本文介绍Cycle GAN的原理和代码。更多文章请点击深度学习理论与实战:提高篇。
目录
Image to Image Tanslation简介
Image to Image Translation是把一张图片变换成另外一张相关图片。注意这是一个很模糊的定义。什么叫”相关”?我们随便拿两张照片然后说我们把一张照片变换成了另一种行不行?很显然是不行的。但是前面我们介绍的Neural Sytle Transfer可以看成是一种Image to Image Translation,因为变换后的图片保留了内容图片的内容和样式图片的样式。
这里我们会介绍 Cycle-Consistent Adversarial Networks(简称Cycle-GAN),下图是这个算法所作的一些变换。左边是把莫奈(Monet)的风景画转换成普通的风景照片以及把普通风景照片变换成莫奈风格的画。中间是实现斑马和普通的马相互变换。右边是实现夏天的风景画和动态的风景画的变换。下边和Neural Style Transfer类似,把输入风景画变换成莫奈(Monet)、梵高(Van Gogh)等人的风格。注意Cycle GAN和Neural Style Transfer的区别,Neural Style Transfer是把梵高的一张作品的风格混入另外一张内容图片,而Cycle GAN是通过多张梵高的作品学习到梵高的风格,然后把它混入内容图片。后面我们会对比Cycle GAN和Neural Style Transfer,因为单张梵高的作品确实有梵高的风格,但是也很容易学习到与风格无关的一些颜色等其他特征,而Cycle GAN通过多张画家的作品,学习到的是更加稳定的风格特征。
 图:Cycle GAN的示例
图:Cycle GAN的示例
这其实比Neural Sytle Tansfer更酷,可惜没有推广,有兴趣的读者可以尝试做个APP。
训练数据
Image to Image Translation的目的是根据训练数据学习一个映射(Mapping)函数,把输入图片映射成相关的输出图片。普通的Image to Image Transation模型和机器翻译类似,需要配对(pair)的训练数据,比如一张普通马的照片,还需要一张斑马的照片,而且要求它们内容是完全匹配的。比如图\ref{fig:cycle-gan-2}就是配对的训练数据,而图\ref{fig:cycle-gan-3}虽然有一张是斑马的,另外一张是普通马的,但是它们的背景,马的数量和外形都不同,因此不能算配对的数据。
 图:paired训练数据
图:paired训练数据
 图:unpaired训练数据
图:unpaired训练数据
要获得配对的数据是非常困难的,我们拍摄的时候不可能找到外形和姿势完全相同的斑马和普通马,包括相同的背景。另外给定一张梵高的作品,我们怎么找到与之配对的照片?或者反过来,给定一张风景照片,去哪找和它内容相同的艺术作品?
而本文介绍的Cycle GAN不要求有配对的训练数据,而只需要两个不同Domain的未标注数据集就行了。比如要把普通马变成斑马,我们只需要准备很多普通马的照片和很多斑马的照片,然后把所有斑马的照片放在一起,把所有的普通马照片放到一起就行了,这显然很容易。风景画变梵高风格也很容易——我们找到很多风景画的照片,然后尽可能多的找到梵高的画作就可以了。注意,这两个Domain内部的照片必须有一些共性的东西,比如都是斑马的照片,你不能把所有动物的照片都放进去然后期望它能学到斑马的特征。
基本原理
那CycleGAN是怎么通过未配对的数据学习到两个Domain的图片直接的Mapping的呢?本文的思想其实很简单,假设有两个集合X和Y,比如X是普通马,Y是斑马。我们首先使用GAN的方式,学习一个生成器(函数)$G: X \rightarrow Y$和一个判别器$D_Y$。生成器的目的就是生成的图片看起来很像Y中的图片(看起来像版本),而判别器就是判断它确实服从Y的分布(比如确实看起来像斑马)。
通过对抗训练,G可以生成斑马的照片。但是这有一个问题,给定一张普通马的照片,G生成的确实是斑马的照片,但是很可能这两张照片的”内容”完全没有任何关系。比如G可能是一个固定的函数,不过输入是什么样子的马(高的矮的胖的瘦的),我们都输出一张Y中概率最高的斑马照片,这样显然判别器$D_Y$分不出这是生成的还是真的。但这样的映射函数G并没有什么意义。怎么解决这个问题呢?CycleGAN又增加了反过来从Y到X的生成器函数$F: Y \rightarrow X$和判别器$D_X$。一张普通马的照片,首先需要经过G把它变成斑马,使得$D_Y$看起来确实是斑马;然后用F把斑马变成马,使得$D_X$看起来它确实是普通马。最后还会加上内容的约束——两次变换回来的马和原来的马要尽量像。
