本文介绍百度的深度学习框架PaddlePaddle的基本概念和用法。本文主要参考了官方文档,也包括一些作者自己的理解。
目录
快速上手
这部分通过一个线性回归的问题来感受一下PaddlePaddle的使用,读者不需要理解每一行代码(但是有必要尝试阅读和尽可能多的理解),后面的部分会详细的介绍。读者需要动手把环境搭建起来,把程序跑起来,这是最重要的第一步。
快速安装
我使用的是GPU的版本,所以使用如下的命令安装:
pip install -U paddlepaddle-gpu
为了避免冲突,建议使用virtualenv。当前最新的(1.5)PaddlePaddle需要CUDA 9 ,cuDNN 7.3 ,NCCL2 等依赖,如果出现安装问题请参考安装说明。如果读者没有GPU的机器或者安装GPU的版本遇到问题,可以先安装CPU的版本跑起来,CPU版本的安装通常更简单,等了解了PaddlePaddle之后可能更容易解决安装的问题。(注:其实学习一个新的东西最大的障碍是把Hello World跑起来,很多时候放弃的原因就是第一步搞不定)
CPU版本的安装可以使用:
pip install -U paddlepaddle
快速使用
我们首先需要导入paddle:
import paddle.fluid as fluid
下面是使用paddle操作tensor几个例子,请读者阅读其中的代码注释,尽量猜测它们的含义。
- 使用Fluid创建5个元素的一维数组,其中每个元素都为1
# 定义数组维度及数据类型,可以修改shape参数定义任意大小的数组
data = fluid.layers.ones(shape=[5], dtype='int64')
# 在CPU上执行运算
place = fluid.CPUPlace()
# 创建执行器
exe = fluid.Executor(place)
# 执行计算
ones_result = exe.run(fluid.default_main_program(),
# 获取数据data
fetch_list=[data],
return_numpy=True)
# 输出结果
print(ones_result[0])
上面代码的结果为:
[1 1 1 1 1]
和Tensorflow等框架类似,paddle也需要定义tensor,比如fluid.layers.ones会创建一个全是1的tensor。同样如果需要查看它的值,我们也需要”运行”它。paddle里需要用执行器fluid.Executor来执行各种操作,另外定义Executor时需要指定在哪个设备上运行,这里用CPUPlace()来让代码则CPU上运行。和Tensorflow不同,paddle没有session,但是有程序(Program)的概念,我们定义的操作(比如定义的data)是默认添加到默认程序(fluid.default_main_program())。执行器执行时要指定运行哪个程序,Executor.run需要传入程序、feed参数(和Tensorflow的run类似,不过这里不需要feed)、输出参数fetch_list。return_numpy告诉Executor返回numpy数组而不是paddle的tensor,这便于我们打印结果(Tensorflow的session.run返回的就是numpy数组)。
- 使用Fluid将两个数组按位相加
接着上面的例子,我们把data和它自己加起来:
# 调用 elementwise_op 将生成的一维数组按位相加
add = fluid.layers.elementwise_add(data,data)
# 定义运算场所
place = fluid.CPUPlace()
exe = fluid.Executor(place)
# 执行计算
add_result = exe.run(fluid.default_main_program(),
fetch_list=[add],
return_numpy=True)
# 输出结果
print (add_result[0])
结果为:
[2 2 2 2 2]
- 使用Fluid转换数据类型
接着我们把int64的类型转换成float64:
# 将一维整型数组,转换成float64类型
cast = fluid.layers.cast(x=data, dtype='float64')
# 定义运算场所执行计算
place = fluid.CPUPlace()
exe = fluid.Executor(place)
cast_result = exe.run(fluid.default_main_program(),
fetch_list=[cast],
return_numpy=True)
# 输出结果
print(cast_result[0])
结果为:
[1. 1. 1. 1. 1.]
运行线性回归模型
这是一个简单的线性回归模型,来帮助我们快速求解4元一次方程。
#加载库
import paddle.fluid as fluid
import numpy as np
#生成数据
np.random.seed(0)
outputs = np.random.randint(5, size=(10, 4))
res = []
for i in range(10):
# 假设方程式为 y=4a+6b+7c+2d
y = 4*outputs[i][0]+6*outputs[i][1]+7*outputs[i][2]+2*outputs[i][3]
res.append([y])
# 定义数据
train_data=np.array(outputs).astype('float32')
y_true = np.array(res).astype('float32')
#定义网络
x = fluid.layers.data(name="x",shape=[4],dtype='float32')
y = fluid.layers.data(name="y",shape=[1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)
#定义损失函数
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
avg_cost = fluid.layers.mean(cost)
#定义优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.05)
sgd_optimizer.minimize(avg_cost)
#参数初始化
cpu = fluid.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
##开始训练,迭代500次
for i in range(500):
outs = exe.run(
feed={'x':train_data,'y':y_true},
fetch_list=[y_predict.name,avg_cost.name])
if i%50==0:
print ('iter={:.0f},cost={}'.format(i,outs[1][0]))
#存储训练结果
params_dirname = "result"
fluid.io.save_inference_model(params_dirname, ['x'], [y_predict], exe)
# 开始预测
infer_exe = fluid.Executor(cpu)
inference_scope = fluid.Scope()
# 加载训练好的模型
with fluid.scope_guard(inference_scope):
[inference_program, feed_target_names,
fetch_targets] = fluid.io.load_inference_model(params_dirname, infer_exe)
# 生成测试数据
test = np.array([[[9],[5],[2],[10]]]).astype('float32')
# 进行预测
results = infer_exe.run(inference_program,
feed={"x": test},
fetch_list=fetch_targets)
# 给出题目为 【9,5,2,10】 输出y=4*9+6*5+7*2+10*2的值
print ("9a+5b+2c+10d={}".format(results[0][0]))
上面的代码就是简单的线性回归,和Tensorflow的有很多类似的地方。不同之处为:
-
不需要运行时指定操作
在Tensorflow里,我们通过session.run告诉引擎计算哪些操作,但是在paddlepaddle里,我们只需要告诉它执行哪个程序,我们默认的操作都是按照顺序添加到程序里的,它会自动执行最后的操作(sgd_optimizer.minimize(avg_cost))。这个操作会首先进行前向的计算,然后反向计算梯度,最后更新参数。
-
save_inference_model自动裁剪
训练介绍后我们需要用save_inference_model函数保存模型,我们只需要告诉它输入和预测的输出,它会自动裁剪计算图,只保留从输入到输出的子图。
-
fluid.scope_guard
为了避免把预测的模型也加载到默认程序里,我们用fluid.scope_guard构造一个新的Scope,然后在这里加载保存的模型来预测。如果不构造新的Scope,虽然代码依然可以运行,但是训练的模型和预测的模型混在一起很容易混淆。
使用指南
LoD-Tensor
大部分深度学习框架都有Tensor的概念,但是PaddlePaddle除了普通的Tensor之外还有一个特殊的LoD-Tensor,它的作用是解决变长序列。在其它的框架里我们通常使用Padding把变长的序列变成定长的序列来解决这个问题,这会导致我们的代码需要有特殊的逻辑来处理padding。而PaddlePaddle则通过Lod-Tensor来系统解决变成的问题。
变长序列的挑战
大多数的深度学习框架使用Tensor表示一个mini-batch。
例如一个mini-batch中有10张图片,每幅图片大小为32x32,则这个mini-batch是一个10x32x32的 Tensor。
或者在处理NLP任务中,一个mini-batch包含N个句子,每个字都用一个D维的one-hot向量表示,假设所有句子都用相同的长度L,那这个mini-batch可以被表示为NxLxD的Tensor。
上述两个例子中序列元素都具有相同大小,但是在许多情况下,训练数据是变长序列。基于这一场景,大部分框架采取的方法是确定一个固定长度,对小于这一长度的序列数据以0填充。
在Fluid中,由于LoD-Tensor的存在,我们不要求每个mini-batch中的序列数据必须保持长度一致,因此您不需要执行填充操作,也可以满足处理NLP等具有序列要求的任务需求。
Fluid引入了一个索引数据结构(LoD)来将张量分割成序列。
LoD索引
为了更好的理解LoD的概念,本节提供了几个例子供您参考:
- 句子组成的mini-batch
假设一个mini-batch中有3个句子,每个句子中分别包含3个、1个和2个单词。我们可以用(3+1+2)xD维Tensor 加上一些索引信息来表示这个mini-batch:
3 1 2
| | | | | |
上述表示中,每一个 | 代表一个D维的词向量,数字3,1,2构成了 1-level LoD。
- 递归序列
让我们来看另一个2-level LoD-Tensor的例子:假设存在一个mini-batch中包含3个句子、1个句子和2个句子的文章,每个句子都由不同数量的单词组成,则这个mini-batch的样式可以看作:
3 1 2
3 2 4 1 2 3
||| || |||| | || |||
表示的LoD信息为:
[[3,1,2]/level=0/,[3,2,4,1,2,3]/level=1/]
- 视频的mini-batch
在视觉任务中,时常需要处理视频和图像这些元素是高维的对象,假设现存的一个mini-batch包含3个视频,分别有3个,1个和2个帧,每个帧都具有相同大小:640x480,则这个mini-batch可以被表示为:
3 1 2
口口口 口 口口
最底层tensor大小为(3+1+2)x640x480,每一个 口 表示一个640x480的图像
- 图像的mini-batch
在传统的情况下,比如有N个固定大小的图像的mini-batch,LoD-Tensor表示为:
1 1 1 1 1
口口口口 ... 口
在这种情况下,我们不会因为索引值都为1而忽略信息,仅仅把LoD-Tensor看作是一个普通的张量:
口口口口 ... 口
- 模型参数
模型参数只是一个普通的张量,在Fluid中它们被表示为一个0-level LoD-Tensor。
LoDTensor的偏移表示
为了快速访问基本序列,Fluid提供了一种偏移表示的方法——保存序列的开始和结束元素,而不是保存长度。
在上述例子中,您可以计算基本元素的长度:
3 2 4 1 2 3
将其转换为偏移表示:
0 3 5 9 10 12 15
= = = = = =
3 2+3 4+5 1+9 2+10 3+12
所以我们知道第一个句子是从单词0到单词3,第二个句子是从单词3到单词5。
类似的,LoD的顶层长度
3 1 2
可以被转化成偏移形式:
0 3 4 6
= = =
3 3+1 4+2
因此该LoD-Tensor的偏移表示为:
0 3 4 6
3 5 9 10 12 15
LoD-Tensor
一个LoD-Tensor可以被看作是一个树的结构,树叶是基本的序列元素,树枝作为基本元素的标识。
