本文的相关项目为微信公众号爬虫的抓取原理。这是尝试抓取阅读数的记录。
目录
问题
微信公众号文章的阅读数是一个非常重要的指标,可以用来衡量一篇文章的关注度。我们之前的文章使用pywinauto驱动微信客户端实现公众号抓取介绍过抓取公众号文章的方法。但是微信对阅读数做了保护(具体原理不清楚),在pywinauto里使用print_control_identifiers是没法输出阅读数的。
解决思路
虽然print_control_identifiers没法得到阅读数,但是用鼠标选中之后又是可以复制粘贴出来的,所以本文的解决思路是模拟人的方法:打开微信公众号文章,通过向下翻页来找到阅读数的页面,然后移动鼠标到数字的地方,通过双击进行选择,最后通过ctrl+c复制出来。
这个方法看起来似乎很简单,但是了解过机器学习的同学应该会了解其中的困难(事实上我在尝试之前也低估了其中的难度)。因为很多在人看起来非常简单的认知问题,对于机器来说异常困难。下面是需要解决的问题。
定位阅读数
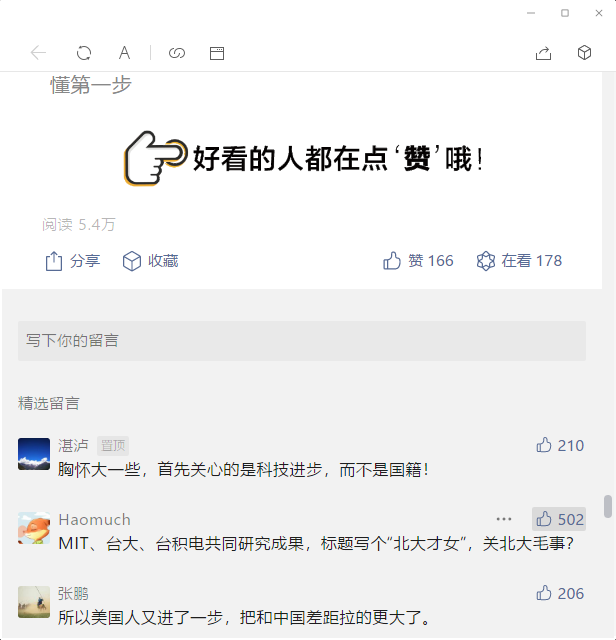
对于人来说很简单,就是向下拖到滚动条或者PageDown或者向下的方向键,然后看到【阅读 5.4万】的时候停下来就行。上面的简单描述其实隐藏了复杂的行为:人的眼睛快速的分析当前页面的结构,他知道需要的信息大概在左侧,并且认识“阅读”这两个字——但是文章正文部分也可能出现阅读两个字,所以后面应该是一个数字,但也可能是【5.4万】或者【10万+】这样的字眼,下面的【分享】和精选留言也是很好的辅助信息。
另外翻页也可能会出现下面的情况:
也就是我们要的那行信息在两页之间,无论那一页可能都不是完整的信息。读者可能会建议使用向下键(Down)而不是下翻页(PageDown),但是下翻页速度太慢,而且理论上仍然是会出现前面的问题。
复制
假设我们定位到了【阅读 xxxx】这一行了,怎么控制鼠标进行复制呢?这对于人来说也是再简单不过的事情了,小学生都能轻松愉快的搞定。当然一种办法是使用OCR,识别并且定位其中的文字,然后把鼠标移动到数字的左侧,按下鼠标左键,拖得到最右侧,然后释放鼠标。这首先要引入ocr模块,而且需要定位其中文本的位置,如果定位不准确很可能会少中一个数字。当然如果有了ocr,那似乎也没有必要复制了,直接就出结果了。但是ocr可能会出错,比如小数点很可能会被漏掉。
解决方法
定位
由于图像分析是比较耗时的,所以我们首先通过PageDown键拖到到最下面。这通常有两种情况:评论数量很少(或者没有)的文章之间可以看到阅读数;阅读数较多无法看到。
