本文介绍怎么在Docker中使用Tensorflow Serving,包括怎么使用nvidia-docker来支持GPU进行预测。
目录
- 简介
- Nvidia-Docker简介
- nvidia-docker的安装
- 使用Docker来运行Tensorflow Serving
- 使用GPU
- 使用Docker来开发
- 自己构建Tensorflow Serving镜像
简介
我们用Tensorflow训练好了一个深度学习模型之后工作并没有结束,我们还需要把这个模型用于生产环境来进行实时的预测。当然最简单的办法是使用Python的Web框架自己造一个轮子,比如实现一个Rest接口,输入是序列化成Json的Tensor,输出是预测的结果(比如分成每个类别的概率)。为了同时服务多个预测请求,我们通常需要使用多线程或者多进程。如果使用多线程,有PIL的存在,我们很难利用多个CPU;而如果使用多进程,那么Tensorflow的模型需要加载多份(进程间的内存共享是个很麻烦的事情)。
因此Tensorflow Serving就来拯救我们于水火之中了。对于预测来说,我们通常只需要执行前向的计算而不需要反向计算梯度,因此这个任务通常是比较简单的,所以可以直接利用Tensorflow的C++执行引擎。在使用Tensorflow Serving之前我们首先需要把Tensorflow的模型用SavedModel把模型导出成C++执行引擎可以理解的Protobuffer个数,详细内容请读者参考Save and Restore,也可以参考《深度学习理论与实战:基础篇》(年中会出版,提前打个广告)。不论你是使用Low-Level的API还是高层的Estimator或者Keras,都可以导出。如果是PyTorch等其它框架,只要它支持ONNX格式,我们也都可以把ONNX格式转换成Tensorflow Serving需要的Protobuffer格式,这样主流的框架都可以在预测的时候使用Tensorflow Serving了,详细内容请参考《深度学习理论与实战:基础篇》。
我们把辛辛苦苦训练好的模型导出成Tensorflow Serving需要的格式后,还剩下最后一个问题,那就是安装Tensorflow Serving来运行它们。这也是个问题?是的,而且问题还不小。因为C++的abi并不能跨平台,再加上使用GPU后CUDA和CUDNN的版本问题,这对于运维来说是个头大的问题。当然我们可以根据不同的操作系统和CUDA等软件自行编译Tensorflow Serving,但这非常麻烦,比如我们线下训练可能使用的是Ubuntu 16.04,使用了CUDA 9.1+CUDNN 7。但是我们把服务部署到阿里云的GPU服务器上,可能运维习惯使用CentOS,而且安装的CUDA版本和我们线下的不一致,维护不同的版本将会非常麻烦。
这个时候Docker来拯救我们了,Docker可以认为是一个轻量级的虚拟机,我们可以在不同的Host系统(甚至包括Windows)上跑Ubuntu 16.04的Image。不了解Docker的读者请先参考官网,了解基本的Docker知识再继续阅读。但是普通的Docker并不能使用GPU,因此我们需要Nvidia-Docker来支持在Docker里使用GPU。
Nvidia-Docker简介
首先我们介绍关于Nvidia GPU的几个基本概念。
-
CUDA Driver CUDA的驱动程序,比如作者使用了Ubuntu 16.04,安装的是390.48,读者可以使用nvidia-smi命令查看驱动版本。
-
CUDA Toolkit CUDA开发工具和运行时库,比如nvcc等,比如作者安装的是CUDA 9.1。每个CUDA Driver支持一定范围的CUDA Toolkit,比如作者安装的390.48最高支持CUDA 9.1,而不能安装CUDA 9.2和CUDA 10。
-
CUDNN 基于CUDA开发的用于神经网络的库,它需要和一定的CUDA Toolkit配合,比如作者安装的是CUDNN 7.0。
如果读者使用过GPU版本的Tensorflow,就会知道CUDA的版本是多么麻烦。Tensorflow的开发者在开发每一个版本时都会选定一个CUDA Toolkit的版本,比如Tensorflow 1.12.0,使用的是CUDA 9.0和CUDNN 7.2。如果读者安装的CUDA和CUDNN版本与官方的一致(兼容),那么直接就可以使用pip install使用GPU的Tensorflow,但是如果不兼容,那么就非常不幸了,你需要自己从源代码来编译。但是要编译Tensorflow的源代码是非常复杂的事情,因为C++的ABI是不能跨平台的,所以的依赖都需要自行安装。如果你比较幸运,比如使用的是和官方环境很类似的Ubuntu 16.04/18.04 LTS,那么还简单一些,如果你是其它的操作系统或者Linux发行版,那么就很痛苦了。另外即使是CPU的版本,线性代数库为了提高效率,会用到很多平台相关的硬件指令,比如AVX和SSE等。在运行Tensorflow的时候读者也经常会看到类似如下的警告:
The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations.