在 Fluid 中 LoD-Tensor 的序列信息有两种表述形式:原始长度和偏移量。在 Paddle 内部采用偏移量的形式表述 LoD-Tensor,以获得更快的序列访问速度;在 python API中采用原始长度的形式表述 LoD-Tensor 方便用户理解和计算,并将原始长度称为: recursive_sequence_lengths 。
以上文提到的一个2-level LoD-Tensor为例:
3 1 2
3 2 4 1 2 3
||| || |||| | || |||
以偏移量表示此 LoD-Tensor:[ [0,3,4,6] , [0,3,5,9,10,12,15] ]。
以原始长度表达此 Lod-Tensor:recursive_sequence_lengths=[ [3-0 , 4-3 , 6-4] , [3-0 , 5-3 , 9-5 , 10-9 , 12-10 , 15-12] ]。
以文字序列为例: [3,1,2] 可以表示这个mini-batch中有3篇文章,每篇文章分别有3、1、2个句子,[3,2,4,1,2,3] 表示每个句子中分别含有3、2、4、1、2、3个字。
recursive_seq_lens 是一个双层嵌套列表,也就是列表的列表,最外层列表的size表示嵌套的层数,也就是lod-level的大小;内部的每个列表,对应表示每个lod-level下,每个元素的大小。
下面三段代码分别介绍如何创建一个LoD-Tensor,如何将LoD-Tensor转换成Tensor,如何将Tensor转换成LoD-Tensor:
- 创建 LoD-Tensor
#创建lod-tensor
import paddle.fluid as fluid
import numpy as np
a = fluid.create_lod_tensor(np.array([[1],[1],[1],
[1],[1],
[1],[1],[1],[1],
[1],
[1],[1],
[1],[1],[1]]).astype('int64') ,
[[3,1,2] , [3,2,4,1,2,3]],
fluid.CPUPlace())
#查看lod-tensor嵌套层数
print (len(a.recursive_sequence_lengths()))
# output:2
#查看最基础元素个数
print (sum(a.recursive_sequence_lengths()[-1]))
# output:15 (3+2+4+1+2+3=15)
- LoD-Tensor 转 Tensor
import paddle.fluid as fluid
import numpy as np
# 创建一个 LoD-Tensor
a = fluid.create_lod_tensor(np.array([[1.1], [2.2],[3.3],[4.4]]).astype('float32'),
[[1,3]], fluid.CPUPlace())
def LodTensor_to_Tensor(lod_tensor):
# 获取 LoD-Tensor 的 lod 信息
lod = lod_tensor.lod()
# 转换成 array
array = np.array(lod_tensor)
new_array = []
# 依照原LoD-Tensor的层级信息,转换成Tensor
for i in range(len(lod[0]) - 1):
new_array.append(array[lod[0][i]:lod[0][i + 1]])
return new_array
new_array = LodTensor_to_Tensor(a)
# 输出结果
print(new_array)
- Tensor 转 LoD-Tensor
import paddle.fluid as fluid
import numpy as np
def to_lodtensor(data, place):
# 存储Tensor的长度作为LoD信息
seq_lens = [len(seq) for seq in data]
cur_len = 0
lod = [cur_len]
for l in seq_lens:
cur_len += l
lod.append(cur_len)
# 对待转换的 Tensor 降维
flattened_data = np.concatenate(data, axis=0).astype("int64")
flattened_data = flattened_data.reshape([len(flattened_data), 1])
# 为 Tensor 数据添加lod信息
res = fluid.LoDTensor()
res.set(flattened_data, place)
res.set_lod([lod])
return res
# new_array 为上段代码中转换的Tensor
lod_tensor = to_lodtensor(new_array,fluid.CPUPlace())
# 输出 LoD 信息
print("The LoD of the result: {}.".format(lod_tensor.lod()))
# 检验与原Tensor数据是否一致
print("The array : {}.".format(np.array(lod_tensor)))
LoD会让序列的处理变得简单,读者可以在下面的情感分析示例里体会到这带来的好处。如果现在还不是特别明白LoD的用处,可以在阅读后面的情感分析的代码时回过头来参考本节内容。
准备数据
使用PaddlePaddle Fluid准备数据分为三个步骤:
- Step1: 自定义Reader生成训练/预测数据
生成的数据类型可以为Numpy Array或LoDTensor。根据Reader返回的数据形式的不同,可分为Batch级的Reader和Sample(样本)级的Reader。
Batch级的Reader每次返回一个Batch的数据,Sample级的Reader每次返回单个样本的数据
如果您的数据是Sample级的数据,我们提供了一个可以数据预处理和组建batch的工具:Python Reader 。
- Step2: 在网络配置中定义数据层变量
用户需使用 fluid.layers.data 在网络中定义数据层变量。定义数据层变量时需指明数据层的名称name、数据类型dtype和维度shape。例如:
import paddle.fluid as fluid
image = fluid.layers.data(name='image', dtype='float32', shape=[28, 28])
label = fluid.layers.data(name='label', dtype='int64', shape=[1])
需要注意的是,此处的shape是单个样本的维度,PaddlePaddle Fluid会在shape第0维位置添加-1,表示batch_size的维度,即此例中image.shape为[-1, 28, 28], label.shape为[-1, 1]。
若用户不希望框架在第0维位置添加-1,则可通过append_batch_size=False参数控制,即:
import paddle.fluid as fluid
image = fluid.layers.data(name='image', dtype='float32', shape=[28, 28], append_batch_size=False)
label = fluid.layers.data(name='label', dtype='int64', shape=[1], append_batch_size=False)
此时,image.shape为[28, 28],label.shape为[1]。
- Step3: 将数据送入网络进行训练/预测
Fluid提供两种方式,分别是异步PyReader接口方式或同步Feed方式,具体介绍如下:
异步PyReader接口方式
用户需要先使用 fluid.io.PyReader 定义PyReader对象,然后通过PyReader对象的decorate方法设置数据源。 使用PyReader接口时,数据传入与模型训练/预测过程是异步进行的,效率较高,推荐使用。
同步Feed方式
用户自行构造输入数据,并在 fluid.Executor 或 fluid.ParallelExecutor 中使用 executor.run(feed=…) 传入训练数据。数据准备和模型训练/预测的过程是同步进行的, 效率较低。
这两种准备数据方法的比较如下:
| 对比项 | 同步Feed方式 | 异步PyReader接口方式 |
|---|---|---|
| API接口 | executor.run(feed=…) | fluid.io.PyReader |
| 数据格式 | Numpy Array或LoDTensor | Numpy Array或LoDTensor |
| 数据增强 | Python端使用其他库完成 | Python端使用其他库完成 |
| 速度 | 慢 | 快 |
| 推荐用途 | 调试模型 | 工业训练 |
数据预处理工具
在模型训练和预测阶段,PaddlePaddle程序需要读取训练或预测数据。为了帮助您编写数据读取的代码,我们提供了如下接口:
- reader: 样本级的reader,用于读取数据的函数,数据可来自于文件、网络、随机数生成器等,函数每次返回一个样本数据项。
- reader creator: 接受一个或多个reader作为参数、返回一个新reader的函数。
- reader decorator: 一个函数,接受一个或多个reader,并返回一个reader。
- batch reader: 用于读取数据的函数,数据可来自于文件、网络、随机数生成器等,函数每次返回一个batch大小的数据项。
此外,还提供了将reader转换为batch reader的函数,会频繁用到reader creator和reader decorator。
Data Reader接口
Data reader不一定要求为读取和遍历数据项的函数。它可以是返回iterable对象(即可以用于for x in iterable的任意对象)的任意不带参数的函数:
iterable = data_reader()
Iterable对象应产生单项或tuple形式的数据,而不是一个mini batch的数据。产生的数据项应在支持的类型中,例如float32,int类型的numpy一维矩阵,int类型的列表等。
以下是实现单项数据reader creator的示例:
def reader_creator_random_image(width, height):
def reader():
while True:
yield numpy.random.uniform(-1, 1, size=width*height)
return reader
以下是实现多项数据reader creator的示例:
def reader_creator_random_image_and_label(width, height, label):
def reader():
while True:
yield numpy.random.uniform(-1, 1, size=width*height), label
return reader
Batch Reader接口
Batch reader可以是返回iterable对象(即可以用于for x in iterable的任意对象)的任意不带参数的函数。Iterable的输出应为一个batch(list)的数据项。list中的每个数据项均为一个tuple元组。
这里是一些有效输出:
# 三个数据项组成一个mini batch。每个数据项有三列,每列数据项为1。
[(1, 1, 1),
(2, 2, 2),
(3, 3, 3)]
# 三个数据项组成一个mini batch。每个数据项是一个列表(单列)。
[([1,1,1],),
([2,2,2],),
([3,3,3],)]
请注意列表里的每个项必须为tuple,下面是一个无效输出:
# 错误, [1,1,1]需在一个tuple内: ([1,1,1],).
# 否则产生歧义,[1,1,1]是否表示数据[1, 1, 1]整体作为单一列。
# 或者数据的三列,每一列为1。
[[1,1,1],
[2,2,2],
[3,3,3]]
很容易将reader转换成batch reader:
mnist_train = paddle.dataset.mnist.train()
mnist_train_batch_reader = paddle.batch(mnist_train, 128)
也可以直接创建一个自定义batch reader:
def custom_batch_reader():
while True:
batch = []
for i in xrange(128):
# 注意一定需要是tuple,所以是(data,)这样的写法
batch.append((numpy.random.uniform(-1, 1, 28*28),))
yield batch
mnist_random_image_batch_reader = custom_batch_reader
使用
以下是我们如何用PaddlePaddle的reader:
batch reader是从数据项到数据层(data layer)的映射,batch_size和总pass数通过以下方式传给paddle.train:
# 创建两个数据层:
image_layer = paddle.layer.data("image", ...)
label_layer = paddle.layer.data("label", ...)