 最后一页能直接看到阅读数
最后一页能直接看到阅读数
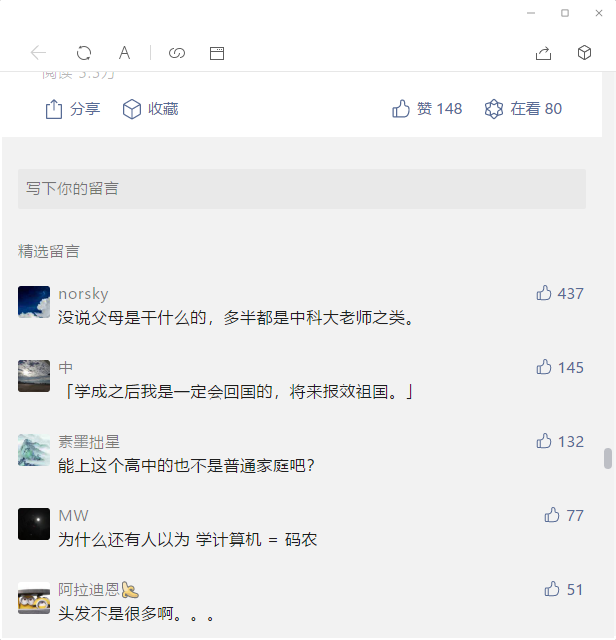
 最后一页无法看到阅读数
最后一页无法看到阅读数
最容易想到的策略是:如果当前页不包含阅读数,则通过PageUp向上翻页;如果阅读数在上部被切断,则我们用向下键微微调整;如果阅读数在下部被切断,则使用向上键微调。
现在的问题是:怎么判断当前可见页面是否包含阅读数以及较为准确的定位?
最简单的方法也许是逐个像素的比较,也就是把固定的“阅读”两个字对应的图片保存下来,然后进行像素级的比较进行定位。这种方法看起来比较简单,但是有一个问题,那就是非常不鲁棒。比如屏幕的分辨率不同就可能让程序无法识别,这样换一台机器就可能无法运行了。
我们需要更加“稳定”的特征来定位。通过分析我们可以发现,正文部分的背景是白色的(可以使用取色器确认),而留言区部分的背景是灰色的。但计算机怎么做到这样的分析呢?我们也许可以通过图像技术对版面进行分析,不过有没有更加简单的方法呢?作者发现,正文的左侧背景是白色的,而留言区背景是灰色的,如下图:
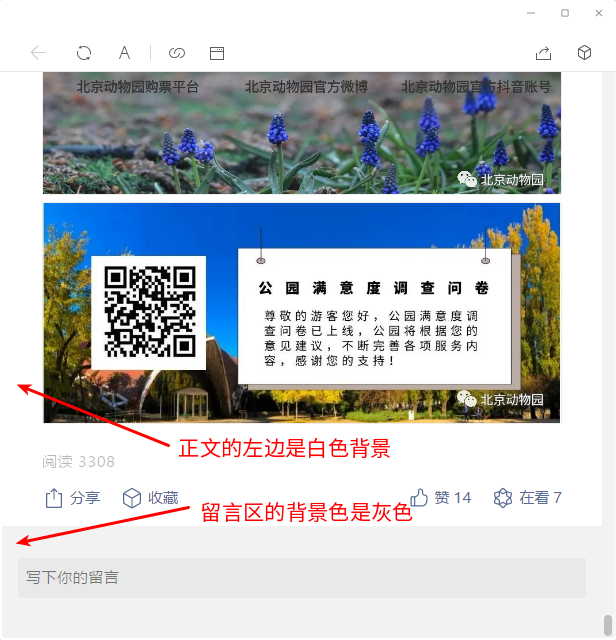
注意:留言区的最左侧有几个像素也是白色的!所以我们可以选择跳过几个像素,也就是分析x坐标(屏幕坐标系统)为10那一列进行分析。
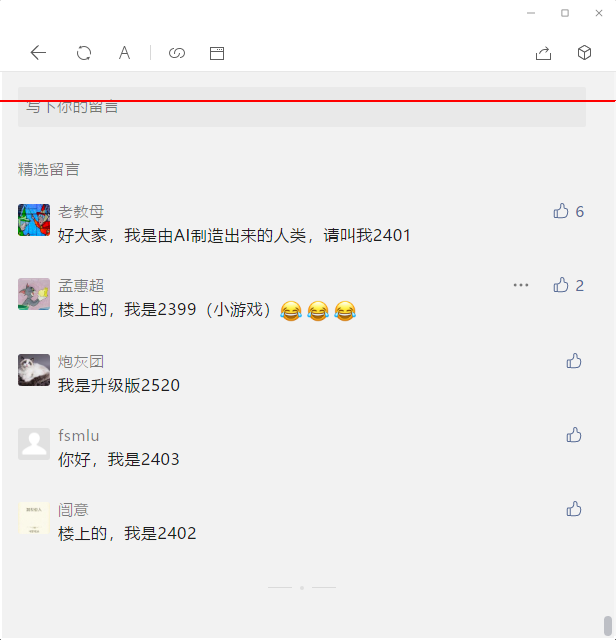
具体的算法思路是:从上往下扫描(x=10, y从0到height),如果遇到的颜色是背景色,那么说明是正文,继续扫描,否则说明遇到了留言区,则可以退出,这个时候的x就是正文最底部的位置。但是这里有两点需要注意。第一点就是正文上方的工具栏,它的背景色也是白色的,而且它是不会随着滚动条滚到。第二点就是如果留言较多,可能整页都没有一点正文,如下图所示:
整页全是留言
我们来看一下代码,完整的代码在read_count分支。
def locate_content_bottom(img_array, debug_fn, bg_color=None):
if bg_color is None:
bg_color = [255, 255, 255]
height, width = img_array.shape[:2]
col = 10
has_content = False
for row in range(100, height-5):
