本文介绍目标检测的常见算法,包括R-CNN、Fast R-CNN、Faster R-CNN和FPN。更多文章请点击深度学习理论与实战:提高篇。
目录
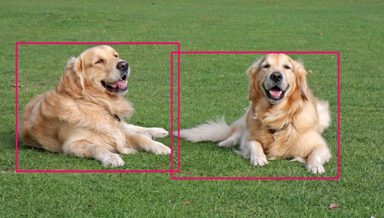 图:目标检测
图:目标检测
我们之前介绍的CNN可以识别一个图片是否有猫或者狗,但是Object Detection不但要判断图片中是否有猫或者狗(或者同时有猫和狗),而且还需要定位它们在图片中的位置,输出一个Bounding Box(x, y, width, height)来告诉我们这个物体的具体位置。问题的难点在于物体可能出现在图片的任意位置,而且它的大小也是不固定的。下面我们介绍一些用于目标检测任务的算法。
R-CNN
R-CNN是“Region-based Convolutional Neural Networks”的缩写,这里是原论文。它包括三个部分:
- 生成物体类别无关的Region proposal的模块。这里没有任何神经网络,它使用图像处理的技术产生可能包含物体的候选区域
- 一个CNN来提取固定大小的特征。这个CNN只是用来提取特征。
- 每个类别都有一个线性的SVM分类器来判断候选区域是否属于这个类别
它的思路比较简单:首先我们找到可能包含物体的区域,然后用目标识别(Object Recogntion)算法来判断它是否属于猫,是否属于狗,然后选择概率最高的输出。不过和目标识别任务有一点不同在于:目标识别我们假设一张图片一定包含某个目标,比如ImageNet的图片一定是1000个分类中的某一个;但是一个候选的区域里可能不包含1000个分类中的任何物体,因此需要一个”background”类来表示1000个分类之外的物体。
Region Proposal算法的输入是一张图片,输出是多个可能包含物体的区域。为了保证不漏过可能的物体,Region Proposal可能会输出并不包含物体的区域,当然有的区域也可能包含物体的一部分,或者某些区域虽然包含物体,但是它也包含了很多物体之外的内容。这些区域大小是不固定的,可能它们直接可能会重叠。一个“好”的Region Proposal算法应该召回率要高(不漏过),准确率也要高(不输出明显不包含物体的区域),当然最理想的情况是图片中有几个物体,它就输出这些物体的Bounding Box。不过这是不可能也是没必要的,否则它就已经完成了目标检查的任务了!准确判断图片是否包含物体会由物体识别算法(比如CNN)来完成,因此Region Proposal算法的主要目标是在高召回率的前提下保证一定的准确率。另外它的计算速度也不能太慢。
如下图所示,Region Proposal算法可能会输出蓝色的区域,它们可能只包含物体的一部分。我们的物体识别算法输出的概率没有绿色区域的高,而且它们又有重叠,因此我们最终会判定绿色的区域是包含物体的区域。
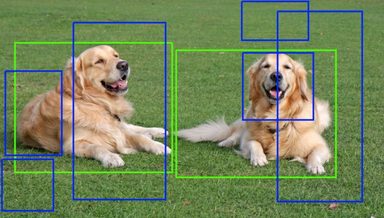 图:Region Proposal
图:Region Proposal
Region Proposal
最简单的的Region Proposal就是滑动窗口,但是于物体的大小不是固定的,因此我们需要穷举所有可能,这样的计算量会非常大。因此我们需要更好的算法。有很多算法用于Region Proposal,R-CNN使用的是seletive search算法。
selective search算法首先使用基于图的图像分割算法,根据颜色对图像进行分割。如下图所示,左边是原图,而右图是分割之后的图。
| 原图 | 分割后的图 |
|---|---|
 |
 |
那我们能不能直接把分割处理的区域作为后续的区域呢?答案是否定的,原因是:
- 很多物体可能包含多个区域
- 有遮挡的物体,比如咖啡杯里有咖啡,这个方法是无法分割出来的
当然我们可以通过聚类再生成包含物体的区域,但是这些区域通常会包含目标物体之外的其它物体。我们的目标并不是需要实现物体切分,而是用来生成可能包含物体的候选区域。因此我们会把原来的图片做更细(oversegment)的切分,如下图所示,然后通过聚类的方法来生成更多的候选区域。
 图:Oversegmented图片
图:Oversegmented图片
