恭喜你进入第7单元🥳 你离完成课程并获取在音频机器学习领域所需的最后几项技能只有几步之遥了。在理解方面,你已经掌握了所有必要的知识!我们一起全面涵盖了构成音频领域的主要主题及其相关理论(音频数据、音频分类、语音识别和文本转语音)。这个单元的目标是提供一个将这些知识整合起来的框架:现在你知道了每个任务在孤立状态下是如何工作的,我们将探讨如何将它们组合起来构建一些真实世界的应用程序。
本单元学习内容
在这个单元中,我们将涵盖以下三个主题:
- 语音到语音翻译:将一种语言的语音翻译成另一种语言的语音
- 创建语音助手:构建一个类似于Alexa或Siri的自己的语音助手
- 会议记录转写:转录一场会议并用谁在何时说过的标签对转录进行标注
语音到语音翻译
语音到语音翻译(STST或S2ST)是一个相对较新的口语语言处理任务。它涉及将一种语言的语音翻译成另一种语言的语音:
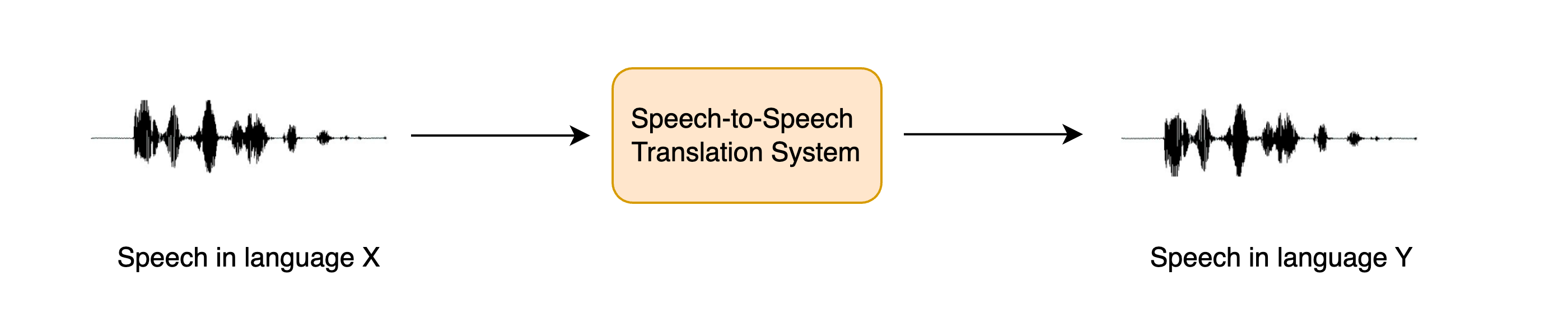
STST可以被视为传统机器翻译(MT)任务的扩展:我们不是将文本从一种语言翻译成另一种语言,而是将语音从一种语言翻译成另一种语言。STST在多语言交流领域具有应用,使不同语言的讲者可以通过语音进行交流。
假设你想要跨越语言障碍与另一个人进行交流。与其将你想传达的信息写下来然后将其翻译成目标语言的文本,不如直接说出来,让一个STST系统将你的口语转换成目标语言。接收者可以通过与STST系统进行口头交流来回应,而你可以听取他们的回答。与基于文本的机器翻译相比,这是一种更自然的交流方式。
在本章中,我们将探讨一种级联方法来进行STST,将你在课程第5和第6单元中所学的知识组合起来。我们将使用语音翻译(ST)系统将源语音转录为目标语言中的文本,然后使用文本到语音(TTS)来从翻译后的文本生成目标语言的语音:

我们也可以采用三阶段方法,首先使用自动语音识别(ASR)系统将源语音转录为相同语言的文本,然后进行机器翻译将转录的文本翻译为目标语言,最后进行文本到语音,生成目标语言的语音。然而,向管道添加更多组件会导致错误传播,即在一个系统中引入的错误会随着它们流经其余系统而不断增加,也会增加延迟,因为需要为更多模型进行推断。
虽然这种级联方法对STST相当直观,但它会产生非常有效的STST系统。ASR + MT + TTS的三阶段级联系统以前被用于驱动许多商业STST产品,包括Google翻译。这也是一种非常数据和计算高效的开发STST系统的方式,因为现有的语音识别和文本到语音系统可以组合在一起,无需任何额外的训练即可产生新的STST模型。
在本单元的其余部分,我们将专注于创建一个STST系统,将任何语言X的语音翻译成英语的语音。所涵盖的方法可以扩展到将任何语言X的语音翻译成任何语言Y的STST系统,但我们将这留给读者自行扩展,并提供适用的指引。我们进一步将STST任务分解为其两个组成部分:ST和TTS。最后,我们将它们组合在一起,构建一个Gradio演示来展示我们的系统。
语音翻译
我们将使用Whisper模型作为我们的语音翻译系统,因为它能够将超过96种语言翻译成英语。具体来说,我们将加载Whisper Base检查点,它拥有7400万个参数。虽然这并不是最高性能的Whisper模型,最大的Whisper检查点超过它的20倍,但由于我们正在将两个自回归系统连接在一起(ST + TTS),我们希望每个模型都能够相对快速地生成,以便获得合理的推断速度:
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
太棒了!为了测试我们的STST系统,我们将加载一个非英语语言的音频样本。让我们加载VoxPopuli数据集的意大利语(it)分割的第一个示例:
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
sample = next(iter(dataset))
要收听此样本,我们可以使用Hub上的数据集查看器播放它:facebook/voxpopuli/viewer或使用ipynb音频功能进行播放:
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
现在让我们定义一个函数,该函数接受此音频输入并返回翻译文本。您会记得,我们必须传递生成关键字参数来设置“任务”,将其设置为“translate”以确保Whisper执行语音翻译而不是语音识别:
def translate(audio):
outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
return outputs["text"]
Whisper也可以被“欺骗”来将来自任何语言X的语音翻译成任何语言Y。只需将任务设置为“transcribe”,并在生成关键字参数中将“language”设置为目标语言,例如,对于西班牙语,可以设置为:
generate_kwargs={"task": "transcribe", "language": "es"}
太好了!让我们快速检查一下我们从模型得到的合理结果:
translate(sample["audio"].copy())
' psychological and social. I think that it is a very important step in the construction of a juridical space of freedom, circulation and protection of rights.'
