本文介绍传统的N-Gram语言模型和RNN语言模型。
目录
简介
我们来看语言模型的定义。首先我们需要定义一个词典$\mathcal{V}$,比如对于英语,它的词典可能是: \(\mathcal{V}=\{the, dog, laughs, saw, barks, cat, . . .\}\)
通常$\mathcal{V}$都会比较大,几千甚至几万,但不管怎样通常都是有限的一个集合。接下来我们定义句子,一个句子就是词的序列:$x_1x_2…x_n$,其中$n \le 1$,对于$i \in {1…(n-1)}$,$x_i \in \mathcal{V}$。同时我们假设$x_n$总是等于一个特殊符号STOP。我们后面会解释为什么句子的最后一个词总是STOP的原因。下面是一些句子的示例:
- the dog barks STOP
- the STOP
- STOP
我们用符号$\mathcal{V}^{+}$来表示由词典$\mathcal{V}$产生的所有句子,这是一个无限的集合,虽然词典的元素是有限的,但是句子的长度是可以无限的。下面是语言模型的定义。语言模型由一个有限集合$\mathcal{V}$和一个函数$p(x_1, x_2, …, x_n)$,它满足如下条件:
- 对于任意的$<x_1, x_2, …, x_n> \in \mathcal{V}^{+}, p(x_1, x_2, …, x_n) \le 0$
- $\sum_{<x_1, x_2, …, x_n> \in \mathcal{V}^{+}}p(x_1, x_2, …, x_n)=1$
因此$p(x_1, x_2, …, x_n)$是$\mathcal{V}$上的所有句子的概率分布。
一种最简单(但很差)的语言模型可以这样定义:$p(x_1, x_2, …, x_n)=\frac{c(x_1, x_2, …, x_n)}{N}$,其中$c(x_1, x_2, …, x_n)$是训练数据中句子$x_1x_2…x_n$出现的次数,而N是训练数据里句子总数。这个模型很不好,因为如果某个句子没有在训练数据里出现过(即使训练数据里有和它很像但不完全一样的句子),那么它的概率就是0。比如前面的示例,$p(the\;dog \; barks\; STOP)=\frac{1}{3}$,但是$p(a\; dog\; barks\; STOP)$的概率就是零,这显然是有问题的。
马尔科夫模型
现在我们的问题是怎么根据训练数据集学习出函数p。我们这里介绍使用马尔科夫模型来表示和学习概率分布p。
定长序列的马尔科夫模型
我们首先考虑固定长度的句子的语言模型。假设句子的长度是n,序列为$X_1, X_2, …, X_n$,其中$X_i \in \mathcal{V}$。对于这个序列的每一种取值$x_1…x_n$,我们需要计算$P(X_1=x_1, X_2=x_2, …, X_n=x_n)$,所有可能的取值组合数为$|\mathcal{V}|^{n}$。如果我们想列举所有的可能,这是很难做到的,我们需要更加紧凑的表示方法。在一阶马尔科夫模型里,我们假设每个词的概率只依赖于它之前的词,而与其它词无关:
\[\begin{split} & P(X_1=x_1, X_2=x_2, ..., X_n=x_n) \\ & = P(X_1=x_1) \prod_{i=2}^{n}P(X_i=x_i|X_1=x_1,...,X_{i-1}=x_{i-1}) \\ & = P(X_1=x_1) \prod_{i=2}^{n}P(X_i=x_i|X_{i-1}=x_{i-1}) \end{split}\]上式的第一步使用链式法则,而第二步使用了一阶马尔科夫假设——第i个词只依赖前一个词。我们也可以做二阶的假设——i时刻的词依赖于i-1和i-2时刻:
\[\begin{split} & P(X_1=x_1, X_2=x_2, ..., X_n=x_n) \\ & = P(X_1=x_1) \prod_{i=2}^{n}P(X_i=x_i|X_1=x_1,...,X_{i-1}=x_{i-1}) \\ & = \prod_{i=1}^{n}P(X_i=x_i|X_{i-2}=x_{i-2}, X_{i-1}=x_{i-1}) \end{split}\]这里为了把$X_1$和$X_2$也写成条件概率的形式,假设$X_{-1}$和$X_{0}$等于特殊单词*,它表示句子的开始。