if np.all(img_array[row, col] == bg_color):
has_content = True
else:
break
if debug_fn:
draw_bbox(img_array, (0, row, width-1, row+1), debug_fn + ".png")
if not has_content:
return -1
return row
imgtool.locate_content_bottom函数的作用就是定位正文的做底部的坐标,它跳过前100行(其实是101行)从而跳过工具栏。根据作者机器的情况,工具栏大概的高度是70个像素。理论上不同分辨率下的页面布局可能不同(这个要看微信前端的实现技术了),也许换一台机器可能有问题?
在逐行扫描的过程中判断当前行(第10列,好吧,精确的讲是第11列)是否白色背景,如果是则继续,否则退出。另外如果出现白色背景则说明有正文,如果一次白色背景都没出现(has_content为False),则说明是上图的情况,则返回-1。否则返回正文的最底部。
下面我们来看一下翻页的逻辑:
def extract_read_count(self, fn):
self.browser_page_down(30, 0.1)
# 初步定位
for i in range(20):
img_array = imgtool.snap_shot(self.browser.rectangle())
bottom = imgtool.locate_content_bottom(img_array, fn+"_coarse_"+str(i))
if bottom == -1:
self.browser_key(1, "{PGUP}", sleep_time=1)
else:
break
# 没找到
if bottom == -1:
return None
height, width = img_array.shape[:2]
content_height = height - self.visible_top
# 精确定位
found = False
for i in range(20):
# 太靠上,使用UP键往下一点
# UP键的作用是往下
if bottom - self.visible_top < 120:
self.browser_key(1, "{UP}")
img_array = imgtool.snap_shot(self.browser.rectangle())
