本文是对Very Little Evolutionary Game Theory的翻译。
目录
从进化的视觉来看,家庭是一个有充满威胁的(hostage)场景。后代是性细胞(精子和卵子),它们偷走了父母的基因的拷贝并且一起私奔。它们偷走的东西使得它们处于有权势的地位。某种变异如果损坏了后代那么从某种意义上来说就是损坏了其父母。而某种变异如果能够帮助后代那么也不亚于帮助父母本身。这并不是完全合作的情景,因为后代不等同其父母。他们有其自己的兴趣。它们可能会利用它们的权势获取超出其所需的帮助。”给我再来一条虫子”,幼鸟叫道,”否则你的后代就会承受这些”(Or your lineage gets it!)
动物社会也存在这种充满威胁的场景。在自然的每一个角落,兄弟姐妹们总是一种重要的正向吸引的(positive assortment)机制。不过这总是产生了合作与冲突的混合。如果在家庭内部存在合作,那么家庭之间就一定有冲突。比如在很多哺乳动物里,姐妹会组成联盟。一个姐妹联盟为了空间、食物以及后代的未来安全而与另一个姐妹联盟展开激烈的竞争。而姐妹之间也会彼此竞争。冲突与合作的天平会随时发生倾斜。狒狒说:我会和我的姐妹竞争;我和我的姐妹会与我的堂姐妹竞争;我和我的姐妹及堂姐妹会与其它的所有人竞争。
人类社会基于威胁构建了荒诞和令人吃惊的场景。在中世纪的欧洲,王族(royalty)控制这政治权力。王族是一个家族。但是王族会与它的敌国王族联姻,并通过这种威胁来维系和平。”不要入侵我的领土”,王子们喊道,”否则你的孩子们就会被侵害。”
本章的内容讨论亲属选择(kin selection)。
【译注:中国的统治者很早就掌握了这项技巧,从有记载的文字来看,春秋战国时各国国君之间就会通婚并且把他国国君的儿子作为质子,最著名的质子当然就是秦始皇。后来与少数民族的和亲,因为处于防守地位,所以更多是把皇帝的女儿嫁到远方。最著名的假公主就是王昭君,她假冒成皇帝的女儿嫁给了xx单于。】
汉密尔顿规则(Hamilton’s rule)
亲属之间的互动能够提升合作的机会。在非常强的假设下,存在一个非常简单的规则。
假设两个有亲属关系的个体在玩一个一次性的囚徒困境游戏。什么时候自然选择会更青睐合作?在进化生物学和anthropology的入门课程里学生们都被教授了如下的简单公式:
\[rb>c\]r是两个个体的亲密(relatedness)系数,b和c就是囚徒困境里的参数,分别代表被帮助的payoff和帮助他人的cost。这个公式被叫做汉密尔顿规则。这个公式用于定性分析非常有价值。它告诉我们:血缘关系越接近的两个个体,其亲密系数也越大,那么他们即使在囚徒困境这样很难合作的游戏里合作的可能性也会越大。这个公式的推导过程也会帮助我们理解为什么会是这样。
我们先介绍一个非常简单的推导,之后会介绍一个更详细并且更有教育意义的推导方法。回顾一下之前的正向吸引的统计模型。在这个模型里,策略X遇到同样策略的对手的概率是:
\[Pr(X | X)=r+(1-r)p\]r是吸引稀疏,p是X在人群中的占比。现在考虑只玩一次的囚徒困境游戏。假设人口中大部分都是不合作(N)的策略者,那么少数合作(C)的策略者入侵的条件是:
\[Pr(C | C)(b-c) + Pr(N | C)(-c) > 0\]上式左边是少量合作者的平均fitness,而右边的零是不合作者的平均fitness。现在把正向吸引的概率代入:
\[(r+(1-r)p)(b-c) + (1-r)(1-p)(-c) > 0\]当合作者很少的时候,p约等于0,因此上面的式子可以进行化简:
\[(r+0)(b-c) + (1-r)(1-0)(-c) > 0 \\ rb - rc - c + rc > 0 \\ rb > c\]最终化简的结果就是$rb > c$。这就是汉密尔顿规则的公式。