好了!如果我们将其与源文本进行比较:
sample["raw_text"]
'Penso che questo sia un passo in avanti importante nella costruzione di uno spazio giuridico di libertà di circolazione e di protezione dei diritti per le persone in Europa.'
我们可以看到翻译基本上吻合(您可以使用Google翻译再次确认),除了转录的开头多出了一些词,这是说话者正在结束他们之前的句子。
通过这样做,我们完成了级联STST管道的前半部分,将我们在第5单元学习如何使用Whisper模型进行语音识别和翻译时获得的技能付诸实践。如果您想要重新学习我们涵盖的任何步骤,请阅读第5单元关于ASR的预训练模型部分。
文本到语音
我们级联STST系统的第二部分涉及从英文文本到英文语音的映射。为此,我们将使用预训练的SpeechT5 TTS模型进行英文TTS。🤗 Transformers目前没有TTS管道,所以我们必须直接使用模型。这没什么大不了的,你们都是在第6单元中使用模型进行推理的专家!
首先,让我们从预训练的检查点中加载SpeechT5处理器、模型和声码器:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
这里我们使用专门用于英文TTS的SpeechT5检查点。如果您希望翻译成除英语以外的其他语言,请将检查点更换为在您选择的语言上进行微调的SpeechT5 TTS模型,或者使用在目标语言上预训练的MMS TTS检查点。 与Whisper模型一样,如果有GPU加速器设备,我们将把SpeechT5模型和声码器放在上面:
model.to(device)
vocoder.to(device)
太好了!让我们加载说话者嵌入:
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
现在我们可以编写一个函数,该函数将文本提示作为输入,并生成相应的语音。我们首先使用SpeechT5处理器预处理文本输入,对文本进行标记化以获取输入id。然后,我们将输入id和说话者嵌入传递给SpeechT5模型,如果有的话,将每个放在加速器设备上。最后,我们将生成的语音返回,将其带回CPU,以便我们可以在ipynb笔记本中播放它:
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
让我们用一个虚拟文本输入来检查它是否有效:
speech = synthesise("Hey there! This is a test!")
Audio(speech, rate=16000)
听起来不错!现在是令人兴奋的部分 - 将所有内容组合在一起。
创建一个STST演示
在我们创建一个Gradio演示来展示我们的STST系统之前,让我们先进行一个快速的健全性检查,确保我们可以连接这两个模型,输入一个音频样本并得到一个音频样本输出。我们将通过连接我们在前面两个子部分中定义的两个函数来完成这个任务,这样我们就可以输入源音频并检索翻译后的文本,然后合成翻译后的文本以获得翻译后的语音。最后,我们将合成的语音转换为int16数组,这是Gradio期望的输出音频文件格式。为此,我们首先必须将音频数组归一化为目标dtype(int16)的动态范围,然后从默认的NumPy dtype(float64)转换为目标dtype(int16):
import numpy as np
target_dtype = np.int16
max_range = np.iinfo(target_dtype).max
def speech_to_speech_translation(audio):
translated_text = translate(audio)
synthesised_speech = synthesise(translated_text)
synthesised_speech = (synthesised_speech.numpy() * max_range).astype(np.int16)
return 16000, synthesised_speech
让我们检查这个连接函数是否给出了预期的结果:
sampling_rate, synthesised_speech = speech_to_speech_translation(sample["audio"])
Audio(synthesised_speech, rate=sampling_rate)
完美!现在我们将把这个整合成一个漂亮的Gradio演示,这样我们就可以使用麦克风输入或文件输入录制我们的源语音,并播放系统的预测:
import gradio as gr
demo = gr.Blocks()
mic_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
file_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
with demo:
gr.TabbedInterface([mic_translate, file_translate], ["Microphone", "Audio File"])
demo.launch(debug=True)
这将启动一个类似于运行在Hugging Face Space上的Gradio演示。
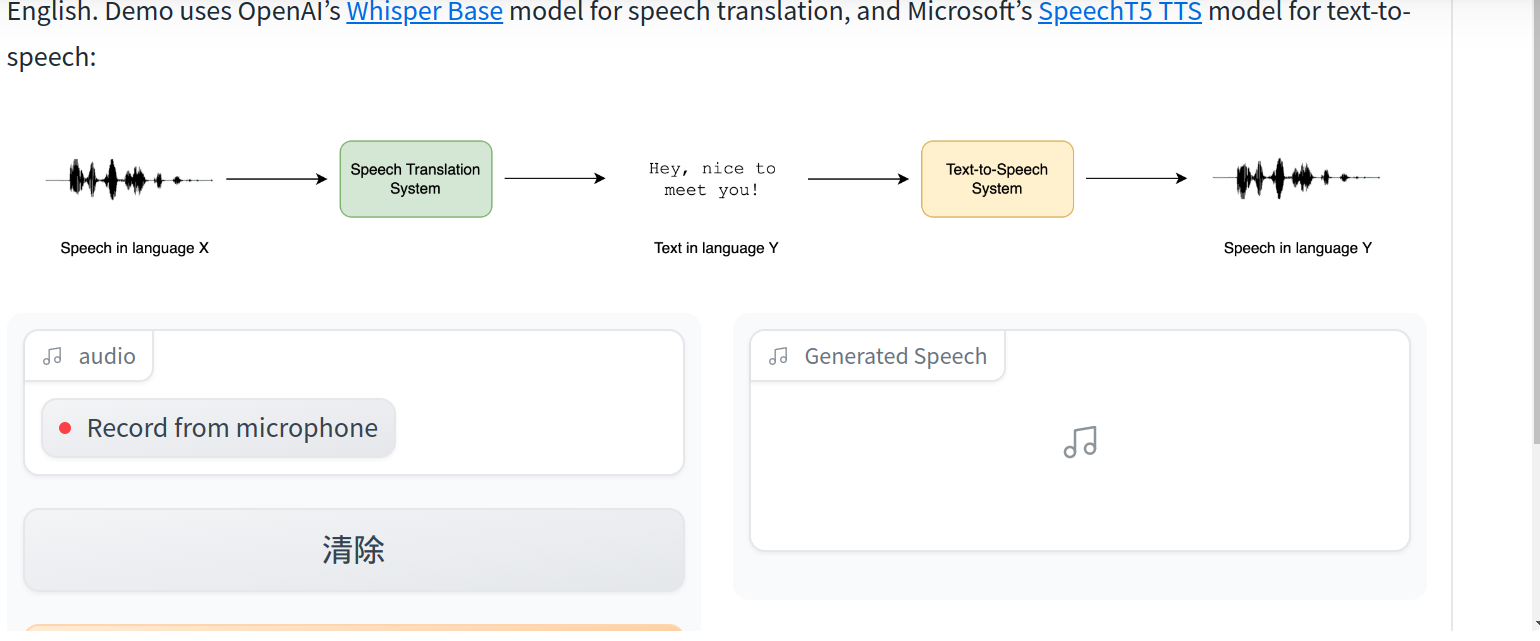
您可以复制此演示并调整它以使用不同的Whisper检查点、不同的TTS检查点,或放宽输出英语语音的约束,并按照提供的提示将其翻译成您选择的语言!
