本文主要介绍流行的开源语音识别工具Kaldi的基本用法。更多文章请点击深度学习理论与实战:提高篇。阅读本文需要理解基于HMM-GMM和HMM-DNN的语音识别框架的基本原理,了解基于WFST的解码器。另外这里也假设读者已经安装了Kaldi,详细的安装请参考Kaldi官网文档。
目录
- 简介
- thchs30示例
- cmd.sh
- path.sh
- 数据
- kaldi的数据格式
- text文件
- wav.scp文件
- segments文件
- utt2spk
- spk2utt
- feats.scp文件
- cmvn.scp
- phones.txt
- words.txt
- L.fst和L_disambig.fst
- oov.txt和oov.int
- lexicon.txt或者lexiconp.txt
- data/lang/topo
- data/lang/phones/目录
- 准备text,wav.scp,utt2spk文件
- 提取MFCC特征
- 准备data/lang
- 训练monophone模型
- 用monophone模型对齐
- 训练triphone模型
- lda_mllt
- sat
- quick
- quick align
- 训练dnn模型
- PyTorch-Kaldi
简介
Kaldi是当前最流行的开源语音识别工具(Toolkit),它使用WFST来实现解码算法。Kaldi的主要代码是C++编写,在此之上使用bash和python脚本做了一些工具。
Kaldi架构如下图所示,最上面是外部的工具,包括用于线性代数库BLAS/LAPACK和我们前面介绍过的OpenFst。中间是Kaldi的库,包括HMM和GMM等代码,下面是编译出来的可执行程序,最下面则是一下脚本,用于实现语音识别的不同步骤(比如特征提取,比如训练单因子模型等等)。
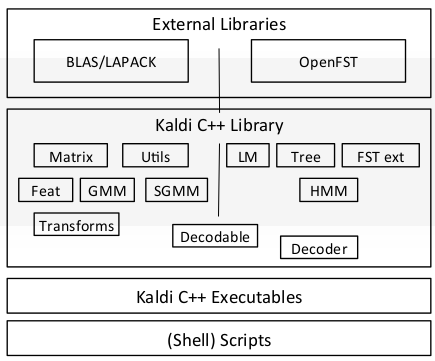 图:Kaldi架构
图:Kaldi架构
对应大部分Kaldi的用户来说,我们只需要使用脚本和配置文件就可以完成语音识别系统的训练和预测了。因此这里只介绍脚本和配置文件,但是实际要使用它来预测的话,需要了解其源代码,有兴趣读者可以自行阅读。
下面我们通过thchs30的例子来介绍Kaldi的用法,thchs30是一个较小的开源中文语料库。
thchs30示例
进入kaldi/egs/thchs30/s5。kaldi主要用脚本来驱动,每个recipe下会有很多脚本。local目录下的脚本通常是与这个example相关,不能移植到别的例子,通常是数据处理等“一次性”的脚本。而util下的脚本是通用的一些工具。steps是训练的步骤,最重要的脚本。我们这里主要介绍数据准备相关的脚本,而训练的脚本我们只是简单列举出来,有兴趣的读者可以阅读这些脚本代码。
cmd.sh
如果是使用单机来训练,我们需要把queue.pl改成run.pl。修改的内容如下:
$diff cmd.sh
-export train_cmd=queue.pl
-export decode_cmd="queue.pl --mem 4G"
-export mkgraph_cmd="queue.pl --mem 8G"
-export cuda_cmd="queue.pl --gpu 1"
+export train_cmd=run.pl
+export decode_cmd="run.pl --mem 4G"
+export mkgraph_cmd="run.pl --mem 8G"
+export cuda_cmd="run.pl --gpu 1"
path.sh
这个脚本执行后会修改一些环境变量,包括export LC_ALL=C,因为很多kaldi的工具需要数据是排序的,而排序需要用C语言字符串顺序。
数据
我们需要设定下载的thchs30数据存放的路径,可以在run.sh脚本里修改。比如作者修改的路径为:
thchs=/home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr
然后注释掉下面的代码:
#[ -d $thchs ] || mkdir -p $thchs || exit 1
#echo "downloading THCHS30 at $thchs ..."
#local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 data_thchs30 || exit 1
#local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 resource || exit 1
#local/download_and_untar.sh $thchs http://www.openslr.org/resources/18 test-noise || exit 1
我们先看一下原始数据是什么样子的。原始的wav文件和transcript文件都在thchs30-openslr/data下。比如A11_1.wav是一个录音文件,而A11_1.wav.trn就是对应的transcript文件。我们可以看看这个文件的内容:
1 他 仅 凭 腰部 的 力量 在 泳道 上下 翻腾 蛹 动 蛇行 状 如 海豚 一直 以 一头 的 优势 领先
2 ta1 jin3 ping2 yao1 bu4 de5 li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi4 tou2 de5 you1 shi4 ling3 xian1
3 t a1 j in3 p ing2 ii iao1 b u4 d e5 l i4 l iang4 z ai4 ii iong3 d ao4 sh ang4 x ia4 f an1 t eng2 ii iong3 d ong4 sh e2 x ing2 zh uang4 r u2 h ai3 t un2 ii i4 zh ix2 ii i3 ii i4 t ou2 d e5 ii iu1 sh ix4 l ing3 x ian1
第一行是文本,分过词,第二行是每个字的拼音,而第三行是分解成音素。除了data目录,还有train、dev和test三个目录,它们把data目录的文件分成训练集、验证集和测试集。
kaldi的数据格式
kaldi需要的“原始”数据主要分为两部分,一部分是”data”相关的数据,通常在data/train下,另一部分是”language”,通常放在data/lang下。”data”部分主要是录音文件相关内容,而”language”部分包括语言相关数据,比如lexicon(词到音子的映射),因子集(phone set)等等。
比如上面的脚本生成的”data/train”目录包括:
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data$ ls -l train/
total 5744
-rw-rw-r-- 1 lili lili 2175289 Aug 14 12:38 phone.txt
-rw-rw-r-- 1 lili lili 80200 Aug 14 12:39 spk2utt
-rw-rw-r-- 1 lili lili 1257119 Aug 14 12:38 text
-rw-rw-r-- 1 lili lili 120000 Aug 14 12:38 utt2spk
-rw-rw-r-- 1 lili lili 974999 Aug 14 12:38 wav.scp
-rw-rw-r-- 1 lili lili 1257119 Aug 14 12:38 word.txt
除了train,data下还通常有dev和test等目录,内容和train类似,目的是用于validation和test。
data/train下一般需要我们准备utt2spk、text和wav.scp,另外有两个文件是可选的,它们是segments和reco2file_and_channel。我们这里每一句话(utterance)对应一个录音文件,因此不需要segments文件,如果一个录音文件包含多句话,那么需要segments文件告诉kaldi每句话的开始和结束时间。reco2file_and_channel我们一般不用到,我们暂时忽略它。
text文件
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data/train$ head -2 text
A02_000 绿 是 阳春 烟 景 大块 文章 的 底色 四月 的 林 峦 更是 绿 得 鲜活 秀媚 诗意 盎然
A02_001 他 仅 凭 腰部 的 力量 在 泳道 上下 翻腾 蛹 动 蛇行 状 如 海豚 一直 以 一头 的 优势 领先
这个文件每一行都是一句话,用空格分开,第一列是utterance-id,后面是分词后的transcript。utterance-id可以是任意字符串,但是要求唯一。但如果需要告诉kaldi这句话是哪个speaker说的,通常的约定是把speaker-id作为utterance-id的前缀。比如A02是一个speaker-id,A02_000表示A02说的第一句话。我们用下划线来连接speaker-id和后面的字符串,更加安全的方法是用”-“来连接。不过这里因为保证后面的字符串都是一个定长的字符串,所以用下划线也不会有问题。如果是我们自己准备数据,尽量按照这种格式准备数据,否则kaldi可能出现奇怪的问题。此外很多脚本文件都会用空格来分隔,所有路径里最好不要用空格。
wav.scp文件
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data/train$ head -2 wav.scp
A02_000 /home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr/data_thchs30/train/A2_0.wav
A02_001 /home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr/data_thchs30/train/A2_1.wav
