目录
本章将介绍 C++ 实用程序(Utility)库中的一些核心类(Essential Classes)。为了有效地处理包含不同类型元素的集合,我们将使用到前一章介绍的一些元编程技术。
C++ 容器是同质的(homogenous),这意味着它们只能存储单一类型的元素。一个 std::vector<int> 存储的是一个整数集合,而存储在 std::list<Boat> 中的所有对象都是 Boat 类型。但有时,我们需要跟踪一个包含不同类型元素的集合。我将这些集合称为异质集合(heterogenous collections)。在一个异质集合中,元素可以具有不同的类型。下图展示了一个同质整数集合和一个包含不同类型元素的异质集合的示例:

本章将涵盖 C++ 实用程序库中的一组有用的模板,这些模板可用于存储多个不同类型的值。本章分为四个部分:
- 使用
std::optional表示可选值 - 使用
std::pair、std::tuple和std::tie()实现固定大小的集合 - 使用元素类型为
std::any和std::variant的标准容器实现动态大小的集合 - 一些真实世界的示例,展示
std::tuple和std::tie()的实用性,以及我们(在第 8 章《编译时编程》中)涵盖的元编程概念
让我们从探索 std::optional 及其一些重要的用例开始。
使用 std::optional 表示可选值
尽管 std::optional 是 C++17 中一个相当小的特性,但它是标准库的一个很好的补充。它简化了一个常见的场景,而这个场景在 std::optional 出现之前无法以清晰直观的方式表达。简而言之,它是一个对任何类型的小型包装器,被包装的类型可以处于已初始化或未初始化两种状态。
用 C++ 的术语来说,std::optional 是一个最大容量为一的栈分配容器。
可选的返回值
在引入 std::optional 之前,没有明确的方法来定义那些可能不会返回一个明确值的函数,比如两条线段的交点。引入 std::optional 之后,这种可选的返回值可以清晰地表达出来。下面是一个返回两条直线可选交点的函数的实现:
// Prerequisite
struct Point { /* ... */ };
struct Line { /* ... */ };
auto lines_are_parallel(Line a, Line b) -> bool { /* ... */ }
auto compute_intersection(Line a, Line b) -> Point { /* ... */ }
auto get_intersection(const Line& a, const Line& b) -> std::optional<Point> {
if (lines_are_parallel(a, b))
return std::optional{compute_intersection(a, b)};
else
return {};
}
std::optional 的语法类似于指针:通过 operator*() 或 operator->() 访问值。尝试使用 operator*() 或 operator->() 访问空的 optional 的值会导致未定义行为。也可以使用 value() 成员函数来访问值,如果 optional 不包含值,该函数将抛出 std::bad_optional_access 异常。下面是一个返回 std::optional 的简单示例:
auto set_magic_point(Point p) { /* ... */ }
auto intersection = get_intersection(line0, line1);
if (intersection.has_value()) {
set_magic_point(*intersection);
}
注意:
std::optional持有的对象始终是栈分配的,将一个类型包装到std::optional中的内存开销是一个bool的大小(通常是一个字节),再加上可能的填充(padding)。
可选的成员变量
假设我们有一个代表人类头部的类(Class)。头部可以戴帽子,也可以不戴帽子。通过使用 std::optional 来表示帽子这个成员变量,实现将尽可能地富有表现力:
struct Hat { /* ... */ };
class Head {
public:
Head() { assert(!hat_); } // hat_ is empty by default
auto set_hat(const Hat& h) { hat_ = h; }
auto has_hat() const { return hat_.has_value(); }
auto& get_hat() const {
assert(hat_.has_value());
return *hat_;
}
auto remove_hat() {
hat_ = {}; // Hat is cleared by assigning to {}
}
private:
std::optional<Hat> hat_;
};
如果没有 std::optional,表示可选的成员变量可能需要依赖指针或额外的 bool 成员变量。两者都有缺点,例如在堆上分配,或者意外地访问一个被认为是空的、且没有警告的可选值。
避免枚举中的空状态
在旧的 C++ 代码库中可以看到一种模式,即在枚举中包含空状态或空值状态。下面是一个示例:
enum class Color { red, blue, none }; // 不要这样做!