由oversegmented图片生成候选区域的算法为:
- 所有细粒度的分隔都加到候选区域里(当然分割不是矩形区域我们需要把它变成矩形区域)
- 在候选区域里根据相似度把最相似的区域合并,然后加到候选区域里。
- 回到1不断的重复这个过程
通过上面的步骤,我们不断得到越来越大的区域,最终整个图片就是一个最大的候选区域。而计算两个区域的相似度会考虑颜色、纹理、大小和形状等特征来计算,这里就不赘述了,有兴趣的读者可以参考论文”Selective Search for Object Recognition”。
下面我们使用opencv来实现selective search。这个算法是在contrib包里,所有需要使用命令pip install opencv-contrib-python来安装。
import sys
import cv2
print(cv2.__version__)
if __name__ == '__main__':
# 使用多线程加速
cv2.setUseOptimized(True);
cv2.setNumThreads(4);
# 读取图片
im = cv2.imread(sys.argv[1])
# resize图片
newHeight = 200
newWidth = int(im.shape[1] * 200 / im.shape[0])
im = cv2.resize(im, (newWidth, newHeight))
# 这行代码创建一个Selective Search Segmentation对象,使用默认的参数。
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# 设置应用算法的图片
ss.setBaseImage(im)
# fast模式,速度快,但是召回率低
if (sys.argv[2] == 'f'):
ss.switchToSelectiveSearchFast()
# 高召回率但是速度慢
elif (sys.argv[2] == 'q'):
ss.switchToSelectiveSearchQuality()
else:
print(__doc__)
sys.exit(1)
# 实际运行算法
rects = ss.process()
print('Total Number of Region Proposals: {}'.format(len(rects)))
# 只显示100个区域
numShowRects = 100
# increment to increase/decrease total number
# of reason proposals to be shown
increment = 50
while True:
# create a copy of original image
imOut = im.copy()
# itereate over all the region proposals
for i, rect in enumerate(rects):
# draw rectangle for region proposal till numShowRects
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle(imOut, (x, y), (x + w, y + h), (0, 255, 0),
1, cv2.LINE_AA)
else:
break
# show output
cv2.imshow("Output", imOut)
cv2.destroyAllWindows()
 图:opencv实现selective search的效果
图:opencv实现selective search的效果
如果不想安装opencv,那么也可以使用纯Python的开源实现。通过pip install selectivesearch安装后就可以使用。
特征提取
因为论文发表的时间是2014年,使用使用比较简单的alex网络来提取特征,当然我们也可以使用更加复杂的网络来提取特征。论文提取的特征是4096维特征。因为ImageNet训练数据的输入是227x227的GRB图像,而Region Proposal出来的图像什么大小的都有,因此我们需要把它缩放成227x227的。当然原始论文在处理缩放时还有一些细节,包括是否要包含一些context。