有了上面的约束之后,我们的G就不可能把普通马映射成与输入内容不像的斑马了,因为如果不像,F映射回去肯定更加不像。这样我们学习的G不但要求看起来像斑马,而且内容和原来也要相同。
因为对称性,为了充分利用数据,我们也加入反过来的损失,也就是斑马映射成普通马的函数F。这样我们一次性学习到两个生成函数G和F,前者学习怎么把普通马变成斑马;而后者学习怎么把斑马变成普通马。
形式化描述
下面我们用数学语言更加形式化的描述CycleGAN的原理和具体实现方法。我们的目标是在两个Domain X和Y之间学习映射函数,我们有属于X的训练数据集\(\{x_i\}_{i=1}^N, x_i \in X\)和属于Y的训练数据集\(\{y_j\}_{j=1}^M, y_j \in Y\)。如下图a中所示,我们需要学习两个映射$G: X \rightarrow Y$和$F: Y \rightarrow X$。此外为了进行对抗训练,我们会引入两个判别函数$D_Y$和$D_X$。其中$D_Y$学会区分Y中的”真实”数据和G(x)变换得到的”伪造”数据;而$D_X$学习区分”真实”的X中的数据和”伪造”的F(y)。
接下来我们介绍两种Loss:Adversarial Loss和Cycle Consistency Loss。前者是让生成器确实能生成斑马的数据;而后者保证生成的斑马在”内容”上和原来的普通马是一样的。
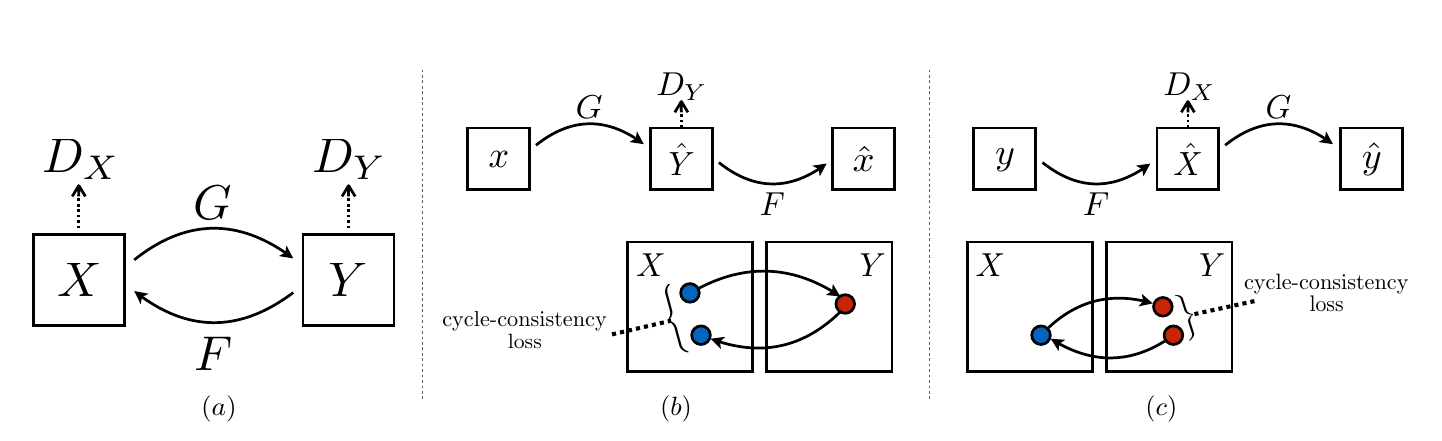 图:Cycle GAN
图:Cycle GAN
Adversarial Loss
Adversarial Loss和标准的GAN完全一样:
\[\mathcal{L}_{GAN}(G, D_Y, X, Y)=\mathbb{E}_{y \sim p_{data}(y)} [logD_Y(y)] + \mathbb{E}_{x \sim p_{data}(x)} [1-logD_Y(G(x))]\]G的目标是生成能以假乱真的很像属于Y的照片,而$D_Y$的目标是能够判断图片是真实的Y中的还是有G伪造出来的。G的目标是让Loss变小,它可以做的就是使得生成的G(x)很像,从而$logD_Y(G(x)$很大,$[1-logD_Y(G(x))]$很小,从而使得最终Loss变小。而$D_Y$要和它唱对台戏,它的目的是让Loss变大,因此它要做的就是对于真实的y,$D_Y(y)$尽量大;而伪造的$G(x)$,$logD_Y(G(x))$尽量小,从而$1-logD_Y(G(x))$尽量大。
因此用数学语言来描述就是$min_Gmax_{D_Y} \mathcal{L}_{GAN}(G, D_Y, X, Y)$。
类似的,我们可以定义$\mathcal{L}_{GAN}(F, D_X, Y, X)$:
\[\mathcal{L}_{GAN}(F, D_X, Y, X)=\mathbb{E}_{x \sim p_{data}(x)} [logD_X(x)] + \mathbb{E}_{y \sim p_{data}(y)} [1-logD_X(F(y))]\]Cycle Consistency Loss
前面说过了,如果只有Adversarial Loss,那么模型完全可以记住Y中的所有照片,对于任意的输入x,G(x)随机的从Y中挑选一张照片,那么$D_Y$肯定认为这是真的照片,这显然是不行的。为了解决这个问题,如上图b所示,对于输入x,我们首先用G(x)把它映射到Y中,然后再用F(G(x))把他映射回来,我们期望$x \approx F(G(x))$,类似的有$y \approx G(F(y))$。因此我们定义如下的Loss:
\[\mathcal{L}_{cyc}=\mathbb{E}_{x \sim p_{data}(x)} [\left\lvert x - F(G(x)) \right\lvert_1] + \mathbb{E}_{y \sim p_{data}(y)} [\left\lvert y - G(F(y)) \right\lvert_1]\]完整的Loss
因此完整的Loss为:
\[\mathcal{L}(G, F, D_X, D_Y)=\mathcal{L}_{GAN}(G, D_Y, X, Y) + \mathcal{L}_{GAN}(F, D_X, Y, X) + \lambda \mathcal{L}_{cyc}(G, F)\]通过对抗训练,我们最终得到: \(F^*, G^*=\underset{G,F}{argmin} \underset{D_X,D_Y}{max}\mathcal{L}(G, F, D_X, D_Y)\)
