本文是Selenium WebDriver来自动化微信进行消息收发系列文章之二,介绍XPath的语法。
目录
为什么需要XPath
前面介绍了WebDriver的基本用法,但是有一个基本的问题,那就是怎么用findElement(s)找到特定的WebElement,然后获取它的内容(文本)或者与它进行交互(点击、拖放和输入等等)。如果只是为了获取文本内容,从理论上来说,我们可以拿到网页的源代码,然后用字符串搜索或者正则表达式搜索。但是这样的代码非常脆弱。比如有一个”<div class='myclass'>想要的文字</div>“,如果我们写一个正则表达式,比如:”<div class=’myclass’[^>]>([^<]*)</div>“。就可以提取出”想要的文字”,但是如果网站的开发者又给它加了一个class,变成了<div class='myclass yourclass'>想要的文字</div>,我们的正则表达式就不work了。而且正则表达式非常难理解,为了解决各种特殊情况,一个正则表达式可能非常复杂。不服的读者可以尝试一下写一个识别电子邮件的正则表达式,可以参考How to validate an email address using a regular expression?。参考的写法是:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
对于HTML来说,它本质上是一颗树。而且浏览器内部也是把它parse成DOM tree,因此使用一种”树”的查询语言就是非常自然的,而XPath就是这样的一种查询语言。它的全称是XML Path Language。XML是通过标记语言来表示一个树的结构,符合规范的HTML(XHTML)就是一个特定领域的XML,因此也可以用XPath来对HTML进行查询。
XPath规范
根据wiki,XPath是一种用于在XML中查找节点(node)的语言。XPath是W3C推荐的一种标准,目前有3个版本。其中XPath 1.0在1999年成为W3C推荐标准;XPath 2.0在2007年成为W3C推荐标准;XPath 3.0在2014年成为标准。目前大部分浏览器只支持XPath 1.0,如果需要XPath 2.0以上的支持,目前可行的方法是用第三方的支持XPath 2.0/3.0的js库然后注入网页中,具体参考python selenium - how to make webdriver use XPATH version 2.0。不过对于我们的任务来说,XPath 1.0的功能已经足够强大了。下表是各浏览器对于XPath的支持情况。
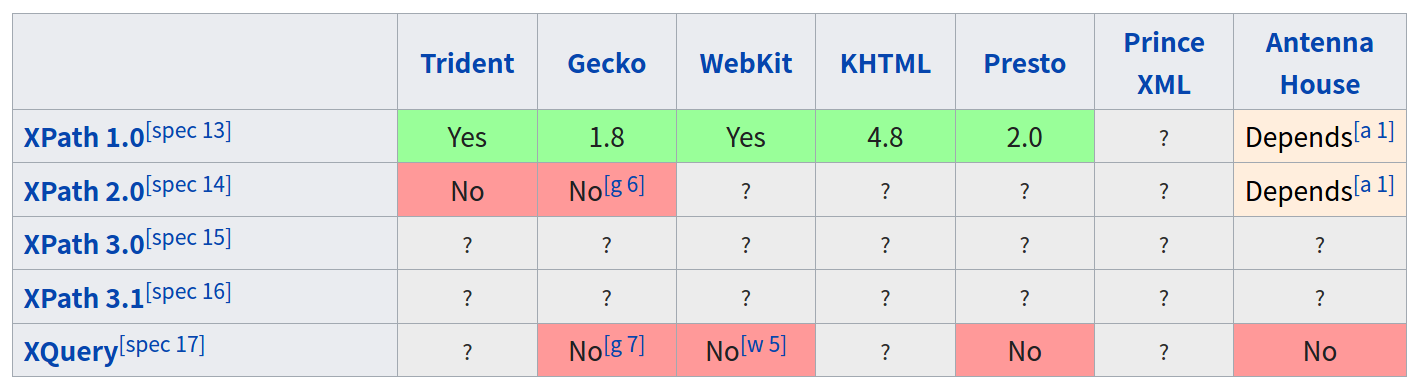 主流浏览器引擎对XPath的支持
主流浏览器引擎对XPath的支持
基本概念
基本术语
Node
在XPath里,有7种node:元素(element)、属性(attribute)、文本节点(text)、命名空间(namespace)、处理指令(processing-instruction)、注释(comment)和文档(document)。