在上面的枚举中,none 是一个所谓的空值状态(null state)。在 Color 枚举中添加 none 值的原因是使表示可选颜色成为可能,例如:
auto get_color() -> Color; // 返回一个可选颜色
然而,这种设计使得无法表示非可选的颜色,这使得所有代码都必须处理额外的空状态 none。
一个更好的替代方案是避免额外的空状态,而是使用 std::optional<Color> 类型来表示可选颜色:
enum class Color { red, blue };
auto get_color() -> std::optional<Color>;
这清楚地表明我们可能无法获得颜色。但我们也知道,一旦我们有了一个 Color 对象,它就不可能是空的:
auto set_color(Color c) { /* c 是一个有效颜色,现在使用它 */}
当实现 set_color() 时,我们知道客户端传递的是一个有效的颜色。
std::optional 的排序和比较
std::optional 同样具有可比性(comparable)和可排序性(sortable),遵循下表所示的规则:

因此,如果你对 std::optional<T> 的容器进行排序,空的 optional 值将位于容器的开头,而那些非空的 optional 则会像往常一样排序,如下所示:
auto c = std::vector<std::optional<int>>{ {3}, {}, {1}, {}, {2}};
std::sort(c.begin(), c.end());
// c is {}, {}, {1}, {2}, {3}
如果你习惯于使用指针表示可选值、使用输出参数设计 API,或者在枚举中添加特殊的空状态,那么是时候将 std::optional 添加到你的工具箱中了,因为它为这些反模式提供了一种高效且安全的替代方案。
让我们继续探索可以容纳不同类型元素的固定大小集合。
固定大小的异质集合
C++ 实用程序(Utility)库包含两个可用于存储多个不同类型值的类模板:std::pair 和 std::tuple。它们都是固定大小的集合。就像 std::array 一样,不可能在运行时动态地添加更多值。
std::pair 和 std::tuple 之间的巨大区别在于,std::pair 只能容纳两个值,而 std::tuple 可以在编译时以任意大小进行实例化。我们将从简要介绍 std::pair 开始,然后转向 std::tuple。
使用 std::pair
类模板 std::pair 位于 <utility> 头文件中,自标准模板库引入以来就已在 C++ 中可用。它在标准库中用于算法需要返回两个值的情况,例如 std::minmax(),它可以返回初始化列表中的最小值和最大值:
std::pair<int, int> v = std::minmax({4, 3, 2, 4, 5, 1});
std::cout << v.first << " " << v.second; // 输出: "1 5"
上面的示例显示,std::pair 的元素可以通过成员 first 和 second 进行访问。
在这里,std::pair 存储了相同类型的值,因此在这里返回一个数组也是可能的。但让 std::pair 更有趣的是它可以存储不同类型的值。正因为如此,尽管它只能容纳两个值,我们仍将其视为异质集合。
标准库中 std::pair 存储不同值的示例是关联容器 std::map。std::map 的值类型是一个由键和与该键关联的元素组成的 pair:
auto scores = std::map<std::string, int>{};
scores.insert(std::pair{"Neo", 12}); // 正确但效率低
scores.emplace("Tri", 45); // 应该使用 emplace()
scores.emplace("Ari", 33);
for (auto&& it : scores) { // "it" 是一个 std::pair
auto key = it.first;
auto val = it.second;
std::cout << key << ": " << val << '\n';
}
显式命名 std::pair 类型的要求已经减少,在现代 C++ 中,通常使用初始化列表和结构化绑定来隐藏我们正在处理 std::pair 值的事实。以下示例表达了相同的意思,但没有显式提及底层的 std::pair:
auto scores = std::map<std::string, int> {
{"Neo", 12}, // 初始化列表
{"Tri", 45},
{"Ari", 33}
};
for (auto&& [key, val] : scores) { // 结构化绑定
std::cout << key << ": " << val << '\n';
}
我们将在本章后面讨论更多关于结构化绑定的内容。
顾名思义,std::pair 只能容纳两个值。C++11 引入了一个名为 std::tuple 的新实用程序类,它是 std::pair 的泛化,可以容纳任意数量的元素。
std::tuple
std::tuple 可用作固定大小的异质集合,可以声明为任意大小。与 std::vector 不同,它的尺寸不能在运行时改变;你不能添加或删除元素。
可以像这样显式指定其成员类型来构造一个 tuple:
auto t = std::tuple<int, std::string, bool>{};
或者,我们可以使用类模板参数推导(Class Template Argument Deduction)对其进行初始化,如下所示:
auto t = std::tuple{0, std::string{}, false};
这将使编译器生成一个类,可以大致看作如下结构:
struct Tuple {
int data0_{};
std::string data1_{};
bool data2_{};
};
与 C++ 标准库中的许多其他类一样,std::tuple 也有一个对应的 std::make_tuple() 函数,该函数可以自动从参数中推导出类型:
auto t = std::make_tuple(42, std::string{"hi"}, true);
但如前所述,从 C++17 及以后版本开始,许多这样的 std::make_ 函数变得多余,因为 C++17 类可以从构造函数中推导出这些类型。
访问 tuple 的成员
可以使用自由函数模板 std::get<Index>() 来访问 std::tuple 的单个元素。你可能会问,为什么不能像常规容器一样使用 at(size_t index) 成员函数来访问成员。原因是像 at() 这样的成员函数只允许返回一种类型,而 tuple 在不同索引处由不同类型组成。因此,使用索引作为模板参数的函数模板 std::get():
auto a = std::get<0>(t); // int
auto b = std::get<1>(t); // std::string
auto c = std::get<2>(t); // bool
我们可以想象 std::get() 函数的实现大致如下:
template <size_t Index, typename Tuple>
auto& get(const Tuple& t) {
if constexpr(Index == 0) {
return t.data0_;
} else if constexpr(Index == 1) {
return t.data1_;
} else if constexpr(Index == 2) {
return t.data2_;
}
}
这意味着当我们像这样创建和访问一个 tuple 时:
auto t = std::tuple(42, true);
auto v = std::get<0>(t);
编译器大致生成以下代码:
// Tuple 类首先被生成:
class Tuple {
int data0_{};