另外在实际的对抗训练中,负log似然非常不稳定,因此在实际代码中通常用MSE替代它。 因此在训练G的时候,实际的损失函数是\(\mathbb{E}_{x \sim p_{data}(x)} [(1-D_Y(G(x)))^2]\);而训练$D_Y$时实际的损失函数是\(\mathbb{E}_{y \sim p_{data}(y)} [(1-D_Y(y))^2] + \mathbb{E}_{x \sim p_{data}(x)} [D(G(x))^2]\)。训练F和$D_X$也是类似的。
和Neural Style Transfer的区别
Neural Style Transfer可以认为是把Style Image的风格加入到Content Image里。因为只有一张Style Image,所以它其实学到的很难完全是Style的特征,因为一个画家的风格很难通过一幅作品就展现出来。
如下图所示,第一列是原始内容图片,第二列是使用画家的作品做Neural Style Transfer得到的图片,第三列是使用另一幅作品做的Neural Style Transfer得到的结果,第四列是把画家的所有作品”平均”后再变换的结果,最后一列是CycleGAN的结果。
因为Neural Style Transfer只能输入一张Style图片,因此为了学习画家的所有作品,只能把这些作品做”平均”。以第一行梵高的风格为例,Neural Style Transfer确实也能学到一些风格特征,但是它也带人了很多非风格的特征,比如第二列明显带人了蓝色的特征,我们总不能说梵高的风格是蓝色吧,只不过那份画有蓝色,然后被Neural Style Transfer错误的认为是作者的风格。第三列也是类似,因为Style图片有红色,所有得到的变换图片也有红色。而平均之后同意不能避免把颜色等非风格特征混入的问题。而CycleGAN能够很好的从梵高的多个作品中学习到他的真正风格特征,因为颜色这样的特征并不是在每幅画都出现的,如果梵高每次作画都用同一种颜色(比如中国画家都是水墨),那么把这种颜色看成风格也是没有问题的。
 图:Cycle GAN和Neural Style Transfer的比较
图:Cycle GAN和Neural Style Transfer的比较
代码
作者提供了PyTorch和Torch的实现,我们这里介绍PyTorch的代码。我们这里以斑马和普通马的转换为例,读者也可以尝试其他数据集。
运行
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
安装Pytorch 0.4.0+
下载数据
bash datasets/download_cyclegan_dataset.sh horse2zebra
# 在GPU上大概需要训练一两天
python train.py --dataroot ./datasets/horse2zebra --name horse2zebra_cyclegan --model cycle_gan
# 预测
python test.py --dataroot ./datasets/horse2zebra --name horse2zebra_cyclegan --model cycle_gan
最终预测的结果在results/horse2zebra_cyclegan/test_latest里。用浏览器打开index.html就能看到类似如下图的结果。
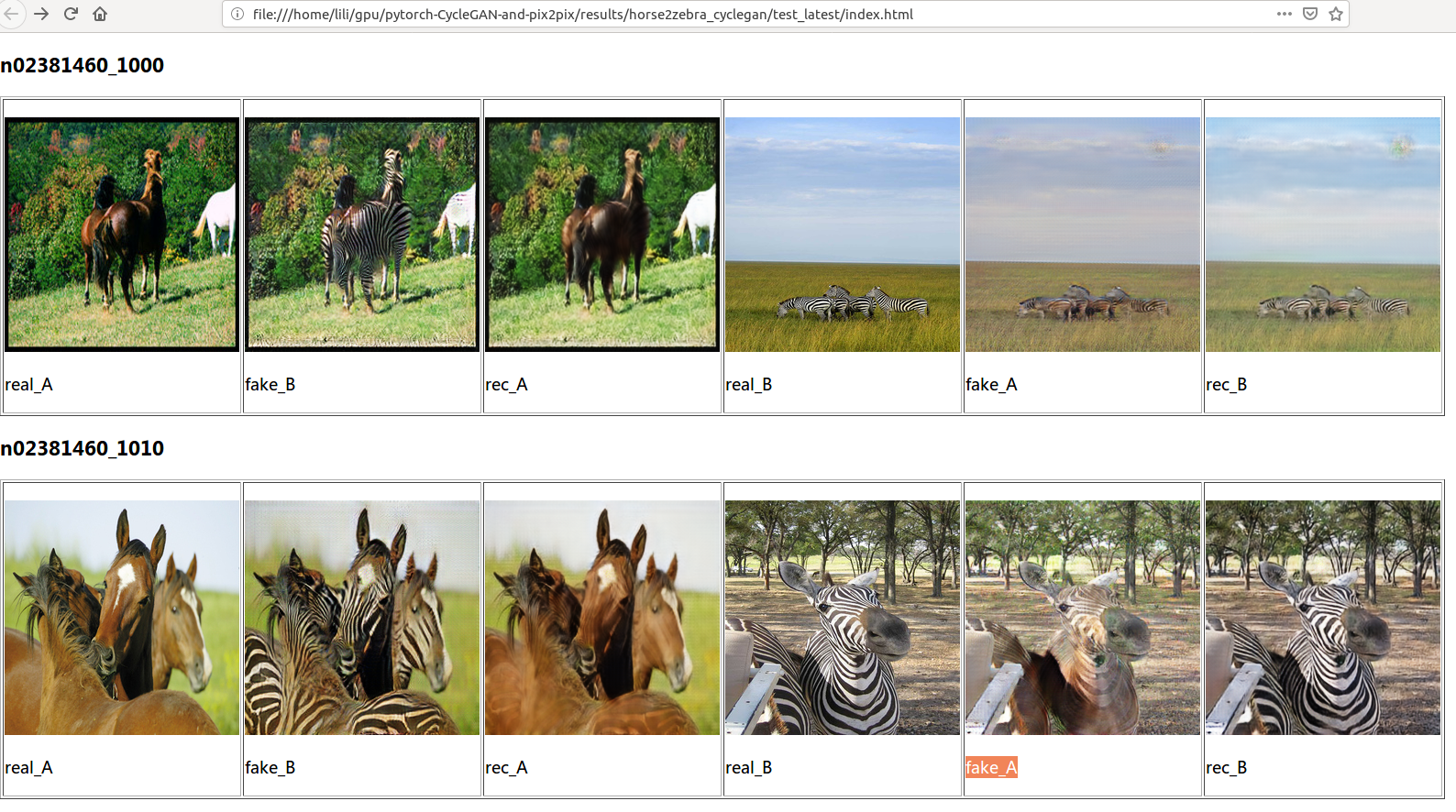 图:Cycle GAN测试结果
图:Cycle GAN测试结果
代码简介
这里会非常简单的介绍最核心的部分代码,完整代码请读者自行阅读,也可以参考博客文章,这是一个Tensorflow的实现,这个blog文章介绍了它的实现过程。
训练的代码首先调用create_model函数创建Model,最终调用到CycleGANModel类的initialize方法来构造网络结构。下面是initialize主要的代码(去掉了不相关的部分):
class CycleGANModel(BaseModel):
def initialize(self, opt):
BaseModel.initialize(self, opt)
# 定义网络
# 这里的命名和论文有些不同
# 代码 (论文): G_A (G), G_B (F), D_A (D_Y), D_B (D_X)
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc,
opt.ngf, opt.which_model_netG, opt.norm,
not opt.no_dropout, opt.init_type, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc,
opt.ngf, opt.which_model_netG, opt.norm,
not opt.no_dropout, opt.init_type, self.gpu_ids)
