本单元学习内容
你将学到什么,以及你将构建什么
音频分类是音频和语音处理中Transformer应用最普遍的应用之一。像机器学习中的其他分类任务一样,该任务涉及根据音频内容将一个或多个标签分配给音频录音。例如,在语音情境中,我们可能希望检测到何时出现像“嘿 Siri”这样的唤醒词,或者从像“今天天气怎么样?”这样的口头查询中推断出“温度”这样的关键词。环境声音提供了另一个例子,我们可能希望自动区分诸如“汽车喇叭”、“警笛”、“狗叫”等声音。
在本节中,我们将看看如何将预训练的音频Transformer应用于一系列音频分类任务。然后,我们将对音乐分类任务上的Transformer模型进行微调,将歌曲分类为“流行”和“摇滚”等流派。这是像 Spotify 这样的音乐流媒体平台的重要部分,它推荐与用户正在收听的歌曲相似的歌曲。
通过本节的学习,你将了解如何:
- 找到适合音频分类任务的预训练模型
- 使用 🤗 数据集库和 Hugging Face Hub 选择音频分类数据集
- 对预训练模型进行微调,以按流派对歌曲进行分类
- 构建一个 Gradio 演示,让你对自己的歌曲进行分类
音频分类的预训练模型和数据集
Hugging Face Hub 拥有超过 500 个音频分类的预训练模型。在本节中,我们将介绍一些最常见的音频分类任务,并为每个任务建议适当的预训练模型。使用 pipeline() 类,切换模型和任务非常简单 - 一旦你知道如何为一个模型使用 pipeline(),你就能够在 Hub 上为任何模型使用它,无需进行代码更改!这使得使用 pipeline() 类进行实验非常快速,让你能够快速选择适合你需求的最佳预训练模型。
在我们深入研究各种音频分类问题之前,让我们快速回顾一下通常使用的Transformer架构。标准的音频分类架构是受任务性质的启发;我们希望将一系列音频输入(即我们的输入音频数组)转换为单个类别标签预测。仅编码器模型首先通过将输入通过一个Transformer块传递来将输入音频序列映射到一系列隐藏状态表示。然后,通过对隐藏状态取平均值,并通过一个线性分类层传递生成的向量,将隐藏状态序列映射到类别标签输出。因此,对于音频分类,首选编码器模型。
解码器模型引入了不必要的复杂性到任务中,因为它们假设输出也可以是一系列预测(而不是单个类别标签预测),因此生成多个输出。因此,它们具有较慢的推理速度,往往不被使用。编码器-解码器模型基本上出于相同的原因被大多数省略。这些架构选择类似于自然语言处理中的选择,在那里,例如 BERT 等仅编码器模型被用于序列分类任务,而诸如 GPT 等仅解码器模型则被保留用于序列生成任务。
现在我们已经回顾了用于音频分类的标准Transformer架构,让我们进入音频分类的不同子集,并涵盖最流行的模型!
🤗 Transformers 安装
在撰写本文时,用于音频分类pipeline的最新更新仅在 🤗 Transformers 存储库的主版本上,而不是最新的 PyPi 版本上。为了确保我们在本地拥有这些更新,我们将使用以下命令从主分支安装 Transformers:
pip install git+https://github.com/huggingface/transformers
关键词检测(Keyword Spotting)
关键词检测(KWS)是识别口语话语中的关键词的任务。可能的关键词集合形成了预测的类别标签集合。因此,要使用预训练的关键词检测模型,您应确保您的关键词与模型预先训练的关键词相匹配。下面,我们将介绍两个用于关键词检测的数据集和模型。
Minds-14
让我们继续使用您在之前单元中探索过的相同的 MINDS-14 数据集。如果您还记得,MINDS-14 包含了人们用几种语言和方言向电子银行系统提问的录音,并且每个录音都有意图类别。我们可以根据通话的意图对录音进行分类。
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
我们将加载检查点 “anton-l/xtreme_s_xlsr_300m_minds14”,这是一个在 MINDS-14 上微调了约 50 个 epochs 的 XLS-R 模型。它在评估集上对来自 MINDS-14 的所有语言都达到了 90% 的准确率。
from transformers import pipeline
classifier = pipeline(
"audio-classification",
model="anton-l/xtreme_s_xlsr_300m_minds14",
)
最后,我们可以将样本传递给分类管道进行预测:
classifier(minds[0]["audio"])
输出:
[
{"score": 0.9631525278091431, "label": "pay_bill"},
{"score": 0.02819698303937912, "label": "freeze"},
{"score": 0.0032787492964416742, "label": "card_issues"},
{"score": 0.0019414445850998163, "label": "abroad"},
{"score": 0.0008378693601116538, "label": "high_value_payment"},
]
太棒了!我们确定通话的意图是支付账单,概率为 96%。你可以想象这种关键词检测系统被用作自动呼叫中心的第一阶段,在这里我们希望根据客户的查询对传入的客户呼叫进行分类,并相应地提供情境化支持。
Speech Commands
Speech Commands 是一个用于评估简单命令词音频分类模型的口语单词数据集。该数据集包含 15 个关键词类别、一个沉默类别以及一个未知类别,以包括假阳性。这 15 个关键词是单词,通常用于设备设置中以控制基本任务或启动其他进程。
类似的模型在您的手机上持续运行。在这里,我们不是使用单个命令词,而是使用特定于您设备的“唤醒词”,如“嘿 Google”或“嘿 Siri”。当音频分类模型检测到这些唤醒词时,它会触发您的手机开始监听麦克风,并使用语音识别模型转录您的语音。
音频分类模型比语音识别模型要小得多、更轻量级,通常只有几百万参数,而语音识别模型则有几亿参数。因此,它可以持续运行在您的设备上,而不会耗尽您的电池!只有在检测到唤醒词时才会启动较大的语音识别模型,然后再次关闭。我们将在下一个单元中介绍用于语音识别的Transformer模型,因此在课程结束时,您应该有所需的工具来构建自己的语音激活助手!