展望未来
虽然级联系统是构建STST系统的一种计算和数据高效的方式,但它受到了上述错误传播和累积延迟的问题的影响。最近的研究探索了一种直接的STST方法,该方法不预测中间文本输出,而是直接将源语音映射到目标语音。这些系统还能够在目标语音中保留源说话者的说话特征(如韵律、音高和语调)。如果您对了解这些系统感兴趣,请查阅附加阅读部分列出的资源。
创建语音助手
在本节中,我们将组合三个我们已经亲身体验过的模型,构建一个名为Marvin的端到端语音助手🤖。像亚马逊的Alexa或苹果的Siri一样,Marvin是一个虚拟语音助手,它会响应特定的“唤醒词”,然后监听口头查询,并最终以口头回答做出响应。
我们可以将语音助手管线分解为四个阶段,每个阶段都需要一个独立的模型:

唤醒词(Wake word)检测
语音助手不断地监听通过您设备麦克风传入的音频输入,但只有在说出特定的“唤醒词”时才会启动。
唤醒词检测任务由一个小型的设备端音频分类模型处理,该模型比语音识别模型小得多、轻得多,通常只有数百万个参数,而不是语音识别的数亿级别。因此,它可以在您的设备上连续运行,而不会耗尽您的电池。只有在检测到唤醒词时,才会启动较大的语音识别模型,然后再次关闭它。
语音转录
管线中的下一个阶段是将口头查询转录为文本。实际上,由于音频文件的体积较大,将音频文件从本地设备传输到云端速度较慢,因此直接在设备上使用自动语音识别(ASR)模型转录它们比使用云端模型更有效率。设备端模型可能比云端托管的模型更小,因此准确性可能较低,但更快的推理速度是值得的,因为我们可以几乎实时地运行语音识别,我们说话时的口头语音被转录为我们说出的话语。 我们现在非常熟悉语音识别过程,所以这应该很容易!
语言模型查询
现在我们知道用户问了什么,我们需要生成一个回答!这项任务的最佳候选模型是大型语言模型(LLM),因为它们能够有效地理解文本查询的语义并生成适当的回答。
由于我们的文本查询很小(只是几个文本标记),而语言模型很大(有数十亿个参数),最有效的运行LLM推理的方法是将我们的文本查询从我们的设备发送到在云端运行的LLM,生成一个文本回答,并将回答返回到设备。
合成语音
最后,我们将使用文本转语音(TTS)模型将文本响应合成为口头语音。这是在设备上完成的,但您也可以在云端运行TTS模型,生成音频输出并将其传输回设备。
同样,我们现在已经做过几次了,所以这个过程会非常熟悉!
