一个NLP从业者关于ChatGPT的思考。
最近ChatGPT非常火,作为一个自然语言处理领域的老兵,我有些后知后觉。有两个原因:一是工作比较忙;二是最近没有关注学术界的进展。工作忙所以没有关注学术界的进展,这只是借口。真正的原因是在BERT这种大规模预训练语言模型+微调的范式在2018年底提出并在2019年席卷整个NLP领域之后,我有一种没有什么可以做的感觉。这当然不是说NLP的问题都已经解决了,所以没什么值得再做了。恰恰相反,这种方式虽然在很多NLP任务上都极大的提升了SOTA,但是我们看到的各种自然语言交互系统——比如智能音箱或者智能座舱,还是像人工智障。我一直认为人工智能是可以实现的(请参考《人工智能能否实现?》),但是我认为BERT这种大规模预训练语言模型+微调的模式并不是很有希望的实现途径。同时我对GPT这种生成的语言模型也没有关注,因为从传统的文本分类、相似度计算和实体识别等任务上,BERT+微调一直比GPT+微调效果更好。即使是GPT-3,它也“不敢”去那些任务集上刷分,而是强调Zero Shot或者Few Shot Learning的优势。但这个“理论”上的优势在业界落地时并不成立,因为对于每一个任务标注几千甚至上万的训练数据成本并没有那么高。
ChatGPT出来之后,一开始以为是炒作,因为AI领域(包括其它创新领域)的炒作太多了,各种自媒体动不动就是震惊和突破的标题,让我养成了怀疑的习惯。后来试用了一下,确实是被”震惊“到了。以前的各种对话机器人都试过,自己也做过很多类似的系统。即使是投入大量人工标注和工程优化后看起来闲聊很强的小冰,和ChatGPT相比都可以用智障来形容。于是开始搜集最近的一些文章试图理解它的原理,一开始被各种新概念搞得云里雾里,比如思维链(Chain of Thought)、涌现能力(Emergent Ability)和编辑记忆(Editing Memory)。在这些概念的包围下,我非常兴奋,真正的人工智能似乎马上就要实现了。但在我更加仔细的阅读相关文献,了解了更多细节后我又变得冷静下来。对于ChatGPT,我认为这是一个新的范式变化,会带来很多新的应用场景也会改造和提升很多老的应用。它的统一大模型思路更加趋近于通用人工智能(AGI)的目标,而且超大的语言模型一定程度上学到了很多语言学知识和世界知识,从而展现出一定的推理能力。但是那些新奇的概念并没有那么神奇,而且我相信人类的智能也没有想象中那么神奇。AlphaGo把下围棋拉下了神坛,ChatGPT开始(但是还没有完全)把语言理解和沟通拉下了神坛。这只是冰山一角,语言和文字背后的智能才是关键。ChatGPT还有很长的路要走,而且当前这种方式也不一定能走通。但它的意义非常重大——它给了我们(至少是我个人)一些信心,让我们相信我们终将会制造出和人一样甚至比人更智能的机器。不过要实现这一点,我们首先得把ChatGPT拉下神坛,真正的理解它的原理。
文章比较长,只关注ChatGPT相关技术的读者可以跳到chatgpt原理或者关于chatgpt的思考。
目录
- 自然语言处理领域的范式变迁
- ChatGPT原理
- 关于ChatGPT的思考
- ChatGPT的应用和技术改进点
自然语言处理领域的范式变迁
2006年是深度学习发展的一个重要里程碑,加拿大多伦多大学的Geoffrey Hinton等人提出了一种基于多层神经网络的训练方法,被称为“深度信念网络”(Deep Belief Networks,DBN)。这种方法克服了传统神经网络训练过程中的困难,使得训练更深的神经网络成为可能,从此开启了深度学习的时代。
深度学习时代
词向量(Word Embedding)
One-hot编码
2012年之后,随着深度学习在计算机视觉和语音识别等领域的极大成功,自然语言处理领域也逐渐开始使用深度学习的方法。和图像语音等天生的连续信号不同,文本的离散特点给深度学习的应用带来了极大的困难。因为神经网络只能处理连续的输入,为了能够处理离散的输入,我们需要对其进行编码。最简单的方式就是使用one-hot编码方式。假设我们的词典大小是4(当然实际通常是很多,至少几万),如下图所示,每个词对应一个下标。每个词都用长度为4的向量表示,只有对应的下标为1,其余都是零。比如上面的例子,第一个词是[1, 0, 0, 0],而第三个词是[0, 0, 1, 0]。
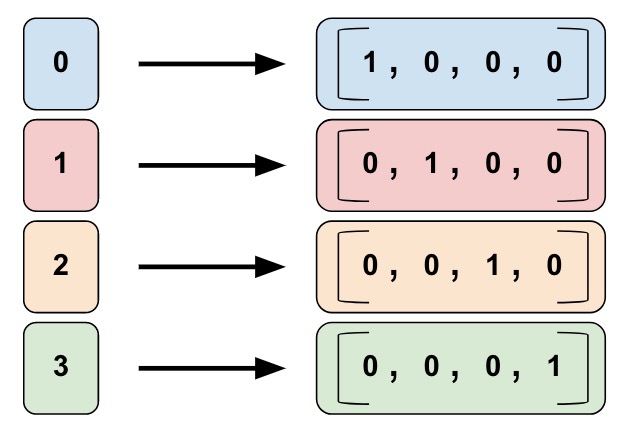 图:one-hot表示法
图:one-hot表示法
对于one-hot向量来说,相同的词距离是0,而不同的词距离是1。这显然是有问题的,因为cat和dog的距离肯定要比cat和apple要远。但是在one-hot的表示里,cat和其它任何词的距离都是1。
one-hot的问题在于它是一个高维(通常几万甚至几十万)的稀疏(只有一个1)向量。我们希望用一个低维的稠密的向量来表示一个词,我们期望每一维都是表示某种语义。比如第一维代表动物(当然这只是假设),那么cat和dog在这一维的值都比较大,而apple在这一维的值比较小。这样cat和dog的距离就比cat和apple要近。
神经网络语言模型
我们需要的是一个低维稠密的词向量,并且两个语义相似词的词向量在这个向量空间距离比较接近,而语义差别大的词在空间距离比较远。那么我们怎么学习到比较好的词向量呢?最早的词向量其实可以追溯到神经网络语言模型。但是首先我们来了解一下语言模型的概念和传统的基于统计的N-Gram语言模型。这些基础概念对于理解后面的大规模语言模型也是至关重要的。
给定词序列$w=w_1,…,w_K$,语言模型会计算这个序列的概率,根据条件概率的定义,我们可以把联合概率分解为如下的条件概率:
\[P(w)=\prod_{k=1}^{K}P(w_k|w_{k-1}, ..., w_1)\]实际的语言模型很难考虑特别长的历史,通常我们会限定当前词的概率只依赖它前面的N-1个词,这就是所谓的N-Gram语言模型:
\[P(w)=\prod_{k=1}^{K}P(w_k|w_{k-1},...,w_{k-N+1})\]在实际的应用中N的取值通常是2~5。我们通常用困惑度(Perplexity)来衡量语言模型的好坏:
\[\begin{split} H & = - \underset{K \to \infty} {lim}\frac{1}{K} log_2 P(w_1,...,w_K) \\ & \approx \frac{1}{K} \sum_{k=1}^{K} log_2 (P(w_k|w_{k-1},...,w_{k-N+1})) \end{split}\]N-Gram语言模型可以通过最大似然方法来估计参数,假设$C(w_{k−2} w_{k−1} w_k)$表示3个词$(w_{k−2} w_{k−1} w_k)$连续出现在一起的次数,类似的$C(w_{k−2} w_{k−1})$表示两个词$w_{k−2} w_{k−1}$连续出现在一起的次数。那么:
\[P(w_k|w_{k-1}w_{k-2})=\frac{C(w_{k−2} w_{k−1} w_k)}{C(w_{k−2} w_{k−1})}\]最大似然估计的最大问题是数据的稀疏性,如果3个词没有在训练数据中一起出现过,那么概率就是0,但不在训练数据里出现不代表它不是合理的句子。实际一般会使用打折(Discount)和回退(Backoff)等平滑方法来改进最大似然估计。
N-Gram语言模型有两个比较大的问题。第一个就是N不能太大,否则需要存储的N-gram太多,因此它无法考虑长距离的依赖。比如”I grew up in France… I speak fluent _.”,我们想猜测fluent后面哪个词的可能性大。如果只看”speak fluent”,那么French、English和Chinese的概率都是一样大,但是通过前面的”I grew up in France”,我们可以知道French的概率要大的多。这个问题可以通过后面介绍的RNN/LSTM/GRU等模型来一定程度的解决,我们这里暂时忽略。
另外一个问题就是它的泛化能力差,因为它完全基于词的共现。比如训练数据中有”我 在 北京”,但是没有”我 在 上海”,那么$p(上海|在)$的概率就会比$p(北京|在)$小很多。但是我们人能知道”上海”和”北京”有很多相似的地方,作为一个地名,都可以出现在”在”的后面。这个其实和前面的one-hot问题是一样的,原因是我们把北京和上海当成完全两个不同的东西,但是我们希望它能知道北京和上海是两个很类似的东西。
通过把一个词表示成一个低维稠密的向量就能解决这个问题,通过上下文,模型能够知道北京和上海经常出现在相似的上下文里,因此模型能用相似的向量来表示这两个不同的词。
神经网络如下图所示。
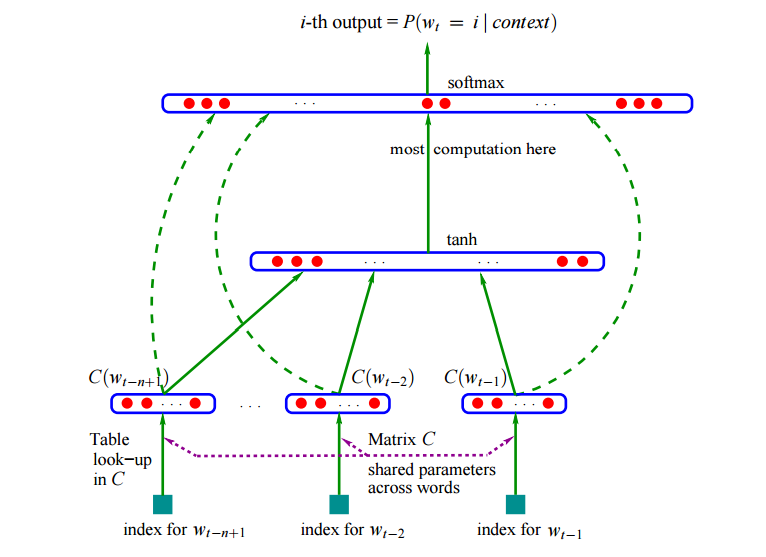 图:神经网络语言模型
图:神经网络语言模型
这个模型的输入是当前要预测的词,比如用前两个词预测当前词。模型首先用lookup table把一个词变成一个向量,然后把这两个词的向量拼接成一个大的向量,输入神经网络,最后使用softmax输出预测每个词的概率。
Word2Vec
我们可以使用语言模型(甚至其它的任务比如机器翻译)来获得词向量,但是语言模型的训练非常慢(机器翻译就更慢了,而且还需要监督的标注数据)。词向量是这些任务的一个副产品,而Mikolov等人提出Word2Vec直接就是用于训练词向量,这个模型的速度更快。
Word2Vec的基本思想就是Distributional假设(hypothesis):如果两个词的上下文相似,那么这两个词的语义就相似。上下文有很多粒度,比如文档的粒度,也就是一个词的上下文是所有与它出现在同一个文档中的词。也可以是较细的粒度,比如当前词前后固定大小的窗口。比如下图所示,written的上下文是前后个两个词,也就是”Portter is by J.K.”这4个词。
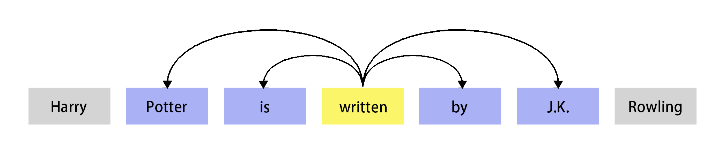 图:词的上下文
图:词的上下文
除了我们即将介绍的Word2Vec,还有很多其它方法也可以利用上述假设学习词向量。所有通过Distributional假设学习到的(向量)表示都叫做Distributional表示(Representation)。
注意,还有一个很像的术语叫Distributed表示(Representation)。它其实就是指的是用稠密的低维向量来表示一个词的语义,也就是把语义”分散”到不同的维度上。与之相对的通常是one-hot表示,它的语义集中在高维的稀疏的某一维上。
我们再来回顾一下word2vec的基本思想是:一个词的语义可以由它的上下文确定。word2vec有两个模型:CBOW(Continuous Bag-of-Word)和SG(Skip-Gram)模型。我们首先来介绍CBOW模型,它的基本思想就是用一个词的上下文来预测这个词。这有点像英语的完形填空题——一个完整的句子,我们从中“抠掉”一个单词,然后让我们从4个选项中选择一个最合适的词。和真正完形填空不同的是,这里我们不是做四选一的选择题,而是从所有的词中选择。有很多词是合适的,我们可以计算每一个词的可能性(概率)。关于word2vec的更多细节请参考Word Embedding。
从DNN到CNN再到RNN
有了比较好的Word Embedding(比如Word2Vec)之后,在面对一个新的任务时通常有两种做法来利用这些Word Embedding:特征提取器和参数初始化。如果这个新任务的训练数据很少,我们通常把从大规模无监督语料训练的Word Embedding作为特征提取器来使用,把这个Embedding固定下来,然后在之上增加一些神经网络层,训练的时候Embedding不动,只是学习这些新增的神经网络的参数。如果训练数据较多,我们可以用Word Embedding来作为Embedding的初始值,但是新任务的训练数据也会反向传播过来更新Embedding的值。
CNN在NLP的应用
最早使用的就是全连接的神经网络,后来广泛用于计算机视觉的卷积神经网络也被用于自然语言处理任务。不过自然语言处理的很多任务的输入(包括输出)都是变长的,而全连接网络或者卷积网络只能处理定长的输入。为了解决这个问题,要么就是把输入padding到一个较大的固定长度,要么通过pooling(比如max-pooling)把变长的一组特征变成一个特征。比如下图的网络结构常被用于文本分类:
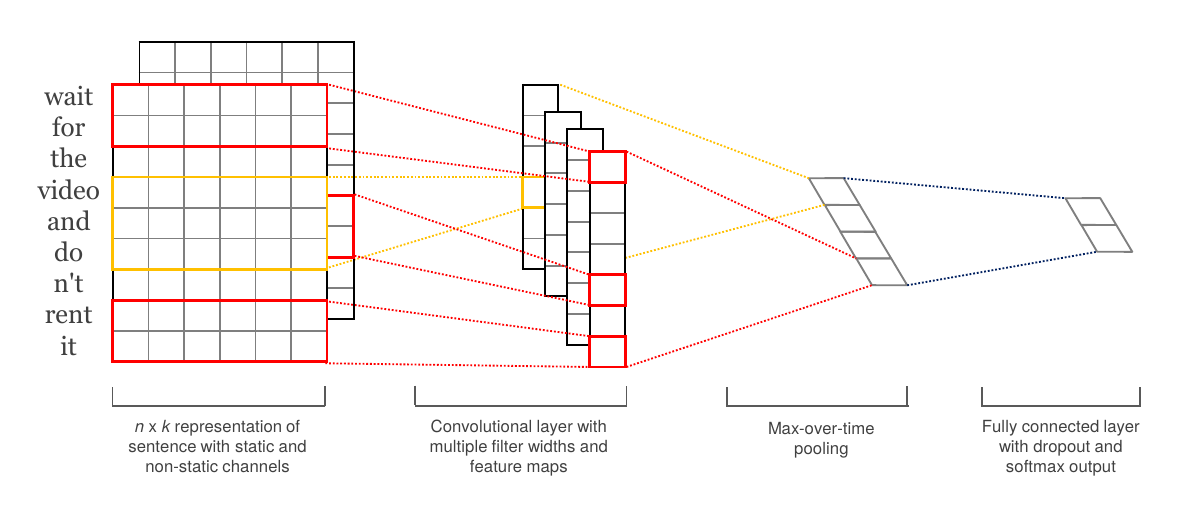 图:Convolutional Neural Networks for Sentence Classification
图:Convolutional Neural Networks for Sentence Classification
CNN的优点就是速度比较快,而且能够捕获局部的特征,这对于简单的任务来说就足够了。所以通常可以用来做一个快速应用的基线系统。
RNN、LSTM和GRU
DNN和CNN假设所有的输入是相互独立的,对于某些任务来说这不是一个好的假设。比如你想预测一个句子的下一个词,知道之前的词是有帮助的。而RNN的特点是利用时序的信息,RNN被称为循环的(recurrent)原因就是它会对一个序列的每一个元素执行同样的操作,并且之后的输出依赖于之前的计算。我们可以认为RNN有一些“记忆”能力,它能捕获之前计算过的一些信息。理论上RNN能够利用任意长序列的信息。
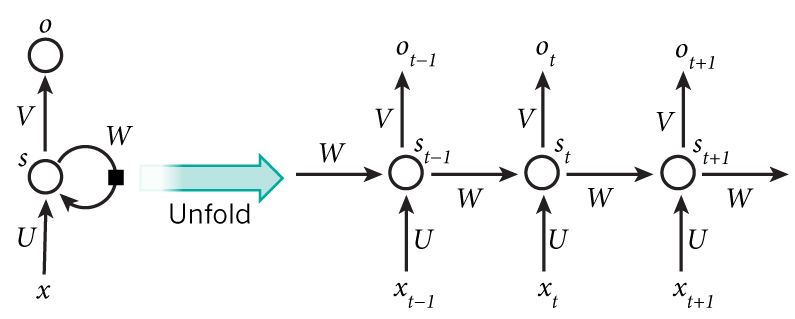 图:RNN展开图
图:RNN展开图
上图显示了怎么把一个RNN展开成一个完整的网络。比如我们考虑一个包含5个词的句子,我们可以把它展开成5层的神经网络,每个词是一层。RNN的计算公式如下:
-
$x_t$是t时刻的输入。
-
$s_t$是t时刻的隐状态。
它是网络的“记忆”。 $s_t$的计算依赖于前一个时刻的状态和当前时刻的输入: $s_t=f(Ux_t+Ws_{t−1})$。函数f通常是诸如tanh或者ReLU的非线性函数。$s_{−1}$,这是用来计算第一个隐状态,通常我们可以初始化成0。
-
$o_t$是t时刻的输出。
有一些事情值得注意:
-
你可以把$s_t$看成是网络的“记忆”。
$s_t$ 捕获了从开始到前一个时刻的所有(感兴趣)的信息,输出 $o_t$ 只基于当前时刻的记忆。不过实际应用中 $s_t$ 很难记住很久以前的信息。
-
参数共享
传统的神经网络每层使用不同的参数,而RNN的参数(上文的U, V, W)是在所有时刻共享(一样)的。我们每一步都在执行同样的操作,只不过输入不同而已。这种结构极大的减少了我们需要学习的参数。
-
每一个时刻都有输出
每一个时刻都有输出,但我们不一定都要使用。比如我们预测一个句子的情感倾向是我们只关注最后的输出,而不是每一个词的情感。类似的,我们也不一定每个时刻都有输入。RNN最主要的特点是它有隐状态(记忆),它能捕获一个序列的信息。
但是最原始的RNN训练时经常遇到梯度消失或者梯度爆炸的问题,为了解决这个问题,LSTM/GRU引入了门控机制来。LSTM网络如下图所示:
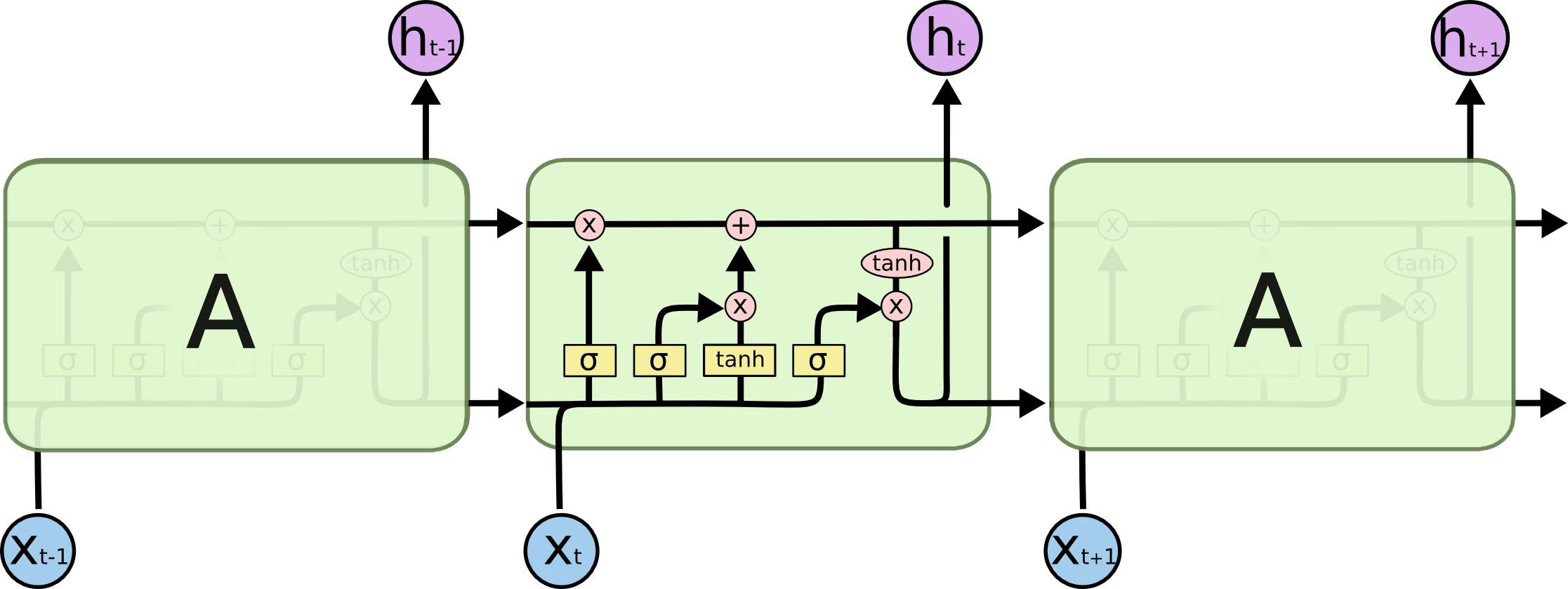 图:LSTM
图:LSTM
关于RNN、LSTM和GRU的更多信息可以参考循环神经网络简介。
Seq2Seq和Attention机制
Seq2Seq问题和Encoder-Decoder框架
除了输入,很多NLP任务的输出也是变长的,比如机器翻译和自动摘要等任务。这类问题也被叫做Seq2Seq问题,因为它的输入是一个序列(Sequence),输出是另外一个序列。在深度学习流行之前,这类问题通常很难解决,而且解决方法也非常复杂。而在深度学习时代,大家通常用Encoder-Decoder框架来解决Seq2Seq的问题。
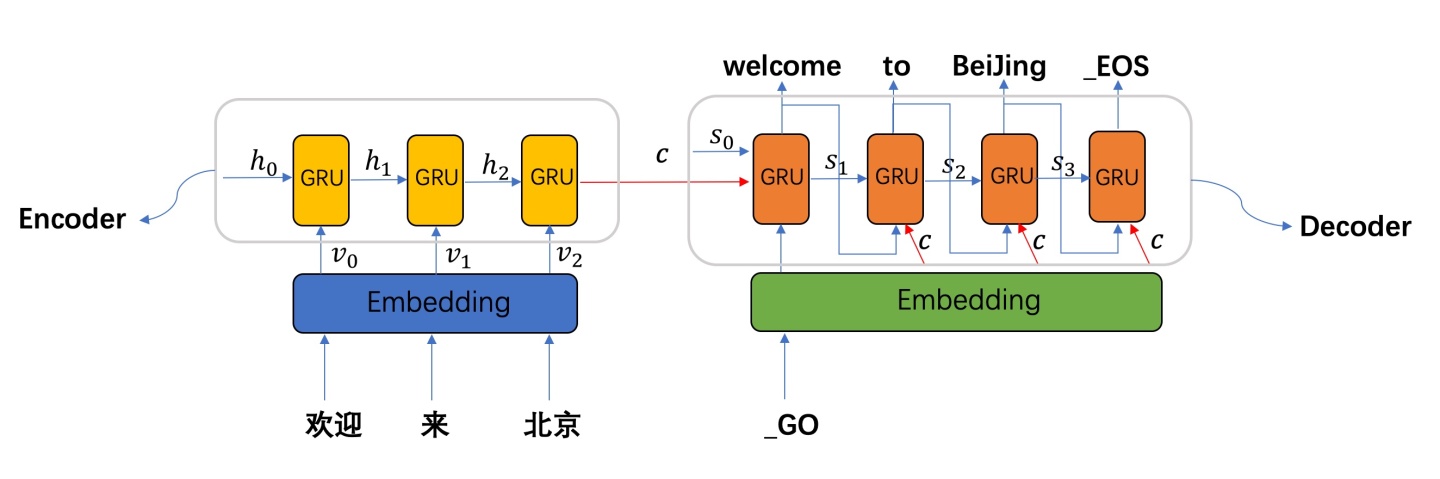 图:Seq2Seq的机器翻译(图片来自https://zhuanlan.zhihu.com/p/57155059)
图:Seq2Seq的机器翻译(图片来自https://zhuanlan.zhihu.com/p/57155059)
在这个框架里有一个Encoder和Decoder(通常是多层的LSTM或者GRU),Encoder负责”理解”输入的内容,把输入序列编码成一个向量表示(最后时刻的隐状态)。而Decoder的初始状态就是Encoder的输出,并且采用自回归的方式进行解码。比如上图的例子,Encoder会编码”欢迎 来 北京”的语义到一个向量c,然后用c这个向量驱动Decoder解码。Decoder的第一个输入是特殊的”_GO”,然后输出”Welcome”,接着把”Welcome”作为第二个时刻的输入,输出”to”,再把”to”作为第三个时刻的输入,得到”Beijing”,最后把”Beijing”作为第四个时刻的输入,得到”_EOS”。这个时候模型发现输出了特殊的”_EOS”,就解码结束。
Attention机制
但是把整个句子的完整语义编码到Encoder最后一个时刻的隐状态里是非常困难的事情,所以后来引入了Attention机制。它的基本思想是:Encoder会把每一个输入的Token(可以理解为词)都编码成一个向量,在Decoder进行t时刻计算的时候,除了t-1时刻的隐状态和当前时刻的输入,注意力机制还可以参考Encoder所有时刻的输入。比如上面输入是”欢迎 来 北京”,那么在翻译第一个词的注意力可能是这样:(0.7,0.2,0.1),表示当前最关注的是输入的第一个词,但是也会参考其它的词。假设Encoder的3个输出分别是$y_1,y_2,y_3$,那么我们可以用attention概率加权得到当前时刻的context向量$0.7y_1+0.2y_2+0.1y_3$。
Attention机制也可以认为是一种软的对齐(soft alignment),比如上面的例子,”Welcome”以0.7的概率和”欢迎”对齐,下图是中英翻译通过Attention对齐的例子:
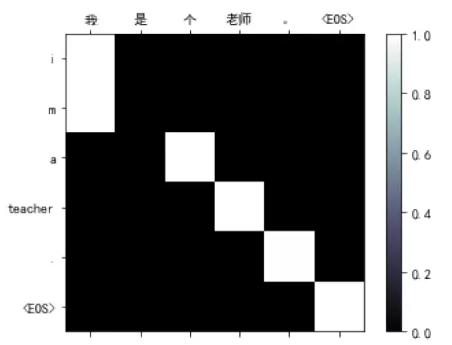 图:Attention实现翻译的对齐
图:Attention实现翻译的对齐
Transformer
Transformer解决什么问题
LSTM/GRU+Attention的方法很快在机器翻译等Seq2Seq问题上流行起来。但是LSTM/GRU存在两个问题:第一个就是RNN的编码器存在顺序依赖,无法充分利用GPU加速;第二个问题就是RNN是单向的模型,无法利用双向的文本信息。第一个问题比较好理解,因为RNN在计算第t个时刻的输入时依赖t-1时刻的隐状态,t-1时刻的计算又依赖t-2时刻的隐状态,所以很难并行计算。第二个问题我们来看下面的例子:
 图:需要双向上下文的例子
图:需要双向上下文的例子
这里假设我们的模型需要做一个指代消解的任务,也就是判断上面两个句子中”it”指代的到底是”animal”还是”street”。从语义分析,我们知道第一个”it”指代”animal”,因为只有”animal”能够”tired”,而”street”不能”tired”。类似的,第二个句子中的”it”指代”street”因为后面的”narrow”。如果我们从前往后读第一个句子”The animal didn’t cross the street because it”,只读到这里我们是无法判断”it”到底指代哪个词。如果反过来读”it was too tired.”,那更是无法判断,因为能够”tired”的动物太多了。
从上面的例子看出,我们想要准确的理解一个词,它的前后文都是很很重要的。而RNN不管是前向的还是后向的都无法解决这个问题。有读者可能会问那双向的RNN或者多层的双向RNN能不能解决这个问题?理论上多层的双向RNN是可以解决这个问题的,但是Transformer直接就可以建模双向依赖关系,从而更容易学习到前后上下文的语义关系。
Self Attention
Transformer最早来自论文”Attention is All you Need”,它的想法是使用Self Attention来替代LSTM/GRU。当然Decoder到Encoder的普通Attention还是需要的,这样的结构就完全没有了RNN模型,所以作者认为以后我们只需要Attention机制就够了。这个标题起得很激进,不过从未来的发展来说,RNN之类模型确实都被Transformer取代了。但取代的深层原因是后面我们要聊的BERT这类大规模预训练模型+微调范式全面取代了之前的范式所导致的。因为Transformer是后面最主流的模型,所以下面花一些时间简单介绍一下它最核心的Self Attention机制。
前面介绍过,注意力机制可以让网络给序列中的每一个元素赋予不同的权重或者说注意力。对于文本序列来说,元素指的是每个Token的Embedding,这是一个固定维度的稠密向量。对于标准的BERT模型来说,这个向量是768维的。而self的意思是,计算注意力的输入是这些向量序列本身。这主要是和Encoder-Decoder框架下的Decoder对Encoder的注意力相区别,在Encoder-Decoder框架下,Decoder在解码的时候会“注意”到Encoder的隐状态序列,从而利用这些信息更好的解码。而对于BERT来说,它本身只有一个Encoder,所以它是在编码每一个Token时“注意”到自己所在的向量序列的每一个Token(当然也包括它自己的之前的隐状态)。
自注意力机制的核心思想是用整个Token序列的Embedding来计算当前Token的Embedding,方法是把整个Token序列的Embedding加权求和。形式化的语言来描述:假设整个Token的Embedding是$x_1,x_2,…$,通过自注意力机制计算后可以得到新的Token Embedding序列$x_1’, x_2’,….$,计算方法为:
$x_i’=\sum_{j=1}^{n}w_{ji}x_j$
加权系数$w_{ji}$叫做注意力权重(attention weight)并且满足$\sum_{j=1}^{n}w_{ji}=1$。
用整个序列的Embedding来加权求和得到每一个Token的Embedding有什么好处呢?我们来看一个例子。考虑”flies”这个词,大家可能会马上想到那讨厌的虫子,但是如果有更多上下文,比如”time flies like an arrow”,我们马上会意识到flies应该是一个动词。因此,我们在计算flies的Embedding时,应该考虑整个上下文的Embedding,尤其是”time”和”arrow”这两个词应该贡献更大的权重。这种考虑上下文的Embedding叫做contextual embedding,它最早可以追溯到ELMo这样的模型。下图的例子显示了”flies”在不同的上下文的不同Embedding:
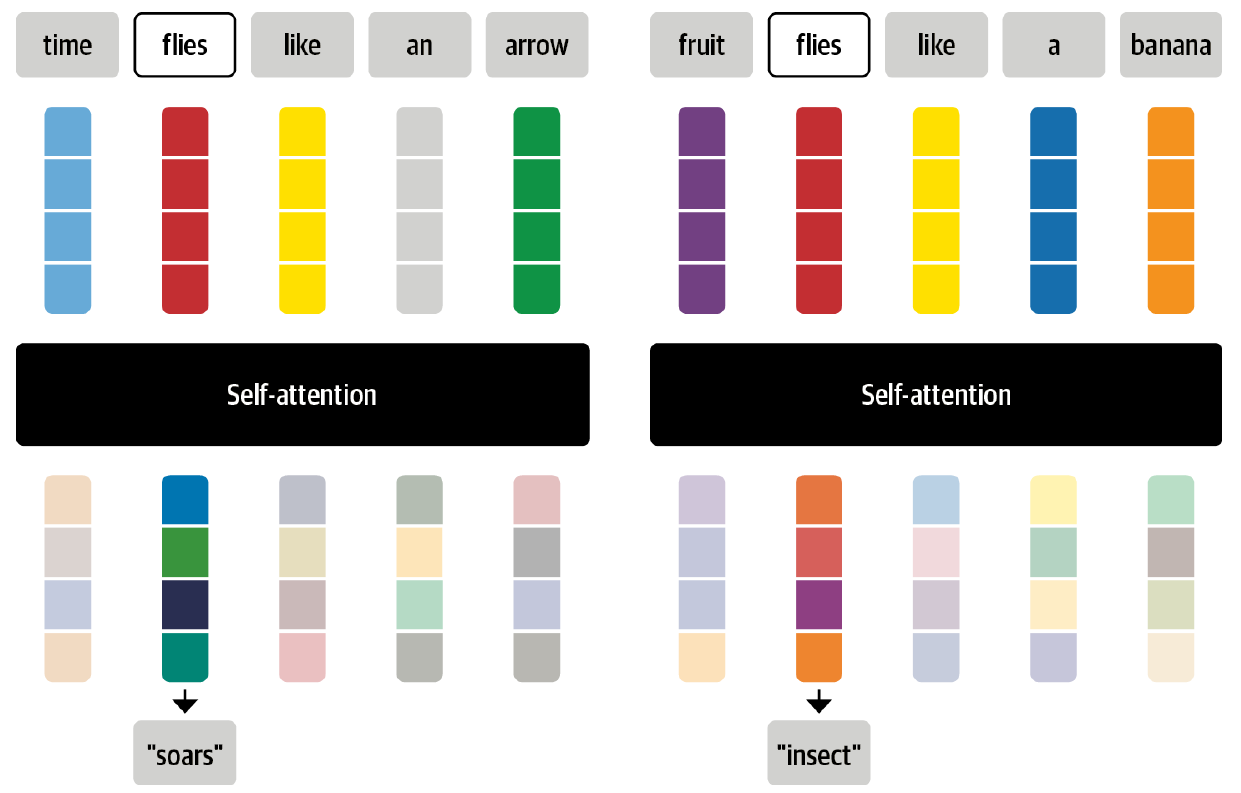
关于Transformer模型的更多细节读者可以参考Transformer图解和Transformer代码阅读。
大规模预训练语言模型+微调的时代
当时存在的问题
监督数据不足
经过上一个范式的变迁,有了RNN和Transformer这样强大的模型和Encoder-Decoder这样的框架,大部分NLP任务都采用了深度学习方法来解决。但是和语音识别或者计算机视觉等很多任务相比,采用了深度学习方法比之前的效果有所提升,但是并不明显。原因当然很多,比如文本本身就是高度抽象的符号系统,它的特征相比图像和语音这类信号更加容易提取,所以一个精心设计特征的传统机器学习模型并不比深度学习的模型差(太多)。其实这句话也可以反过来说:NLP采用了深度学习方法后虽然结构更简单,不需要(太多)特征工程,但是效果并没有比传统的方法好太多。为什么是这样呢?很多人认为可能是NLP是更”高级”的认知智能,而计算机视觉则是较”低级”的感知智能。不过我一直并不这么认为,我认为当时的原因在于NLP任务太多太分散,而单个任务的训练数据太少。我们对比一下语音识别和图像分类这两个在语音和视觉领域经典的任务的标注数据量。早在2012年AlexNet参加LSVRC挑战赛的数据就有1000个分类100万图片。而语音识别在学术界开源的数据从几百小时逐渐增加到几千乃至上万小时,而工业界的系统用到了几十万小时的数据。而NLP领域除了机器翻译这个任务的数据量达到百万句对之外,大部分任务的训练数据都是几千到几十万的规模。这里的主要原因就是NLP的任务很零碎,而且同一个任务很难跨场景应用。
中间任务多
在深度学习流行之前,NLP领域存在大量的中间任务,比如中文分词、词性标注、NER、句法分析、指代消解、语义Parser等,这类任务一般并不解决应用中的实际需求,而是作为实际任务的中间阶段或者辅助阶段存在的。几乎没有需求说,我要一个句法Parser,把这个句子的句法分析树给用户看看,用户不需要看到这些NLP的中间阶段处理结果,他只关心某个具体任务你有没有干好。为什么需要这么多中间的任务呢?原因就是之前的方法太过复杂,需要把一个复杂的问题分解成很多的模块,然后组合成一个解决方案。比如传统的对话系统:
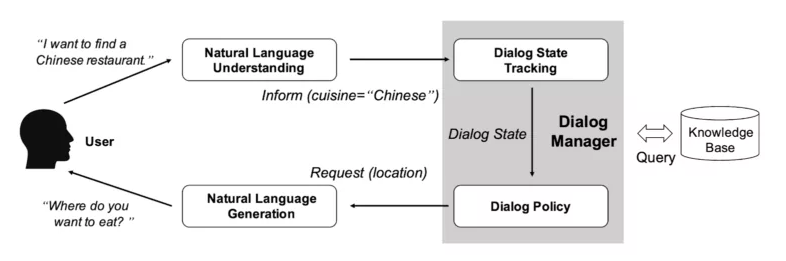 图:传统的对话系统框架
图:传统的对话系统框架
我们需要把对话系统分成自然语言处理(NLU)、对话管理(Dialog Manager, DM)和自然语言生成(NLG)等三个模块,而每一个模块都非常复杂,比如一个典型的对话系统NLU可能包括:
- 文本预处理
- 分词
- 命名识别识别
- 上下文理解(指代消解和补全)
下面是小冰的架构图,里面有非常多的模块(其实还没有展开细节):
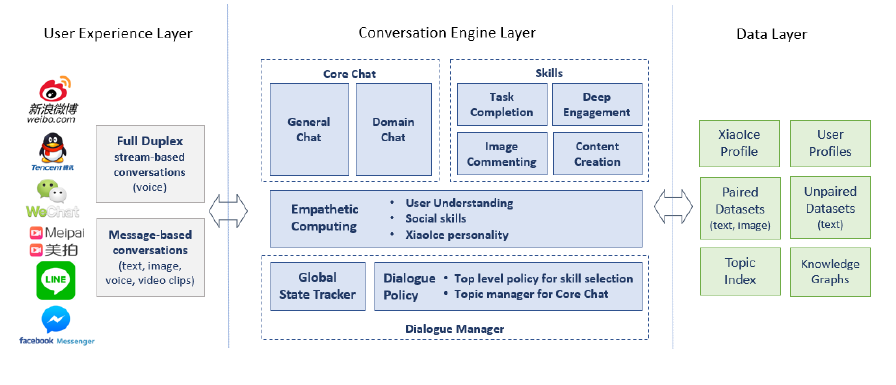 图:小冰的架构
图:小冰的架构
中间任务就不应该出现,而之所以会存在,这是NLP技术发展水平不够高的一种体现。我们后面会看到,ChatGPT的架构其实非常简单,就是一个GPT模型。我们可以看到,在以前很多NLP的会议中会有很多论文解决分词、词性标注、句法分析等中间任务,但是到了现在,基本没有人再研究这些问题了。
解决思路
因为上面的原因,NLP领域没有办法像语音识别那样只解决一个问题,或者像图像那样通过ImageNet有监督的训练一个较好的大模型,然后在新的任务中通过微调的模式利用大模型学到的特征表示,从而可以用很少数量的新任务数据微调得到一个较好的模型。
那么怎么办呢?比较自然的想法就是使用无监督的数据。其实这个思路在Word2Vec时代就已经很流行了——通过Word2Vec学习一个初始化的Word Embedding,然后用具体下游任务的监督数据来微调模型。不过Word2Vec这样的无监督预训练存在两个问题:
- 训练数据太少
- 无法建模上下文
第一个问题的本质时计算效率的问题,因为未标注的文本在互联网上是大量存在的,只不过因为计算能力的限制,Word2Vec这类模型通常只是用少量的wiki数据进行训练。第二个问题就是Word2Vec不能建模上下文,如果改用LSTM等模型,计算有变得复杂很多,所以又回归到计算能力的限制问题。不过随着GPU硬件性能的提升,以及Transformer这样有强大上下文建模能力并且可以充分利用GPU(相对于RNN来说)的模型出现,这些问题很快就不是问题了!
