目录
- 模板元编程简介 (Introduction to Template Metaprogramming)
- 类型特性 (Type Traits)
- 常量表达式编程 (Programming with Constant Expressions)
- 在编译期检查程序错误
- 约束和概念 (Constraints and Concepts)
- 元编程的实际应用示例
- 总结
C++ 具备在编译期(Compile Time)评估表达式的能力,这意味着当程序执行时,一些值已经计算完毕。尽管元编程(Metaprogramming)自 C++98 以来就已成为可能,但由于其复杂的基于模板的语法,最初非常复杂。随着 constexpr、if constexpr 以及最近的 C++ Concepts 的引入,元编程已变得与编写常规代码更加相似。
本章将简要介绍 C++ 中的编译期表达式求值,以及它们如何用于性能优化。
我们将涵盖以下主题:
- 使用 C++ 模板进行元编程,以及如何在 C++20 中编写简洁函数模板。
- 使用类型特性(Type Traits)在编译期检查和操作类型。
- 由编译器求值的常量表达式(Constant Expressions)。
- C++20 Concepts 及其如何用于为我们的模板参数添加约束。
- 元编程的一些实际应用示例。
我们将从模板元编程的介绍开始。
模板元编程简介 (Introduction to Template Metaprogramming)
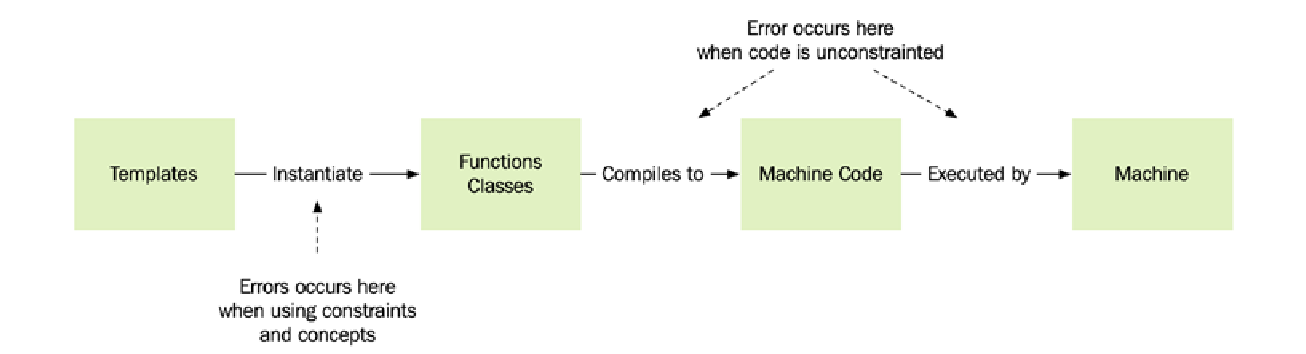
在编写常规 C++ 代码时,它最终会被转换成机器代码。而元编程(Metaprogramming)则允许我们编写将自身转换为常规 C++ 代码的代码。更广义地讲,元编程是一种编写能够转换或生成其他代码的技术。
通过使用元编程,我们可以避免重复编写仅因所用数据类型而略有不同的代码,或者通过预先计算在最终程序执行前即可知晓的值来最小化运行时开销。
当然,我们也可以使用其他语言来生成 C++ 代码。例如,我们可以通过广泛使用预处理器宏来进行元编程,或者编写 Python 脚本来为我们生成或修改 C++ 文件:
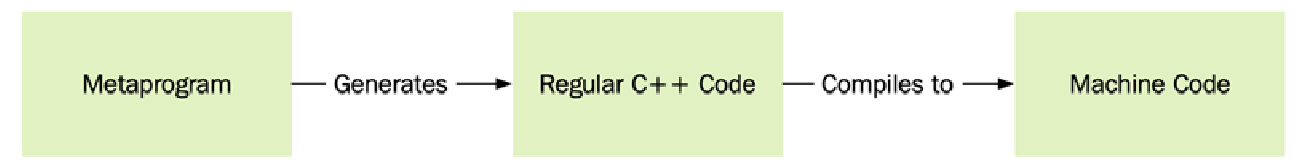
尽管我们可以使用任何语言来生成常规代码,但在 C++ 中,我们有幸可以直接在语言内部使用模板(templates)和常量表达式(constant expressions)来编写元程序。C++ 编译器可以执行我们的元程序并生成常规 C++ 代码,随后编译器会将这些代码进一步转换为机器代码。
直接在 C++ 中使用模板和常量表达式进行元编程相比于使用其他技术有许多优势:
- 我们不必解析 C++ 代码(编译器为我们完成了这项工作)。
- 在使用 C++ 模板元编程时,对 C++ 类型的分析和操作具有出色的支持。
- 元程序的代码与常规的非泛型代码混合在 C++ 源代码中。有时,这可能会使我们难以理解哪些部分分别在运行时和编译期执行。然而,总的来说,这是使 C++ 元编程有效使用的一个非常重要的方面。
在 C++ 中,模板元编程最简单和最常见的形式是用于生成接受不同类型的函数、值和类。当编译器使用某个模板来生成一个类或函数时,我们就说该模板被实例化(instantiated)了。常量表达式则由编译器求值以生成常量值。
这是一个有所简化的观点;并没有规定 C++ 编译器必须以这种方式执行转换。然而,将 C++ 元编程视为在以下两个不同阶段进行是有益的:
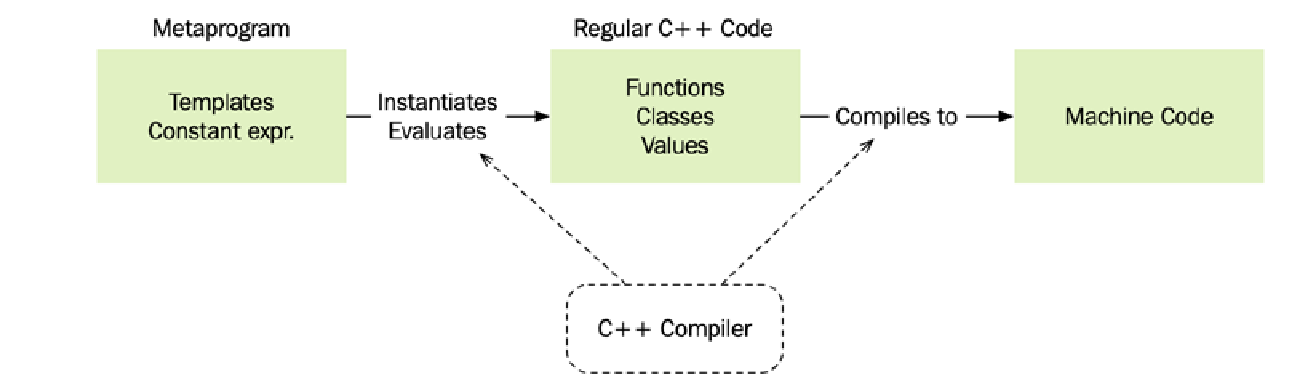
- 初始阶段: 模板和常量表达式生成常规 C++ 代码,包括函数、类和常量值。这个阶段通常被称为常量求值(constant evaluation)。
- 第二阶段: 编译器最终将常规 C++ 代码编译成机器代码。
在本章后续部分,我将把由元编程生成的 C++ 代码称为常规 C++ 代码。
在使用元编程时,重要的是要记住它的主要用途是创建优秀的库,从而向用户代码隐藏复杂的结构/优化。请注意,无论元程序的内部代码多么复杂,重要的是要将其隐藏在一个良好的接口之后,以便用户代码库易于阅读和使用。
接下来,我们将创建第一个用于生成函数和类的模板。
创建模板
让我们看一个简单的 pow() 函数和一个 Rectangle 类。通过使用类型模板参数(type template parameter),pow() 函数和 Rectangle 类可以与任何整数或浮点类型一起使用。如果没有模板,我们就必须为每一种基础类型创建一个单独的函数或类。
编写元编程代码可能非常复杂;让它变得更容易的方法之一是,想象预期的常规 C++ 代码应该是什么样子的。
这是一个简单的函数模板示例:
// pow_n 接受任何数字类型
template <typename T>
auto pow_n(const T& v, int n) {
auto product = T{1};
for (int i = 0; i < n; ++i) {
product *= v;
}
return product;
}
使用此函数将生成一个返回类型依赖于模板参数类型的函数:
auto x = pow_n<float>(2.0f, 3); // x 是一个 float
auto y = pow_n<int>(3, 3); // y 是一个 int
在这种情况下,显式模板参数类型(float 和 int)可以(最好)被省略,而由编译器自行推断出来。这种机制被称为模板参数推导(template argument deduction),因为编译器推导出了模板参数。以下示例将产生与上面所示相同的模板实例化:
auto x = pow_n(2.0f, 3); // x 是一个 float
auto y = pow_n(3, 3); // y 是一个 int
相应地,一个简单的类模板可以定义如下:
// Rectangle 可以是任何类型
template <typename T>
class Rectangle {
public:
Rectangle(T x, T y, T w, T h) : x_{x}, y_{y}, w_{w}, h_{h} {}
auto area() const { return w_ * h_; }
auto width() const { return w_; }
auto height() const { return h_; }
private:
T x_{}, y_{}, w_{}, h_{};
};
当使用类模板时,我们可以显式指定模板应该为其生成代码的类型,像这样:
auto r1 = Rectangle<float>{2.0f, 2.0f, 4.0f, 4.0f};