变长序列的马尔科夫模型
前面的例子假设句子的长度为固定的n,如果使用最大似然估计,我们如果把所有长度为n的句子的概率加起来是1。这样长度不为n的句子就没有概率了。那怎么建模所有长度的句子呢?这里有一个简单的方法——使用一个特殊的STOP符号。
我们用“生成”一个句子来看这个STOP的作用,以一阶的模型为例。我们首先生成第一个词$p(X_1=x_1 \vert X_0=*)$,这里$X_1 \in \mathcal{V} \cup {STOP}$。因此长度为1的句子的概率为$1-p(STOP \vert *)$,然后我们再根据第一个词生成第二个词$p(X_2=x_ \vert X_1=x_1)$,…,这样所有长度的句子都有一定的概率。
在这里,我们假设一个句子总是以STOP结尾,因此对于二阶的马尔科夫假设,我们有:
\[p(X_1=x_1, X_2=x_2, ..., X_n=x_n)=\prod_{i=1}^{n}p(X_i=x_i|X_{i-2}=x_{i-2},X_{i-1}=x_{i-1})\]上式中$X_n$一定是STOP。
Trigram语言模型
Trigram语言模型包括一个词典集合$\mathcal{V}$和参数$q(w \vert u,v)$,其中\(w \in \mathcal{V} \cup \{ STOP \}\),\(u,v \in \mathcal{V} \cup \{*\}\)。
$q(w \vert u, v)$可以认为是看到bigram(u,v)之后出现w的概率。Trigram可以计算一个句子$x_1,x_2,…,x_n(=STOP)$的概率:
\[p(x_1, x_2, ..., x_n)=\prod_{i-1}^{n}q(x_i|x_{i-2},x_{i-1})\]其中$x_{-1}=x_0=*$。比如句子”the dog barks STOP”的概率可以这样计算:
\[\begin{split} & p(\text{the dog barks STOP}) \\ & = q(the|*, *) \times q(dog|*, the) \times q(barks|the, dog) \times q(STOP|dog, barks) \end{split}\]为了满足概率的定义,我们要求对于任意的u,v,w,满足$q(w|u,v) \le 0$,并且对于任意的u,v,满足:
\[\sum_{w \in \mathcal{V} \cup \{STOP\} } q(w|u,v)=1\]接下来需要解决的关键问题是怎么通过训练数据估计出$q(w|u,v)$,假设$\vert \mathcal{V} \vert =10,000$,那么$q(w|u,v)$的可能取值是$\vert \mathcal{V} \vert ^3=10^{12}$,虽然实际在训练数据中很多没出现,但是这个值也是非常大的。
我们可以用最简单的最大似然估计方法来估计trigram的参数。我们首先定义c(u,v,w)为trigram (u, v, w)在训练集上出现的次数。类的c(u,v)为bigram (u,v)在训练集上出现的次数。那么$q(w \vert u,v)$的最大似然估计为:$\frac{c(u,v,w)}{c(u,v)}$。比如我们要估计$q(barks \vert the, dog)$,那么它的计算公式为:
\[q(barks|the, dog)=\frac{c(\text{the dog barks})}{c(\text{the dog})}\]它的意义很简单:我们要估计barks出现在(the,dog)后的概率,我们数一数(the,dog)出现了多少次,然后再数数(the, dog, barks)出现了多少次,两个数一除就计算出来了。但是最大似然估计有一个问题,它的分子很可能为零。一个trigram在训练数里不出现不代表它的概率就为零。此外分母也可能为零,那么这个概率就不是合法的定义(well-defined)。
语言模型的平滑