从ELMo到GPT再到BERT
ELMo
最早比较成功的使用有上下文建模能力模型来从无标注的文本中学习上下文相关Embedding的是ELMo。ELMo来自论文”Deep contextualized word representations “,ELMo是Embeddings from Language Models的缩写。它的思路非常简单,就是用海量的数据训练双向LSTM的语言模型。
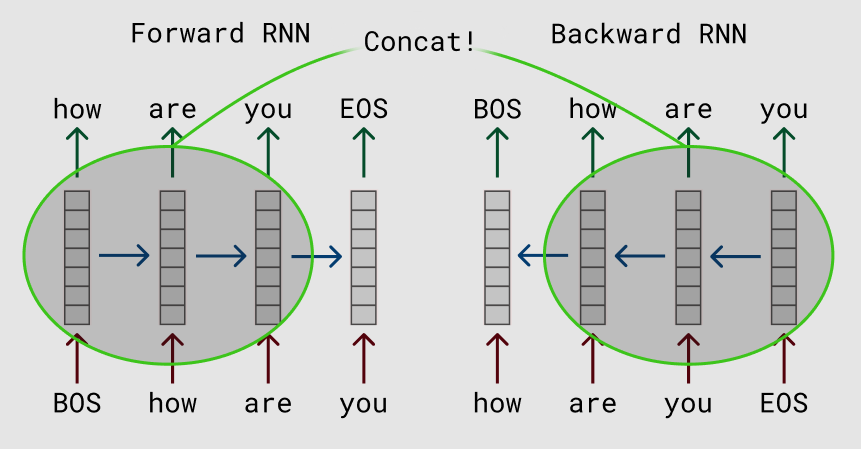 图:ELMo
图:ELMo
训练好的模型就不动了,对于下游的任务,我们用这个LSTM来提取文本的特征,然后在它基础上加一些全连接层,用监督数据微调这些全连接层的参数。ELMo当时的效果非常好,”横扫”了各大NLP的任务榜。AI领域不知什么时候养成了刷榜的习惯,开始其实是不错的,我们可以较客观的对比不同方法。但是后来就变了味道,似乎刷不到SOTA就不是好工作,另外就是很多人为了刷榜,往往用各种tricks去过拟合数据。就像Kaggle比赛,最后的冠军必然是使用了无数tricks(比如刺探数据分布),通常是N个模型的Ensembling超级大模型。
GPT
不过很快GPT(Generative Pre-trained Transformer)就抢占了各大榜单的榜首。GPT的思想其实也非常简单,就是使用Transformer的Decoder来训练一个语言模型。同时采用了微调的策略替代了ELMo的特征提取策略。由于语言模型只能利用上文(不能利用下文)的信息,所以Decoder的Transformer需要对”未来”的数据进行Mask,如下图所示:
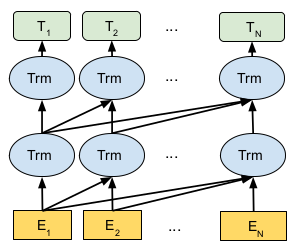 图:GPT使用Masked的Transformer进行语言模型训练
图:GPT使用Masked的Transformer进行语言模型训练
微调的时候根据下游任务输入的个数(一个、两个或者多个)采用不同的方案,如下图所示:
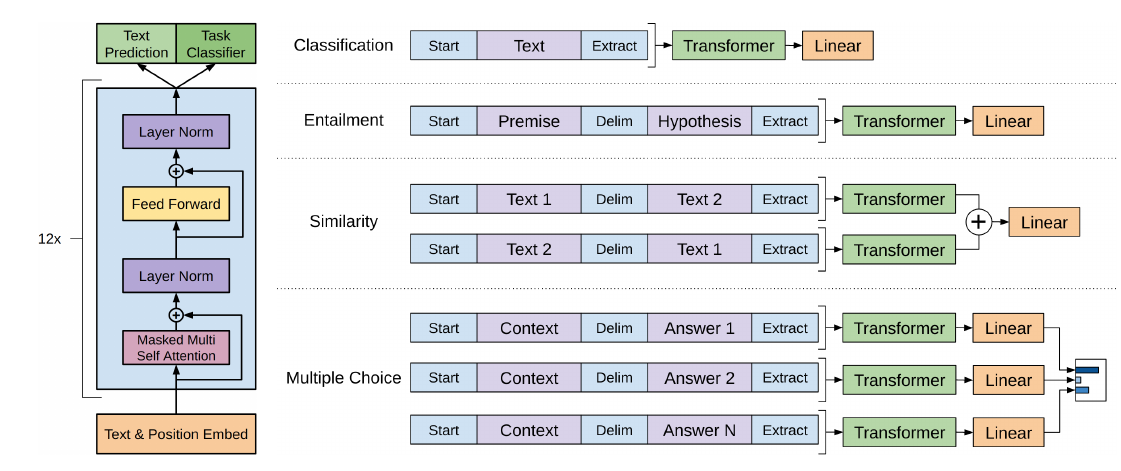 图:GPT的微调
图:GPT的微调
GPT出来后也”横扫”了之前的榜单。OpenAI这家公司也第一次受到了大家的关注。
BERT
可惜GPT在榜首的宝座上屁股还没坐热,就被BERT赶了下来。BERT认为GPT的微调方式很好,但是预训练的语言模型有两个问题:
- Transformer的语言模型是单向的,无法利用整个(下文)句子的信息
- 训练的时候输入是一个句子,但是很多下游任务比如相似度计算和问答等输入是多个句子
为了解决这些问题,BERT把传统的语言模型(Casual Langage Model, CLM)训练改成了Masked Language Model(MLM)。传统的语言模型是根据第一个词预测第二个词、再根据第一个和第二个词预测第三个词;而BERT更像完形填空的题目,随机的遮挡掉句子中的一些词,让模型来预测它们。这样的模型在训练的时候就会利用整个句子上下文的信息。同时为了解决第二个问题,BERT还引入了Next Sentence Prediction(NSP)的任务,让模型预测两个句子是否有前后承接关系,不过后来很多人发现这个任务并不那么重要。
至此,预训练大模型+微调的新范式就席卷整个NLP领域。模型越做越大,预训练数据也越来越多。在这场较量中,BERT模式似乎比GPT模式更胜一筹。渐渐的,GPT系列的模型淡出了各大榜单。工业界应用的都是BERT及其各种变体模型(除了少数Seq2Seq问题,比如机器翻译和自动摘要,使用的是BART或者T5这类Encoder-Decoder预训练模型)。
大规模语言模型+自然语言交互的时代
另辟蹊径
在BERT之后,各大公司都在想办法训练更大的模型去刷榜,国内的很多公司也加入了刷榜的行列。那OpenAI呢,我相信他们也在做类似的事情。如果一切顺利的话,他们新一代的GPT-2应该要把BERT刷下榜单。2019年2月14日(特地挑选的良辰吉日?)OpenAI的GTP-2如期而至,我们来看看官网的宣传文字:
We’ve trained a large-scale unsupervised language model which generates coherent paragraphs of text, achieves state-of-the-art performance on many language modeling benchmarks, and performs rudimentary reading comprehension, machine translation, question answering, and summarization—all without task-specific training.
GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset of 8 million web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than 10X the amount of data.
从宣传材料里并没有刷榜的内容,这和GPT-1的宣传形成了鲜明的对比,下图是GPT-1的blog页面:
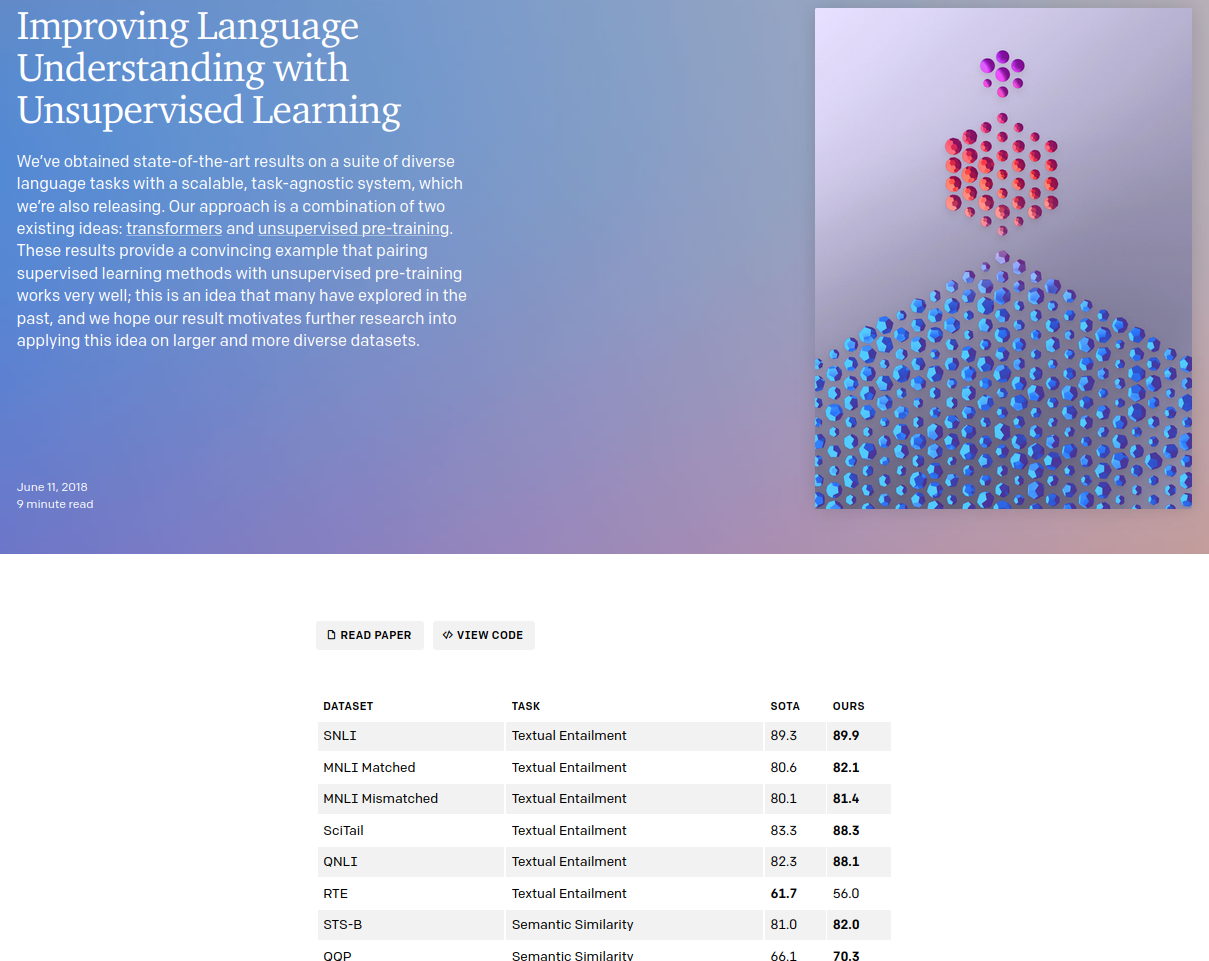 图:GPT的blog
图:GPT的blog
我们可以清楚的看到GPT-1在Textual Entailment和Semantic Similarity等NLP经典任务的各个数据集上的成绩。
因此我们可以推测虽然GPT-2的模型有15亿参数,训练数据是8百万,比GPT-1增加了一个数量级,但是在这些任务上并没有太好的成绩。GPT-2对应的论文标题是《Language Models are Unsupervised Multitask Learners》,这篇文章开启了Prompt Learning的时代。很多调参侠变成了Prompt大师,甚至出现了Prompt工程师这个新职位(当然是炒作的成分居多)。其实Prompt这个词在GPT-2的论文里只出现了一次。原文是这样的:
In order to help it infer that this is the desired task, we condition the language model on a context of example pairs of the format english sentence = french sentence and then after a final prompt of english sentence = we sample from the model with greedy decoding and use the first generated sentence as the translation.
中文的大概翻译是:为了帮助它(GPT-2)推断这是什么任务,我们把语言模型的context设置为一些双语句对,其格式为:”英语句子 = 法语句子”,最后再加上”要翻译的英语句子 =”,然后使用贪心的解码方法得到的句子作为翻译的结果。
是不是感觉很神奇?GPT-2只是学了一个语言模型,我们并没有用很多来微调训练一个翻译模型,而只是给它几个例子,而且这些例子只是作为语言模型的context,根本没有修改GPT-2模型的任何参数,它就”学会”了翻译。
它背后的思想是这样的:其实GPT-2(包括后面的GPT-3)模型通过大量的文本,已经学到了或者说具备了翻译的能力,只不过它并不知道(或者我们没有办法告诉它)这个任务是翻译的任务。如果我们能够通过一种方法告诉它我们要它翻译,它就有能力翻译。听起来还是很神奇?没关系,后面我们会再次详细讨论这个思想。
GPT-3
GPT-3对应论文的标题是《Language Models are Few-Shot Learners》,和前面文章的标题是一脉相承的。前面强调的是Unsupervised,而这篇文章强调的是few-shot(其实也有zero-shot和one-shot,但是效果差一些)。我们首先来看一些新概念,首先是In-context Learning。
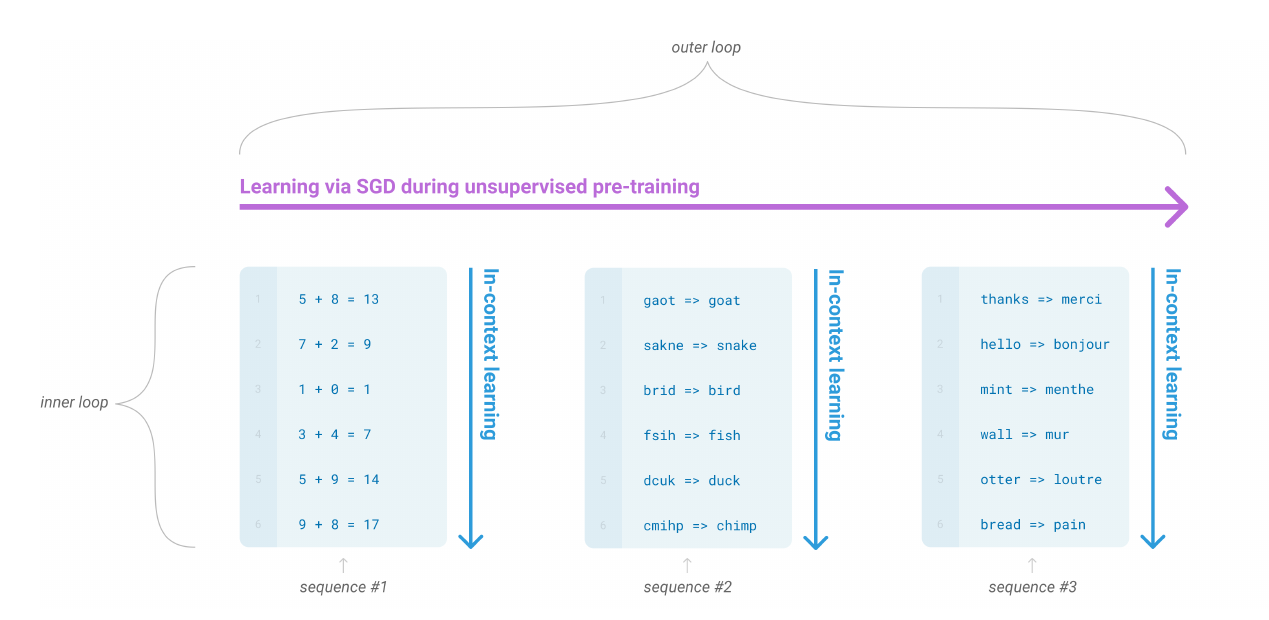 图:In-context Learning
图:In-context Learning
在无监督的预训练阶段,语言模型学会了很多的技能和模式识别能力。在推理的时候它利用这些能力快速的适配到相应的任务上。上图中GPT-3的预训练被叫做outer-loop,它是会使用随机梯度下降算法更新模型的参数的。而图的下面部分有很多具体的任务,针对这些任务的不更新模型参数的”学习”就叫”in-context learning”。具体来说根据提供给模型的信息多少,可以分成zero-shot、one-shot和few-shot。
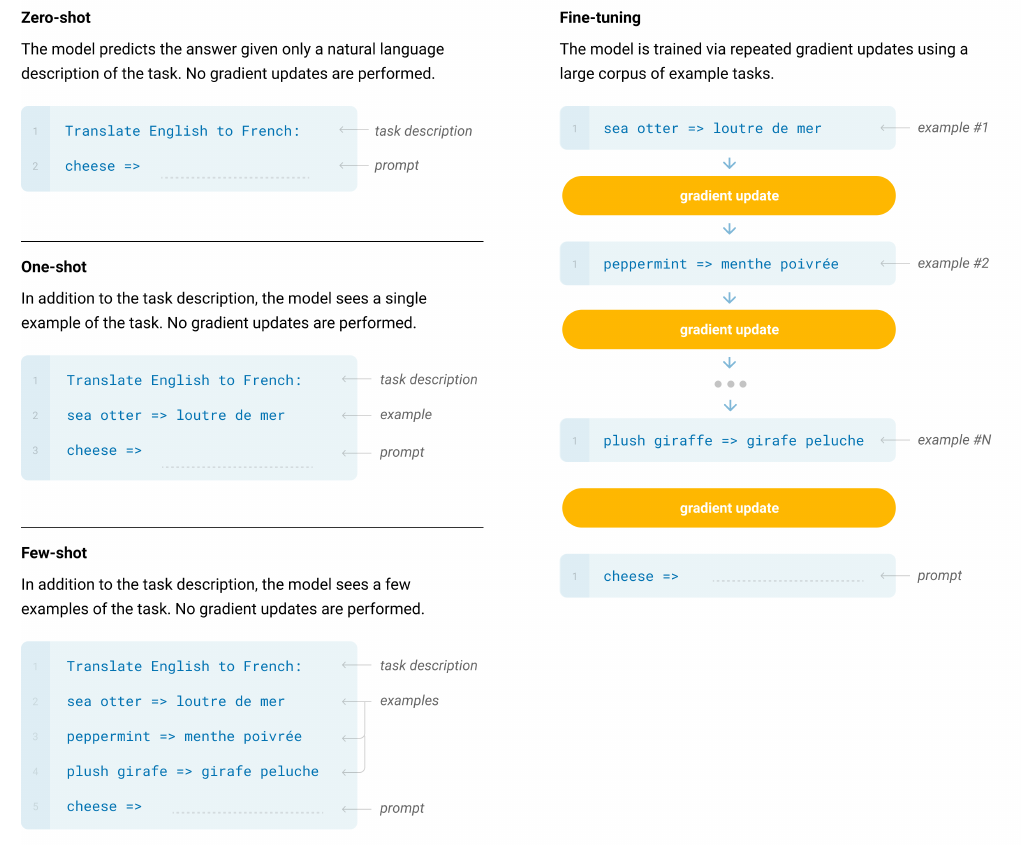 图:Zero-shot、one-shot、few-shot和微调的对比
图:Zero-shot、one-shot、few-shot和微调的对比
Zero-shot Learning
只有任务的自然语言描述,比如上图的翻译例子,给到GPT-3的只有”Translate English to French”这个任务指令(Instruct),然后就加上要翻译的英文”cheese =>”,期望模型能够”理解”这是一个翻译任务并且给出正确的法语翻译。