和进化博弈论中的很多其它公式一样,这个规则的公式依赖于很多具体的假设。因此它不是通用的规则。但是目前有一种夸大其适用范围的趋势,尤其是在人类进化科学领域。这很容易产生误导性的结果。比如进化心理学期刊的创建者这样写道:“在任何时候任何地方对任何物种都成立”。但请看一下如下的难题(Puzzle)。
在很多鸟类物种里很多雏鸟在第一年并没有性成熟,因而它们可以留在父母的鸟巢里并且为其父母提供帮助。考虑一个场景:这个雏鸟能够帮助它的四个兄弟姐妹但是也可能会牺牲自己。因此b=4,c=1,r=0.5。汉密尔顿公式是满足的,但是这种牺牲自己的基因会消失从而使得它不再出现在基因库里。因此汉密尔顿公式是错误的,那它错在哪里呢?【译注:译者认为这里逻辑可能有点问题,牺牲自己的雏鸟救回了4个兄弟姐妹,那么这4个兄弟姐妹也有一半的概率拥有这种舍己救人的基因,也就是2,为什么这种基因就消失了呢?】
亲兄弟姐妹的亲密系数是1/2,堂兄弟姐妹是1/4,以此类推,血缘关系越远亲密系数就越小。这个系数通常被解释为两个个体共享一个等位基因(allele)的概率。这是不对的,因为在genome的许多地点,只有少量的等位基因。所以许多非常远房的亲戚之间也会共享等位基因。实际上,r更可能是从同一个共同祖先基础下来相同的等位基因的概率。但是这也不完全正确,因为如果变异占很少的人口,并且人口也不是非常多,那么共享这个等位基因的个体都是从共同祖先那里来的。那么自然选择为什么不青睐让它们合作?【译注:这一段译者没有太理解,所以翻译只是根据字面进行,可能不准确。建议读者阅读原文,如果读者发现翻译的错误,请帮我纠正。】
Price等式
为了推导汉密尔顿公式,我们需要一步一步来。我们首先需要得出自然选择更通用的结论,之后在引入一些假设得到简单的汉密尔顿公式。我们先从Price等式开始:
\[\bar{w} \Delta p = cov(w_i,p_i)\]这个等式说明了进化的一个简单事实:拥有某个等位基因的人口比例的变化等于个体fitness值$w_i$和个体等位基因频率$p_i$。下面我们来详细的推导Price等式。
下面我们聚焦与一个特定的等位基因S来推导在人群中它的频率改变的期望值。假设$n_i$是第i个个体拥有等位基因S的个数,也就是它的ploidy(几倍体)。对于人类来说,染色体总是成对的,所有的$n_i$几乎都等于2。【译注:如果读者记不起了,我们再来回忆一些中学的生物学知识,也就是孟德尔种豌豆的故事。豌豆的花有两种颜色:紫色和白色,这是由某个基因决定的,这个基因有两个等位基因,其中一个是显性基因S,另一个是隐性基因s。人类是二倍体,所以一个基因可以取两个值,那么这个基因就有三种可能,SS、Ss和ss。因为S是显性基因,所以SS和Ss都是紫色。如果我们让Ss和Ss杂交,那么后代基因组合有4种可能:SS、Ss、sS和ss,前三种都是紫色,只有最后一种是yy白色,所以其后代的比例是3:1。对于人类来说所以个体的$n_i$都是相同的,但是某些植物,不同个体的$n_i$可能不同。】假设群体中等位基因的总是是N,那么显然有$N=\sum_in_i$。假设第i个个体中S的比例是$p_i$,那么人口中等位基因S的比例为:
\[p = \sum_i \frac{n_ip_i}{N}\]【译注:对于人类来说,p_i的取值只能是0、1/2和1,分别对应ss、Ss和SS的情况。】现在我们用符号’表示下一代的情况。所以在下一代的时候S的占比为$\sum_i \frac{n_i’p_i’}{N’}$。现在假设个体i的fitness是$w_i$,这里假设fitness就是其后代的个数。假设等位基因S的平均fitness是$\bar{w}$,那么有$\bar{w}=\sum_i(n_i/N)w_i$。【译注:这个 $\bar{w}$是什么意思呢?我们假设种群里有3个个体,其fitness分别是1、2和3,并且3个个体的$n_i$是2、2和4,那么$\bar{w}=(2 \times 1+2 \times 2+4 \times 3)/(2+2+4)$。所以我们看到,这里的fitness是从基因的角度来定义的。这个例子里一共有3个个体,8个基因(可能取值S或者s),平均每个基因的fitness是(18/8)。】然后我们可以计算出$n_i’=w_in_i$和$N’=\bar{w}N$,把这两个式子代入得到:
\[p'=\sum_i\frac{w_in_ip'}{\bar{w}N}\]接下来我们计算两代之间p的差值$\Delta p = p’-p$:
\[\Delta p = \sum_i\frac{w_in_ip'}{\bar{w}N} - p\]上式两边都乘以$\bar{w}$得到:
\[\bar{w} \Delta p = \sum_i\frac{n_i}{N}w_ip_i' - p \bar{w} = \sum_i\frac{n_i}{N}w_ip_i' - p \sum_i \frac{n_i}{N}w_i\]接着我们在给上式加上然后再减去$\sum_i \frac{n_i}{N}w_ip_i$,上式仍然成立:
\[\bar{w} \Delta p = \underbrace{\sum_i\frac{n_i}{N}w_ip_i'}_{A} - \underbrace{p \sum_i \frac{n_i}{N}w_i}_{B} + \underbrace{\sum_i \frac{n_i}{N}w_ip_i}_{C} - \underbrace{\sum_i \frac{n_i}{N}w_ip_i}_{D}\]A和B是原式中的项,C和D是加上并且随后减去的相同项。我们重新整理一下:
\[\bar{w} \Delta p = \underbrace{\sum_i \frac{n_i}{N}w_ip_i}_{C} - \underbrace{p \sum_i \frac{n_i}{N}w_i}_{B} + \underbrace{\sum_i\frac{n_i}{N}w_ip_i'}_{A} - \underbrace{\sum_i \frac{n_i}{N}w_ip_i}_{D} \\ = \sum_i\frac{n_i}{N}w_i(p_i-p) + \sum_i\frac{n_i}{N}w_i(p_i'-p_i)\]最后一步,协方差的定义是$cov(x,y)=E(x(y-\bar{y}))$。
【译注:我们最常见的定义应该是$cov(x,y)=E((x-\bar{x})(y-\bar{y}))$,不过可以证明这是相等的。
\[cov(X,Y)=E[(X-EX)(Y-EY)]=E[X(Y-EY)-EX(Y-EY)]=E[X(Y-EY)] - E[EX(Y-EY)]\]而
\[E[EX(Y-EY)]=E[EX \times Y-EX \times EY]=EX \times EY-E[EX \times EY]=EX \times EY-EX \times EY=0\]所以有$cov(X,Y)=E(X(Y-EY)]$ 】
所以等式右边第一项是$w_i$和$p_i$的协方差,因为p的定义就是$p_i$的均值。所以我们得到Price等式:
\[\bar{w} \Delta p = cov(w_i,p_i) + E(w_i \Delta p_i)\]上式中$\Delta p_i = p_i’ - p_i$,是一个个体在生命不同阶段等位基因S的比例,对于人类来说它是不变的,当然有些植物在生命的不同阶段会发生变化。我们这里简单的假设它是不变的,因此$E(w_i \Delta p_i)=0$,这样就得到了Price等式。【译注:前面说的下一代并不是这个个体的儿子或者女儿,这里说的是在同一个个体中细胞的下一代,拿人来说,我们的体细胞在我们一生中是会发生很多次分裂的,我们可以把这个后代理解为体细胞分裂产生的后代。一次游戏可以理解为一次猎鹿游戏,合作的花双方可以获得更多食物,因此吃得更饱,从而体重增加,从细胞层面上来看一个平均每个细胞通过分裂产生的后代越多。】