检测
每个候选区域都提取成4096维特征之后,我们可以用SVM分类器来判断它是否是猫,是否是狗。因为候选区域可能会有重叠,因此最后会使用non-maximum suppression方法来去掉重复的区域。比如有3个候选区域被判断成猫了,那么有5种可能——三个区域其实都是同一只猫;也可能是三个区域分别是三只不同的猫,当然也可能两个区域是一只猫而另一个区域是另外一只猫。non-maximum suppression其实也很简单,首先找到打分最高的区域,判定它是一只猫,然后再看得分第二高的区域,看它和以判定为猫的区域(最高的区域)的交并比(IoU,暂时可以理解为重叠的比例)是否大于一个阈值(比如0.5),如果大于则认为它是已知的猫而不是一只”新“猫,否则认为它是一个新猫加到猫列表里。接着再用类似的方法判断第三个区域的猫是否”新“猫。注意non-maximum suppression它是对每个类别来说的,如果两个区域很重叠,但是分类器分别判断为猫和狗(猫和狗抱在一起?),那么是不会suppress的。
IoU(Intersection over union)是两个区域的交集的大小比上两个区域的并集的大小,如下图所示。
\[IoU=\frac{|A \cup B|}{|A \cap B|}\]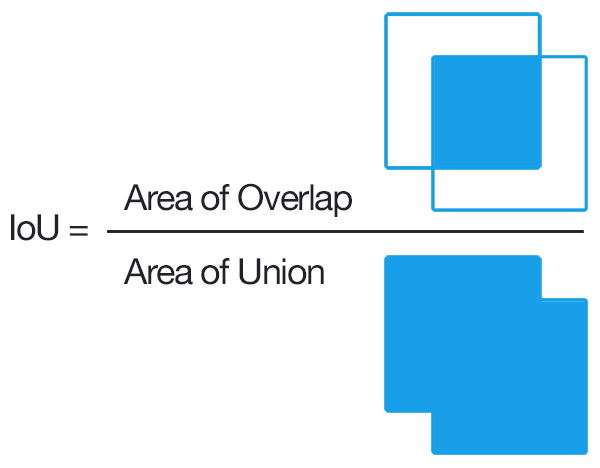 图:IoU示意图
图:IoU示意图
训练
由于标注了Bounding box的训练数据较少,因此首先使用ILSVRC2012的所有图片进行Pretraining,然后使用标注的数据进行fine-tuning。因为ImageNet的图片是1000类的,而目标检测的类别是不同的,比如VOC数据集只有20类,而ILSVRC2013的检测任务类别是200类。因此我们把最后一个softmax换掉来进行fine-tuning。fine-tuning的数据怎么获得呢?比如对于一张图片,我们可能标注了(100,100,50,40)这个矩形区域是一条狗。我们可以使用Region Proposal算法找出很多候选的区域,如果一个候选区域和标注的区域的IoU大于某个阈值(比如0.5),那么我们就认为这个区域就是狗,否则就不是狗。然后使用这些数据来fine-tuning这个卷积网络。
接下来是给每个类别训练一个二分类的SVM分类器,它的输入就是上面的卷积网络的最后一个全连接层(4096)。这个分类器的训练数据怎么获得呢?和上面的fine-tuning类似,也是看Region Proposal的区域和标注区域的IoU,这个阈值是多少呢?通过交叉验证,发现最优值是0.3。为什么前面fine-tuning时随便的指定一个0.5而这里需要仔细的选择阈值呢?因为前面训练卷积网络不是用于最终的分类,只是用于提取特征,因此大致差不多就行了,而这里训练分类器是用于最终的决策,因此这个阈值对最终的效果影响很大。
Bounding box回归
对于Region Proposal出来的区域,如果被判断为猫,本文还使用了Bounding box技术来”改进“这个区域。因为Region Proposal使用的只是底层的一些颜色纹理等特征,所有它建议的候选区域可能会包括一些多余的像素,而Bounding-box regression会使用CNN的特征来预测,因此能够更加准确的判断物体的边界。使用了Bounding box回归后在VOC2010测试集合上能够提高mAP3.5个百分点。因为这项技术被后面的更新的所取代,所以这里不再介绍,对Bounding box回归细节内容感兴趣的读者可以参考论文的附录部分。
Fast R-CNN
前面介绍的R-CNN虽然效果不错,但是它有如下缺点:
- 训练需要很多步骤,从卷积网络到SVM再到Bounding box回归,整个Pipeline过于复杂
- 训练需要大量时间和空间 我们需要为每个类别都训练一个二分类的SVM,而且由于SVM的特征来自于卷积网络的全连接层,这是两个模型不好集成,因此需要把卷积网络的特征写到磁盘上,这要占用大量磁盘空间和IO时间