# ...
batch_reader = paddle.batch(paddle.dataset.mnist.train(), 128)
# 第二个参数告诉paddle batch_reader的样本的tuple的第一个元素(0)是image,第二个是label
# 128是batch_size,10是训练的epoch数。
paddle.train(batch_reader, {"image":0, "label":1}, 128, 10, ...)
Data Reader装饰器
Data reader decorator接收一个或多个reader对象作为参数,返回一个新的reader对象。它类似于python decorator ,但在语法上不需要写@。
我们对data reader接口有严格限制(无参数并返回单个数据项),data reader可灵活地搭配data reader decorators使用。以下是一些示例:
预取回数据(缓存数据)
由于读数据需要一些时间,而没有数据无法进行训练,因此一般而言数据预读取会是一个很好的方法。
用paddle.reader.buffered预读取数据:
buffered_reader = paddle.reader.buffered(paddle.dataset.mnist.train(), 100)
buffered_reader将尝试缓存(预读取)100个数据项。
组成多个Data Reader
例如,如果我们想用实际图像源(也就是复用mnist数据集)和随机图像源作为Generative Adversarial Networks的输入。
我们可以参照如下:
def reader_creator_random_image(width, height):
def reader():
while True:
yield numpy.random.uniform(-1, 1, size=width*height)
return reader
def reader_creator_bool(t):
def reader():
while True:
yield t
return reader
true_reader = reader_creator_bool(True)
false_reader = reader_creator_bool(False)
reader = paddle.reader.compose(paddle.dataset.mnist.train(), reader_creator_random_image(20, 20),
true_reader, false_reader)
# 跳过1因为paddle.dataset.mnist.train()为每个数据项生成两个项。
# 并且这里我们暂时不考虑第二项。
paddle.train(paddle.batch(reader, 128), {"true_image":0, "fake_image": 2, "true_label": 3, "false_label": 4}, ...)
随机排序
给定大小为n的随机排序缓存, paddle.reader.shuffle返回一个data reader ,缓存n个数据项,并在读取一个数据项前进行随机排序。
示例:
reader = paddle.reader.shuffle(paddle.dataset.mnist.train(), 512)
异步数据读取
PyReader用于进行异步数据的读取。PyReader的性能比同步数据读取更好,因为PyReader的数据读取和模型训练过程是异步进行的,且能与double_buffer_reader配合以进一步提高数据读取性能。此外,double_buffer_reader负责异步完成CPU Tensor到GPU Tensor的转换,一定程度上提升了数据读取效率。
创建PyReader对象
创建PyReader对象的方式为:
import paddle.fluid as fluid
image = fluid.layers.data(name='image', dtype='float32', shape=[784])
label = fluid.layers.data(name='label', dtype='int64', shape=[1])
ITERABLE = True
py_reader = fluid.io.PyReader(feed_list=[image, label], capacity=64,
use_double_buffer=True, iterable=ITERABLE)
其中,
- feed_list为需要输入的数据层变量列表;
- capacity为PyReader对象的缓存区大小;
- use_double_buffer默认为True,表示使用 double_buffer_reader 。建议开启,可提升数据读取速度;
- iterable默认为True,表示该PyReader对象是可For-Range迭代的。当iterable=True时,PyReader与Program解耦,定义PyReader对象不会改变Program;当iterable=False时,PyReader会在Program中插入数据读取相关的op。
需要注意的是:Program.clone()不能实现PyReader对象的复制。如果您要创建多个不同PyReader对象(例如训练和预测阶段需创建两个不同的PyReader),则需重定义两个PyReader对象。 若需要共享训练阶段和测试阶段的模型参数,您可以通过 fluid.unique_name.guard() 的方式来实现。 注:Paddle采用变量名区分不同变量,且变量名是根据 unique_name 模块中的计数器自动生成的,每生成一个变量名计数值加1。 fluid.unique_name.guard() 的作用是重置 unique_name 模块中的计数器,保证多次调用 fluid.unique_name.guard() 配置网络时对应变量的变量名相同,从而实现参数共享。
下面是一个使用PyReader配置训练阶段和测试阶段网络的例子:
import paddle
import paddle.fluid as fluid
import paddle.dataset.mnist as mnist
def network():
image = fluid.layers.data(name='image', dtype='float32', shape=[784])
label = fluid.layers.data(name='label', dtype='int64', shape=[1])
reader = fluid.io.PyReader(feed_list=[image, label], capacity=64)
# Here, we omitted the definition of loss of the model
return loss , reader
# Create main program and startup program for training
train_prog = fluid.Program()
train_startup = fluid.Program()
with fluid.program_guard(train_prog, train_startup):
# Use fluid.unique_name.guard() to share parameters with test network
with fluid.unique_name.guard():
train_loss, train_reader = network()
adam = fluid.optimizer.Adam(learning_rate=0.01)
adam.minimize(train_loss)
# Create main program and startup program for testing
test_prog = fluid.Program()
test_startup = fluid.Program()
with fluid.program_guard(test_prog, test_startup):
# Use fluid.unique_name.guard() to share parameters with train network
with fluid.unique_name.guard():
test_loss, test_reader = network()
设置PyReader对象的数据源
PyReader对象通过 decorate_sample_generator(),decorate_sample_list_generator和decorate_batch_generator()方法设置其数据源。 这三个方法均接收Python生成器generator作为参数,其区别在于:
- decorate_sample_generator()要求generator返回的数据格式为[img_1, label_1],其中img_1和label_1为单个样本的Numpy Array类型数据。
- decorate_sample_list_generator()要求generator返回的数据格式为[(img_1, label_1), (img_2, label_2), …, (img_n, label_n)],其中img_i和label_i均为每个样本的Numpy Array类型数据,n为batch size。
- decorate_batch_generator()要求generator返回的数据的数据格式为[batched_imgs, batched_labels],其中batched_imgs和batched_labels为batch级的Numpy Array或LoDTensor类型数据。
当PyReader的iterable=True(默认)时,必须给这三个方法传 places 参数, 指定将读取的数据转换为CPU Tensor还是GPU Tensor。当PyReader的iterable=False时,不需传places参数。
例如,假设我们有两个reader,其中fake_sample_reader每次返回一个sample的数据,fake_batch_reader每次返回一个batch的数据。
import paddle.fluid as fluid
import numpy as np
# sample级reader
def fake_sample_reader():
for _ in range(100):
sample_image = np.random.random(size=(784, )).astype('float32')
sample_label = np.random.random_integers(size=(1, ), low=0, high=9).astype('int64')
yield sample_image, sample_label
# batch级reader
def fake_batch_reader():
batch_size = 32
for _ in range(100):
batch_image = np.random.random(size=(batch_size, 784)).astype('float32')
batch_label = np.random.random_integers(size=(batch_size, 1), low=0, high=9).astype('int64')
yield batch_image, batch_label
image1 = fluid.layers.data(name='image1', dtype='float32', shape=[784])
label1 = fluid.layers.data(name='label1', dtype='int64', shape=[1])
image2 = fluid.layers.data(name='image2', dtype='float32', shape=[784])
label2 = fluid.layers.data(name='label2', dtype='int64', shape=[1])
image3 = fluid.layers.data(name='image3', dtype='float32', shape=[784])
label3 = fluid.layers.data(name='label3', dtype='int64', shape=[1])
对应的PyReader设置如下:
import paddle
import paddle.fluid as fluid
ITERABLE = True
USE_CUDA = True
USE_DATA_PARALLEL = True
if ITERABLE:
# 若PyReader可迭代,则必须设置places参数
if USE_DATA_PARALLEL:
# 若进行多GPU卡训练,则取所有的CUDAPlace
# 若进行多CPU核训练,则取多个CPUPlace,本例中取了8个CPUPlace
places = fluid.cuda_places() if USE_CUDA else fluid.cpu_places(8)
else:
# 若进行单GPU卡训练,则取单个CUDAPlace,本例中0代表0号GPU卡
# 若进行单CPU核训练,则取单个CPUPlace,本例中1代表1个CPUPlace
places = fluid.cuda_places(0) if USE_CUDA else fluid.cpu_places(1)
else:
# 若PyReader不可迭代,则不需要设置places参数
places = None
# 使用sample级的reader作为PyReader的数据源
py_reader1 = fluid.io.PyReader(feed_list=[image1, label1], capacity=10, iterable=ITERABLE)
py_reader1.decorate_sample_generator(fake_sample_reader, batch_size=32, places=places)
# 使用sample级的reader + paddle.batch设置PyReader的数据源
py_reader2 = fluid.io.PyReader(feed_list=[image2, label2], capacity=10, iterable=ITERABLE)
sample_list_reader = paddle.batch(fake_sample_reader, batch_size=32)
sample_list_reader = paddle.reader.shuffle(sample_list_reader, buf_size=64) # 还可以进行适当的shuffle
py_reader2.decorate_sample_list_generator(sample_list_reader, places=places)
# 使用batch级的reader作为PyReader的数据源
py_reader3 = fluid.io.PyReader(feed_list=[image3, label3], capacity=10, iterable=ITERABLE)
py_reader3.decorate_batch_generator(fake_batch_reader, places=places)
使用PyReader进行模型训练和测试
使用PyReader进行模型训练和测试的例程如下。
- 第一步,我们需组建训练网络和预测网络,并定义相应的PyReader对象,设置好PyReader对象的数据源。
import paddle
import paddle.fluid as fluid
import paddle.dataset.mnist as mnist
import six
ITERABLE = True
def network():
# 创建数据层对象
image = fluid.layers.data(name='image', dtype='float32', shape=[784])
