本文介绍Git的文件管理和Index
目录
文件管理和Index
在普通的VCS系统里,我们通常会有一个工作目录(Working Directory),我们会对这个目录进行操作,然后定期把修改更新到repo里。Git也类似,只是多了Index这暂存区。我们首先修改工作目录,然后通过”git add”、”git rm”等把修改同步到Index,最后通过commit把Index的所有修改同步到repo里。本节内容就是介绍怎么操作Index区。
Index的重要性
Linus Torvalds在Git的Mailing list里说过:如果不能理解Index,你就不能掌握和欣赏Git。Git的Index不包含任何文件内容,它只是记录你想要提交的内容。当运行git commit的时候,Git会检查Index而不是工作目录,然后根据Index的内容找到哪些需要提交的东西来进行提交。
我们可以用git status来查看Index的状态,也可以用git ls-files查看更多底层的信息。git diff会比较工作目录和Index的差异,因此diff的结果就是工作目录里没有暂存的内容;git diff –cached会比较Index和HEAD(上一次提交)的差异,因此git diff –cached就是下一次用git commit的内容。
Git的文件类型
-
已跟踪的(Tracked)
通过git add加到index里或者通过git commit到repo的里的文件就是已跟踪的,表示这个已经被版本控制系统管理起来了。
-
被忽略的(Ignored)
被忽略的文件,比如代码生成的中间结果或者一些IDE的项目文件/目录,是不需要放到版本控制系统里的,我们可以通过配置告诉git不需要管理这些文件,后面我们会介绍怎么配置。如果不配置,每次用git status都出现在UnTracked的列表里会很烦人,而且也容易不小心加到repo里。
-
未跟踪的(Untracked)
除了已跟踪的和被忽略的,剩下的都是未跟踪的。未跟踪的是新增的那些没有暂存或者提交的文件,而且我们也没有忽略它们。
下面我们通过一个例子来探索这些类别。
$ mkdir /tmp/my_stuff
$ cd /tmp/my_stuff
$ git init
初始化空的 Git 仓库于 /tmp/my_stuff/.git/
$ git status
位于分支 master
初始提交
无文件要提交(创建/拷贝文件并使用 "git add" 建立跟踪)
git status告诉我们没有需要提交的文件,下面我们来加入一些内容:
$ echo "New data" > data
$ git status
位于分支 master
初始提交
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
data
提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪)
一开始,工作目录为空,所以没有需要提交的内容。然后我们创建了一个data文件,这个时候git status告诉我们data文件是未跟踪的,也就是还没有纳入Git的管理之中。
一些代码生成的中间结果,我们通常不希望加到版本控制系统里,比如我们写的一个main.c会被编译成目标文件main.o,我们来模拟一下:
$ touch main.o
在运行git status:
$ git status
位于分支 master
初始提交
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
data
main.o
提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪)
未跟踪的文件又多了一个main.o,但是我们不想让Git管理main.o,当然我们可以在使用git add的时候去除它,但是如果这样的文件太多了,一运行git status就占据整个屏幕,那也很烦并且容易出错,因此我们可以创建一个.gitignore文件,在里面配置需要忽略的文件:
$ echo main.o > .gitignore
再来看看:
$ git status
位于分支 master
初始提交
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
.gitignore
data
提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪)
我们发现main.o不在为跟踪的文件列表里,但是又多了一个.gitignore。这个.gitignore文件是一个特殊文件,git status会认为这个文件里列举的文件是被忽略的(Ignored),但是这个文件本身也可以纳入Git的管理之中。当然我们可以不把这个.gitignore纳入Git的管理之中(我们可以在.gitignore文件里加入内容为.gitignore的一行),但是这个repo的其它用户可能也要类似的困扰,所以一般我们需要把.gitignore也纳入Git的控制之中。
使用git add
git add会暂存(stage)一个文件到Index里,暂存的文件就变成了已跟踪的状态。我们也可以对一个目录进行git add,这时候它会递归的把这个目录的所有文件(多层)都暂存到Index里。注意:git只关心文件,目录结构是文件的一个属性,在树对象里才能体现层次结构。我们继续前面的例子:
$ git add data .gitignore
$ git status
位于分支 master
初始提交
要提交的变更:
(使用 "git rm --cached <文件>..." 以取消暂存)
新文件: .gitignore