if self.isTrain:
use_sigmoid = opt.no_lsgan
self.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.which_model_netD,
opt.n_layers_D, opt.norm, use_sigmoid, opt.init_type, self.gpu_ids)
self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.which_model_netD,
opt.n_layers_D, opt.norm, use_sigmoid, opt.init_type, self.gpu_ids)
if self.isTrain:
self.fake_A_pool = ImagePool(opt.pool_size)
self.fake_B_pool = ImagePool(opt.pool_size)
# 定义损失函数
self.criterionGAN = networks.GANLoss(use_lsgan=not opt.no_lsgan,
tensor=self.Tensor)
self.criterionCycle = torch.nn.L1Loss()
self.criterionIdt = torch.nn.L1Loss()
# 初始化optimizers
self.optimizer_G = torch.optim.Adam(itertools.chain(self.netG_A.parameters(),
self.netG_B.parameters()),
lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(itertools.chain(self.netD_A.parameters(),
self.netD_B.parameters()), lr=opt.lr,
betas=(opt.beta1, 0.999))
self.optimizers = []
self.schedulers = []
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
for optimizer in self.optimizers:
self.schedulers.append(networks.get_scheduler(optimizer, opt))
首先是定义两个Generator G_A和G_B(论文里是G和F),接下来定义两个Discriminator D_A和D_B(论文是$D_Y$和$D_X$)。接下来定义两个ImagePool,论文里提到,为了稳定的训练,伪造的图像会随机的从最近N(50)个steps里随机选择。这个ImagePool就是用来存储生成器伪造的图像,因为有两个生成器G_A和G_B,因此ImagePool也有两个。接下来就是定义损失函数和优化器,这都是常规的代码。
这里最主要的两个函数就是定义生成器的函数networks.define_G以及定义判别器的函数networks.define_D。下面我们简要的来看看这两个函数,define_G最终(默认参数)会调用到ResnetGenerator,这是一个Module,它的代码为:
class ResnetGenerator(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d,
use_dropout=False, n_blocks=6, padding_type='reflect'):
super(ResnetGenerator, self).__init__()
self.input_nc = input_nc
self.output_nc = output_nc
self.ngf = ngf
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
model = [nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0,
bias=use_bias),
norm_layer(ngf),
nn.ReLU(True)]
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3,
stride=2, padding=1, bias=use_bias),
norm_layer(ngf * mult * 2),
nn.ReLU(True)]
mult = 2**n_downsampling
for i in range(n_blocks):