label = fluid.layers.data(name='label', dtype='int64', shape=[1])
# 创建PyReader对象
reader = fluid.io.PyReader(feed_list=[image, label], capacity=64, iterable=ITERABLE)
# Here, we omitted the definition of loss of the model
return loss , reader
# 创建训练的main_program和startup_program
train_prog = fluid.Program()
train_startup = fluid.Program()
# 定义训练网络
with fluid.program_guard(train_prog, train_startup):
# fluid.unique_name.guard() to share parameters with test network
with fluid.unique_name.guard():
train_loss, train_reader = network()
adam = fluid.optimizer.Adam(learning_rate=0.01)
adam.minimize(train_loss)
# 创建预测的main_program和startup_program
test_prog = fluid.Program()
test_startup = fluid.Program()
# 定义预测网络
with fluid.program_guard(test_prog, test_startup):
# Use fluid.unique_name.guard() to share parameters with train network
with fluid.unique_name.guard():
test_loss, test_reader = network()
place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
# 运行startup_program进行初始化
exe.run(train_startup)
exe.run(test_startup)
# Compile programs
train_prog = fluid.CompiledProgram(train_prog).with_data_parallel(loss_name=train_loss.name)
test_prog = fluid.CompiledProgram(test_prog).with_data_parallel(share_vars_from=train_prog)
# 设置PyReader的数据源
places = fluid.cuda_places() if ITERABLE else None
train_reader.decorate_sample_list_generator(
paddle.reader.shuffle(paddle.batch(mnist.train(), 512), buf_size=1024), places=places)
test_reader.decorate_sample_list_generator(paddle.batch(mnist.test(), 512), places=places)
- 第二步:根据PyReader对象是否iterable,选用不同的方式运行网络。
若iterable=True,则PyReader对象是一个Python的生成器,可直接for-range迭代。for-range返回的结果通过exe.run的feed参数传入执行器。
def run_iterable(program, exe, loss, py_reader):
for data in py_reader():
loss_value = exe.run(program=program, feed=data, fetch_list=[loss])
print('loss is {}'.format(loss_value))
for epoch_id in six.moves.range(10):
run_iterable(train_prog, exe, train_loss, train_reader)
run_iterable(test_prog, exe, test_loss, test_reader)
若iterable=False,则需在每个epoch开始前,调用 start() 方法启动PyReader对象;并在每个epoch结束时,exe.run会抛出 fluid.core.EOFException 异常,在捕获异常后调用 reset() 方法重置PyReader对象的状态, 以便启动下一轮的epoch。iterable=False时无需给exe.run传入feed参数。具体方式为:
def run_non_iterable(program, exe, loss, py_reader):
py_reader.start()
try:
while True:
loss_value = exe.run(program=program, fetch_list=[loss])
print('loss is {}'.format(loss_value))
except fluid.core.EOFException:
print('End of epoch')
py_reader.reset()
for epoch_id in six.moves.range(10):
run_non_iterable(train_prog, exe, train_loss, train_reader)
run_non_iterable(test_prog, exe, test_loss, test_reader)
同步数据读取
PaddlePaddle Fluid支持使用 fluid.layers.data()配置数据层;再使用Numpy Array或者直接使用Python创建C++的 fluid.LoDTensor,通过Executor.run(feed=…)传给fluid.Executor或fluid.ParallelExecutor。
数据层配置
通过fluid.layers.data()可以配置神经网络中需要的数据层。具体方法为:
import paddle.fluid as fluid
image = fluid.layers.data(name="image", shape=[3, 224, 224])
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
# use image/label as layer input
prediction = fluid.layers.fc(input=image, size=1000, act="softmax")
loss = fluid.layers.cross_entropy(input=prediction, label=label)
...
上段代码中,image和label是通过fluid.layers.data创建的两个输入数据层。其中image是[3, 224, 224]维度的浮点数据;label是[1]维度的整数数据。这里需要注意的是:
Fluid中默认使用-1表示batch size维度,默认情况下会在shape的第一个维度添加-1。所以上段代码中,我们可以接受将一个[32, 3, 224, 224]的numpy array传给image。如果想自定义batch size维度的位置的话,请设置fluid.layers.data(append_batch_size=False)。请参考进阶使用中的自定义BatchSize维度。
Fluid中用来做类别标签的数据类型是int64,并且标签从0开始。可用数据类型请参考下面的Fluid目前支持的数据类型。
传递训练数据给执行器
Executor.run和ParallelExecutor.run都接受一个feed参数。这个参数是一个Python的字典。它的键是数据层的名字,例如上文代码中的image。它的值是对应的numpy array。
例如:
exe = fluid.Executor(fluid.CPUPlace())
# init Program
exe.run(fluid.default_startup_program())
exe.run(feed={
"image": numpy.random.random(size=(32, 3, 224, 224)).astype('float32'),
"label": numpy.random.random(size=(32, 1)).astype('int64')
})
进阶使用
如何传入序列数据
序列数据是PaddlePaddle Fluid支持的特殊数据类型,可以使用LoDTensor作为输入数据类型。它需要用户: 1. 传入一个mini-batch需要被训练的所有数据; 2.每个序列的长度信息。用户可以使用fluid.create_lod_tensor来创建LoDTensor。
传入序列信息的时候,需要设置序列嵌套深度,lod_level。例如训练数据是词汇组成的句子,lod_level=1;训练数据是词汇先组成了句子, 句子再组成了段落,那么lod_level=2。
例如:
sentence = fluid.layers.data(name="sentence", dtype="int64", shape=[1], lod_level=1)
...
exe.run(feed={
"sentence": create_lod_tensor(
data=numpy.array([1, 3, 4, 5, 3, 6, 8], dtype='int64').reshape(-1, 1),
recursive_seq_lens=[[4, 1, 2]],
place=fluid.CPUPlace()
)
})
训练数据sentence包含三个样本,他们的长度分别是4, 1, 2。他们分别是data[0:4],data[4:5]和data[5:7]。
如何分别设置ParallelExecutor中每个设备的训练数据
用户将数据传递给使用ParallelExecutor.run(feed=…)时,可以显式指定每一个训练设备(例如GPU)上的数据。用户需要将一个列表传递给 feed参数,列表中的每一个元素都是一个字典。这个字典的键是数据层的名字,值是数据层的值。
例如:
parallel_executor = fluid.ParallelExecutor()
parallel_executor.run(
feed=[
{
"image": numpy.random.random(size=(32, 3, 224, 224)).astype('float32'),
"label": numpy.random.random(size=(32, 1)).astype('int64')
},
{
"image": numpy.random.random(size=(16, 3, 224, 224)).astype('float32'),
"label": numpy.random.random(size=(16, 1)).astype('int64')
},
]
)
上述代码中,GPU0会训练32个样本,而GPU1训练16个样本。
自定义BatchSize维度
PaddlePaddle Fluid默认batch size是数据的第一维度,以-1表示。但是在高级使用中,batch_size可以固定,也可以是其他维度或者多个维度来表示。这都需要设置fluid.layers.data(append_batch_size=False)来完成。
- 固定batch size维度
image = fluid.layers.data(name="image", shape=[32, 784], append_batch_size=False)
这里,image永远是一个[32, 784]大小的矩阵。
- 使用其他维度表示batch size
sentence = fluid.layers.data(name="sentence",
shape=[80, -1, 1],
append_batch_size=False,
dtype="int64")
这里sentence的中间维度是batch size。这种数据排布会用在定长的循环神经网络中。
- Fluid目前支持的数据类型
PaddlePaddle Fluid目前支持的数据类型包括:
- float16: 部分操作支持
- float32: 主要实数类型
- float64: 次要实数类型,支持大部分操作
- int32: 次要标签类型
- int64: 主要标签类型
- uint64: 次要标签类型
- bool: 控制流数据类型
- int16: 次要标签类型
- uint8: 输入数据类型,可用于图像像素
配置简单的网络
在解决实际问题时,可以先从逻辑层面对问题进行建模,明确模型所需要的输入数据类型、计算逻辑、求解目标以及优化算法。PaddlePaddle提供了丰富的算子来实现模型逻辑。下面以一个简单回归任务举例说明如何使用PaddlePaddle构建模型。该例子完整代码参见fit_a_line。
问题描述及定义
问题描述: 给定一组数据$<X,Y>$,求解出函数$f$,使得$y=f(x)$,其中 $x \subset X$ 表示一条样本的特征,为13维的实数向量;$y \subset Y$为一实数表示该样本对应的值。
我们可以尝试用回归模型来对问题建模,回归问题的损失函数有很多,这里选择常用的均方误差。为简化问题,这里假定$f$为简单的线性变换函数,同时选用随机梯度下降算法来求解模型。
使用PaddlePaddle建模
从逻辑层面明确了输入数据格式、模型结构、损失函数以及优化算法后,需要使用PaddlePaddle提供的API及算子来实现模型逻辑。一个典型的模型主要包含4个部分,分别是:输入数据格式定义,模型前向计算逻辑,损失函数以及优化算法。
数据层
PaddlePaddle提供了fluid.layers.data()算子来描述输入数据的格式。
fluid.layers.data() 算子的输出是一个Variable。这个Variable的实际类型是Tensor。Tensor具有强大的表征能力,可以表示多维数据。为了精确描述数据结构,通常需要指定数据shape以及数值类型type。其中shape为一个整数向量,type可以是一个字符串类型。目前支持的数据类型参考 Fluid目前支持的数据类型 。 模型训练一般会使用batch的方式读取数据,而batch的size在训练过程中可能不固定。data算子会依据实际数据来推断batch size,所以这里提供shape时不用关心batch size,只需关心一条样本的shape即可,更高级用法请参考 自定义BatchSize维度。从上知,x为13维的实数向量,y为实数,可使用下面代码定义数据层:
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
该模型使用的数据比较简单,事实上data算子还可以描述变长的、嵌套的序列数据。也可以使用 open_files 打开文件进行训练。更详细的文档可参照 准备数据。
前向计算逻辑
实现一个模型最重要的部分是实现计算逻辑,PaddlePaddle提供了丰富的算子。这些算子的封装粒度不同,通常对应一种或一组变换逻辑。算子输出即为对输入数据执行变换后的结果。用户可以灵活使用算子来完成复杂的模型逻辑。比如图像相关任务中会使用较多的卷积算子、序列任务中会使用LSTM/GRU等算子。复杂模型通常会组合多种算子,以完成复杂的变换。PaddlePaddle提供了非常自然的方式来组合算子,一般地可以使用下面的方式:
op_1_out = fluid.layers.op_1(input=op_1_in, ...)
op_2_out = fluid.layers.op_2(input=op_1_out, ...)