XML被看成一棵树,最上层的节点叫做树根(root)。
比如下面的XML:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
它包含如下的一些节点(node):
<bookstore> (根节点)
<author>J K. Rowling</author> (元素(element)节点)
lang="en" (属性节点)
原子值(atomic value)
原子值是没有孩子和父亲的节点,比如:
J K. Rowling
"en"
Item
节点和原子值都是item。
节点的关系
Parent
每个元素和属性只有一个parent。比如下面的例子,book是title、author、year和price的parent。
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
Children
一个元素可以有零个或者多个children。还是上面的例子,title、author、year和price都是book的children。
Sibling
属于同一个parent的节点互称sibling。比如上面的例子,title、author、year和price互相之间都是sibling。
Ancestor
一个节点的parent或者parent的parent。也就是在树的结构中某个节点一直往上走遇到的所有节点。root是所有节点(自己除外)的ancestor。
Descendant
和Ancestor相反,如果A是B的ancestor,则B是A的descendant。
XPath语法
XPath使用路径表达式来选取XML中的一个或者多个节点。下面是我们本节的示例XML:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选择节点
常见的选择节点路径表达式如下下表,它和*nix的文件系统路径很类似:
| 表达式 | 说明 |
|---|---|
| node名字 | 选择所有这个名字的node |
| / | 从树根开始 |
| // | 从任意节点开始 |
| . | 选择当前节点 |
| .. | 选择当前节点的parent |
| @ | 选择属性 |
下表展示怎么使用这些表达式的例子:
| 表达式示例 | 结果 |
|---|---|
| bookstore | 选择所有bookstore节点 |
| /bookstore | 选择所有根节点下的bookstore节点,单个/开始的总是表示绝对XPath |
| bookstore/book | 选择所有的book节点,要求它的parent是bookstore |
| //book | 选择所有book节点,不管其parent是什么 |
| bookstore//book | 选择所有book节点,要求它的某一个ancestor是bookstore |
