本文是《深度学习理论与实战:基础篇》第3章的补充知识。为了便于读者理解,作者先介绍了CNN、RNN等模型之后再介绍Tensorflow和PyTorch等工具。但是为了在介绍理论的同时也能了解它的基本用法,所以在这一章就需要读者了解基本的Tensorflow用法了,这就造成了”循环依赖”。因此这里的内容和后面的章节有一些重复,出版时把这部分去掉了,但是读者如果不了解Tensorflow的基本用法,可能无法了解本章的代码,所以建议没有Tensorflow基础的读者阅读一下这部分的内容。
目录
我们这里会用TensorFlow构造全连接网络来识别MNIST数字。本章会简单的介绍TensorFlow最基本的概念,目的是让读者能够大致读懂示例代码。后面会详细的介绍TensorFlow,需要提前学习TensorFlow的读者可以参考相关章节的内容。TensorFlow的API大致可以分为High Level的和Low Level的,前者做的封装更多,需要的代码更少;而后者用户可以控制的东西更多,调试也更加方便。本书会更多的使用后者,因为后者更加灵活而且也有助于理解原理。
名字由来
TensorFlow名字的由来就是张量(Tensor)在计算图(Computational Graph)里的流动(Flow),如图\ref{fig:tf}。它的基础就是前面介绍的基于计算图的自动微分,除了自动帮你求梯度之外,它也提供了各种常见的操作(op,也就是计算图的节点),常见的损失函数,优化算法。
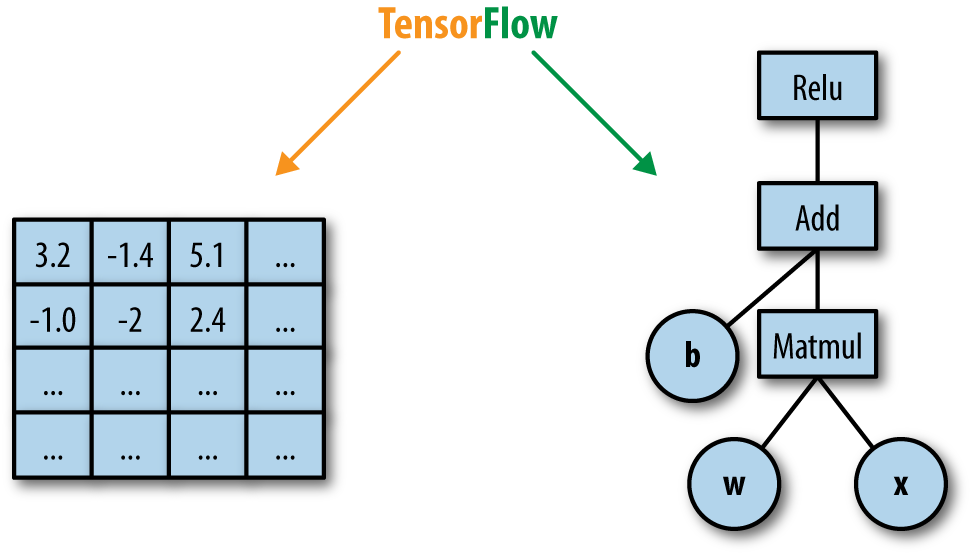 图:TensorFlow
图:TensorFlow
张量(Tensor)
Tensor是向量和矩阵向更高维的推广,在内部,TensorFlow用n维数组来表示Tensor。在编写TensorFlow程序的时候最常用的就是tf.Tensor对象。tf.Tensor代表了一个部分被定义的计算,它最终会产生一个值。TensorFlow程序就是定义tf.Tensor对象的一个图,这个图描述了每个Tensor的计算细节。一个tf.Tensor对象有两个属性:
- 数据类型(比如float32、int32或者string)
- shape(Tensor每一维的大小)
Tensor的每一个元素的类型都是一样的并且在定义的时候就确定了。但是shape的某些部分可以是未知的。下面这些Tensor是比较特殊的,后面我们会单独介绍它们:
- tf.Variable
- tf.constant
- tf.placeholder
- tf.SparseTensor
变量(Variables)
我们一般用变量来表示模型的参数,因为变量是共享并且持久化的Tensor。下面是我们创建变量的一些代码示例:
my_variable = tf.get_variable("my_variable", [1, 2, 3])
上面的代码创建了变量my_variable,它是一个3维的Tensor,shape是[1, 2, 3]。变量默认的数据类型是tf.float32,值通过tf.glorot_uniform_initializer来随机初始化(不同版本可能会不同)。
我们也可以指定数据类型和初始化对象(initializer),如下面的代码:
my_int_variable = tf.get_variable("my_int_variable", [1, 2, 3], dtype=tf.int32,
initializer=tf.zeros_initializer)
此外,我们也可以通过常量来初始化变量:
other_variable = tf.get_variable("other_variable", dtype=tf.int32,
initializer=tf.constant([23, 42]))