...
其中op_1和op_2表示算子类型,可以是fc来执行线性变换(全连接),也可以是conv来执行卷积变换等。通过算子的输入输出的连接来定义算子的计算顺序以及数据流方向。上面的例子中,op_1的输出是op_2的输入,那么在执行计算时,会先计算op_1,然后计算op_2。更复杂的模型可能需要使用控制流算子,依据输入数据来动态执行,针对这种情况,PaddlePaddle提供了IfElseOp和WhileOp等。算子的文档可参考 fluid.layers。具体到这个任务, 我们使用一个fc算子:
y_predict = fluid.layers.fc(input=x, size=1, act=None)
损失函数
损失函数对应求解目标,我们可以通过最小化损失来求解模型。大多数模型使用的损失函数,输出是一个实数值。但是PaddlePaddle提供的损失算子一般是针对一条样本计算。当输入一个batch的数据时,损失算子的输出有多个值,每个值对应一条样本的损失,所以通常会在损失算子后面使用mean等算子,来对损失做归约。模型在一次前向迭代后会得到一个损失值,PaddlePaddle会自动执行链式求导法则计算模型里面每个参数和变量对应的梯度值。这里使用均方误差损失:
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_cost = fluid.layers.mean(cost)
优化方法
确定损失函数后,可以通过前向计算得到损失值,然后通过链式求导法则得到参数的梯度值。获取梯度值后需要更新参数,最简单的算法是随机梯度下降法:$w=w - \eta \cdot g$。但是普通的随机梯度下降算法存在一些问题: 比如收敛不稳定等。为了改善模型的训练速度以及效果,学术界先后提出了很多优化算法,包括: Momentum、RMSProp、Adam 等。这些优化算法采用不同的策略来更新模型参数,一般可以针对具体任务和具体模型来选择优化算法。不管使用何种优化算法,学习率一般是一个需要指定的比较重要的超参数,需要通过实验仔细调整。这里采用随机梯度下降算法:
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
更多优化算子可以参考fluid.optimizer()。
训练神经网络
单机训练
准备工作
要进行PaddlePaddle Fluid单机训练,需要先准备数据和配置简单的网络。当配置简单的网络完毕后,可以得到两个fluid.Program,startup_program和main_program。默认情况下,可以使用 fluid.default_startup_program()与fluid.default_main_program()获得全局的fluid.Program。
例如:
import paddle.fluid as fluid
image = fluid.layers.data(name="image", shape=[784])
label = fluid.layers.data(name="label", shape=[1])
hidden = fluid.layers.fc(input=image, size=100, act='relu')
prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
loss = fluid.layers.cross_entropy(input=prediction, label=label)
loss = fluid.layers.mean(loss)
sgd = fluid.optimizer.SGD(learning_rate=0.001)
sgd.minimize(loss)
# Here the fluid.default_startup_program() and fluid.default_main_program()
# has been constructed.
在上述模型配置执行完毕后,fluid.default_startup_program()与fluid.default_main_program()配置完毕了。
初始化参数
参数随机初始化
用户配置完模型后,参数初始化操作会被写入到fluid.default_startup_program()中。使用fluid.Executor()运行这一程序,初始化之后的参数默认被放在全局scope中,即fluid.global_scope()。例如:
exe = fluid.Executor(fluid.CUDAPlace(0))
exe.run(program=fluid.default_startup_program())
载入预定义参数
在神经网络训练过程中,经常会需要载入预定义模型,进而继续进行训练。如何载入预定义参数,请参考模型/变量的保存、载入与增量训练。
单卡训练
执行单卡训练可以使用 fluid.Executor()中的run()方法,运行训练fluid.Program即可。在运行的时候,用户可以通过run(feed=…)参数传入数据;用户可以通过run(fetch=…)获取持久的数据。例如:
import paddle.fluid as fluid
import numpy
train_program = fluid.Program()
startup_program = fluid.Program()
with fluid.program_guard(train_program, startup_program):
data = fluid.layers.data(name='X', shape=[1], dtype='float32')
hidden = fluid.layers.fc(input=data, size=10)
loss = fluid.layers.mean(hidden)
sgd = fluid.optimizer.SGD(learning_rate=0.001)
sgd.minimize(loss)
use_cuda = True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
# Run the startup program once and only once.
# Not need to optimize/compile the startup program.
startup_program.random_seed=1
exe.run(startup_program)
# Run the main program directly without compile.
x = numpy.random.random(size=(10, 1)).astype('float32')
loss_data, = exe.run(train_program,
feed={"X": x},
fetch_list=[loss.name])
# Or use CompiledProgram:
compiled_prog = compiler.CompiledProgram(train_program)
loss_data, = exe.run(compiled_prog,
feed={"X": x},
fetch_list=[loss.name])
多卡训练
在多卡训练中,你可以使用 fluid.compiler.CompiledProgram来编译fluid.Program,然后调用with_data_parallel。例如:
# NOTE: If you use CPU to run the program, you need
# to specify the CPU_NUM, otherwise, fluid will use
# all the number of the logic cores as the CPU_NUM,
# in that case, the batch size of the input should be
# greater than CPU_NUM, if not, the process will be
# failed by an exception.
if not use_cuda:
os.environ['CPU_NUM'] = str(2)
compiled_prog = compiler.CompiledProgram(
train_program).with_data_parallel(
loss_name=loss.name)
loss_data, = exe.run(compiled_prog,
feed={"X": x},
fetch_list=[loss.name])
注释:
- CompiledProgram会将传入的fluid.Program转为计算图,即Graph,因为compiled_prog与传入的train_program是完全不同的对象,目前还不能够对compiled_prog 进行保存。
- 多卡训练也可以使用 ParallelExecutor,但是现在推荐使用CompiledProgram
- 如果exe是用CUDAPlace来初始化的,模型会在GPU中运行。在显卡训练模式中,所有的显卡都将被占用。用户可以配置CUDA_VISIBLE_DEVICES 以更改被占用的显卡。
- 如果exe 是用CPUPlace来初始化的,模型会在CPU中运行。在这种情况下,多线程用于运行模型,同时线程的数目和逻辑核的数目相等。用户可以配置CPU_NUM以更改使用中的线程数目。
训练过程中评测模型
模型的测试评价与训练的 fluid.Program 不同。在测试评价中:
- 测试评价不进行反向传播,不优化更新参数。
-
测试评价执行的操作可以不同。
- 例如 BatchNorm 操作,在训练和测试时执行不同的算法。
- 测试评价模型与训练模型可以是完全不同的模型。
生成测试 fluid.Program
- 通过克隆训练fluid.Program生成测试fluid.Program
用Program.clone() 方法可以复制出新的fluid.Program。通过设置Program.clone(for_test=True)复制含有用于测试的操作 fluid.Program。简单的使用方法如下:
import paddle.fluid as fluid
img = fluid.layers.data(name="image", shape=[784])
prediction = fluid.layers.fc(
input=fluid.layers.fc(input=img, size=100, act='relu'),
size=10,
act='softmax'
)
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
loss = fluid.layers.mean(fluid.layers.cross_entropy(input=prediction, label=label))
acc = fluid.layers.accuracy(input=prediction, label=label)
test_program = fluid.default_main_program().clone(for_test=True)
adam = fluid.optimizer.Adam(learning_rate=0.001)
adam.minimize(loss)
注意上面的代码,我们通常在optimizer之前(或者更早的在定义预测结果后定义loss之前)clone测试Program,因为测试的时候不需要反向计算更新参数。
在使用Optimizer之前,将fluid.default_main_program()复制成一个 test_program 。之后使用测试数据运行 test_program,就可以做到运行测试程序,而不影响训练结果。
- 分别配置训练fluid.Program和测试fluid.Program
如果训练程序和测试程序相差较大时,用户也可以通过完全定义两个不同的fluid.Program,分别进行训练和测试。在PaddlePaddle Fluid中,所有的参数都有名字。如果两个不同的操作,甚至两个不同的网络使用了同样名字的参数,那么他们的值和内存空间都是共享的。
PaddlePaddle Fluid中使用fluid.unique_name 包来随机初始化用户未定义的参数名称。通过fluid.unique_name.guard可以确保多次调用某函数参数初始化的名称一致。
例如:
import paddle.fluid as fluid
def network(is_test):
file_obj = fluid.layers.open_files(filenames=["test.recordio"] if is_test else ["train.recordio"], ...)
img, label = fluid.layers.read_file(file_obj)
hidden = fluid.layers.fc(input=img, size=100, act="relu")
hidden = fluid.layers.batch_norm(input=hidden, is_test=is_test)
...
return loss
with fluid.unique_name.guard():
train_loss = network(is_test=False)
sgd = fluid.optimizer.SGD(0.001)
sgd.minimize(train_loss)
test_program = fluid.Program()
with fluid.unique_name.guard():
with fluid.program_gurad(test_program, fluid.Program()):
test_loss = network(is_test=True)
# fluid.default_main_program() is the train program
# fluid.test_program is the test program
执行测试fluid.Program
- 使用 Executor执行测试fluid.Program
用户可以使用 Executor.run(program=…) 来执行测试 fluid.Program。
例如
exe = fluid.Executor(fluid.CPUPlace())
test_acc = exe.run(program=test_program, feed=test_data_batch, fetch_list=[acc])
print 'Test accuracy is ', test_acc
- 使用ParallelExecutor执行测试fluid.Program
用户可以使用训练用的ParallelExecutor与测试fluid.Program一起,新建一个测试的ParallelExecutor;再使用测试ParallelExecutor.run来执行测试。
例如:
train_exec = fluid.ParallelExecutor(use_cuda=True, loss_name=loss.name)
test_exec = fluid.ParallelExecutor(use_cuda=True, share_vars_from=train_exec,
main_program=test_program)
test_acc = test_exec.run(fetch_list=[acc], ...)