与 Hugging Face Hub 上的任何数据集一样,我们可以在不下载或占用内存的情况下了解它所包含的音频数据的类型。在前往 Speech Commands 数据集卡片的 Hub 后,我们可以使用数据集查看器来滚动浏览数据集的前 100 个样本,听取音频文件并检查任何其他元数据信息:

数据集预览是在决定使用它们之前体验音频数据集的绝佳方式。您可以在 Hub 上选择任何数据集,浏览样本并听取不同子集和拆分的音频,以判断它是否符合您的需求。一旦您选择了数据集,加载数据以开始使用它就非常简单。
让我们来做这件事,并使用流式模式加载 Speech Commands 数据集的一个样本:
speech_commands = load_dataset(
"speech_commands", "v0.02", split="validation", streaming=True
)
sample = next(iter(speech_commands))
我们将加载一个在 Speech Commands 数据集上微调过的官方Audio Spectrogram Transformer检查点,命名空间为 “MIT/ast-finetuned-speech-commands-v2”:
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2"
)
classifier(sample["audio"].copy())
输出:
[{'score': 0.9999892711639404, 'label': 'backward'},
{'score': 1.7504888774055871e-06, 'label': 'happy'},
{'score': 6.703040185129794e-07, 'label': 'follow'},
{'score': 5.805884484288981e-07, 'label': 'stop'},
{'score': 5.614546694232558e-07, 'label': 'up'}]
太棒了!看起来这个示例包含了“backward”这个词的概率很高。我们可以听一下这个样本,并验证这是否正确:
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
现在,您可能想知道我们是如何选择这些预训练模型来展示这些音频分类示例的。事实是,找到适合您数据集和任务的预训练模型非常简单!我们需要做的第一件事是前往 Hugging Face Hub 并点击“模型”选项卡:https://huggingface.co/models
这将显示所有 Hub 上的模型,按过去 30 天的下载次数排序。
您会注意到在左侧我们有一系列选项卡可供选择,可以通过任务、库、数据集等进行模型筛选。向下滚动并从音频任务列表中选择“Audio Classification”任务:

现在,我们看到了 Hub 上 500 多个音频分类模型的子集。为了进一步细化这个选择,我们可以按数据集筛选模型。点击“Datasets”选项卡,在搜索框中键入“speech_commands”。当您开始输入时,您将看到在搜索选项卡下方出现的 speech_commands 选择。您可以点击此按钮将所有音频分类模型过滤为在 Speech Commands 数据集上微调过的模型:
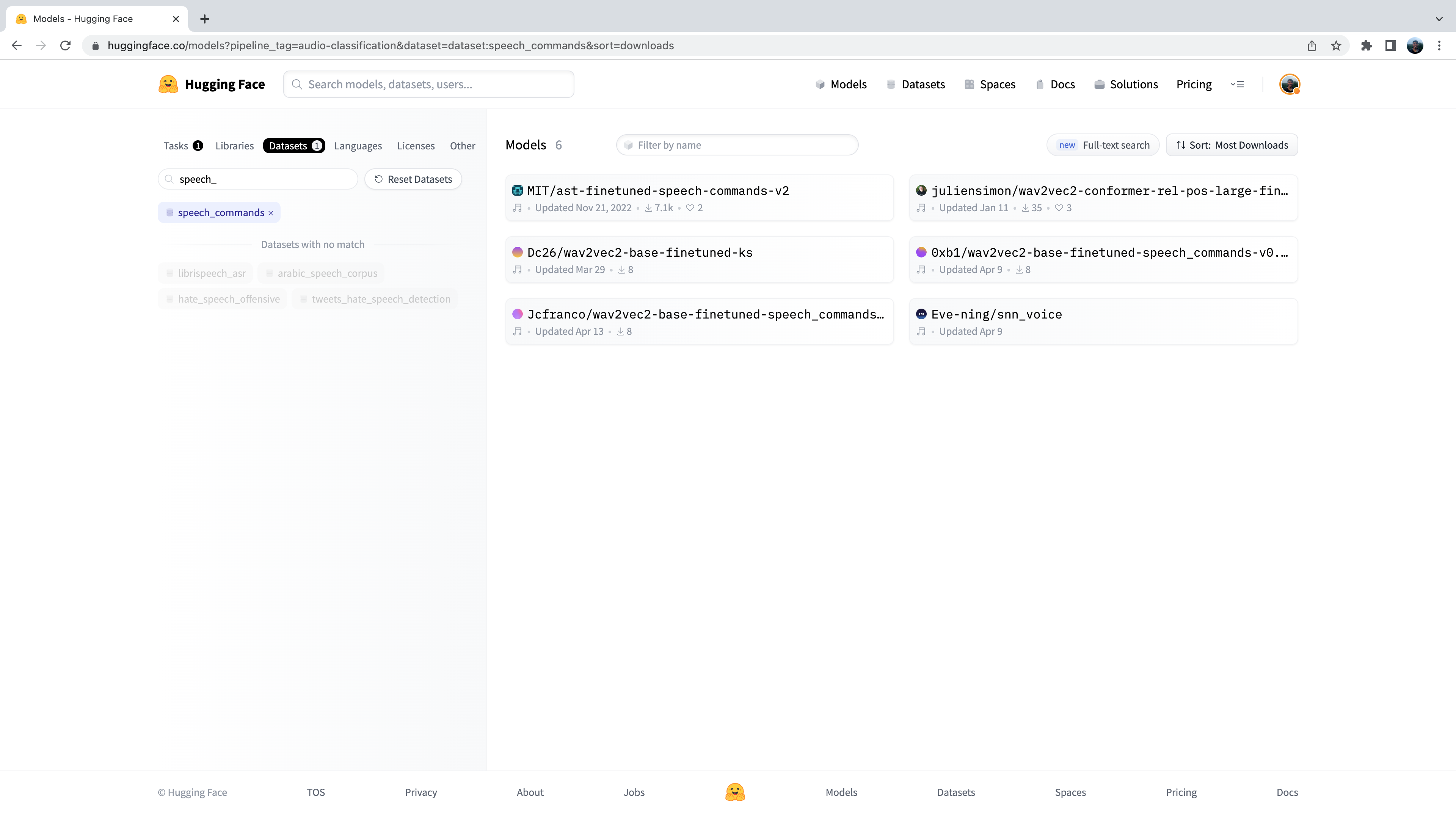
太棒了!我们发现我们有 6 个针对此特定数据集和任务可用的预训练模型。您会认出这些模型中的第一个模型是我们在前面示例中使用的Audio Spectrogram Transformer检查点。在 Hub 上筛选模型的这个过程正是我们选择检查点来展示给您的方法!