在使用变量之前需要初始化它们。我们需要注意,TensorFlow的代码其实都是在“定义”计算图,比如我们定义了$c=a+b$,但并没有“执行”代码,如果我们需要“执行”代码,我们要用session(后面我们会介绍graph和session)来执行它,初始化也是如此。一般我们会通过下面的代码在执行其它代码前一次初始化所有的变量:
session.run(tf.global_variables_initializer())
这会把graph里的所有全局变量都初始化。当然我们可以自己一个一个的初始化:
session.run(my_variable.initializer)
变量可以像普通的Tensor那样来使用,比如通过变量b和c的加法操作(op)来构造新的Tensor c:
c=a+b
我们也可以通过函数assign, assign_add直接修改变量的值,这并不常见,我们修改变量的目的通常是计算梯度,然后根据梯度下降算法修改变量。不过因为TensorFlow提供常见的优化器(Optimizer),通常优化器会帮我们做这些事情。
我们有两种方式来共享一个变量:
- 直接传递这个Python对象
- 把tf.Variable放到tf.variable_scope里
前一种方法看起来更加简单直接,但是后者更容易通过scope和名字来共享(而不要一层一层的函数传递),我们会大量使用后一种方法。在调用一些函数隐式(Implicitly)的创建变量时,通过变量的scope可以控制变量的重用。此外通过scope也可以实现变量的层次结构。比如我们可以用下面的函数来创建卷积和Relu层:
def conv_relu(input, kernel_shape, bias_shape):
# 创建名为"weights"的变量
weights = tf.get_variable("weights", kernel_shape,
initializer=tf.random_normal_initializer())
# 创建"biases".
biases = tf.get_variable("biases", bias_shape,
initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(input, weights,
strides=[1, 1, 1, 1], padding='SAME')
return tf.nn.relu(conv + biases)
这个函数很简单,给定一个输入input,我们创建一个卷积和Relu层。但是我们的深度卷积网络通常有很多这样的卷积和Relu层,那么如下的代码会怎么样呢?
input1 = tf.random_normal([1,10,10,32])
input2 = tf.random_normal([1,20,20,32])
x = conv_relu(input1, kernel_shape=[5, 5, 32, 32], bias_shape=[32])
x = conv_relu(x, kernel_shape=[5, 5, 32, 32], bias_shape = [32]) # 运行会失败
代码会失败,因为第二次调用conv_relu时代码tf.get_variable(“weights”)已经执行过一次了,默认get_variable发现某个变量已经定义过一次后会抛出异常。
那怎么办呢?我们可以把上面的代码放到不同的scope里:
def my_image_filter(input_images):
with tf.variable_scope("conv1"):
# 创建的变量名字为"conv1/weights", "conv1/biases".
relu1 = conv_relu(input_images, [5, 5, 32, 32], [32])
with tf.variable_scope("conv2"):