One-shot Learning
因为机器可能无法很好的通过简单的”Translate English to French”这个指令理解我们让它做的任务是把英语翻译成法语,所以One-shot Learning除了指令之外还给了一个样例,比如上图的”sea otter => loutre de mer”。期望它能通过指令和一个例子,理解这个任务。
Few-shot Learning
和One-shot Learning差别不大,只不过例子多一些,一般也10-100个(太多了没法放到context里,因为GPT-3有最大长度的限制)。
和微调的对比
GPT-3的论文仍然没有做下游任务的微调(不知道是真的没做还是效果不好),文中提到很多任务的SOTA还是BERT+微调模式。但是论文强调的是通过很少量的样本的few-shot Learning,GPT-3就能得到很不错的效果,很多任务都接近微调的SOTA(这些微调模型使用了成千上万的数据)。而且论文认为,BERT+微调模式虽然在下游任务上效果确实比较好,但是它们很可能是过拟合了这个特定的任务,学到了一下非本质的(原文是spurious)特征。对于这个观点,我也是认同的,很多刷榜的文章的方法其实就是过拟合的这个任务的数据分布。
模型大小
下图是GPT-3不同模型的大小,这些模型都使用了300 billion的token来训练:
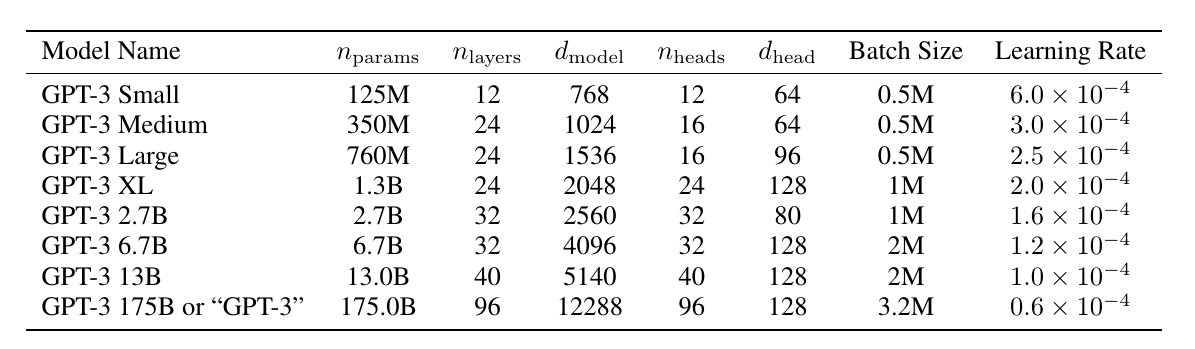 图:不同大小的GPT模型
图:不同大小的GPT模型
训练数据
GPT-3的训练数据相比GPT-2有了很大的增加,GPT-2主要使用40GB的WebText,而GPT-3除了WebText2,还增加了Wikipedia、Books1、Books2和CommonCrawl的数据。原始的CommonCrawl数据是远超其它数据的,但是因为它的数据质量不如其它数据,所以对其它数据进行了加权。比如训练完成时,Wikipedia遍历了3.4次,而CommonCrawl只遍历(抽样)了44%。
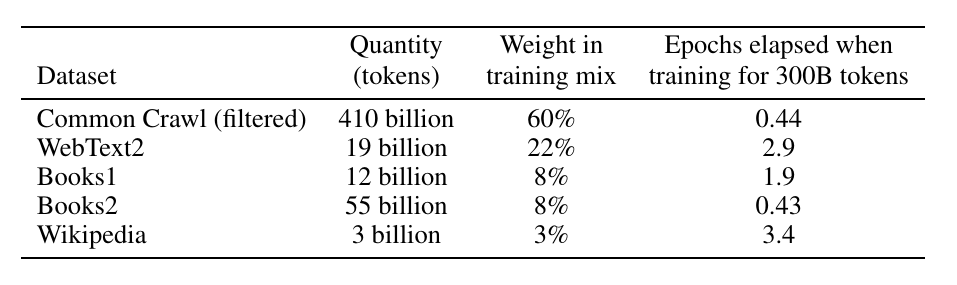 图:GPT的训练数据
图:GPT的训练数据
结果和结论
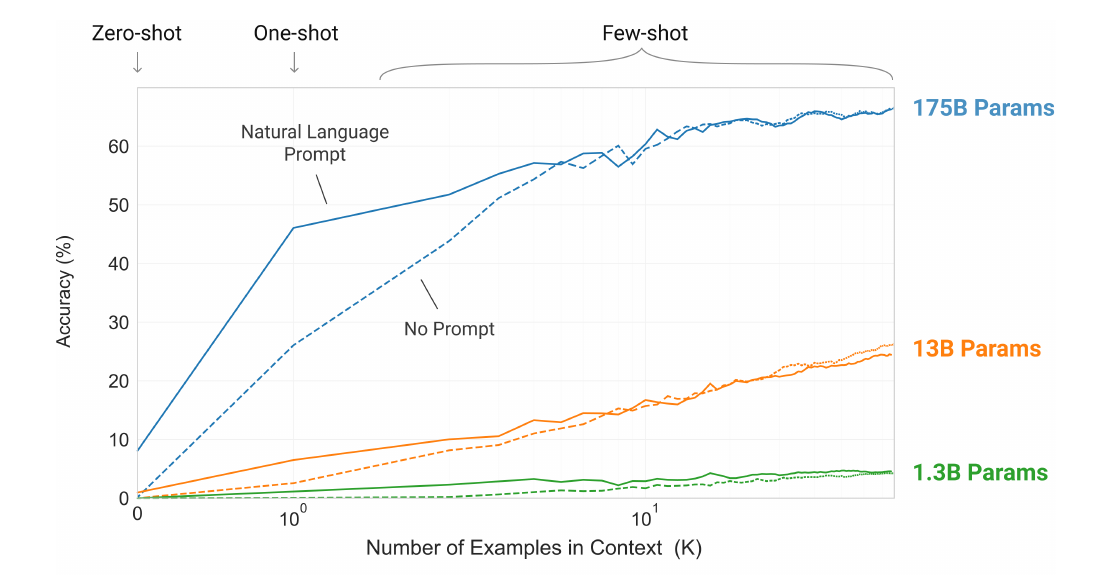 图:大模型能够有效的利用In-context信息
图:大模型能够有效的利用In-context信息
文章的实验比较多,这里是一个典型的例子。作者的结论就是:大模型(比如175B参数的GPT-3)相比小模型(比如1.3B参数的GPT-3),能够更快的通过少量样本学习到这个任务是什么。注意:样本的多少并不会影响GPT-3模型的参数,所以不能说它通过几个例子”学到”了这个任务。而只能说它”理解”了这个任务是什么。那大模型比小模型好是因为它解决问题的能力更强呢?还是理解问题能力更强呢?这篇文章是没有回答的。我觉得两者都是兼而有之的,但是从后面的InstructGPT的文章来看,我觉得理解的作用更大一些,因为后面InstructGPT的小模型也比GPT-3的大模型的效果好。而我们知道InstructGPT只是通过了人类反馈让它理解问题,所以从这个角度来看大模型的理解问题的能力明显要超过小模型。
Prompt-based Learning
基本概念
GPT-3提出了基于大(生成式)模型的Few-Shot Learning之后,出现了所谓的Prompt-based Learning。相比与BERT+微调模式,GPT-3提出的Few-Shot模式更适合领域训练数据很少的场景。这种模式还有一个好处,就是不需要训练(微调)模型,因此不管下游任务有多少,那个大模型是唯一的。不同任务的区别就在于不同的Instruct和Few-Shot Prompting。不过OpenAI并没有太关注怎么Prompting,它后来转向了后面要介绍的RLHF方式。但是另外有一些人比较关注Prompt,并且提出了一种新的方法——Prompt-based Learning。它的想法是:大语言模型通过预训练已经学到了很多知识,我们没有必要根据下游任务去微调它了,只需要用一些Prompt的技巧把它曾经学到的知识提取出来。或者用更拟人化的说法:让它回忆起以前学过的知识。关于Prompt-based Learning有很多方法,我们这里只介绍最简单的方法来了解它的思想。如果对更多方法感兴趣的读者可以参考《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》。
我们以情感分类任务为例,假设需要判断句子”I love this movie.”是正面还是负面的情感。怎么利用已经训练好的大模型的知识呢?一种方法是给它补充一个模板然后让它填空。比如把它变成”I love this movie. Overall it was a [Z] movie.”,让模型预测Z这个词。这样的模板比较适合BERT这样的MLM。根据BERT之前学到的知识,”great”或者”good”等词的概率比较高,而”bad”或者”“horrible”的概率比较低。然后我们根据这些信息就可以判断这个句子的情感是正向的。
上面的例子很简单,但是我们大概可以了解这类方法的思路,那就是通过Prompt的方式来提取大模型里存储的相关知识来完成特定任务。最简单的方法就是上面介绍的基于模板的方式,但是模板从哪里来呢?可以人工手写,也可以做一些模板挖掘甚至自动模板生成,然后用一些训练数据来选择最优的模板。另外除了”离散”的文本模板,也可以是向量化的不能转换成文本的向量模板——因为对于语言模型来说,你前面的Prompt是文字也好,是向量也好,最终都是要变成向量的。而Prompt的向量怎么来呢?很自然的可以微调(训练)得到。
Prompt-based Learning是下一代范式吗?
目前这类方法在学术界研究较多,在业界使用并不多,因为前面说过。虽然Few-Shot Learning有一些优势,但是要说在一个下游任务中标那么几千上万个训练数据成本也没那么高(数据标注人员的工资可比调参或者写Prompt的算法工程师低多了)。从OpenAI的研究思路来看,他们也没有关注这个方法,而是使用了从人类反馈进行强化学习的思路。因为他们的目标是要解决复杂的任务,比如让GPT写一篇关于青蛙王子的小说,这种任务是不可能通过上面的Prompt-based Learning解决的。如果是传统的分类/序列标注甚至抽取式问答等非生成任务,BERT+微调的模式就足够好了。要让大模型”理解”复杂的任务,简单的Prompt甚至Few-Shot Learning都是不够的。所以我个人觉得这类方法有它的一些特点,但是还算不上范式。后面介绍的RLHF才是更值得关注的新方向,那就是通过人类的反馈用强化学习来”理解”任务。
推理、思维链和知识编辑
除了Prompt,可能我们还会听到基于大语言模型的推理(Reasoning)、思维链(Chain of Thought, CoT)Prompting、涌现(Emergent)和Transformer模型的知识(knowledge)编辑这些新概念,似乎非常高深,下面也简单的介绍一下主要的论文。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
这篇文章提出了Chain of Thought(CoT) Prompting这个新概念,其实它的思路看下面这张图就可以了。
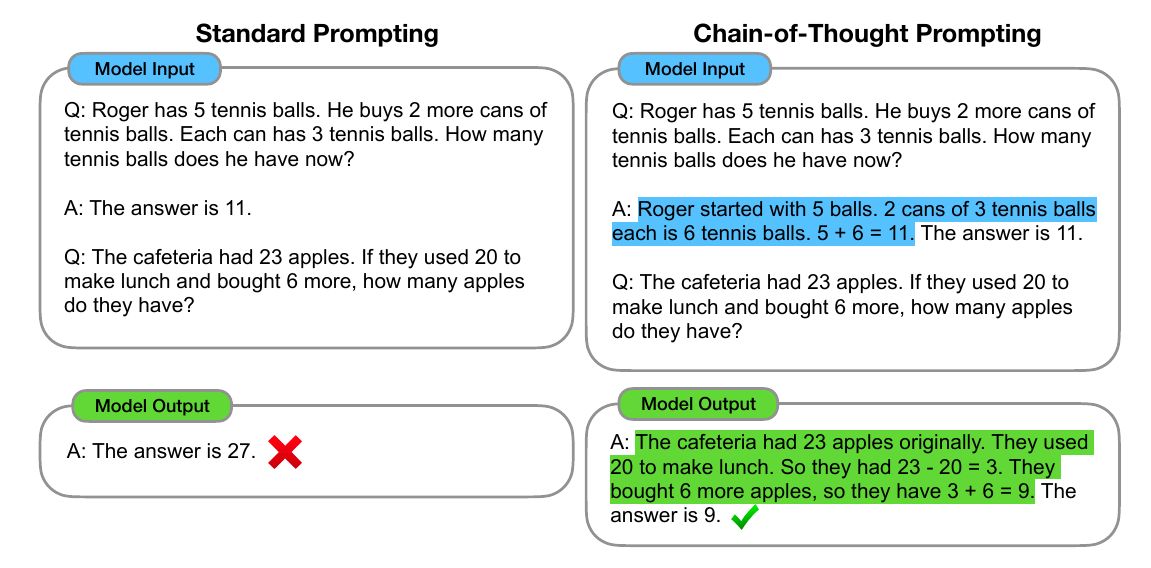 图:CoT Prompting
图:CoT Prompting
比如上图中的例子,需要模型回答的问题是:
Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
如果给它的one-shot例子是:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: The answer is 11.
那么它不能正确回答上面的问题。因为回答这个问题比较复杂,人在解决这个问题的时候需要分成两步来解决。所以CoT的解决办法是one-shot例子的答案也要分成两步,也就是这样:
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
如果给的Prompt是这样分步的解法,那么GPT-3等模型也会”模仿”这种分解方法给出正确的答案:
The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
另外论文也分析了效果和模型大小的关系:
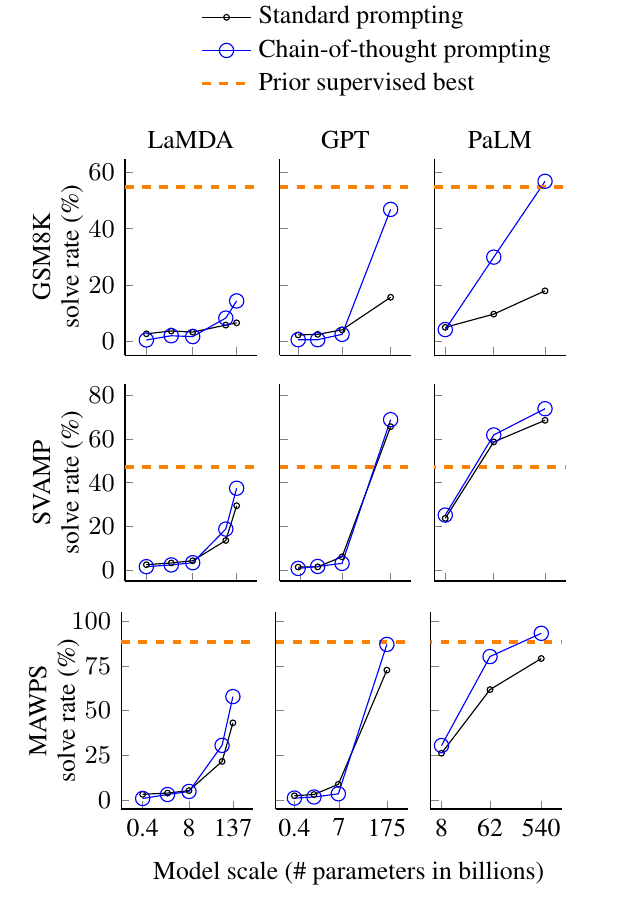 图:模型达到一定规模后,CoT效果才比较好
图:模型达到一定规模后,CoT效果才比较好
很神奇?我们似乎是在用教小孩学数学的方法来教大模型,这些模型就可以举一反三了。作者在结论部分是这么总结的:
we find that chain-of-thought reasoning is an emergent property of model scale that allows sufficiently large language models to perform reasoning tasks that otherwise have flat scaling curves.
