本文是《深度学习理论与实战:基础篇》第4章的补充知识。为了便于读者理解,作者先介绍了CNN、RNN等模型之后再介绍Tensorflow和PyTorch等工具。但是为了在介绍理论的同时也能了解它的基本用法,所以在这一章就需要读者了解基本的Tensorflow用法了,这就造成了”循环依赖”。因此这里的内容和后面的章节有一些重复,出版时把这部分去掉了,但是读者如果不了解PyTorch的基本用法,可能无法了解本章的代码,所以建议没有PyTorch基础的读者阅读一下这部分的内容。
目录
基础知识
Tensor
和TensorFlow类似,PyTorch的核心对象也是Tensor。下面是创建Tensor的代码:
x = torch.Tensor(5, 3)
print(x)
输出:
0.2455 0.1516 0.5319
0.9866 0.9918 0.0626
0.0172 0.6471 0.1756
0.8964 0.7312 0.9922
0.6264 0.0190 0.0041
[torch.FloatTensor of size 5x3]
我们可以得到Tensor的大小:
print(x.size())
输出:
torch.Size([5, 3])
Operation
和TensorFlow一样,有了Tensor之后就可以用Operation进行计算了。TensorFlow只是定义计算图但不会立即“执行”,而Pytorch的Operation是马上“执行”的。所以PyTorch使用起来更加简单,当然PyTorch也有计算图的执行引擎,但是它不对用户可见,它是动态实时编译的。
首先是加法操作:
y = torch.rand(5, 3)
print(x + y)
上面的加法会产生一个新的Tensor,但是我们可以提前申请一个Tensor来存储Operation的结果:
result = torch.Tensor(5, 3)
torch.add(x, y, out=result)
print(result)
也可以in-place的修改:
# adds x to y
y.add_(x)
print(y)
一般来说,如果一个方法以_结尾,那么这个方法一般来说就是in-place的函数。PyTorch支持类似numpy的索引操作,比如取第一列:
print(x[:, 1])
我们也可以用view来修改Tensor的shape,注意view要求新的Tensor的元素个数和原来是一样的。
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # the size -1 is inferred from other dimensions
print(x.size(), y.size(), z.size())
输出:torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
numpy ndarray的转换
我们可以很方便的把Tensor转换成numpy的ndarray或者转换回来,它们是共享内存的,修改Tensor会影响numpy的ndarray,反之亦然。
Tensor转numpy
a = torch.ones(5)
b = a.numpy()
a.add_(1) # 修改a会影响b
numpy转Tensor
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a) # 修改a会影响b
CUDA Tensor
Tensor可以移到GPU上用GPU来加速计算:
# let us run this cell only if CUDA is available
if torch.cuda.is_available():
x = x.cuda()
y = y.cuda()
x + y 在GPU上计算
Autograd
autograd是PyTorch核心的包,用于实现自动梯度算法。首先我们介绍其中的变量。
Variable
autograd.Variable是Tensor的封装,我们也就计算了最终的变量(一般是Loss)后,我们可以调用它的backward()方法,PyTorch就会自动的计算梯度。
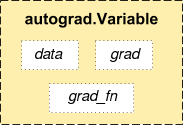 图:PyTorch的变量
图:PyTorch的变量
如上图所示,PyTorch的变量值会存储到data里,而梯度值会存放到grad里,此外还有一个grad_fn,它是用来计算梯度的函数。除了用户创建的Tensor之外,通过Operatioon创建的变量会记住它依赖的变量,从而形成一个有向无环图。计算这个变量的梯度的时候会自动计算它依赖的变量的梯度。
我们可以这样定义变量,参数requires_grad说明这个变量是否参与计算梯度:
x = Variable(torch.ones(2, 2), requires_grad=True)
Gradient
我们可以用backward()来计算梯度,它等价于variable.backward(torch.Tensor([1.0])),梯度会从后往前传递,最后的变量一般传递的就是1,然后往前计算梯度的时候会把之前的值累积起来,PyTorch会自动处理这些东西,我们不需要操心。
x = Variable(torch.ones(2, 2), requires_grad=True)
y=x+2
z = y * y * 3
out = z.mean()
out.backward() # 计算所有的dout/dz,dout/dy,dout/dx
print(x.grad) # x.grad就是dout/dx
输出为:
4.5000 4.5000
4.5000 4.5000
[torch.FloatTensor of size 2x2]
我们手动来验证一下:
\[\begin{split} & out=\sum_iz_i \\ & z_i=3(x_i+2)^2 \\ & \frac{\partial out}{\partial x_i} =\frac{3}{2}(x_i+2)=4.5 \end{split}\]每次调用backward()都会计算梯度然后累加到原来的值之上,所以每次计算梯度之前要调用变量的zero_grad()函数。
变量的requires_grad和volatile
每个变量有两个flag:requires_grad和volatile,它们可以细粒度的控制一个计算图的某个子图不需要计算梯度,从而可以提高计算速度。如果一个Operation所有的输入都不需要计算梯度(requires_grad==False),那么这个Operation的requires_grad就是False,而只要有一个输入,那么这个Operation就需要计算梯度。比如下面的代码片段:
>>> x = Variable(torch.randn(5, 5))
>>> y = Variable(torch.randn(5, 5))
>>> z = Variable(torch.randn(5, 5), requires_grad=True)
>>> a = x + y
>>> a.requires_grad
False
>>> b = a + z
>>> b.requires_grad
True
如果你想固定住模型的某些参数,或者你知道某些参数的梯度不会被用到,那么就可以把它们的requires_grad设置成False。比如我们想微调(fine-tuing)预先训练好的一个CNN,我们会固定最后一个全连接层之前的所有卷积层参数,我们可以这样:
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# 把最后一个全连接层替换成新构造的全连接层
# 默认的情况下,新构造的模块的requires_grad=True
model.fc = nn.Linear(512, 100)
# 优化器只调整新构造的全连接层的参数。
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
volatile在0.4.0之后的版本以及deprecated了,不过我们后面的代码会用到它之前的版本,因此还是需要了解一下。它适用于预测的场景,在这里完全不需要调用backward()函数。它比requires_grad更加高效,而且如果volatile是True,那么它会强制requires_grad也是True。它和requires_grad的区别在于:如果一个Operation的所有输入的requires_grad都是False的时候,这个Operation的requires_grad才是False,这时这个Operation就不参与梯度的计算;而如果一个Operation的一个输入是volatile是True,那么这个Operation的volatile就是True了,那么这个Operation就不参与梯度的计算了。因此它很适合的预测场景时:不修改模型的任何定义,只是把输入变量(的一个)设置成volatile,那么计算forward的时候就不会保留任何用于backward的中间结果,这样就会极大的提高预测的速度。下面是示例代码:
>>> regular_input = Variable(torch.randn(1, 3, 227, 227))
>>> volatile_input = Variable(torch.randn(1, 3, 227, 227), volatile=True)
>>> model = torchvision.models.resnet18(pretrained=True)
>>> model(regular_input).requires_grad
True
>>> model(volatile_input).requires_grad
False
>>> model(volatile_input).volatile
True
>>> model(volatile_input).grad_fn is None
True
使用PyTorch实现卷积神经网络
有了前面的变量和梯度计算,理论上我们就可以自己实现各种深度学习算法,但用户会有很多重复的代码,因此PyTorch提供了神经网络模块torch.nn。在实际的PyTorch开发中,我们通过继承nn.Module来定义一个网络,我们一般只需要实现forward()函数,PyTorch会自动帮我们计算backward的梯度,此外它还提供了常见的Optimizer和Loss,减少我们的重复劳动。
我们下面会实现下图所示的卷积网络,因为之前已经详细的介绍了理论的部分,我们这里只是简单的介绍怎么用PyTorch来实现。完整代码在这里。
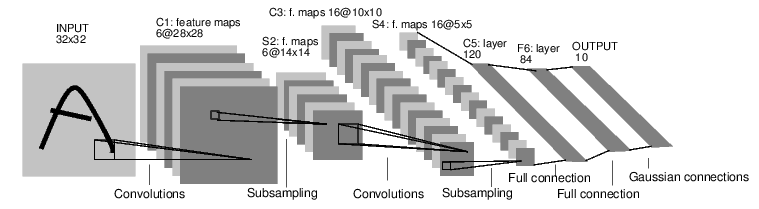 图:卷积网络结构
图:卷积网络结构
对于PyTorch的开发来说,一般是如下流程:
- 定义网络可训练的参数
- 变量训练数据
- forward计算loss
- backward计算梯度
- 更新参数,比如weight = weight - learning_rate * gradient
下面我们按照前面的流程来实现这个卷积网络。
定义网络
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module): # 必须继承nn.Module
def __init__(self):
super(Net, self).__init__() # 必须调用父类的构造函数,传入类名和self
# 输入是1个通道(灰度图),卷积feature map的个数是6,大小是5x5,无padding,stride是1。
self.conv1 = nn.Conv2d(1, 6, 5)