新文件: data
在git add之前,这两个文件的状态都是未跟踪的,而git add之后,变成了暂存的(staged)状态。在内部,git会把这两个文件都加到object pool里,并且通过它的SHA1(而不是文件名)来索引查找这个对象,我们可以用git ls-files命令来查看这些暂存的对象:
$ git ls-files --stage
100644 0487f44090ad950f61955271cf0a2d6c6a83ad9a 0 .gitignore
100644 534469f67ae5ce72a7a274faf30dee3c2ea1746d 0 data
--stage(也可以用短形式的-s)选项告诉git ls-files查看暂存的对象。我们的日常工作就是修改工作目录的文件,然后用git add把这些修改暂存到index,如果我们的修改没有git add,则工作目录和index就和存在差异,我们用git diff看到的就是它们的差异。
下面我们再给data增加一行内容:
$ echo "And some more data now" >> data
我们可以看这个修改后的文件的SHA1,git hash-object会计算某个文件的SHA1:
$ git hash-object data
e476983f39f6e4f453f0fe4a859410f63b58b500
这和object pool里的文件是不同的,我们可以把新修改暂存起来:
$ git add data
$ git ls-files --stage
100644 0487f44090ad950f61955271cf0a2d6c6a83ad9a 0 .gitignore
100644 e476983f39f6e4f453f0fe4a859410f63b58b500 0 data
我们看到object pool里暂存的对象发生了变化,原来的data(534469)变成了e47698。这里的git add不是添加(add)一个文件,我们把它理解为添加一个内容更合适,而原来的内容因为没有人引用而变成垃圾被回收掉。
使用git commit的一些注意事项
git commit --all
-a或者--all会让git暂存所有的未暂存并且已经跟踪的文件,包括删除工作目录里的文件,然后提交。下面我们通过一个例子来说明它的用法。
$ mkdir /tmp/commit-all-example
$ cd /tmp/commit-all-example
$ git init
初始化空的 Git 仓库于 /tmp/commit-all-example/.git/
$ echo something >> ready
$ echo somthing else >> notyet
$ git add ready notyet
$ git commit -m "Setup"
[master (根提交) 70d9797] Setup
2 files changed, 2 insertions(+)
create mode 100644 notyet
create mode 100644 ready
上面我们初始化一个repo创建ready和notyet两个文件、暂存它们到Index,最后提交。接下来我们修改ready并且把它加到索引:
$ echo "add to ready" >> ready
$ git add ready
接着我们修改notyet文件,但是不add:
$ echo "add to notyet" >> notyet
接着创建一个新的子目录,往里面加一个文件:
$ mkdir subdir
$ echo Nope >> subdir/new
让我们来看看现在repo的状态:
$ git status
位于分支 master
要提交的变更:
(使用 "git reset HEAD <文件>..." 以取消暂存)
修改: ready
尚未暂存以备提交的变更:
(使用 "git add <文件>..." 更新要提交的内容)
(使用 "git checkout -- <文件>..." 丢弃工作区的改动)
修改: notyet
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
subdir/
目前的状态是:我们修改了notyet,但是没有添加到index里;我们修改了ready并且添加到index里;而subdir(及其下面的文件)还没有纳入Git的管理之下。所以这个时候如果执行git commit,则只会把ready的修改添加到repo里。如果我们使用git commit --all,则git会把notyet也自动的用git add加入到index里然后提交。但是subdir由于未纳入控制,所以不会被add从而更不会被commit。如果我们运行git commit --all而不带-m,则编辑器的注释里会看到它确实是把notyet也提交了:
1
2 # 请为您的变更输入提交说明。以 '#' 开始的行将被忽略,而一个空的提交
3 # 说明将会终止提交。
4 # 位于分支 master
5 # 要提交的变更:
6 # 修改: notyet
7 # 修改: ready
8 #
9 # 未跟踪的文件:
10 # subdir/
11 #
上面是启动VIM的原始注释,第一行是空,第二行开始都是注释,它告诉我们会提交notyet和ready两个文件,而subdir是未跟踪的状态。我们可以用VIM编辑注释,然后保存退出,接着git commit会从VIM读取注释,进行提交:
[master 312deba] git commit --all测试
2 files changed, 2 insertions(+)