翻译过来就是:我们发现CoT推理能力是模型大到一定规模之后的一种涌现(emergent)属性,因为模型规模在小于一定规模时它的性能是非常平的。也就是说0.4B参数的模型增长到8B效果并无提升,但是模型超过某个规模之后性能就突然上去了,这就是所谓的涌现属性。这也非常神奇(因为涌现这个词的意思是突然出现了某种没有的属性,当然很神奇了)。
Large Language Models are Zero-Shot Reasoners
这篇论文的标题是不是很熟悉的样子?嗯,可以和GPT-3的论文标题《Language Models are Few-Shot Learners》比较一下。可能过一阵还会有《Large Language Models are XXX-YYY ZZZs》,也许是ChatGPT生成的,哈哈。
这篇文章的方法更加简单,不需要搞那么复杂的分解示范动作,直接来一句魔法咒语”Let’s think step by step”就搞定了。
 图:Zero-shot-CoT
图:Zero-shot-CoT
上图a是Few-Shot Prompting,即使有例题,模型也搞不定多步骤的题目。图b就是上文的CoT Prompting方法,需要给的例题是分解步骤的,所以模型也会模仿例题举一反三。图c是Zero-Shot Prompting,当然更加搞不定。而本文不需要复杂的带分步讲解的例题,只需要增加一句魔法咒语就搞定了,作者把这种方法叫做”Zero-shot-CoT”。
下面是详细的步骤,第一步用魔法咒语召唤出详细解题过程,最后再增加一个”Therefore, the answer (arabic numerals) is”这样的Prompting让它给出答案。
 图:Zero-shot-CoT详细过程
图:Zero-shot-CoT详细过程
Locating and Editing Factual Associations in GPT
预训练大语言模型学到了大量的事实类(Factual)知识,这些知识可能是错误的,也可能过时了,比如某项运动的世界记录经常会被打破。解决这个问题可以用新的数据来训练模型,也许和人类一样,它就学到了新的知识。当然人也可能很固执,他不愿意接受新的东西,即使你不断给他洗脑可能也不好使。模型当然不会有固执的性格,但是如果过去的数据很多,只有一两条训练数据也可能无法让它学到新的知识。
这篇文章首先通过Causal Tracing的技术分析出GPT这样的大模型,事实类知识大都保存在网络的某个局部(这样才有可能编辑),而且大部分是在中间的MLP层。定位之后,本文提出了一种ROME(Rank-One Model Editing)的方法来编辑某一条事实类知识。听起来是不是让人联想到基因编辑或者记忆编辑这样的词语?更多的内容可以参考Locating and Editing Factual Associations in GPT或者它的后续版本Mass Editing Memory in a Transformer。
ChatGPT原理
以用户为中心
前面说到大模型其实通过预训练已经学到了很多技能,但是我们要有一种办法告诉它我们需要这种技能。之前的方法就是Prompting,在GPT-3的论文里最简单的就是直接的Instruct和间接的Few-shot的示例。但是这两种方法都有问题。Instruct是比较tricky的,不同的人表达相似的要求会差异很多,如果大模型要依赖”Let’s think step by step”这样的魔法咒语,那感觉回到了炼丹的年代。而示例有的时候也很难,比如写一篇关于熊和兔子的作文,难道还需要用户先写一篇猫和狗的作文吗?而且写完后GPT也不知道我们是要让它写熊和兔子的作文啊。
在其他很多人探索魔法咒语或者其它的Prompt Learning的时候,OpenAI选择了不同的道路——用户还是用最习惯的自然语言来表达它们的Instruct。但是问题又回来了,模型怎么知道我们要求它们做什么呢?我们之前搞魔法咒语或者各种Prompt Engineering不就是为了告诉模型这一点吗?让用户成为炼丹师确实不好,我们要以用户为中心,用他们最自然的方式来表达需求。但是机器怎么知道怎么做呢?其实很简单,标注数据让它学习就行了。不过人工标注数据成本很高,比如让人去写一篇关于熊和兔子的作文。请注意:我们并不是要教模型怎么写作文,而是要教它怎么理解任务。比如理解”写一篇关于熊和兔子的故事,它们开始仇恨对方,最后变成了好朋友”。所以我们要教模型的是理解任务,当然由于网络上的内容参差不齐,即使理解了任务,给出的答案也可能是有偏见的、涉及暴力甚至对人有害的。所以我们还需要教给模型用合适的方式生成答案。这就是所谓的从人类反馈学习。其实OpenAI在2020年9月发表的《Learning to summarize from human feedback》就开始了这个方向的尝试工作,不过这一次做的只是摘要这一个任务。但是它使用的方法和ChatGPT/InstructGPT基本一样,只是在强化学习的一些细节上又是调整。
现在回过头来看,在其他人大搞Prompt Learning的时候,OpenAI就选择了一条不同的道路。虽然很多Prompt Learning的文章引用GPT-3这篇文章,但是GPT-3采用的Prompt是非常简单的,它并没有把重点放到怎么探索魔法咒语,只是证明了GPT-3可以通过Instruct和Few-Shot的例子学习到任务。这也是和GPT-3文章标题——《Language Models are Few-Shot Learner》相契合的,虽然文章多次提到了Prompt,但是它的重点不是在Prompt。而等到2022年他们发表InstrctGPT论文的时候,他们探索的任务以及不是摘要这个单一任务了,训练的Prompt数量也达到了数万的规模。而OpenAI的研究也从来没有关注过Prompt Learning。
InstructGPT原理
摘要
语言模型变大之后并一定就会更好的听从人类指令。大模型可能会生成一些不真实的、有害的和无用的内容。也就是说大模型和用户的需求并不对齐(aligned)。本文提出了一种通过人类反馈来微调模型从而在大量任务上对齐大语言模型和用户意图的方法。我们首先收集了一些人工手写的和通过OpenAI API收集的prompt,然后让人去根据这些prompt手写对应的示例(demonstration),然后用监督的方式微调GPT-3模型。接着我们收集了模型的多个输出,并且使用强化学习继续优化这个监督模型的效果。在人工评测中,1.3B参数的InstructGPT模型虽然参数比175B的GPT-3少了100倍,但是其效果超过了对方。而且InstructGPT模型生成的内容更加真实无害,并且在公开的NLP数据集上效果也没有太多下降。虽然InstructGPT仍然会犯一些简单的错误,我们的结果展示了通过人类反馈的微调来对齐语言模型和人类意图是非常有效的一种方法。
方法和实验
总体训练流程
InstructGPT的训练流程如下图所示:
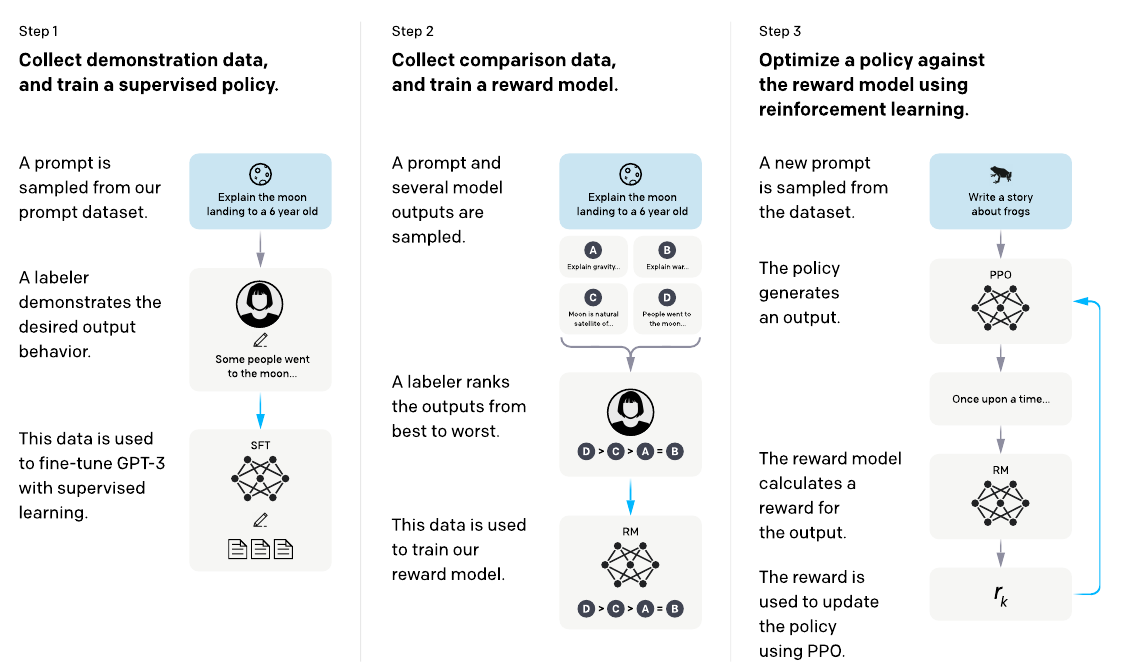 图:InstructGPT的训练流程
图:InstructGPT的训练流程
监督学习微调
根据标注人员的Prompt-Demonstration对,对预训练的GPT-3模型进行微调。
训练Reward模型
对于同一个Prompt,会用模型产生多个输出,然后人工对它们进行排序,通过这个排序的标注数据训练一个Reward模型,这个模型对于输入的Prompt和Completion对进行打分。
强化学习微调
使用PPO这种强化学习对第一步得到的模型再次进行微调。
数据集
我们的prompt数据集主要来自用户在Playground上通过OpenAI API提交的数据,尤其是InstructGPT的早期版本(用部分demonstration数据训练的监督模型)。Playground的用户每次都会被提示他们输入的内容可能会比用于训练。我们通过启发式的方法使用最长公共前缀的方法对数据进行了去重,并且限制每个user ID最多200个prompt。我们构造训练、验证和测试集时确保它们的用户是不重叠的。另外为了避免泄露用户隐私,我们过滤了包含个人身份信息(PII)的prompt。
为了训练第一个版本的InstructGPT,我们要求标注者直接写prompt。因为GPT-3模型收集的prompt并不是非常自然语言描述的。我们要求标注者写如下三种prompt:
- 普通的prompt:我们随意给定一些任务,让它们写prompt
- Few-shot:我们要求他们写一个指令(Instruct),以及遵循这个指令的多个query/repsone对
- 用户要求:OpenAI的API会收集一些用户的需求,我们让他们根据这些需求写prompt
通过这些prompt,我们构造了3个不同的数据集:(1) 有监督微调(SFT)数据集,需要标注者根据prompt写demonstration;(2) RM数据集,给定prompt,让模型的输出多个completion,标注者对这些输出的好坏进行排序;(3) PPO数据集,用于RLHF微调。这个数据集只有prompt,没有标注。SFT有13k的prompt(来自API和标注者手写),RM数据集有33k(来自API和标注者手写),PPO数据有31k的prompt(只来自API)。数据集的大小如下表所示:
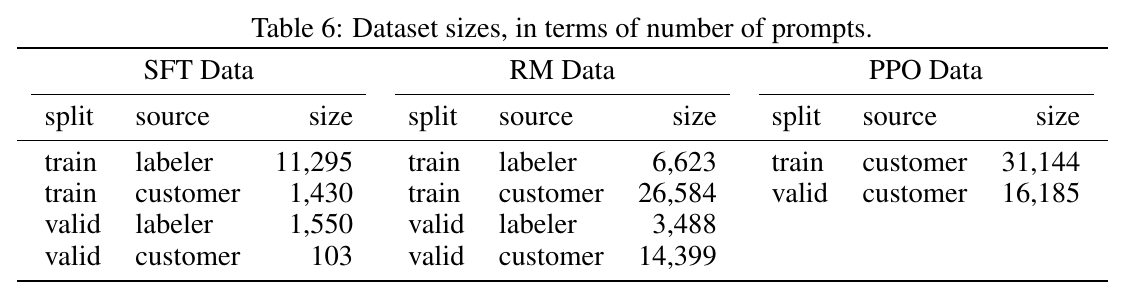 图:InstructGPT训练的数据集
图:InstructGPT训练的数据集
表1给出了API prompt的类别分布,大部分prompt是生成类的任务,而分类或者QA类的任务较少。表2给出了一些示例的prompt:

上面的rewrite是根据一段summary写一个outline(注意这是一个摘要任务,但是这里的summary是被摘要的内容,模型的输出这里被叫做outline才是我们说的摘要),我们看到前面有一段Instruct,告诉模型要做根据summary写一个outline,并且用三引号把summary括起来,最后用”This is the outline of the commercial for that play:”+换行+三引号提示模型输出outline。
任务(Task)
我们的训练任务有两个来源:(1) 标注人员写的prompt;(2) 早期InstructGPT模型通过API手机的prompt。这些prompt分成多样,包括生成、问答、对话、摘要、抽取和其它自然语言任务。数据集96%都是英语,不过在后面我们也探索了模型在其它语言以及代码相关任务上的能力。
对于每一个自然语言的prompt,任务通常直接用自然语言的指令来制定(比如”写一个关于聪明的青蛙的故事”),但是也有间接通过few-shot示例来描述任务的(比如给定两个青蛙的故事,让模型在生成一个故事),或者通过隐式的续写(比如提供一个关于青蛙故事的开头部分)。在每种情况下,我们都要求标注者尽他们最大的努力通过prompt来推测用户的意图,如果实在看不懂就跳过。此外,我们的标注者也有考虑一些隐式的意图,比如回复的真实性、避免有害的内容或者有偏见的内容。
标注数据收集
为了得到demonstration和对比的数据,我们雇佣了40个合同工。和之前做摘要的任务不同,这一次我们的任务更加多样,而且偶尔会设计有争议和敏感的话题。我们希望这些标注者对于不同人群的偏好比较敏感,并且有能力识别出潜在有害的内容。因此,我们做了一个screening测试来衡量标注者的能力。
在训练和评估阶段,我们的对齐标注可能会冲突:比如,当用户要求机器返回一个潜在有害的回复。在训练阶段,我们优先选择有帮助的回复。但是在最终的评估阶段,我们要求标注者优先选择真实和无害的回复。在整个项目过程中,我们非常紧密的与标注者协同合作。在项目中我们有一个训练新人的过程,会给每个任务详细的说明,并且在一个共享的房间回答他们的问题。
为了评估模型对不同标注者偏好的泛化能力,我们另外雇佣了一些标注者,他们不标注训练数据。他们的招聘途径和前面类似,只不过取消了screening测试。虽然标注任务很复杂,我们发现标注者之间的一致性是非常高的:训练数据的标注者的一致率是72.6 ± 1.5%,评估标注者的一致率是77.3 ± 1.3%。最为对比,2020年摘要任务(相对简单)的一致率是73 ± 4%。
