本文介绍计算机视觉的常见任务。更多文章请点击深度学习理论与实战:提高篇。
目录
如图下图所示,常见的图像识别任务包括图像分类(Image Classification)、目标检测(Object Detection)、语义分割(Semantic Segmentation)和实例分割(Instance Segmentation)。
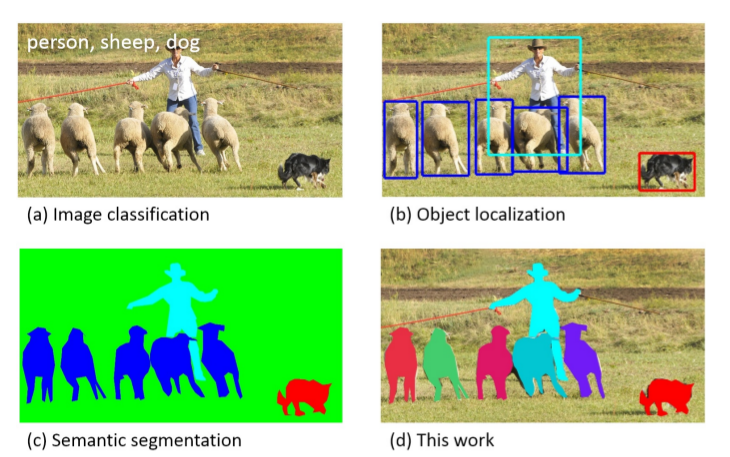 图:常见计算机视觉任务的比较,图片来自COCO dataset
图:常见计算机视觉任务的比较,图片来自COCO dataset
图像分类我们已经介绍过了,它的输入是一张图片,输出其类别。有的数据比如(MNIST或者CIFAR10)每张图片只有一个物体,而有些数据比如ImageNet的图片里可能包含多个物体,标注的时候一般只标注一个物体,评价时通常使用top-5的准确率。也就是模型按照概率从高到低输出5个类别,只要正确的类别包含在这5个类别中就算对。因此图像分类判断图片中是否存在某类(一个或者多个)物体。
目标检测除了需要检测出图片中包含的目标物体,同时还需要标注一个Bounding box——一个包含物体每一个像素的最小矩形框。一个图片中可能包含多个目标物体,因此目标检查需要检测出所有的目标物体,同时还要通过Bounding box定位(localize)它们。
语义分割需要判断每个像素属于哪个类别,而实例分割需要判断每个像素属于哪个实体。注意语义分割和实例分割的区别:比如上图中有6只羊,语义分割只要标注出来某个像素属于羊就算对;而后一个任务需要标注出来某个像素属于对应的羊才算对。如果有两只羊有重叠,那么语义分割可能比较容易的判断重叠的像素是属于羊的,但是要判断属于哪一只羊就更困难了。
上面任务的难度是逐渐增加的,我们这里会介绍目标检测和实例分割的一些算法。当然如果实现了实例分割,自然就实现了语义分割;而实现了语义分割,自然就实现了图像分类;而实现了目标检测,也就实现了图像分类。注意:语义分割和目标检测没有这种包含关系,因为语义分割只需要判断这个像素点属于羊,但不需要判断图片中有几只羊。
- 显示Disqus评论(需要科学上网)