bottom = imgtool.locate_content_bottom(img_array, fn+"_fine_"+str(i))
elif bottom > height - 50:
self.browser_key(1, "{DOWN}")
img_array = imgtool.snap_shot(self.browser.rectangle())
bottom = imgtool.locate_content_bottom(img_array, fn + "_fine_" + str(i))
else:
found = True
break
if not found:
return None
location = imgtool.locate_read_count(img_array, fn+"_locate", bottom)
rect = self.browser.rectangle()
self.double_click((location[0] + rect.left, location[1] + rect.top))
imgtool.snap_shot_to_file(rect, fn+"-click.png")
self.browser.type_keys("^c")
count = clipboard.GetData()
if count.startswith("http"):
return None
return count
代码首先向下翻30页(我们假设微信公众号的文章不会超过30页)。然后接下来的循环进行初步的定位,也就是调用locate_content_bottom来定位正文的底部。如果返回值是-1,则说明没有正文,这个时候可以使用PageUp快速上翻页。如果不是-1,说明以及有正文了,那么就退出。
接下来的循环就是精细的定位,也就是使用UP或者DOWN键进行微调。我们希望把包含“阅读数”的那个区域放置在屏幕的合适的区域:如果它太靠上了,那么我们使用UP键往下走一点;如果太靠下了则用DOWN键上走一点。
定位到了正文的底部之后就需要定位“阅读”的那行内容,那怎么定位呢?作者发现了如下的特征:从正文底部往上走,遇到的第一个非背景色的区域块是【分享】,然后又是一些纯背景色的区域,再往上就是【阅读】所在的行。
根据这个发现,我们可以逐行扫描,把有文字(非背景色)的行合并就得到【分享】块和【阅读】快。这里有个假设:文字在垂直方向是“连续”的。这理论上可能是有问题的,比如汉字“三”,在三横中间有两个区域是背景色。不过这里比较幸运的是分享的图标肯定是“连续”的。另外“阅读”两个子也是“连续“的。