这个文件告诉kaldi每个utterance-id对应的录音文件的位置。这里是非常简单的方法,用空格分开的两列。第一列是utterance-id,第二列是录音文件的路径。我们这里的例子第二列是录音文件的路径,但是kaldi实际要求的是<extended-filename>,这个<extended-filename>可以是一个wav文件,但是也可以是一个命令,这个命令能产生一个wav文件。
segments文件
我们这里不会用到,但是简要的介绍一下,如果读者遇到别的例子,也能读懂。
s5# head -3 data/train/segments
sw02001-A_000098-001156 sw02001-A 0.98 11.56
sw02001-A_001980-002131 sw02001-A 19.8 21.31
sw02001-A_002736-002893 sw02001-A 27.36 28.93
这个文件的每行为4列,第1列是utterance-id,第2列是recording-id。什么是recording-id?如果有segments文件,那么wav.scp第一列就不是utterance-id而变成recording-id了。recording-id表示一个录音文件的id,而一个录音文件可能包含多个utterance。因此第3列和第4列告诉kaldi这个utterance-id在录音文件中开始和介绍的实际。比如上面的例子,utterance “sw02001-A_000098-001156”在sw02001-A这个录音文件里,开始和结束时间分别是0.98秒到11.56秒。
utt2spk
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data/train$ head -2 utt2spk
A02_000 A02
A02_001 A02
这个文件告诉kaldi,utterance-id对应哪个speaker-id。比如上面的文件告诉我们A02_000这个句子的spaker-id是A02。speaker-id不一定要求准确的对应到某个人,只要大致准确就行。如果我们不知道说话人是谁,那么我们可以把speaker-id设置成utterance-id。一种常见的错误做法是把未知说话人的句子都对应到一个“全局”的speaker,这样的坏处是它会使得cepstral mean normalization变得无效。
另外某些数据有spk2gender文件,它是speaker-id到性别的映射,不过kaldi不需要这个文件。注意:上面的文件都要求排好序(并且使用LC_ALL=C),如果没有排序,后续的脚本会出问题!除了上面的几个文件,其它文件都是kaldi的脚本自动帮我们生成的。我们下面来逐个分析。
spk2utt
这个文件和utt2spk反过来,它存储的是speaker和utterance的对应关系,这是一对多的关系,可以使用脚本来得到:
utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt
这个文件的内容为:
A04 A04_000 A04_001 A04_002 A04_003 A04_005 A04_006 A04_007 A04_008 ...
feats.scp文件
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data/mfcc/train$ head -3 feats.scp
A02_000 /home/lili/codes/kaldi/egs/thchs30/s5/mfcc/train/raw_mfcc_train.1.ark:8
A02_001 /home/lili/codes/kaldi/egs/thchs30/s5/mfcc/train/raw_mfcc_train.1.ark:12868
A02_002 /home/lili/codes/kaldi/egs/thchs30/s5/mfcc/train/raw_mfcc_train.1.ark:26222
这个文件是提取的mfcc特征,第一列是utterance-id,第二列是mfcc特征文件。raw_mfcc_train.1.ark:8表示特征在raw_mfcc_train.1.ark这个文件,开始的位置是8。我们通常可以用如下命令来生成feats.scp文件:
steps/make_mfcc.sh --nj 8 --cmd "$train_cmd" data/train exp/make_mfcc/train $mfccdir
参数data/train是输入目录,exp/make_mfcc是log的目录,而$mfccdir是输出mfcc的目录。
cmvn.scp
这个文件包括倒谱(cepstral)均值和方程归一化(normalization)需要的统计信息,每个speaker一行。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/data/mfcc/train$ head -2 cmvn.scp
A02 /home/lili/codes/kaldi/egs/thchs30/s5/mfcc/train/cmvn_train.ark:4
A04 /home/lili/codes/kaldi/egs/thchs30/s5/mfcc/train/cmvn_train.ark:247
我们可以使用如下的脚本来生成这个文件:
steps/compute_cmvn_stats.sh data/train exp/make_mfcc/train $mfccdir
参数的含义同上。
接下来我们介绍”data/lang”目录下的文件。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ ls data/lang
L_disambig.fst L.fst oov.int oov.txt phones phones.txt topo words.txt
上面的phones是一个目录:
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ ls data/lang/phones
align_lexicon.int disambig.int nonsilence.txt sets.int wdisambig.txt
align_lexicon.txt disambig.txt optional_silence.csl sets.txt wdisambig_words.int
context_indep.csl extra_questions.int optional_silence.int silence.csl
context_indep.int extra_questions.txt optional_silence.txt silence.int
context_indep.txt nonsilence.csl roots.int silence.txt
disambig.csl nonsilence.int roots.txt wdisambig_phones.int
phones.txt
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head data/lang/phones.txt
<eps> 0
sil 1
a1 2
a2 3
a3 4
a4 5
a5 6
aa 7
ai1 8
ai2 9
这个文件是因子和id的映射,WFST里用的都是id。脚本utils/int2sym.pl用于把id转换成符号,而utils/sym2int.pl把符号转换成id。对于英文来说,最常见的音子集合是ARPABET,对于汉语,我们常见的音子就是拼音,但是汉语是的韵母是有声调的,不同的声调是不同的因子。因此a1到a5分别表示ā、á、ǎ、à和a,代表阴平、阳平、上声、去声和轻声。
words.txt
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head data/lang/words.txt
<eps> 0
# 1
<SPOKEN_NOISE> 2
SIL 3
一 4
一一 5
一丁点 6
一万 7
一万元 8
一万多 9
这个文件是词与id的映射。
L.fst和L_disambig.fst
L.fst是lexicon的WFST格式,而L_disambig.fst引入了消歧符号。
oov.txt和oov.int
oov.txt里是未登录词(Out of Vocabulary Words)。这里把所有未登录词映射成一个噪音<SPOKEN_NOISE>。而.int文件是词对应的ID。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/oov.txt
<SPOKEN_NOISE>
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/oov.int
2
这个<SPOKEN_NOISE>并没有什么特殊含义,很多地方也简写成SPN,kaldi对待它和普通词一样。在发音词典文件里,它对应SIL(silence)。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head -5 data/local/lang/lexiconp.txt
# 1.0 sil
<SPOKEN_NOISE> 1.0 sil
SIL 1.0 sil
一 1.0 ii i1
一一 1.0 ii i1 ii i1
lexicon.txt或者lexiconp.txt
这两个文件至少有一个(通常只有一个,如果两个都有则忽略lexicon.txt而使用lexiconp.txt)。这个文件就是发音词典文件,它告诉kaldi每个词对应的音素是什么。比如在前面的例子中词“一”的发音是”ii i1”,”ii”就是y的发音,而”i1”就是ī。一个词(字)可以是多音词(字),比如:
和 1.0 h e2
和 1.0 h e4
和 1.0 h u2
和 1.0 h uo2
和 1.0 h uo4
data/lang/topo