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
use_dropout=use_dropout, use_bias=use_bias)]
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
norm_layer(int(ngf * mult / 2)),
nn.ReLU(True)]
model += [nn.ReflectionPad2d(3)]
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
model += [nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input):
return self.model(input)
代码有点长,但是并不复制,首先是一个padding+7x7卷积+norm+relu,接下来使用stride为2的3x3卷积(也包括norm和relu)进行下采样,每次是图片尺寸缩小一倍。接下来是几个参差块,它不改变图片尺寸。然后就是上采样,它使用ConvTranspose2d,每次使得图片尺寸放大一倍,上采样和下采样是一样多的,这样生成的图片和输入的图片是一样的大小。最后再加上一个7x7的卷积层,最后的激活是tanh,因为需要输出的范围是(-1,1)(注意,输入的范围一上来也变换到了这个范围内)。
network.define_D函数最终会调用到NLayerDiscriminator,它的代码为:
class NLayerDiscriminator(nn.Module):
def __init__(self, input_nc, ndf=64, n_layers=3,
norm_layer=nn.BatchNorm2d, use_sigmoid=False):
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4
padw = 1
sequence = [
nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
nn.LeakyReLU(0.2, True)
]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers):
nf_mult_prev = nf_mult
nf_mult = min(2**n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult,
kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2**n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult,
kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)]
if use_sigmoid:
sequence += [nn.Sigmoid()]
self.model = nn.Sequential(*sequence)
def forward(self, input):
return self.model(input)
这里代码就非常直接了,都是卷积。因为判别器最后需要输出一个概率值,这里没有使用通常的把卷积展开,然后接全连接层的做法,而是直接用卷积实现同样的功能,sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)],最后一个卷积输出的feature map是1,并且卷积核的大小等于输入的大小,这输出就是一个值了。下面是G_A和D_A的详细信息:
DataParallel(
(module): ResnetGenerator(
(model): Sequential(
(0): ReflectionPad2d((3, 3, 3, 3))
(1): Conv2d(3, 64, kernel_size=(7, 7), stride=(1, 1))
(2): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(6): ReLU(inplace)
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(8): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(9): ReLU(inplace)