以下部分需要使用麦克风录制语音输入。由于Google Colab机器不具备麦克风兼容性,建议在本地运行此部分,无论是在您的CPU上还是在您有本地访问权限的GPU上。所选的检查点大小足够小,在CPU上运行时仍然可以获得良好的性能,因此即使没有GPU,您仍然会获得良好的性能。
唤醒词检测
语音助手管线中的第一个阶段是检测是否说出了唤醒词,我们需要找到一个适合这个任务的预训练模型!您会记得,从音频分类的预训练模型部分,Speech Commands是一个包含15个以上简单命令词的口头单词数据集,旨在评估音频分类模型,如“up”、“down”、“yes”和“no”,以及一个“silence”标签来分类无语音。花一分钟时间在Hub上的数据集查看器上听一下样本,并重新熟悉Speech Commands数据集:
我们可以使用在Speech Commands数据集上预训练的音频分类模型,并选择其中一个简单命令词作为我们选择的唤醒词。在15个以上可能的命令词中,如果模型以最高概率预测我们选择的唤醒词,我们就可以相当肯定地说唤醒词已经被说出来了。
让我们前往Hugging Face Hub,并单击“Models”选项卡:https://huggingface.co/models
这将显示Hub上的所有模型,按过去30天的下载量排序:
您会注意到在左侧有一些选项卡,我们可以选择这些选项卡来按任务、库、数据集等筛选模型。向下滚动并从音频任务列表中选择“音频分类”任务:
现在我们看到了在Hub上的500多个音频分类模型的子集。为了进一步细化选择,我们可以按数据集过滤模型。点击“数据集”选项卡,并在搜索框中输入“speech_commands”。当您开始输入时,您会看到speech_commands的选择出现在搜索选项卡下方。您可以点击此按钮,将所有音频分类模型过滤为在Speech Commands数据集上微调的模型:
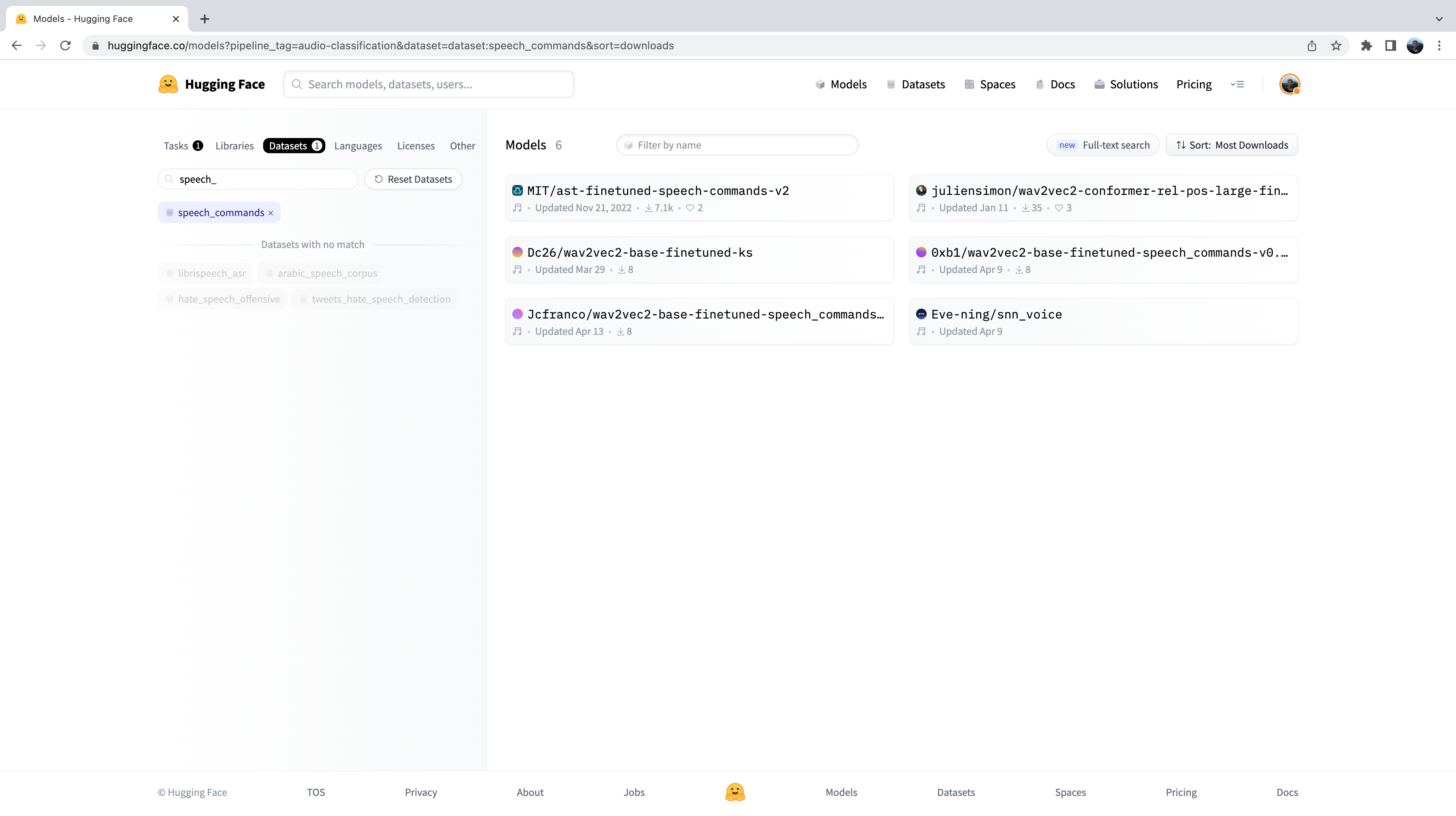
太好了!我们看到我们有六个可用于此特定数据集和任务的预训练模型(尽管如果您在以后阅读可能会有新模型添加!)。您会认识到这些模型中的第一个是我们在Unit 4示例中使用的Audio Spectrogram Transformer检查点。我们将再次将此检查点用于我们的唤醒词检测任务。
让我们继续使用pipeline类加载检查点:
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)
我们可以通过检查模型配置中的id2label属性来查看模型训练的标签:
classifier.model.config.id2label
好的!我们看到模型在35个类标签上进行了训练,包括我们上面描述的一些简单命令词,以及一些特定的对象,如“床”、“房子”和“猫”。我们看到这些类标签中有一个名称:id 27 对应于标签“marvin”:
classifier.model.config.id2label[27]
'marvin'
完美!我们可以将此名称用作我们语音助手的唤醒词,类似于“Alexa”用于亚马逊的Alexa,或“Hey Siri”用于苹果的Siri。在所有可能的标签中,如果模型以最高的类概率预测“marvin”,我们可以相当确信我们选择的唤醒词已经被说出。
现在我们需要定义一个函数,该函数不断监听我们设备的麦克风输入,并持续将音频传递给分类模型进行推理。为此,我们将使用一个非常方便的带有🤗 Transformers的辅助函数,称为ffmpeg_microphone_live。
该函数将指定长度chunk_length_s的小块音频转发给模型进行分类。为了确保我们在音频块之间获得平滑的边界,我们使用步幅chunk_length_s / 6在我们的音频上运行一个滑动窗口。为了在开始推断之前不必等待整个第一个音频块被记录下来,我们还定义了一个最小的临时音频输入长度stream_chunk_s,在达到chunk_length_s时间之前将其转发到模型。
函数ffmpeg_microphone_live返回一个生成器对象,产生一个音频块序列,每个音频块可以传递给分类模型进行预测。我们可以直接将这个生成器传递给管道,管道反过来返回一个输出预测序列,每个音频输入块一个预测。我们可以检查每个音频块的类标签概率,并在检测到唤醒词已被说出时停止我们的唤醒词检测循环。
我们将使用非常简单的标准来分类我们的唤醒词是否被说出:如果具有最高概率的类标签是我们的唤醒词,并且此概率超过一个阈值prob_threshold,我们宣布唤醒词已被说出。通过使用概率阈值以这种方式对我们的分类器进行门控,可以确保在音频输入是噪音时不会错误地预测唤醒词,这通常是模型非常不确定且所有类标签的概率都很低的情况下。您可能想调整此概率阈值,或通过基于熵(或不确定性)的度量探索更复杂的唤醒词决策方式。
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return True
让我们试试这个函数,看看它的工作原理!我们将设置标志debug=True以打印出每个音频块的预测结果。让模型运行几秒钟,看看在没有语音输入时它会做出什么样的预测,然后清晰地说出唤醒词“marvin”,观察“marvin”的类标签预测会接近1:
launch_fn(debug=True)
Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}
太棒了!正如我们预期的那样,模型在最初几秒钟生成了垃圾预测。没有语音输入,所以模型做出接近随机的预测,但概率非常低。一旦说出唤醒词,模型以接近1的概率预测“marvin”,并终止循环,表示已检测到唤醒词,并且应激活ASR系统!