这个文件是HMM的拓扑结构定义,通常在语音识别中我们使用的Bakis结构——一个状态可以自跳转保持状态不变,可以跳到下一个状态,也可以跳过下一个状态跳到下下个状态(说话特别快的时候)。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/topo
<Topology>
<TopologyEntry>
<ForPhones>
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218
</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.75 <Transition> 1 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.75 <Transition> 2 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 2 0.75 <Transition> 3 0.25 </State>
<State> 3 </State>
</TopologyEntry>
<TopologyEntry>
<ForPhones>
1
</ForPhones>
<State> 0 <PdfClass> 0 <Transition> 0 0.25 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 </State>
<State> 1 <PdfClass> 1 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 2 <PdfClass> 2 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 3 <PdfClass> 3 <Transition> 1 0.25 <Transition> 2 0.25 <Transition> 3 0.25 <Transition> 4 0.25 </State>
<State> 4 <PdfClass> 4 <Transition> 4 0.75 <Transition> 5 0.25 </State>
<State> 5 </State>
</TopologyEntry>
</Topology>
这里我们使用的HMM每个phone有3个状态,每个状态只能自跳转和跳到下一个状态,并且我们指定初始化的概率分别是0.75和0.25。 lexicon.txt和lexiconp.txt的区别在于后者可以在第二列说明一个词发不同音的概率。
data/lang/phones/目录
我们这里只分析人可读的txt文件。
context_indep.txt
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/phones/context_indep.txt
sil
这个文件的内容是上下文无关的phone,这里只有一个sil是上下文无关的。
silence.txt
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/phones/silence.txt
sil
nonsilence.txt
非silence的phone,应该和silence没有交集。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head -3 data/lang/phones/nonsilence.txt
a1
a2
a3
disambig.txt
这个文件包含所有的消岐符号。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head -3 data/lang/phones/disambig.txt
#0
#1
#2
optional_silence.txt
可选的silence,在两个词之间可能会有silence,因此需要定义可选的silence。我们这里和普通的silence一样,当然也可以单独给它建模。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/phones/optional_silence.txt
sil
sets.txt
这个文件用于因子的决策树聚类,会把一行的因子用于聚类的问题。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head -3 data/lang/phones/sets.txt
sil
a1
a2
如果有上下文相关的因子,通常会把它们放到一起,比如英语的例子:
s5# head -3 data/lang/phones/sets.txt
SIL SIL_B SIL_E SIL_I SIL_S
SPN SPN_B SPN_E SPN_I SPN_S
NSN NSN_B NSN_E NSN_I NSN_S
extra_questions.txt
决策树聚类额外的问题,这个文件不是必须的。和HTK不同,kaldi会自己生成决策树聚类的问题。我们这里提供额外的问题,注意是根据音调来提问(英语通常会对重音)。 这里根据音调的不同把因子分成5类,然后再加上sil和辅音,共7类。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ cat data/lang/phones/extra_questions.txt
sil
a1 ai1 an1 ang1 ao1 e1 ei1 en1 eng1 i1 ia1 ian1 iang1 iao1 ie1 in1 ing1 iong1 iu1 ix1 iy1 o1 ong1 ou1 u1 ua1 uai1 uan1 uang1 ueng1 ui1 un1 uo1 v1 van1 ve1 vn1
a2 ai2 an2 ang2 ao2 e2 ei2 en2 eng2 er2 i2 ia2 ian2 iang2 iao2 ie2 in2 ing2 iong2 iu2 ix2 iy2 o2 ong2 ou2 u2 ua2 uai2 uan2 uang2 ui2 un2 uo2 v2 van2 ve2 vn2
a3 ai3 an3 ang3 ao3 e3 ei3 en3 eng3 er3 i3 ia3 ian3 iang3 iao3 ie3 in3 ing3 iong3 iu3 ix3 iy3 o3 ong3 ou3 u3 ua3 uai3 uan3 uang3 ueng3 ui3 un3 uo3 v3 van3 ve3 vn3
a4 ai4 an4 ang4 ao4 e4 ei4 en4 eng4 er4 i4 ia4 ian4 iang4 iao4 ie4 in4 ing4 iong4 iu4 ix4 iy4 iz4 o4 ong4 ou4 u4 ua4 uai4 uan4 uang4 ueng4 ui4 un4 uo4 v4 van4 ve4 vn4
a5 ai5 an5 ang5 ao5 e5 ei5 en5 eng5 er5 i5 ia5 ian5 iang5 iao5 ie5 in5 ing5 iong5 iu5 ix5 iy5 iz5 o5 ong5 ou5 u5 ua5 uai5 uan5 uang5 ueng5 ui5 un5 uo5 v5 van5 ve5 vn5
aa b c ch d ee f g h ii j k l m n oo p q r s sh t uu vv x z zh
roots.txt
决策树聚类的树根(root),这里每个因子一行。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5$ head data/lang/phones/roots.txt
shared split sil
shared split a1
shared split a2
shared split a3
shared split a4
shared split a5
shared split aa
shared split ai1
shared split ai2
shared split ai3
如果有上下文相关的phone,那么一行会有多个,比如英语的例子:
head data/lang/phones/roots.txt
shared split SIL SIL_B SIL_E SIL_I SIL_S
shared split SPN SPN_B SPN_E SPN_I SPN_S
shared split NSN NSN_B NSN_E NSN_I NSN_S
shared split LAU LAU_B LAU_E LAU_I LAU_S
...
shared split B_B B_E B_I B_S
准备text,wav.scp,utt2spk文件
local/thchs-30_data_prep.sh $H $thchs/data_thchs30 || exit 1;
我们来看一下脚本local/thchs-30_data_prep.sh,根据kaldi的约定,local目录下是与特定数据集相关的数据处理脚本。这个脚本有两个参数,第一个是输出的目录,这里传入的是当前目录”/home/lili/codes/kaldi/egs/thchs30/s5”;而第二个参数是数据目录”/home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr/data_thchs30”。这个脚本会根据thchs30的数据生成kaldi需要的text, wav.scp, utt2pk, spk2utt等文件。
#!/bin/bash
# Copyright 2016 Tsinghua University (Author: Dong Wang, Xuewei Zhang). Apache 2.0.
# 2016 LeSpeech (Author: Xingyu Na)
#This script pepares the data directory for thchs30 recipe.
#It reads the corpus and get wav.scp and transcriptions.