从执行的结果看,这次commit确实提交了两个文件的修改。
提交日志
如果指向commit时没有带-m选项,则会弹出一个编辑器,前面我们也介绍了怎么配置你喜欢的编辑器。如果弹出编辑器后你又不想提交,则可以不保存退出编辑器(比如VIM的q!),万一你之前暂存了结果(比如VIM的w)呢?那么你可以把所有的内容都删除,然后再保存退出。git commit发现日志为空,则会中止提交。
使用git rm
git rm是git add的逆操作,它会从Index和工作目录里同时删除这个文件。但是删除文件比较容易出错,所以git rm在删除文件时会更加小心。
git rm要么同时从Index和工作目录里删除一个文件,要么只在Index里删除一个文件(比如你手工删除工作目录里的文件后这个文件只在Index里存在),如果git rm的文件只在工作目录里存在,而index没有,则会失败。这种情况下如果你还想删除工作目录里的这个文件,那么使用操作系统提供的删除文件命令,比如rm而不是git rm。
从Index和工作目录删除一个文件并不会从历史里删除文件,历史是不可删除的,所以我们会碰到这种情况:我们不小心提交了一个不需要的(大)文件,然后用git rm和git commit”删除”它们,但是发现repo的空间并没有变小!如果真的想永久的改下历史(不可恢复!),可以使用git filter-branch或者BFG Repo-Cleaner(推荐)这个工具,读者可以参考github的帮助:Removing files from a repository’s history或者SO问题:How to remove/delete a large file from commit history in Git repository?。
继续前面的例子,我们假设不小心往Index里添加了一个文件:
$ echo "Random stuff" > oops
我们能够用git rm删除这个文件吗?我们来试试:
$ git rm oops
fatal: 路径规格 'oops' 未匹配任何文件
因为oops这个文件还是未跟踪的状态,还没有在Index或者repo里,所以git rm会出错。下面我们先把这个文件用git add加到index里(当然如果这个时候你发现不想要这个文件,直接rm就行):
$ git add oops
$ git status
位于分支 master
要提交的变更:
(使用 "git reset HEAD <文件>..." 以取消暂存)
新文件: oops
运行git add之后,oops已经添加到Index里,运行git status能够确认这一点。而且git status还告诉我们,如果想要取消暂存(也就是只从Index里删除,但是不删除工作目录的这个文件),则可以运行git reset HEAD oops。后面我们会详细介绍git reset,不熟悉的读者暂时可以忽略。注:老版本的git会提示使用git rm –cached,关于这两个命令的差异需要等到介绍git reset,着急的读者可以参考SO问题:“git rm –cached x” vs “git reset head – x”?。
我们看看现在Index里都有哪些内容:
$ git ls-files --stage
100644 0a276f290c955aa51b70feb1dd27db519c4dc513 0 notyet
100644 fcd87b055f261557434fa9956e6ce29433a5cd1c 0 oops
100644 191a2bbbf08a6551ed217f80b5484a1178850b10 0 ready
100644 c9e302a78b5660de810c6a0161c8592ceed1ea5c 0 subdir/new
下面我们用git reset HEAD删除(这里也可以用git rm –cached,在这种状态下它们是等价的,都是只删除index的oops):
$ git reset HEAD oops
$ git ls-files --stage
100644 0a276f290c955aa51b70feb1dd27db519c4dc513 0 notyet
100644 191a2bbbf08a6551ed217f80b5484a1178850b10 0 ready
100644 c9e302a78b5660de810c6a0161c8592ceed1ea5c 0 subdir/new
我们发现这个文件确实从索引里删除了,而且它的状态变成未跟踪:
$ git status
位于分支 master
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
oops
提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪)
如果我们想删除已经提交的文件,比如notyet文件,则可以先用git rm把它从工作目录和Index里删除:
$ rm oops
$ git rm notyet
rm 'notyet'
$ git status
位于分支 master
要提交的变更:
(使用 "git reset HEAD <文件>..." 以取消暂存)
删除: notyet
接下来用git commit从repo里删除(但是历史还在!),注意:git commit删除一个文件时会比较Index里的文件和当前分支的最新版本是否一致,如果不一致则不会允许commit,因为这说明还有修改没有提交到repo里。如果你在这种情况下还想提交,那么可以使用git rm -f之后再git commit。一定要小心!出现这种情况一定是哪出来问题!