有很多平滑的方法,我们这里介绍discount的方法。为了简单我们用bigram为例子来说明其原理。它的想法很简单,除了训练集中出现的bigram,还有很多合理的bigram并没有在训练集合里出现,因此如果我们使用最大似然估计,我们会“高估”$p(w|v)=\frac{c(v,w)}{c(v)}$。discount的思路是给c(v,w)打个折扣,把多出来的概率分给没有出现过的bigram。如果c(v,w)>0(说明(v,w)在训练集上出现过),那么我们计算\(c^{*}(v,w)=c(v,w)-\beta\),其中$\beta$是一个0-1之间的数。我们用这个打折后的\(c^{*}(v,w)\)来计算$p(w|v)$:
\[p(w|v)=\frac{c^{*}(v,w)}{c(v)}\]原来我们有$\sum_wp(w|v)=\sum_w \frac{c(v,w)}{c(v)}=\frac{c(v)}{(c(v))}=1$,现在打折后$\sum_wp(w|v)<1$,多余的概率为:
\[\alpha(v)=1-\sum_{w:c(v,w)>0}\frac{c^{*}(v,w)}{c(v)}\]这些概率可以分配给没有在训练数据中出现的(v,w’),那怎么分配呢?最简单的是平均分配,但是不同的$p(w’ \vert v)$是不同的。一个简单的想法就是如果w’出现的概率大,那么$p(w’ \vert v)$也可能大。因此对于那些c(v,w’)=0的w’来说,我们可以根据\(q_{ML}(w')\)来分配$\alpha(v)$。为了形式化的用数学公式来描述,我们首先定义如下两个集合:
\[\begin{split} \mathcal{A}(v)=\{w|c(v,w)>0\} \\ \mathcal{B}(v)=\{w|c(v,w)=0\} \end{split}\]根据c(v,w)是否出现过把w划分为了两个集合,对于这两个集合中的w,使用不同的方法来计算$p(w|v)$。
\[q_D(w|v)=\begin{cases} \frac{c^{*}(v,w)}{c(v)} & \text{If }w \in \mathcal{A}(v) \\ \alpha(v) \times \frac{q_{ML}(w)}{\sum_{w \in \mathcal{B}(v)} q_{ML}(w)} & \text{If }w \in \mathcal{B}(v) \end{cases}\]对于trigram,我们可以使用类似的discount策略。对trigram c(u,v,w)进行打折,留一些概率给没有出现的(u,v,w’)。这些概率的时候可以用前面我们估计的$q_D(w’|v)$来分配。打折后$c^{*}(u,v,w)=c(u,v,w)-\beta$。和前面类似,我们根据(u,v,w)是否出现分成如下两个集合:
\[\begin{split} \mathcal{A}(u,v)=\{w|c(u,v,w)>0\} \\ \mathcal{B}(u,v)=\{w|c(u,v,w)=0\} \end{split}\]打折后剩余的概率\(\alpha(u,v)=1-\sum_{w \in \mathcal{A}(u,v)} \frac{c^{*}(u,v,w)}{c(u,v)}\)
\[q_D(w|u,v)=\begin{cases} \frac{c^{*}(u,v,w)}{c(u,v)} & \text{If }w \in \mathcal{A}(u,v) \\ \alpha(u,v) \times \frac{q_{ML}(w)}{\sum_{w \in \mathcal{B}(u,v)} q_D(w|v)} & \text{If }w \in \mathcal{B}(v) \end{cases}\]语言模型的评价标准
语言模型通常使用perplexity(PPL)来评价,PPL的计算公式如下:
\[PPL=2^{-\frac{1}{M}\sum_{i=1}^{m}log_2p(x_i)}\]其中m是句子的个数,M是语料库中单词的个数$M=\sum_{i=1}^{m}n_i$。$p(x_i)$是语言模型输出的这个句子的概率。有时候我们的模型输出是自然对数为底的概率,则我们可以这样计算:
\[PPL=e^{-\frac{1}{M}\sum_{i=1}^{m}log_ep(x_i)}\]这两者是相等的,有兴趣的读者可以自己证明一下。
RNN语言模型
简介
n-gram语言模型问题之一是不能利用长距离的信息,在实际的场景中,由于模型参数过多,5-gram基本就是极限了。另外一个问题就是它的泛化能力差,因为它完全基于词的共现。比如训练数据中有”我 在 北京”,但是没有”我 在 上海”,那么$p(上海|在)$的概率就会比$p(北京|在)$小很多。但是我们人能知道”上海”和”北京”有很多相似的地方,作为一个地名,都可以出现在”在”的后面。