bool data1_{};
public:
Tuple(int v0, bool v1) : data0_{v0}, data1_{v1} {}
};
// get<0>(Tuple) 接着被生成为类似于这样:
auto& get(const Tuple& tpl) { return data0_; }
// 然后利用生成的函数:
auto t = Tuple(42, true);
auto v = get(t);
请注意,这个示例只能被视为想象编译器在构造 std::tuple 时生成代码的简化方式;std::tuple 的内部结构非常复杂。不过,理解 std::tuple 类基本上是一个简单结构体(struct),其成员可以通过编译时索引访问是重要的。
注意:
std::get()函数模板也可以使用类型名作为参数。它的使用方式如下:auto number = std::get<int>(tuple); auto str = std::get<std::string>(tuple);只有当指定的类型在 tuple 中仅包含一次时,这才是可能的。
迭代 std::tuple 成员
从程序员的角度来看,std::tuple 似乎可以像任何其他容器一样,使用常规的基于范围的 for 循环进行迭代,如下所示:
auto t = std::tuple(1, true, std::string{"Jedi"});
for (const auto& v : t) {
std::cout << v << " ";
}
这不可能的原因是 const auto& v 的类型只被评估一次,并且由于 std::tuple 包含不同类型的元素,这段代码根本无法编译。
常规算法也是如此,因为迭代器不会改变其指向的类型;因此,std::tuple 既不提供 begin() 或 end() 成员函数,也不提供用于访问值的下标运算符 []。所以,我们需要想出其他方法来展开 tuple。
展开 tuple
由于 tuple 不能像往常一样进行迭代,我们需要做的是使用元编程来展开循环。从前面的示例中,我们希望编译器生成类似于以下的代码:
auto t = std::tuple(1, true, std::string{"Jedi"});
std::cout << std::get<0>(t) << " ";
std::cout << std::get<1>(t) << " ";
std::cout << std::get<2>(t) << " ";
// 打印 "1 true Jedi"
如你所见,我们迭代了 tuple 的每个索引,这意味着我们需要 tuple 中包含的类型/值的数量。然后,由于 tuple 包含不同的类型,我们需要编写一个元函数,为 tuple 中的每种类型生成一个新函数。
如果我们从一个为特定索引生成调用的函数开始,它将如下所示:
template <size_t Index, typename Tuple, typename Func>
void tuple_at(const Tuple& t, Func f) {
const auto& v = std::get<Index>(t);
std::invoke(f, v);
}
然后,我们可以将其与泛型 Lambda 结合使用,就像你在第 2 章《基本 C++ 技术》中学到的那样:
auto t = std::tuple{1, true, std::string{"Jedi"}};
auto f = [](const auto& v) { std::cout << v << " "; };
tuple_at<0>(t, f);
tuple_at<1>(t, f);
tuple_at<2>(t, f);
// 打印 "1 true Jedi"
有了 tuple_at() 函数,我们就可以继续进行实际的迭代了。我们首先需要的是 tuple 中值的数量作为一个编译时常量。幸运的是,这个值可以通过类型特性 std::tuple_size_v<Tuple> 获得。使用 if constexpr,我们可以通过创建一个类似的函数来展开迭代,该函数根据索引采取不同的操作:
- 如果索引等于 tuple 大小,则生成一个空函数。
- 否则,它执行传入索引处的 Lambda,并生成一个索引加 1的新函数。
代码如下所示:
template <typename Tuple, typename Func, size_t Index = 0>
void tuple_for_each(const Tuple& t, const Func& f) {
constexpr auto n = std::tuple_size_v<Tuple>;
if constexpr(Index < n) {
tuple_at<Index>(t, f);
tuple_for_each<Tuple, Func, Index+1>(t, f);
}
}
如你所见,默认索引设置为零,这样我们在迭代时就不必指定它。然后,可以像这样调用 tuple_for_each() 函数,直接将 Lambda 放入其中:
auto t = std::tuple{1, true, std::string{"Jedi"}};
tuple_for_each(t, [](const auto& v) { std::cout << v << " "; });
// 打印 "1 true Jedi"
相当不错;从语法上讲,它看起来与 std::for_each() 算法非常相似。
在 tuple_for_each() 的基础上扩展,可以以类似的方式实现迭代 tuple 的不同算法。以下是 std::any_of() 用于 tuple 的实现示例:
template <typename Tuple, typename Func, size_t Index = 0>
auto tuple_any_of(const Tuple& t, const Func& f) -> bool {
constexpr auto n = std::tuple_size_v<Tuple>;
if constexpr(Index < n) {
bool success = std::invoke(f, std::get<Index>(t));
if (success) {
return true;
}
return tuple_any_of<Tuple, Func, Index+1>(t, f);
} else {
return false;
}
}
它可以像这样使用:
auto t = std::tuple{42, 43.0f, 44.0};
auto has_44 = tuple_any_of(t, [](auto v) { return v == 44; });
函数模板 tuple_any_of() 迭代 tuple 中的每种类型,并为当前索引处的元素生成一个 Lambda 函数,然后将其与 44 进行比较。在这种情况下,has_44 将评估为 true,因为最后一个元素(一个 double 值)是 44。如果我们添加一个无法与 44 比较的类型元素,例如 std::string,我们将收到一个编译错误。
访问 Tuple 元素
在 C++17 之前,有两种标准方式访问 std::tuple 的元素:
- 对于访问单个元素,使用函数
std::get<N>(tuple)。 - 对于访问多个元素,使用函数
std::tie()。
尽管它们都能工作,但执行这样一个简单任务的语法却非常冗长,如下例所示:
// Prerequisite
using namespace std::string_literals; // "..."s
auto make_saturn() { return std::tuple{"Saturn"s, 82, true}; }
int main() {
// Using std::get<N>()
{
auto t = make_saturn();
auto name = std::get<0>(t);
auto n_moons = std::get<1>(t);
auto rings = std::get<2>(t);