# dir可能是"/home/lili/codes/kaldi/egs/thchs30/s5"
dir=$1
# corpus_dir可能是"/home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr/data_thchs30"
corpus_dir=$2
cd $dir
# 在data目录下创建 train,dev和test子目录
echo "creating data/{train,dev,test}"
mkdir -p data/{train,dev,test}
# 创建 wav.scp, utt2spk.scp, spk2utt.scp, text
(
# x分别取值"train","dev"和"test"
for x in train dev test; do
echo "cleaning data/$x"
# 进入到相应目录,比如data/train
cd $dir/data/$x
# 删除下面的相关文件
rm -rf wav.scp utt2spk spk2utt word.txt phone.txt text
echo "preparing scps and text in data/$x"
# 在/home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30-openslr/data_thchs30/train
# 下找所有的wav文件,并且根据名字排序
for nn in `find $corpus_dir/$x -name "*.wav" | sort -u | xargs -I {} basename {} .wav`; do
# 从文件名中抽取信息,比如从C8_742.wav
# spkid 为C8(需要了解简单的awk)
spkid=`echo $nn | awk -F"_" '{print "" $1}'`
# spk_char为C
spk_char=`echo $spkid | sed 's/\([A-Z]\).*/\1/'`
# spk_num为8
spk_num=`echo $spkid | sed 's/[A-Z]\([0-9]\)/\1/'`
# 把spkid变成C08(原来是C8),因为说话人小于100个,这样就可以保证顺序
spkid=$(printf '%s%.2d' "$spk_char" "$spk_num")
# 抽取下划线后面的 742
utt_num=`echo $nn | awk -F"_" '{print $2}'`
# 变成C08_742
uttid=$(printf '%s%.2d_%.3d' "$spk_char" "$spk_num" "$utt_num")
# 输出到wav.scp的一行,类似
# "C08_742 /home/lili/codes/kaldi/egs/thchs30/s5/data/thchs30
# -openslr/data_thchs30/train/C8_742.wav"
echo $uttid $corpus_dir/$x/$nn.wav >> wav.scp
# 输出到utt2spk的一行 "C08_742 C08"
echo $uttid $spkid >> utt2spk
# 输出到word.txt "C08_742 这里 说 的 易 牙 蒸 了 他 儿子 给 桀纣 吃
# 也是 狂人 语 颇 错 杂 无 伦次 的 表现"
echo $uttid `sed -n 1p $corpus_dir/data/$nn.wav.trn` >> word.txt
# 输出到phone.txt "C08_742 zh e4 l i3 sh uo1 d e5 ii i4 ii ia2 zh eng1 l e5 t a1 ee
# er2 z iy5 g ei3 j ie2 zh ou4 ch ix1 ii ie3 sh ix4 k uang2 r en2 vv v3 p o1 c uo4
# z a2 uu u2 l un2 c iy4 d e5 b iao3 x ian4"
echo $uttid `sed -n 3p $corpus_dir/data/$nn.wav.trn` >> phone.txt
done
# word.txt就是kaldi要的text
cp word.txt text
# wav.scp排序
sort wav.scp -o wav.scp
# utt2spk排序
sort utt2spk -o utt2spk
# text排序
sort text -o text
# phone.txt排序
sort phone.txt -o phone.txt
done
) || exit 1
# 根据utt2spk生成spk2utt
utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt
utils/utt2spk_to_spk2utt.pl data/dev/utt2spk > data/dev/spk2utt
utils/utt2spk_to_spk2utt.pl data/test/utt2spk > data/test/spk2utt
echo "creating test_phone for phone decoding"
(
# 复制data/test目录到data/test_phone
rm -rf data/test_phone && cp -R data/test data/test_phone || exit 1
# 把phone.txt复制到text
cd data/test_phone && rm text && cp phone.txt text || exit 1
)
对shell脚本不熟悉的读者可能需要找一些相关的资料学习一下。上面的脚本里加入了一些注释,请读者参考注释读懂代码。
提取MFCC特征
#produce MFCC features
rm -rf data/mfcc && mkdir -p data/mfcc && cp -R data/{train,dev,test,test_phone} data/mfcc || exit 1;
for x in train dev test; do
#make mfcc
steps/make_mfcc.sh --nj $n --cmd "$train_cmd" data/mfcc/$x exp/make_mfcc/$x mfcc/$x || exit 1;
#compute cmvn
steps/compute_cmvn_stats.sh data/mfcc/$x exp/mfcc_cmvn/$x mfcc/$x || exit 1;
done
#copy feats and cmvn to test.ph, avoid duplicated mfcc & cmvn
cp data/mfcc/test/feats.scp data/mfcc/test_phone && cp data/mfcc/test/cmvn.scp data/mfcc/test_phone || exit 1;
首先把data/train,data/dev,data/test,data/test_phone4个目录复制到data/mfcc/下。然后用steps/make_mfcc.sh和steps/compute_cmvn_stats.sh分别提取MFCC特征和计算CMVN统计信息。test_phone不需要重复计算,只需要直接从test复制就可以了。
准备data/lang
run.sh的下面部分代码准备data/lang里的数据和把arpa格式的语言模型转换成WFST格式。
#prepare language stuff
#build a large lexicon that invovles words in both the training and decoding.
(
echo "make word graph ..."
cd $H; mkdir -p data/{dict,lang,graph} && \
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict && \
cat $thchs/resource/dict/lexicon.txt $thchs/data_thchs30/lm_word/lexicon.txt | \
grep -v '<s>' | grep -v '</s>' | sort -u > data/dict/lexicon.txt || exit 1;
utils/prepare_lang.sh --position_dependent_phones false data/dict "<SPOKEN_NOISE>" data/local/lang data/lang || exit 1;
gzip -c $thchs/data_thchs30/lm_word/word.3gram.lm > data/graph/word.3gram.lm.gz || exit 1;
utils/format_lm.sh data/lang data/graph/word.3gram.lm.gz $thchs/data_thchs30/lm_word/lexicon.txt data/graph/lang || exit 1;
)
#make_phone_graph
(
echo "make phone graph ..."
cd $H; mkdir -p data/{dict_phone,graph_phone,lang_phone} && \
cp $thchs/resource/dict/{extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt} data/dict_phone && \
cat $thchs/data_thchs30/lm_phone/lexicon.txt | grep -v '<eps>' | sort -u > data/dict_phone/lexicon.txt && \
echo "<SPOKEN_NOISE> sil " >> data/dict_phone/lexicon.txt || exit 1;
utils/prepare_lang.sh --position_dependent_phones false data/dict_phone "<SPOKEN_NOISE>" data/local/lang_phone data/lang_phone || exit 1;
gzip -c $thchs/data_thchs30/lm_phone/phone.3gram.lm > data/graph_phone/phone.3gram.lm.gz || exit 1;
utils/format_lm.sh data/lang_phone data/graph_phone/phone.3gram.lm.gz $thchs/data_thchs30/lm_phone/lexicon.txt \
data/graph_phone/lang || exit 1;
)
代码很简单,首先创建data/dict,data/lang和data/graph目录。然后把提前准备好的extra_questions.txt,nonsilence_phones.txt,optional_silence.txt,silence_phones.txt等文件从resource/dict/复制到data/dict。而发音词典来自两个文件resource/dict/lexicon.txt和data_thchs30/lm_word/lexicon.txt,把这两个文件合并,去掉<s>和</s>,排序后放到data/dict/lexicon.txt里。
然后调用:
utils/prepare_lang.sh --position_dependent_phones false data/dict "<SPOKEN_NOISE>" data/local/lang data/lang
prepare_lang.sh脚本会生成我们之前在data/lang里看到的文件和目录。它的输入是data/dict,输出是data/lang,而data/local/lang是个临时目录,里面存放一些中间结果。此外需要一个参数告诉kaldi OOV对于哪个词。选项position_dependent_phones告诉脚本我们这里生成的是上下文无关的phone,因为这里数据不太大,所以使用的是上下文无关的phone,但是如果要效果更好,通常这个选项是true(默认值),这时就会生成类似带后缀”_B, _E, _S”的phone。
最后使用format_lm.sh把arpa格式的语言模型转化成WFST。如果我们需要自己训练语言模型,一般的n-gram语言模型都可以转换成arpa格式。
utils/format_lm.sh data/lang data/graph/word.3gram.lm.gz $thchs/data_thchs30/lm_word/lexicon.txt data/graph/lang
生成的结果放在data/graph/lang,比如data/graph/lang/G.fst就是语言模型转换成的WFST。但如果不是n-gram的语言模型,比如RNN的语言模型,目前还很难集成到WFST的解码架构里,通常的方法是使用n-gram做一遍解码,然后再用更好的RNN语言模型做第二遍的rescoring。
因为除了训练语音转文字的识别系统,这里也实现了phone的识别,也就是把语音变成phone。所以也用类似的方法准备数据到data/graph_phone/lang。
训练monophone模型
接下来使用steps/train_mono.sh来monophone模型。
#monophone
steps/train_mono.sh --boost-silence 1.25 --nj $n --cmd "$train_cmd" data/mfcc/train data/lang exp/mono || exit 1;
#test monophone model
local/thchs-30_decode.sh --mono true --nj $n "steps/decode.sh" exp/mono data/mfcc &
这个脚本的输入是之前我们准备好的数据目录data/mfcc/train和lang目录data/lang,输出是exp/mono。 nj选项指定cpu的使用数,读者需要根据自己的机器配置设置合适的值。cmd选项是在是在cmd.sh里设置的。训练好了就会测试,这里测试会在后台运行,然后脚本就往下走了。如果读者的机器没有足够的计算资源,建议把”\&”去掉,否则脚本会继续执行训练下面的模型,同时又在测试刚训练好的monophone模型,机器的负载就会很高。
这个脚本的输出为:
steps/train_mono.sh --boost-silence 1.25 --nj 4 --cmd run.pl data/mfcc/train data/lang exp/mono
steps/train_mono.sh: Initializing monophone system.