(10): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(11): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(12): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(13): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(14): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(15): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(16): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(17): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(18): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace)
(4): Dropout(p=0.5)
(5): ReflectionPad2d((1, 1, 1, 1))
(6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(7): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(19): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(20): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(21): ReLU(inplace)
(22): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(23): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(24): ReLU(inplace)
(25): ReflectionPad2d((3, 3, 3, 3))
(26): Conv2d(64, 3, kernel_size=(7, 7), stride=(1, 1))
(27): Tanh()
)
)
)
DataParallel(
(module): NLayerDiscriminator(
(model): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.2, inplace)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(3): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(4): LeakyReLU(negative_slope=0.2, inplace)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(7): LeakyReLU(negative_slope=0.2, inplace)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(9): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(10): LeakyReLU(negative_slope=0.2, inplace)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
)
)
)
创建完了模型之后就是for循环的训练,其实核心的就是下面这段:
for epoch in range(opt.epoch_count, opt.niter + opt.niter_decay + 1):
for i, data in enumerate(dataset):
model.optimize_parameters()
我们来看model.optimize_parameters()。
def optimize_parameters(self):
self.forward()
# G_A and G_B
self.optimizer_G.zero_grad()
self.backward_G()
self.optimizer_G.step()
# D_A and D_B
self.optimizer_D.zero_grad()
self.backward_D_A()
self.backward_D_B()
self.optimizer_D.step()
这个函数分别训练G(G_A和G_B),D_A和D_B。