语言识别(Language Identification)
语言识别(LID)是从候选语言列表中识别音频样本中所说语言的任务。LID 可以在许多语音流水线中起到重要作用。例如,对于给定的未知语言音频样本,可以使用 LID 模型对音频样本中所说语言进行分类,然后选择一个针对该语言进行训练的适当的语音识别模型来转录音频。
FLEURS
FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)是用于评估 102 种语言中的语音识别系统的数据集,其中包括许多被归类为“低资源”的语言。查看一下 Hub 上的 FLEURS 数据集卡片,并探索其中存在的不同语言:google/fleurs。您能在这里找到您的母语吗?如果找不到,最接近的语言是哪种?
让我们使用流式模式从 FLEURS 数据集的验证集中加载一个样本:
fleurs = load_dataset("google/fleurs", "all", split="validation", streaming=True)
sample = next(iter(fleurs))
太好了!现在我们可以加载我们的音频分类模型。为此,我们将使用在 FLEURS 数据集上微调过的 Whisper 版本,目前是 Hub 上性能最好的 LID 模型:
classifier = pipeline(
"audio-classification", model="sanchit-gandhi/whisper-medium-fleurs-lang-id"
)
然后,我们可以将音频通过我们的分类器,并生成一个预测:
```python
classifier(sample["audio"])
输出:
[{'score': 0.9999330043792725, 'label': 'Afrikaans'},
{'score': 7.093023668858223e-06, 'label': 'Northern-Sotho'},
{'score': 4.269149485480739e-06, 'label': 'Icelandic'},
{'score': 3.2661141631251667e-06, 'label': 'Danish'},
{'score': 3.2580724109720904e-06, 'label': 'Cantonese Chinese'}]
我们可以看到,模型以极高的概率(接近 1)预测该音频为南非荷兰语。FLEURS 数据集包含来自多种语言的音频数据 - 我们可以看到可能的类别标签包括北索托语、冰岛语、丹麦语和粤语等。您可以在数据集卡片中找到完整的语言列表:google/fleurs。
轮到您了!您能在 Hub 上找到 FLEURS LID 的其他检查点吗?它们在底层使用的是哪些Transformer模型?
零样本音频分类(Zero-Shot Audio Classification)
在传统的音频分类范式中,模型从预定义的可能类别集中预测类别标签。这给使用预训练模型进行音频分类带来了障碍,因为预训练模型的标签集必须与下游任务的标签匹配。对于上述 LID 示例,模型必须预测它训练的 102 种语言类别之一。如果下游任务实际需要 110 种语言,则该模型将无法预测其中的 8 种语言,因此需要重新训练以实现完全覆盖。这限制了将迁移学习应用于音频分类任务的有效性。
零样本音频分类是一种方法,用于使用一组标记示例进行预训练的音频分类模型,并使其能够对以前未见过的类别进行分类。让我们看看我们如何实现这一点!