语音转录
我们将再次使用Whisper模型作为我们的语音转录系统。具体来说,我们将加载Whisper基础英语检查点,因为它足够小,可以在合理的转录准确性下提供良好的推理速度。我们将使用一个技巧,通过巧妙地将我们的音频输入转发给模型来实现接近实时的转录。与以前一样,可以随意使用Hub上的任何语音识别检查点,包括Wav2Vec2、MMS ASR或其他Whisper检查点:
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)
如果您使用的是GPU,可以增加检查点大小以使用Whisper小型英语检查点,这将提供更好的转录准确性,并且仍将在所需的延迟阈值内。只需将模型id更改为:”openai/whisper-small.en”。
现在我们可以定义一个函数来记录我们的麦克风输入并转录相应的文本。借助ffmpeg_microphone_live辅助函数,我们可以控制我们的语音识别模型的“实时性”。使用较小的stream_chunk_s更适合实时语音识别,因为我们将输入音频划分为较小的块,并即时转录它们。然而,这会以较低的准确性为代价,因为模型可以推断的上下文更少。
当我们转录语音时,我们还需要知道用户何时停止说话,以便我们可以终止录音。为简单起见,我们将在第一个chunk_length_s(默认设置为5秒)之后终止麦克风录音,但您可以尝试使用语音活动检测(VAD)模型来预测用户何时停止说话。
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]
让我们试一试,看看效果如何!一旦麦克风开始工作,开始说话,然后观察您的转录几乎实时地出现:
transcribe()
Start speaking...
Hey, this is a test with the whisper model.