std::cout << name << ' ' << n_moons << ' ' << rings << '\n';
// Output: Saturn 82 true
}
// Using std::tie()
{
auto name = std::string{};
auto n_moons = int{};
auto rings = bool{};
std::tie(name, n_moons, rings) = make_saturn();
std::cout << name << ' ' << n_moons << ' ' << rings << '\n';
}
}
为了能够优雅地执行这个常见任务,C++17 引入了结构化绑定(Structured Bindings)。
使用结构化绑定,可以使用 auto 和一个方括号声明列表一次性初始化多个变量。与 auto 关键字一样,你可以使用相应的修饰符来控制这些变量是可变引用、转发引用、const 引用还是值。在下面的例子中,正在构造一个 const 引用的结构化绑定:
const auto& [name, n_moons, rings] = make_saturn();
std::cout << name << ' ' << n_moons << ' ' << rings << '\n';
结构化绑定还可以用于在 for 循环中提取 tuple 的单个成员,如下所示:
auto planets = {
std::tuple{"Mars"s, 2, false},
std::tuple{"Neptune"s, 14, true}
};
for (auto&& [name, n_moons, rings] : planets) {
std::cout << name << ' ' << n_moons << ' ' << rings << '\n';
}
// Output:
// Mars 2 false
// Neptune 14 true
快速提示: 如果你想返回多个带有名变量的参数而不是 tuple 索引,可以返回在函数内部定义的结构体(struct),并使用自动返回类型推导:
auto make_earth() { struct Planet { std::string name; int n_moons; bool rings; }; return Planet{"Earth", 1, false}; } // ... auto p = make_earth(); std::cout << p.name << ' ' << p.n_moons << ' ' << p.rings << '\n';结构化绑定也适用于结构体,所以即使返回的是结构体,我们也可以像下面这样直接捕获单个数据成员:
auto [name, num_moons, has_rings] = make_earth();在这种情况下,我们可以为标识符选择任意名称,因为相关的是
Planet数据成员的顺序,就像返回 tuple 一样。
现在,我们将探讨 std::tuple 和 std::tie() 在处理任意数量的函数参数时的另一个用例。
变长参数模板包
变长参数模板包(The variadic template parameter pack)使程序员能够创建可以接受任意数量参数的模板函数。
具有变长参数数量的函数示例
如果我们要创建一个函数,该函数将任意数量的参数组合成一个字符串,但不使用变长参数模板包,我们就需要使用 C 风格的变长参数(就像 printf() 所做的那样),或者为每种参数数量创建单独的函数:
auto make_string(const auto& v0) {
auto ss = std::ostringstream{};
ss << v0;
return ss.str();
}
auto make_string(const auto& v0, const auto& v1) {
return make_string(v0) + " " + make_string(v1);
}
auto make_string(const auto& v0, const auto& v1, const auto& v2) {
return make_string(v0, v1) + " " + make_string(v2);
}
// ... 依此类推,直到所需的最大参数数量
我们期望的函数用法是这样的:
auto str0 = make_string(42);
auto str1 = make_string(42, "hi");
auto str2 = make_string(42, "hi", true);
如果我们需要大量的参数,这将变得乏味,但有了参数包,我们可以将其实现为一个接受任意数量参数的函数。
如何构造变长参数包
参数包通过在 typename 前面放置三个点来标识,并在变长参数后面放置三个点(中间用逗号分隔)来展开包:
template<typename ...Ts>
auto f(Ts... values) {
g(values...);
}
这是语法解释:
Ts是一个类型列表。<typename ...Ts>表示该函数处理一个列表。values...展开参数包,使得每个值之间添加一个逗号。
将其放入代码中,考虑以下 expand_pack() 函数模板:
template <typename ...Ts>
auto expand_pack(const Ts& ...values) {
auto tuple = std::tie(values...);
}
让我们像这样调用上面的函数:
expand_pack(42, std::string{"hi"});
在这种情况下,编译器将生成一个类似于这样的函数:
auto expand_pack(const int& v0, const std::string& v1) {
auto tuple = std::tie(v0, v1);
}
这是各个参数包部分展开后的样子:

现在,让我们看看如何使用变长参数包创建 make_string() 函数。
使用 std::tuple 迭代参数包
继续实现最初的 make_string() 函数,为了从每个参数创建字符串,我们需要迭代参数包。没有直接迭代参数包的方法,但一个简单的解决方法是使用 std::tie() 从中创建一个 tuple,然后使用 tuple_for_each() 函数模板对其进行迭代,如下所示:
template <typename ...Ts>
auto make_string(const Ts& ...values) {
auto ss = std::ostringstream{};
// Create a tuple of the variadic parameter pack
auto tuple = std::tie(values...);
// Iterate the tuple
tuple_for_each(tuple, [&ss](const auto& v) { ss << v; });
return ss.str();
}
// ...
auto str = make_string("C++", 20); // OK: str is "C++"
参数包通过 std::tie() 转换为 std::tuple,然后使用 tuple_for_each() 进行迭代。回顾一下,我们需要使用 std::tuple 来处理参数的原因是我们想要支持任意数量的不同类型参数。如果我们只需要支持一种特定类型的参数,我们就可以改用 std::array 和基于范围的 for 循环,如下所示:
template <typename ...Ts>
auto make_string(const Ts& ...values) {
auto ss = std::ostringstream{};
auto a = std::array{values...}; // 只支持一种类型
for (auto&& v : a) { ss << v; }
return ss.str();
}
// ...