但也可以受益于类模板参数推导(Class Template Argument Deduction, CTAD),让编译器为我们推导参数类型。以下代码将实例化一个 Rectangle<int>:
auto r2 = Rectangle{-2, -2, 4, 4}; // Rectangle<int>
然后,一个函数模板可以接受一个 Rectangle 对象,其中矩形的维度是用任意类型 T 定义的,如下所示:
template <typename T>
auto is_square(const Rectangle<T>& r) {
return r.width() == r.height();
}
类型模板参数是最常见的模板参数。接下来,你将看到如何使用数值参数而不是类型参数。
使用整数作为模板参数
除了通用类型之外,模板还可以是其他类型,例如整数类型和浮点类型。在下面的示例中,我们将在模板中使用一个 int,这意味着编译器将为每一个作为模板参数传递的唯一整数值生成一个新的函数:
template <int N, typename T>
auto const_pow_n(const T& v) {
auto product = T{1};
for (int i = 0; i < N; ++i) {
product *= v;
}
return product;
}
以下代码将强制编译器实例化两个不同的函数:一个求值的平方,一个求值的立方:
auto x2 = const_pow_n<2>(4.0f); // 平方
auto x3 = const_pow_n<3>(4.0f); // 立方
注意模板参数 N 和函数参数 v 之间的区别。对于 N 的每一个值,编译器都会生成一个新函数。然而,v 是作为一个常规参数传递的,因此不会导致生成新函数。
提供模板特化
默认情况下,每当我们使用具有新参数的模板时,编译器都会生成常规 C++ 代码。但也可以为模板参数的某些特定值提供自定义实现。
例如,假设我们想为 const_pow_n() 函数在与整数类型和 $N$ 值为 2 时,提供常规 C++ 代码。我们可以为此情况编写一个模板特化(template specialization),如下所示:
template<>
auto const_pow_n<2, int>(const int& v) {
return v * v;
}
对于函数模板,我们在编写特化时需要固定所有模板参数。例如,不可能只指定 $N$ 的值而让类型参数 $T$ 不指定。然而,对于类模板,可以只指定模板参数的一个子集。这被称为偏特化(partial template specialization)。编译器将首先选择最具体的模板。
我们不能对函数应用偏特化的原因在于函数可以被重载(overloaded)(而类不能)。如果允许混合重载和偏特化,理解起来将非常困难。
编译器如何处理模板函数
当编译器处理一个模板函数时,它会构造一个模板参数被展开的常规函数。以下代码将使得编译器生成常规函数,因为它使用了模板:
auto a = pow_n(42, 3); // 1. 生成新函数: pow_n<int>
auto b = pow_n(42.f, 2); // 2. 生成新函数: pow_n<float>
auto c = pow_n(17.f, 5); // 3. (使用 pow_n<float>)
auto d = const_pow_n<2>(42.f); // 4. 生成新函数: const_pow_n<2, float>
auto e = const_pow_n<2>(99.f); // 5. (使用 const_pow_n<2, float>)
auto f = const_pow_n<3>(42.f); // 6. 生成新函数: const_pow_n<3, float>
因此,在编译时,与常规函数不同,编译器将为每一组唯一的模板参数生成新的函数。这意味着它相当于手动创建了四个不同的函数,看起来像这样:
auto pow_n__int(int v, int n) {/*...*/} // 被 1 使用
auto pow_n__float(float v, int n) {/*...*/} // 被 2 和 3 使用
auto const_pow_n__2_float(float v) {/*...*/} // 被 4 和 5 使用
auto const_pow_n__3_float(float v) {/*...*/} // 被 6 使用
这对于理解元编程的工作原理至关重要。模板代码生成非模板化的 C++ 代码,然后这些代码作为常规代码执行。如果生成的 C++ 代码无法编译,错误将在编译时被捕获。
简洁函数模板
C++20 引入了一种新的简洁语法来编写函数模板,它采用了与泛型 Lambda相同的风格。通过对函数参数类型使用 auto,我们实际上是在创建函数模板,而不是常规函数。
回顾我们最初的 pow_n() 模板,它是这样声明的:
template <typename T>
auto pow_n(const T& v, int n) {
// ...
使用简洁函数模板语法,我们可以转而使用 auto 来声明它:
auto pow_n(const auto& v, int n) { // 声明了一个函数模板
// ...
这两个版本之间的区别是,简洁版本没有为变量 v 的类型提供显式的占位符。由于我们在实现中使用了占位符 T,这段代码将不幸地编译失败:
auto pow_n(const auto& v, int n) {
auto product = T{1}; // 错误:T 是什么?
for (int i = 0; i < n; ++i) {
product *= v;
}
return product;
}
使用 decltype 获取变量类型
为了解决这个问题,我们可以使用 decltype 说明符。decltype 说明符用于检索变量的类型,并在没有显式类型名称可用时使用。
有时,我们需要一个类型的显式占位符,但只有变量名可用。这在使用简洁函数模板语法时,在实现 pow_n() 函数时就发生了。
让我们看看使用 decltype 修复 pow_n() 实现的示例:
auto pow_n(const auto& v, int n) {
auto product = decltype(v){1}; // 替代 T{1}
for (int i = 0; i < n; ++i) { product *= v; }
return product;
}
尽管这段代码可以编译和工作,但我们有点幸运,因为 v 的类型实际上是一个 const 引用,而不是我们期望用于 product 变量的类型。
auto pow_n(const auto& v, int n) {
decltype(v) product{1};
for (int i = 0; i < n; ++i) { product *= v; } // 错误!