原因就是为了尽量保证兼容性,官方发布的版本是不利用这些特定平台的指令的,这能够使得尽可能多的机器可以把Tensorflow跑起来,但是我们的机器有SSE2指令集,不利用是相当可惜的,因此Tensorflow会打出上面的警告。因此为了在CPU上跑到更快,我们也有必要自己编译Tensorflow(Tensorflow Serving也是一样,不过作者是在GPU上训练和预测,因此不考虑这个)。
为了解决软件兼容性的问题,我们可以使用虚拟机的方案,不管Host机器是Windows,Mac还是Linux,我们都可以构建一个Ubuntu的虚拟机。但是虚拟机的方案是比较重量级的,而且虚拟机的指令集和Host机器的指令集的转换会带来比较大的性能损耗。现在更加流行的是Docker的方案,我们暂时可以把它看成一个轻量级的虚拟机。但是普通的Docker是不能使用GPU的,因此有了Nvidia-Docker,它是对Docker的扩展,使得Docker可以使用GPU。
使用了Nvidia-Docker之后我们就可以在各种Host机器上运行Tensorflow Serving了(注:Tensorflow也是可以使用Docker的,原理和本文一样,本文不做介绍,感兴趣的读者参考官方文档)。
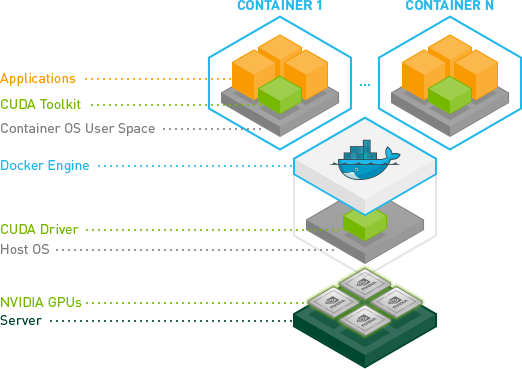 图:nvidia-docker
图:nvidia-docker
如上图所示,最下层是有Nvidia GPU的服务器,比如作者使用的GeForce GTX 1070;再往上是操作系统和CUDA驱动,比如作者的下图是Ubuntu 16.04 LTS,CUDA驱动是390.48。再往上就是不同的Docker容器,里面会包含CUDA Toolkit和CUDNN。比如作者可以启动一个docker来跑Tensorflow Serving 1.12.0,它使用的是CUDA 9.0和CUDNN 7;也可以启动一个docker来跑Tensorflow Serving 1.6.0,它使用的是CUDA 8。但是作者的CUDA驱动不能支持CUDA 10.0,因为CUDA 10.0要求的CUDA驱动至少是410.48。完整的CUDA驱动和CUDA Toolkit的对应关系参考下表(表格来自Wiki):
| CUDA toolkit version | Driver version | GPU architecture |
|---|---|---|
| 6.5 | >= 340.29 | >= 2.0 (Fermi) |
| 7.0 | >= 346.46 | >= 2.0 (Fermi) |
| 7.5 | >= 352.39 | >= 2.0 (Fermi) |
| 8.0 | == 361.93 or >= 375.51 | == 6.0 (P100) |
| 8.0 | >= 367.48 | >= 2.0 (Fermi) |
| 9.0 | >= 384.81 | >= 3.0 (Kepler) |
| 9.1 | >= 387.26 | >= 3.0 (Kepler) |
| 9.2 | >= 396.26 | >= 3.0 (Kepler) |
| 10.0 | >= 384.111, < 385.00 | Tesla GPUs |
| 10.0 | >= 410.48 | >= 3.0 (Kepler) |
| 10.1 | >= 384.111, < 385.00 | Tesla GPUs |
| 10.1 | >=410.72, < 411.00 | Tesla GPUs |
| 10.1 | >= 418.39 | >= 3.0 (Kepler) |
nvidia-docker的安装
安装请参考官方文档,这里介绍的方法适用于Ubuntu 14.04/16.04/18.04。
# 如果之前安装过nvidia-docker 1.0,那么我们需要卸载它以及已经创建的容器(container)
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# 更新源
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
# 安装nvidia-docker2并且充钱docker的daemon进程
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# 可以跳过,但是建议测试一下安装是否有问题,如果出现nvidia-smi的结果,那么说明安装成功
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
默认的docker需要sudo权限才能运行,为了让当前用户可以运行docker,需要把当前用户加到docker组里:
sudo groupadd docker
# 确认环境遍历$USER是否正确,如果不对需要设置正确或者执行下面的命令时把$USER替换成当前的用户名。
echo $USER