auto a = make_string("A", "B", "C"); // OK: 只有一种类型
auto b = make_string(100, 200, 300); // OK: 只有一种类型
auto c = make_string("C++", 20); // Error: 混合类型
正如你所见,std::tuple 是一个具有固定大小和固定元素位置的异质集合——或多或少像一个常规的结构体(struct),只是没有命名的成员变量。
我们如何在此基础上进行扩展,以创建一个动态大小的集合(例如 std::vector 和 std::list),但同时能够存储混合类型的元素呢?我们将在下一节中探讨解决此问题的方法。
动态大小的异质集合
本章开头我们提到,C++ 提供的动态大小容器是同质的(homogenous),这意味着我们只能存储单一类型的元素。但有时,我们需要跟踪一个大小动态且包含不同类型元素的集合。为了做到这一点,我们将使用包含 std::any 或 std::variant 类型元素的容器。
最简单的解决方案是使用 std::any 作为基本类型。std::any 对象可以存储任何类型的价值:
auto container = std::vector<std::any>{42, "hi", true};
不过,它有一些缺点。首先,每次访问其中的值时,必须在运行时测试其类型。换句话说,我们完全丢失了存储值的编译时类型信息。相反,我们必须依赖运行时类型检查来获取信息。其次,它在堆上而不是栈上分配对象,这可能会带来显著的性能影响。
如果我们要迭代我们的容器,我们需要显式地告诉每个 std::any 对象:如果你是 int,这样做;如果你是 char 指针,那样做。这是不可取的,因为它需要重复的源代码,而且效率也低于我们将在本章后面介绍的其他替代方案。
以下示例可以编译;类型被显式地测试并进行转换:
for (const auto& a : container) {
if (a.type() == typeid(int)) {
const auto& value = std::any_cast<int>(a);
std::cout << value;
}
else if (a.type() == typeid(const char*)) {
const auto& value = std::any_cast<const char*>(a);
std::cout << value;
}
else if (a.type() == typeid(bool)) {
const auto& value = std::any_cast<bool>(a);
std::cout << value;
}
}
我们不能简单地使用常规的流操作符来打印它,因为 std::any 对象不知道如何访问其存储的值。因此,以下代码无法编译;编译器不知道 std::any 中存储了什么:
for (const auto& a : container) {
std::cout << a; // 不会编译
}
我们通常不需要 std::any 提供的全部类型灵活性,在许多情况下,我们最好使用 std::variant,这是我们接下来要介绍的内容。
std::variant
如果我们不需要在容器中存储任何类型,而是想集中于在容器初始化时声明的固定类型集合,那么 std::variant 是一个更好的选择。
std::variant 相对于 std::any 有两个主要优点:
- 它不会将其包含的类型存储在堆上(与
std::any不同)。 - 它可以被泛型 Lambda 调用,这意味着你不需要显式知道它当前包含的类型(关于这方面的更多信息将在本章后面的部分介绍)。
std::variant 的工作方式与 tuple 有些相似,不同之处在于它一次只存储一个对象。所包含的类型和值是我们最后分配给它的类型和值。下图说明了 std::tuple 和 std::variant 在使用相同类型实例化时的区别:

下面是一个使用 std::variant 的示例:
using VariantType = std::variant<int, std::string, bool>;
VariantType v{};
std::holds_alternative<int>(v); // true, int 是第一个备选类型
v = 7;
std::holds_alternative<int>(v); // true
v = std::string{"Anne"};
std::holds_alternative<int>(v); // false, int 被覆盖
v = false;
std::holds_alternative<bool>(v); // true, v 现在是 bool
我们使用 std::holds_alternative<T>() 来检查 variant 当前是否持有给定的类型。您可以看到,当我们为 variant 分配新值时,其类型会发生变化。
除了存储实际值之外,std::variant 还通过一个通常大小为 std::size_t 的索引来跟踪当前持有的备选类型。这意味着 std::variant 的总大小通常是最大备选类型的大小,加上索引的大小。我们可以使用 sizeof 运算符来验证我们的类型:
std::cout << "VariantType: "<< sizeof(VariantType) << '\n';
std::cout << "std::string: "<< sizeof(std::string) << '\n';
std::cout << "std::size_t: "<< sizeof(std::size_t) << '\n';
使用 Clang 10.0 和 libc++ 编译并运行此代码会生成以下输出:
VariantType: 32
std::string: 24
std::size_t: 8
正如你所见,VariantType 的大小是 std::string 和 std::size_t 大小之和。
std::variant 的异常安全性
当一个新值被分配给一个 std::variant 对象时,它被放置在 variant 当前持有的值所在的相同位置。如果由于某种原因,新值的构造或赋值失败并抛出异常,旧值可能无法恢复。相反,variant 可能会变成无值状态(valueless)。您可以使用成员函数 valueless_by_exception() 来检查 variant 对象是否处于无值状态。这可以通过尝试使用 emplace() 成员函数构造对象来演示:
struct Widget {
explicit Widget(int) { // 抛出异常的构造函数
throw std::exception{};
}
};
auto var = std::variant<double, Widget>{1.0};
try {
var.emplace<1>(42); // 尝试构造一个 Widget 实例
} catch (...) {
std::cout << "exception caught\n";