steps/train_mono.sh: Compiling training graphs
steps/train_mono.sh: Aligning data equally (pass 0)
steps/train_mono.sh: Pass 1
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 2
....
steps/train_mono.sh: Aligning data
steps/train_mono.sh: Pass 39
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/mono
steps/diagnostic/analyze_alignments.sh: see stats in exp/mono/log/analyze_alignments.log
6154 warnings in exp/mono/log/align.*.*.log
153 warnings in exp/mono/log/acc.*.*.log
1051 warnings in exp/mono/log/update.*.log
exp/mono: nj=4 align prob=-100.09 over 25.49h [retry=0.2%, fail=0.0%] states=656 gauss=990
steps/train_mono.sh: Done training monophone system in exp/mono
using monophone to generate graph
WARNING: the --mono, --left-biphone and --quinphone options are now deprecated and ignored.
tree-info exp/mono/tree
tree-info exp/mono/tree
fstminimizeencoded
fstpushspecial
fsttablecompose data/graph/lang/L_disambig.fst data/graph/lang/G.fst
fstdeterminizestar --use-log=true
fstisstochastic data/graph/lang/tmp/LG.fst
-0.0480882 -0.0488869
[info]: LG not stochastic.
fstcomposecontext --context-size=1 --central-position=0 --read-disambig-syms=data/graph/lang/phones/disambig.int --write-disambig-syms=data/graph/lang/tmp/disambig_ilabels_1_0.int data/graph/lang/tmp/ilabels_1_0.27036
fstisstochastic data/graph/lang/tmp/CLG_1_0.fst
-0.0480882 -0.0488869
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/mono/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_1_0 exp/mono/tree exp/mono/final.mdl
fsttablecompose exp/mono/graph_word/Ha.fst data/graph/lang/tmp/CLG_1_0.fst
fstrmsymbols exp/mono/graph_word/disambig_tid.int
fstminimizeencoded
fstdeterminizestar --use-log=true
fstrmepslocal
fstisstochastic exp/mono/graph_word/HCLGa.fst
0.644531 -0.0974261
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/mono/final.mdl
steps/decode.sh --cmd run.pl --mem 4G --nj 4 exp/mono/graph_word data/mfcc/test exp/mono/decode_test_word
decode.sh: feature type is delta
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/mono/graph_word exp/mono/decode_test_word
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(3,36,176) and mean=69.7
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_word/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/mono/graph_word exp/mono/decode_test_word
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
WARNING: the --mono, --left-biphone and --quinphone options are now deprecated and ignored.
tree-info exp/mono/tree
tree-info exp/mono/tree
fstminimizeencoded
fstpushspecial
fstdeterminizestar --use-log=true
fsttablecompose data/graph_phone/lang/L_disambig.fst data/graph_phone/lang/G.fst
fstisstochastic data/graph_phone/lang/tmp/LG.fst
-0.264706 -0.265648
[info]: LG not stochastic.
fstcomposecontext --context-size=1 --central-position=0 --read-disambig-syms=data/graph_phone/lang/phones/disambig.int --write-disambig-syms=data/graph_phone/lang/tmp/disambig_ilabels_1_0.int data/graph_phone/lang/tmp/ilabels_1_0.31511
fstisstochastic data/graph_phone/lang/tmp/CLG_1_0.fst
-0.264706 -0.265648
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/mono/graph_phone/disambig_tid.int --transition-scale=1.0 data/graph_phone/lang/tmp/ilabels_1_0 exp/mono/tree exp/mono/final.mdl
fstrmepslocal
fstrmsymbols exp/mono/graph_phone/disambig_tid.int
fstdeterminizestar --use-log=true
fstminimizeencoded
fsttablecompose exp/mono/graph_phone/Ha.fst data/graph_phone/lang/tmp/CLG_1_0.fst
fstisstochastic exp/mono/graph_phone/HCLGa.fst
0.00033643 -0.522085
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/mono/final.mdl
steps/decode.sh --cmd run.pl --mem 4G --nj 4 exp/mono/graph_phone data/mfcc/test_phone exp/mono/decode_test_phone
decode.sh: feature type is delta
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/mono/graph_phone exp/mono/decode_test_phone
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_phone/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(6,20,62) and mean=28.8
steps/diagnostic/analyze_lats.sh: see stats in exp/mono/decode_test_phone/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test_phone exp/mono/graph_phone exp/mono/decode_test_phone
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
monophone训练的信息都在exp/mono目录下,我们通常会关心模型的识别的词错误率,这在exp/mono/decode_test_word可以看到。
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/exp/mono/decode_test_word$ cat wer_9_0.0
compute-wer --text --mode=present ark:exp/mono/decode_test_word/scoring_kaldi/test_filt.txt ark,p:-
%WER 50.74 [ 41169 / 81139, 511 ins, 2413 del, 38245 sub ]
%SER 100.00 [ 2495 / 2495 ]
Scored 2495 sentences, 0 not present in hyp.
wer_9_0.0是词错误率的结果,文件名中的9代表语言模型的scale factor。我们可以看到monophone的词错误率在50%左右。 我们可以查看解码测试数据的例子,结果在exp/mono/decode_test_word/log里:
lili@lili-Precision-7720:~/codes/kaldi/egs/thchs30/s5/exp/mono/decode_test_word/log$ cat decode.1.log
gmm-latgen-faster --max-active=7000 --beam=13.0 --lattice-beam=6.0 --acoustic-scale=0.083333 --allow-partial=true --word-symbol-table=exp/mono/graph_word/words.txt exp/mono/final.mdl exp/mono/graph_word/HCLG.fst 'ark,s,cs:apply-cmvn --utt2spk=ark:data/mfcc/test/split4/1/utt2spk scp:data/mfcc/test/split4/1/cmvn.scp scp:data/mfcc/test/split4/1/feats.scp ark:- | add-deltas ark:- ark:- |' 'ark:|gzip -c > exp/mono/decode_test_word/lat.1.gz'
add-deltas ark:- ark:-
apply-cmvn --utt2spk=ark:data/mfcc/test/split4/1/utt2spk scp:data/mfcc/test/split4/1/cmvn.scp scp:data/mfcc/test/split4/1/feats.scp ark:-
D04_750 受 北京 一些 爱国 驾驶 满载 山 起步 长期 无 说明 艾 根 钱 没 敢 言 奋起 抗战
LOG (gmm-latgen-faster[5.4.232~1-532f3]:DecodeUtteranceLatticeFaster():decoder-wrappers.cc:286) Log-like per frame for utterance D04_750 is -8.33257 over 961 frames.