return product;
}
现在,我们得到了一个编译错误,因为 product 是一个 const 引用,不能被赋值一个新值。
我们真正想要的是在定义变量 product 时,摆脱 v 类型中的 const 引用。我们可以为此使用一个方便的模板,叫做 std::remove_cvref。这样,我们对 product 的定义将变成:
typename std::remove_cvref<decltype(v)>::type product{1};
唉!在这种特殊情况下,坚持我们最初的 template <typename T> 语法可能会更容易。但现在,你已经学会了如何将 std::remove_cvref 与 decltype 一起使用,这是编写泛型 C++ 代码时常见的模式。
在 C++20 之前,在泛型 Lambda 的主体中看到 decltype 是很常见的。然而,现在可以通过向泛型 Lambda 添加显式模板参数来避免相当不方便的 decltype:
auto pow_n = []<class T>(const T& v, int n) {
auto product = T{1};
for (int i = 0; i < n; ++i) { product *= v; }
return product;
};
在 Lambda 的定义中,我们编写了 <class T> 以便获取一个参数类型的标识符,它可以在函数体内使用。
你可能需要一些时间来习惯使用 decltype 和操作类型的实用工具。std::remove_cvref 一开始可能看起来有点神秘。它是来自 <type_traits> 头文件的一个模板,我们将在下一节中进一步探讨。
类型特性 (Type Traits)
在进行模板元编程时,您经常会发现自己需要在编译期获取有关所处理类型的信息。在编写常规(非泛型)C++ 代码时,我们处理的是我们拥有完整知识的具体类型;但编写模板时则不然,具体的类型直到编译器实例化模板时才确定。类型特性(Type Traits)允许我们提取模板所处理类型的信息,以便生成高效且正确的 C++ 代码。
为了提取模板类型的信息,标准库提供了一个类型特性库,它位于 <type_traits> 头文件中。所有类型特性都在编译期进行求值。
类型特性的类别
类型特性分为两大类别:
- 返回信息值:返回一个布尔值或整数值的类型特性。
- 返回新类型:返回一个新类型的类型特性。这些类型特性也称为元函数(metafunctions)。
这类特性根据输入返回 true 或 false,并以 _v 结尾(v 是 value 的缩写)。
注意:
_v后缀是在 C++17 中添加的。如果您的库实现不提供带_v后缀的类型特性,您可以使用旧版本,例如std::is_floating_point<float>::value。换句话说,去掉_v扩展并添加::value在末尾。
以下是一些使用类型特性进行编译期类型检查的示例,针对基本类型:
auto same_type = std::is_same_v<uint8_t, unsigned char>; // 结果为 true
auto is_float_or_double = std::is_floating_point_v<decltype(3.f)>; // 结果为 true
类型特性也可以用于用户自定义类型:
class Planet {};
class Mars : public Planet {};
class Sun {};
static_assert(std::is_base_of_v<Planet, Mars>); // 断言 Planet 是 Mars 的基类,通过
static_assert(!std::is_base_of_v<Planet, Sun>); // 断言 Planet 不是 Sun 的基类,通过
这类类型特性返回一个新类型,并以 _t 结尾(t 是 type 的缩写)。这些类型特性转换(或元函数)在处理指针和引用时非常有用:
// 类型特性转换示例
using value_type = std::remove_pointer_t<int*>; // -> int
using ptr_type = std::add_pointer_t<float>; // -> float*
我们前面使用过的 std::remove_cvref 类型特性也属于此类别。它用于移除类型中的引用部分(如果有)以及 const 和 volatile 限定符。
注意:
std::remove_cvref是在 C++20 中引入的。在此之前,通常使用std::decay来完成此任务。
使用类型特性 (Using Type Traits)
如前所述,所有类型特性都在编译期求值。例如,下面这个函数,如果值大于或等于零则返回 1,否则返回 -1。对于无符号整数,它可以立即返回 1:
template<typename T>
auto sign_func(T v) -> int {
if (std::is_unsigned_v<T>) {
return 1;
}
return v < 0 ? -1 : 1;
}
由于类型特性是在编译期求值的,因此当分别使用无符号整数和有符号整数调用时,编译器将生成下表所示的代码:

接下来,我们将讨论常量表达式。
常量表达式编程 (Programming with Constant Expressions)
用 constexpr 关键字作为前缀的表达式告诉编译器该表达式应该在编译期求值:
constexpr auto v = 43 + 12; // 常量表达式
constexpr 关键字也可以用于函数。在这种情况下,它告诉编译器:如果所有允许编译期求值的条件都满足,该函数旨在在编译期求值。否则,它将在运行时像常规函数一样执行。
一个 constexpr 函数有一些限制,不允许执行以下操作:
- 处理局部静态变量。
- 处理
thread_local变量。 - 调用任何本身不是
constexpr函数的函数。
有了 constexpr 关键字,编写一个编译期求值的函数就像编写一个常规函数一样简单,因为它的参数是常规参数而不是模板参数。
考虑以下 constexpr 函数:
constexpr auto sum(int x, int y, int z) { return x + y + z; }
我们像这样调用该函数:
constexpr auto value = sum(3, 4, 5);
由于 sum() 的结果用于一个常量表达式,并且它的所有参数都可以在编译期确定,编译器将生成以下常规 C++ 代码:
const auto value = 12;
然后,这段代码像往常一样被编译成机器码。换句话说,编译器求值 constexpr 函数,并生成结果已计算出的常规 C++ 代码。
如果我们调用 sum() 并将结果存储在一个未标记为 constexpr 的变量中,编译器可能(很可能)仍会在编译期求值 sum():
auto value = sum(3, 4, 5); // value 不是 constexpr
总结来说,如果一个 constexpr 函数从一个常量表达式中调用,并且它的所有参数都是常量表达式,那么它保证在编译期求值。
constexpr 函数在运行时上下文
在前面的示例中,求和的值(3, 4, 5)在编译期对编译器是已知的。但是 constexpr 函数如何处理直到运行时才知道值的变量呢?