if (var.valueless_by_exception()) { // var 可能会或可能不会
std::cout << "valueless\n"; // 处于无值状态
} else {
std::cout << std::get<0>(var) << '\n';
}
}
在异常被抛出和捕获之后,初始的 double 值 1.0 可能会或可能不会消失。该操作不保证回滚,这通常是我们期望标准库容器提供的。换句话说,std::variant 不提供强大的异常安全保证,其原因是为了性能开销,因为它将需要 std::variant 使用堆分配。
std::variant 的这种行为是一个有用的特性,而不是一个缺点,因为它意味着您可以在具有实时要求的代码中安全地使用 std::variant。
如果你想要一个堆分配的版本,但具有强大的异常安全保证和“永不为空”的保证,boost::variant 提供了此功能。如果你对实现此类类型所面临的挑战感兴趣,可以阅读 https://www.boost.org/doc/libs/1_74_0/doc/html/variant/design.html,它提供了一个有趣的阅读。
访问 Variants
当访问 std::variant 中的变量时,我们使用全局函数 std::visit()。正如您可能猜到的,在处理异质类型时,我们必须使用我们的主要伙伴:泛型 Lambda:
auto var = std::variant<int, bool, float>{};
std::visit([](auto&& val) { std::cout << val; }, var);
在示例中,使用泛型 Lambda 和 variant var 调用 std::visit() 时,编译器将在概念上将该 Lambda 转换为一个常规类,其中包含针对 variant 中每种类型的 operator() 重载。这看起来类似于这样:
struct GeneratedFunctorImpl {
auto operator()(int&& v) { std::cout << v; }
auto operator()(bool&& v) { std::cout << v; }
auto operator()(float&& v) { std::cout << v; }
};
然后,std::visit() 函数会被展开为一个使用 std::holds_alternative<T>() 的 if...else 链,或一个使用 std::variant 索引的跳转表,以生成对 std::get<T>() 的正确调用。
在前面的示例中,我们将泛型 Lambda 中的值直接传递给 std::cout,而不考虑当前持有的备选类型。但是,如果我们要根据我们正在访问的类型来做不同的事情呢?对于这种情况,可以使用一种模式来定义一个可变参数类模板,它将继承自一组 Lambdas。然后,我们需要为我们正在访问的每种类型定义这个。听起来很复杂,不是吗?这在一开始可能看起来有点神奇,并且也考验了我们的元编程技能,但是一旦我们设置好可变参数类模板,它就很容易使用了。
我们将从可变参数类模板开始。它是这样的:
template<class... Lambdas>
struct Overloaded : Lambdas... {
using Lambdas::operator()...;
};
如果您的编译器是 C++17,您还需要添加一个显式推导指南,但从 C++20 开始则不需要:
template<class... Lambdas>
Overloaded(Lambdas...) -> Overloaded<Lambdas...>;
就是这样。模板类 Overloaded 将继承自我们实例化该模板的所有 Lambdas,并且函数调用运算符 operator()() 将被每个 Lambda 重载一次。现在可以创建一个只包含多个调用运算符重载的无状态对象:
auto overloaded_lambdas = Overloaded{
[](int v) { std::cout << "Int: " << v; },
[](bool v) { std::cout << "Bool: " << v; },
[](float v) { std::cout << "Float: " << v; }
};
我们可以使用不同的参数进行测试,并验证正在调用正确的重载:
overloaded_lambdas(30031); // Prints "Int: 30031"
overloaded_lambdas(2.71828f); // Prints "Float: 2.71828"
现在,我们可以将其与 std::visit() 一起使用,而无需将 Overloaded 对象存储在左值中。它最终看起来像这样:
auto var = std::variant<int, bool, float>{42};
std::visit(Overloaded{
[](int v) { std::cout << "Int: " << v; },
[](bool v) { std::cout << "Bool: " << v; },
[](float v) { std::cout << "Float: " << v; }
}, var);
// Outputs: "Int: 42"
因此,一旦我们设置好 Overloaded 模板,我们就可以使用这种便捷的方式来为不同类型的参数指定一组 Lambdas。在下一节中,我们将开始将 std::variant 与标准容器一起使用。
使用 Variant 的异质集合
既然我们有了一个可以存储所提供列表中的任何类型的 variant,我们就可以将其扩展到异质集合。我们通过简单地创建一个我们的 variant 的 std::vector 来实现:
using VariantType = std::variant<int, std::string, bool>;
auto container = std::vector<VariantType>{};
我们现在可以将不同类型的元素推入我们的 vector:
container.push_back(false);
container.push_back("I am a string"s);
container.push_back("I am also a string"s);
container.push_back(13);
现在,vector 在内存中将如下所示,其中 vector 中的每个元素都包含 variant 的大小,在本例中为 sizeof(std::size_t) + sizeof(std::string):
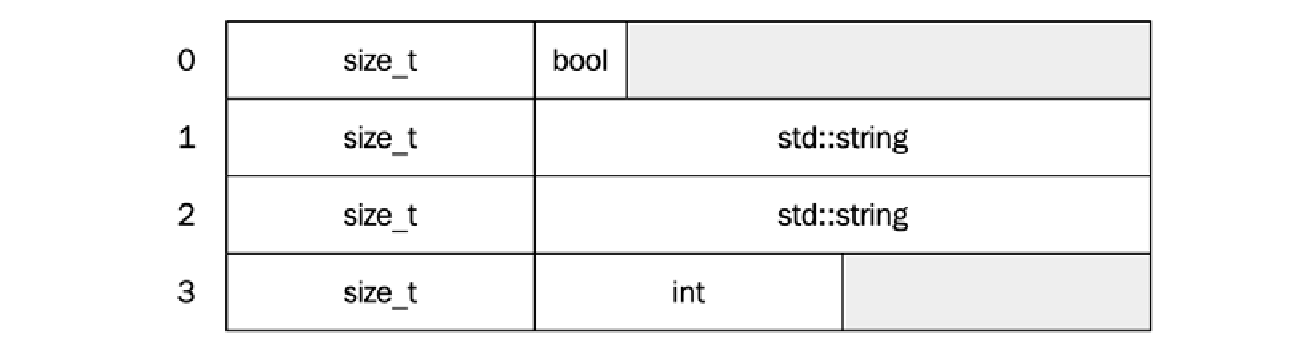
当然,我们也可以 pop_back() 或以容器允许的任何其他方式修改容器:
container.pop_back();
std::reverse(container.begin(), container.end());
// etc...