使用git mv
如果想移动或者重命名一个文件,可以先用mv移动这个文件、然后git rm删除一个文件,然后再用git add添加新的文件:
$ mv stuff newstuff
$ git rm stuff
$ git add newstuff
第一个命令把stuff文件重命名为newstuff,然后第二个git rm从Index删除stuff(工作目录已经没有了),最后用git add newstuff添加一个新的,当然也可以用cp替代mv:
$ cp stuff newstuff
$ git rm stuff
$ git add newstuff
但是这有一个缺点,需要复制一个文件,如果文件很大,这会很费时并且占据空间。
除了上面的三个命令,我们也可以用git mv这个命令,它等价于上面的三个命令:
$ git mv stuff newstuff
下面我们来实际演练一下,首先我们创建一个测试的repo和一些文件:
$ mkdir /tmp/mv-example
$ cd /tmp/mv-example/
$ mv-example$ git init
初始化空的 Git 仓库于 /tmp/mv-example/.git/
mv-example$ echo "data" > data
mv-example$ git add data
mv-example$ git commit -m "add data"
[master (根提交) 94ef35e] add data
1 file changed, 1 insertion(+)
create mode 100644 data
接着我们用git mv:
$ git mv data mydata
$ git status
位于分支 master
要提交的变更:
(使用 "git reset HEAD <文件>..." 以取消暂存)
重命名: data -> mydata
$ git commit -m "Moved data to mydata"
[master b9e4714] Moved data to mydata
1 file changed, 0 insertions(+), 0 deletions(-)
rename data => mydata (100%)
如果我们想看mydata的历史版本:
$ git log mydata
commit b9e471484176e581f43b817af00d14cee7da7dc0
Author: lili <fancyerii@gmail.com>
Date: Sat Feb 8 17:45:24 2020 +0800
Moved data to mydata
只有mv之后的修改,那之前的修改丢了吗?显然不会,但是我们需要用--follow选项让git继续往上追踪mv前的历史:
$ git log --follow mydata
commit b9e471484176e581f43b817af00d14cee7da7dc0
Author: lili <fancyerii@gmail.com>
Date: Sat Feb 8 17:45:24 2020 +0800
Moved data to mydata
commit 94ef35e7d71c9a5eb2450519b4d65d7d415a7d9b
Author: lili <fancyerii@gmail.com>
Date: Sat Feb 8 17:43:14 2020 +0800
add data
我们发现了这个文件的完整历史,包括mv之前的。很多VCS都很难处理mv,很容易丢失之前的历史,但还是git不会。
处理重命名的细节
本节介绍git是怎么处理文件的重命名的。对于一下早期的版本控制系统比如SVN,因为它保存的是文件和上一个版本的diff,因此它需要格外小心的处理重命名。理论上来说重命名一个文件等价于先删除老文件的全部内容,然后把这些内容加到一个新的文件里,这两个操作是相互独立的应用到(新老)两个文件上的。但是这样一个重命名会带来两个很大的diff,比如一个文件有一千万行,那么这两个diff都是一千万行。那如果要移动或者重命名一个目录,则需要递归的处理下面的所有子目录和文件,这会带来极大的开销。为了避免这个问题,SVN会显示的跟踪文件的重命名。比如我们想把hello.txt重命名(移动)为subdir/hello.txt,我们需要用svn mv而不是svn rm和svn add的组合,如果我们用svn rm和svn add的组合,则SVN不知道新老两个文件是同一个文件,从而无法跟踪之前的历史并且造成两个大的diff!