如前一节所述,constexpr 是给编译器的一个指示,表明在某些条件下,函数可以在编译期求值。如果变量的值直到运行时才可知晓,它们将像常规函数一样被求值。
在以下示例中,x、y 和 z 的值由用户在运行时提供,因此编译器不可能在编译期计算它们的总和:
int x, y, z;
std::cin >> x >> y >> z; // 获取用户输入
auto value = sum(x, y, z); // 运行时执行 sum()
如果我们根本不打算在运行时使用 sum(),我们可以通过将其设置为立即函数(immediate function)来禁止这种用法。
使用 consteval 声明立即函数
一个 constexpr 函数可以在运行时或编译期调用。如果想限制函数的使用,使其只在编译期被调用,我们可以使用关键字 consteval 来代替 constexpr。
假设我们想禁止在运行时使用 sum()。使用 C++20,我们可以用以下代码实现:
consteval auto sum(int x, int y, int z) { return x + y + z; }
使用 consteval 声明的函数称为立即函数(immediate function),并且只能生成常量。如果我们要调用 sum(),我们需要从一个常量表达式中调用它,否则编译将失败:
constexpr auto s = sum(1, 2, 3); // OK
auto x = 10;
auto s = sum(x, 2, 3); // 错误 (Error),表达式不是常量
int x, y, z;
std::cin >> x >> y >> z;
constexpr auto s = sum(x, y, z); // 错误 (Error)
if constexpr 语句 (The if constexpr Statement)
if constexpr 语句允许模板函数在编译期(也称为编译期多态)评估同一函数中的不同代码块。
看下面的示例,一个名为 speak() 的函数模板试图根据类型来区分成员函数:
struct Bear { auto roar() const { std::cout << "roar\n"; } };
struct Duck { auto quack() const { std::cout << "quack\n"; } };
template <typename Animal>
auto speak(const Animal& a) {
if (std::is_same_v<Animal, Bear>) { a.roar(); }
else if (std::is_same_v<Animal, Duck>) { a.quack(); }
}
假设我们编译以下代码行:
auto bear = Bear{};
speak(bear);
编译器将生成一个类似于这样的 speak() 函数:
auto speak(const Bear& a) {
if (true) { a.roar(); }
else if (false) { a.quack(); } // 这一行将无法编译
}
正如您所见,编译器将保留对成员函数 quack() 的调用,而这会导致编译失败,因为 Bear 中不包含 quack() 成员函数。即使 quack() 成员函数永远不会因为 else if (false) 语句而被执行,这种情况也会发生。
为了让 speak() 函数无论类型如何都能编译,我们需要通知编译器:如果 if 语句为 false,我们想完全忽略该代码块。巧合的是,这正是 if constexpr 的作用。
以下是我们如何编写 speak() 函数,使其能够处理 Bear 和 Duck,即使它们不共享通用接口:
template <typename Animal>
auto speak(const Animal& a) {
if constexpr (std::is_same_v<Animal, Bear>) { a.roar(); }
else if constexpr (std::is_same_v<Animal, Duck>) { a.quack(); }
}
当 speak() 使用 Animal == Bear 调用时:
auto bear = Bear{};
speak(bear);
编译器生成的函数如下:
auto speak(const Bear& animal) { animal.roar(); }
当 speak() 使用 Animal == Duck 调用时:
auto duck = Duck{};
speak(duck);
编译器生成的函数如下:
auto speak(const Duck& animal) { animal.quack(); }
如果 speak() 使用任何其他基本类型(如 Animal == int)调用:
speak(42);
编译器生成一个空函数:
auto speak(const int& animal) {}
与常规 if 语句不同,编译器现在能够生成多个不同的函数:一个使用 Bear,另一个使用 Duck,最后一个用于类型既不是 Bear 也不是 Duck 的情况。如果我们想让第三种情况成为编译错误,可以通过添加一个带有 static_assert 的 else 分支来实现:
template <typename Animal>
auto speak(const Animal& a) {
if constexpr (std::is_same_v<Animal, Bear>) { a.roar(); }
else if constexpr (std::is_same_v<Animal, Duck>) { a.quack(); }
else { static_assert(false); } // 触发编译错误
}
与运行时多态性的比较
作为一个旁注,如果我们要使用传统的运行时多态性(使用继承和虚函数)来实现与上一个示例相同的功能,实现方式如下:
struct AnimalBase {
virtual ~AnimalBase() {}
virtual auto speak() const -> void {}
};
struct Bear : public AnimalBase {
auto roar() const { std::cout << "roar\n"; }
auto speak() const -> void override { roar(); }
};
struct Duck : public AnimalBase {
auto quack() const { std::cout << "quack\n"; }
auto speak() const -> void override { quack(); }
};
auto speak(const AnimalBase& a) {
a.speak();
}
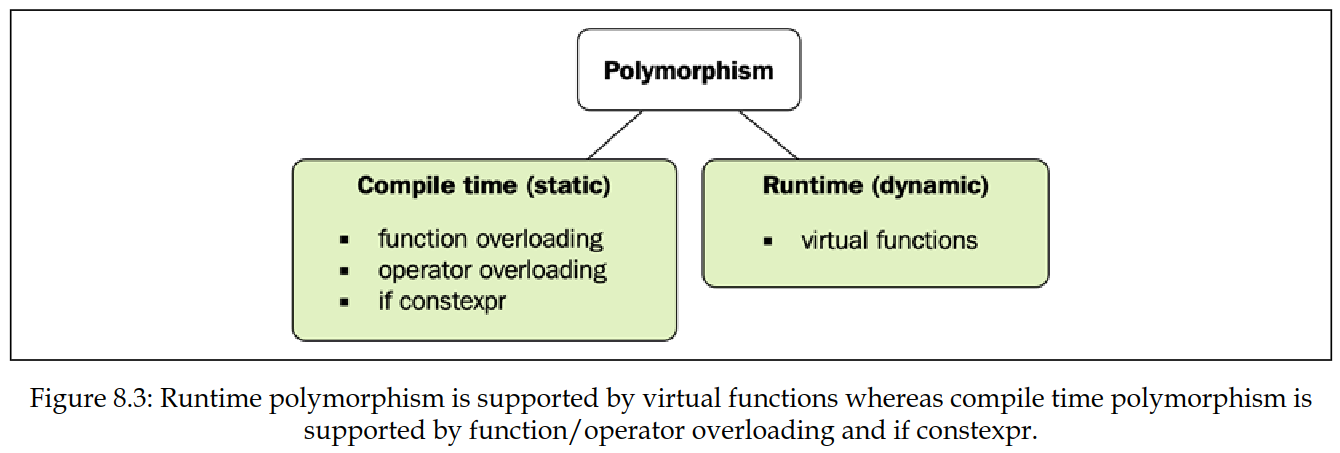
对象必须使用指针或引用访问,并且类型是在运行时推断的,这与编译期版本相比会造成性能损失,因为编译期版本在应用程序执行时一切都已确定。
示例:使用 if constexpr 实现泛型求模函数
这个示例将展示如何使用 if constexpr 来区分运算符和全局函数。在 C++ 中,% 运算符用于获取整数的模数,而 std::fmod() 用于浮点类型。假设我们想泛化代码库,创建一个名为 generic_mod() 的泛型求模函数。
如果我们使用常规 if 语句实现 generic_mod():
template <typename T>
auto generic_mod(const T& v, const T& n) -> T {
assert(n != 0);
if (std::is_floating_point_v<T>) { return std::fmod(v, n); }
else { return v % n; }
}
如果使用 T == float 调用它,它将失败,因为编译器会生成以下函数,该函数无法编译:
auto generic_mod(const float& v, const float& n) -> float {
assert(n != 0);
if (true) { return std::fmod(v, n); }
else { return v % n; } // 将无法编译
}
即使应用程序无法执行到 return v % n; 这一行,编译器也会生成它,但这不符合浮点类型的要求。由于编译器无法为其生成汇编代码,它会编译失败。
像前面的示例一样,我们将 if 语句更改为 if constexpr 语句:
template <typename T>
auto generic_mod(const T& v, const T& n) -> T {
assert(n != 0);