# 创建的变量名字为"conv2/weights", "conv2/biases".
return conv_relu(relu1, [5, 5, 32, 32], [32])
比如上面的代码,我们把两次conv_relu函数调用放到不同的variable_scope里就不会有问题了,这样创建出来的4个变量分别是“conv1/weights”,“conv2/weights”,“conv1/biases”和“conv2/biases”。如果我们要在两层中用同一个参数,那么可以这样:
with tf.variable_scope("model"):
output1 = my_image_filter(input1)
with tf.variable_scope("model", reuse=True):
output2 = my_image_filter(input2)
也可以这样:
with tf.variable_scope("model") as scope:
output1 = my_image_filter(input1)
scope.reuse_variables()
output2 = my_image_filter(input2)
Graph和Session
TensorFlow使用dataflow graph来表示计算,其中边代表Tensor,而点代表计算。
tf.Graph是什么
tf.Graph包括图的结构,也就是图中的点(计算op)和边(Tensor)。此外还包括图的collections,所谓的collections通常就是一些变量的集合。比如我们在创建一个变量时,默认会把这个变量加到“global变量”和“trainable变量”这两个集合里。我们就可以通过graph的get_collection拿到所有可以训练的变量。
构建tf.Graph
大部分TensorFlow程序的第一步就是构建数据流图,我们通过api构建tf.Operation (点)和tf.Tensor(边)并且把它们加到tf.Graph里。TensorFlow提供了默认的graph,如果我们调用时没有提供graph,那么就会加到这个默认graph里。下面是一下例子:
- tf.constant(42.0)会创建一个Operation(node),这个node没有输入边,直接输出42,并且它返回一个Tensor那表示这个输出的常量。
- tf.matmul(x, y)创建一个Operation来计算输入Tensor x和y的乘积,返回代表乘积结果的Tensor。
- v = tf.Variable(0)会向graph添加一个Operation,这个Operation会存储一个可以修改的Tensor值,而且这个值是可以跨越多次session.run的。tf.Variable封装了这个Operation,使得它可以像一个Tensor那样被使用。除此之外,这个对象还提供assign和assign_add方法来创建对应的Operation,这些Operation的效果就是修改变量的值。
- 调用tf.train.Optimizer.minimize会添加很多Operation和Tensor,它们一起用于计算损失对变量的梯度。这个函数返回一个Operation,在session里run一次它,就会根据当前的Tensor(包括变量)的值计算梯度,然后用梯度更新变量(从而实现梯度下降)。
在session里执行graph
tf.Session代表客户端程序(最常见的Python)和c++运行时的联系。也就是说,我们之前定义的Tensor和Operation都是在Python里“定义”这个graph,但是并没有任何真正的运算发生,如果要真正执行这个计算图,就需要使用session来和c++运行时沟通,让c++运行时真正的执行运算。
创建好了session之后,我们可以通过session.run函数让TensorFlow执行图的某些部分的计算。我们只需要告诉run函数我们想要计算的节点,它会根据graph的定义首先计算它依赖的节点,最终计算出我们想要的值。比如下面的代码:
x = tf.constant([[37.0, -23.0], [1.0, 4.0]])
w = tf.Variable(tf.random_uniform([2, 2]))
y = tf.matmul(x, w)
output = tf.nn.softmax(y)
init_op = w.initializer
with tf.Session() as sess:
# 初始化w
sess.run(init_op)
# 运行`output`. `sess.run(output)`会返回一个NumPy数组,它是运行output的结果
print(sess.run(output))
# 同时执行`y`和`output`。注意`y` 只会计算一次,
# 返回的y_val和计算`tf.nn.softmax()`用的都是同一个y
# 返回的`y_val`和`output_val`都是NumPy数组
y_val, output_val = sess.run([y, output])
上面的代码首先定义常量x和变量w,然后定义y是w和x的乘积,最后把output定义为y的softmax函数。接着创建一个session,一般我们用with创建session,这样不会忘记关闭资源。
注意,在用session进行计算时一定要保证所有的变量都已经初始化过了。初始化也要用session来运行。因此我们首先通过sess.run(init_op)来初始化w,当然这里只有一个变量,更常见的是我们通过tf.global_variables_initializer来得到所有变量的初始化器,然后运行它来初始化所有全局变量。(注意,有一个tf.initialize_all_variables是类似的功能,但是已经deprecated了,建议不要用了)
接着print(sess.run(output)),sess.run会计算output的值,output依赖y,所以y的值也被计算了。sess.run会返回output这个Tensor的值,返回类型转换成了numpy。注意:output只是python对象tf.Tensor,这个Tensor真正的值是在c++运行时里的。我们也可以同时计算y和output,session根据graph知道它们之间的依赖关系,而且一次run一个节点只会计算一次。
PlaceHolder
除了常量和变量,TensorFlow里还有一种类似Tensor的对象是PlaceHolder,它有点像常量,但是它的值是在session.run的时候通过feed_dict传进去的,这非常适合传入训练数据的输入和输出,因为每次mini-batch梯度下降的时候都需要传入不同的值。
全连接神经网络示例
接下来我们用TensorFlow来实现一个简单的全连接网络,并且把它用于MNIST数据集。通过它来学习一些基本的TensorFlow技巧,这个例子的代码的封装和复用不太好,目的是为了让读者了解TensorFlow的基本概念。完整代码在这里下载。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./data/MNIST_data", one_hot=True)
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.0, shape=shape)
return tf.Variable(initial)
# 输入数据
x = tf.placeholder(tf.float32, [None, 784])
h1_num=1000
h2_num=500
# 正确的标签
labels = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
W_fc1 = weight_variable([784, h1_num])
b_fc1 = bias_variable([h1_num])
h_fc1 = tf.nn.relu(tf.matmul(x, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([h1_num, h2_num])
b_fc2 = bias_variable([h2_num])
h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
W_fc3 = weight_variable([h2_num, 10])
b_fc3 = bias_variable([10])