代码如下:
def locate_read_count(img_array, debug_fn, bottom, bg_color=None):
if bg_color is None:
bg_color = [255, 255, 255]
height, width = img_array.shape[:2]
for r in range(bottom-1, bottom-MAX_SEARCH_ROW, -1):
# 找到第一行非全白背景的行,此行内容是分享
if not np.all(img_array[r][LEFT_MOST:RIGHT_MOST] == bg_color):
break
if debug_fn:
draw_bbox(img_array, (0, r, width-1, r+1), debug_fn + "-1.png")
for r2 in range(r-1, r-MAX_SEARCH_ROW, -1):
if np.all(img_array[r2][LEFT_MOST:RIGHT_MOST] == bg_color):
break
if debug_fn:
draw_bbox(img_array, (0, r2, width - 1, r2 + 1), debug_fn + "-2.png")
for r3 in range(r2-1, r2-MAX_SEARCH_ROW, -1):
if not np.all(img_array[r3][LEFT_MOST:RIGHT_MOST] == bg_color):
break
if debug_fn:
draw_bbox(img_array, (0, r3, width - 1, r3 + 1), debug_fn + "-3.png")
for r4 in range(r3-1, r3-MAX_SEARCH_ROW, -1):
if np.all(img_array[r4][LEFT_MOST:RIGHT_MOST] == bg_color):
break
if debug_fn:
draw_bbox(img_array, (0, r4, width - 1, r4 + 1), debug_fn + "-4.png")
row = (r3 + r4)//2
# 从右边往左的第一个非白色像素就是阅读数的最后一个数字的最右侧
for col_end in range(width//2, LEFT_MOST, -1):