- 预测的速度慢,对于每个候选区域,我们都要用卷积网络提取特征(基本相对于一次forward计算),即使有一个GPU,预测一个图片平均都需要47s的时间
R-CNN慢的最主要原因就是每个候选的区域都要用CNN提取特征,而事实上它们都是这张图片的一部分,很多计算都是重复的。此外训练慢的原因在于有多个模型——卷积网络、SVM和Bouding box回归。下面我们介绍Fast R-CNN的模型结构以及它是怎么来解决上述的问题的。
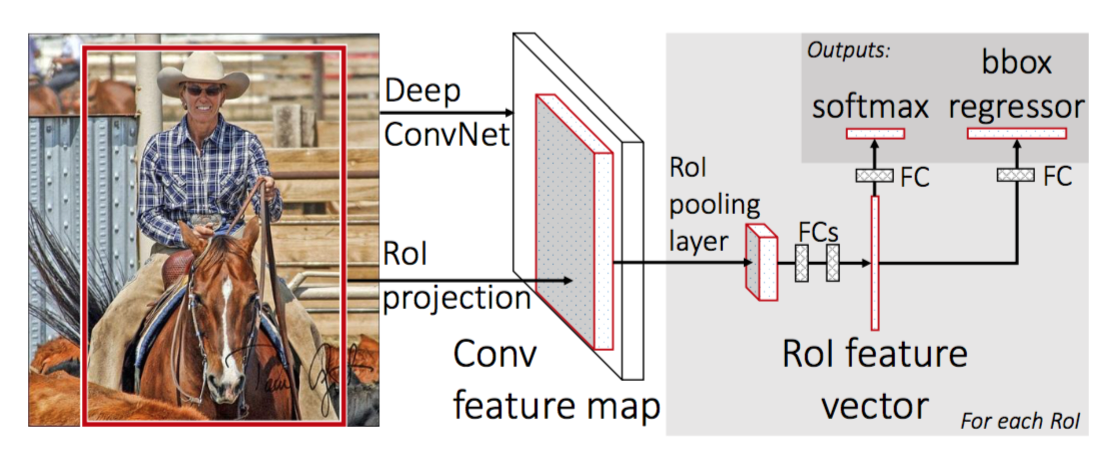 图:Fast R-CNN架构图
图:Fast R-CNN架构图
Fast R-CNN的架构如上图所示。它的输入是一张图片和一些候选区域,对于输入的图片,它会使用多层的卷积网络得到一些特征映射(Feature Map),然后对于每一个候选区域,一个RoI(Region of Interest)的pooling层会从这些特征映射中选取与之对应的区域,通过pooling得到固定大小的特征,再把这些特征输入全连接层。然后再从全连接层分出两个分支,一个用softmax进行分类,另一个分支直接输出4个数值,分别表示Bounding box的位置。
Fast R-CNN对于每个图片只用CNN提取一次特征,然后不同的候选区域会”共享“这个特征,只是使用RoI来选择空间位置上与之对应的部分,这样预测的时候速度会比R-CNN快很多。其次,Fast R-CNN完全抛弃了SVM和一个单独的Bouding box回归。而是使用统一的一个深度神经网络来同时输出分类和Bouding box的位置,因此是一个统一的训练过程,从而避免复杂的Pipeline和提高训练速度。
RoI pooling层
因为不同的候选区域的尺寸是不同的,所以对应的Feature map的尺寸也是不同,因此使用max pooling把它们变成固定大小(H=7 x W=7)的特征。每个RoI都对应原始Feature map的某个区域,比如某个RoI的大小是(h=21, w=21),那么我们就可以使用(h/H=3, w/W=3)的max pooling层把它变成(H, W)的特征。当然如果某个RoI的大小是(14, 14),那么我们就需要(2, 2)的max pooling,从而保证最终的输出是(7, 7)。这样通过不同大小的RoI,我们的模型就可以检查不同大小的目标对象。
预训练
和R-CNN类似,Fast R-CNN也可以使用图片分类(而不是目标检测)的数据来预训练。预训练完成后我们再fine-tuning,把最后一个pooling层换成RoI层,把1000类的softmax换成N(目标检测的类别数)+1(其它对象或者背景)。此外再加上4个预测Bounding Box的输出,这就有两个损失函数,这是典型的multi-task学习问题,后面我们会介绍它的损失函数。这样这个模型学习出来的特征既要考虑分类的准确率,也同时要考虑回归的准确率。而之前的R-CNN里的特征只考虑分类,而Bounding box回归是单独的一个模块,而且它的输入就是CNN的特征,这个是在分类训练完成后就固定了的,Bounding box回归是不能调整它的。
Multi-task Loss
对于每一个候选区域,它的真实类别是u(0代表不是任何目标物体),它的真实bounding box是$t^u$。而模型预测的分类是一个概率分布$p=(p_0, p_1, …, p_K)$,模型预测的bouding box是$v$。因为候选区域的大小不是固定的,因此这里的bounding box都是相对候选区域的位置,我们只要理解它是和候选区域大小无关的一种相对位置就行了,感兴趣的读者可以参考R-CNN论文的附录部分。最终的loss为:
\[L(p, u, t^u, v)=L_{cls}(p, u) + \lambda[u \ge 1]L_{loc}(t^u, v)\]其中$L_{cls}(p, u)=-logp_u$就是我们熟悉的交叉熵损失函数,而$L_{loc}(t^u, v)$是bounding box预测和真实值的差别带来的损失。这里还有一个$\lambda[u \ge 1]$,它的意思是如果真实分类是背景,那么它的值就是零,也就不要考虑Bounding box预测的损失了,因为我们的模型不需要预测背景的Bounding box。