# 第二个卷积层feature map个数是16,大小还是5*5,无padding,stride是1。
self.conv2 = nn.Conv2d(6, 16, 5)
# 仿射层y = Wx + b,ReLu层没有参数,因此不在这里定义
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 卷积然后Relu然后2x2的max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 再一层卷积relu和max pooling
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# 把batch x channel x width x height 展开成 batch x all_nodes
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除了batchSize之外的其它维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
输出为:
Net(
(conv1): Conv2d (1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d (6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120)
(fc2): Linear(in_features=120, out_features=84)
(fc3): Linear(in_features=84, out_features=10)
)
我们只需要实现forward()函数,PyTorch会自动帮我们实现backward()和梯度计算。我们可以列举net的所有可以训练的参数,前面我们在Net里定义的所有变量都会保存在net的parameters里。
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weight
10
torch.Size([6, 3, 5, 5])
代码要求forward的输入是一个变量(不需要梯度),它的大小是batch x 1 x 32 x 32。
input = Variable(torch.randn(1, 1, 32, 32))
out = net(input)
print(out)
我们直接调用net(input),而不需要显式调用forward()方法。我们可以调用backward()来计算梯度,调用前记得调用zero_grad。
net.zero_grad()
out.backward(torch.randn(1, 10))
nn.Conv2d()只支持batch的输入,如果只有一个数据,也要转成batchSize为1的输入。如果输入是channel x width x height,我们可以使用input.unsqueeze(0)把它变成1 x channel x width x height的。
损失函数
PyTorch为我们提供了很多常见的损失函数,比如MSELoss:
output = net(input)
target = Variable(torch.arange(1, 11)) # 只是示例
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
如果我们沿着loss从后往前用grad_fn函数查看,可以得到如下:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> view -> linear -> relu -> linear -> relu -> linear
-> MSELoss
-> loss
我们可以用next_function来查看之前的grad_fn。
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
梯度计算
有了Loss之后我们就可以计算梯度:
net.zero_grad() # 记得清零。
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
更新参数
我们可以自己更新参数: weight = weight - learning_rate * gradient。比如代码:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
但是除了标准的SGD算法,我们前面还介绍了很多算法比如Adam等,没有必要让大家自己实现,所以PyTorch提供了常见的算法,包括SGD:
import torch.optim as optim
# 创建optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 训练循环
optimizer.zero_grad() # 清零
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # 更新参数
数据集和transforms
对于常见的MNIST和CIFAR-10数据集,PyTorch自动提供了下载和读取的代码:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
这里有个transform,datasets.CIFAR10返回的是PIL的[0,1]的RGB值,我们首先转成Tensor,然后把它转换成[-1,1]区间的值。transforms.Normalize(0.5,0.5)会用如下公式进行归一化:
\[input[channel] = (input[channel] - mean[channel]) / std[channel]\]对于上面的取值 input=(input-0.5)*2,也就是把范围从[0,1]变成[-1,1]。
- 显示Disqus评论(需要科学上网)