| //@lang | 选择所有的名为lang的属性 |
谓词(Predicate)
谓词用来查找特定值的节点,谓词包含在[]里面。下表是谓词的一些示例:
| 表达式示例 | 结果 |
|---|---|
| /bookstore/book[1] | 根节点下的bookstore的第一个名为book的孩子节点,W3C的标准下标从1开始,但是IE5,6,7,8,9是从0开始的 |
| /bookstore/book[last()] | 根节点下的bookstore的最后一个名为book的孩子节点 |
| /bookstore/book[last()-1] | 根节点下的bookstore的倒数第二个名为book的孩子节点 |
| /bookstore/book[position()<3] | 根节点下的bookstore的前两个名为book的孩子节点(如果不够,可能是0个或者1个) |
| //title[@lang] | 从任意位置开始名为title并且有lang属性的title节点,注意最终选择的是title节点 |
| //title[@lang=’en’] | 从任意位置开始名为title并且lang属性等于en的title节点 |
| /bookstore/book[price>35.00] | 从根开始bookstore下的book节点,要求price子节点的值大于35.00,注意最终选中的是book,price只是条件 |
| /bookstore/book[price>35.00]/title | 满足上面条件的book的title孩子节点 |
选择未知节点
| 通配符 | 说明 |
|---|---|
| * | 匹配任意Element节点,注意它不能匹配属性和文本等节点 |
| @* | 匹配任意属性节点 |
| node() | 匹配任意节点,包括Element、属性等等7种node |
示例
| 表达式示例 | 匹配结果 |
|---|---|
| /bookstore/* | 匹配/bookstore下的任意Element |
| //* | 匹配整个文档的任意Element |
| //title[@*] | 匹配title节点,要求它至少有一个属性 |
选择多个路径的节点
可以用或(|)来选择多个路径的节点,比如:
| 表达式示例 | 匹配结果 |
|---|---|
| //book/title | //book/price | 匹配book下的title或者price |
| //title | //price | 匹配title或者price |
| /bookstore/book/title | //price | 匹配bookstore/book/title或者所有的price |
XPath Axis
下面是本节使用的示例XML:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="en">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