目前,🤗 Transformers 支持一种零样本音频分类模型:CLAP 模型。CLAP 是一种基于Transformer的模型,接受音频和文本作为输入,并计算两者之间的相似度。如果我们传递一个与音频输入强相关的文本输入,我们将获得一个较高的相似度分数。相反,传递一个与音频输入完全无关的文本输入将返回一个较低的相似度。
我们可以通过将一个音频输入和多个候选标签传递给模型来使用这种相似度预测进行零样本音频分类。模型将为我们定义的每个候选标签返回一个相似度分数,我们可以选择具有最高分数的标签作为我们的预测。
让我们以一个示例开始,我们将从环境音频挑战(ESC)数据集中使用一个音频输入:
dataset = load_dataset("ashraq/esc50", split="train", streaming=True)
audio_sample = next(iter(dataset))["audio"]["array"]
然后,我们定义我们的候选标签,这些标签形成了可能的分类标签集。模型将为我们定义的每个标签返回一个分类概率。这意味着我们需要事先知道我们分类问题中可能标签的集合,以便正确标签包含在集合中,并因此被分配一个有效的概率分数。请注意,我们可以将完整的标签集传递给模型,也可以传递我们认为包含正确标签的手动选择的子集。将完整的标签集传递给模型将更加详尽,但会以较低的分类准确性为代价,因为分类空间更大(前提是正确的标签是我们选择的标签子集):
candidate_labels = ["Sound of a dog", "Sound of vacuum cleaner"]
我们可以通过模型运行这两者来找到与音频输入最相似的候选标签:
classifier = pipeline(
task="zero-shot-audio-classification", model="laion/clap-htsat-unfused"
)
classifier(audio_sample, candidate_labels=candidate_labels)
输出:
[{'score': 0.9997242093086243, 'label': '狗的声音'}, {'score': 0.0002758323971647769, 'label': '吸尘器的声音'}]
太好了!模型似乎非常确信我们听到的是狗的声音 - 它以 99.96% 的概率进行了预测,因此我们将其作为我们的预测。让我们通过听音频样本来确认我们是否正确(不要把音量调得太高,否则可能会吓到!):
Audio(audio_sample, rate=16000)
完美!我们听到了狗叫声 🐕,这与模型的预测相符。尝试不同的音频样本和不同的候选标签 - 您能定义一组标签,使其在 ESC 数据集上具有良好的泛化性吗?提示:考虑一下您可以在 ESC 中找到有关可能声音的信息,并据此构建您的标签!
您可能想知道为什么我们不将零样本音频分类流水线用于所有音频分类任务?似乎我们可以通过事先定义适当的类别标签来为任何音频分类问题进行预测,从而绕过了我们的分类任务需要与模型预先训练的标签匹配的约束。这归结于零样本流水线中使用的 CLAP 模型的特性:CLAP 在通用音频分类数据上进行了预训练,类似于 ESC 数据集中的环境声音,而不是专门的语音数据,就像我们在 LID 任务中所用的那样。如果您给它一段英语和一段西班牙语的语音,CLAP 将知道这两个示例都是语音数据 🗣️,但它无法像专门的 LID 模型那样区分语言。
下一步是什么?
我们已经涵盖了许多不同的音频分类任务,并提供了您可以从 Hugging Face Hub 下载并仅使用几行代码就能使用 pipeline() 类中的最相关数据集和模型。这些任务包括关键词识别、语言识别和零样本音频分类。
但是如果我们想要做一些新的事情呢?我们在语音处理任务上做了大量工作,但这只是音频分类的一个方面。另一个流行的音频处理领域涉及音乐。虽然音乐具有与语音不同的内在特征,但我们已经学到的许多相同原理也可以应用于音乐。
在接下来的部分中,我们将逐步介绍如何使用 🤗 Transformers 在音乐分类任务上对Transformer模型进行微调。到最后,您将拥有一个微调的检查点,可以将其插入到 pipeline() 类中,使您能够以与我们在这里分类语音相同的方式对歌曲进行分类!