很好!您可以根据自己说话的速度调整最大音频长度chunk_length_s(如果您感觉没有足够的时间说话,请增加它;如果您在最后等待了一段时间,请减少它),以及实时因子stream_chunk_s。只需将这些作为参数传递给transcribe函数。
语言模型查询
现在我们已经将口头查询转录成文本,我们希望生成一个有意义的回答。为此,我们将使用托管在云端的LLM。具体来说,我们将在Hugging Face Hub上挑选一个LLM,并使用推理API轻松查询模型。
首先,让我们前往Hugging Face Hub。为了找到我们的LLM,我们将使用🤗 Open LLM Leaderboard,这是一个根据四个生成任务的性能对LLM模型进行排名的Space。我们将搜索“instruct”来过滤出已经进行指令微调的模型,因为这些模型应该更适合我们的查询任务:
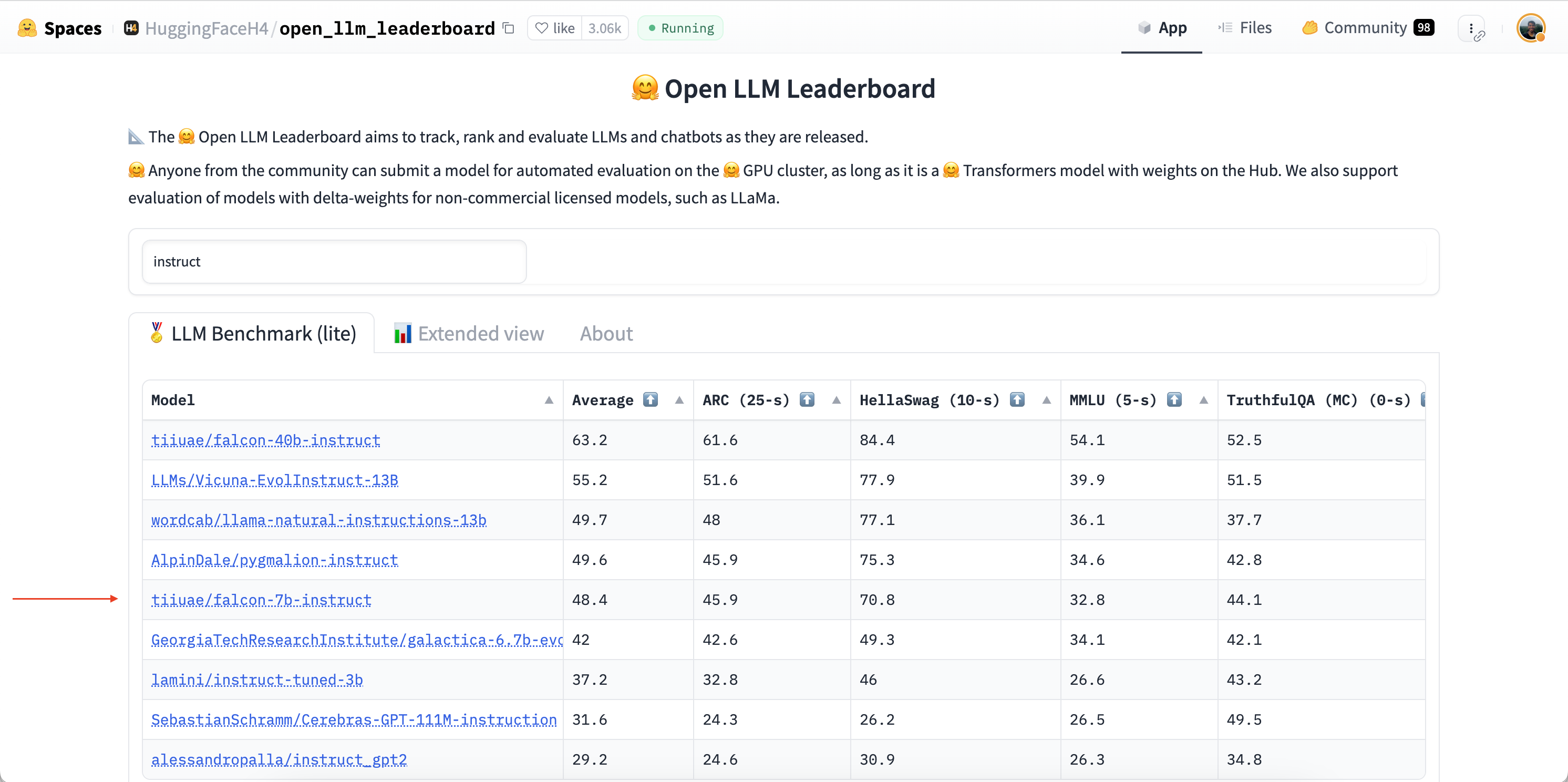
我们将使用TII团队的tiiuae/falcon-7b-instruct检查点,这是一个7B参数的仅解码器LLM,经过混合聊天和指令数据集的微调。您可以使用Hugging Face Hub上任何启用了“托管推理API”的LLM,只需注意模型卡片右侧的小部件:
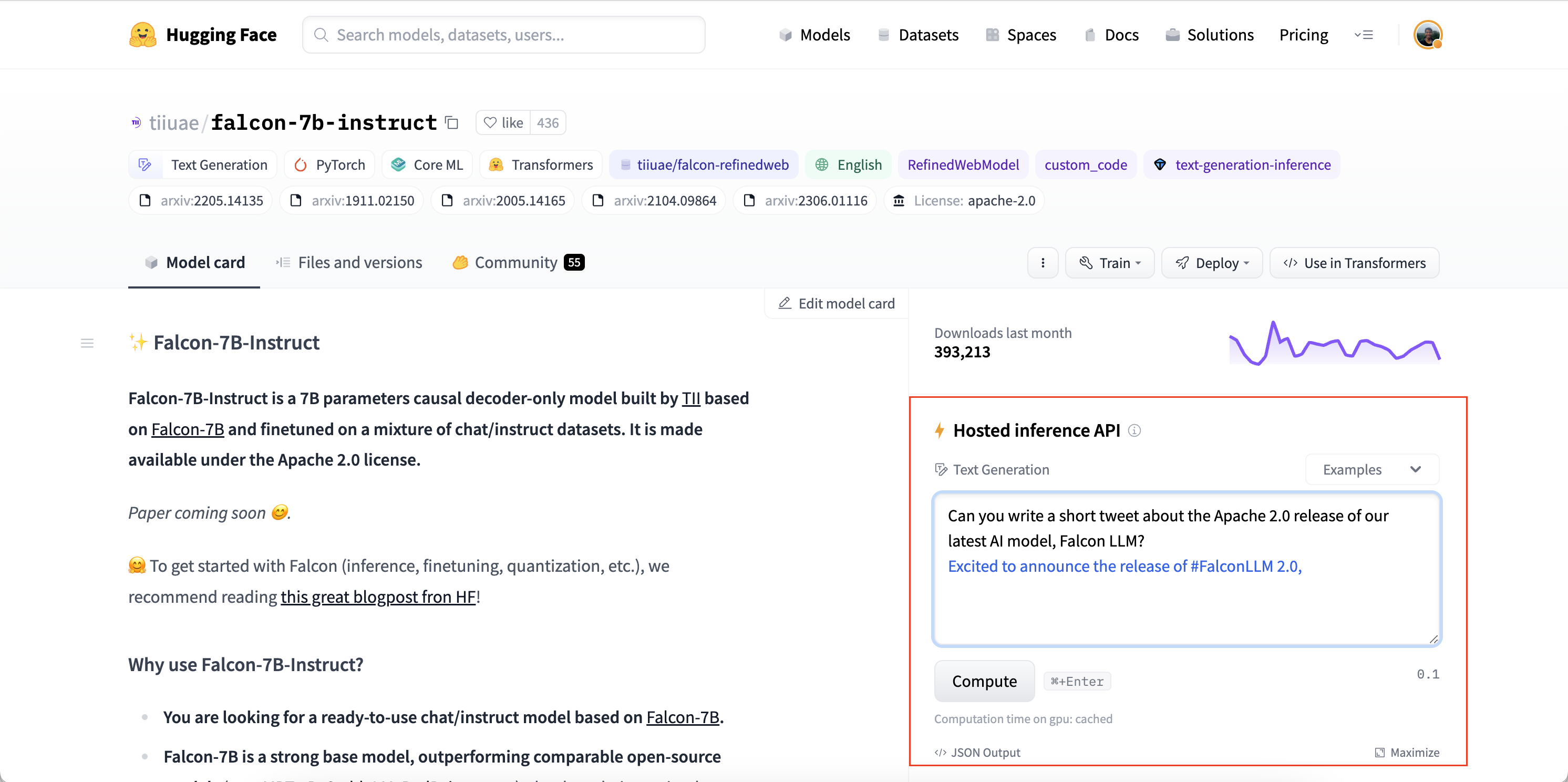
推理API允许我们从本地机器向托管在Hub上的LLM发送HTTP请求,并将响应作为json文件返回。我们所需要提供的只是我们的Hugging Face Hub令牌(直接从我们的Hugging Face Hub文件夹中检索)和我们希望查询的LLM的模型id:
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]
让我们尝试一下测试输入!
query("What does Hugging Face do?")