sudo usermod -aG docker $USER
然后需要退出再重新登录,对于ssh远程登录来说退出后再次ssh登进去就可以了。但是如果是直接在本机登录,那么需要重启才能生效,这比较麻烦,如果不想重启,可以这样:
# 执行下面的命令确保当前用户在docker组里,如果不在,需要退出重新登录或者使用下面的su命令。
groups
# 把lili改成你的文件名
sudo su - lili
使用Docker来运行Tensorflow Serving
关于Tensorflow Serving的使用,请读者参考官方文档或者《深度学习理论与实战:基础篇》,本文假设读者已经知道怎么从Tensorflow里把模型导出,并且使用Tensorflow Serving来启动这些模型。
快速上手
使用Docker运行Tensorflow Serving非常简单,只需要如下几步:
# 拉取最新的tensorflow serving镜像
docker pull tensorflow/serving
# clone代码,主要是用到里面的测试数据
git clone https://github.com/tensorflow/serving
# 测试模型的位置保存到一个环境变量里,当然也可以使用绝对路径
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
# 在docker容器里启动tensorflow serving,把8501(rest)端口映射出来
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
# 使用curl测试REST接口
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
# Returns => { "predictions": [2.5, 3.0, 4.5] }
上面的代码首先拉取最新的tensorflow serving镜像,然后clone serving的代码,从而获得可以测试用的模型(当然也可以用自己训练后导出的模型)。最后用docker run来启动tensorflow serving。除了最新的版本,我们也可以拉取某个版本的的镜像,比如拉取1.12.0:
docker pull tensorflow/serving:1.12.0
完整的镜像列表参考这里。
参数说明
上面的docker启动tensorflow/serving镜像时会启动tensorflow_model_server命令,它会有如下默认行为:
-
在8500端口启动gRPC服务
gRPC接口比REST接口更加紧凑一些,因此如果输入的数据很大,比如是一个大视频,那么gRPC接口会更加高效一下。gRPC接口在基础篇我们做过介绍,包括怎么使用Java的gRPC Client。
-
在8501端口启动REST服务
REST接口使用JSON作为输入输出,使用更加简单。注:在比较老的Tensorflow Serving版本,比如1.5,只有gRPC接口而没有REST接口。
-
环境变量 MODEL_NAME,默认是model
-
环境变量 MODEL_BASE_PATH 默认是/models
当docker启动时,会执行如下命令:
tensorflow_model_server --port=8500 --rest_api_port=8501 \
--model_name=${MODEL_NAME} --model_base_path=${MODEL_BASE_PATH}/${MODEL_NAME}
它会在docker的8500和8501分别启动gRPC服务和REST服务。同时模型的名字是环境变量MODEL_NAME,模型的路径是\${MODEL_BASE_PATH}/\${MODEL_NAME}。
注意:上面的命令是在docker里执行(而不是在Host机器上执行),因此port和rest_api_port都是docker里的端口,为了让外部访问,我们需要把它映射到Host机器的端口。model_name是模型的名字,这是客户端请求时需要用到的,比如前面的例子:
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
我们请求的模型名字是half_plus_two,我们也可以在一个Tensorflow Serving上启动多个模型,细节参考基础篇。
model_base_path指定模型的路径,\${MODEL_BASE_PATH}/\${MODEL_NAME},默认是/models/\${model_name}
因此实际我们在Host机器上启动docker的命令类似如下:
docker run -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
-e MODEL_NAME=my_model -t tensorflow/serving