【译注: 我们再来看一下哈密尔顿规则:
\[\bar{w} \Delta p = cov(w_i,p_i)\]这个公式翻译成自然语言是这样的:当前这一代的平均fitness值$\bar{w}$乘以等位基因S比例的变化($\Delta p$)等于个体fitness值$w_i$和个体中等位基因S占比$p_i$的协方差。这又是什么意思呢?根据协方差的定义,随机变量X和Y的协方差是$cov(X,Y)=E(X-EX)(Y-EY)$。我们举一个例子。假设w_i和p_i分别是0.8,1,1.2和0,1/2,1。我们来计算一下:
\[X-EX=-0.2,0,0.2 \\ Y-EY=-0.5,0,0.5 \\ cov(X,Y)=(-0.2 \times -0.5)+(0 \times 0)+(0.2 \times 0.5)\]我们看到$w_1$和$p_1$都低于平均值,所以它们减去平均值乘起来是大于0的,类似的是$w_3$和$p_3$。因此我们看到,如果和平均水平相比(减去平均值),$w_i$和$p_i$都大于零或者都小于零,则它们对$cov(w_i,p_i)$是有正向的贡献,而且两者越大贡献越大。它说明变量w和p是相关的。我们也可以这样来解读:如果在所有个体中,等位基因S的比例越大就有fitness越大,以及S的比例越小就有fitness越小,那么我们就可以认为等位基因S对于个体的fitness是有正向作用的,那么S的比例就应该增加$\Delta p > 0$。 】
Price等式是一个非常通用的式子,它和自然选择无关。如果$w_i$是随机的(【译注:也就是和$p_i$无关,所以cov(w,p)=0】,那么自然选择不会让等位基因S变化。这个等式也能够完美的推广到很多不同的遗传系统,比如在昆虫的社会里,雌性是二倍体(diploid)而雄性是单倍体(haploid)。
加性(additive)fitness
我们这里还是假设重复的囚徒困境游戏是加性的,也就是同时合作的受益是单方合作的相加。并且假设:
\[w_i=w+h_i(-c)+y_ib\]其中w是和游戏无关的一个baseline值,c和b的含义和前面一样,仍然是帮助别人的cost和被帮助的受益。$h_i$是第i个个体帮助对方的概率,$y_i$是对方帮助第i个个体的概率。
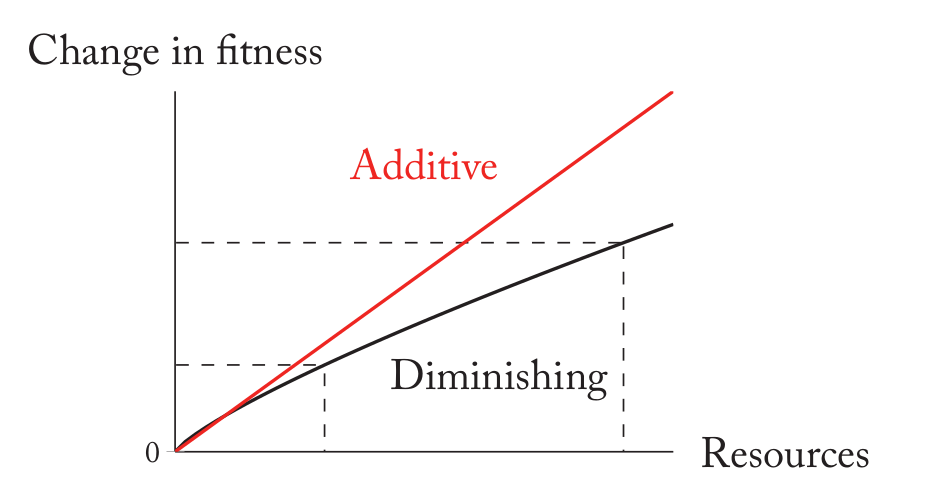
加性fitness是一个非常特别的情况,它不考虑协调效应(synergy)和边际递减效应【译注:原文是diminishing】。对于大部分资源,比如你给我的帮助增加到两倍,那么我的收益不会是原来的两倍。如下图所示:加性收益是线性的,而实际情况可能是递减的。
把上式代入Price等式,得到: \(\bar{w}\Delta p= cov(w+h_i(-c)+y_ib, p_i)\)
因为协方差就是期望(积分或者求和),期望就是求和,因此我们可以把上式进行分解:
\[\bar{w}\Delta p= cov(w, p_i) + cov(h_i(-c), p_i) + cov(y_ib, p_i)\]第一项$cov(w, p_i)$是零。原因在于w是常量,常量不会变(don’t vary),所以也不会和另外的变量协变(co-vary)。【译注:协方差(co-variance)的含义是协同改变(你大我也大,你小我也小),但是翻译成中文之后就没有这层意思了。读者可以阅读原文体会其中的含义。】接下来我们把第二和第三项的常量提取到前面:
\[\bar{w}\Delta p= (-c) cov(h_i,p_i) + b cov(y_i, p_i)\]如果右边大于零,则意味着等位基因S的占比会增加,也就是合作的可能性会增加。右边大于零的条件是:
\[b \frac{cov(y_i,p_i)}{cov(h_i, p_i)} > c\]这还不是哈密尔顿公式,但是有点像了,它们的区别是那个比值和r,如果两者相等,那就搞定了。那个比值是什么意思呢?用生物学语言来描述就是:第i个个体得到帮助(这个随机变量)和等位基因S的协方差除以第i个个体帮助别人(也是一个随机变量)和等位基因S的协方差。$p_i$是个体的基因型(genotype),而$h_i$和$y_i$表现型(phenotype)。
【译注:生物知识还给老师的读者可以回顾一下孟德尔豌豆颜色的例子。我们能看到的是表现型,而实际的基因是基因型。SS和Ss是不同的基因型,但是表现出来的颜色(性状)都是红色。】
加性基因
现在我们需要建立基因型$p_i$和表现型$y_i$与$h_i$的关系了,我们还是假设它们的关系是最简单的线性关系:
\[h_i = a + k p_i \\ y_i = a + k p_j\]第一个式子是个体i帮助别人的概率,这是一个线性公式,如果k大于0,则等位基因S越多,这个个体越倾向于帮助别人。注意第二个式子$p_j$的下标是j,第i个个体被别人帮助跟自己(i)无关【译注:也许某些个体更容易被帮助,比如长相优雅,不过这里不考虑这么复杂的情况。】而只与对方的基因相关。
$p_i$是个体i中等位基因S的比例,我们这里假设S越多,它就越容易帮助别人。但实际情况可能并不完全这样,比如拿人来说,因为人是二倍体,所以$p_i$只有三种取值:0,1/2,1,分别对应ss,Ss,SS。由于S是显性基因,Ss和SS在表现上都是一样的,都是同样的乐于助人。把上面的两个式子代入前面的条件,得到:
\(b \frac{cov(a + k p_j, p_i)}{cov(a + k p_i, p_i)} > c\) 和前面类似,我们可以把协方差的求和分解并且利用常量的协方差是零进行化简: \(b \frac{cov(p_j, p_i)}{cov(p_i, p_i)} > c\)
分母是变量$p_i$和自己的协方差,也就是$p_i$的方差:
\[b \frac{cov(p_j, p_i)}{var(p_i)} > c\]我们常常用一个变量$\beta(p_j,p_i)$来表示左边的第二个因子,这样看起来和哈密尔顿公式更像一点:
\[b \beta(p_j,p_i) > c\]其中$\beta(p_j,p_i)$是用focal对象的基因型$p_i$来回顾预测对手基因型$p_j$的回归系数。【译注:这个地方译者没有完全明白。为什么$\frac{cov(p_j, p_i)}{var(p_i)}$就是回归系数呢?译者大概的理解是:如果要用$p_i$来预测(线性回顾)$p_j$,那么$p_i$方差越大就越难预测。方差小,比如最极端的0,说明$p_i$是一个常量,则能更准确的预测。另外就是$cov(p_j,p_i)$是正的,则说明$p_j$随着$p_i$增大而增大。而且$cov(p_j,p_i)$越大,这条直线就越陡。】所以用$p_j$的期望可以用$p_i$来线性预测:
\[E(p_j | p_i) = E(p_j)+\beta(p_j,p_i)(p_i-E(p_i)) \\ = p + \beta(p_j,p_i)(p_i - p)\]把$\beta(p_j,p_i)$解出来:
\[\beta(p_j,p_i) = \frac{E(p_j | p_i)-p}{p_i - p}\]上面的式子得到的$\beta(p_j,p_i)$依然不是r,但它是两个个体基因型$p_i$和$p_j$的函数。任何生物过程如果能够使得$E(p_j | p_i) > p$都会促使合作得以进化。