微调模型用于音乐分类
在本节中,我们将提供一个逐步指南,介绍如何对编码器-解码器Transformer模型进行音乐分类的微调。我们将使用一个轻量级模型进行演示,并使用相对较小的数据集,这意味着代码可以在任何消费级 GPU 上运行,包括 Google Colab 免费套餐提供的 T4 16GB GPU。本节包括各种提示,如果您使用较小的 GPU 并在过程中遇到内存问题,可以尝试这些提示。
数据集
为了训练我们的模型,我们将使用 GTZAN 数据集,这是一个包含 1,000 首歌曲的流行数据集,用于音乐流派分类。每首歌曲是来自 10 种音乐流派中的一种的 30 秒片段,涵盖了从迪斯科到金属的各种音乐类型。我们可以使用 🤗 Datasets 中的 load_dataset() 函数从 Hugging Face Hub 获取音频文件及其对应的标签:
from datasets import load_dataset
gtzan = load_dataset("marsyas/gtzan", "all")
gtzan
输出:
Dataset({
features: ['file', 'audio', 'genre'],
num_rows: 999
})
GTZAN 中的一个录音已损坏,因此已从数据集中移除。这就是为什么我们只有 999 个示例而不是 1,000 个。
GTZAN 没有提供预定义的验证集,因此我们必须自己创建一个。数据集在流派上是平衡的,因此我们可以使用 train_test_split() 方法快速创建 90/10 的划分,如下所示:
gtzan = gtzan["train"].train_test_split(seed=42, shuffle=True, test_size=0.1)
gtzan
输出:
DatasetDict({
train: Dataset({
features: ['file', 'audio', 'genre'],
num_rows: 899
})
test: Dataset({
features: ['file', 'audio', 'genre'],
num_rows: 100
})
})
好的,现在我们已经有了训练集和验证集,让我们来看看其中一个音频文件:
gtzan["train"][0]
输出:
{
"file": "~/.cache/huggingface/datasets/downloads/extracted/fa06ce46130d3467683100aca945d6deafb642315765a784456e1d81c94715a8/genres/pop/pop.00098.wav",
"audio": {
"path": "~/.cache/huggingface/datasets/downloads/extracted/fa06ce46130d3467683100aca945d6deafb642315765a784456e1d81c94715a8/genres/pop/pop.00098.wav",
"array": array(
[
0.10720825,
0.16122437,
0.28585815,
...,
-0.22924805,
-0.20629883,
-0.11334229,
],
dtype=float32,
),
"sampling_rate": 22050,
},
"genre": 7,
}
正如我们在第 1 单元中看到的那样,音频文件表示为一维 NumPy 数组,其中数组的值表示该时间步长的振幅。对于这些歌曲,采样率为 22,050 Hz,这意味着每秒采样 22,050 个振幅值。在使用具有不同采样率的预训练模型时,我们必须牢记这一点,自行转换采样率以确保其匹配。我们还可以看到流派表示为一个整数,或者类标签,这是模型进行预测的格式。让我们使用流派特征的 int2str() 方法将这些整数映射为可读的名称:
id2label_fn = gtzan["train"].features["genre"].int2str
id2label_fn(gtzan["train"][0]["genre"])
输出:
'pop'
这个标签看起来是正确的,因为它与音频文件的文件名匹配。现在让我们使用 Gradio 创建一个简单的界面,通过 Blocks API 来聆听更多示例:
import gradio as gr
def generate_audio():
example = gtzan["train"].shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label_fn(example["genre"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
从这些样本中,我们确实能听出不同流派之间的差异,但Transformer也能做到吗?让我们训练一个模型来找出答案!首先,我们需要找到一个适合这项任务的预训练模型。让我们看看我们可以如何做到这一点。
挑选预训练模型用于音频分类
首先,让我们选择一个适合的预训练模型用于音频分类。在这个领域,预训练通常是在大量未标记的音频数据上进行的,使用类似 LibriSpeech 和 Voxpopuli 的数据集。在 Hugging Face Hub 上找到这些模型的最佳方法是使用“音频分类”筛选器,就像在前一节中描述的那样。尽管像 Wav2Vec2 和 HuBERT 这样的模型非常受欢迎,但我们将使用一个名为 DistilHuBERT 的模型。这是 HuBERT 模型的一个更小(或蒸馏)版本,训练速度大约快了 73%,但保留了大部分性能。
数据预处理
类似于 NLP 中的标记化,音频和语音模型要求输入以模型可以处理的格式进行编码。在 🤗 Transformers 中,从音频到输入格式的转换由模型的特征提取器处理。与分词器类似,🤗 Transformers 提供了一个方便的 AutoFeatureExtractor 类,可以自动选择给定模型的正确特征提取器。为了看看我们如何处理音频文件,让我们从预训练检查点中实例化 DistilHuBERT 的特征提取器:
from transformers import AutoFeatureExtractor
model_id = "ntu-spml/distilhubert"
feature_extractor = AutoFeatureExtractor.from_pretrained(
model_id, do_normalize=True, return_attention_mask=True
)
由于模型的采样率和数据集不同,我们必须在将其传递给特征提取器之前将音频文件重新采样为 16,000 Hz。我们可以通过首先从特征提取器获取模型的采样率来实现这一点:
sampling_rate = feature_extractor.sampling_rate
sampling_rate
输出:
16000
接下来,我们使用 🤗 Datasets 中的 cast_column() 方法和 Audio 特征来重新采样数据集:
from datasets import Audio
gtzan = gtzan.cast_column("audio", Audio(sampling_rate=sampling_rate))
现在,我们可以检查数据集训练划分的第一个样本,以验证它确实是在 16,000 Hz。当我们加载每个音频样本时,🤗 Datasets 将实时重新采样音频文件:
gtzan["train"][0]
输出:
{
"file": "~/.cache/huggingface/datasets/downloads/extracted/fa06ce46130d3467683100aca945d6deafb642315765a784456e1d81c94715a8/genres/pop/pop.00098.wav",
"audio": {
"path": "~/.cache/huggingface/datasets/downloads/extracted/fa06ce46130d3467683100aca945d6deafb642315765a784456e1d81c94715a8/genres/pop/pop.00098.wav",
"array": array(
[
0.0873509,
0.20183384,
0.4790867,
...,
-0.18743178,
-0.23294401,
-0.13517427,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"genre": 7,
}
太好了!我们可以看到采样率已经降低到 16kHz。数组的值也不同了,因为我们现在每大约 1.5 个振幅值只有一个。
Wav2Vec2 和 HuBERT 等模型的一个显著特点是它们接受与语音信号的原始波形对应的浮点数组作为输入。这与其他模型相反,例如 Whisper,在这些模型中,我们将原始音频波形预处理为频谱图格式。
我们提到音频数据表示为一维数组,因此它已经以正确的格式准备好供模型读取(在离散时间步长上连续的一组输入)。那么,特征提取器究竟做了什么呢?