'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'
您会注意到使用推理API进行推断的速度有多快 - 我们只需要从本地机器发送少量文本标记到托管模型,因此通信成本非常低。LLM托管在GPU加速器上,因此推断速度非常快。最后,生成的响应再次通过低通信开销从模型传输回我们的本地机器。
合成语音
现在我们准备好获取最终的口头输出了!我们再次将使用Microsoft SpeechT5 TTS模型进行英文TTS,但您可以使用您选择的任何TTS模型。让我们继续加载处理器和模型:
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)
以及说话者嵌入:
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
我们将重用在上一章关于语音到语音翻译中定义的合成函数:
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
让我们快速验证这是否符合预期:
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)
Marvin 🤖
现在我们已经为语音助手流程的四个阶段定义了各自的函数,剩下的就是将它们串联起来,得到我们的端到端语音助手。我们只需简单地连接这四个阶段,从唤醒词检测(launch_fn)开始,到语音转录,再到LLM查询,最后是语音合成。
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)
尝试使用一些提示!以下是一些示例,供您开始尝试:
- What is the hottest country in the world?
- How do Transformer models work?
- Do you know Spanish?
有了这个,我们的端到端语音助手就完成了,使用了您在本课程中学到的🤗音频工具,并在最后添加了一些LLM的魔法。我们可以进行一些扩展来改进语音助手。首先,音频分类模型对35个不同的标签进行分类。我们可以使用一个更小、更轻量级的二元分类模型,只预测是否已说出唤醒词。其次,我们提前加载所有模型并在设备上保持运行。如果我们想要节省电力,我们只会在需要时加载每个模型,然后在不需要时卸载它们。第三,我们的转录函数中缺少语音活动检测模型,它会固定时间进行转录,有时太长,有时太短。
泛化到任何内容
到目前为止,我们已经看到了如何使用我们的语音助手Marvin生成语音输出。最后,我们将演示如何将这些语音输出泛化为文本、音频和图像。
我们将使用Transformers Agents来构建我们的助手。Transformers Agents在🤗 Transformers 和 Diffusers 库的基础上提供了一个自然语言API,使用LLM解释自然语言输入,并使用一组精心设计的提示来提供多模态输出。
让我们来实例化一个代理。Transformers Agents提供了三个LLM,其中两个是开源的,并且在Hugging Face Hub上免费提供。第三个是来自OpenAI的模型,需要OpenAI API密钥。在本示例中,我们将使用免费的Bigcode Starcoder模型,但您也可以尝试其他可用的LLM之一:
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)
要使用代理,我们只需调用 agent.run 并传入我们的文本提示。例如,我们将让它生成一张猫的图片 🐈(希望看起来比这个表情符号更好看):
agent.run("Generate an image of a cat")

请注意,第一次调用此功能将触发模型权重的下载,这可能会根据您的Hub下载速度需要一些时间。
就是这么简单!代理解释了我们的提示,并在幕后使用了Stable Diffusion模型来生成图像,而我们不必担心加载模型、编写函数或执行代码。
现在我们可以用Transformers Agent替换我们语音助手中的LLM查询函数和文本合成步骤,因为Agent将为我们处理这两个步骤:
launch_fn()
transcription = transcribe()
agent.run(transcription)
尝试说出相同的提示“生成一张猫的图片”,看看系统的反应如何。如果您询问代理一个简单的问题/回答查询,代理将以文本回答。您可以通过要求返回图像或语音来鼓励它生成多模态输出。例如,您可以要求它:“生成一张猫的图片,加上标题,并朗读标题”。
虽然Agent比我们第一次迭代的Marvin 🤖助手更灵活,但以这种方式泛化语音助手任务可能会导致标准语音助手查询的性能下降。为了恢复性能,您可以尝试使用更高性能的LLM检查点,比如来自OpenAI的检查点,或者定义一组专门针对语音助手任务的自定义工具。
转录会议
在这最后一节中,我们将使用Whisper模型为两个或多个发言者之间的对话或会议生成转录。然后,我们将与说话人分离模型配对,以预测“谁何时发言”。通过将Whisper转录的时间戳与说话人分离模型的时间戳进行匹配,我们可以预测具有完全格式化的每个发言者的开始/结束时间的端到端会议转录。这是您可能在像Otter.ai等在线服务中看到的会议转录服务的基本版本。
说话人分离(Speaker Diarization/Diarisation)
说话人分离是将未标记的音频输入转换为预测“谁何时发言”的任务。通过这样做,我们可以预测每个发言者回合的开始/结束时间戳,对应于每个发言者开始讲话和结束讲话的时间。
🤗 Transformers目前尚未在库中包含用于说话人分离的模型,但Hub上有一些可以相对轻松使用的检查点。在本示例中,我们将使用来自pyannote.audio的预训练说话人分离模型。让我们开始并安装该包:
pip install --upgrade pyannote.audio
太棒了!这个模型的权重托管在Hugging Face Hub上。要访问它们,我们首先必须同意说话人分离模型的使用条款:pyannote/speaker-diarization。随后同意分割模型的使用条款:pyannote/segmentation。
完成后,我们可以在本地设备上加载预训练的说话人分离管道:
from pyannote.audio import Pipeline
diarization_pipeline = Pipeline.from_pretrained(
"pyannote/speaker-diarization@2.1", use_auth_token=True
)
让我们尝试在示例音频文件上使用它!为此,我们将加载LibriSpeech ASR数据集的一个样本,该数据集包含两个不同的发言者,这些发言者已被连接在一起,以提供单个音频文件:
from datasets import load_dataset
concatenated_librispeech = load_dataset(
"sanchit-gandhi/concatenated_librispeech", split="train", streaming=True
)
sample = next(iter(concatenated_librispeech))
我们来听一下:
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
太酷了!我们可以清楚地听到两个不同的发言者,大约15秒的过渡。让我们将此音频文件传递给分离模型,以获取发言者的开始/结束时间。请注意,pyannote.audio期望音频输入是形状为(通道,seq_len)的PyTorch张量,因此我们需要在运行模型之前执行此转换:
import torch
input_tensor = torch.from_numpy(sample["audio"]["array"][None, :]).float()
outputs = diarization_pipeline(
{"waveform": input_tensor, "sample_rate": sample["audio"]["sampling_rate"]}
)
outputs.for_json()["content"]
[{'segment': {'start': 0.4978125, 'end': 14.520937500000002},
'track': 'B',
'label': 'SPEAKER_01'},
{'segment': {'start': 15.364687500000002, 'end': 21.3721875},
'track': 'A',
'label': 'SPEAKER_00'}]
这看起来很不错!我们可以看到第一个发言者被预测为一直发言到14.5秒的标记,第二个发言者从15.4秒开始。现在我们需要获取我们的转录!