D04_751 王 金山 被 枪毙 后 部分 余孽 宣传 起来 其次 为 捕 鲸 被 抓获
用monophone模型对齐
steps/align_si.sh --boost-silence 1.25 --nj 6 --cmd run.pl data/mfcc/train data/lang exp/mono exp/mono_ali
steps/align_si.sh: feature type is delta
steps/align_si.sh: aligning data in data/mfcc/train using model from exp/mono, putting alignments in exp/mono_ali
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/mono_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/mono_ali/log/analyze_alignments.log
steps/align_si.sh: done aligning data.
训练triphone模型
steps/train_deltas.sh --boost-silence 1.25 --cmd run.pl 2000 10000 data/mfcc/train data/lang exp/mono_ali exp/tri1
steps/train_deltas.sh: accumulating tree stats
steps/train_deltas.sh: getting questions for tree-building, via clustering
steps/train_deltas.sh: building the tree
steps/train_deltas.sh: converting alignments from exp/mono_ali to use current tree
steps/train_deltas.sh: compiling graphs of transcripts
steps/train_deltas.sh: training pass 1
steps/train_deltas.sh: training pass 2
steps/train_deltas.sh: training pass 3
steps/train_deltas.sh: training pass 4
steps/train_deltas.sh: training pass 5
steps/train_deltas.sh: training pass 6
...
steps/train_deltas.sh: training pass 34
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri1
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri1/log/analyze_alignments.log
153 warnings in exp/tri1/log/align.*.*.log
1 warnings in exp/tri1/log/compile_questions.log
281 warnings in exp/tri1/log/update.*.log
124 warnings in exp/tri1/log/acc.*.*.log
9 warnings in exp/tri1/log/init_model.log
9 warnings in exp/tri1/log/questions.log
1 warnings in exp/tri1/log/build_tree.log
exp/tri1: nj=6 align prob=-96.74 over 25.48h [retry=0.5%, fail=0.0%] states=1648 gauss=10031 tree-impr=4.77
steps/train_deltas.sh: Done training system with delta+delta-delta features in exp/tri1
tree-info exp/tri1/tree
tree-info exp/tri1/tree
fstcomposecontext --context-size=3 --central-position=1 --read-disambig-syms=data/graph/lang/phones/disambig.int --write-disambig-syms=data/graph/lang/tmp/disambig_ilabels_3_1.int data/graph/lang/tmp/ilabels_3_1.17687
fstisstochastic data/graph/lang/tmp/CLG_3_1.fst
0 -0.0488869
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/tri1/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri1/tree exp/tri1/final.mdl
fstrmepslocal
fsttablecompose exp/tri1/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
fstrmsymbols exp/tri1/graph_word/disambig_tid.int
fstdeterminizestar --use-log=true
fstminimizeencoded
fstisstochastic exp/tri1/graph_word/HCLGa.fst
0.644531 -0.128776
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri1/final.mdl
steps/decode.sh --cmd run.pl --mem 4G --nj 6 exp/tri1/graph_word data/mfcc/test exp/tri1/decode_test_word
decode.sh: feature type is delta
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri1/graph_word exp/tri1/decode_test_word
steps/diagnostic/analyze_lats.sh: see stats in exp/tri1/decode_test_word/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(1,13,72) and mean=28.3
steps/diagnostic/analyze_lats.sh: see stats in exp/tri1/decode_test_word/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/tri1/graph_word exp/tri1/decode_test_word
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
tree-info exp/tri1/tree
tree-info exp/tri1/tree
fstcomposecontext --context-size=3 --central-position=1 --read-disambig-syms=data/graph_phone/lang/phones/disambig.int --write-disambig-syms=data/graph_phone/lang/tmp/disambig_ilabels_3_1.int data/graph_phone/lang/tmp/ilabels_3_1.24591
fstisstochastic data/graph_phone/lang/tmp/CLG_3_1.fst
0 -0.265648
[info]: CLG not stochastic.
make-h-transducer --disambig-syms-out=exp/tri1/graph_phone/disambig_tid.int --transition-scale=1.0 data/graph_phone/lang/tmp/ilabels_3_1 exp/tri1/tree exp/tri1/final.mdl
fstrmepslocal
fstminimizeencoded
fstrmsymbols exp/tri1/graph_phone/disambig_tid.int
fstdeterminizestar --use-log=true
fsttablecompose exp/tri1/graph_phone/Ha.fst data/graph_phone/lang/tmp/CLG_3_1.fst
fstisstochastic exp/tri1/graph_phone/HCLGa.fst
0.000486116 -0.797725
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri1/final.mdl
steps/decode.sh --cmd run.pl --mem 4G --nj 6 exp/tri1/graph_phone data/mfcc/test_phone exp/tri1/decode_test_phone
decode.sh: feature type is delta
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri1/graph_phone exp/tri1/decode_test_phone
steps/diagnostic/analyze_lats.sh: see stats in exp/tri1/decode_test_phone/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(3,10,32) and mean=14.7
steps/diagnostic/analyze_lats.sh: see stats in exp/tri1/decode_test_phone/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test_phone exp/tri1/graph_phone exp/tri1/decode_test_phone
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
steps/align_si.sh --nj 6 --cmd run.pl data/mfcc/train data/lang exp/tri1 exp/tri1_ali
steps/align_si.sh: feature type is delta
steps/align_si.sh: aligning data in data/mfcc/train using model from exp/tri1, putting alignments in exp/tri1_ali
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri1_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri1_ali/log/analyze_alignments.log
steps/align_si.sh: done aligning data.
lda_mllt
steps/train_lda_mllt.sh --cmd run.pl --splice-opts --left-context=3 --right-context=3 2500 15000 data/mfcc/train data/lang exp/tri1_ali exp/tri2b
steps/train_lda_mllt.sh: Accumulating LDA statistics.
steps/train_lda_mllt.sh: Accumulating tree stats
steps/train_lda_mllt.sh: Getting questions for tree clustering.
steps/train_lda_mllt.sh: Building the tree
steps/train_lda_mllt.sh: Initializing the model
...
sat
steps/train_sat.sh --cmd run.pl 2500 15000 data/mfcc/train data/lang exp/tri2b_ali exp/tri3b
steps/train_sat.sh: feature type is lda
steps/train_sat.sh: obtaining initial fMLLR transforms since not present in exp/tri2b_ali
steps/train_sat.sh: Accumulating tree stats
steps/train_sat.sh: Getting questions for tree clustering.
steps/train_sat.sh: Building the tree
steps/train_sat.sh: Initializing the model
...
quick
steps/train_quick.sh --cmd run.pl 4200 40000 data/mfcc/train data/lang exp/tri3b_ali exp/tri4b
steps/train_quick.sh: feature type is lda
steps/train_quick.sh: using transforms from exp/tri3b_ali
steps/train_quick.sh: accumulating tree stats
steps/train_quick.sh: Getting questions for tree clustering.
steps/train_quick.sh: Building the tree
steps/train_quick.sh: Initializing the model
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 109 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 121 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 163 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 175 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 176 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 177 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 203 of new tree has no stats.