Axis代表了和当前节点有某种关系的一些节点,比如我们想找到某个div的下一个兄弟div。因为之前我们学习的XPath只能从根往下走,但是我们有的时候可能定位A比较困难,但是定位B比较容易,而B和A又有某种关系,那么我们可以先定位B,然后通过B和A的关系定位到A。因为B和A的关系通常不是从上往下的parent-children关系,所以需要特殊的Axis关系。也就是说普通的XPath都是从树的上面往下走,而通过Axis,我们可以从下往上,甚至往左右(sibling)走。
Axis列表
下面是XPath支持的Axis列表:
| Axis名称 | 说明 |
|---|---|
| ancestor | 当前节点的ancestor,包括它的parent、它parent的parent、…… |
| ancestor-or-self | 包括ancestor和它自己 |
| attribute | 选择当前节点的所有attribute |
| child | 选择当前节点的所有child |
| descendant | 选择当前节点的所有child、child的child、…… |
| descendant-or-self | descendant或者自己 |
| following | 当前节点之后的所有节点,也就是当前Element的结束</elem>之后的所有内容 |
| following-sibling | 当前节点之后的所有兄弟节点 |
| namespace | 命名空间 |
| parent | parent |
| preceding | 和following相反,在当前Element开始前的所有内容 |
| preceding-sibling | 当前节点之前的所有兄弟节点 |
| self | 自己 |
相对和绝对XPath
从格式上看,以/开头的XPath是绝对XPath,它从树根开始;而没有/开头的代表相对XPath,它需要一个相对参考的Node。这就是和文件路径的绝对路径与相对路径类似。
axis的语法为:
axisname::nodetest[predicate]
语法就不解释了,我们直接看具体例子:
| Axis示例 | 说明 |
|---|---|
| child::book | 当前节点的所有孩子,并且这个孩子的tag是book。div/child::span等价于div/span |
| attribute::lang | 当前节点的lang属性。div/attribute::lang等价于div/@lang |
| child::* | 当前节点的所有孩子,并且这个孩子是Element()。div/child::等价于div/* |
| attribute::* | 当前节点的所有属性。div/attribute::等价于div/@ |
| child::text() | 当前节点的所有文本节点。div/child::text()等价于div/text() |