if constexpr (std::is_floating_point_v<T>) {
return std::fmod(v, n);
} else { // 如果 T 是浮点类型,
return v % n; // 这段代码将被消除
}
}
现在,当使用浮点类型调用该函数时,它将生成以下函数,其中 v % n 操作被消除:
auto generic_mod(const float& v, const float& n) -> float {
assert(n != 0);
return std::fmod(v, n);
}
运行时 assert() 告诉我们,如果第二个参数是 0,则不能调用此函数。
在编译期检查程序错误
断言语句(Assert statements)是一个简单但非常强大的工具,用于验证代码库中调用者和被调用者之间的不变量(invariants)和契约(contracts)。(参见第 2 章,核心 C++ 技术)。我们可以使用 assert() 在程序执行时检查编程错误。但是,我们应该始终努力尽早检测错误,如果涉及常量表达式,我们可以使用 static_assert() 在编译程序时就捕获编程错误。
运行时使用 assert 触发错误
回顾模板版本的 pow_n() 函数。假设我们希望阻止它被负指数(n 值)调用。为了在运行时版本中阻止这种情况(其中 n 是一个常规参数),我们可以添加一个运行时断言:
template <typename T>
auto pow_n(const T& v, int n) {
assert(n >= 0); // 仅适用于正数
auto product = T{1};
for (int i = 0; i < n; ++i) {
product *= v;
}
return product;
}
如果函数使用负值 n 调用,程序将中断并通知我们应该从哪里开始查找错误。这很好,但如果能在编译期而不是运行时跟踪到这个错误,那就更好了。
编译期使用 static_assert 触发错误
如果我们在模板版本上做同样的操作,就可以利用 static_assert()。与常规的 assert 不同,static_assert() 声明如果条件不满足,将拒绝编译。因此,在构建(Build)时中断比让程序在运行时中断要好。
在下面的示例中,如果模板参数 N 是一个负数,static_assert() 将阻止函数编译:
template <int N, typename T>
auto const_pow_n(const T& v) {
static_assert(N >= 0, "N must be positive"); // 编译期断言
auto product = T{1};
for (int i = 0; i < N; ++i) {
product *= v;
}
return product;
}
auto x = const_pow_n<5>(2); // 编译通过,N 是正数
auto y = const_pow_n<-1>(2); // 无法编译,N 是负数
换句话说,对于常规变量,编译器只知道其类型,而不知道它包含的值。对于编译期值,编译器既知道其类型也知道其值。这允许编译器计算其他编译期值。
提示:与其使用
int并断言它不是负数,我们本可以使用(也应该)使用unsigned int代替。我们在这个示例中仅使用有符号int是为了演示assert()和static_assert()的用法。
使用编译期断言是检查约束的一种方法。它是一个简单但非常有用的工具。在过去几年中,C++ 对编译期编程的支持取得了令人兴奋的进展。现在,我们将转向 C++20 中最大的特性之一,它将约束检查提升到了一个新的水平。
约束和概念 (Constraints and Concepts)
到目前为止,我们已经介绍了许多用于编写 C++ 元编程的重要技术。您已经了解了模板如何借助类型特性库生成具体的类和函数。此外,您也看到了 constexpr、consteval 和 if constexpr 的使用如何帮助我们将计算从运行时转移到编译期。通过这种方式,我们可以在编译期检测编程错误,并编写具有更低运行时开销的程序。
这很棒,但在编写和使用 C++ 泛型代码方面仍有很大的改进空间。我们尚未解决的一些问题包括:
- 接口过于泛化: 当使用具有任意类型的模板时,很难知道该类型需要满足哪些要求。这使得仅检查模板接口时很难使用模板。相反,我们必须依赖文档或深入研究模板的实现细节。
- 类型错误捕获较晚: 编译器最终会在编译常规 C++ 代码时检查类型,但错误消息通常难以解释。我们希望在模板实例化阶段就能捕获类型错误。
- 无约束的模板参数使元编程复杂: 本章到目前为止我们编写的代码使用了无约束的模板参数(除了一些
static_assert)。这对于小型示例来说尚可管理,但如果能像类型系统帮助我们编写正确的非泛型 C++ 代码一样,访问到更有意义的类型,那么编写和推导我们的元程序就会容易得多。 - 条件代码生成(编译期多态): 虽然可以通过
if constexpr来执行,但大规模使用时很快就会变得难以阅读和编写。
如您将在本节中看到的,C++ 概念通过引入两个新关键字:concept 和 requires,以优雅且有效的方式解决了这些问题。在探索约束和概念之前,我们将花一些时间思考没有概念的模板元编程的缺点。然后,我们将使用约束和概念来强化我们的代码。
无约束版本的 Point2D 模板
假设我们正在编写一个处理二维坐标系的程序。我们有一个类模板表示一个具有 $x$ 和 $y$ 坐标的点:
template <typename T>
class Point2D {
public:
Point2D(T x, T y) : x_{x}, y_{y} {}
auto x() { return x_; }
auto y() { return y_; }
// ...
private:
T x_{};
T y_{};
};
假设我们需要计算两个点的欧几里得距离,如下图所示:
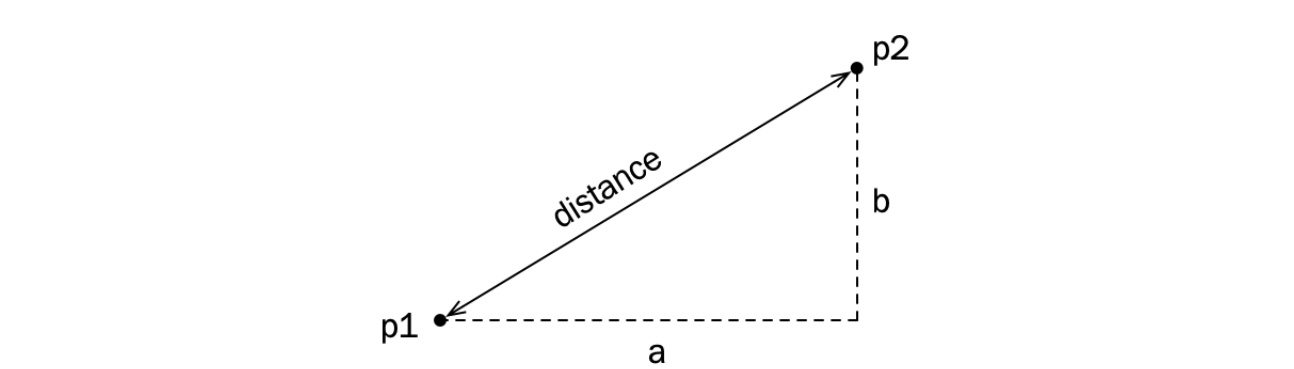
我们实现一个自由函数来计算两个点 $p1$ 和 $p2$ 之间的欧几里得距离,使用勾股定理(实际数学计算在此处不重要):
auto dist(auto p1, auto p2) {
auto a = p1.x() - p2.x();
auto b = p1.y() - p2.y();
return std::sqrt(a*a + b*b);
}
一个小的测试程序验证了我们可以使用整数实例化 Point2D 模板并计算两点之间的距离:
int main() {
auto p1 = Point2D{2, 2};
auto p2 = Point2D{6, 5};
auto d = dist(p1, p2);
std::cout << d; // 输出 5
}
这段代码编译并运行良好,输出 5 到控制台。
泛型接口和糟糕的错误消息
在继续之前,让我们思考一下 dist() 函数模板。假设我们无法轻松访问 dist() 的实现,只能阅读它的接口:
auto dist(auto p1, auto p2) // 接口部分
关于返回值类型以及 p1 和 p2 的类型,我们几乎不能得出任何结论——因为 p1 和 p2 完全没有受到约束,dist() 的接口没有向我们透露任何信息。但这并不意味着我们可以向 dist() 传递任何东西,因为最终生成的常规 C++ 代码必须能够编译。
例如,如果我们尝试用两个整数而不是 Point2D 对象来实例化 dist() 模板,像这样:
auto d = dist(3, 4);
编译器将生成一个类似于这样的常规 C++ 函数:
auto dist(int p1, int p2) {
auto a = p1.x() – p2.x(); // 将产生错误:
auto b = p1.y() – p2.y(); // int 没有 x() 和 y() 成员函数
return std::sqrt(a*a + b*b);
}
这个错误将在编译器检查常规 C++ 代码时较晚被捕获。Clang 在尝试用两个整数实例化 dist() 时会生成以下错误信息:
error: member reference base type 'int' is not a structure or unionauto a = p1.x() – p2.y();
这个错误消息引用了 dist() 的实现,这是 dist() 的调用者不应该需要知道的。这是一个微不足道的例子,但尝试解释由向复杂的模板库提供错误类型引起的错误消息可能是一个真正的挑战。
更糟糕的是,如果我们运气不好,提供的类型完全没有意义,但整个编译过程却通过了。在这种情况下,我们用 const char* 实例化 Point2D:
int main() {
auto from = Point2D{"2.0", "2.0"}; // 糟糕!