因此我们可以用word embedding的技术来解决第二个问题,而第一个问题可以使用RNN(LSTM/GRU)模型来解决。如下图所示,给定一个句子”what is the problem”,我们可以构造训练数据——输入”what is the”和输出序列”is the problem”。然后使用RNN根据之前的词来预测当前词。RNN/LSTM/GRU我们都介绍过了,因此下面通过代码来了解RNN语言模型的实现
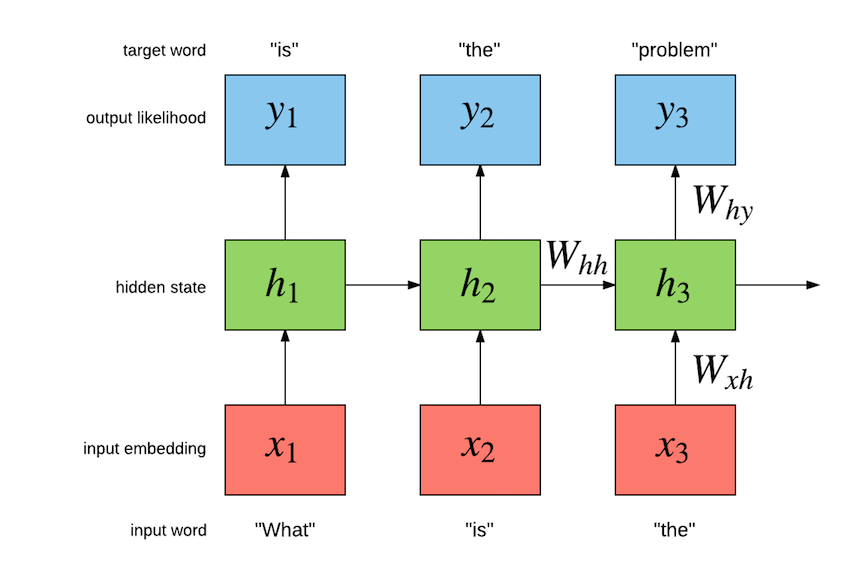 图:RNN语言模型
图:RNN语言模型
代码
完整代码在这里目录下。
reader.py
我们首先看语言模型的训练数据是什么格式以及怎么读取的。原始的数据可以在http://www.fit.vutbr.cz/%7Eimikolov/rnnlm/simple-examples.tgz下载。下载解压后数据在data目录下,这个目录包含如下文件:
~/data/simple-examples/data$ ls -1
ptb.char.test.txt
ptb.char.train.txt
ptb.char.valid.txt
ptb.test.txt
ptb.train.txt
ptb.valid.txt
README
我们用到的训练数据,验证数据和测试数据分别是ptb.train.txt、ptb.valid.txt和ptb.test.txt。另外3个文件是训练char的语言模型用的,我们暂时用不到。这些文件的格式都是一行一个句子的文本文件。比如ptb.train.txt的前3行:
1 aer banknote berlitz calloway centrust cluett fromstein gitano guterman hydro-quebec ipo kia memotec mlx nahb punts rake regatta rubens sim snack-food ssangyong swapo wachter
2 pierre <unk> N years old will join the board as a nonexecutive director nov. N
3 mr. <unk> is chairman of <unk> n.v. the dutch publishing group
这里有一个特殊的词
我们首先来看ptb_raw_data函数,它的输入是data目录,输出是3个list,每个list里都是整数,表示词的id,其中换行会被替换成特殊的词
def ptb_raw_data(data_path=None):
train_path = os.path.join(data_path, "ptb.train.txt")
valid_path = os.path.join(data_path, "ptb.valid.txt")
test_path = os.path.join(data_path, "ptb.test.txt")
word_to_id = _build_vocab(train_path)
train_data = _file_to_word_ids(train_path, word_to_id)
valid_data = _file_to_word_ids(valid_path, word_to_id)
test_data = _file_to_word_ids(test_path, word_to_id)
vocabulary = len(word_to_id)
return train_data, valid_data, test_data, vocabulary
接下来的ptb_producer函数会用上一个函数返回的list生成一个iterator。这个iterator每次返回一个[batch_size, num_steps]的数据。
def ptb_producer(raw_data, batch_size, num_steps, name=None):
"""PTB data上的iterator
参数:
raw_data: 来自ptb_raw_data函数
batch_size: batch size.