WARNING (gmm-init-model[5.4.232~1-532f3]:InitAmGmmFromOld():gmm-init-model.cc:147) Leaf 208 of new tree has no stats.
steps/train_quick.sh: This is a bad warning.
steps/train_quick.sh: mixing up old model.
steps/train_quick.sh: converting old alignments
steps/train_quick.sh: compiling training graphs
steps/train_quick.sh: pass 1
steps/train_quick.sh: pass 2
steps/train_quick.sh: pass 3
steps/train_quick.sh: pass 4
steps/train_quick.sh: pass 5
steps/train_quick.sh: pass 6
steps/train_quick.sh: pass 7
steps/train_quick.sh: pass 8
steps/train_quick.sh: pass 9
steps/train_quick.sh: pass 10
steps/train_quick.sh: aligning data
steps/train_quick.sh: pass 11
steps/train_quick.sh: pass 12
steps/train_quick.sh: pass 13
steps/train_quick.sh: pass 14
steps/train_quick.sh: pass 15
steps/train_quick.sh: aligning data
steps/train_quick.sh: pass 16
steps/train_quick.sh: pass 17
steps/train_quick.sh: pass 18
steps/train_quick.sh: pass 19
steps/train_quick.sh: estimating alignment model
Done
tree-info exp/tri4b/tree
tree-info exp/tri4b/tree
make-h-transducer --disambig-syms-out=exp/tri4b/graph_word/disambig_tid.int --transition-scale=1.0 data/graph/lang/tmp/ilabels_3_1 exp/tri4b/tree exp/tri4b/final.mdl
fsttablecompose exp/tri4b/graph_word/Ha.fst data/graph/lang/tmp/CLG_3_1.fst
fstrmsymbols exp/tri4b/graph_word/disambig_tid.int
fstdeterminizestar --use-log=true
fstrmepslocal
fstminimizeencoded
fstisstochastic exp/tri4b/graph_word/HCLGa.fst
0.644531 -0.128947
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri4b/final.mdl
steps/decode_fmllr.sh --cmd run.pl --mem 4G --nj 6 exp/tri4b/graph_word data/mfcc/test exp/tri4b/decode_test_word
steps/decode.sh --scoring-opts --num-threads 1 --skip-scoring false --acwt 0.083333 --nj 6 --cmd run.pl --mem 4G --beam 10.0 --model exp/tri4b/final.alimdl --max-active 2000 exp/tri4b/graph_word data/mfcc/test exp/tri4b/decode_test_word.si
decode.sh: feature type is lda
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri4b/graph_word exp/tri4b/decode_test_word.si
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_word.si/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(1,6,35) and mean=13.7
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_word.si/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/tri4b/graph_word exp/tri4b/decode_test_word.si
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
steps/decode_fmllr.sh: feature type is lda
steps/decode_fmllr.sh: getting first-pass fMLLR transforms.
steps/decode_fmllr.sh: doing main lattice generation phase
steps/decode_fmllr.sh: estimating fMLLR transforms a second time.
steps/decode_fmllr.sh: doing a final pass of acoustic rescoring.
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri4b/graph_word exp/tri4b/decode_test_word
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_word/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(1,6,35) and mean=13.9
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_word/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test exp/tri4b/graph_word exp/tri4b/decode_test_word
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
tree-info exp/tri4b/tree
tree-info exp/tri4b/tree
make-h-transducer --disambig-syms-out=exp/tri4b/graph_phone/disambig_tid.int --transition-scale=1.0 data/graph_phone/lang/tmp/ilabels_3_1 exp/tri4b/tree exp/tri4b/final.mdl
fstrmsymbols exp/tri4b/graph_phone/disambig_tid.int
fstminimizeencoded
fstrmepslocal
fsttablecompose exp/tri4b/graph_phone/Ha.fst data/graph_phone/lang/tmp/CLG_3_1.fst
fstdeterminizestar --use-log=true
fstisstochastic exp/tri4b/graph_phone/HCLGa.fst
0.00048422 -0.797661
HCLGa is not stochastic
add-self-loops --self-loop-scale=0.1 --reorder=true exp/tri4b/final.mdl
steps/decode_fmllr.sh --cmd run.pl --mem 4G --nj 6 exp/tri4b/graph_phone data/mfcc/test_phone exp/tri4b/decode_test_phone
steps/decode.sh --scoring-opts --num-threads 1 --skip-scoring false --acwt 0.083333 --nj 6 --cmd run.pl --mem 4G --beam 10.0 --model exp/tri4b/final.alimdl --max-active 2000 exp/tri4b/graph_phone data/mfcc/test_phone exp/tri4b/decode_test_phone.si
decode.sh: feature type is lda
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri4b/graph_phone exp/tri4b/decode_test_phone.si
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_phone.si/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(2,6,17) and mean=7.9
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_phone.si/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test_phone exp/tri4b/graph_phone exp/tri4b/decode_test_phone.si
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
steps/decode_fmllr.sh: feature type is lda
steps/decode_fmllr.sh: getting first-pass fMLLR transforms.
steps/decode_fmllr.sh: doing main lattice generation phase
steps/decode_fmllr.sh: estimating fMLLR transforms a second time.
steps/decode_fmllr.sh: doing a final pass of acoustic rescoring.
steps/diagnostic/analyze_lats.sh --cmd run.pl --mem 4G exp/tri4b/graph_phone exp/tri4b/decode_test_phone
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_phone/log/analyze_alignments.log
Overall, lattice depth (10,50,90-percentile)=(2,5,14) and mean=6.9
steps/diagnostic/analyze_lats.sh: see stats in exp/tri4b/decode_test_phone/log/analyze_lattice_depth_stats.log
local/score.sh --cmd run.pl --mem 4G data/mfcc/test_phone exp/tri4b/graph_phone exp/tri4b/decode_test_phone
local/score.sh: scoring with word insertion penalty=0.0,0.5,1.0
quick align
steps/align_fmllr.sh --nj 6 --cmd run.pl data/mfcc/train data/lang exp/tri4b exp/tri4b_ali
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
steps/align_fmllr.sh: aligning data in data/mfcc/train using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
steps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali/log/analyze_alignments.log
72 warnings in exp/tri4b_ali/log/align_pass2.*.log
4 warnings in exp/tri4b_ali/log/fmllr.*.log
49 warnings in exp/tri4b_ali/log/align_pass1.*.log
steps/align_fmllr.sh --nj 6 --cmd run.pl data/mfcc/dev data/lang exp/tri4b exp/tri4b_ali_cv
steps/align_fmllr.sh: feature type is lda
steps/align_fmllr.sh: compiling training graphs
steps/align_fmllr.sh: aligning data in data/mfcc/dev using exp/tri4b/final.alimdl and speaker-independent features.
steps/align_fmllr.sh: computing fMLLR transforms
steps/align_fmllr.sh: doing final alignment.
steps/align_fmllr.sh: done aligning data.
steps/diagnostic/analyze_alignments.sh --cmd run.pl data/lang exp/tri4b_ali_cv
steps/diagnostic/analyze_alignments.sh: see stats in exp/tri4b_ali_cv/log/analyze_alignments.log
6 warnings in exp/tri4b_ali_cv/log/align_pass2.*.log
5 warnings in exp/tri4b_ali_cv/log/align_pass1.*.log
训练dnn模型
DNN training: stage 0: feature generation
producing fbank for train
steps/make_fbank.sh --nj 6 --cmd run.pl data/fbank/train exp/make_fbank/train fbank/train
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/train
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
Succeeded creating filterbank features for train
steps/compute_cmvn_stats.sh data/fbank/train exp/fbank_cmvn/train fbank/train
Succeeded creating CMVN stats for train
producing fbank for dev
steps/make_fbank.sh --nj 6 --cmd run.pl data/fbank/dev exp/make_fbank/dev fbank/dev
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/dev
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
Succeeded creating filterbank features for dev
steps/compute_cmvn_stats.sh data/fbank/dev exp/fbank_cmvn/dev fbank/dev
Succeeded creating CMVN stats for dev
producing fbank for test
steps/make_fbank.sh --nj 6 --cmd run.pl data/fbank/test exp/make_fbank/test fbank/test
utils/validate_data_dir.sh: Successfully validated data-directory data/fbank/test
steps/make_fbank.sh: [info]: no segments file exists: assuming wav.scp indexed by utterance.