auto to = Point2D{"6.0", "5.0"}; // Point2D<const char*>
auto d = dist(from, to);
std::cout << d;
}
它编译并运行了,但输出可能不是我们期望的。我们希望在程序的早期捕获这些错误,这可以通过使用约束和概念来实现:
稍后,您将看到如何使这段代码更具表达力,使其更容易正确使用,更难被误用。我们将通过向代码添加概念和约束来实现这一点。但首先,我将提供一个关于如何定义和使用概念的快速概述。
约束和概念的语法概述
本节简要介绍约束和概念。我们不会在本书中完全涵盖它们,但我会为您提供足够的内容以进行高效编程。
定义新概念
在您已经熟悉的类型特性(type traits)的帮助下,定义新概念非常简单。以下示例使用 concept 关键字定义了 FloatingPoint 概念:
template <typename T>
concept FloatingPoint = std::is_floating_point_v<T>;
赋值表达式的右侧是我们指定类型 T 的约束条件的地方。也可以使用 ||(逻辑或)和 &&(逻辑与)组合多个约束。以下示例使用 || 将浮点数和整数组合成一个 Number 概念:
template <typename T>
concept Number = FloatingPoint<T> || std::is_integral_v<T>;
您会注意到,也可以在右侧使用已经定义的概念来构建新的概念。标准库包含一个 <concepts> 头文件,其中定义了许多有用的概念,例如 std::floating_point(我们应该使用它而不是定义自己的)。
此外,我们可以使用 requires 关键字来添加一组应该添加到我们概念定义中的语句。例如,这是 Ranges 库中 std::range 概念的定义:
template<typename T>
concept range = requires(T& t) {
ranges::begin(t);
ranges::end(t);
};
简而言之,这个概念规定:一个 range 是我们可以传递给 std::ranges::begin() 和 std::ranges::end() 的东西。
可以编写比这更复杂的 requires 子句,稍后您将看到更多内容。
使用概念约束类型
我们可以通过使用 requires 关键字为模板参数类型添加约束。通过使用 std::integral 概念,以下模板只能用整数类型的参数实例化:
template <typename T>
requires std::integral<T>
auto mod(T v, T n) {
return v % n;
}
我们可以在定义类模板时使用相同的技术:
template <typename T>
requires std::integral<T>
struct Foo {
T value;
};
另一种替代语法允许我们通过直接用概念替换 typename 来以更紧凑的方式编写:
template <std::integral T>
auto mod(T v, T n) {
return v % n;
}
这种形式也可以用于类模板:
template <std::integral T>
struct Foo {
T value;
};
如果我们在定义函数模板时想使用简洁函数模板形式,可以将概念放在 auto 关键字前面:
auto mod(std::integral auto v, std::integral auto n) {
return v % n;
}
返回值类型也可以通过使用概念进行约束:
std::integral auto mod(std::integral auto v, std::integral auto n) {
return v % n;
}
如您所见,有多种方法可以指定相同的事物。简洁形式与概念相结合确实使受约束的函数模板既易于阅读又易于编写。C++ 概念的另一个强大功能是以清晰且富有表现力的方式重载函数的能力。
函数重载 (Function Overloading)
回顾我们之前使用 if constexpr 实现的 generic_mod() 函数。它看起来像这样:
template <typename T>
auto generic_mod(T v, T n) -> T {
if constexpr (std::is_floating_point_v<T>) {
return std::fmod(v, n);
} else {
return v % n;
}
}
通过使用概念,我们可以重载函数模板,类似于编写常规 C++ 函数时的做法:
template <std::integral T>
auto generic_mod(T v, T n) -> T { // 整数版本
return v % n;
}
template <std::floating_point T>
auto generic_mod(T v, T n) -> T { // 浮点数版本
return std::fmod(v, n);
}
掌握了约束和概念的新知识,是时候回到我们的 Point2D 模板示例,看看如何改进它了。
Point2D 模板的约束版本
现在您知道了如何定义和使用概念,让我们开始编写一个更好的 Point2D 和 dist() 模板版本。请记住,我们的目标是实现更具表达力的接口,并使由不相关参数类型引起的错误在模板实例化阶段出现。
我们将首先创建一个用于算术类型的概念:
template <typename T>
concept Arithmetic = std::is_arithmetic_v<T>;
接下来,我们将创建一个名为 Point 的概念,它定义了一个点应该具有 x() 和 y() 成员函数,它们返回相同的类型,并且该类型应该支持算术运算:
template <typename T>
concept Point = requires(T p) {
// x() 和 y() 必须返回相同的类型
requires std::is_same_v<decltype(p.x()), decltype(p.y())>;
// 返回类型必须是算术类型
requires Arithmetic<decltype(p.x())>;
};
现在,这个概念可以通过显式约束使 dist() 的接口大大改善:
auto dist(Point auto p1, Point auto p2) {
// 与之前相同...
这看起来非常有前景,所以我们再为返回值类型添加一个约束。尽管 Point2D 可能是用整数类型实例化的,但我们知道距离可能是一个浮点数。标准库中的 std::floating_point 概念非常适合这个需求。这是 dist() 的最终版本:
std::floating_point auto dist(Point auto p1, Point auto p2) {
auto a = p1.x() - p2.x();
auto b = p1.y() - p2.y();
return std::sqrt(a*a + b*b);
}
我们的接口现在更具描述性,当我们尝试用错误的参数类型实例化它时,我们将在实例化阶段而不是最终编译阶段收到错误。
我们现在应该对 Point2D 模板做同样的事情,以避免有人意外地用它不打算处理的类型来实例化它。例如,我们希望阻止有人用 const char* 实例化 Point2D 类,像这样:
auto p1 = Point2D{"2.0", "2.0"}; // 我们如何阻止这种情况?
我们已经创建了 Arithmetic 概念,可以在这里用来约束 Point2D 的模板参数。以下是我们的做法:
template <Arithmetic T> // T 现在被约束了!
class Point2D {
public:
Point2D(T x, T y) : x_{x}, y_{y} {}
auto x() { return x_; }
auto y() { return y_; }
// ...
private:
T x_{};
T y_{};
};
我们需要做的唯一改变是指定类型 T 应该支持 Arithmetic 概念所指定的操作。现在,尝试使用 const char* 实例化模板将在编译器尝试实例化 Point2D<const char*> 类时生成直接错误消息。
向代码添加约束
概念的用处远超模板元编程。它是 C++20 的一个基础特性,改变了我们编写和推导代码的方式,使用的是除了具体类型或完全无约束的 auto 声明变量之外的概念。
概念与类型(例如 int、float 或 Plot2D<int>)非常相似。类型和概念都指定了对象支持的一组操作。通过检查类型或概念,我们可以确定某些对象如何构造、移动、比较以及通过成员函数访问等等。然而,一个很大的区别是:概念不会说明对象在内存中如何存储,而类型除了支持的操作集外,还提供了这些信息。例如,我们可以对类型使用 sizeof 运算符,但不能对概念使用。
通过概念和 auto,我们可以在不需要拼写出确切类型的情况下声明变量,同时仍然非常清晰地表达代码意图。请看下面的代码片段:
const auto& v = get_by_id(42); // 我能对 v 做什么?