分布式训练快速开始
准备工作
在本篇文章中,我们将会在介绍如何快速在一个集群中启动一个PaddlePaddle的分布式训练任务,在开始之前,请按如下步骤做些准备工作:
- 准备一个网络连通的训练集群,在本文中我们使用4个训练节点使用 *.paddlepaddle.com 来表示节点的主机名称,您可以根据实际情况修改它。
- 在开始之前确保已经阅读过 install_steps 并且可以在集群的所有节点上可以正常运行 PaddlePaddle。
样例代码
下面使用一个非常简单的线性回归模型作为样例来解释如何启动一个包含2个PSERVER节点以及2个TRAINER节点的分布式训练任务,您可以将本段代码保存为 dist_train.py 运行。
import os
import paddle
import paddle.fluid as fluid
# train reader
BATCH_SIZE = 20
EPOCH_NUM = 30
BATCH_SIZE = 8
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
batch_size=BATCH_SIZE)
def train():
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
loss = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_loss = fluid.layers.mean(loss)
opt = fluid.optimizer.SGD(learning_rate=0.001)
opt.minimize(avg_loss)
place = fluid.CPUPlace()
feeder = fluid.DataFeeder(place=place, feed_list=[x, y])
exe = fluid.Executor(place)
# fetch distributed training environment setting
training_role = os.getenv("PADDLE_TRAINING_ROLE", None)
port = os.getenv("PADDLE_PSERVER_PORT", "6174")
pserver_ips = os.getenv("PADDLE_PSERVER_IPS", "")
trainer_id = int(os.getenv("PADDLE_TRAINER_ID", "0"))
eplist = []
for ip in pserver_ips.split(","):
eplist.append(':'.join([ip, port]))
pserver_endpoints = ",".join(eplist)
trainers = int(os.getenv("PADDLE_TRAINERS"))
current_endpoint = os.getenv("PADDLE_CURRENT_IP", "") + ":" + port
t = fluid.DistributeTranspiler()
t.transpile(
trainer_id = trainer_id,
pservers = pserver_endpoints,
trainers = trainers)
if training_role == "PSERVER":
pserver_prog = t.get_pserver_program(current_endpoint)
startup_prog = t.get_startup_program(current_endpoint, pserver_prog)
exe.run(startup_prog)
exe.run(pserver_prog)
elif training_role == "TRAINER":
trainer_prog = t.get_trainer_program()
exe.run(fluid.default_startup_program())
for epoch in range(EPOCH_NUM):
for batch_id, batch_data in enumerate(train_reader()):
avg_loss_value, = exe.run(trainer_prog,
feed=feeder.feed(batch_data),
fetch_list=[avg_loss])
if (batch_id + 1) % 10 == 0:
print("Epoch: {0}, Batch: {1}, loss: {2}".format(
epoch, batch_id, avg_loss_value[0]))
# destory the resource of current trainer node in pserver server node
exe.close()
else:
raise AssertionError("PADDLE_TRAINING_ROLE should be one of [TRAINER, PSERVER]")
train()
环境变量说明
在启动分布式训练任务时,使用不同的环境变量来表示不同的节点角色,具体如下:
| 环境变量 | 数据类型 | 样例 | 描述 |
|---|---|---|---|
| PADDLE_TRAINING_ROLE | str | PSERVER,TRAINER | 当前训练节点角色 |
| PADDLE_PSERVER_IPS | str | ps0.paddlepaddle.com,ps1.paddlepaddle.com | 分布式训练任务中所有 PSERVER 节点的 IP 地址或 hostname, 使用”,”分隔 |
| PADDLE_PSERVER_PORT | int | 6174 | PSERVER 进程监听的端口 |
| PADDLE_TRAINERS | int | 2 | 分布式训练任务中 trainer 节点的数量 |
| PADDLE_CURRENT_IP | str | ps0.paddlepaddle.com | 当前 PSERVER 节点的 IP 地址或 hostname |
| PADDLE_TRAINER_ID | str | 0 | 当前 TRAINER 节点的 ID (唯一), 取值范围为 [0, PADDLE_TRAINERS) |
注: 环境变量只是获取运行时信息的一种方式,实际任务中可以采用命令行参数等方式获取运行时信息。
分布式训练相关 API
DistributeTranspiler
基于 pserver-trainer 架构的的分布式训练任务分为两种角色:Parameter Server(PSERVER)以及TRAINER, 在Fluid中,用户只需配置单机训练所需要的网络配置, DistributeTranspiler 模块会自动地根据 当前训练节点的角色将用户配置的单机网路配置改写成PSERVER和TRAINER需要运行的网络配置:
t = fluid.DistributeTranspiler()
t.transpile(
trainer_id = trainer_id,
pservers = pserver_endpoints,
trainers = trainers)
if PADDLE_TRAINING_ROLE == "TRAINER":
# fetch the trainer program and execute it
trainer_prog = t.get_trainer_program()
...
elif PADDLE_TRAINER_ROLE == "PSERVER":
# fetch the pserver program and execute it
pserver_prog = t.get_pserver_program(current_endpoint)
...
exe.close()
PSERVER节点中会保存所有TRAINER节点的状态信息,在TRAINER结束训练时需要调用exe.close()通知所有PSERVER节点释放当前TRAINER节点的资源:
exe = fluid.Executor(fluid.CPUPlace())
# training process ...
exe.close() # notify PServer to destory the resource
注意:所有的trainer在退出时都需要调用exe.close()。
启动分布式训练任务
| 启动节点 | 启动命令 | 说明 |
|---|---|---|
| ps0.paddlepaddle.com | PADDLE_TRAINING_ROLE=PSERVER PADDLE_CURRENT_IP=ps0.paddlepaddle.com PADDLE_PSERVER_IPS=ps0.paddlepaddle.com,ps1.paddlepaddle.com PADDLE_TRAINERS=2 PADDLE_PSERVER_PORT=6174 python fluid_dist.py | 启动 PSERVER 节点 |
| ps1.paddlepaddle.com | PADDLE_TRAINING_ROLE=PSERVER PADDLE_CURRENT_IP=ps1.paddlepaddle.com PADDLE_PSERVER_IPS=ps0.paddlepaddle.com,ps1.paddlepaddle.com PADDLE_TRAINERS=2 PADDLE_PSERVER_PORT=6174 python fluid_dist.py | 启动 PSERVER 节点 |
| trainer0.paddlepaddle.com | PADDLE_TRAINING_ROLE=TRAINER PADDLE_PSERVER_IPS=ps0.paddlepaddle.com,ps1.paddlepaddle.com PADDLE_TRAINERS=2 PADDLE_TRAINER_ID=0 PADDLE_PSERVER_PORT=6174 python fluid_dist.py | 启动第0号 TRAINER 节点 |
| trainer1.paddlepaddle.com | PADDLE_TRAINING_ROLE=TRAINER PADDLE_PSERVER_IPS=ps0.paddlepaddle.com,ps1.paddlepaddle.com PADDLE_TRAINERS=2 PADDLE_TRAINER_ID=1 PADDLE_PSERVER_PORT=6174 python fluid_dist.py | 启动第1号 TRAINER 节点 |
分布式训练使用手册
分布式训练基本思想
分布式深度学习训练通常分为两种并行化方法:数据并行,模型并行,参考下图:
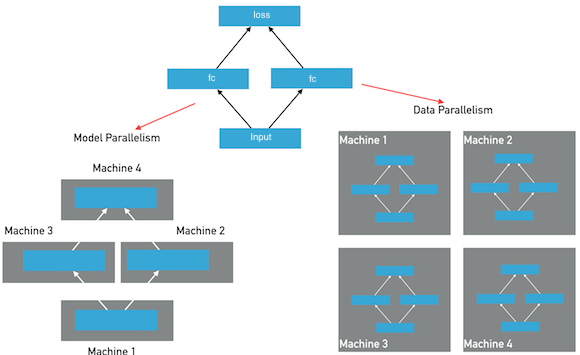 图:数据并行和模型并行
图:数据并行和模型并行
在模型并行方式下,模型的层和参数将被分布在多个节点上,模型在一个mini-batch的前向和反向训练中,将经过多次跨节点之间的通信。每个节点只保存整个模型的一部分;在数据并行方式下,每个节点保存有完整的模型的层和参数,每个节点独自完成前向和反向计算,然后完成梯度的聚合并同步的更新所有节点上的参数。Fluid目前版本仅提供数据并行方式,另外诸如模型并行的特例实现(超大稀疏模型训练)功能将在后续的文档中予以说明。
在数据并行模式的训练中,Fluid使用了两种通信模式,用于应对不同训练任务对分布式训练的要求,分别为RPC通信和Collective通信。其中RPC通信方式使用gRPC,Collective通信方式使用NCCL2。
这两种方式的核心区别就是:RPC是把数据放到特定的Parameter Server(pserver)上,所有的训练节点和pserver通信;而Collective方式没有pserver,所有的训练节点之间直接进行数据交互(类似MPI的方式)。
RPC通信和Collective通信的横向对比如下:
| Feature | Collective | RPC |
|---|---|---|
| Ring-Based通信 | Yes | No |
| 异步训练 | Yes | Yes |
| 分布式模型 | No | Yes |
| 容错训练 | No | Yes |
| 性能 | Faster | Fast |
RPC通信方式的结构:
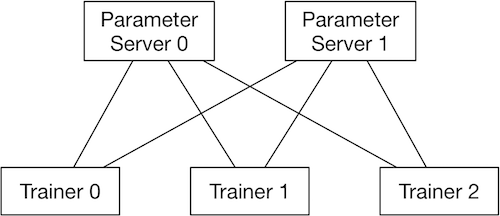
使用RPC通信方式的数据并行分布式训练,会启动多个pserver进程和多个trainer进程,每个pserver进程会保存一部分模型参数,并负责接收从trainer发送的梯度并更新这些模型参数;每个trainer进程会保存一份完整的模型,并使用一部分数据进行训练,然后向pserver发送梯度,最后从pserver拉取更新后的参数。