def backward_G(self):
lambda_idt = self.opt.lambda_identity
lambda_A = self.opt.lambda_A
lambda_B = self.opt.lambda_B
# Identity loss
if lambda_idt > 0:
# G_A should be identity if real_B is fed.
self.idt_A = self.netG_A(self.real_B)
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
# G_B should be identity if real_A is fed.
self.idt_B = self.netG_B(self.real_A)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
else:
self.loss_idt_A = 0
self.loss_idt_B = 0
# GAN loss D_A(G_A(A))
self.fake_B = self.netG_A(self.real_A)
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
# GAN loss D_B(G_B(B))
self.fake_A = self.netG_B(self.real_B)
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# Forward cycle loss
self.rec_A = self.netG_B(self.fake_B)
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss
self.rec_B = self.netG_A(self.fake_A)
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A +
self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
self.loss_G.backward()
和论文稍微不同,这里还加了一个Identity Loss,什么意思呢?比如G是从X到Y的映射,我们给定普通马,它生成斑马。但是如果我给你斑马呢?你还是应该生成完全一样的斑马。因此有代码:
# 输入斑马
self.idt_A = self.netG_A(self.real_B)
# 输出idt_A应该尽量和输入real_B相同
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
接下来是GANLoss和CycleLoss,代码都非常直观。
然后是训练D_A,代码为:
def backward_D_A(self):
# 从fake Pool里找伪造的图片
fake_B = self.fake_B_pool.query(self.fake_B)
# 计算loss,代码下面介绍。
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
上面的backward_D_A会调用backward_D_basic,其代码为:
def backward_D_basic(self, netD, real, fake):
# Real
pred_real = netD(real)
loss_D_real = self.criterionGAN(pred_real, True)
# Fake
pred_fake = netD(fake.detach())
loss_D_fake = self.criterionGAN(pred_fake, False)
# Combined loss
loss_D = (loss_D_real + loss_D_fake) * 0.5
# backward
loss_D.backward()
return loss_D
这是计算判别器D_A或者D_B的梯度的函数。分为两部分,第一部分是真实(real)的损失;第二部分是伪造(fake)的损失。代码都非常直观,唯一需要注意的是”pred_fake = netD(fake.detach())”。real不需要detach,二fake需要detach呢?因为real是直接从文件读取的输入的tensor,而fake是用G(或者F)生成的,如果不detach,那么梯度会传播到G或者F里,这显然不是想要的结果,因为我们这里求D的loss只是为了更新判别器的参数而不是生成器的参数,生成器的参数在前面已经更新过了。
- 显示Disqus评论(需要科学上网)