嗯,音频数据已经是正确的格式,但我们对它可以取的值没有施加任何限制。为了使我们的模型能够最优地工作,我们希望保持所有输入在相同的动态范围内。这将确保我们的样本获得类似的激活和梯度范围,有助于在训练过程中的稳定性和收敛性。
为了做到这一点,我们对我们的音频数据进行归一化,将每个样本重新缩放到零均值和单位方差,这个过程称为特征缩放。我们的特征提取器正是执行这种特征标准化!
我们可以通过将其应用于我们的第一个音频样本来观察特征提取器的运行情况。首先,让我们计算原始音频数据的均值和方差:
import numpy as np
sample = gtzan["train"][0]["audio"]
print(f"Mean: {np.mean(sample['array']):.3}, Variance: {np.var(sample['array']):.3}")
输出:
Mean: 0.000185, Variance: 0.0493
我们可以看到,平均值已经接近零了,但方差更接近0.05。如果样本的方差更大,可能会导致我们的模型出现问题,因为音频数据的动态范围会非常小,因此很难分离。让我们应用特征提取器,看看输出是什么样子的:
inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
print(f"inputs keys: {list(inputs.keys())}")
print(
f"Mean: {np.mean(inputs['input_values']):.3}, Variance: {np.var(inputs['input_values']):.3}"
)
输出:
inputs keys: ['input_values', 'attention_mask']
Mean: -4.53e-09, Variance: 1.0
好的!我们的特征提取器返回了一个包含两个数组的字典:input_values 和 attention_mask。input_values 是我们将传递给 HuBERT 模型的预处理音频输入。attention_mask 在同时处理一批音频输入时使用 - 它用于告诉模型我们在哪里填充了不同长度的输入。
我们可以看到,平均值现在非常接近零,方差完全是一!这正是我们希望在将其馈送到 HuBERT 模型之前将音频样本转换成的形式。
请注意,我们已将音频数据的采样率传递给了我们的特征提取器。这是一个好的做法,因为特征提取器在底层执行检查,以确保我们的音频数据的采样率与模型期望的采样率相匹配。如果我们的音频数据的采样率与模型的采样率不匹配,我们就需要将音频数据上采样或下采样到正确的采样率。
太好了,现在我们知道如何处理重采样的音频文件了,剩下的最后一件事是定义一个我们可以应用到数据集中所有示例的函数。由于我们预计音频片段的长度为 30 秒,我们还将使用特征提取器的 max_length 和 truncation 参数来截断任何更长的片段如下所示:
max_duration = 30.0
def preprocess_function(examples):
audio_arrays = [x["array"] for x in examples["audio"]]
inputs = feature_extractor(
audio_arrays,
sampling_rate=feature_extractor.sampling_rate,
max_length=int(feature_extractor.sampling_rate * max_duration),
truncation=True,
return_attention_mask=True,
)
return inputs
定义了这个函数之后,我们现在可以使用 map() 方法将其应用到数据集上。.map() 方法支持处理一批示例,我们将通过设置 batched=True 来启用它。默认批大小是 1000,但我们将其减小到 100,以确保 Google Colab 的免费服务的峰值 RAM 保持在合理范围内:
gtzan_encoded = gtzan.map(
preprocess_function,
remove_columns=["audio", "file"],
batched=True,
batch_size=100,
num_proc=1,
)
gtzan_encoded
输出:
DatasetDict({
train: Dataset({
features: ['genre', 'input_values','attention_mask'],
num_rows: 899
})
test: Dataset({
features: ['genre', 'input_values','attention_mask'],
num_rows: 100
})
})
如果执行上述代码时耗尽了设备的 RAM,您可以调整批处理参数以减少峰值 RAM 使用量。特别是,可以修改以下两个参数:* batch_size:默认值为 1000,但上面设置为 100。再次尝试将其减小一半至 50 * writer_batch_size:默认值为 1000。尝试将其减小为 500,如果不起作用,则再次将其减小一半至 250
为了简化训练,我们已经从数据集中移除了音频和文件列。input_values 列包含编码音频文件,attention_mask 是一个包含 0/1 值的二进制掩码,指示我们在哪里填充了音频输入,genre 列包含相应的标签(或目标)。为了使 Trainer 能够处理类别标签,我们需要将 genre 列重命名为 label:
gtzan_encoded = gtzan_encoded.rename_column("genre", "label")
