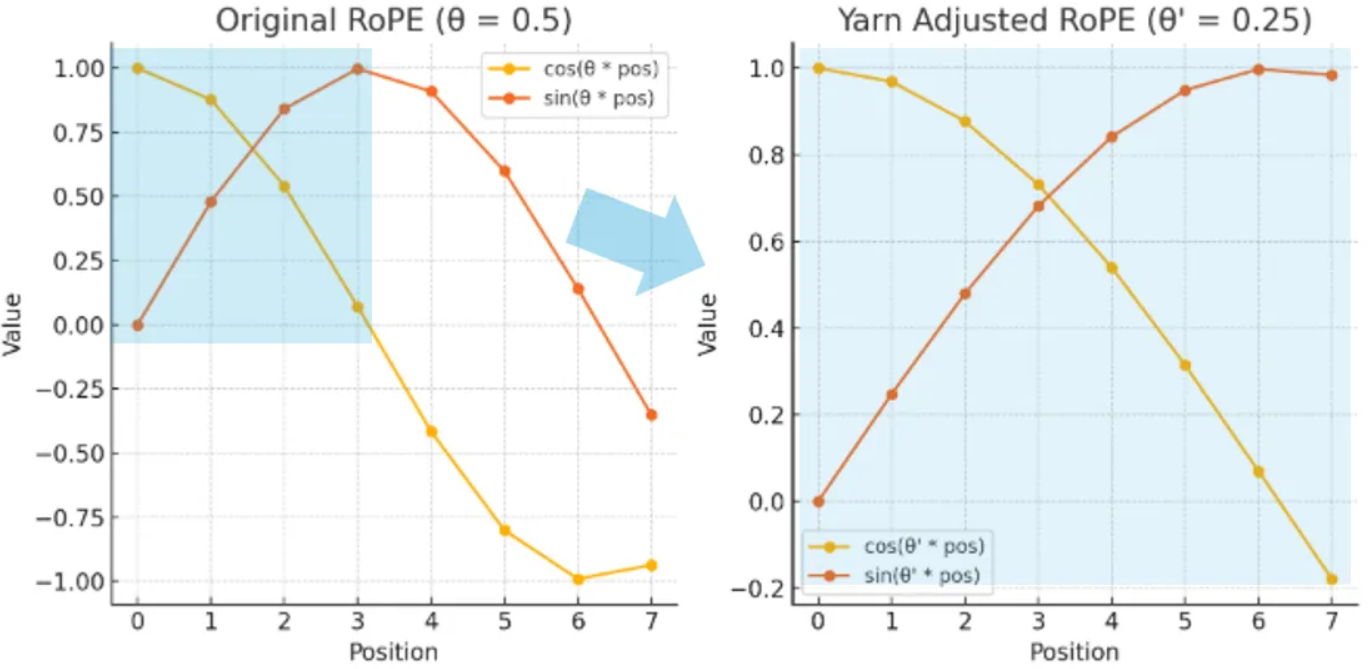 图 8. YaRN 工作原理示意图。图片由作者创建。
图 8. YaRN 工作原理示意图。图片由作者创建。
根据此图:
- 在 RoPE 中,余弦和正弦值随着位置索引的增加而快速振荡,导致难以扩展到更长的上下文。
- 在 YaRN 中,我们观察到一个更平滑的过渡,因为原始的余弦和正弦函数以缩放后的频率内插到扩展的上下文长度(参见蓝色高亮区域),从而使模型能够更有效地处理更长的序列。
下图显示了在“大海捞针”(Needle In A Haystack, NIAH)测试中进行的评估结果,展示了 DeepSeek-V3 在高达 128K 的所有上下文窗口长度下的性能。
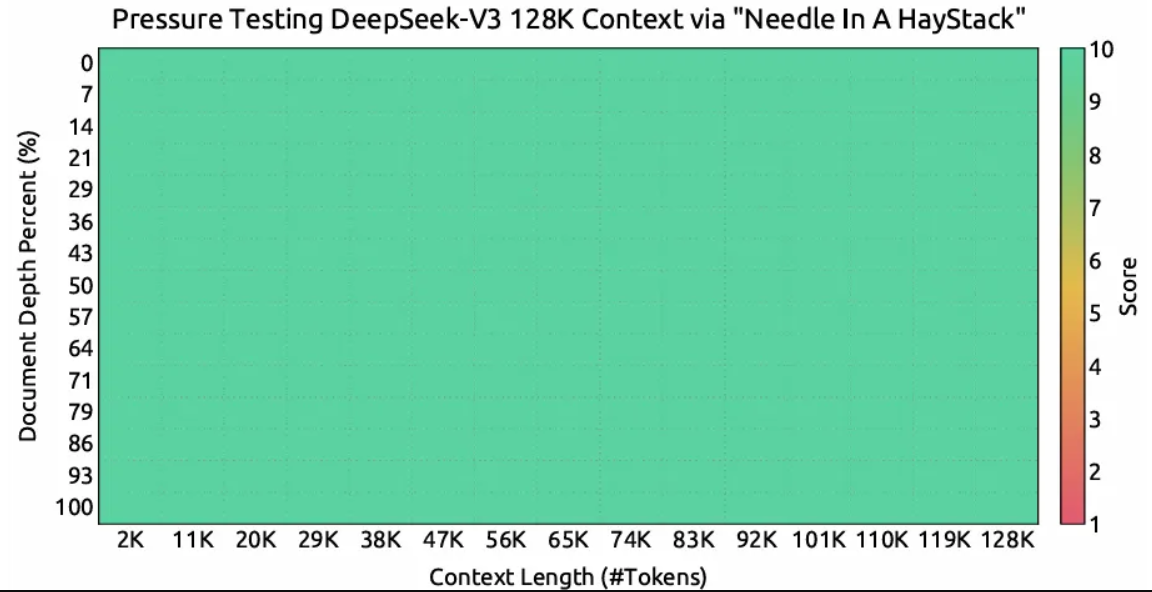 图 9. DeepSeek-V3 的“大海捞针”评估。图片来自 [2]。
图 9. DeepSeek-V3 的“大海捞针”评估。图片来自 [2]。
预训练
本节将介绍 DeepSeek-V3-Base 的训练方式。我们将特别关注数据构建并强调预训练中的一些关键策略。
数据构建
数据规模和质量对于大型语言模型(LLM)训练至关重要。在 DeepSeek-V3 中,预训练语料库通过利用从先前模型中获得的洞察力持续优化其数据语料库而构建:
- 在 DeepSeek 67B [8] 中,训练语料库采用去重-过滤-重组策略:首先对 Common Crawl 语料库进行严格去重,然后使用稳健的标准进行文档质量评估,最后进行数据重组阶段,重点解决数据不平衡问题。
- 在 DeepSeek-V2 [9] 中,通过 1) 添加更多中文数据和来自各种来源的高质量数据,以及 2) 通过优化数据清洗过程,恢复了 [8] 中先前删除的大量数据,从而扩大了训练语料库。通过改进基于质量的过滤算法,数据质量也得到了提升。
- 在 DeepSeek-V3 [2] 中,预训练语料库通过增加更多的数学和编程样本以及英语和中文之外的多语言样本得到了进一步丰富。