【译注:如果对上式的推导过程没有完全理解,我们至少要理解$E(p_j | p_i)$的含义。它的含义是用自己(i)的等位基因S的比例去预测对手(j)的比例。如果是随机的两个人,那么他们是无关的,所以知道了自己的基因对于预测对手的基因是不提供任何信息的,所以$E(p_j | p_i)=E(p_j)$。但是我们这里假设i和j是有血缘关系的,所以如果我(i)有S基因,那么j有S基因的概率会更大。】
非常弱的(自然)选择
为了得到哈密尔顿规则,我们需要让$\beta(p_j,p_i)=r$。如果自然选择非常弱的情况下,我们可以得到$\beta(p_j,p_i) \approx r$。推导的方法是,我们把$E(p_j | p_i)$,也就是给定i的条件下基因型j的期望,关联到i和j的共同祖先。接下来我们会解释为什么这个推导依赖弱的自然选择。
我们定义个体i和j的基因中通过继承而获得的相同(identical by descent, IBD)等位基因比例为r。当一个基因是IBD,它的意思是i和j有相同的等位基因并且这个基因来自某个共同的祖先。当一个决定是否合作的等位基因是IBD时,它可能是增加合作的等位基因但也可能不是。举例来说,假设$p_i=0.5$,这可能是一个二倍体,两个染色体中可能有一个是促进合作的等位基因S。因此虽然i和j通过血统共享比例为r的基因,这些基因只有一半的机会是合作的基因。所以j和i通过血统继承而来的合作基因为$rp_i$。
除了通过IBD之外,i和j还有可能是通过人口比例随机的遇到合作的等位基因S,其概率是$(1-r)p$。所以有:
\(E(p_j | p_i) = \underbrace{rp_i}_{\text{IBD}} + \underbrace{(1-r)p}_{\text{non-IBD}}\) 【译注:我们再来用自然语言描述一下上面的公式。已知$p_i$,$p_j$的期望值(估计值)是多少呢?首先因为$p_j$和$p_i$有比例为r的基因是从相同祖先继承而来,而i中有$p_i$的比例是等位基因S,那么j中就有$rp_j$的等位基因S。另外j中的等位基因来自人群的随机比例。因此首先是(1-r)的概率这些基因不是IBD,然后人群中有p的比例是S,所以相乘得到第二项。】 解出r:
\[r = \frac{E(p_j | p_i)-p}{p_i-p}\]r正好等于$\beta(p_j,p_i)$。这样我们就完成了哈密尔顿规则的证明!
前面我们说要做弱自然选择的前提下才能推导出来,但是我们似乎已经推导出来了,而且好像还没有用到这个假设。当我们认为通过IBD继承使得j获得合作的等位基因S的概率是$rp_i$时,我们隐含了这样一个假设:合作的等位基因S和不合作的等位基因s从共同祖先传递给后代的概率是一样的。但如果存在较强的自然选择时,这个隐含假设可能不成立。比如你(读者)能够出现在这个世界上就说明了你没有从祖先那里基础什么致命的基因。因此如果在过去的世代里,自然选择偏爱合作基因S(或者不合作的s),那么i和j的IBD就不能简单的在家谱中计算它们的链接来计算r了。所以我们需要使用弱选择的假设。
对于较近的亲属关系,自然选择即使较强,上面计算r的方法也是一个不错的近似。但是如果对于较远的亲属关系,即使是较弱的自然选择也会使得用i来预测j的基因变得非常不准确。一旦一个等位基因在人群中变得很多,那么几乎所有个体都会通过血缘继承这个等位基因。但这个对于理解合作的进化并没有帮助。因为我们假设这个合作的等位基因S是一个突变基因,它在一开始是很少的。近亲更容易共享一些最近的祖先才产生的变异,这使得近亲之间的表现型(比如合作)的正向吸引得以出现。
- 显示Disqus评论(需要科学上网)