\[L_{loc}(t^u, v)=\sum_{i \in \{x,y,w,h\}}smooth_{L_1}(t_i^u-v_i)\]这个损失是计算预测的x,y,w,h与真实的$L_1$距离,只不过加了一点平滑:
\[smooth_{L_1}=\begin{cases} 0.5x^2 & if |x| < 1 \\ |x| - 0.5 & otherwise \end{cases}\]改进效果
模型的效果对于指标mAP有6%的提高,而训练速度是原来的18倍,预测速度是原来的169倍,对于大的模型,预测也只需要0.3秒。
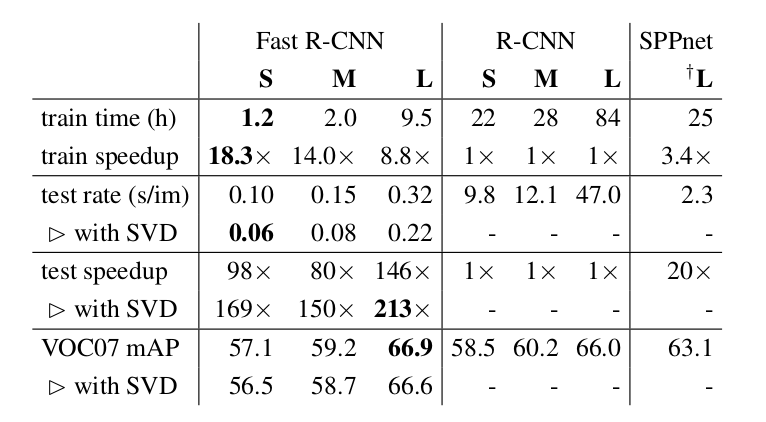 图:训练和预测速度对比
图:训练和预测速度对比
Faster R-CNN
前面的Fast R-CNN的速度能到0.3秒,这是忽略了Region Proposal的时间。对于之前的Selective Search,对一张图片进行处理需要2秒的时间,因此问题的瓶颈变成了Region Proposal。
一种解决办法是改进Region Proposal算法,在保证召回率的前提下提高其速度。除此之外的思路就是“去掉”这个模块,就像Fast R-CNN去掉SVM和Bounding box回归那样。本论文的思路就是怎么样把Region Proposal也纳入到神经网络模型中,从而实现End-to-end的模型。
这样的模型除了可以去掉Region Proposal从而提高速度之外,它也能提高识别效果,原因在于Region Proposal是由数据驱动学习出来的,而不是之前Selective Search那种固定的人工设计的算法。
Faster R-CNN的架构
Faster R-CNN的架构如下图所示。对于一种输入的图片,首先使用一些卷积池化层得到一些feature map。然后使用一个单独的RPN(Region Proposal Network)来生成候选区域和Bounding Box回归,最后通过RoI Pooling得到的特征训练卷积网络来判断物体的类别(包括不是目标的背景类别)。
注意图中通过RoI Pooling之后除了分类,同时也需要Bounding box回归,论文原图这个细节有问题,更详细的图为下图。另外一点需要注意的就是RPN和Fast R-CNN是共享卷积层参数的。
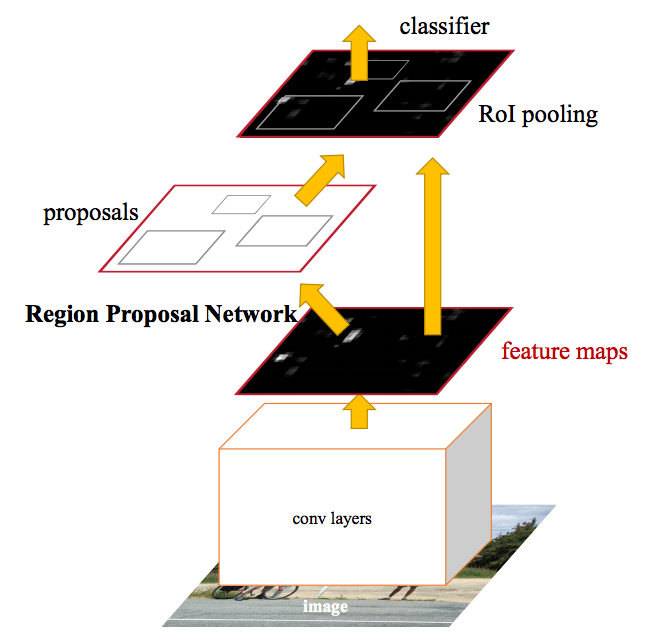 图:Faster R-CNN架构
图:Faster R-CNN架构
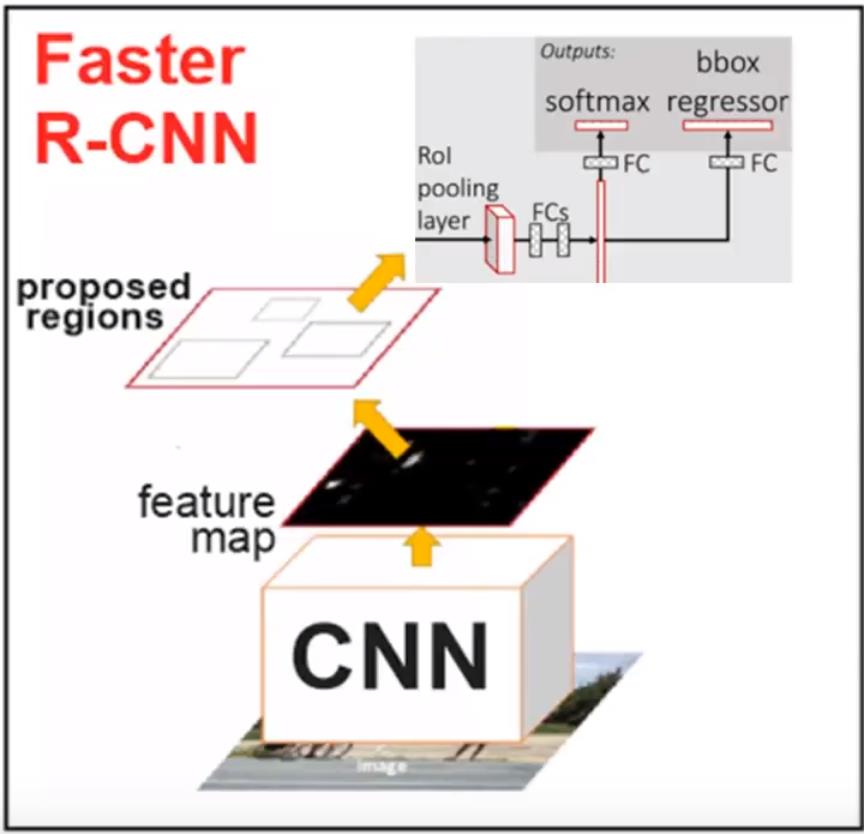 图:Faster R-CNN架构
图:Faster R-CNN架构
RPN
RPN的输入是一张图片,它的输出是一些矩形的区域,每个区域都会有一个可能是目标物体的得分,它会把得分高的一些区域交给Fast R-CNN来判断它到底是哪个分类。
为了得到候选的区域,RPN首先会使用一个n(3)xn(3)的滑动窗口,注意这个3x3的窗口会很“深”,比如128,那么实际这个滑动窗口的参数是3x3x128,然后我们使用一个全连接层把它降维到d(256)。注意:虽然这个滑动窗口是3x3的,但是这个3x3是在feature map里的尺寸,如果对应到原始的图像中,比如在VGG网络中,它的尺寸就是228x228。因此RPN在发现候选区域时用的感受野(receptive field)其实是很大的,也就是它使用的信息是很多的。
接着这个256维的向量被输入到两个网络中,一个网络用来做区域的Proposal,估计实际的候选区域;另一个网络用来判断这个候选区域是否我们关注的目标物体。
但这里有一个问题:我们这个3x3的滑动窗口对于的感受野其实是228x228的,这么大的一个区域里可能包含多个物体(当然也可能只有一个物体,甚至这个物体的尺寸比228x228还大),按照上面的逻辑,它最多生成一个候选区域。那怎么办呢?我们需要它输出k(9)个候选。那怎么输出k个候选呢?当然最直观的想法就是构造k个模型,每个模型输出4个坐标代表候选区域。但这又有一个问题——比如某个区域有两个物体,我们有9个模型,那到底让这9个模型中的哪两个模型来(学习)识别这个物体呢?我们需要对区域进行分类。怎么分类呢?这里可以使用区域的大小(scale)和形状(aspect ratio,也简写为ar)来分类。比如一个模型学习判断128x128的(scale=128, ar=1:1),另一个模型学习判断128x64(scale=64, ar=2:1)。这些固定大小的区域在论文中叫anchor。注意anchor的个数和大小是提前根据经验确定的,比如论文中使用了9个anchor,scale分别是64、128和256,ar是1:1、1:2和2:1。