我们通过-p把docker的8501映射成Host的8501端口(而8500没有映射,因此8500的gRPC接口只能在Docker内部访问,而不能在Host以及其它机器上访问),同时我们把Host的路径/path/to/my_model/映射到docker里的/models/my_model,接着我们指定环境变量MODEL_NAME为my_model,最后-t启动tensorflow/serving这个镜像。
根据上面的描述,我们把model_name设置成立my_model,而MODEL_BASE_PATH是默认的/models,因此tensorflow_model_server命令会去/models/my_model下寻找模型,根据前面的–mount的bind,/models/my_model是Host机器的/path/to/my_model/。也就是实际模型存放的位置。
如果我们想让外部可以通过gRPC访问,那么可以增加-p 8500:8500。当然我们不一定要使得Host的端口是8500,也可以是-p 12345:8500。
创建自己的镜像
前面的方法是把模型放到Host机器上,然后通过mount把Host机器的模型目录挂载到Docker里的/models/下。这是需要人(运维)来修改的,他们不了解模型的情况,很容易出错。更好的办法是直接把模型打包到镜像里面,同时像MODEL_NAME这些环境变量也可以放到镜像里,这样运维就不用操心这些了,这就需要我们创建自己的镜像。
我们首先运行基本的tensorflow/sering镜像:
docker run -d --name serving_base tensorflow/serving
为了后面方便引用,我们把它起名为serving_base,然后用-d在后台运行。
接着我们把模型从Host复制到docker的特定位置:
docker cp models/my_model serving_base:/models/my_model
上面我们用到了前面的serving_base这个名字。最后我们commit得到一个新的镜像:
docker commit --change "ENV MODEL_NAME my_model" serving_base my_img
上面我们把有了模型目录的镜像commit得到新的名为my_img的镜像,同时用–change设置环境变量 MODEL_NAME为my_model,这样启动的时候就不需要设置环境变量了。
接下来我们kill掉serving_base然后启动我们自己创建的镜像my_img:
docker kill serving_base
docker run -p 8501:8501 my_img
我们看到上面的启动非常简单,只需要做端口映射和知道image的名字就可以了。
使用GPU
前面我们介绍了可以通过nvidia-docker来在运行Tensorflow Serving时使用GPU,请确保nvidia-docker安装完成。
我们首先拉取GPU版本的Tensorflow Serving镜像:
docker pull tensorflow/serving:1.12.0-gpu
这里我拉取的1.12.0,因为这是我的CUDA Driver支持的最新的版本,如果拉取latest-gpu,那么运行时会出现如下的错误:
docker: Error response from daemon: OCI runtime create failed: container_linux.go:348: starting container process caused "process_linux.go:402: container init caused \"process_linux.go:385: running prestart hook 1 caused \\\"error running hook: exit status 1, stdout: , stderr: exec command: [/usr/bin/nvidia-container-cli --load-kmods configure --ldconfig=@/sbin/ldconfig.real --device=all --compute --utility --require=cuda>=10.0 brand=tesla,driver>=384,driver<385 --pid=22318 /var/lib/docker/overlay2/c41ef77cb1dd5b1448625c5b643b002c25396a5cc7311e974a4e6551cfd74c9c/merged]\\\\nnvidia-container-cli: requirement error: unsatisfied condition: brand = tesla\\\\n\\\"\"": unknown.