| child::node() | 当前节点的所有节点。div/child::node()等价于div/node() |
| descendant::book | 当前节点的所有后代book节点,div/descendant::book等价于div//book |
| ancestor::book | 当前节点的所有ancestor的book节点 |
| ancestor-or-self::book | 当前节点的ancestor或者自己,并且要求是book |
| child::*/child::price | 当前节点的孩子的孩子,并且是price,等价于./*/price |
注意:child的大部分功能都可以用/来替代;descendant大部分功能可以用//替代。
XPath的运算符
XPath可以继续简单的算是逻辑运算,下表是XPath支持的运算符:
| 运算符 | 说明 | 示例 |
|---|---|---|
| | | 两个的并 | //book | //cd |
| + | 加 | 4 + 6 |
| - | 减 | 4 - 6 |
| * | 乘 | 4 * 6 |
| div | 除 | 4 div 6 |
| = | 等于 | name = ‘tom’ |
| != | 不等于 | name != ‘tom’ |
| < | 小于 | 4 < 6 |
| <= | 小于等于 | 4 <= 6 |
| > | 小于 | 4 > 6 |
| >= | 小于等于 | 4 >= 6 |
| and | 逻辑与 | 4 <= 6 and 3 > 6 |
| or | 逻辑或 | name = ‘tom’ and age > 10 |
| mod | 取模 | 4 mod 6 |
XPath函数
XPath支持很多函数,详细列表参考这里。我们这里列举几个常用的。
- contains
- //BUTTON[contains(text(), ‘登录’)] ,查找所有文字包含登录的button。
- starts-with
- 例子参考上面,把contains改成starts-with
- ends-with
- 例子同上
- position
- //book[position() mod 2 = 0] 偶数位置的book
- last
- //book[last()]
XPath定位的一些基本原则
XPath是一门很灵活的语言,为了定位一个/多个元素可能有很多种表达方式。比如为了(唯一)定位百度首页的输入文本框,我们可以这样:
/html/body/div[1]/div[1]/div[5]/div[2]/div/form/span[1]/input
也可以:
//*[@id="kw"]
这两个哪个好呢?很显然第二个好一些。为什么呢?首先因为它短;其次它使用的是这个元素的不常变化的属性id。如果读者做过前端开发或者写过一些简单的HTML,就会知道一个原则:内容和样式分离。具体来说就是HTML标签只实现内容,而由CSS来实现可视化的效果。那CSS怎么能知道把样式应用到一个或者一类元素上呢,这就是所谓的CSS selector。除了通过标签名字筛选,最常见的两类筛选就是id和class选择器。一般来说,id是唯一的,而class代表一个类通常是多个。如果有过写爬虫的经验,可能最讨厌的就是微软那些拖拽生成的网页了,所有的页面全是大table套小table,没有任何id和name。