Succeeded creating filterbank features for test
steps/compute_cmvn_stats.sh data/fbank/test exp/fbank_cmvn/test fbank/test
Succeeded creating CMVN stats for test
producing test_fbank_phone
# INFO
steps/nnet/train.sh : Training Neural Network
dir : exp/tri4b_dnn
Train-set : data/fbank/train 10000, exp/tri4b_ali
CV-set : data/fbank/dev 893 exp/tri4b_ali_cv
SKIPPING TRAINING... (steps/nnet/train.sh)
nnet already trained : exp/tri4b_dnn/final.nnet (nnet/nnet_iter14_learnrate7.8125e-06_tr1.0435_cv1.3938_final_)
# Accounting: time=1 threads=1
# Ended (code 0) at Tue Aug 7 21:42:03 CST 2018, elapsed time 1 seconds
# steps/nnet/train.sh --copy_feats false --cmvn-opts "--norm-means=true --norm-vars=false" --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# Started at Tue Aug 21 11:10:36 CST 2018
#
steps/nnet/train.sh --copy_feats false --cmvn-opts --norm-means=true --norm-vars=false --hid-layers 4 --hid-dim 1024 --learn-rate 0.008 data/fbank/train data/fbank/dev data/lang exp/tri4b_ali exp/tri4b_ali_cv exp/tri4b_dnn
# INFO
steps/nnet/train.sh : Training Neural Network
dir : exp/tri4b_dnn
Train-set : data/fbank/train 10000, exp/tri4b_ali
CV-set : data/fbank/dev 893 exp/tri4b_ali_cv
SKIPPING TRAINING... (steps/nnet/train.sh)
nnet already trained : exp/tri4b_dnn/final.nnet (nnet/nnet_iter14_learnrate7.8125e-06_tr1.0435_cv1.3938_final_)
# Accounting: time=0 threads=1
# Ended (code 0) at Tue Aug 21 11:10:36 CST 2018, elapsed time 0 seconds
steps/nnet/align.sh --nj 6 --cmd run.pl data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_ali
steps/nnet/decode.sh --nj 6 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_word data/fbank/test exp/tri4b_dnn/decode_test_word
steps/nnet/decode.sh --nj 6 --cmd run.pl --mem 4G --srcdir exp/tri4b_dnn --config conf/decode_dnn.config --acwt 0.1 exp/tri4b/graph_phone data/fbank/test_phone exp/tri4b_dnn/decode_test_phone
steps/nnet/align.sh: aligning data 'data/fbank/train' using nnet/model 'exp/tri4b_dnn', putting alignments in 'exp/tri4b_dnn_ali'
run.pl: 6 / 6 failed, log is in exp/tri4b_dnn/decode_test_phone/log/decode.*.log
run.pl: 6 / 6 failed, log is in exp/tri4b_dnn/decode_test_word/log/decode.*.log
steps/nnet/align.sh: done aligning data.
steps/nnet/make_denlats.sh --nj 6 --cmd run.pl --mem 4G --config conf/decode_dnn.config --acwt 0.1 data/fbank/train data/lang exp/tri4b_dnn exp/tri4b_dnn_denlats
Making unigram grammar FST in exp/tri4b_dnn_denlats/lang
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
sym2int.pl: replacing = with 2
sym2int.pl: replacing l with 2
....
PyTorch-Kaldi
前面我们了解了Kaldi的基本用法,Kaldi最早设计是基于HMM-GMM架构的,后来通过引入DNN得到HMM-DNN模型。但是由于Kaldi并不是一个深度学习框架,我们如果想使用更加复杂的深度学习算法会很困难,我们需要修改Kaldi里的C++代码,需要非常熟悉其代码才能实现。而且我们可能需要自己实现梯度计算,因为它不是一个Tensorflow或者PyTorch这样的框架。这样就导致想在Kaldi里尝试不同的深度学习(声学)模型非常困难。而PyTorch-Kaldi就是为了解决这个问题,它的架构如图下图所示,它把PyTorch和Kaldi完美的结合起来,使得我们可以把精力放到怎么用PyTorch实现不同的声学模型,而把PyTorch声学模型和Kaldi复杂处理流程结合的dirty工作它都帮我们做好了。
因为PyTorch-Kaldi还是一个比较早期的项目,本书就不详细介绍它了,感兴趣的读者可以去这里了解更多内容。
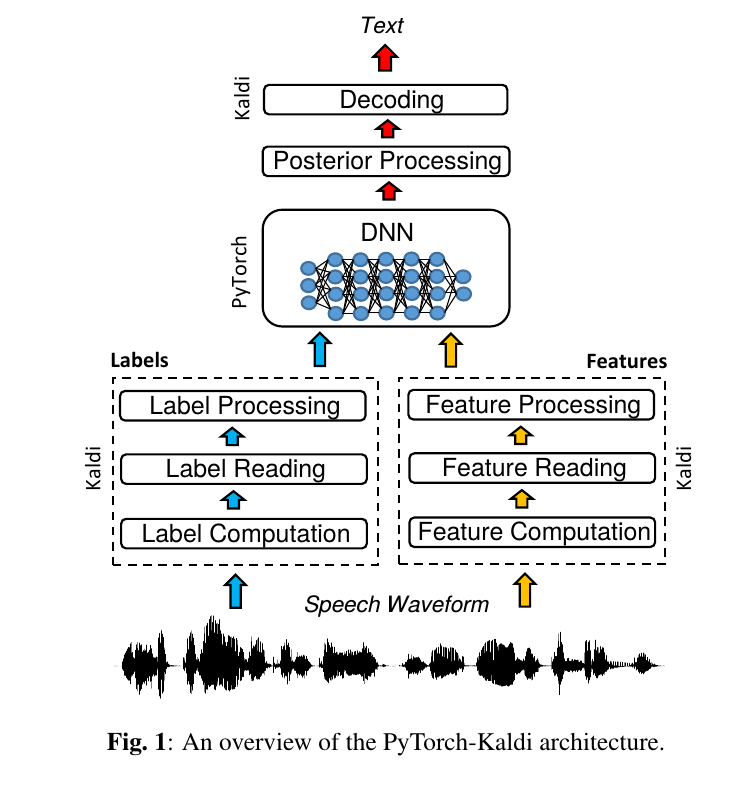 图:PyTorch-Kaldi架构
图:PyTorch-Kaldi架构
- 显示Disqus评论(需要科学上网)