而Git不需要显示的记录重命名,你可以任意的移动一个文件,这之后修改树对象,而blob对象不会发生变化。git在diff重命名的两个树对象是很容易发现两个节点指向的是同一个blob,从而判断这是一个文件的重命名操作。
.gitignore
前面我们已经介绍过用.gitignore来忽略main.o文件了,下面我们再稍微深入一点讨论一下这个文件。如果我们想忽略一个文件,那么在这个文件相同目录下可以创建一个.gitignore文件,它会让我们忽略这个目录及其子目录(递归)下的main.o文件。如果我们在根目录下创建.gitignore,那么所有的main.o都会被忽略。除了具体的列举每一个文件名,.gitignore也支持更加复杂的模式(pattern)。具体的规则如下:
- git会忽略.gitignore里的空行或者#开头的行,但是如果#不是一行的开头,则不会有什么特殊含义
- 简单的文件名会匹配一个文件
- 如果想忽略一个目录(及其下面的所有内容),可以用目录名加上”/”
- 我们可以用通配符来匹配任意符号,和shell类似,不能匹配/。因此”debug/32bit/*.o”会匹配两层目录debug/32bit下的所有后缀为o的文件
- !表示一个规则的逻辑非
Git对象模型和文件的详细图示
前进介绍了用git跟踪和管理文件的一些常见技巧,但是工作目录、Index和repo的概念很容易混淆,下面我们通过图示的方式来可视化这些概念。我们会展示编辑、暂存到提交的过程中的状态。
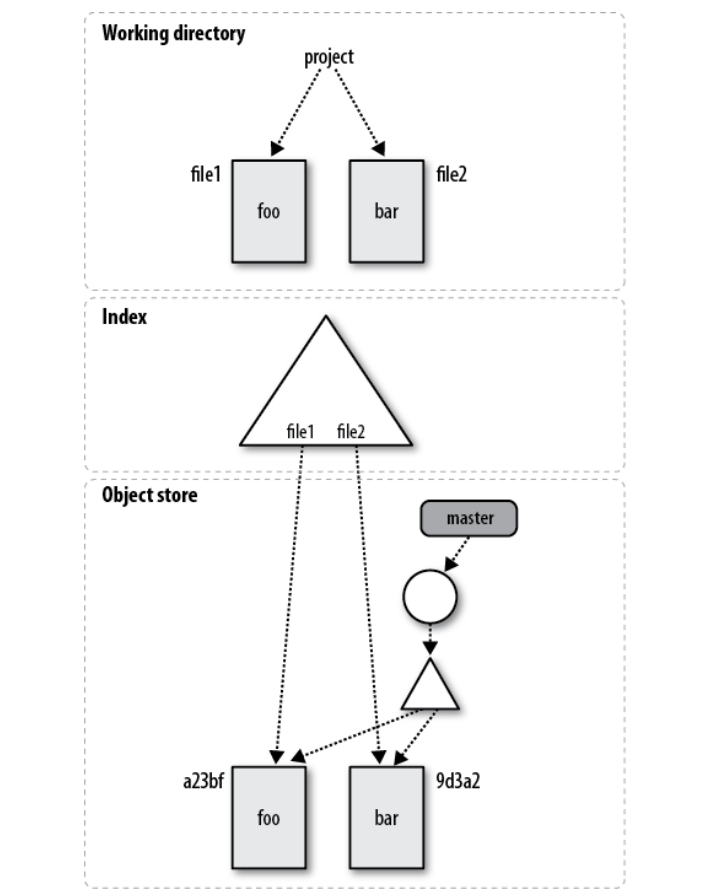 图:初始的文件和状态
图:初始的文件和状态
一开始,工作目录包含file1和file2两个文件,它们的内容分别是”foo”和”bar”。这两个文件也添加到了Index和提交到repo里,因此Index会指向这两个文件,而master分支只有一个提交,它的HEAD就这些这个提交。这个提交的的树对象也包含这两个文件的blob。在这个时候,工作目录、Index和repo是同步的(synchronized),没有脏的(dirty)东西。
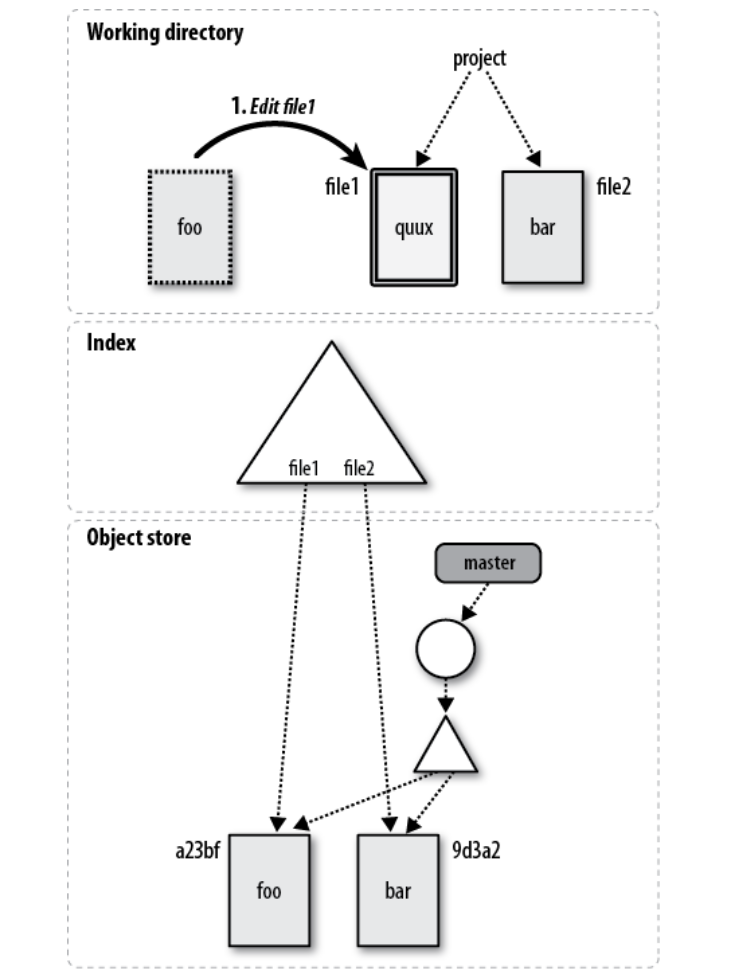 图:编辑file1之后的状态
图:编辑file1之后的状态
接着我们修改file1,把它的内容从foo改成quux。因为还没有add和commit,所以只有工作目录发生了改变,而Index和repo都没有改变。接下来我们使用git add file1把修改更新到Index里,如下图所示:
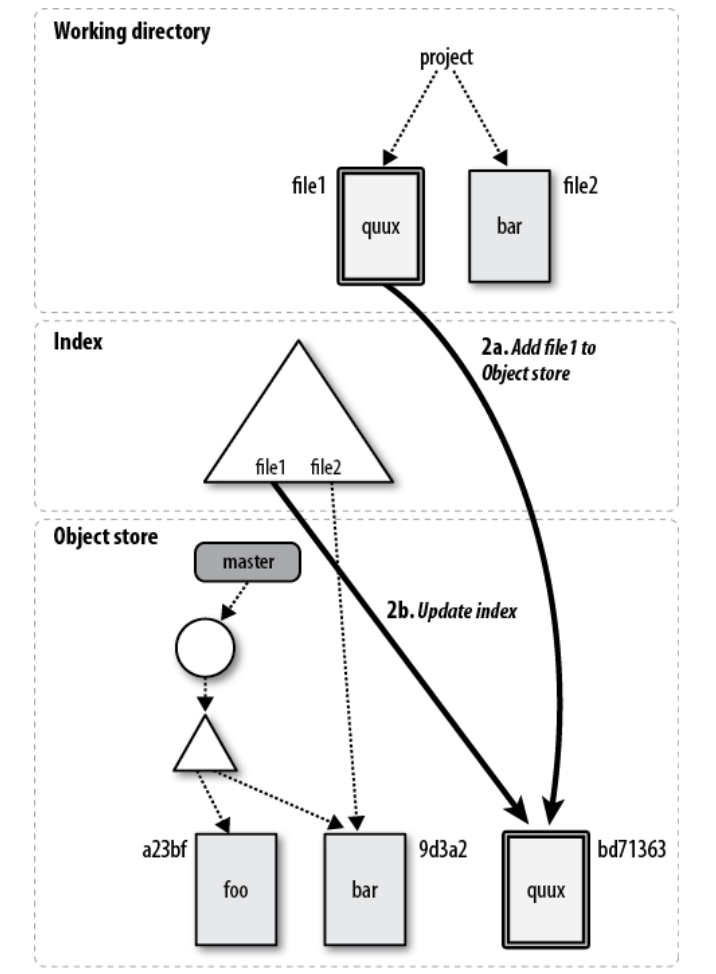 图:git add file1 之后的状态
图:git add file1 之后的状态
执行git add file1时,首先git会计算新文件的SHA1,然后在object pool里创建一个这个新的file1(bd71363),接着更新Index,让file1指向这个新的blob对象。而repo没有变化,master没有新的提交,老的提交的树还是指向老的file1。
最后我们使用git commit把Index里的修改提交到repo里,如下图所示:
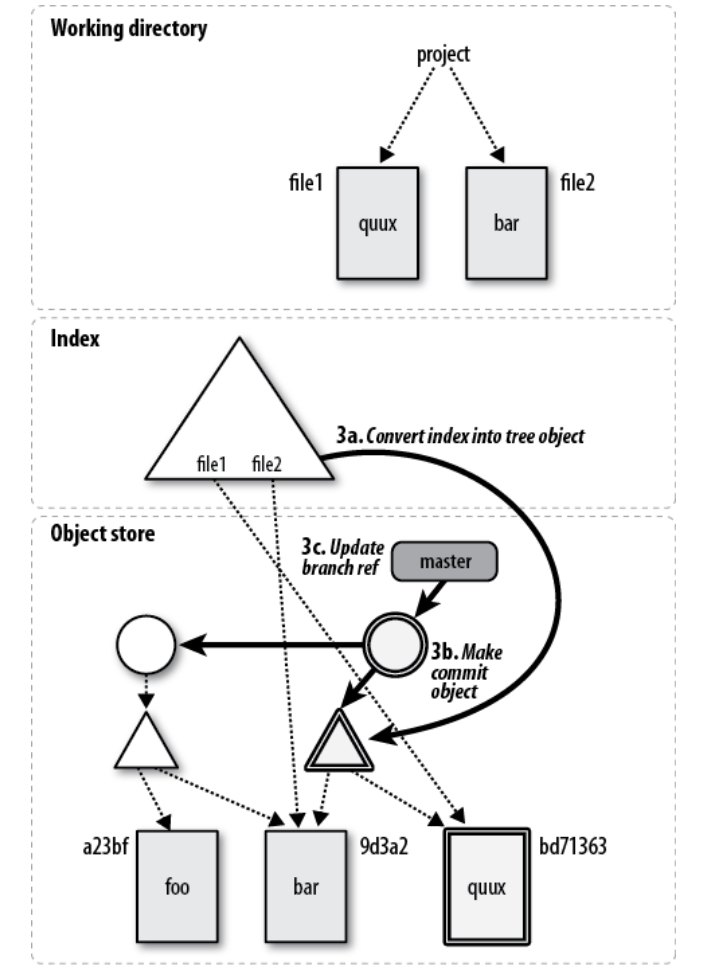 图:git commit 之后的状态
图:git commit 之后的状态
git commit分为三步。第一步(3a)是把Index里的修改变成一个树对象,这个树对象包含file2和新的file1。第二步(3b)是创建一个新的提交(两个圆圈),这个提交包含一个树对象,这个树对象就是第一步得到的树对象;此外还会更新这个新的提交的parent为原来的提交。第三步(3c)是更新master(当前)分支的HEAD,使得master的HEAD指向新的提交。
- 显示Disqus评论(需要科学上网)