接下来启动docker:
docker run --runtime=nvidia -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving:1.12.0-gpu
和前面不同的是需要增加–runtime-nvidia,这样就会使用nvidia-docker了。如果在没有GPU的机器上(或者CUDA驱动有问题)运行会出现类似下面的错误:
Cannot assign a device for operation 'a': Operation was explicitly assigned to /device:GPU:0
使用Docker来开发
我们也可以用dev的版本来训练模型,我首先拉取dev的镜像:
docker pull tensorflow/serving:latest-devel
或者是GPU的版本:
docker pull tensorflow/serving:1.12.0-devel-gpu
注意:如果是GPU的版本,确保拉取但是你的CUDA Driver支持的版本。
拉取之后我们可以用交互的方式(-i)启动docker:
docker run -it -p 8500:8500 tensorflow/serving:latest-devel
我们可以在Docker里面训练模型、启动Tensorflow Serving服务并且测试客户端:
# 训练mnist模型并且保存到/tmp/mnist_model
python tensorflow_serving/example/mnist_saved_model.py /tmp/mnist_model
# 启动tensorflow_model_server
tensorflow_model_server --port=8500 --model_name=mnist --model_base_path=/tmp/mnist_model/ &
# 测试gRPC的client
python tensorflow_serving/example/mnist_client.py --num_tests=1000 --server=localhost:8500
自己构建Tensorflow Serving镜像
对于GPU的版本,我们通常不需要构建自己的,除非我们修改了Tensorflow Serving的代码。但是对于CPU的版本,为了性能考虑我们通常需要自己构建镜像,因为前面介绍过了,为了让尽可能多的系统可以运行,CPU的版本没有使用特定平台的指令集来优化。这些Build版本会带上–config=nativeopt,从而尽量优化性能。
获取代码
我们首先clone Tensorflow Serving代码(前面如果已经clone过了可以跳过):
git clone https://github.com/tensorflow/serving
cd serving
构建ModelServer
接着我们需要构建优化版本的ModelServer,如果是CPU版本的,使用:
docker build --pull -t $USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile.devel .
如果机器安装了Intel的MKL库(据说要比开源的OpenBLAS快),那么可以使用:
docker build --pull -t $USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile.devel-mkl .
如果要构建GPU的镜像(前面说了必要性不大),可以:
docker build --pull -t $USER/tensorflow-serving-devel-gpu \
-f tensorflow_serving/tools/docker/Dockerfile.devel-gpu .
上面的(任选一个)过程会构建$USER/tensorflow-serving-devel这个镜像。
构建自己的Tensorflow Serving 镜像
接下来我们用上面构建的$USER/tensorflow-serving-devel来构建Tensorflow Serving镜像。
如果是CPU版本:
docker build -t $USER/tensorflow-serving \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile .
如果是MKL的CPU版本:
docker build -t $USER/tensorflow-serving \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile.mkl .
如果是GPU的版本:
docker build -t $USER/tensorflow-serving \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile.gpu .
tensorflow-serving-devel和tensorflow-serving的区别
前面的步骤我们首先使用了Dockerfile.devel构建了镜像tensorflow-serving-devel,接着用Dockerfile构建了tensorflow-serving,好奇的读者可能会问它们有什么区别呢?
tensorflow-serving-devel镜像可以认为是构建Tensorflow Serving的过程,编译Tensorflow Serving需要安装Bazel,需要准备很多依赖,因此会非常大。打好这个image之后我们运行Tensorflow Serving其实不需要这些,比如我们运行Tensorflow Serving肯定不需要Bazel,因此就有了后面的构建Tensorflow Serving的镜像的过程。
- 显示Disqus评论(需要科学上网)