所以使用id或者class来选择是较好的选择。另外如果我们使用class,尽量使用contains而不是等于。举个例子,比如百度的首页有个搜图的按钮,我们可以通过class来定位:
//SPAN[@class='soutu-btn']
但是如果我们写过css,可能会知道未来前端可能会给某个元素加更多样式,比如哪天前端把它改成了:
<span class="soutu-btn another-class" style="outline: orange dashed 2px !important; outline-offset: -1px !important;"></span>
那我们的XPath就不work了,所以更好的写法是:
//SPAN[contains(@class, 'soutu-btn')]
另外一个原则就是先定位大块然后再定位小块。比如还是前面的例子,css的样式通常会应用到多个元素上,通过class通常很难唯一定位。所以我们可以先找到一个能唯一定位的,比如先找到包含SPAN的FORM,它是有id的,然后在定位它:
//FORM[@id='form']//SPAN[contains(@class, 'soutu-btn')]
当然要提高写XPath的能力需要很多实践,后面的资源部分也推荐了一些可以在线练习的网站,有兴趣的读者可以去练习练习。
工具
下面介绍一些用于测试XPath的工具,方便大家使用。作者选择的浏览器是Chrome浏览器,所以相关的工具都是能用于Chrome的,但是其它的浏览器可能需要读者自己寻找类似的工具。
Chrome开发者工具
这个工具是Chrome自带的,非常强大,如果做过前端开发的同学肯定不会陌生。我们可以通过菜单”工具”->”开发者工具”或者在网页的任意位置右键唤出上下文菜单然后点击”检查”打开开发者工具。如下图所示:
我们可以调整它的位置,通过dock side选择让它出现在下方、左方还是右方。比如下图我们就把它放到了右边。
详细的使用请参考官方文档。我们暂时用不到查看网络,调试JS代码这些功能。我们需要的是查看DOM树,可以参考Get Started With Viewing And Changing The DOM。我们这里只介绍与元素选择和XPath相关的功能。
比如打开百度,搜索”天气预报”可以得到一个页面,我们可以用开发者工具的Elements面板查看整颗DOM树。我们可以把鼠标移动到某个节点上,浏览器会自动的把对于元素的区域变成特殊的颜色。如下图所示:
另外有的时候想在一棵复杂的树上找到一个节点会很可能,这个时候就可以点击左上角按钮:

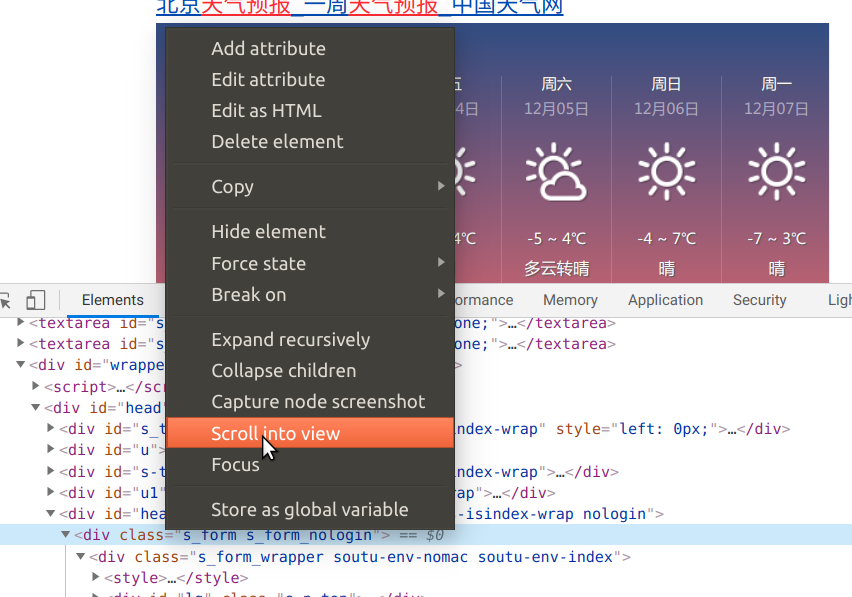