pserver进程可以在和trainer完全不同的计算节点上,也可以和trainer公用节点。一个分布式任务所需要的pserver进程个数通常需要根据实际情况调整,以达到最佳的性能,然而通常来说pserver的进程不会比trainer更多。
注: 在使用GPU训练时,pserver可以选择使用GPU或只使用CPU,如果pserver也使用GPU,则会增加一次从CPU拷贝接收到的梯度数据到GPU的开销,在某些情况下会导致整体训练性能降低。
注: 在使用GPU训练时,如果每个trainer节点有多个GPU卡,则会先在每个trainer节点的多个卡之间执行NCCL2通信方式的梯度聚合,然后再通过pserver聚合多个节点的梯度。
NCCL2通信方式的结构:
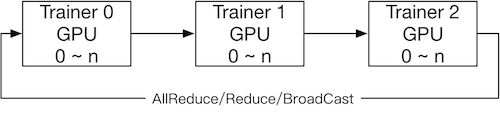
使用NCCL2(Collective通信方式)进行分布式训练,是不需要启动pserver进程的,每个trainer进程都保存一份完整的模型参数,在完成计算梯度之后通过trainer之间的相互通信,Reduce梯度数据到所有节点的所有设备然后每个节点在各自完成参数更新。
使用parameter server方式的训练
使用transpiler API可以把单机可以执行的程序快速转变成可以分布式执行的程序。在不同的服务器节点上,通过传给transpiler对应的参数,以获取当前节点需要执行的Program。
配置参数
| 参数 | 说明 |
|---|---|
| role | 必选区分作为pserver启动还是trainer启动,不传给transpile,也可以用其他的变量名或环境变量 |
| trainer_id | 必选如果是trainer进程,用于指定当前trainer在任务中的唯一id,从0开始,在一个任务中需保证不重复 |
| pservers | 必选当前任务所有pserver的ip:port列表字符串,形式比如:127.0.0.1:6170,127.0.0.1:6171 |
| trainers | 必选trainer节点的个数 |
| sync_mode | 可选True为同步模式,False为异步模式 |
| startup_program | 可选如果startup_program不是默认的fluid.default_startup_program(),需要传入此参数 |
| current_endpoint | 可选只有NCCL2模式需要传这个参数 |
一个例子,假设有两个节点,分别是192.168.1.1和192.168.1.2,使用端口6170,启动4个trainer,则代码可以写成:
role = "PSERVER"
trainer_id = 0 # get actual trainer id from cluster
pserver_endpoints = "192.168.1.1:6170,192.168.1.2:6170"
current_endpoint = "192.168.1.1:6170" # get actual current endpoint
trainers = 4
t = fluid.DistributeTranspiler()
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers)
if role == "PSERVER":
pserver_prog = t.get_pserver_program(current_endpoint)
pserver_startup = t.get_startup_program(current_endpoint,
pserver_prog)
exe.run(pserver_startup)
exe.run(pserver_prog)
elif role == "TRAINER":
train_loop(t.get_trainer_program())
选择同步或异步训练
Fluid分布式任务可以支持同步训练或异步训练,在同步训练方式下,所有的trainer节点,会在每个mini-batch 同步地合并所有节点的梯度数据并发送给parameter server完成更新,在异步训练方式下,每个trainer没有相互同步等待的过程,可以独立地更新parameter server的参数。通常情况下,使用异步训练方式,可以在trainer节点更多的时候比同步训练方式有更高的总体吞吐量。
在调用 transpile 函数时,默认会生成同步训练的分布式程序,通过指定sync_mode=False参数即可生成异步训练的程序:
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers, sync_mode=False)
选择是否使用分布式embedding表进行训练
embedding被广泛应用在各种网络结构中,尤其是文本处理相关的模型。在某些场景,例如推荐系统或者搜索引擎中,embedding的feature id可能会非常多,当feature id达到一定数量时,embedding参数会变得很大,一方面可能单机内存无法存放导致无法训练,另一方面普通的训练模式每一轮迭代都需要同步完整的参数,参数太大会让通信变得非常慢,进而影响训练速度。
Fluid支持千亿量级超大规模稀疏特征embedding的训练,embedding参数只会保存在parameter server上,通过参数prefetch和梯度稀疏更新的方法,大大减少通信量,提高通信速度。
该功能只对分布式训练有效,单机无法使用。需要配合稀疏更新一起使用。
使用方法,在配置embedding的时候,加上参数is_distributed=True以及is_sparse=True即可。 参数dict_size定义数据中总的id的数量,id可以是int64范围内的任意值,只要总id个数小于等于dict_size就可以支持。 所以配置之前需要预估一下数据中总的feature id的数量。
emb = fluid.layers.embedding(
is_distributed=True,
input=input,
size=[dict_size, embedding_width],
is_sparse=True)
选择参数分布方法
参数split_method可以指定参数在parameter server上的分布方式。
Fluid默认使用RoundRobin方式将参数分布在多个parameter server上。此方式在默认未关闭参数切分的情况下,参数会较平均的分布在所有的 parameter server上。如果需要使用其他,可以传入其他的方法,目前可选的方法有:RoundRobin和HashName。也可以使用自定义的分布方式,只需要参考这里编写自定义的分布函数。
关闭切分参数
参数 slice_var_up 指定是否将较大(大于8192个元素)的参数切分到多个parameter server以均衡计算负载,默认为开启。
当模型中的可训练参数体积比较均匀或者使用自定义的参数分布方法是参数均匀分布在多个parameter server上,可以选择关闭切分参数,这样可以降低切分和重组带来的计算和拷贝开销:
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers, slice_var_up=False)
开启内存优化
在parameter server分布式训练模式下,要开启内存优化memory_optimize和单机相比,需要注意按照下面的规则配置:
- 在pserver端,不要执行memory_optimize
- 在trainer端,先执行fluid.memory_optimize再执行t.transpile()
- 在trainer端,调用memory_optimize需要增加 skip_grads=True 确保发送的梯度不会被重命名:fluid.memory_optimize(input_program, skip_grads=True)
示例:
if role == "TRAINER":
fluid.memory_optimize(fluid.default_main_program(), skip_grads=True)
t = fluid.DistributeTranspiler()
t.transpile(trainer_id, pservers=pserver_endpoints, trainers=trainers)
if role == "PSERVER":
# start pserver here
elif role == "TRAINER":
# start trainer here
使用NCCL2通信方式的训练
NCCL2模式的分布式训练,由于没有parameter server角色,是trainer之间互相通信,使用时注意:
- 配置 fluid.DistributeTranspilerConfig中mode=”nccl2” 。
- 调用 transpile时,trainers传入所有trainer节点的endpoint,并且传入参数current_endpoint。在此步骤中,会在startup program中增加gen_nccl_id_op用于在多机程序初始化时同步NCCLID信息。
- 初始化ParallelExecutor时传入num_trainers和trainer_id。在此步骤中,ParallelExecutor会使用多机方式初始化NCCL2并可以开始在多个节点对每个参数对应的梯度执行跨节点的allreduce操作,执行多机同步训练
一个例子:
trainer_id = 0 # get actual trainer id here
trainers = "192.168.1.1:6170,192.168.1.2:6170"
current_endpoint = "192.168.1.1:6170"
config = fluid.DistributeTranspilerConfig()
config.mode = "nccl2"
t = fluid.DistributeTranspiler(config=config)
t.transpile(trainer_id, trainers=trainers, current_endpoint=current_endpoint)
exe = fluid.ParallelExecutor(use_cuda,
loss_name=loss_name, num_trainers=len(trainers.split(",")), trainer_id=trainer_id)
...
NCCL2模式必要参数说明
| 参数 | 说明 |
|---|---|
| trainer_id | (int) 任务中每个trainer节点的唯一ID,从0开始,不能有重复 |
| trainers | (int) 任务中所有trainer节点的endpoint,用于在NCCL2初始化时,广播NCCL ID |
| current_endpoint | (string) 当前节点的endpoint |
目前使用NCCL2进行分布式训练仅支持同步训练方式。使用NCCL2方式的分布式训练,更适合模型体积较大,并需要使用同步训练和GPU训练,如果硬件设备支持RDMA和GPU Direct,可以达到很高的分布式训练性能。
启动多进程模式 NCCL2 分布式训练作业
通常情况下使用多进程模式启动NCCL2分布式训练作业可以获得更好多训练性能,Paddle提供了paddle.distributed.launch模块可以方便地启动多进程作业,启动后每个训练进程将会使用一块独立的GPU设备。使用时需要注意:
- 设置节点数:通过环境变量PADDLE_NUM_TRAINERS设置作业的节点数,此环境变量也会被设置在每个训练进程中。
- 设置每个节点的设备数:通过启动参数–gpus可以设置每个节点的GPU设备数量,每个进程的序号将会被自动设置在环境变量PADDLE_TRAINER_ID中。
- 数据切分: 多进程模式是每个设备一个进程,一般来说需要每个进程处理一部分训练数据,并且保证所有进程能够处理完整的数据集。
- 入口文件:入口文件为实际启动的训练脚本。
- 日志:每个训练进程的日志默认会保存在./mylog目录下,您也可以通过参数–log_dir进行指定。
启动样例:
> PADDLE_NUM_TRAINERS=<TRAINER_COUNT> python -m paddle.distributed.launch train.py --gpus <NUM_GPUS_ON_HOSTS> <ENTRYPOINT_SCRIPT> --arg1 --arg2 ...