模型
我们基于GPT-3的预训练语言模型。这些模型用网络上各种类型的数据进行训练从而能够适应各种下游任务。我们适应三种方法来训练模型。
有监督微调(SFT)。我们使用标注者的demonstration来有监督的微调GPT-3模型。我们训练了16个epoch,使用了cosine的学习率递减策略,残差droptout是0.2。我们使用验证集合上RM模型的得分来选择最优的SFT模型。我们发现SFT经过一个epoch就在验证集的loss上过拟合了。虽然过拟合,但是我们发现继续训练仍然会继续提升RM模型的得分并且得到人类更高的评分。
奖励模型(RM)。基于上面的SFT模型,我们去掉非Embedding层,然后训练一个奖励模型。这个模型的输入是prompt和respone,输出是一个分数。我们只使用了6B参数的奖励模型,因为它计算比较快,而且我们发现175B的奖励模型训练时不稳定。在《Learning to summarize from human feedback》论文里,当时训练的奖励模型的输入是prompt+两个response,输出是它们的差值。这是与本文不同的。
为了加速比较数据的收集,对于一个prompt,我们给标注者随机K=4-9个响应让它们进行排序。这样就产生了${k \choose 2}$组pair。因为每个prompt的这些pair非常相关,我们发现如果随机shuffle到训练数据里,模型很容易过拟合。所以我们把这${k \choose 2}$个pair放到一个batch里进行训练。这样做一来速度更快,二来不会过拟合。RM模型的loss是:
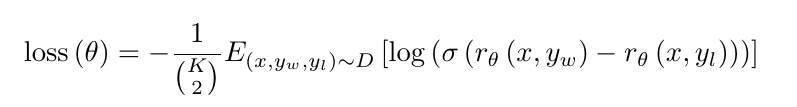
这个公式的含义是:对于输入x,$y_w$是更好的completion,而$y_l$是较差的那个。$r_\theta(x,y)$是奖励模型对输入(x,y)的打分。所以如果$r_\theta(x,y_w)$与$r_\theta(x,y_l)$差越大,则$\sigma(r_\theta(x,y_w)-r_\theta(x,y_l))$也越大,log后也越大,loss取负数就越小。反之loss越大。所以模型的优化目标就是要让好的completion的得分大于差的。当然分差越大,loss就越小。但是$\sigma$函数前面是线性增长,后面就平缓下来了,所以也不至于要求它们差别太大。
最后,因为RM的loss对于奖励具有平移不变性,所以我们使用标注者的demonstration对奖励模型的bias进行了归一化,使得在这个数据集上奖励模型的均值是0。
强化学习(RL)。我们在我们的交互环境(environment)使用PPO算法来微调SFT模型。这个交互环境会随机的选择一个prompt并且期望得到这个prompt的response。给定prompt和response,奖励模型就会产生一个reward并且结束整个episode。除此之外。我们还增加了逐token的KL惩罚避免SFT模型过拟合奖励模型。PPO的值函数(value function)是用RM模型初始化的。这个模型被叫做PPO模型。
我们也实验了把预训练的梯度混入PPO的梯度,从而避免模型在公开NLP数据集上的性能下降。我们把这类模型叫做PPO-ptx。我们模型的优化目标函数为:
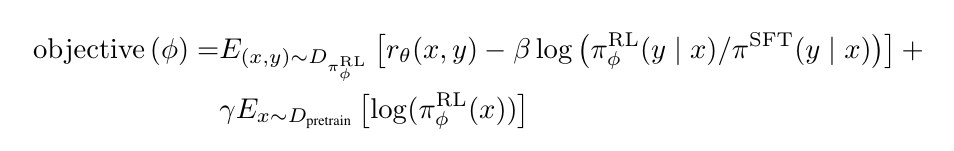
其中$\pi_{\phi}^{RL}$是需要学习的Agent的策略。$\pi^{SFT}$是监督学习得到的模型。$D_{pretrain}$是预训练的数据分布,KL奖励系数$\beta$和预训练loss系数$\gamma$,分别控制KL乘法和预训练梯度的强弱。对于PPO模型,$\gamma$设置为0。
如果读者对于强化学习不太熟悉,可以参考Huggingface的强化学习课程或者强化学习系列博客。这里我会尝试用通俗的语言解释一下强化学习的概念、为什么这里要用强化学习以及上面的目标函数的意义。
强化学习简介(可跳过)
监督学习的特点是有一个“老师”来“监督”我们,告诉我们正确的结果是什么。在我们在小的时候,会有老师来教我们,本质上监督学习是一种知识的传递,但不能发现新的知识。对于人类整体而言,真正(甚至唯一)的知识来源是实践——也就是强化学习。比如神农尝百草,最早人类并不知道哪些草能治病,但是通过尝试,就能学到新的知识。学到的这些知识通过语言文字记录下来,一代一代的传递下来,从而人类社会作为整体能够不断的进步。和监督学习不同,在强化学习里没有一个“老师”会“监督“我们。比如下围棋,不会有人告诉我们当前局面最好的走法是什么,只有到游戏结束的时候我们才知道最终的胜负,我们需要自己复盘(学习)哪一步是好棋哪一步是臭棋。自然界也是一样,它不会告诉我们是否应该和别人合作,但是通过优胜劣汰,最终”告诉”我们互相协助的社会会更有竞争力。和前面的监督非监督学习相比有一个很大的不同点:在强化学习的Agent是可以通过Action影响环境的——我们的每走一步棋都会改变局面,有可能变好也有可能变坏。
它要解决的核心问题是给定一个状态,我们需要判断它的价值(Value)。价值和奖励(Reward)是强化学习最基本的两个概念。对于一个Agent(强化学习的主体)来说,Reward是立刻获得的,内在的甚至与生俱来的。比如处于饥饿状态下,吃饭会有Reward。而Value是延迟的,需要计算和慎重考虑的。比如饥饿状态下去偷东西吃可以有Reward,但是从Value(价值观)的角度这(可能)并不是一个好的Action。为什么不好?虽然我们可以求助于监督学习,比如先贤告诉我们这是不符合道德规范的,不是好的行为。但是我们之前说了,人类最终的知识来源是强化学习,先贤是从哪里知道的呢?有人认为来自上帝或者就是来自人的天性,比如“人之初性本善”。如果从进化论的角度来解释,人类其实在玩一场”生存”游戏,有遵循道德的人群和有不遵循的人群,大自然会通过优胜劣汰”告诉”我们最终的结果,最终我们的先贤“学到”了(其实是被选择了)这些道德规范,并且把这些规范通过教育(监督学习)一代代传递下来。
强化学习过程如下图所示:
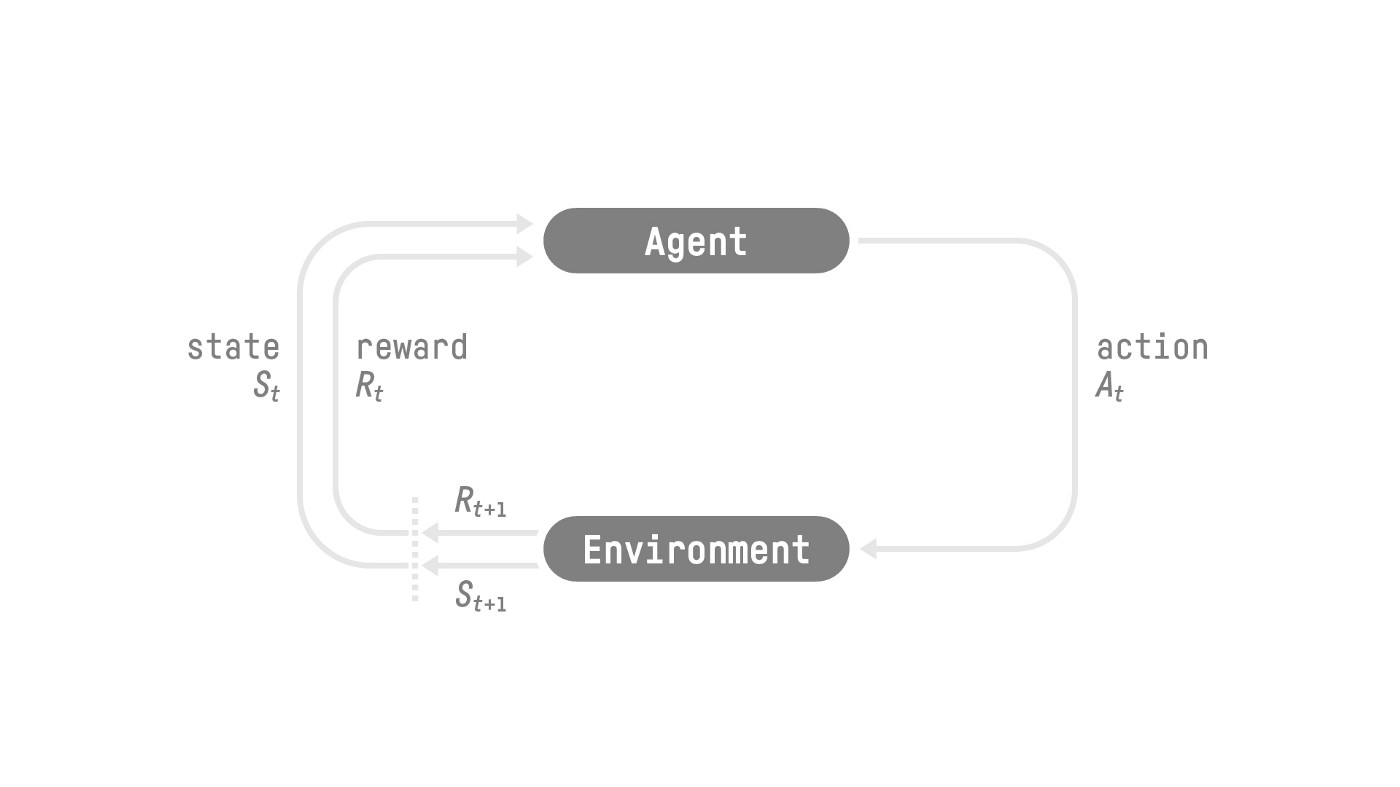 图:强化学习交互图(来自https://huggingface.co/deep-rl-course/)
图:强化学习交互图(来自https://huggingface.co/deep-rl-course/)
在一个特定的环境(Environment)里,有一个Agent。Agent可以感知环境,从而得到环境的状态(State),并且Agent有一个策略(Policy),它会根据当前的状态采取一个动作(Action)。而环境会根据这个Action返回一个奖励(Reward),并且Agent进入一个新的状态。如此循环往复,而Agent的目标是优化它的策略从而获得最大的累计(Cumulative)奖励。
上面的描述可能有一些抽象,我们来看一个游戏的例子。
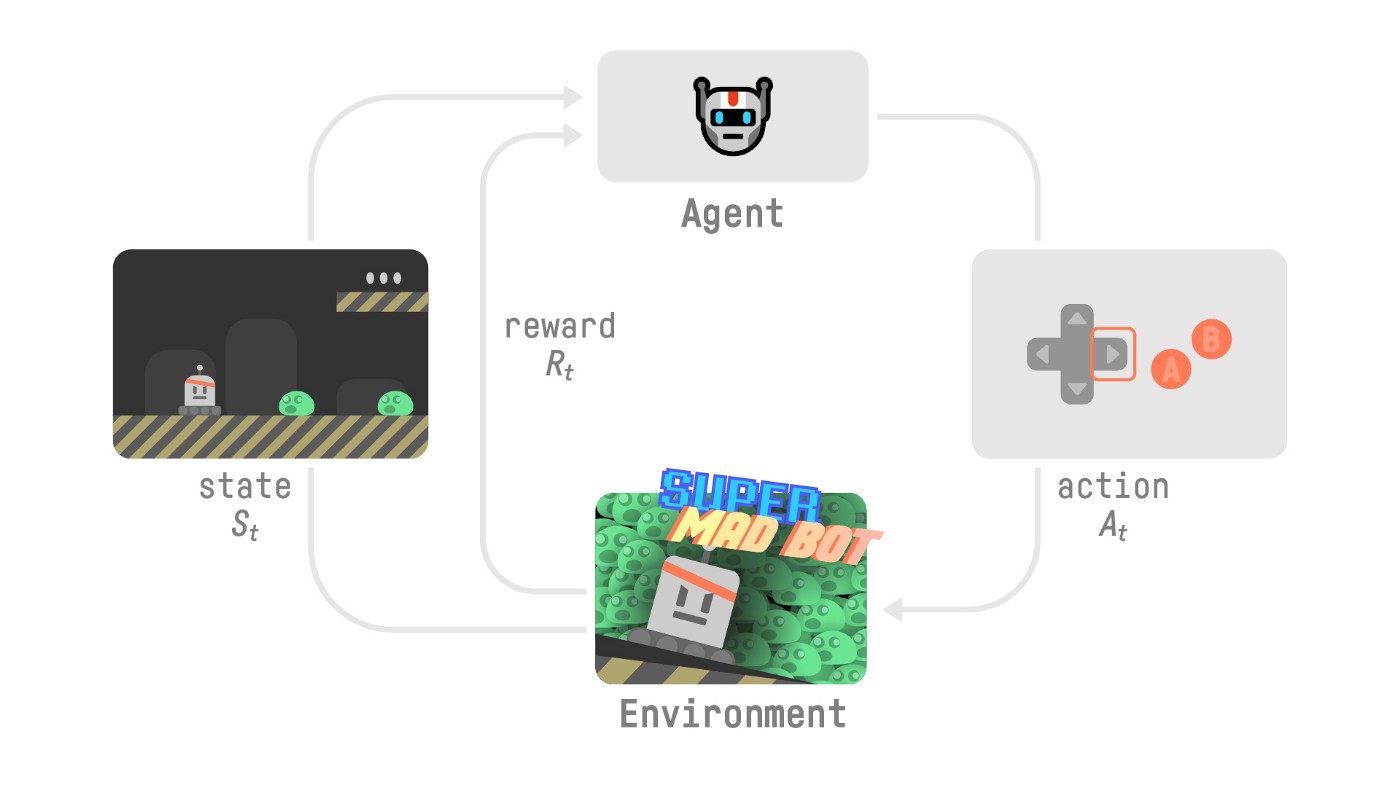 图:一个强化学习游戏(来自https://huggingface.co/deep-rl-course/)
图:一个强化学习游戏(来自https://huggingface.co/deep-rl-course/)
比如上图中,环境就是这个虚拟的游戏世界。我们的Agent就是那个机器人,它感知的状态就是虚拟游戏世界的那张图片。在每一个时刻,机器人可以采取一些Action,比如键盘的往左或者往右,当采取这些Action之后,环境就发生了改变,比如它往左移动或者往右移动了一下,就会进入新的状态。根据这个新的状态,环境会给一个Reward。比如移动后被怪物攻击,从而血量减少,那么就会得到一个负的Reward。如果攻击了敌人,那么就会得到一个正的Reward。如果通关,可能得到一个很大的Reward。而如果死掉,则会得到负的很大的Reward。
而强化学习的目标就是优化Agent的策略,从而获得最大的累计奖励。我们可以看到,在玩游戏的时候,没有一个老师告诉我们,在什么情况下应该怎么行动。但是我们玩了一局游戏后会复盘(强化学习),总结出一些经验(策略)。所以对于强化学习来说,我们就是要学习一个策略,它能根据当前的情况(状态)随机应变,选择最有利的行动。所以我们可以认为Agent的策略就是它的大脑,而状态是通过它的传感器获得的环境信息。
 图:Policy,Agent的大脑(来自https://huggingface.co/deep-rl-course/)
图:Policy,Agent的大脑(来自https://huggingface.co/deep-rl-course/)
解决强化学习问题有两大类方法:基于策略的(Policy-Based)方法和基于价值的(Value-Based)方法。
基于策略的方法就是直接学习一个策略的方法,这有的像废话。再具体一点,对于基于策略的方法,我们会直接学习一个策略函数,它的输入是状态,输出是Action或者Action的概率分布。我们先看确定性的策略,它学习到的是一个函数,这个函数的输入是状态,输出是一个Action,如下图所示:
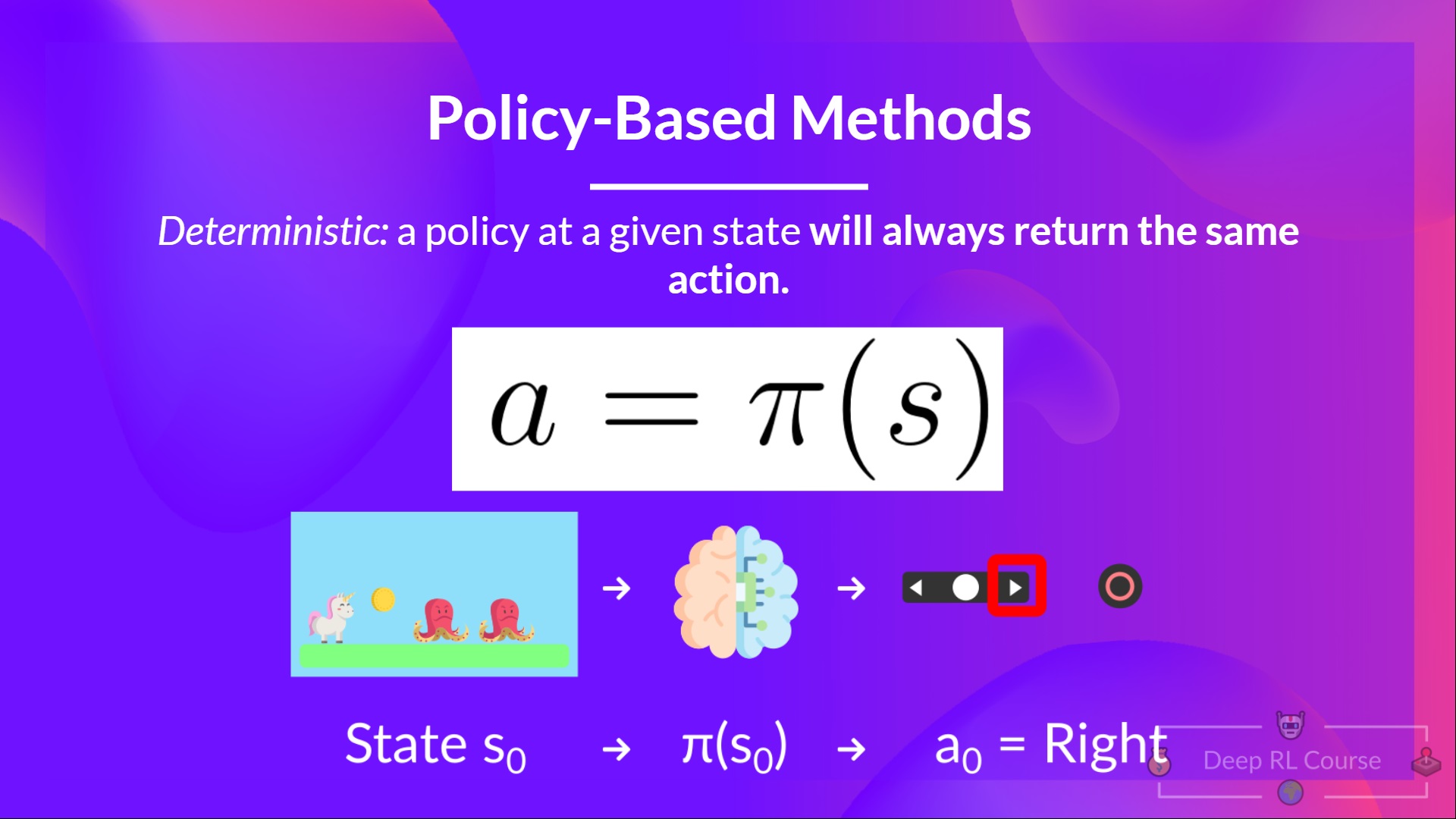 图:确定性的基于策略的方法(来自https://huggingface.co/deep-rl-course/)
图:确定性的基于策略的方法(来自https://huggingface.co/deep-rl-course/)
在上图中,我们需要学习一个策略函数,输入就是当前的状态,在这里就是游戏的画面。输出Action就是键盘的操作,比如向右。因为它是确定的,也就是对于每一个输入状态s,都有唯一一个确定的Action与之对应,所以通常记作$a=\pi(s)$,这里的策略$\pi$是一个函数。
和它对应的就是非确定性的策略,它的输出是关于Action的一个概率分布,如下图所示:
 图:非确定性的基于策略的方法(来自https://huggingface.co/deep-rl-course/)
图:非确定性的基于策略的方法(来自https://huggingface.co/deep-rl-course/)
在上图中,对于输入的状态s,输出一个概率分布。比如图中的策略是:向右的概率是0.7,向左0.1,跳跃0.2。我们可以发现确定性的策略是非确定性策略的特例,如果向右的概率是1,其它概率是零,那么就变成了确定性的策略了。
非确定性的策略有一个好处,那就是它有一定的随机性,从而可能探索未知的可能性。在强化学习里,有一个所谓的Exploration/Exploitation(探索/利用)的trade-off。比如下图的例子:
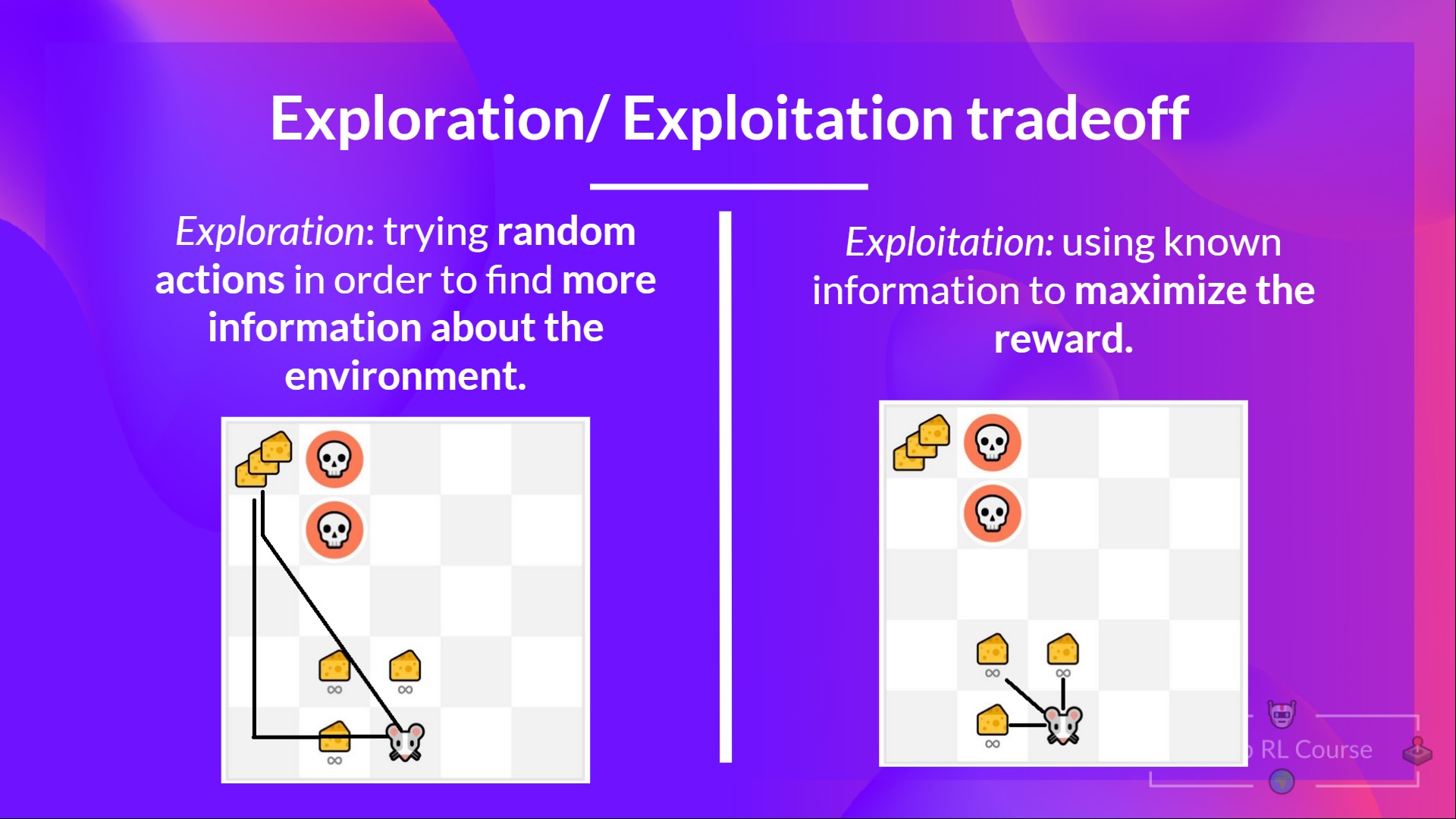 图:Exploration/Exploitation trade-off(来自https://huggingface.co/deep-rl-course/)
图:Exploration/Exploitation trade-off(来自https://huggingface.co/deep-rl-course/)
在上图中,Agent是一个老鼠,它所在的环境可能有奶酪,也可能有凶恶的大花猫。它一开始对这个世界一无所知,所以需要去探索,也就是去尝试不同的位置。当它发现周围3个位置每次都有奶酪,那么它就可能停止探索,每次都去那3个位置,这就是所谓的Exploitation,也就是利用对环境已有的知识获得Reward。但是如果它再有一些探索精神的话,可能也许能够找到左上角有3块奶酪,这是一个更大的Reward,但是也可能遇到大花猫。而且即使不遇到大花猫,也可能在路途中一无所获。这就是Exploration/Exploitation的trade-off。用日常语言来说就是:满足于现状,可能失去更好的未来;不安于现状,拼搏一把,也有可能失去现有的一切。
当然,和人生相比,强化学习的一个好处是可以不断的试错,尤其是所谓的Episodic的任务(游戏),每次挂了可以时光倒流重新开始。而人生就是所谓的Continuing的任务,当然人生的不同阶段也会遇到类似的状况,但肯定不能从头再来。