num_steps: 训练时的句子长度
name: 名字
返回:
返回两个tensor,每个的shape是[batch_size, num_steps]。
比如句子是 it is a good day。那么第一个tensor是"it is a good";第二个是"is a good day"。
"""
with tf.name_scope(name, "PTBProducer", [raw_data, batch_size, num_steps]):
raw_data = tf.convert_to_tensor(raw_data, name="raw_data", dtype=tf.int32)
data_len = tf.size(raw_data)
batch_len = data_len // batch_size
data = tf.reshape(raw_data[0 : batch_size * batch_len],
[batch_size, batch_len])
epoch_size = (batch_len - 1) // num_steps
assertion = tf.assert_positive(
epoch_size,
message="epoch_size == 0, decrease batch_size or num_steps")
with tf.control_dependencies([assertion]):
epoch_size = tf.identity(epoch_size, name="epoch_size")
i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue()
x = tf.strided_slice(data, [0, i * num_steps],
[batch_size, (i + 1) * num_steps])
x.set_shape([batch_size, num_steps])
y = tf.strided_slice(data, [0, i * num_steps + 1],
[batch_size, (i + 1) * num_steps + 1])
y.set_shape([batch_size, num_steps])
return x, y
it is a good day <eos> I am <unk> of that <eos> ..... it is funny <eos>
假设文本总共有203个词(跟多少个句子没有关系),batch_size=4。那么data_len=50,也就是把203个词切分成4段,每段50个(连续的)词。data就是4*50=200个词,然后reshape成[batch_size(4), data_len(50)]:
data = tf.reshape(raw_data[0 : batch_size * batch_len],
[batch_size, batch_len])
如果LSTM的长度是num_steps(10),那么50个单词可以产生(50-1)//10=4个batch的数据。为什么要减一呢?因为我们的预测数据需要把输入数据后移一个时刻。比如句子是”It is a good day”,那么输入是”It is a good”,输出是”is a good day”。
epoch_size = (batch_len - 1) // num_steps
理解了这个,后面的代码就很容易了。我们产生一个大小是epoch_size(4)的range_input_producer,然后用strided_slice得到对于的x和y。
i = tf.train.range_input_producer(epoch_size, shuffle=False).dequeue()
x = tf.strided_slice(data, [0, i * num_steps],
[batch_size, (i + 1) * num_steps])
x.set_shape([batch_size, num_steps])
y = tf.strided_slice(data, [0, i * num_steps + 1],
[batch_size, (i + 1) * num_steps + 1])
y.set_shape([batch_size, num_steps])
return x, y
在产生第i个batch的时候,我们给strided_slice的参数是[0, i * num_steps], [batch_size, (i + 1) * num_steps],它截取的起点是第0行和第(i * num_steps)列,终点(不包含)是第batch_size行和第(i+1) * num_steps列。而y的列下标是x加1。
从代码我们可以看出,训练语言模型是并不是以“句子”为基本单位,而是把固定长度的num_steps个词作为一次训练。句子之间会有
定义模型
模型的代码主要在PTBModel这个类的构造函数中定义,下面是部分重要代码:
with tf.device("/cpu:0"):
embedding = tf.get_variable(
"embedding", [vocab_size, size], dtype=data_type())
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
if is_training and config.keep_prob < 1:
inputs = tf.nn.dropout(inputs, config.keep_prob)
output, state = self._build_rnn_graph(inputs, config, is_training)
softmax_w = tf.get_variable(
"softmax_w", [size, vocab_size], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=data_type())
logits = tf.nn.xw_plus_b(output, softmax_w, softmax_b)
# 从[batch*time, vocab_size]reshpae成[self.batch_size, self.num_steps, vocab_size]
logits = tf.reshape(logits, [self.batch_size, self.num_steps, vocab_size])
# 计算loss
loss = tf.contrib.seq2seq.sequence_loss(