NCCL2分布式训练注意事项
注意: 使用NCCL2模式分布式训练时,需要确保每个节点训练等量的数据,防止在最后一轮训练中任务不退出。通常有两种方式:
- 随机采样一些数据,补全分配到较少数据的节点上。(推荐使用这种方法,以训练完整的数据集)。
- 在python代码中,每个节点每个pass只训练固定的batch数,如果这个节点数据较多,则不训练这些多出来的数据。
说明:使用NCCL2模式分布式训练时,如果只希望使用一个节点上的部分卡,可以通过配置环境变量:export CUDA_VISIBLE_DEVICES=0,1,2,3 指定。
注意:如果系统中有多个网络设备,需要手动指定NCCL2使用的设备,假设需要使用 eth2 为通信设备,需要设定如下环境变量:
export NCCL_SOCKET_IFNAME=eth2
另外NCCL2提供了其他的开关环境变量,比如指定是否开启GPU Direct,是否使用RDMA等,详情可以参考ncclknobs。
模型/变量的保存、载入与增量训练
模型变量分类
在PaddlePaddle Fluid中,所有的模型变量都用fluid.framework.Variable()作为基类。在该基类之下,模型变量主要可以分为以下几种类别:
模型参数
模型参数是深度学习模型中被训练和学习的变量,在训练过程中,训练框架根据反向传播(backpropagation)算法计算出每一个模型参数当前的梯度, 并用优化器(optimizer)根据梯度对参数进行更新。模型的训练过程本质上可以看做是模型参数不断迭代更新的过程。 在PaddlePaddle Fluid中,模型参数用fluid.framework.Parameter来表示, 这是一个fluid.framework.Variable()的派生类,除了具有fluid.framework.Variable()的各项性质以外,fluid.framework.Parameter还可以配置自身的初始化方法、更新率等属性。
长期变量
长期变量指的是在整个训练过程中持续存在、不会因为一个迭代的结束而被销毁的变量,例如动态调节的全局学习率等。在PaddlePaddle Fluid中,长期变量通过将fluid.framework.Variable()的persistable属性设置为True来表示。所有的模型参数都是长期变量,但并非所有的长期变量都是模型参数。
临时变量
不属于上面两个类别的所有模型变量都是临时变量,这种类型的变量只在一个训练迭代中存在,在每一个迭代结束后,所有的临时变量都会被销毁,然后在下一个迭代开始之前,又会先构造出新的临时变量供本轮迭代使用。一般情况下模型中的大部分变量都属于这一类别,例如输入的训练数据、一个普通的layer的输出等等。
如何保存模型变量
根据用途的不同,我们需要保存的模型变量也是不同的。例如,如果我们只是想保存模型用来进行以后的预测,那么只保存模型参数就够用了。但如果我们需要保存一个checkpoint(检查点,类似于存档,存有复现目前模型的必要信息)以备将来恢复训练,那么我们应该将各种长期变量都保存下来,甚至还需要记录一下当前的epoch和step的id。因为一些模型变量虽然不是参数,但对于模型的训练依然必不可少。
save_vars、save_params、save_persistables 以及 save_inference_model的区别
- save_inference_model会根据用户配置的feeded_var_names和target_vars进行网络裁剪,保存下裁剪后的网络结构的__model__以及裁剪后网络中的长期变量
- save_persistables 不会保存网络结构,会保存网络中的全部长期变量到指定位置。
- save_params 不会保存网络结构,会保存网络中的全部模型参数到指定位置。
- save_vars 不会保存网络结构,会根据用户指定的fluid.framework.Parameter列表进行保存。
save_persistables 保存的网络参数是最全面的,如果是增量训练或者恢复训练,请选择save_persistables进行变量保存。save_inference_model会保存网络参数及裁剪后的模型,如果后续要做预测相关的工作,请选择save_inference_model进行变量和网络的保存。save_vars和save_params仅在用户了解清楚用途及特殊目的情况下使用,一般不建议使用。
保存模型用于对新样本的预测
如果我们保存模型的目的是用于对新样本的预测,那么只保存模型参数就足够了。我们可以使用 fluid.io.save_params() 接口来进行模型参数的保存。
例如:
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
param_path = "./my_paddle_model"
prog = fluid.default_main_program()
fluid.io.save_params(executor=exe, dirname=param_path, main_program=None)
上面的例子中,通过调用fluid.io.save_params函数,PaddlePaddle Fluid会对默认fluid.Program也就是prog中的所有模型变量进行扫描,筛选出其中所有的模型参数,并将这些模型参数保存到指定的param_path之中。
如何载入模型变量
与模型变量的保存相对应,我们提供了两套API来分别载入模型的参数和载入模型的长期变量,分别为保存、加载模型参数的 save_params() 、 load_params() 和 保存、加载长期变量的 save_persistables 、 load_persistables 。
载入模型用于对新样本的预测
对于通过 fluid.io.save_params 保存的模型,可以使用 fluid.io.load_params 来进行载入。
例如:
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
param_path = "./my_paddle_model"
prog = fluid.default_main_program()
fluid.io.load_params(executor=exe, dirname=param_path,
main_program=prog)
上面的例子中,通过调用fluid.io.load_params函数,PaddlePaddle Fluid会对prog中的所有模型变量进行扫描,筛选出其中所有的模型参数,并尝试从param_path之中读取加载它们。
需要格外注意的是,这里的prog必须和调用fluid.io.save_params时所用的prog中的前向部分完全一致,且不能包含任何参数更新的操作。如果两者存在不一致,那么可能会导致一些变量未被正确加载;如果错误地包含了参数更新操作,那可能会导致正常预测过程中参数被更改。这两个fluid.Program之间的关系类似于训练fluid.Program和测试fluid.Program之间的关系,详见:训练过程中评测模型。
另外,需特别注意运行fluid.default_startup_program()必须在调用fluid.io.load_params之前。如果在之后运行,可能会覆盖已加载的模型参数导致错误。
预测模型的保存和加载
预测引擎提供了存储预测模型 fluid.io.save_inference_model 和加载预测模型 fluid.io.load_inference_model 两个接口。
增量训练
增量训练指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识。因此增量学习涉及到两点:在上一次训练结束的时候保存需要的长期变量,在下一次训练开始的时候加载上一次保存的这些长期变量。因此增量训练涉及到如下几个API: fluid.io.save_persistables、fluid.io.load_persistables 。
单机增量训练
单机的增量训练的一般步骤如下:
- 在训练的最后调用fluid.io.save_persistables保存持久性参数到指定的位置。
- 在训练的startup_program通过执行器Executor执行成功之后调用fluid.io.load_persistables加载之前保存的持久性参数。
- 通过执行器Executor或者ParallelExecutor继续训练。
例如:
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
path = "./models"
prog = fluid.default_main_program()
fluid.io.save_persistables(exe, path, prog)
上面的例子中,通过调用fluid.io.save_persistables函数,PaddlePaddle Fluid会从默认fluid.Program也就是prog的所有模型变量中找出长期变量,并将他们保存到指定的path目录下。
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
path = "./models"
startup_prog = fluid.default_startup_program()
exe.run(startup_prog)
fluid.io.load_persistables(exe, path, startup_prog)
main_prog = fluid.default_main_program()
exe.run(main_prog)
上面的例子中,通过调用fluid.io.load_persistables函数,PaddlePaddle Fluid会从默认fluid.Program也就是prog的所有模型变量中找出长期变量,从指定的path目录中将它们一一加载,然后再继续进行训练。
多机增量(不带分布式大规模稀疏矩阵)训练
多机增量训练和单机增量训练有若干不同点:
- 在训练的最后调用fluid.io.save_persistables保存长期变量时,不必要所有的trainer都调用这个方法来保存,一般0号trainer来保存即可。
- 多机增量训练的参数加载在PServer端,trainer端不用加载参数。在PServer全部启动后,trainer会从PServer端同步参数。
- 在确认需要使用增量的情况下, 多机在调用fluid.DistributeTranspiler.transpile时需要指定current_endpoint参数。
多机增量(不带分布式大规模稀疏矩阵)训练的一般步骤为:
- 0号trainer在训练的最后调用fluid.io.save_persistables保存持久性参数到指定的path下。
- 通过HDFS等方式将0号trainer保存下来的所有的参数共享给所有的PServer(每个PServer都需要有完整的参数)。
- PServer在训练的startup_program通过执行器(Executor)执行成功之后调用fluid.io.load_persistables加载0号trainer保存的持久性参数。
- PServer通过执行器Executor继续启动PServer_program。
- 所有的训练节点trainer通过执行器Executor或者ParallelExecutor正常训练。
对于训练过程中待保存参数的trainer,例如:
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
path = "./models"
trainer_id = 0
if trainer_id == 0:
prog = fluid.default_main_program()
fluid.io.save_persistables(exe, path, prog)
上面的例子中,0号trainer通过调用fluid.io.save_persistables函数,PaddlePaddle Fluid会从默认fluid.Program也就是prog的所有模型变量中找出长期变量,并将他们保存到指定的path目录下。然后通过调用第三方的文件系统(如HDFS)将存储的模型进行上传到所有PServer都可访问的位置。
对于训练过程中待载入参数的PServer, 例如:
import paddle.fluid as fluid
exe = fluid.Executor(fluid.CPUPlace())
path = "./models"
pserver_endpoints = "127.0.0.1:1001,127.0.0.1:1002"
trainers = 4
training_role == "PSERVER"
config = fluid.DistributeTranspilerConfig()
t = fluid.DistributeTranspiler(config=config)
t.transpile(trainer_id, pservers=pserver_endpoints,
trainers=trainers, sync_mode=True, current_endpoint=current_endpoint)
if training_role == "PSERVER":
current_endpoint = "127.0.0.1:1001"
pserver_prog = t.get_pserver_program(current_endpoint)
pserver_startup = t.get_startup_program(current_endpoint, pserver_prog)
exe.run(pserver_startup)
fluid.io.load_persistables(exe, path, pserver_startup)
exe.run(pserver_prog)
if training_role == "TRAINER":
main_program = t.get_trainer_program()
exe.run(main_program)
上面的例子中,每个PServer通过调用HDFS的命令获取到0号trainer保存的参数,通过配置获取到PServer的fluid.Program,PaddlePaddle Fluid会从此fluid.Program也就是pserver_startup的所有模型变量中找出长期变量,并通过指定的path目录下一一加载。
- 显示Disqus评论(需要科学上网)