logits=tf.matmul(h_fc2_drop, W_fc3) + b_fc3
# 定义损失函数
# 1. unstable版本,不要使用!
#y = tf.nn.softmax(logits)
#cross_entropy = tf.reduce_mean(-tf.reduce_sum(label * tf.log(y), [1]))
# 2. stable版本
#scaled_logits = logits - tf.reduce_max(logits)
#normalized_logits = scaled_logits - tf.reduce_logsumexp(scaled_logits)
#cross_entropy =-tf.reduce_mean(labels * normalized_logits)
# 3. 推荐版本
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,
labels=labels))
# define training step and accuracy
train_step = tf.train.RMSPropOptimizer(learning_rate=0.0001).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# initialize the graph
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
batch_size=100
best_accuracy = 0.0
total_steps=0
train_kp_prop=0.5
for epcho in range(100):
for i in range(60000//batch_size):
input_images, correct_predictions = mnist.train.next_batch(batch_size)
_, loss=sess.run([train_step,cross_entropy], feed_dict=
{x: input_images, labels: correct_predictions, keep_prob: train_kp_prop})
if(i==0):
print("step %d, loss %g" %(total_steps, loss))
total_steps += 1
train_accuracy = sess.run(accuracy, feed_dict={
x: mnist.train.images, labels: mnist.train.labels, keep_prob: 1})
print("step %d, training accuracy %g" % (total_steps, train_accuracy))
# validate
test_accuracy = sess.run(accuracy, feed_dict={
x: mnist.test.images, labels: mnist.test.labels, keep_prob:1})
print("step %d, test accuracy %g" % (total_steps, test_accuracy))
首先是import tensorflow,然后用input_data.read_data_sets来下载并读取MNIST数据,传入了参数one_hot=True,这个函数返回mnist对象。这个对象有三个数据集mnist.train、mnist.validation和mnist.test,分别代表训练数据(55,000)、验证数据(5,000)和测试数据(10,000),我们这里只使用训练数据和测试数据。它们的结构都是一样的,比如mnist.train包含images和labels两个属性,都是numpy的ndarray。images.shape是(55000, 784),而labels.shape是(55000,10),注意labels变成了one-hot的形式,因此shape是(55000,10),比如某个图片是数值1,那么它对应行是(0,1,0,…)。
接下来定义两个函数weight_variable和bias_variable,因为我们需要为每一层的全连接网络定义权重w和b,因此封装一下避免重复代码,这里简单的传入参数的shape,然后我们用tf.Variable创建变量。对于w,我们使用truncated_normal来随机初始化,而对于b,我们只需要初始化成零即可。truncated_normal函数的参数除了shape之外,还有均值(mean)和标准差(stddev),它可以生成正态分布的数据,但是它会truncated(去掉)离均值的距离大于两倍标准差的点,并且重新采样。
这里我们实现一个两个隐层的全连接网络,它们的神经元个数是超参数,我们用变量h1_num和h2_num来表示。
然后我们定义3个PlaceHolder,x,labels和keep_prob,x代表一个mini-batch的输入,labels代表正确的标签,而keep_prob用来表示dropout保留的概率。我们定义PlaceHolder时一般不需要指定batch的大小,因此是None。为什么要keep_prob也定义为PlaceHolder呢?因为我们训练的时候要dropout,但是预测的时候不dropout,所以使用PlaceHolder便于修改它。再下来我们定义第一个隐层和dropout层:
W_fc1 = weight_variable([784, h1_num])
b_fc1 = bias_variable([h1_num])
h_fc1 = tf.nn.relu(tf.matmul(x, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
代码非常直接,就跟我们写数学公式差不多。接着定义第二个隐层和dropout层,代码几乎一样。接着是输出层,它没有使用激活函数:
W_fc3 = weight_variable([h2_num, 10])
b_fc3 = bias_variable([10])
logits=tf.matmul(h_fc2_drop, W_fc3) + b_fc3
然后是对logits使用softmax函数并且使用交叉熵损失函数,这里我们首先使用交叉熵的定义自己来实现。注意,这个版本是有bug的,我们应该使用Tensorflow提供的实现,这里只是为了让读者熟悉交叉熵的定义。