访问 Variant 容器中的值
现在我们有了动态大小的异质集合的样板,让我们看看如何像常规 std::vector 一样使用它:
-
构造 Variant 的异质容器: 在这里,我们构造一个带有不同类型的
std::vector。请注意,初始化列表包含不同的类型:using VariantType = std::variant<int, std::string, bool>; auto v = std::vector<VariantType>{ 42, "needle"s, true }; -
通过常规
for循环迭代并打印内容: 要使用常规for循环迭代容器,我们利用std::visit()和泛型 Lambda。全局函数std::visit()负责类型转换。该示例将每个值打印到std::cout,与类型无关:for (const auto& item : v) { std::visit([](const auto& x) { std::cout << x << '\n';}, item); } -
检查容器中有哪些类型: 在这里,我们按类型检查容器的每个元素。这是通过使用全局函数
std::holds_alternative<type>实现的,如果 variant 当前持有请求的类型,则返回true。以下示例计算容器中当前包含的布尔值的数量:auto num_bools = std::count_if(v.begin(), v.end(), [](auto&& item) { return std::holds_alternative<bool>(item); }); -
通过包含的类型和值查找内容: 在此示例中,我们通过结合
std::holds_alternative()和std::get()来检查容器的类型和值。此示例检查容器是否包含值为"needle"的std::string:auto contains = std::any_of(v.begin(), v.end(), [](auto&& item) { return std::holds_alternative<std::string>(item) && std::get<std::string>(item) == "needle"; });
全局函数 std::get()
全局函数模板 std::get() 可用于 std::tuple、std::pair、std::variant 和 std::array。有两种方法可以实例化 std::get():使用索引或使用类型:
std::get<Index>(): 当std::get()与索引一起使用时,如std::get<1>(v),它返回std::tuple、std::pair或std::array中相应索引处的值。std::get<Type>(): 当std::get()与类型一起使用时,如std::get<int>(v),它返回std::tuple、std::pair或std::variant中相应的值。对于std::variant,如果 variant 当前不持有该类型,则会抛出std::bad_variant_access异常。
注意: 如果
v是一个std::tuple并且Type包含多次,您必须使用索引来访问该类型。
讨论完 Utility 库中的基本模板后,让我们看看本章中涵盖的内容的一些实际应用。
一些实际示例
我们将通过检查两个示例来结束本章,在这些示例中,std::tuple、std::tie() 和一些模板元编程可以帮助我们在实践中编写简洁高效的代码。
示例 1: 投影和比较操作符
C++20 的出现极大地减少了为类实现比较操作符的必要性,但仍然存在一些情况,我们需要提供自定义的比较函数,以便在特定场景下按自定义顺序对对象进行排序。
考虑以下类:
struct Player {
std::string name_{};
int level_{};
int score_{};
// etc...
};
auto players = std::vector<Player>{};
// Add players here...
假设我们想要根据玩家的属性对他们进行排序:主要排序顺序是 level_,次要排序顺序是 score_。在实现比较和排序时,看到如下代码并不少见:
auto cmp = [](const Player& lhs, const Player& rhs) {
if (lhs.level_ == rhs.level_) {
return lhs.score_ < rhs.score_;
}
else {
return lhs.level_ < rhs.level_;
}
};
std::sort(players.begin(), players.end(), cmp);
以这种风格使用嵌套 if-else 块编写比较操作符,随着属性数量的增加,很快就会变得容易出错。我们真正想要表达的是,我们正在比较 Player 属性的投影(在这个例子中是一个严格的子集)。std::tuple 可以帮助我们以更简洁的方式重写这段代码,而无需使用 if-else 语句。
让我们使用 std::tie(),它创建一个包含我们传入的左值引用的 std::tuple。以下代码创建了两个投影 p1 和 p2,并使用 < 运算符比较它们:
auto cmp = [](const Player& lhs, const Player& rhs) {
auto p1 = std::tie(lhs.level_, lhs.score_); // Projection
auto p2 = std::tie(rhs.level_, rhs.score_); // Projection
return p1 < p2;
};
std::sort(players.begin(), players.end(), cmp);
与最初使用 if-else 语句的版本相比,这非常简洁且易于阅读。但是这真的高效吗?看起来我们需要创建临时对象只是为了比较两个玩家。在微基准测试中运行并检查生成的代码时,使用 std::tie() 完全没有开销;事实上,在这个例子中,使用 std::tie() 的版本比使用 if-else 语句的版本略快。
使用 ranges 算法,我们可以通过将投影作为参数提供给 std::ranges::sort() 来进行排序,这使得代码更加简洁:
std::ranges::sort(players, std::less{}, [](const Player& p) {
return std::tie(p.level_, p.score_);