收集到的预训练语料库随后使用前面介绍的中间填充(FIM)策略和 Prefix-Suffix-Middle (PSM) 框架进行预处理,并结合文档打包(document-packing)技术。
训练
原始论文 [2] 详细描述了预训练参数,这里我们只强调几点:
- 长上下文扩展:首先在 14.8T 令牌上使用 4K 上下文窗口进行预训练,然后用 1000 步扩展到 32K,最后再用 1000 步扩展到 128K。
- 多令牌预测:正如我们在之前的文章《多令牌预测》中解释的那样,DeepSeek-V3 应用了优化版的多令牌预测,允许模型同时解码多个令牌,以加速训练中的解码过程。
- FP8 训练:DeepSeek-V3 采用混合精度算术来提高计算效率,通过对某些计算使用较低精度格式(例如 8 位浮点数),减少内存使用并加速计算,而不会显著影响准确性。
- 学习率调度:学习率在前 2K 步中从 0 线性增加到 2.2e–4,并在 10T 令牌的训练中保持不变。然后,学习率在 4.3T 令牌中遵循余弦曲线下降到 2.2e-5。在最后 500B 令牌的训练中,学习率在前 333B 令牌的训练中保持不变,然后在剩余的 167B 令牌中进一步下降到 7.3e-6。
- 批次大小调度:批次大小在前 469B 令牌的训练中从 3072 增加到 15360,然后在剩余的训练中保持不变。
评估
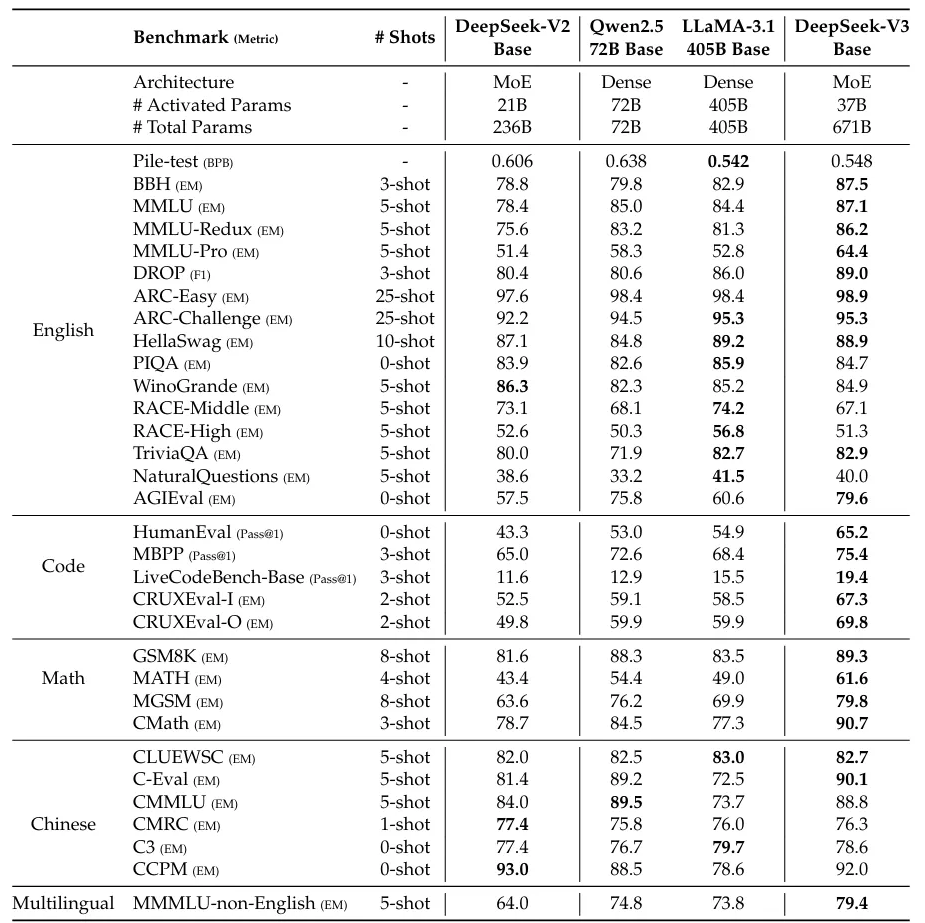
下表比较了 DeepSeek-V3 与其他几个开源基础模型在不同任务上的表现,其中 DeepSeek-V3 在大多数数据集上取得了最佳性能,尤其是在数学和编码相关任务上。
需要注意的是,DeepSeek-V3 的强大性能是在极高的训练效率下实现的,这归功于我们在本系列中介绍的所有创新。更具体地说,DeepSeek-V3 每训练万亿个令牌仅需 180K H800 GPU 小时,这比训练 72B 或 405B 密集模型要便宜得多。
原论文 [2] 还进行了全面的消融研究,以验证无辅助损失负载均衡和多令牌预测等关键创新。然而,由于我们已在之前的文章中讨论过这些主题,此处不再赘述。
总结