if not np.all(img_array[row, col_end] == bg_color):
break
for col_start in range(col_end-1, LEFT_MOST, -1):
if np.all(img_array[row, col_start] == bg_color):
break
if debug_fn:
draw_bbox(img_array, (col_start, r4, col_end, r3), debug_fn + "-final.png")
return (col_start + col_end)//2, row
下面是代码执行的一个例子:
 粗定位1
粗定位1
 粗定位2
粗定位2
 定位分享行的底部
定位分享行的底部
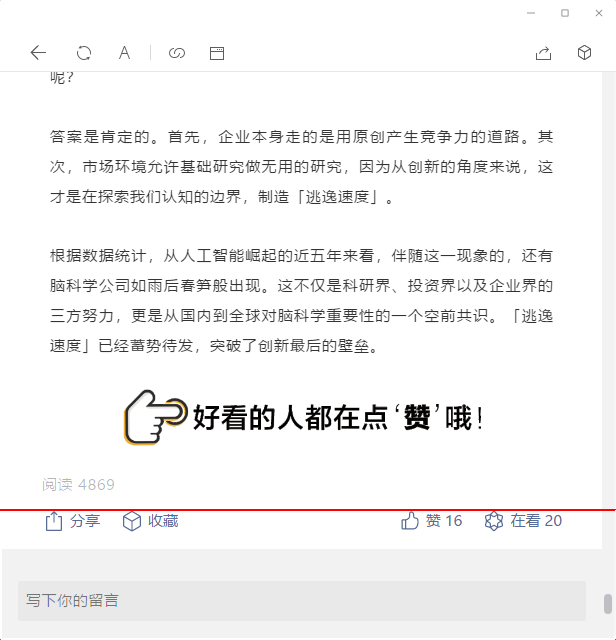 定位分享行的顶部
定位分享行的顶部
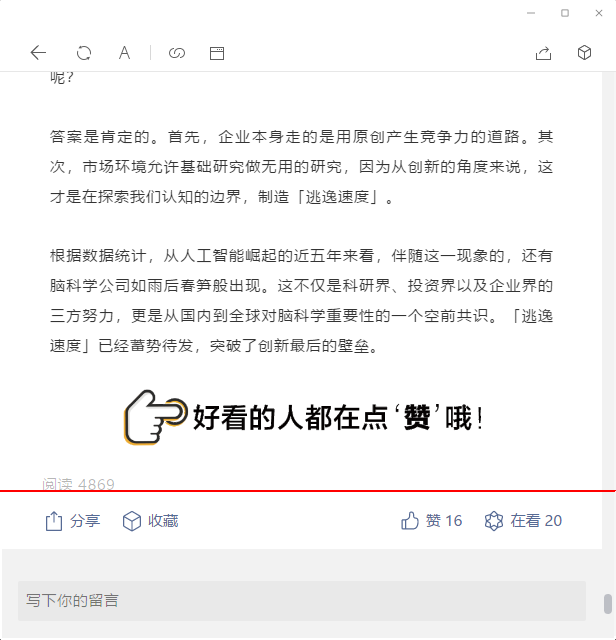 定位阅读行的底部
定位阅读行的底部
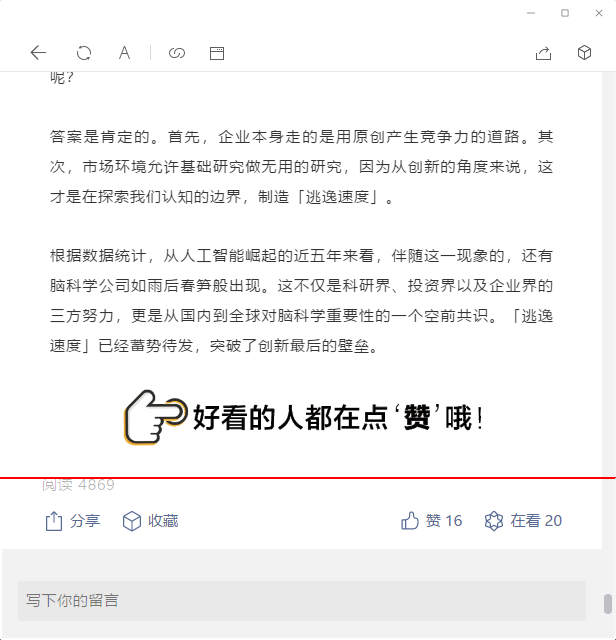 定位阅读行的顶部
定位阅读行的顶部
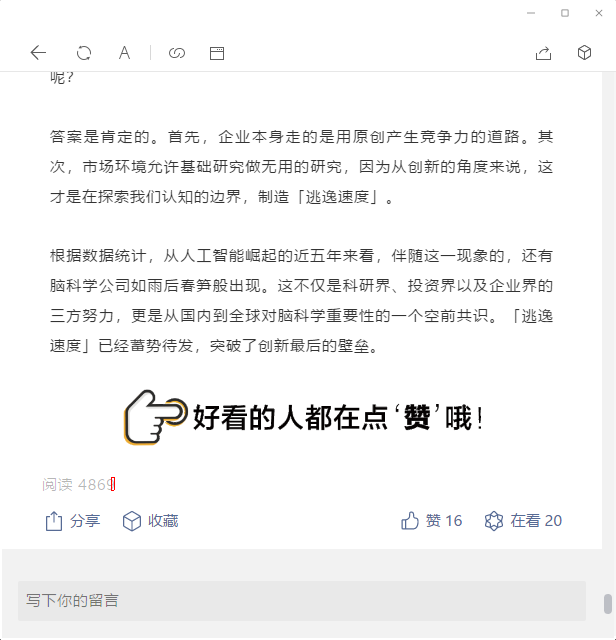 定位阅读行最后一个字符中心的坐标
定位阅读行最后一个字符中心的坐标
选择
代码定位到了包含”阅读“的行之后,从右往左扫描非背景色的内容定位最后一个字符。从而可以通过双击选择对应的数字。但是这里有一些问题,比如超过1万的阅读数显示为【3.5万】,如果双击最右一个万字,选中的只是万字,而不会选中【3.5万】。另外一个问题就是如下图所示:
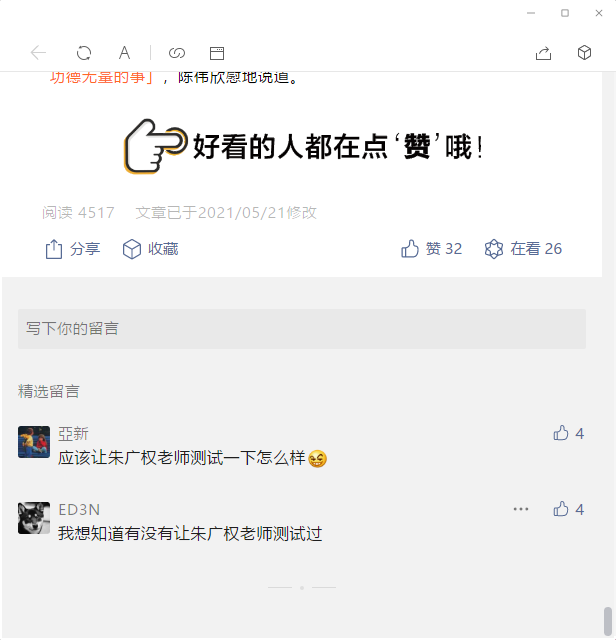 阅读行最后的一些字符不是数字
阅读行最后的一些字符不是数字
这样的问题对于人来说非常简单,但是算法很难理解最后的几个字符到底是不是想要的内容,因为它“看到”的就是RGB的颜色值。
总结
通过上面的尝试,我们可以比较准确的定位包含阅读数的行。目前尚待解决的问题是怎么理解哪些内容是数字,然后选中它。目前来看比较简单的方法是对这块区域进行ocr,然后后处理。这也是后续的尝试方向。
另外在实现的过程中,我们也会发现对于人类来说很简单的事情要算法实现是多么麻烦,也许我们可以把这个做成一个“框架”,用一种简单的描述语言来模糊的定义控制动作?
- 显示Disqus评论(需要科学上网)