});
这是一个关于 std::tuple 如何在不需要完整的带有命名成员的结构体的情况下,仍能用于上下文中,而不会牺牲代码清晰度的例子。
示例 2: 反射(Reflection)
术语反射是指在不知道类内容的情况下检查类的能力。与许多其他编程语言不同,C++ 没有内置的反射机制,这意味着我们必须自己编写反射功能。反射计划包含在未来的 C++ 标准中;希望我们能在 C++23 中看到这个特性。
在这个例子中,我们将限制反射的功能,使其能够像迭代 tuple 的成员一样,迭代类的成员。通过使用反射,我们可以创建通用的序列化或日志记录函数,这些函数可以自动适用于任何类。这减少了传统上 C++ 类所需的大量样板代码。
使类反射其成员
由于我们需要自己实现所有的反射功能,我们将从通过一个名为 reflect() 的函数来暴露成员变量开始。我们将继续使用上一节中介绍的 Player 类。添加 reflect() 成员函数和构造函数后,它看起来如下:
class Player {
public:
Player(std::string name, int level, int score)
: name_{std::move(name)}, level_{level}, score_{score} {}
auto reflect() const {
return std::tie(name_, level_, score_);
}
private:
std::string name_;
int level_{};
int score_{};
};
reflect() 成员函数通过调用 std::tie() 返回一个包含成员变量引用的 tuple。我们现在可以开始使用 reflect() 函数了,但首先,请注意使用手动反射的替代方案。
C++ 中简化反射的库
在 C++ 库领域,已经有不少尝试来简化反射的创建。一个例子是 Louis Dionne 的元编程库 Boost Hana,它通过一个简单的宏为类提供了反射功能。最近,Boost 还添加了 Anthony Polukhin 的 Precise and Flat Reflection,它可以自动反射类的公共内容,只要所有成员都是简单类型。
然而,为了清晰起见,在这个例子中,我们将只使用我们自己的
reflect()成员函数。
使用反射
现在 Player 类有了反射其成员变量的能力,我们可以自动化创建批量功能,否则我们将需要重新键入每个成员变量。正如您可能已经知道的,C++ 可以自动生成构造函数、析构函数和比较操作符,但其他操作符必须由程序员实现。其中一个函数是 operator<<(),它将内容输出到流中,以便将它们存储到文件中,或者更常见的是,记录在应用程序日志中。
通过重载 operator<<() 并使用我们在本章前面实现的 tuple_for_each() 函数模板,我们可以简化类的 std::ostream 输出的创建,如下所示:
auto& operator<<(std::ostream& ostr, const Player& p) {
tuple_for_each(p.reflect(), [&ostr](const auto& m) {
ostr << m << " ";
});
return ostr;
}
现在,该类可以与任何 std::ostream 类型一起使用,如下所示:
auto v = Player{"Kai", 4, 2568};
std::cout << v; // Prints: "Kai 4 2568 "
通过通过 tuple 反射我们的类成员,我们只需要在类中添加/删除成员时更新我们的 reflect 函数,而不是更新每个函数并迭代所有成员变量。
有条件地重载全局函数
现在我们有了使用反射而不是手动键入每个变量来编写批量函数的机制,我们仍然需要为每种类型键入简化的批量函数。如果我们希望为所有可以反射的类型生成这些函数呢?
我们可以通过使用约束(constraint),为所有具有 reflect() 成员函数的类有条件地启用 operator<<()。
首先,我们需要创建一个引用 reflect() 成员函数的新概念(Concept):
template <typename T>
concept Reflectable = requires (T& t) {
t.reflect();
};
当然,这个概念只检查一个类是否有一个名为 reflect() 的成员函数;它并不总是返回一个 tuple。一般来说,我们应该对只使用像这样的单个成员函数的弱概念持怀疑态度,但它达到了示例的目的。无论如何,我们现在可以重载全局命名空间中的 operator<<(),使所有可反射的类都能够进行比较并打印到 std::ostream:
auto& operator<<(std::ostream& os, const Reflectable auto& v) {
tuple_for_each(v.reflect(), [&os](const auto& m) {
os << m << " ";
});
return os;
}
上述函数模板将仅为包含 reflect() 成员函数的类型实例化,因此不会与其他重载发生冲突。
测试反射能力
现在,我们已将所有内容准备就绪:
- 我们将测试的
Player类有一个reflect()成员函数,返回一个包含其成员引用的 tuple。 - 全局
std::ostream& operator<<()已为可反射类型重载。
这是一个验证此功能的简单测试:
int main() {
auto kai = Player{"Kai", 4, 2568};
auto ari = Player{"Ari", 2, 1068};
std::cout << kai; // Prints "Kai 4 2568 "
std::cout << ari; // Prints "Ari 2 1068 "
}
这些示例演示了像 std::tie() 和 std::tuple 这样小而基本的实用程序与少量元编程结合时的有用性。
总结
在本章中,您学习了如何使用 std::optional 来表示代码中的可选值。您还了解了如何将 std::pair、std::tuple、std::any 和 std::variant 与标准容器和元编程结合使用,以存储和迭代不同类型的元素。您还了解到 std::tie() 是一个概念简单但功能强大的工具,可用于投影和反射。
在下一章中,您将通过学习如何构造隐藏的代理对象,了解如何进一步扩展您的 C++ 工具箱来创建库。
- 显示Disqus评论(需要科学上网)