anchor和滑动窗口的中心在原始图像中是重合的,比如下图中的滑动窗口是3x3的,它对应的原始感受野是228x228的,而后边第二行第二列的anchor是128x64的,这两个矩形的中心在原始图像中要重合,如下图所示。而这个anchor对于的模型学到的是什么呢?原始图像228x228的信息压缩到256维的特征向量里了,而这个模型需要学习的就是根据228x228的信息来判断这个128x64的区域是否是一个目标物体,并且判断这个目标物体所在的区域位置。
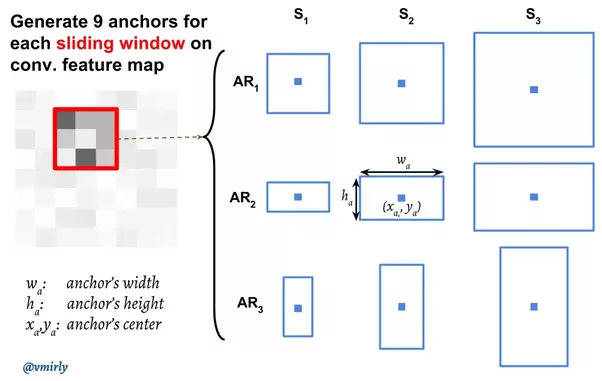 图:滑动窗口和anchor
图:滑动窗口和anchor
 图:某个滑动窗口和anchor
图:某个滑动窗口和anchor
注意:anchor的大小可能会比228x228大,比如256x256的anchor,另外模型预测的候选区域也可能比anchor大(否则我们能够识别最大的物体只能是256x256的,这显然不对)!这看起来似乎不太可能?我们看到的图片是228x228,我们怎么能够预测出一个物体的实际尺寸是比256x256还大呢?但是再想想也不是不可能,所谓窥豹一斑,我们看到一只猫的身体,虽然每看到头,但也是可能推测出它的头的大小和位置的。当然如果有一只猫头和身体的比例与我们训练数据中见过的不一样,比如有一只大头猫,那么可能会预测出错。下图是ZF Net不同anchor提议的候选的平均尺寸,我们可以看到256x128的anchor,平均的候选尺寸是416×229。说明这个anchor对应的模型学到的都是较大的物体,而且它的宽度要比高度大。另外因为后面还会有Bounding box回归,因此这里的位置信息即使不准后面也可能纠正。
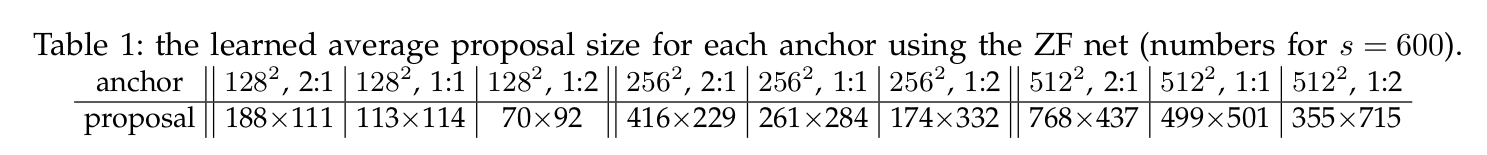 图:ZF Net不同anchor平均的候选区域大小
图:ZF Net不同anchor平均的候选区域大小
损失函数
训练RPN的时候,对于每一个anchor,我们需要训练一个分类器来判断它是否一个目标物体。怎么获得训练数据呢?如果某个anchor的区域和真实的(ground truth)区域的IoU大于0.7就作为正样本,小于0.3就作为负样本,0.3-0.7之间的丢弃掉,目的是避免给模型模拟两可的数据。定义了正负样本之后我们就可以定义损失函数了:
\[\mathcal{L}(\{p_i\}, \{t_i\}) = \frac{1}{N_\text{cls}} \sum_i \mathcal{L}_\text{cls} (p_i, p^*_i) + \frac{\lambda}{N_\text{box}} \sum_i p^*_i \cdot L_1^\text{smooth}(t_i - t^*_i)\]上式中$p_i$是这个anchor被预测的分类,而\(p^*_i\)是真实的分类,$\mathcal{L}_\text{cls}$是交叉熵:
\[\mathcal{L}_\text{cls} (p_i, p^*_i) = - p^*_i \log p_i - (1 - p^*_i) \log (1 - p_i)\]$L_1^\text{smooth}$是bounding box位置的预测值和真实值的距离,使用的是和Fast R-CNN一样的公式。再前面乘以$p^*$的意思是如果是目标物体,那么就计算回归的损失,如果是背景,那么就不要考虑回归的损失。
另外上式的$t_x,t_y,t_w,t_h$以及\(t^*_x,t^*_y,t^*_w,t^*_h\)分别是预测bounding box的(x,y,w,h)和真实bounding box的(x,y,w,h)的变换:
\[\begin{split} t_x=(x-x_a)/w_a & t_y=(y-y_a)/w_a \\ t_w=log(w/w_a) & t_h=log(h/h_a) \\ t^*_x=(x^*-x_a)/w_a & t^*_y=(y^*-y_a)/w_a \\ t^*_w=log(w^*/w_a) & t^*_h=log(h^*/h_a) \\ \end{split}\]上式中$x_a,y_a,w_a,h_a$分别是anchor的中心点xy左边和宽度高度。
效果改进
模型的效果对于指标mAP有6%的提高,而训练速度是原来的18倍,预测速度是原来的169倍,对于大的模型,预测也只需要0.3秒。
图:训练和预测速度对比
Feature Pyramid Networks(FPN)
FPN简介
检测不同尺度的目标(尤其是小目标)是很困难的。如下图左所示,我们可以使用同一图像的不同尺度版本来检测目标。但是处理多尺度图像很费时,内存需求过高,难以同时进行End-to-end的训练。因此,我们可能只在推理阶段使用这种方法,以尽可能提高精确度,尤其是竞赛这种不考虑时间的情况,但是在实际环境中我们很难使用它。此外我们也可以创建特征金字塔来检测目标,如下图右所示。但是低层的特征映射在精确目标预测上效果不佳。
注意左右两图的区别:左图是一张图片的4个尺度,然后分别用卷积网络来提取特征并且进行预测,这样每次预测的时候都要用4倍的时间,而且模型的参数也会增加很多。而右图是一张图片,只有一个卷积网络来逐层的提取层次化的特征,然后对4个特征映射进行预测,它可以避免4次的特征提取。但是它的问题在于底层的特征(比如边角等)很难用于判断它是猫还是狗,而只有高层的特征(比如鼻子、眼睛等)才容易判断目标物体。而高层的特征虽然有较强的语义(容易判断目标),但是它丢失了一些更精细的位置等信息,在定位物体时也会有问题。
FPN是基于金字塔概念设计的特征提取器,设计时考虑到了精确性和速度。它代替了Faster R-CNN的检测模型的特征提取器,生成多层特征映射(多尺度特征映射),它的质量比普通的特征金字塔好。因此在左图中图像金字塔提取的特征都是有较强语义的(图中用边框较粗的平行四边形表示);而特征金字塔高层的特征语义较强,但是底层的特征语义较弱,用来预测效果不佳。
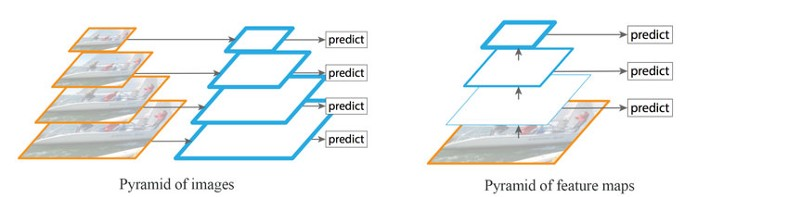 图:左:图像金字塔;右:特征金字塔
图:左:图像金字塔;右:特征金字塔
数据流
FPN的结构如下图所示,和图像金字塔类似,它的每一层都有较强的语义,同时它的速度也很快。
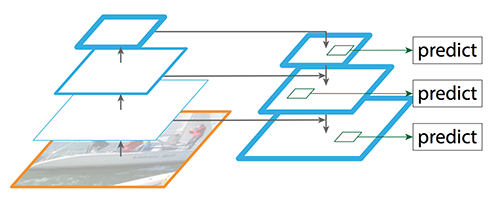 图:FPN
图:FPN
FPN由自底向上(bottom-up)和自顶向下(top-down)两个路径(pathway)组成。自底向上的路径是通常的提取特征的卷积网络,如下图所示。自底向上,空间分辨率变小,但能检测更多高层结构,网络层的语义在增强。
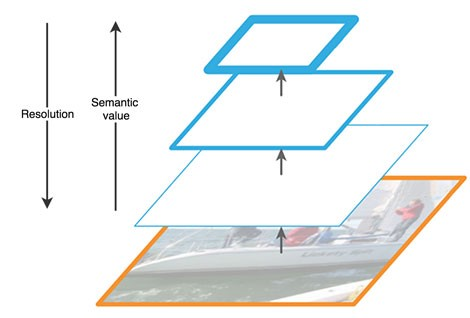 图:FPN的自底向上路径
图:FPN的自底向上路径
SSD(Single Shot MultiBox Detector)也会基于多个特征映射进行检测。但是低层并不用于目标检测,原因是这些层的分辨率虽然很高,但语义不够强,因此,为了避免显著的速度下降,目标检测时不使用这些层。因为SSD检测时仅使用高层,所以在小目标上的表现要差很多。它的结构如下图所示。
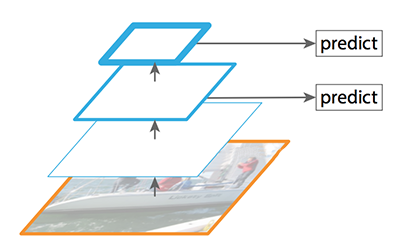 图:SSD结构
图:SSD结构
而FPN提供了自顶向下的路径,基于语义较丰富的层从上向下来构建分辨率较高的层。如下图所示。
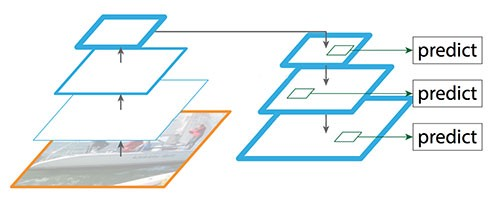 图:FPN自顶向下的路径(不含skip connection)
图:FPN自顶向下的路径(不含skip connection)
虽然重建的层语义足够强,但经过这些下采样和上采样之后,目标的位置不再准确了。因此FPN在重建层和相应的特征映射间增加了横向连接,以帮助检测器更好地预测位置。这些横向连接同时起到了跳跃连接(skip connection)的作用(类似残差网络的做法),如下图所示。