语音转录
在本单元的第三次,我们将使用Whisper模型进行语音转录系统。具体来说,我们将加载Whisper Base检查点,因为它足够小,可以在合理的转录准确性下提供良好的推理速度。与以前一样,可以随意使用Hub上的任何语音识别检查点,包括Wav2Vec2、MMS ASR或其他Whisper检查点:
from transformers import pipeline
asr_pipeline = pipeline(
"automatic-speech-recognition",
model="openai/whisper-base",
)
让我们获取我们示例音频的转录,同时返回片段级别的时间戳,以便我们知道每个片段的开始/结束时间。您将会记得,在第5单元中,我们需要传递参数return_timestamps=True以激活Whisper的时间戳预测任务:
asr_pipeline(
sample["audio"].copy(),
generate_kwargs={"max_new_tokens": 256},
return_timestamps=True,
)
{
"text": " The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight. He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
"chunks": [
{"timestamp": (0.0, 3.56), "text": " The second and importance is as follows."},
{
"timestamp": (3.56, 7.84),
"text": " Sovereignty may be defined to be the right of making laws.",
},
{
"timestamp": (7.84, 13.88),
"text": " In France, the king really exercises a portion of the sovereign power, since the laws have",
},
{"timestamp": (13.88, 15.48), "text": " no weight."},
{
"timestamp": (15.48, 19.44),
"text": " He was in a favored state of mind, owing to the blight his wife's action threatened to",
},
{"timestamp": (19.44, 21.28), "text": " cast upon his entire future."},
],
}
好吧!我们看到转录的每个片段都有开始和结束时间,说话者在15.48秒的时候发生了变化。我们现在可以将此转录与我们从分离模型获得的说话者时间戳配对,以获得我们的最终转录。
Speechbox
为了获得最终的转录,我们将从分离模型和Whisper模型中对齐时间戳。分离模型预测第一个发言者在14.5秒结束,第二个发言者在15.4秒开始,而Whisper预测的段边界分别为13.88、15.48和19.44秒。由于Whisper的时间戳与分离模型的时间戳不完全匹配,因此我们需要找出哪些边界最接近14.5和15.4秒,并相应地按说话者对转录进行分段。具体来说,我们将通过最小化分离和转录时间戳之间的绝对距离来找到分离和转录时间戳之间的最接近对齐。
幸运的是,我们可以使用🤗 Speechbox软件包来执行此对齐。首先,让我们从main安装speechbox:
pip install git+https://github.com/huggingface/speechbox
现在,我们可以通过将分离模型和ASR模型传递给ASRDiarizationPipeline类来实例化我们的组合分离加转录管道:
from speechbox import ASRDiarizationPipeline
pipeline = ASRDiarizationPipeline(
asr_pipeline=asr_pipeline, diarization_pipeline=diarization_pipeline
)
您还可以通过指定Hub上的ASR模型的模型id直接从预训练实例化ASRDiarizationPipeline:
pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")
让我们将音频文件传递给组合管道,看看我们得到了什么结果:
pipeline(sample["audio"].copy())
[{'speaker': 'SPEAKER_01',
'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
'timestamp': (0.0, 15.48)},
{'speaker': 'SPEAKER_00',
'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
'timestamp': (15.48, 21.28)}]
太棒了!第一个发言者被划分为从0到15.48秒发言,第二个发言者从15.48到21.28秒发言,对应于每个发言者的相应转录。
我们可以通过定义两个辅助函数来更好地格式化时间戳。第一个将时间戳元组转换为字符串,四舍五入到一定数量的小数位。第二个将说话者id、时间戳和文本信息组合到一行,并将每个说话者分成一行,以便阅读:
def tuple_to_string(start_end_tuple, ndigits=1):
return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
def format_as_transcription(raw_segments):
return "\n\n".join(
[
chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
for chunk in raw_segments
]
)
让我们重新运行管道,这次根据我们刚定义的函数格式化转录:
outputs = pipeline(sample["audio"].copy())
format_as_transcription(outputs)
SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
his entire future.
完成!通过这样做,我们已经对输入音频进行了分段和转录,并返回了按发言者分段的转录。尽管最小距离算法用于对齐分离的时间戳和转录的时间戳是简单的,但在实践中表现良好。如果您想探索更高级的方法来结合时间戳,那么ASRDiarizationPipeline的源代码是一个很好的起点:speechbox/diarize.py。
- 显示Disqus评论(需要科学上网)