y = tf.nn.softmax(logits)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(labels * tf.log(y), [1]))
注意Tensor的shape,logits是(batch, 10),labels也是(batch, 10)。labels * tf.log(y)还是(batch, 10),reduce_sum((xx, [1])会把Tensor的第二维加起来,因此shape变成(batch),每一个值对应一个样本的损失,最后reduce_mean把它们平均起来就得到了cross_entropy损失函数。接下来定义train_step和准确率:
train_step = tf.train.RMSPropOptimizer(learning_rate=0.0001).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
我们使用了RMSPropOptimizer,读者也可以尝试其它的Optimizer。我们通过tf.argmax(logits, 1)来计算模型预测的分类的下标。比如logits是如下值(shape是(3,10)):
\[\begin{bmatrix} 1 & 20 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\ 1 & 2 & 30 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\ 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \\ \end{bmatrix}\]argmax(logits,1)对第二维求最大值对应的下标(因为softmax是单调函数,因此对logits取argmax是一样的),得到如下值(shape是(3)):
\[\begin{bmatrix} 1 \\ 2 \\ 9 \\ \end{bmatrix}\]同样的,对真实的labels也是使用argmax函数。最后用equals函数,如果预测的和真实的是相同的,那么correct_prediction就是True,反正就是False。最后计算准确率,我们需要把Bool值转成Float。TensorFlow提高了cast函数,默认True转成1,False变成0,因此直接用reduce_mean计算平均值就是分类准确率。接下来定义session和初始化参数:
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
最后的代码是训练过程,我们一般把训练数据用mini-batch训练一遍叫做一个epoch。对于每个epoch,我们获得mini-batch,然后用session运行一次train_step,让它进行一次随机梯度下降。然后每个epoch结束,我们运行一下训练数据和测试数据上的准确率。训练的代码:
_, loss=sess.run([train_step,cross_entropy], feed_dict={x: input_images,
labels: correct_predictions, keep_prob: train_kp_prop})
注意feed_dict,我们需要传入x,labels和keep_prob。而计算准确率的代码:
train_accuracy = sess.run(accuracy, feed_dict={
x: mnist.train.images, labels: mnist.train.labels, keep_prob: 1})
在预测的时候,我们的keep_prob是1。
如果运行上面的代码,我们会发现刚开始准确率不断提高,一般能到98%以上,但是突然在某个epoch,准确率就掉到0.1左右(就是瞎猜的概率),而且会发现loss是nan。这是怎么回事呢?读者碰到这种情况一般要想到nan就表示浮点数上溢超出浮点数的最大值。这时候可以使用TensorFlow提高的debug功能,后面我们会介绍。这里读者可以思考一下,看看能不能想出可能的问题来。作者先给出两种正确的代码,然后分析上面代码的问题。
# 2. stable版本
#scaled_logits = logits - tf.reduce_max(logits)
#normalized_logits = scaled_logits - tf.reduce_logsumexp(scaled_logits)
#cross_entropy =-tf.reduce_mean(labels * normalized_logits)
# 3. 推荐版本
#cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
为什么训练的epoch变多之后就出现nan呢?关键是这个函数
y = tf.nn.softmax(logits)
cross_entropy = tf.reduce_mean(-tf.reduce_sum(labels * tf.log(y), [1]))
之前我们也介绍过,softmax的计算技巧,如果直接按照softmax的定义计算,因为指数很容易上溢或者下溢,所以需要减去最大的那个后再计算。当然我们这里使用的是TensorFlow的函数,因此不(太)用担心会有什么bug。那么问题在哪呢?问题出在tf.log(y),当y非常逼近0的时候,log(y)就是负无穷,因此就溢出了。
那怎么解决呢?当然最简单的就是用TensorFlow提供的softmax_cross_entropy_with_logits函数,TensorFlow帮我们解决数值计算不稳定(unstable)的问题。这个函数需要两个参数logits和labels,如果我们的labels不是one-hot的(前面的input_data.read_data_sets的参数one_hot=False),而是一个分类值,那么可以使用sparse_softmax_cross_entropy_with_logits。
另外后一种复杂的方法就是用reduce_logsumexp函数,这里不详细介绍了。作者的建议是尽量用TensorFlow提供的更“高层”的Operation而不是直接用更“底层”的基本Operation来组合。运行这个全连接网络,应该可以得到98%以上的准确率。
- 显示Disqus评论(需要科学上网)