大多数时候,当我们遇到这样的代码时,我们更感兴趣的是可以对 v 执行哪些操作,而不是要知道确切的类型。在 auto 前面添加一个概念就带来了改变:
const Person auto& v = get_by_id(42);
v.get_name(); // 现在知道 v 支持 get_name()
概念几乎可以在所有可以使用 auto 关键字的上下文中找到:局部变量、返回值、函数参数等等。在我们的代码中使用概念使其更容易阅读。虽然在编写本书时(2020 年年中),主流 C++ IDE 还没有对概念的额外支持,但基于概念的代码补全以及其他有用的编辑器功能很快就会出现,使 C++ 编程更加有趣和安全。
标准库中的概念
C++20 还包含一个新的 <concepts> 头文件,其中定义了预定义的概念。您已经看到了一些它们的实际应用。许多概念都是基于类型特性库中的 Traits。然而,也有一些以前没有用 Traits 表达过的基础概念。其中最重要的是比较概念,例如 std::equality_comparable 和 std::totally_ordered,以及对象概念,例如 std::movable、std::copyable、std::regular 和 std::semiregular。
我们不会再花时间介绍标准库中的概念,但请记住在开始定义自己的概念之前要考虑它们。在正确的通用性级别上定义概念并非易事,通常基于已有的概念来定义新概念是明智的选择。
让我们以一些 C++ 元编程的实际示例来结束本章。
元编程的实际应用示例
高级元编程可能看起来非常学术化,为了展示其实用性,我们来看一些不仅展示元编程语法,而且展示如何在实践中使用的示例。
示例 1: 创建一个泛型安全转换函数 (Safe Cast)
在 C++ 中进行数据类型转换时,有很多地方可能会出错:
- 如果转换到位长更短的整数类型,您可能会丢失数值。
- 如果将负值转换到无符号整数,您可能会丢失数值。
- 如果将指针转换到
uintptr_t以外的任何其他整数类型,正确的地址可能会变得不正确。这是因为 C++ 只保证uintptr_t是唯一可以容纳地址的整数类型。 - 如果从
double转换到float,如果double的值太大,float无法容纳,结果可能是int。 - 如果使用
static_cast<>()在不共享公共基类的指针之间进行转换,我们可能会得到未定义行为(Undefined Behavior)。
为了使我们的代码更健壮,我们可以创建一个泛型检查转换函数,它在调试模式下验证我们的转换,并在发布模式下尽可能快地执行转换。
根据正在转换的类型,会执行不同的检查。如果我们尝试在未经验证的类型之间进行转换,代码将无法编译。
safe_cast() 旨在处理以下情况:
- 相同类型: 显然,如果转换的是相同类型,我们直接返回输入值。
- 指针到指针: 如果在指针之间转换,
safe_cast()在调试模式下执行dynamic_cast来验证其可转换性。 - Double 到浮点数:
safe_cast()允许从double到float的精度损失,但有一个例外——如果从double转换到float,double值可能太大而float无法处理结果。 - 算术到算术: 如果在算术类型之间转换,该值会被转换回其原始类型,以验证没有精度损失。
- 指针到非指针: 如果从指针转换到非指针类型,
safe_cast()验证目标类型是uintptr_t或intptr_t,这是仅有的保证可以容纳地址的整数类型。
在任何其他情况下,safe_cast() 函数都会编译失败。
让我们看看如何实现这一点。我们首先在 constexpr boolean 中获取有关我们转换操作的信息。它们是 constexpr boolean 而不是 const boolean 的原因是,我们稍后将在需要 constexpr 条件的 if constexpr 表达式中利用它们:
template <typename T> constexpr auto make_false() { return false; }
template <typename Dst, typename Src>
auto safe_cast(const Src& v) -> Dst{
using namespace std;
constexpr auto is_same_type = is_same_v<Src, Dst>;
constexpr auto is_pointer_to_pointer =
is_pointer_v<Src> && is_pointer_v<Dst>;
constexpr auto is_float_to_float =
is_floating_point_v<Src> && is_floating_point_v<Dst>;
constexpr auto is_number_to_number =
is_arithmetic_v<Src> && is_arithmetic_v<Dst>;
constexpr auto is_intptr_to_ptr =
(is_same_v<uintptr_t,Src> || is_same_v<intptr_t,Src>)
&& is_pointer_v<Dst>;
constexpr auto is_ptr_to_intptr =
is_pointer_v<Src> &&
(is_same_v<uintptr_t,Dst> || is_same_v<intptr_t,Dst>);
现在我们已经将所有关于转换的必要信息作为 constexpr boolean 获取,我们将在编译期断言我们可以执行该转换。如前所述,如果条件不满足,static_assert() 将导致编译失败(不像常规 assert 在运行时验证条件)。
注意: 请注意在
if/else链的末尾使用static_assert()和make_false<T>()。我们不能简单地输入static_assert(false),因为那样会阻止safe_cast()完全编译;相反,我们利用模板函数make_false<T>()来延迟生成,直到需要时才进行评估。
当实际执行 static_cast() 时,我们会转换回原始类型,并使用常规的运行时 assert() 验证结果是否等于未转换的参数。这样,我们可以确保 static_cast() 没有丢失任何数据:
if constexpr(is_same_type) {
return v;
}
else if constexpr(is_intptr_to_ptr || is_ptr_to_intptr){
return reinterpret_cast<Dst>(v);
}
else if constexpr(is_pointer_to_pointer) {
assert(dynamic_cast<Dst>(v) != nullptr);
return static_cast<Dst>(v);
}
else if constexpr (is_float_to_float) {
auto casted = static_cast<Dst>(v);
auto casted_back = static_cast<Src>(v);
assert(!isnan(casted_back) && !isinf(casted_back));
return casted;
}
else if constexpr (is_number_to_number) {
auto casted = static_cast<Dst>(v);
auto casted_back = static_cast<Src>(casted);
assert(casted == casted_back);
return casted;
}
else {
static_assert(make_false<Src>(),"CastError");
return Dst{}; // 这永远不会发生,
// static_assert 应该已经失败
}
}
请注意我们如何使用 if constexpr 来让函数条件编译。如果使用常规的 if 语句,函数将无法编译:
auto x = safe_cast<int>(42.0f);
这是因为编译器会尝试编译以下这行,而 dynamic_cast 只接受指针:
// Dst 类型是 int
assert(dynamic_cast<int>(v) != nullptr); // 无法编译
然而,多亏了 if constexpr 和 safe_cast<int>(42.0f) 构造,以下函数可以正确编译:
auto safe_cast(const float& v) -> int {
// ... constexpr auto 都是 false 或 true
if constexpr(is_same_type) { /* 消除 */ }
else if constexpr(is_intptr_to_ptr||is_ptr_to_intptr){/* 消除 */}
else if constexpr(is_pointer_to_pointer) {/* 消除 */}
else if constexpr(is_float_to_float) {/* 消除 */}
else if constexpr(is_number_to_number) {
auto casted = static_cast<int>(v);
auto casted_back = static_cast<float>(casted);
assert(casted == casted_back);
return casted;
}
else { /* 消除 */ }
}
正如您所看到的,除了 is_number_to_number 子句之外,if constexpr 语句之间的所有内容都已被完全消除,从而允许函数编译。
示例 2: 编译期哈希字符串
假设我们有一个资源系统,由一个包含字符串的无序映射(unordered map)组成,这些字符串用于标识位图(bitmap)。如果位图已加载,系统返回已加载的位图;否则,它加载位图并返回它:
// 外部函数,从文件系统加载位图
auto load_bitmap_from_filesystem(const char* path) -> Bitmap {/* ... */}
// 位图缓存
auto get_bitmap_resource(const std::string& path) -> const Bitmap& {
// 所有已加载位图的静态存储
static auto loaded = std::unordered_map<std::string, Bitmap>{};
// 如果位图已经在 loaded_bitmaps 中,返回它
if (loaded.count(path) > 0) {
return loaded.at(path);
}
// 位图尚未加载,加载并返回它
auto bitmap = load_bitmap_from_filesystem(path.c_str());
loaded.emplace(path, std::move(bitmap));
return loaded.at(path);
}
位图缓存随后在需要位图资源的任何地方使用:
- 如果尚未加载,
get_bitmap_resource()函数将加载并返回它。 - 如果已经在其他地方加载,
get_bitmap_resource()将简单地返回已加载的函数。
因此,无论这些绘制函数中哪一个先执行,第二个都不必从磁盘加载位图:
auto draw_something() {
const auto& bm = get_bitmap_resource("my_bitmap.png");
draw_bitmap(bm);
}
auto draw_something_again() {
const auto& bm = get_bitmap_resource("my_bitmap.png");
draw_bitmap(bm);
}
由于我们使用的是无序映射(unordered map),每当我们检查位图资源时,都需要计算一个哈希值。您现在将看到我们如何通过将计算转移到编译期来优化运行时代码。
编译期哈希求和计算的优势
我们试图解决的问题是:每次执行 get_bitmap_resource("my_bitmap.png") 这行代码时,应用程序都将在运行时计算字符串 "my_bitmap.png" 的哈希和。我们希望在编译期执行此计算,以便应用程序执行时,哈希和已经计算好。换句话说,就像您学习使用元编程在编译期生成函数和类一样,我们现在将让它在编译期生成哈希和。
旁注: 您可能已经得出结论,这是一种微优化(micro-optimization):计算一个小字符串的哈希和并不会影响应用程序的整体性能,因为它是一个微小的操作。这可能是完全正确的;但这只是一个将计算从运行时转移到编译期的示例,在其他情况下可能会产生显著的性能影响。在为性能较弱的硬件编写软件时,字符串哈希是一种纯粹的奢侈,但在编译期哈希字符串,可以在任何平台上提供这种奢侈,因为所有计算都在编译期完成。
实现和验证编译期哈希函数
为了让编译器能够在编译期计算哈希和,我们重写 hash_function(),使其接受一个原始的空终止 char 字符串作为参数,而不是 std::string 这样的高级类(后者无法在编译期求值)。
现在,我们可以将 hash_function() 标记为 constexpr:
constexpr auto hash_function(const char* str) -> size_t {
auto sum = size_t{0};
for (auto ptr = str; *ptr != '\0'; ++ptr)
sum += *ptr;
return sum;
}
现在,我们用一个编译期已知的原始字面量字符串调用它:
auto hash = hash_function("abc");
编译器将生成以下常规 C++ 代码,它是对应于 a、b 和 c(97、98 和 99)的 ASCII 值之和:
auto hash = size_t{294};
警告: 仅累加单个值是一个非常糟糕的哈希函数;请不要在实际应用中这样做。它在这里只是为了方便理解。一个更好的哈希函数是使用
boost::hash_combine()组合所有单个字符,如第 4 章《数据结构》中所解释的那样。
hash_function()只有在编译器在编译期知道字符串时才会求值;否则,编译器将在运行时执行constexpr,就像任何其他表达式一样。
现在我们有了哈希函数,是时候创建一个使用它的字符串类了。
构造 PrehashedString 类
我们现在准备实现一个用于预哈希字符串的类,它将使用我们创建的哈希函数。这个类包括以下内容:
- 一个构造函数,接受一个原始字符串作为参数,并在构造时计算哈希值。
- 比较运算符。
- 一个
get_hash()成员函数,返回哈希值。 std::hash()的重载,它简单地返回哈希值。这个重载被std::unordered_map、std::unordered_set或任何其他使用哈希值的标准库类使用。简单来说,这使得容器知道PrehashedString存在一个哈希函数。
以下是 PrehashedString 类的基本实现:
class PrehashedString {
public:
template <size_t N>
constexpr PrehashedString(const char(&str)[N])
: hash_{hash_function(&str[0])},
size_{N - 1}, // 减去 1 是为了避免末尾的空字符
strptr_{&str[0]} {}
auto operator==(const PrehashedString& s) const {
return
size_ == s.size_ &&
std::equal(c_str(), c_str() + size_, s.c_str());
}
auto operator!=(const PrehashedString& s) const {
return !(*this == s); }
constexpr auto size()const{ return size_; }
constexpr auto get_hash()const{ return hash_; }
constexpr auto c_str()const->const char*{ return strptr_; }
private:
size_t hash_{};
size_t size_{};
const char* strptr_{nullptr};
};
namespace std {
template <>
struct hash<PrehashedString> {
constexpr auto operator()(const PrehashedString& s) const {
return s.get_hash();
}
};
} // namespace std
请注意构造函数中的模板技巧。这强制 PrehashedString 只接受编译期字符串字面量。这样做的原因是 PrehashedString 类并不拥有 const char* 指针,因此我们只能将其用于在编译期创建的字符串字面量:
// 编译通过
auto prehashed_string = PrehashedString{"my_string"};
// 无法编译
// 如果 str 被修改,prehashed_string 对象将损坏
// auto str = std::string{"my_string"};
// auto prehashed_string = PrehashedString{str.c_str()};
// 无法编译
// 如果 strptr 被删除,prehashed_string 对象将损坏
// auto* strptr = new char[5];
// auto prehashed_string = PrehashedString{strptr};
既然我们已经准备就绪,让我们看看编译器如何处理 PrehashedString。
求值 PrehashedString
这是一个简单的测试函数,它返回字符串 "abc" 的哈希值(为简单起见):
auto test_prehashed_string() {
const auto& hash_fn = std::hash<PrehashedString>{};
const auto& str = PrehashedString("abc");
return hash_fn(str);
}
由于我们的哈希函数只是简单地求和值,而字母 "abc" 的 ASCII 值分别为 $a=97$、$b=98$ 和 $c=99$,因此汇编器(由 Clang 生成)应该在某个地方输出总和 $97 + 98 + 99 = 294$。检查汇编器,我们可以看到 test_prehashed_string() 函数编译成恰好一个 return 语句,返回 $294$:
mov eax, 294
ret
这意味着整个 test_prehashed_string() 函数已经在编译期执行了;当应用程序执行时,哈希和已经计算出来了!
使用 PrehashedString 求值 get_bitmap_resource()
让我们回到最初的 get_bitmap_resource() 函数,将最初使用的 std::string 替换为 PrehashedString:
// 位图缓存
auto get_bitmap_resource(const PrehashedString& path) -> const Bitmap&
{
// 所有已加载位图的静态存储
static auto loaded_bitmaps =
std::unordered_map<PrehashedString, Bitmap>{};
// 如果位图已经在 loaded_bitmaps 中,返回它
if (loaded_bitmaps.count(path) > 0) {
return loaded_bitmaps.at(path);
}
// 位图尚未加载,加载并返回它
auto bitmap = load_bitmap_from_filesystem(path.c_str());
loaded_bitmaps.emplace(path, std::move(bitmap));
return loaded_bitmaps.at(path);
}
我们还需要一个测试函数:
auto test_get_bitmap_resource() { return get_bitmap_resource("abc"); }
我们想知道的是这个函数是否预计算了哈希和。由于 get_bitmap_resource() 执行了相当多的操作(构造静态 std::unordered_map、检查映射等),生成的汇编代码大约有 500 行。然而,如果我们的“神奇哈希和”在汇编代码中被找到,就意味着我们成功了。
检查 Clang 生成的汇编代码时,我们会找到对应于我们的哈希和 $294$ 的一行:
.quad 294 # 0x126
为了确认这一点,我们将字符串从 "abc" 更改为 "aaa",这应该会将汇编代码中的这行更改为 $97 \cdot 3 = 291$,而其他一切都应保持不变。
我们这样做是为了确保这不是一些无关的“魔法数字”。
检查生成的汇编代码,我们找到了预期的结果:
.quad 291 # 0x123
除了这行之外,所有其他内容都相同,因此我们可以安全地假设哈希是在编译期计算的。
我们所看的这些示例表明,我们可以将编译期编程用于非常不同的事物。添加可以在编译期验证的安全检查使我们无需运行程序和搜索错误,即可发现错误。而将昂贵的运行时操作转移到编译期可以使我们最终的程序更快。
总结
在本章中,您学习了如何使用元编程在编译期而不是运行时生成函数和值。您还发现了如何使用模板、constexpr、static_assert() 和 if constexpr、类型特性(Type Traits)以及 概念(Concepts)以现代 C++ 的方式来做到这一点。此外,通过常量字符串哈希,您看到了如何在实际上下文中应用编译期求值。
在下一章中,您将学习如何通过构造隐藏的代理对象来进一步扩展您的 C++ 工具箱,从而创建库。
- 显示Disqus评论(需要科学上网)