本文探讨了 DeepSeek-V3 预训练策略中的关键创新,旨在提升效率、可扩展性和性能。由此产生的 DeepSeek-V3-Base 模型为更高级的推理模型(如 DeepSeek-R1-Zero 和 DeepSeek-R1)奠定了基础,而这些模型反过来又通过知识蒸馏帮助改进 DeepSeek-V3。
除了先前讨论的架构创新——多头潜在注意力、DeepSeekMoE、无辅助损失负载均衡和多令牌预测——本文还介绍了文档打包、中间填充 (FIM) 以及使用 YaRN 进行长上下文扩展等技术。
所有这些技术共同推动了 LLM 效率和可扩展性的边界,为高性能 AI 模型树立了新的标杆。
参考文献
- [1] DeepSeek
- [2] DeepSeek-V3 Technical Report
- [3] Fewer Truncations Improve Language Modeling
- [4] Efficient Training of Language Models to Fill in the Middle
- [4] DeepSeek-Coder: When the Large Language Model Meets Programming — The Rise of Code Intelligence
- [5] DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence
- [6] YaRN: Efficient Context Window Extension of Large Language Models
- [7] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- [8] DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- [9] DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- [10] Language Models are Unsupervised Multitask Learners
- 显示Disqus评论(需要科学上网)