最后,我们需要从数据集中获取标签映射。这个映射将把我们从整数 id(例如 7)转换为可读的类别标签(例如 “pop”),然后再次转换回来。通过这样做,我们可以将模型的整数 id 预测转换为可读的格式,从而使我们能够在任何下游应用中使用模型。我们可以通过使用 int2str() 方法来实现:
id2label = {
str(i): id2label_fn(i)
for i in range(len(gtzan_encoded["train"].features["label"].names))
}
label2id = {v: k for k, v in id2label.items()}
id2label["7"]
输出:
'pop'
好的,现在我们有了一个准备好进行训练的数据集!让我们看看如何在这个数据集上训练模型。
对模型进行微调
为了对模型进行微调,我们将使用 🤗 Transformers 中的 Trainer 类。正如我们在其他章节中看到的那样,Trainer 是一个高级 API,旨在处理最常见的训练场景。在这种情况下,我们将使用 Trainer 对 GTZAN 上的模型进行微调。为此,我们首先需要加载用于此任务的模型。我们可以使用 AutoModelForAudioClassification 类来完成此操作,该类将自动添加适当的分类头到我们预训练的 DistilHuBERT 模型中。让我们继续实例化模型:
from transformers import AutoModelForAudioClassification
num_labels = len(id2label)
model = AutoModelForAudioClassification.from_pretrained(
model_id,
num_labels=num_labels,
label2id=label2id,
id2label=id2label,
)
我们强烈建议您在训练期间直接将模型检查点上传到 Hugging Face Hub。Hub 提供了:
- 集成版本控制:您可以确保在训练过程中不会丢失任何模型检查点。
- Tensorboard 日志:跟踪训练过程中的重要指标。
- 模型卡片:记录模型的功能及其预期用途。
- 社区:与社区分享和合作的简单方式!🤗
将笔记本链接到 Hub 很简单 - 只需要在提示时输入您的 Hub 认证令牌。在此处找到您的 Hub 认证令牌:
from huggingface_hub import notebook_login
notebook_login()
输出:
Login successful
Your token has been saved to /root/.huggingface/token
下一步是定义训练参数,包括批大小、梯度累积步数、训练周期数和学习率:
from transformers import TrainingArguments
model_name = model_id.split("/")[-1]
batch_size = 8
gradient_accumulation_steps = 1
num_train_epochs = 10
training_args = TrainingArguments(
f"{model_name}-finetuned-gtzan",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=5e-5,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_train_epochs,
warmup_ratio=0.1,
logging_steps=5,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
fp16=True,
push_to_hub=True,
)
在这里,我们将 push_to_hub=True 设置为 True,以便在训练期间自动上传我们微调的检查点。如果您不希望将检查点上传到 Hub,则可以将其设置为 False。
我们需要做的最后一件事是定义指标。由于数据集是平衡的,我们将使用准确度作为我们的指标,并使用 🤗 Evaluate 库进行加载:
import evaluate
import numpy as np
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""Computes accuracy on a batch of predictions"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
现在我们已经准备好了所有的组件!让我们实例化 Trainer 并训练模型:
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=gtzan_encoded["train"],
eval_dataset=gtzan_encoded["test"],
tokenizer=feature_extractor,
compute_metrics=compute_metrics,
)
trainer.train()
根据您的 GPU,当您开始训练时,可能会遇到 CUDA “内存不足”错误。在这种情况下,您可以将批量大小逐渐减小为 2 的倍数,并使用 gradient_accumulation_steps 来补偿。
输出:
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7297 | 1.0 | 113 | 1.8011 | 0.44 |