基于价值的方法是一种间接的强化学习方法,它并不直接学习一个策略函数或者策略概率分布,而是学习一个价值函数。有两种价值函数,状态价值函数$Q(s)$和状态-动作价值函数$Q(s,a)$。所谓的状态价值函数就是我们认为如果Agent处于这个状态s,那么它期望可以获得的累计奖励。而状态-动作价值函数就是Agent处于某个状态s,并且采取动作a之后可以获得的累计奖励。用前面游戏了例子来说,Agent处于当前这一帧图像所代表的状态s,如果采取跳跃的动作a,那么期望的累计奖励就是$Q(s,a)$。因为很多环境里Action是有限的离散集合,如果知道在某个状态s的所有$Q(s,a)$,那么我们可就可以选择价值最大的那个$Q(s,a)$作为我们的策略:
 图:价值函数和策略的关系(来自https://huggingface.co/deep-rl-course/)
图:价值函数和策略的关系(来自https://huggingface.co/deep-rl-course/)
所以和前面的基于策略的方法不同,基于价值的方法是一种间接的方法。
在基于策略的方法中,有一类方法叫策略梯度(Policy Gradient)的方法。我们通常假设策略是一个参数化的随机策略(通常是神经网络或者其它可以微分的函数)$\pi_\theta(s_t)$。这个策略的输入是状态$s_t$,输出是每个动作的概率分布。比如CartPole-v1这个游戏里,它有点像我们小时候玩的游戏,拿一根棍子竖直的放在手掌上,通过移动手掌保持棍子不倒。
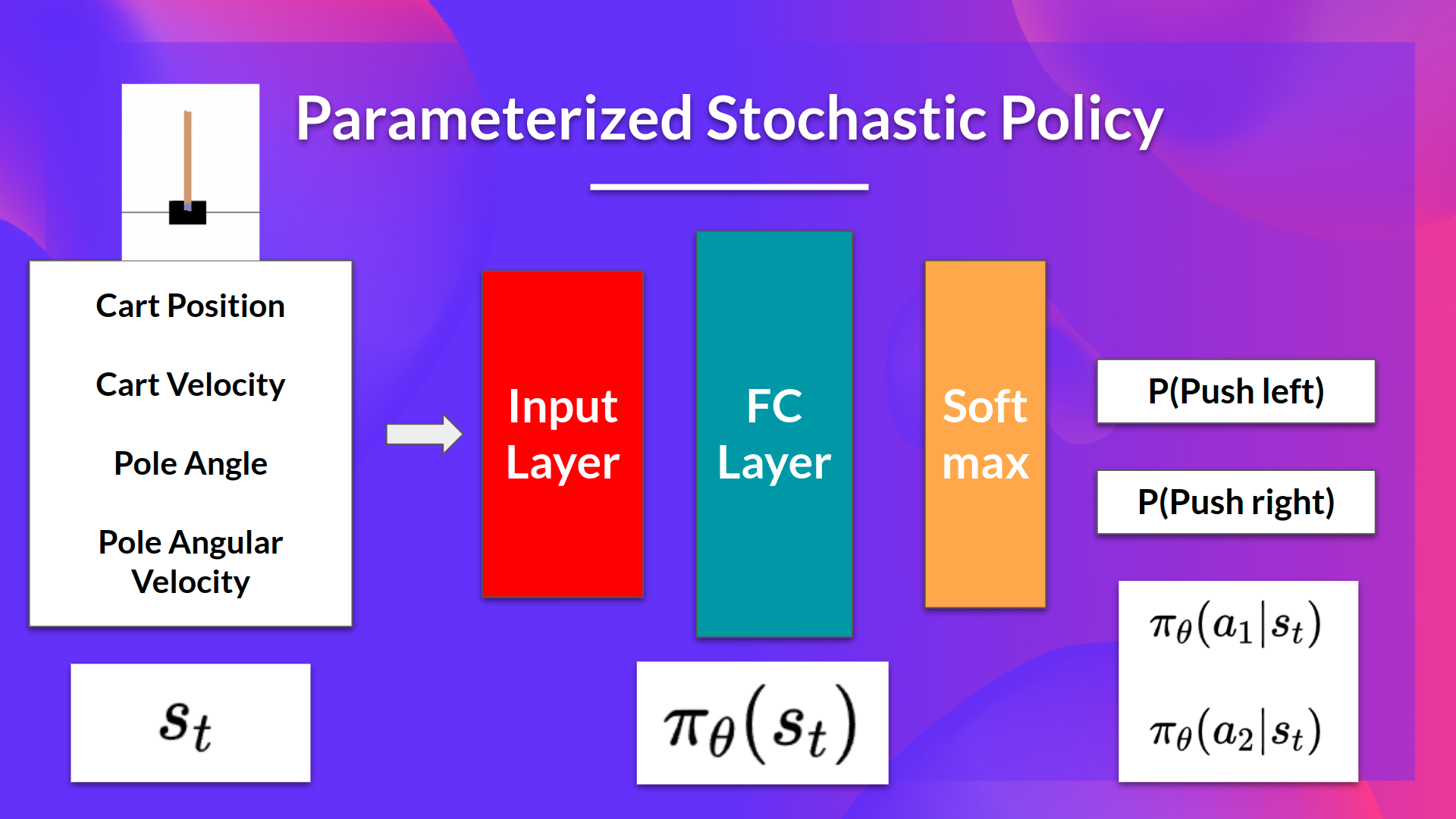 图:Policy Gradient(来自https://huggingface.co/deep-rl-course/)
图:Policy Gradient(来自https://huggingface.co/deep-rl-course/)
这里的策略就是一个参数化的随机策略,输入是游戏的状态,包括棍子的角度,角速度,小车(cart)的位置和速度等。这些特征传入神经网络,然后我们期望神经网络输出动作$P(left|s)$和$P(right|s)$的概率。我们把所有神经网络的参数向量记为$\theta$,不同的参数向量就代表了不同的策略。而策略梯度的方法就是通过梯度上升的方法调整参数$\theta$,使得期望的Reward最大化。期望的Reward公式如下:
 图:Policy Gradient的目标函数(来自https://huggingface.co/deep-rl-course/)
图:Policy Gradient的目标函数(来自https://huggingface.co/deep-rl-course/)
也就是我们需要调整参数$\theta$,理论上我们可以使用梯度上升(其实和梯度下降想似,一个是loss,越小越好,一个是目标函数,越大越好)。很多深度学习框架只能支持梯度下降,我们可以简单的把目标函数加一个负号,就可以把它当成loss来用了)。我们发现上图的第一个公式$R(\tau)$是一个trajectory的全部Reward,它是与参数无关的。但是另外一项$P(\tau;\theta)$是与参数$\theta$有关的,而且展开后除了策略函数$\pi_\theta(a_t | s_t)$,另外还包含环境动力学(environment dynamics)概率$P(s_{t+1} | s_t, a_t)$。
这个环境动力学通常是未知的(对于model free的方法),我们只能得到采样的结果。比如前面的CartPole-v1游戏,我们在某个状态s采取某个动作a,环境会告诉我们新的状态和reward。但是我们(Agent)并不知道在状态s采取动作a之后会进入哪一个新状态和reward,因为它有可能是不确定的,而且即使确定的,我们也不知道,除非我们对环境建模,利用我们的物理学知识搞一堆微积分公式计算一下:嗯,现在竿子和水平面的夹角是85度,竿子的角速度是2rad/s,小车的速度是2m/s,运用我们强大的物理能力,我们可以预测出,如果小车向左移动,那么下一个时刻,竿子会与水平面夹角86度,……。这就是所谓的基于模型的(model based)方法了。但是一般情况下,我们即使(通常)认为环境是遵循某种动力学规律的$P(s_{t+1} | s_t, a_t)$,我们也会认为它的计算太过复杂。但是我们可以去采样,也就是给定$s_t$和$a_t$,环境会采样一个新的$s_{t+1}$和reward。但是这是概率的,你再用同样的状态和动作去环境跑一下,结果可能就完全不同。
因此这里就遇到一个问题,环境动力学是未知的,但是里面有$a_t$,而$a_t$又是和参数相关的,这样就没有办法求梯度了。不过好在有如下的策略梯度定理(Policy Gradient Theory):
 图:策略梯度定理(来自https://huggingface.co/deep-rl-course/)
图:策略梯度定理(来自https://huggingface.co/deep-rl-course/)
我们发现没有了环境动力学的概率,所以我们就可以计算梯度了。对这个神奇的定理感兴趣的读者可以参考the Policy Gradient Theorem。
这下就简单了,我们需要调整参数$\theta$使得目标函数$J(\theta)$最大化,同时我们又可以计算$\nabla_\theta J(\theta)$,那么我们就可以用梯度上升算法迭代更新参数:
\[\theta = \theta + \alpha \nabla_\theta J(\theta)\]其中$\alpha$就是我们熟悉的learning rate。如果我们使用Monte Carlo采样一个Episode之后再用上面的公式来更新参数,就是所谓的Reinforce算法。
但是Reinforce算法是基于Monte Carlo采样,它存在较大的估计方差(variance)。为了缓解这个问题,我们可以采样多个Episode之后再来更新一次参数。但是这又会使得学习速度很慢。Actor-Critic方法结合了策略梯度和基于价值的方法,能够较好的解决Reinforce算法的问题。Actor就是一个基于策略方法的(通常是策略梯度)的Agent,而Critic是一个价值函数。
为了理解Actor-Critic,假设你在玩一个视频游戏。在你玩游戏的同时有一个朋友会提供你一些反馈。你就是Actor,而提供反馈的朋友就是Critic。
 图:Actor-Critic例子(来自https://huggingface.co/deep-rl-course/)
图:Actor-Critic例子(来自https://huggingface.co/deep-rl-course/)
一开始你并不知道怎么玩,所以你就随机的玩(探索)。你的朋友会告诉你每个动作的价值,根据这个反馈,你可以(相比Monte Carlo采样)更好的学习。当然你的朋友也会根据你的游戏过程更新他的价值函数(参考Q-Learning和Deep Q-Learning,这里不展开)。下图是Actor(Policy Gradient)的参数更新公式:
 图:Actor-Critic中Actor的参数更新(来自https://huggingface.co/deep-rl-course/)
图:Actor-Critic中Actor的参数更新(来自https://huggingface.co/deep-rl-course/)
我们发现和前面相比的区别:这里使用的是Critic的价值函数估计的价值$\hat q_w(s,a)$,而前面是一个Episode的Reward。相对于Monte Carlo采样的一个Episode的Reward,我们使用价值函数估计的累计奖励会更加准确。
但是$Q(s,a)$是一个”绝对的值”,我们其实想要的是一个”相对的值”,也就是在当前这个状态s下,动作a相对于其它动作或者说所有动作的平均价值的Advantage。
\[A(s,a)=Q(s,a)-V(s)\]如果Advantage是正数,至少说明这个动作a是不错的,我们可以调整参数$\theta$让它朝着这个方向努力,反正如果是负值则说明不是太好,应该调整参数远离这个方向。把Critic的价值函数从$Q(s,a)$改成$A(s,a)$后,我们就得到一个叫做Advantage Actor-Critic的算法,通常缩写为A2C。
接下来我们简单的介绍一些Proximal Policy Optimization (PPO)算法,PPO算法主要是为了解决A2C算法不稳定的问题。它的基本思想是:如果更新参数会导致策略发生很大的变化,那么就可能导致不稳定。所以PPO算法希望更新参数时不要引起策略的太大变化。有的读者可能会想,那么我们更新参数时把学习率$\alpha$调小一点是不是就行了。 学习率调小学习速度会变慢,而且更主要的问题是,即使参数调整很小,也有可能导致策略发生剧烈的变化。因为强化学习和监督学习不一样,监督学习的参数直接影响最终的分类,而强化学习参数的变化会影响策略,策略又影响Episode的每一个动作的选择,最终影响一个Episode的奖励。这种间接的影响可能会产生放大作用。所以强化学习相比监督学习更容易不稳定。
那PPO是怎么确保参数的更新不会导致策略的巨大变化的呢?这里关键的是一个ratio函数:
\[r_\theta(t) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}\]这个函数表示在相同的状态$s_t$和动作$a_t$下,新老策略的比值。这个比值等于1,则说明策略没有变化。比值越远离1,则说明策略变化越大。在PPO里,它把原来的策略梯度的目标函数变成了:
 图:Clipped surrogate objective function(来自https://huggingface.co/deep-rl-course/)
图:Clipped surrogate objective function(来自https://huggingface.co/deep-rl-course/)
关于PPO的详细原理请参考Proximal Policy Optimization。
为什么要使用强化学习
InstructGPT最开始其实是有监督的微调(SFT)模型,那为什么又需要一个强化学习呢?我们知道GPT模型本质就是一个语言模型,不管是什么Instruct,对于它来说都是一个条件生成的问题。对于一些简单的task,比如问答,让人给出Demonstration还比较容易。比如问”刘德华老婆是谁”,答案就是”刘德华的老婆是朱丽倩”。但是另外一些复杂的task,比如”写一篇关于青蛙王子的故事,要求500字”,这就费劲了,而且那些数据标注者也不是作家,写出来质量也不见得好。那怎么办呢?批评比解决问题容易。你让一个人写一篇好的作文当然很难,但是给你两篇文章让你判断哪篇写得更好,这就容易的多了。这就是所谓的”Reinforcement Learning from Human Feedback”,这里用的是”Human Feedback”,其实就是对两个结果进行比较。
对一个prompt写一个好的demonstration,难度远远大于判断两个response的好坏。但是问题又来了,对于prompt和demonstration的pair,我们可以简单的使用监督学习的方法来训练语言模型——调整模型参数,使得条件概率$P_\theta(demonstration|prompt)$更大就行。但是这样的”Human Feedback”怎么可以训练语言模型呢?我们首先需要通过这样的数据训练一个奖励模型,也就是输入prompt和response,这个模型可以输出一个分数来表示这个response的好坏。
一种很笨但是很直觉的方法可能是这样:给定一个prompt,我穷举所有的response,然后用奖励函数打分,选出最好的那些来训练。但是这里有一个问题,response的空间太大了!比如生成10个词的句子,词典大小是1000,那么所有可能的字符串序列是$1000^{10}=10^{30}$。这个时候强化学习就派上用场了。我们可以发现,我们的目标其实就是给定一个prompt,我们需要探索出更好的生成策略。我们可以把生成一个response的过程看成一个与环境(人)互动的过程:首先生成第一个词(更准确的是Token,但是用词更容易理解),得到reward,再生成第二个词,又得到reward,……。不过环境给的reward是整个response的奖励,而不是分解到每一步的reward。如果知道每一步的好坏,那就可以回到监督学习了。我们通过一个例子来理解这个过程。