点击后我们就可以移动鼠标在浏览器中找到对应的元素,点击后Elements面板的树就会自动展开到对应的节点。另外有时候我们在看Elements面板的DOM树的某些元素时,它可能没有出现在窗口的view里,这个时候可以通过scorll into view来把它滚到到可见的区域,如下图所示:
通过上面的方式,我们应该可以轻松的找到某个元素在DOM树中的位置。接下来就是写XPath了,我们当然可以自己写,但是开发者工具也能”自动”的生成可以参考的XPath:
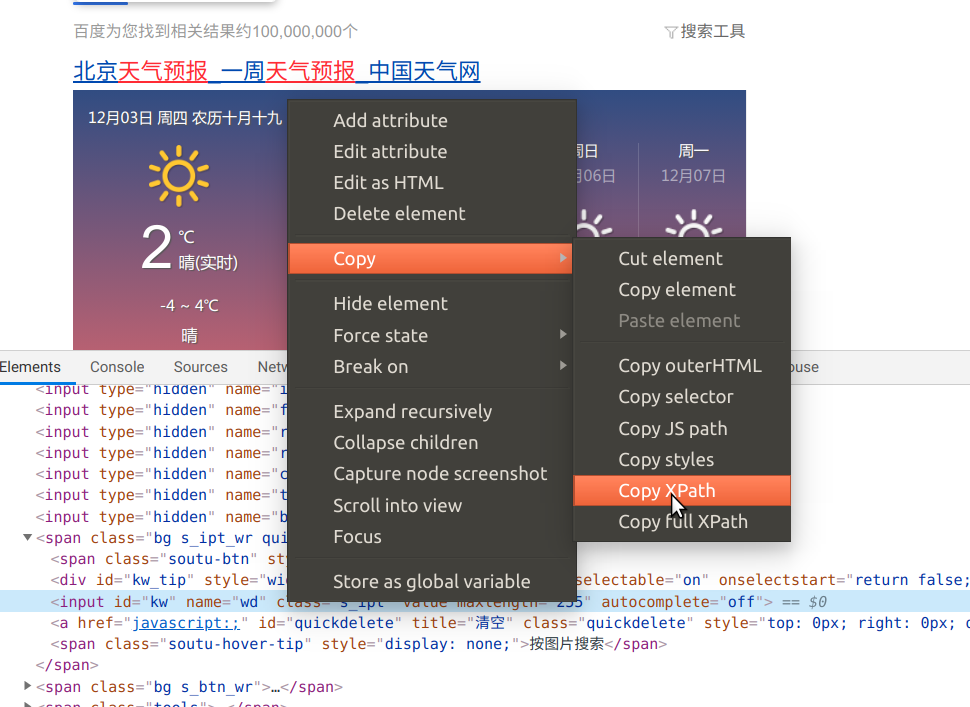
比如上面的例子,我们在DOM树中找到了文本框,我们可以右键单击元素,选择”copy”->”copy xpath”,就得到了如下的XPath:
//*[@id="kw"]
看起来还不错,我们再试一下搜索按钮坐标那个拍照图标,它生成的是:
//*[@id="form"]/span[1]/span[1]
我们发现对于有id的,它会自动用id;没有id的,效果就不好了。上面的XPath使用了span[1]这样的方法,这是不好的XPath,因为很可能过两天网站开发者有增加一个SPAN,这个XPath就不能用了,更好的方法是使用class。
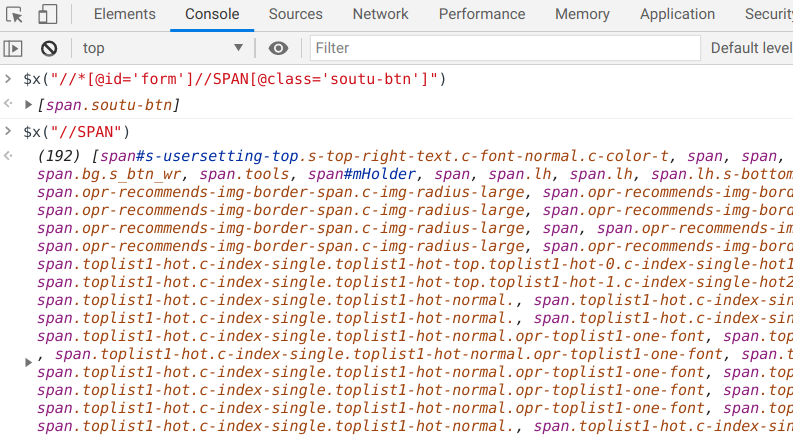
如果我们自己写了一个XPath,想验证一下,也可以用开发者工具。我们可以点击Elements面板旁边的Console,然后在文本框里输入:
$x("//*[@id='form']//SPAN[@class='soutu-btn']")
结果如下图所示:
chropath
另一个好用的Chrome插件是chropath。它是完全集成在开发者工具里的,我们在Elements右侧的面板可以找到它。如果没有看到,请点击»把它弄出来,如下图所示:
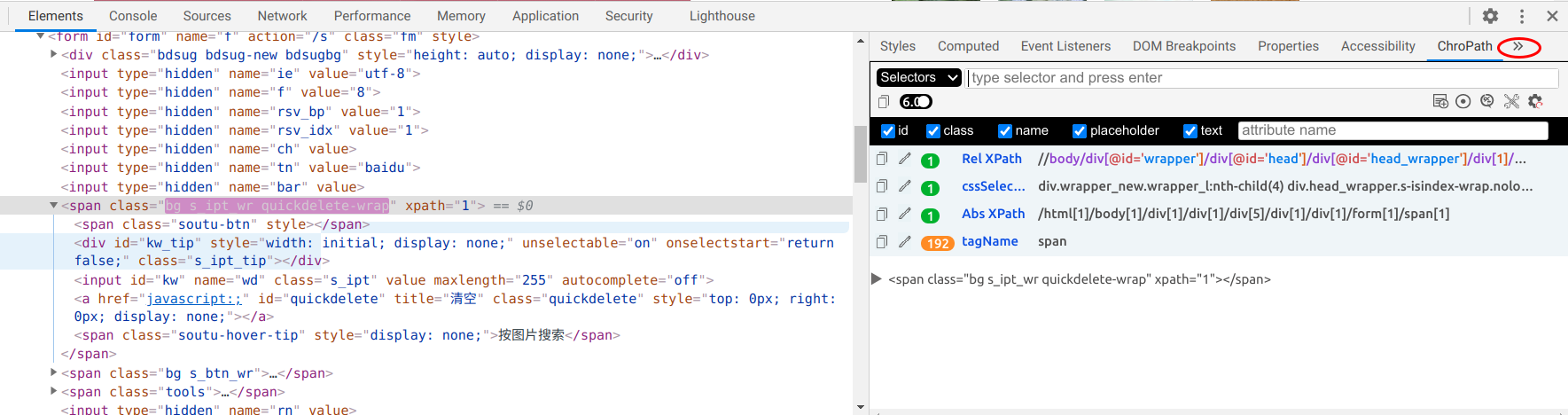
另外它也集成在浏览器的上下文右键菜单里,比如可以让它来帮我们生成XPath:
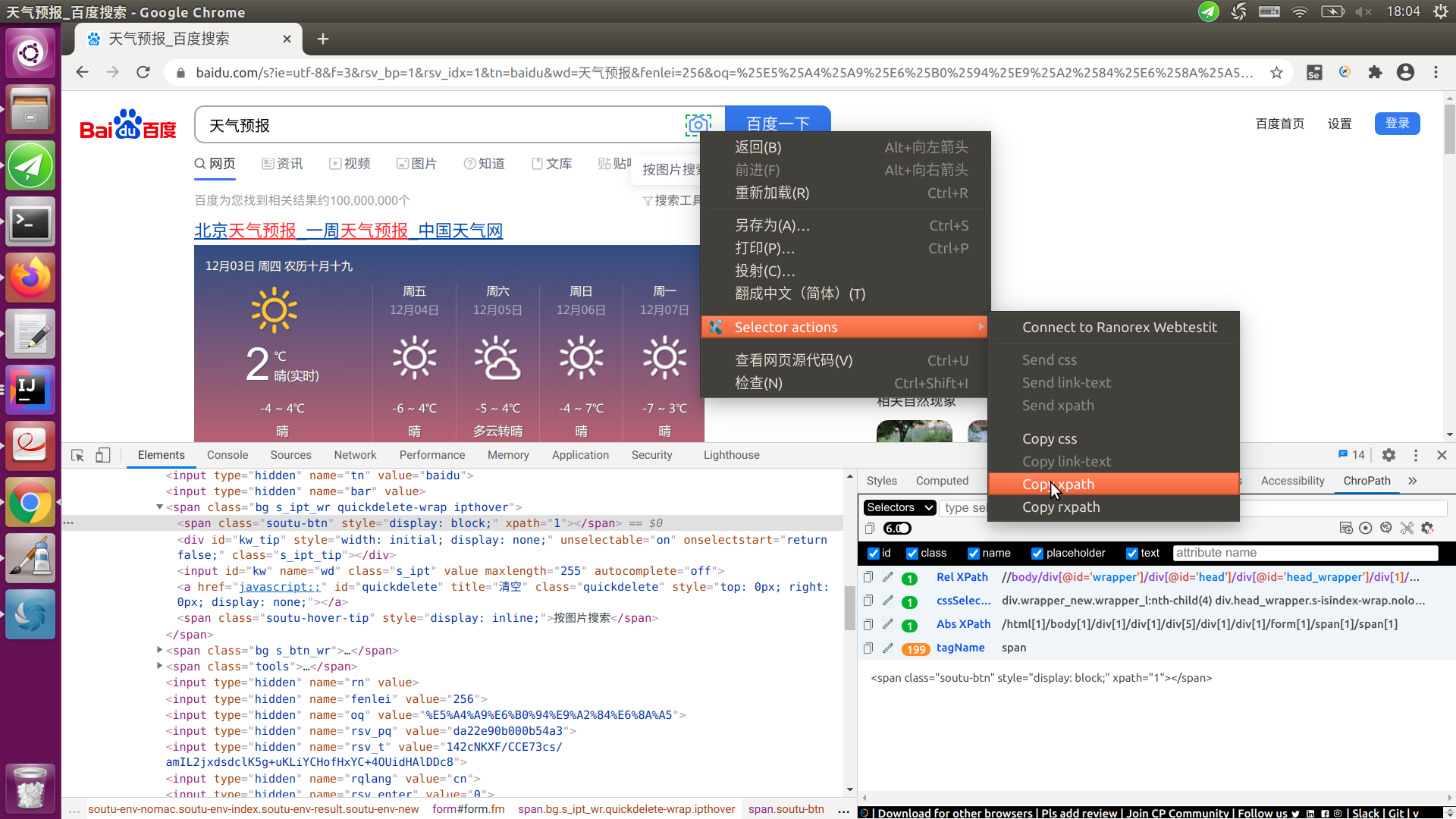
生成的XPath为:
//form[@id='form']//span[@class='soutu-btn']
这个比开发者工具自己生成的要好!
我们也可以在chropath里验证XPath(包括css选择器),如下图所示:
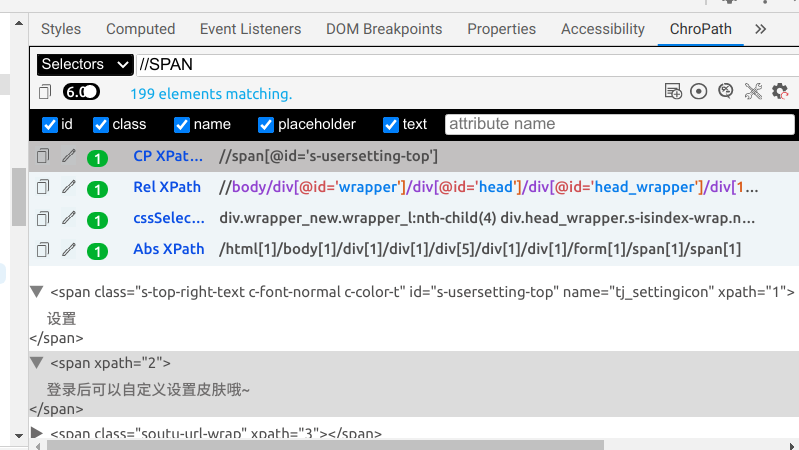
相关资源
- w3cschool tutorial
- XPath in Selenium WebDriver: Complete Tutorial
- Mastering XPath for Selenium Test Automation Engineers
- Xpath Diner
- 很好的游戏
- W3C XPath exercises
- 在线的XPath练习题
- scrapy XPath Tutorial
- 显示Disqus评论(需要科学上网)