logits,
input_.targets,
tf.ones([self.batch_size, self.num_steps], dtype=data_type()),
average_across_timesteps=False,
average_across_batch=True)
self._cost = tf.reduce_sum(loss)
self._final_state = state
代码首先定义embedding矩阵[vocab_size, size],然后对输入使用tf.nn.embedding_lookup函数进行embedding。输入是[batch_size, num_steps],每个元素是一个整数,代表词对于的id;输出是[batch_size, num_steps, size]。
如果是训练阶段并且keep_prob<1的话,就会对inputs再加一层dropout。然后使用_build_rnn_graph函数构造RNN,这个函数返回两个值,一个是output,一个是state。这两个值分别表示RNN的输出和最后一个时刻的隐状态,其中output的shape是[batch_size*num_steps, hidden_size(200)]。而state是一个tuple,分别表示c和h,它们的shape都是[num_layers, batch_size, hidden_size]。
接着我们定义softmax_w和softmax_b,把输出从hidden_size变成vocab_size,这就得到了logits,它的shape是[batch_size*num_steps, vocab_size],然后我们再把logits reshape成[batch_size, num_steps, vocab_size]。最后我们通过tf.contrib.seq2seq.sequence_loss来计算loss,这个函数的参数为:
- logits shape是[batch_size, sequence_length, num_decoder_symbols],dtype是float
- targets 真实的label序列,shape是[batch_size, sequence_length],dtype要求是int
- weights 计算loss时label的权重,如果要实现padding,那么可以把padding的地方设置为零。shape是[batch_size, sequence_length],dtype是float
- average_across_timesteps 如果是True,那么返回的loss会对timestep这个维度进行求平均值
- average_across_batch 如果是True,返回的loss会对batch这个维度求平均值
- softmax_loss_function 如果None,使用默认的softmax函数,调用的时候也可以自己提供以softmax函数
- name
前两个参数很容易理解,第3个参数一般用来实现mask的功能。对于很多序列问题,一个batch的数据每个训练样本的num_steps是不一样的,我们通常会用一个最大的长度来padding,但是在计算loss的时候,这些padding的地方不应该算到loss里,这个时候我们可以使用weights参数,把padding的地方设置成零,而没有padding的地方设置成1。average_across_timesteps设置是否对loss进行时间维度的平均,而average_across_batch设置是否对batch维度进行平均。
我们这里调用时weights就是一个shape和targets一样的全为1的tensor,因为我们这里是没有padding的。这里我们调研时average_across_timesteps是False,而average_across_batch是True,因此它之后对batch求平均。为什么不对时间求平均呢?因为我们需要把所有时间维度的都加起来然后再求平均,所有这个求平均放在后面的run_epoch函数里:
for step in range(model.input.epoch_size):
# 省略了feed_dict的构建
vals = session.run(fetches, feed_dict)
cost = vals["cost"]
costs += cost
iters += model.input.num_steps
ppl = np.exp(costs / iters)
对训练数据的一次遍历需要epoch_size次,每次访问num_steps个词,因此对于时间维度的平均放到最后ppl的计算上。接下来我们介绍最关键的函数_build_rnn_graph:
def _build_rnn_graph(self, inputs, config, is_training):
if config.rnn_mode == CUDNN:
return self._build_rnn_graph_cudnn(inputs, config, is_training)
else:
return self._build_rnn_graph_lstm(inputs, config, is_training)
它会根据配置config的rnn_mode是否是CUDNN来决定使用CudnnLSTM还是普通的LSTM(也可以通过配置选择BasicLSTMCell或者LSTMBlockCell)。如果有GPU可以在运行的时候加上”–rnn_mode=cudnn”。我们先看_build_rnn_graph_lstm函数:
def _build_rnn_graph_lstm(self, inputs, config, is_training):
def make_cell():
cell = self._get_lstm_cell(config, is_training)
if is_training and config.keep_prob < 1:
cell = tf.contrib.rnn.DropoutWrapper(
cell, output_keep_prob=config.keep_prob)
return cell
cell = tf.contrib.rnn.MultiRNNCell(
[make_cell() for _ in range(config.num_layers)], state_is_tuple=True)
self._initial_state = cell.zero_state(config.batch_size, data_type())