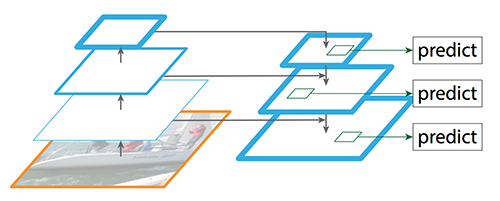 图:增加skip connection
图:增加skip connection
接下来我们详细介绍FPN的自顶向下和自底向上路径。
自底向上路径
文章使用残差网络来构建自底向上的路径。这个网络由很多卷积层组成,我们把大小相同的分成一组,共计有五组,相邻组之间大小减半,从下往上我们把每一组最后一层记为C1-C5。如下图左边的虚线框所示。
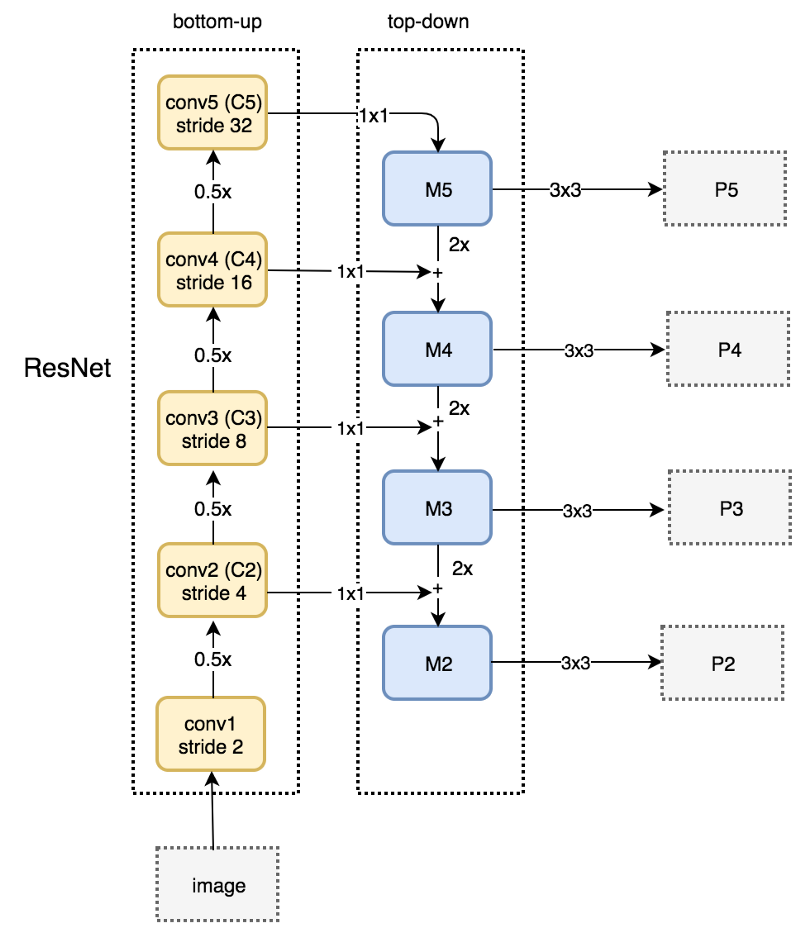 图:增加skip connection
图:增加skip connection
自顶向下路径
如上图右边的虚线框所示,FPN使用一个1x1的卷积过滤器将C5(最上面的卷积模块)的channel数降至256维,得到M5。接着应用一个3x3的卷积得到P5,P5正是用于目标预测的第一个特征映射。
沿着自顶向下的路径往下,FPN对之前的层应用最近邻上采样使得空间分辨率翻倍。同时,FPN对自底向上通路中的相应特征映射应用1x1卷积,并把它加到上采样的结果里(skip-connection)。最后同样用3x3卷积得到目标检测的特征映射,这有助于减轻了上采样的混叠效应。
我们重复上面的过程得到P3和P2,我们没有生成P1,因为它的尺寸太多,会严重影响速度。因为所有的P2-P5会共享目标检测的分类器和Bounding box回归模型,所以要求它们的channel数都是256。
FPN用于RPN
FPN自身并不是目标检测器,而只是一个配合目标检测器使用的特征提取器。我们可以使用FPN提取多层特征映射后将它传给RPN(基于卷积和anchor的目标检测器)检测目标。RPN在特征映射上应用3x3卷积,之后在为分类预测和bounding box回归分别应用1x1卷积。这些3x3和1x1卷积层称为RPN头(head)。其他特征映射应用同样的RPN头,如下图所示。
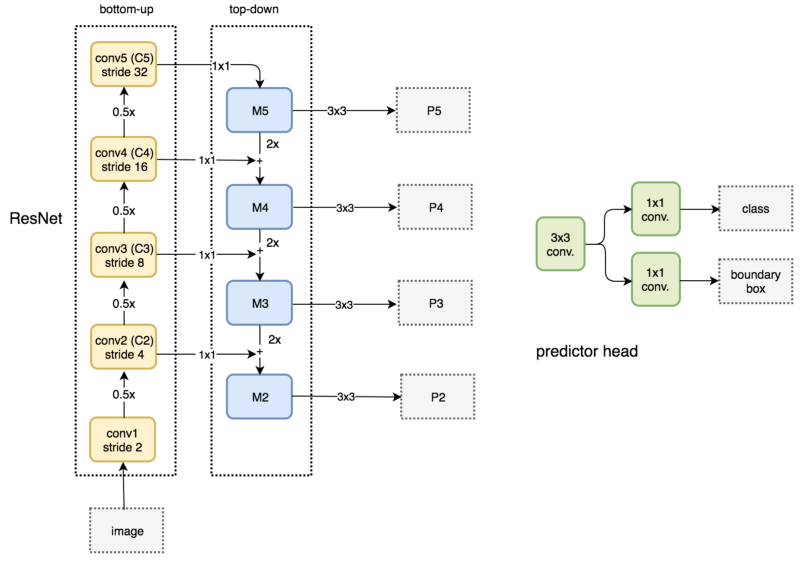 图:FPN用于RPN
图:FPN用于RPN
下面我们来详细分析FPN怎么集成到我们之间介绍过的Faster R-CNN里。
FPN用于Faster R-CNN
我们首先来回顾一下Fast R-CNN,如下图所示,输入一张图片,我们首先使用卷积网络(通常叫作backbone)来提取特征,得到一组特征映射。然后使用Region Proposal选择出一些(图中是3个)可能的候选区域,然后根据候选区域的位置从特征映射中选择对应区域的特征。因为候选区域大小不一,所以使用RoI Pooling的技巧把它们都变成相同的大小,然后在接一些网络层来实现分类和Bounding box回归。
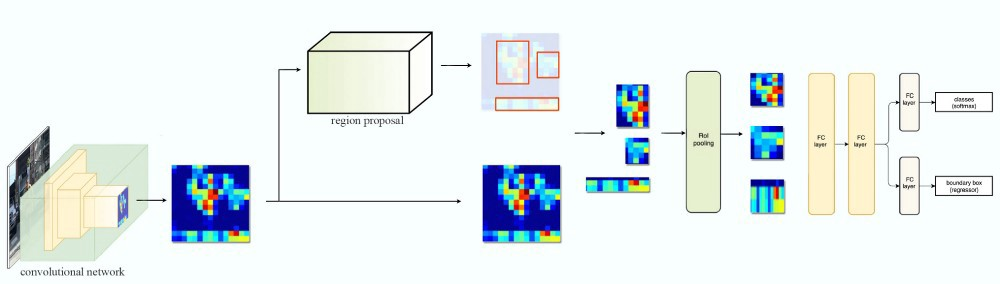 图:Fast R-CNN
图:Fast R-CNN
如果是Faster R-CNN的话,结构和Fast R-CNN类似,只是把Region Proposal用一个RPN网络来代替,而且Bounding box回归也由它来完成,其余都是类似的。那现在怎么把FPN集成近Faster R-CNN呢?
如下图所示,我们首先用FPN提取特征,和之前不同,FPN产生的是多个(更准确的说应该是多组)特征映射,代表同一幅图的不同尺度。这些特征映射输入RPN网络来产生候选的区域,这都没有什么不同。有了候选区域,我们需要从特征映射里选择对应的区域,这就有所不同了。前面只有一组特征映射,所以所有的候选区域都是从这组特征映射的对应位置产生。而现在有了多个不同尺度的特征映射,就可以根据候选区域的大小选择合适的尺度了,基本的原则就是候选区域越大,我们就应该选择越高层的特征映射。具体的计算公式为:
\[k=\lfloor k_0+log_2(\sqrt{wh}/224) \rfloor\]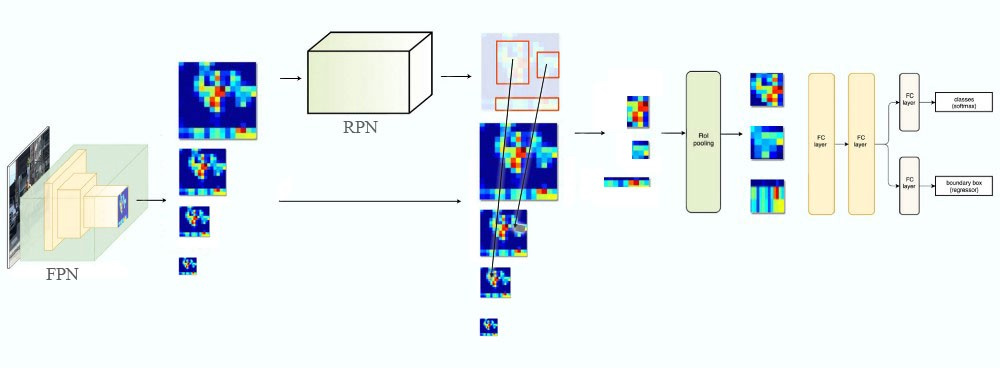 图:FPN用于Faster R-CNN
图:FPN用于Faster R-CNN
实验结果
FPN搭配RPN,提升AR到56.3,相比RPN的baseline提高了8%。 在小目标上的更是提高12.9%。如下表所示。
 图:实验结果
图:实验结果
- 显示Disqus评论(需要科学上网)