| 1.24 | 2.0 | 226 | 1.3045 | 0.64 |
| 0.9805 | 3.0 | 339 | 0.9888 | 0.7 |
| 0.6853 | 4.0 | 452 | 0.7508 | 0.79 |
| 0.4502 | 5.0 | 565 | 0.6224 | 0.81 |
| 0.3015 | 6.0 | 678 | 0.5411 | 0.83 |
| 0.2244 | 7.0 | 791 | 0.6293 | 0.78 |
| 0.3108 | 8.0 | 904 | 0.5857 | 0.81 |
| 0.1644 | 9.0 | 1017 | 0.5355 | 0.83 |
| 0.1198 | 10.0 | 1130 | 0.5716 | 0.82 |
根据您的 GPU 或分配给 Google Colab 的 GPU,训练大约需要 1 小时。我们的最佳评估准确度为 83% - 对于仅使用 899 个训练数据示例的 10 个周期来说,这还不错!我们肯定可以通过训练更多周期,使用正则化技术(如丢失)或将每个音频示例从 30 秒划分为 15 秒片段来改进这一结果的。
重要的问题是这与其他音乐分类系统相比如何 🤔 为此,我们可以查看自动评估排行榜,这是一个根据语言和数据集对模型进行分类,并根据其准确度对其进行排名的排行榜。
当我们将训练结果推送到 Hub 时,我们可以自动将我们的检查点提交到排行榜 - 我们只需设置适当的关键字参数(kwargs)。您可以更改这些值以匹配您的数据集、语言和模型名称:
kwargs = {
"dataset_tags": "marsyas/gtzan",
"dataset": "GTZAN",
"model_name": f"{model_name}-finetuned-gtzan",
"finetuned_from": model_id,
"tasks": "audio-classification",
}
现在,训练结果可以上传到 Hub。要执行此操作,请执行 .push_to_hub 命令:
trainer.push_to_hub(**kwargs)
这将在“your-username/distilhubert-finetuned-gtzan”下保存训练日志和模型权重。对于此示例,请查看在“sanchit-gandhi/distilhubert-finetuned-gtzan”处的上传。
分享模型
您现在可以使用 Hub 上的链接与任何人分享此模型。他们可以直接将其加载到 pipeline() 类中,使用标识符“your-username/distilhubert-finetuned-gtzan”加载微调的检查点。例如,要加载微调的检查点“sanchit-gandhi/distilhubert-finetuned-gtzan”:
from transformers import pipeline
pipe = pipeline(
"audio-classification", model="sanchit-gandhi/distilhubert-finetuned-gtzan"
)
结论
在本节中,我们详细介绍了对 DistilHuBERT 模型进行音乐分类微调的逐步指南。虽然我们关注的是音乐分类任务和 GTZAN 数据集,但这里呈现的步骤更普遍地适用于任何音频分类任务 - 同一脚本可用于语音语言音频分类任务,如关键词检测或语言识别。您只需将数据集替换为与您感兴趣的任务相对应的数据集即可!如果您有兴趣对其他 Hugging Face Hub 模型进行音频分类的微调,我们鼓励您查看 🤗 Transformers 存储库中的其他示例。
在下一节中,我们将使用您刚刚微调的模型构建一个音乐分类演示,您可以在 Hugging Face Hub 上分享。
使用Gradio构建演示
在音频分类的最后一节中,我们将构建一个Gradio演示,展示我们刚刚在GTZAN数据集上训练的音乐分类模型。首先要做的是使用pipeline()类加载微调的检查点 - 这在预训练模型部分非常熟悉。您可以将model_id更改为您在Hugging Face Hub上微调的模型的命名空间:
from transformers import pipeline
model_id = "sanchit-gandhi/distilhubert-finetuned-gtzan"
pipe = pipeline("audio-classification", model=model_id)
其次,我们将定义一个函数,该函数接受音频输入的文件路径,并通过管道传递它。在这里,管道会自动负责加载音频文件,将其重采样为正确的采样率,并使用模型进行推断。我们获取模型的预测值preds,并将它们格式化为一个字典对象以在输出上显示:
def classify_audio(filepath):
preds = pipe(filepath)
outputs = {}
for p in preds:
outputs[p["label"]] = p["score"]
return outputs
最后,我们使用我们刚刚定义的函数启动Gradio演示:
import gradio as gr
demo = gr.Interface(
fn=classify_audio, inputs=gr.Audio(type="filepath"), outputs=gr.outputs.Label()
)
demo.launch(debug=True)
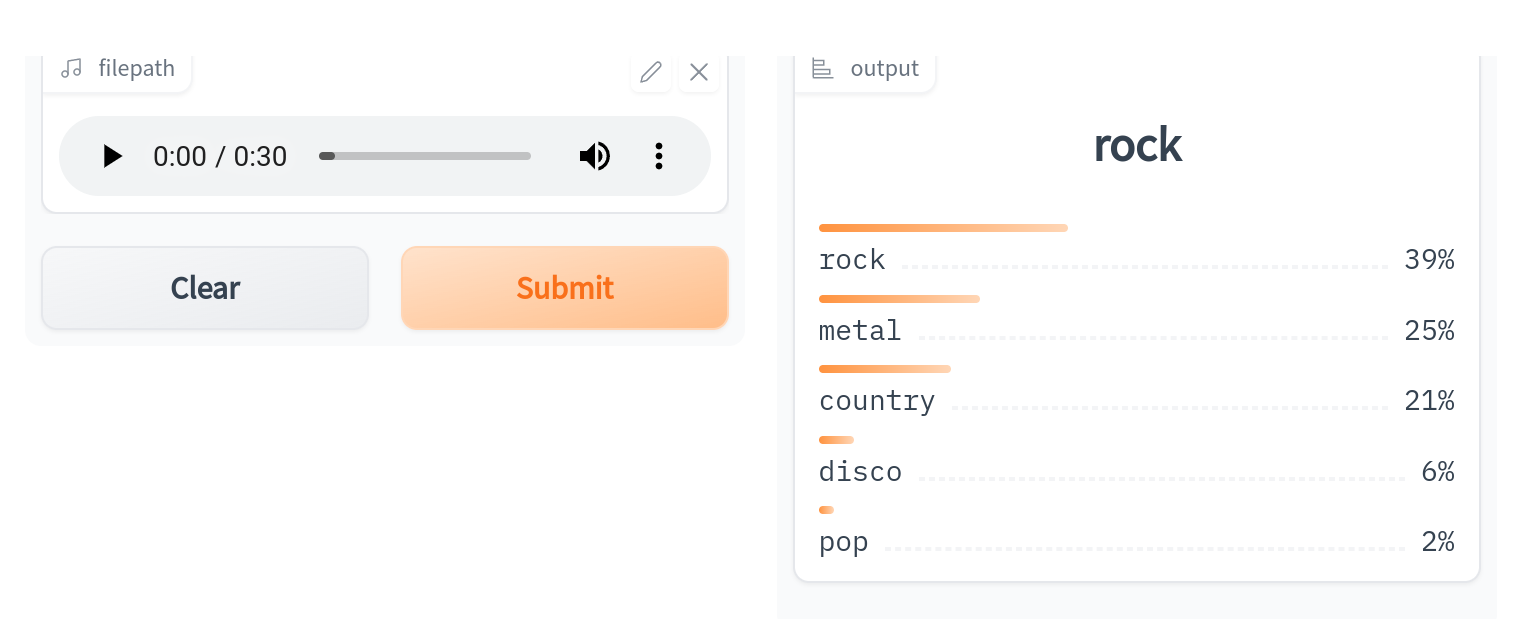
这将启动一个类似于在Hugging Face Space上运行的Gradio演示:
- 显示Disqus评论(需要科学上网)