state = self._initial_state
# 手动unroll来实现tf.nn.static_rnn()。
# 这里手动实现unroll的目的是为了展示怎么手动实现。
# 实际使用是应该用tf.nn.static_rnn()或者tf.nn.static_state_saving_rnn().
#
# 实际我们应该使用如下代码:
#
# inputs = tf.unstack(inputs, num=self.num_steps, axis=1)
# outputs, state = tf.nn.static_rnn(cell, inputs,
# initial_state=self._initial_state)
outputs = []
with tf.variable_scope("RNN"):
for time_step in range(self.num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
output = tf.reshape(tf.concat(outputs, 1), [-1, config.hidden_size])
return output, state
这个函数首先定义一个函数make_cell,它会调用self._get_lstm_cell来根据不同的配置生成不同的RNNCell。然后根据是否有dropout来使用DropoutWrapper对RNNCell进行wrapping。这个在Tensorflow的章节都有详细介绍,忘记了的话可以参考相关内容。
然后用MultiRNNCell来生成多层的RNN。接着用cell.zero_state来生成初始化状态。使用RNNCell.zero_state而不是自己构造初始状态的好处是我们不需要关心RNNCell到底是LSTM还是GRU,到底是单向的还是双向的,到底有几层。这些参数RNNCell都知道,它自己会帮助我们计算,我们只需要告诉它batch大小(因为它不知道batch大小)和dtype就行。然后我们就可以使用static_rnn来构造静态unroll的RNN。但是这里的代码为了教学目的使用了手动展开的方式,我们简单的了解一下即可,实际的工作中我们应该使用注释掉的代码。
接下来的_get_lstm_cell函数根据配置来构造BasicLSTMCell或者LSTMBlockCell:
def _get_lstm_cell(self, config, is_training):
if config.rnn_mode == BASIC:
return tf.contrib.rnn.BasicLSTMCell(
config.hidden_size, forget_bias=0.0, state_is_tuple=True,
reuse=not is_training)
if config.rnn_mode == BLOCK:
return tf.contrib.rnn.LSTMBlockCell(
config.hidden_size, forget_bias=0.0)
raise ValueError("rnn_mode %s not supported" % config.rnn_mode)
通常LSTMBlockCell会比BasicLSTMCell更快,而且它们两者的用法完全一样,因此建议使用LSTMBlockCell。接下来我们看看_build_rnn_graph_cudnn,如果有GPU,默认会调用这个函数。
def _build_rnn_graph_cudnn(self, inputs, config, is_training):
inputs = tf.transpose(inputs, [1, 0, 2])
self._cell = tf.contrib.cudnn_rnn.CudnnLSTM(
num_layers=config.num_layers,
num_units=config.hidden_size,
input_size=config.hidden_size,
dropout=1 - config.keep_prob if is_training else 0)
params_size_t = self._cell.params_size()
self._rnn_params = tf.get_variable(
"lstm_params",
initializer=tf.random_uniform(
[params_size_t], -config.init_scale, config.init_scale),
validate_shape=False)
c = tf.zeros([config.num_layers, self.batch_size, config.hidden_size],
tf.float32)
h = tf.zeros([config.num_layers, self.batch_size, config.hidden_size],
tf.float32)
self._initial_state = (tf.contrib.rnn.LSTMStateTuple(h=h, c=c),)
outputs, h, c = self._cell(inputs, h, c, self._rnn_params, is_training)
outputs = tf.transpose(outputs, [1, 0, 2])
outputs = tf.reshape(outputs, [-1, config.hidden_size])
return outputs, (tf.contrib.rnn.LSTMStateTuple(h=h, c=c),)
这个函数会使用CudnnLSTM,注意这个函数构造的是一个完整的LSTM层而不是一个RNNCell,因此它不需要使用static_rnn或者dynamic_rnn来unroll,这个函数都帮我们做好了。因为cudnnLSTM需要的输入是时间主序的,因此我们首先把输入从[batch_size, num_steps, hidden_size] transpose成[num_steps, batch_size, hidden_size]。
接下来使用函数CudnnLSTM,我们需要传入num_layers、num_units、input_size和dropout,这几个参数都很容易理解。这里我们的输入(input_size)和隐单元(num_units)是一样的大小,但是这不是必须的。上面的CudnnLSTM函数只是定义了LSTM的配置,但是并没有真正的在Graph里构造相应operation,真正的构造在调用CudnnLSTM的__call__方法时,也就是outputs, h, c = self._cell(inputs, h, c, self._rnn_params, is_training),调用这个方法需要传入inputs,初始的hidden和cell state和is_training,以及LSTM的参数变量。
注意我们需要自己创建LSTM需要的变量,那么它需要的变量的shape是多大呢?我们可以通过self._cell.params_size()得到。然后构造这样一个shape的变量。调用过_cell之后,我们它的输出也是[num_steps, batch_size, hidden_size],我们需要再次transpose回去变成[batch_size, num_steps, hidden_size]。然后再reshape成[batch_size*num_steps, hidden_size]便于后面的loss的计算(同样也保持和_build_rnn_graph_lstm函数的一致)。
- 显示Disqus评论(需要科学上网)