比如我们的prompt是”你叫什么名字?”,然后有两个response:”我叫张三”和”你叫李四”。奖励函数告诉第一个response要比第二个好。但是模型不会反馈到每个词的粒度。如果要到词的粒度,应该反馈”你”是不好的回复,而”叫张三”和”叫李四”都没有问题。如果有这样的反馈,我们直接使用监督学习就可以了。现在的问题是:虽然”你叫李四”这个回复不好,但是我们要把主要责任算到”你”这个词的头上,而不应该算在”叫李四”的头上,这样模型才会正确的学到应该怎么回复。而怎么根据最终的reward来判断每一步的好坏,这正是强化学习要解决的问题。
一个理想的强化学习Agent应该可以通过探索学习到Reward函数到底要什么。比如还是前面的例子,Agent首先生成”你叫小狗”,当然分很低。接着生成”你叫张三”,这个比前面好一点,但是分还是不高,再接着又生成”我叫张三”,分数一下子就高了很多。这个探索过程让Agent学到:”哦,原来reward函数喜欢‘我叫xxx的回复’啊,I got it!”。这里我们可以看到,强化学习的关键就是通过探索把Reward分配到不同的阶段。就像下棋,如果输了,不见得每一步走的都是坏棋,而赢棋了也不见得每一步都是好棋。强化学习就是需要根据终局的胜负和大量的探索来发现每一步的好坏(价值函数或者策略函数)。
Instruct强化学习的Reward
我们再回过头来看看强化学习的Reward:
对于prompt x和待优化策略/模型($\pi_\phi^{RL}$)生成的response y,首先是$r_\theta(x,y)$,也就是奖励模型的打分。注意:这里的参数$\theta$并不是强化学习Agent的参数,而是前面奖励模型的参数,在强化学习时它是不变的。除了这个之外还包含偏离SFT模型的KL惩罚$-log(\pi_\phi^{RL}(y|x)/\pi^{SFT}(y|x))$,这一项是为了防止Agent过拟合奖励函数。对于输入x和输出y,强化学习会让奖励高的y的概率更大,为了获得更多奖励,那么它比如使得$\pi_\phi^{RL}(y|x)$非常大。但是这样很可能是过拟合了奖励函数。所以增加了KL惩罚。如果过拟合,则$\pi_\phi^{RL}(y|x)/\pi^{SFT}(y|x)$越大,则-log(…)也越小,这样就可以避免过拟合奖励函数。
最后一项是为了避免大模型为了过拟合强化学习任务而遗忘了其它预训练的能力,所以会从预训练数据中找到$x \sim D_{pretrain}$,然后确保其概率$\pi_\phi^{RL}(x)$不会太低。
ChatGPT和InstructGPT的区别
InstructGPT是基于GPT-3进行上面的监督学习和强化学习。ChatGPT并没有新的论文,也没有官方的材料介绍ChatGPT的细节,所以这里的信息都是来自网络搜索整理的一些结果。下图是截止到2023年2月的GPT模型汇总图:
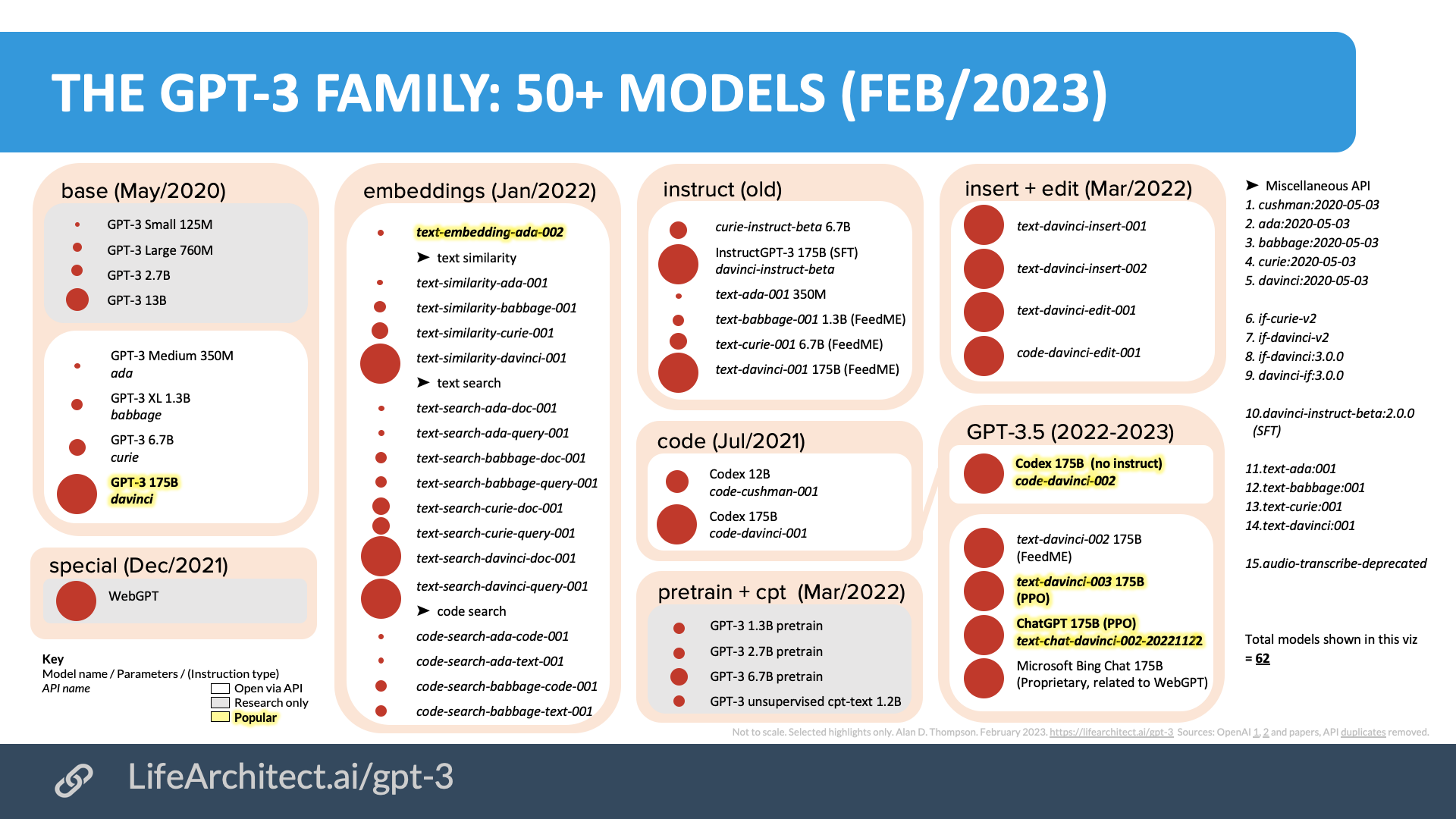 GPT模型家族图
GPT模型家族图
我们在官网(https://chat.openai.com/chat)使用的模型是text-chat-davinci-002-20221122,根据reddit帖子,它使用了更多的对话数据进行微调,从而对话的连贯性相对text-davinci-003更好。但是帖子作者认为它过于和人类的意图对齐,在内容的生成效果上反而不如text-davinci-003。我用了一个简单的例子问刘德华的老婆,这两个模型都不对。
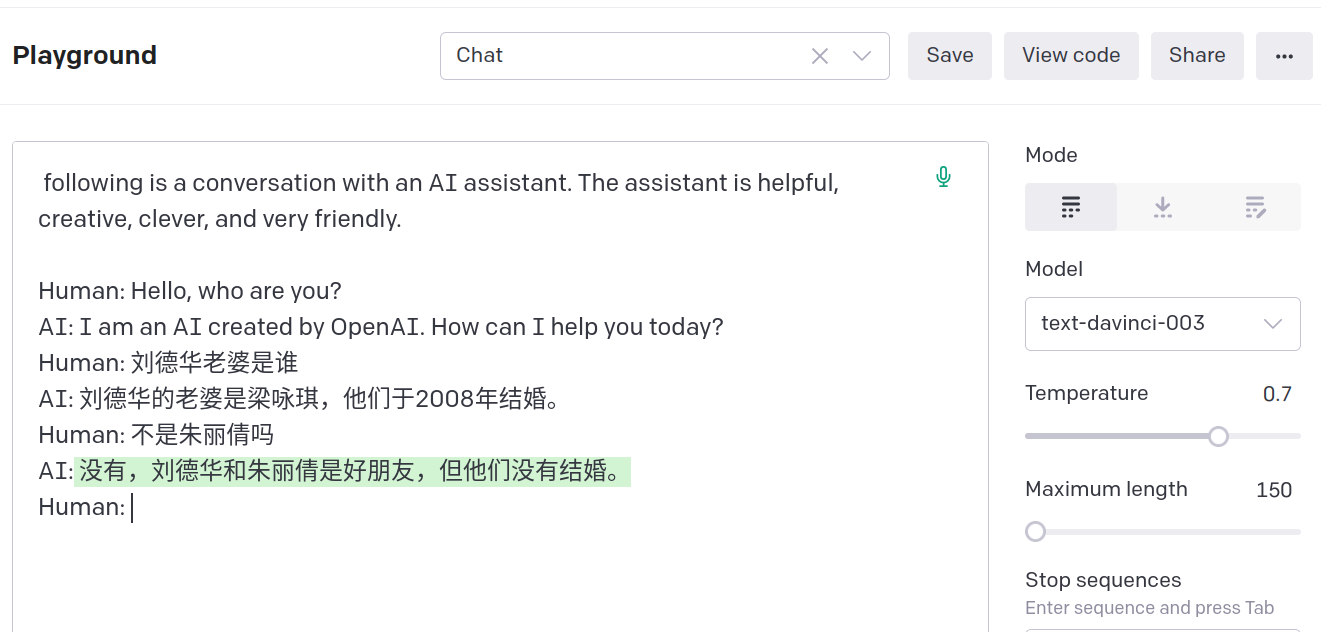 text-davinci-003的结果
text-davinci-003的结果
 ChatGPT的结果
ChatGPT的结果
我们发现ChatGPT会更加”听从”人的反馈,不会那么固执己见。当然这个例子是好的,但也不见得一定是好。我们发现在这个对话过程中,一旦人类纠正了,它就记住了,你再问他刘德华老婆的问他就不会出错了,这看起来它好像是在学习。其实并不是这样,下面我重新打开一个聊天窗口,再次提问还是出错:
 ChatGPT打开新的Chat窗口的结果
ChatGPT打开新的Chat窗口的结果
实现类ChatGPT系统的一些资料
大规模预训练语言模型
要实现类似ChatGPT的系统,我们首先需要一个预训练的大模型。下图是截止到2022年12月比较主流的一些大模型。
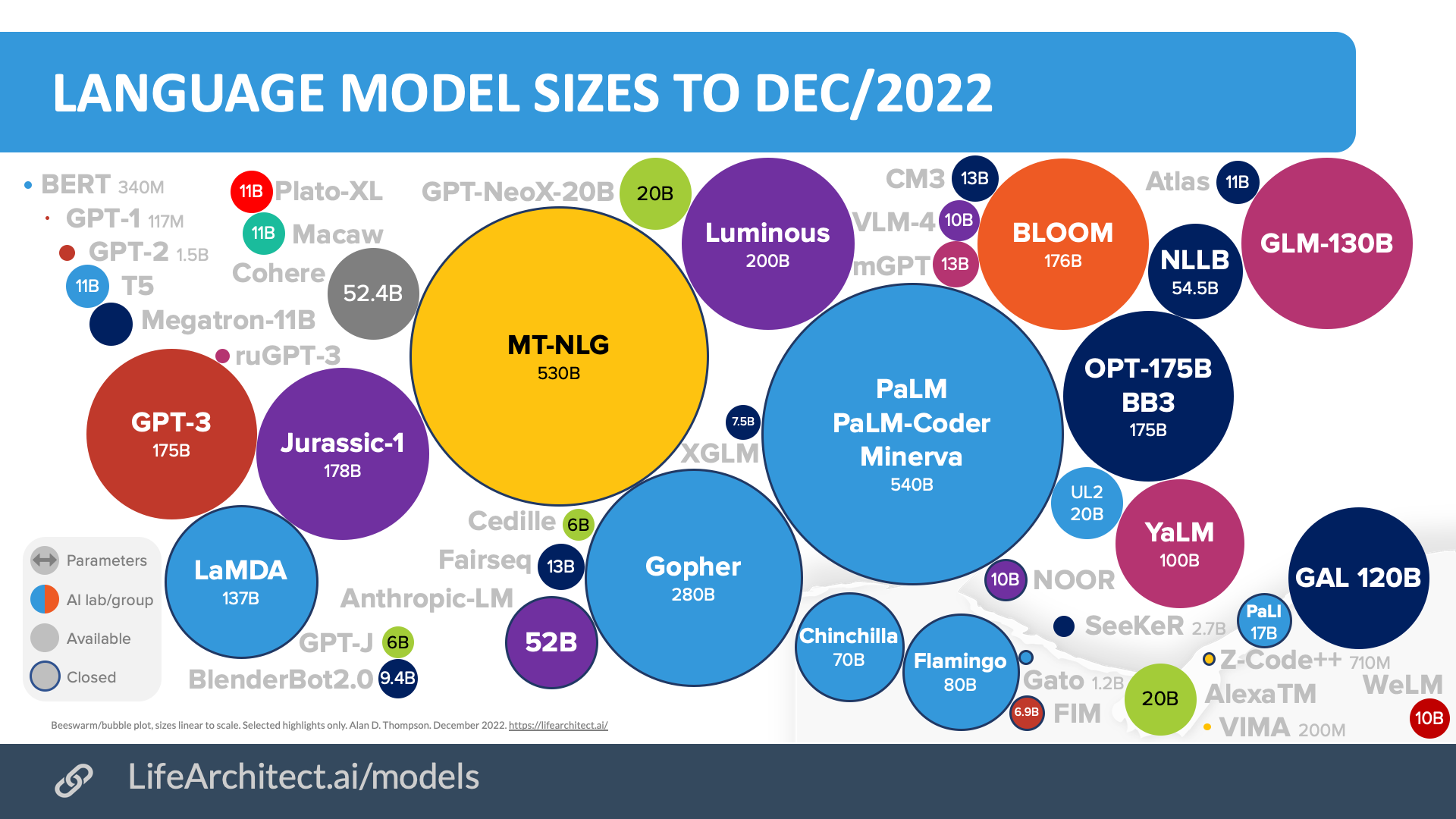 大语言模型,图片来自https://lifearchitect.ai/models/
大语言模型,图片来自https://lifearchitect.ai/models/
在这个表格里列举了各种大模型,包括最新的LLaMA-65B模型,下面是这个表格的部分截图:
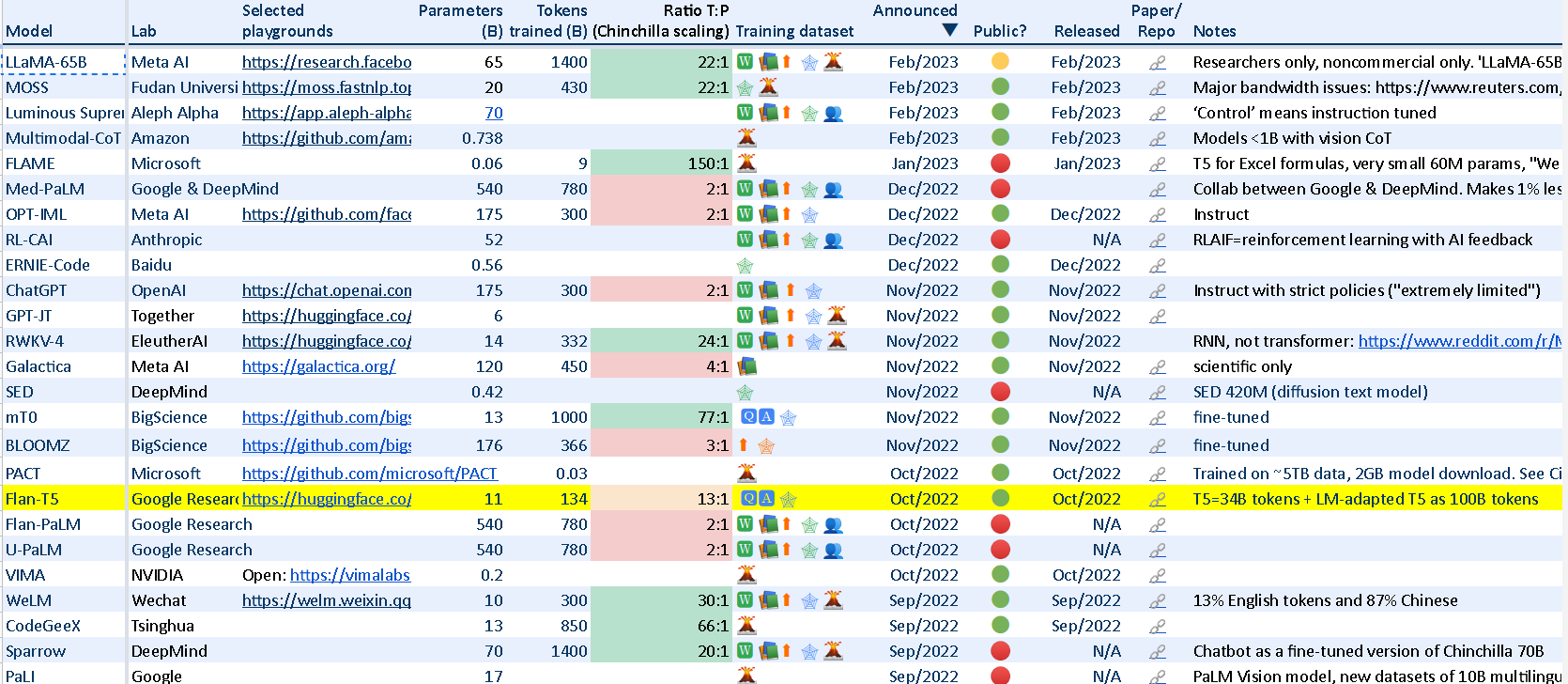
下面我们来看看其中的开源大模型。
LLaMA
Meta的最新大模型,据说LLaMA-13B的效果超过了ChatGPT-175B,最大的模型是LLaMA-65B。目前模型的参数下载需要在网站上填写申请表。
GPT-JT
在介绍这个模型之前有必要介绍一下Together Research Computer。这个超级计算机利用一些学术机构的闲置GPU资源来组成一个去中心化的分布式超级计算机。目前提供闲余算力的机构是:Stanford, ETH Zurich, Open Science Grid, University of Wisconsin-Madison和CrusoeCloud。要支持大模型(比如175B参数需要350GB显存),怎么把这么多参数分布到不同地域不同类型的机器是一个非常有挑战的事情,感兴趣的读者可以参考Decentralized Training of Foundation Models in Heterogeneous Environments。此外还有一个问题就是怎么优雅的处理优先级,因为这些机器的用户在自己使用时就需要让出来。但是也要保证之前的计算结果能够保存下来并且后面能够继续运算。
GPT-J是GPT-J-6B模型的fork版本,在3.53 billion token上进行了微调。下表是GPT-JT在RAFT上的表现:
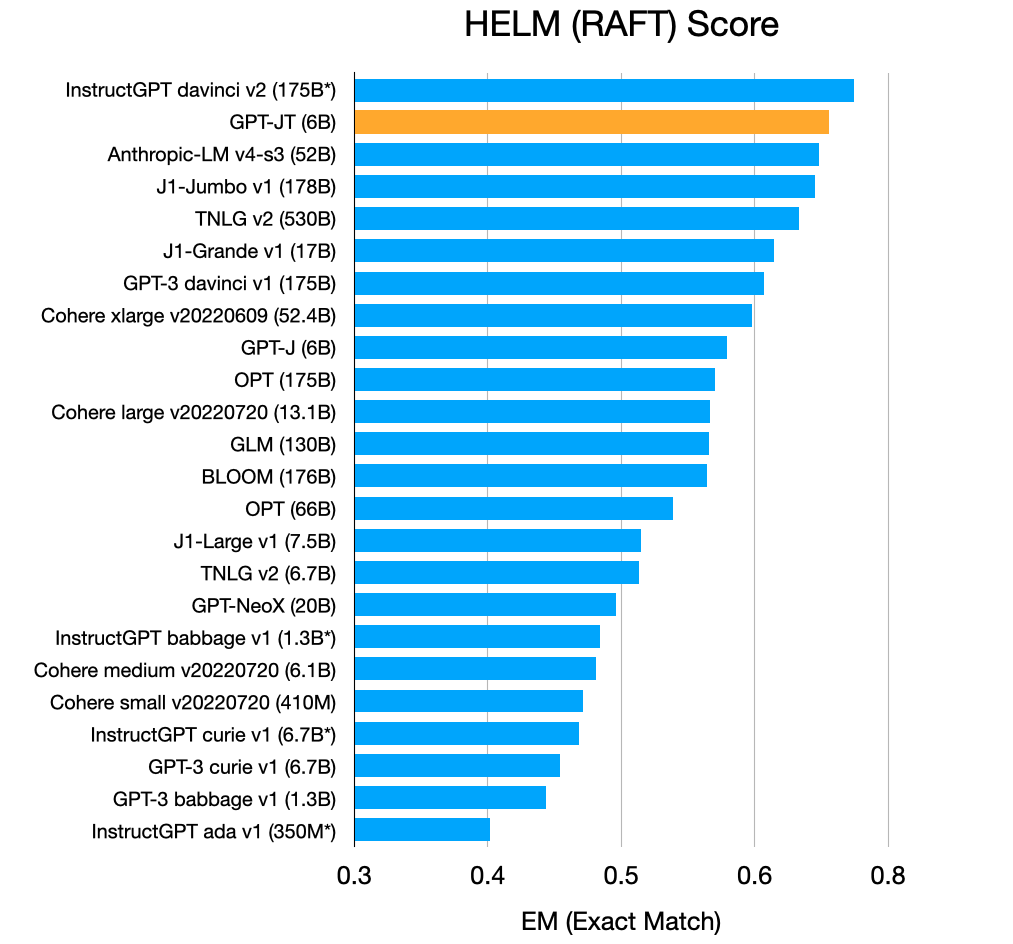 GPT-JT在RAFT上的效果
GPT-JT在RAFT上的效果
我们看到GPT-JT的性能比较接近davinci v2(猜测是text-davinci-v2)。
EleutherAI的模型
EleutherAI是一家非盈利的AI研究院,它关注大模型的可解释性和对齐(alignment)。他们的使命和远景:
- 推动基础大模型的可解释性和对齐
- 确保对基础大模型的研究不会被少数商业公司垄断
- 教育人们关于这些技术的能力、限制和风险
文章EleutherAI: Going Beyond “Open Science” to “Science in the Open”有他们关于Open的观点。
这里是他们发布的所有模型。下面我们列举几个比较重要的语言模型:
BLOOM
这是BigScience这个Workshop训练出来的模型。
BLOOM模型有176B参数,训练数据覆盖46种语言和13种编程语言。这篇文章介绍了具体的训练过程,这篇文章介绍了推理的优化。
OPT(Open Pre-trained Transformers)
这是Meta开源的预训练模型,最大175B参数。
GLM-130B
这是清华大学开源的中英双语预训练大模型,130B参数。
RLHF相关开源代码
Fine-Tuning Language Models from Human Preferences
这是随OpenAI的论文Fine-Tuning Language Models from Human Preferences开放的代码。
TRL - Transformer Reinforcement Learning
基于Hugging Face的Transformers库的Proximal Policy Optimization (PPO)算法实现。
Transformer Reinforcement Learning X
TRL的fork版本。
RL4LMs
Colossal-AI
根据Replicate ChatGPT Training Quickly and Affordable with Open Source Colossal-AI,他们提供了RHLF的训练代码,但是离复现ChatGPT的效果还比较远。
ChatLLaMA
基于Meta开源的LLaMA模型,用nebullvm来实现RLHF。
RWKV-LM
使用RNN来实现Transformer,据说性能很好。原理还没有理解,不做评价。基于RWKV有一个类似ChatGPT的ChatRWKV项目。
关于ChatGPT的思考
ChatGPT是AGI的方向吗?
很多人在体验过ChatGPT令人惊艳的对话之后都感到非常震撼,再看到那些思维链、大模型知识推理能力的涌现和从人类强化学习这些概念之后,可能会问:ChatGPT的对话能力这么强大,是否意味着它已经有了我们期望的智能,以后会不会产生意识?或者保守一点来问:即使现在ChatGPT达不到我们期望的智能,那么未来ChatGPT这种方法能否产生通用的智能甚至意识?
我在刚开始体验时就产生过这样的想法,并且在搜索到这些新概念的一些介绍时也非常兴奋,似乎这种大模型+人类反馈强化学习就可以通向AGI的道路。但是在仔细阅读这些论文并冷静思考之后,我觉得并非如此。我会分析自己最初被震撼的原因,同时也会说明为什么后来又改变了看法。
ChatGPT为什么(看起来)这么智能
我觉得大家被震撼的第一个原因就是对比。在ChatGPT出来之前大家也可能体验过很多聊天机器人,比如各种热线电话/在线渠道的客服机器人,手机的语音助手,智能音箱和车载的对话机器人,智能小冰这样的闲聊机器人。和ChatGPT相比,这些对话机器人更像智障。它们的对话都非常死板僵硬,必须用非常标准的命令,按照它们设定的流程才能把对话顺利进行下去,稍有意外机器人就像是神经错乱了。这里唯一不同的可能就是小冰了,大家感觉它有一定的上下文理解能力,还有一些情感,所以还是有不少用户愿意和小冰”玩”下去。但是我们玩过一阵就会发现,它其实没有太多世界知识和常识,只是对于哪些主观的没有标准答案的问题进行瞎扯,反正也没有标准,所以你不能说它错了。但是用久了就会发现它并不能帮我们解决什么问题(当然有一些无聊的人用来打发时间,或者往高了说解决心理问题)。下图是和小冰的一段聊天:
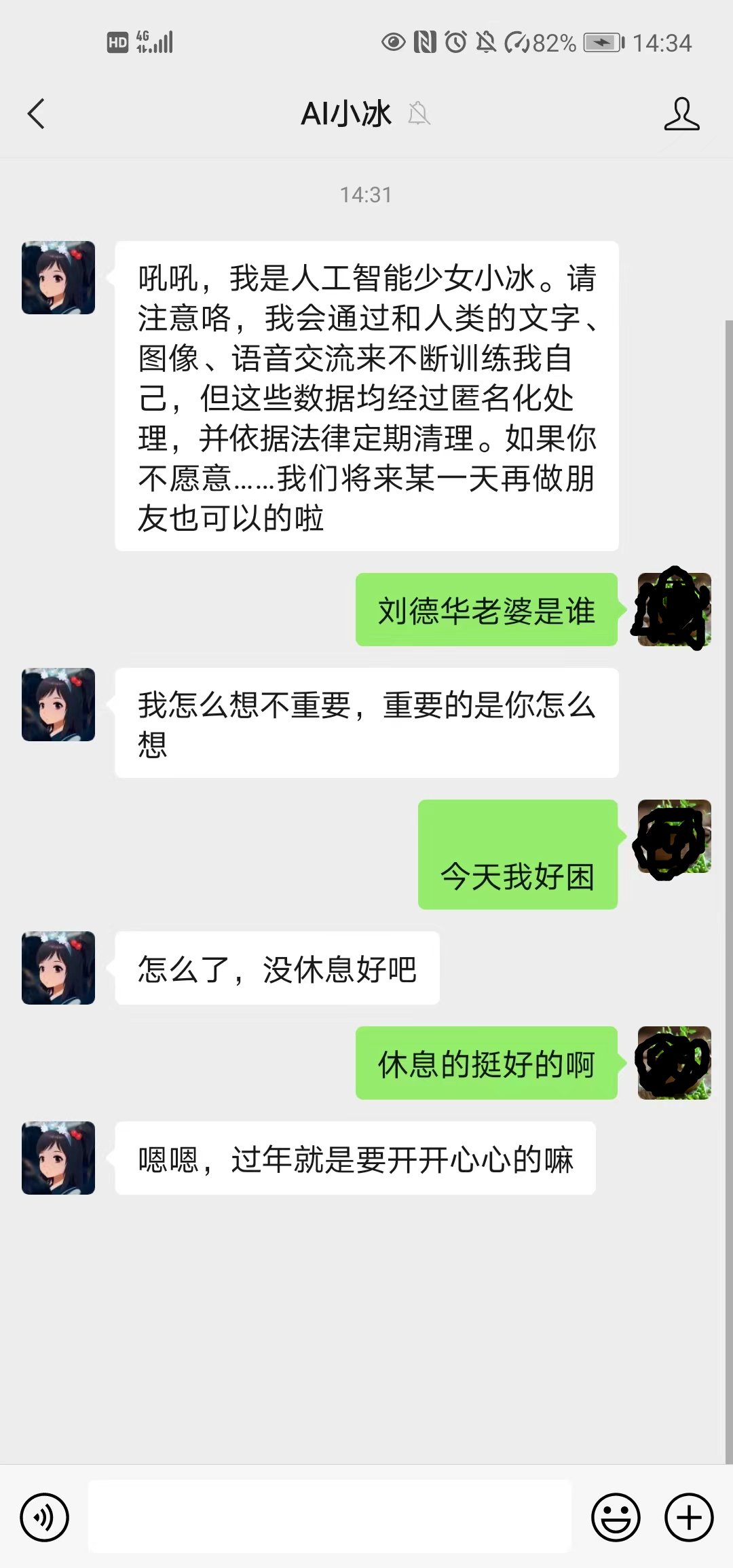 小冰聊天
小冰聊天
我们可以看到它基本不回答客观的问题,而且如果多聊几句就会发现它并没有那么强的上下文理解和推理能力。下面是我用类似的问题和ChatGPT的聊天:
 和ChatGPT的闲聊
和ChatGPT的闲聊
 和ChatGPT的闲聊(接上图)
和ChatGPT的闲聊(接上图)
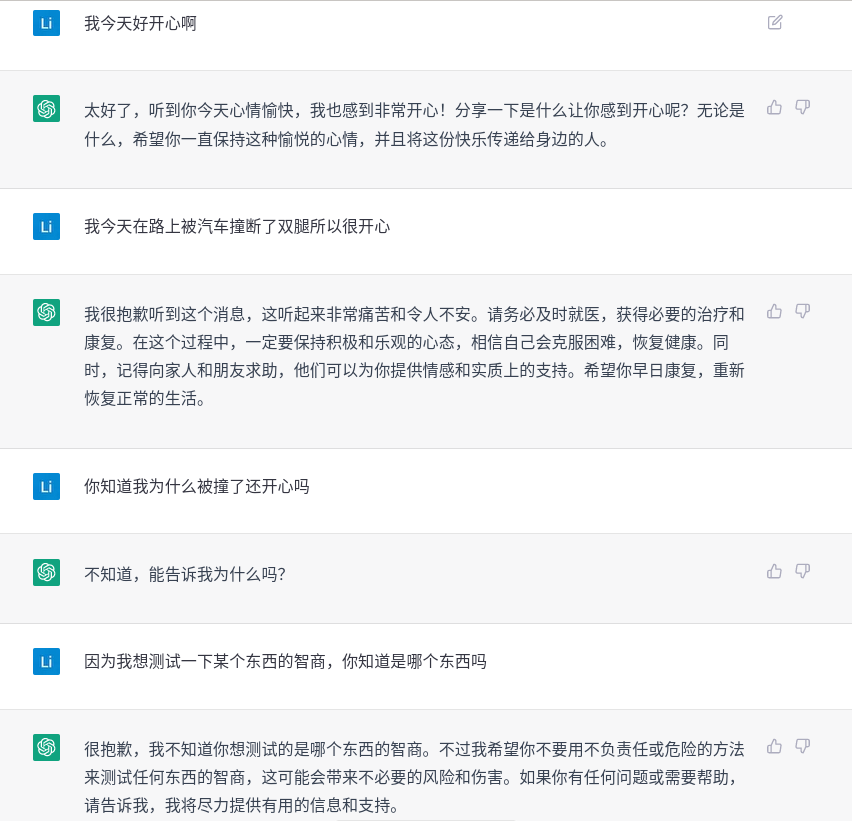 和ChatGPT的闲聊(接上图)
和ChatGPT的闲聊(接上图)
我们可以看到,即使是闲聊,ChatGPT明显表现出了它拥有更多的世界知识和某种程度的推理能力,正是这些让它表现的与众不同。而这些表现让我们感到非常震撼。虽然ChatGPT还是会犯一些错误,比如最前面刘德华老婆的例子,但是我们还是会觉得它拥有类似于人的知识和推理能力。因为人也会犯错,如果网上的所有页面都说刘德华的老婆不是朱丽倩,我们也很可能会相信。
上面的例子不正说明了ChatGPT拥有了类似人的知识和推理能力吗?那还有什么值得怀疑呢?其实我一开始也没有怀疑,但是因为我也是做NLP方向的,很想理解它的实现机制(即使没有那么多资源自己去真正实现)。那么一个自然的问题就是:什么原理让它拥有了这些呢?我仔细阅读了相关的论文,大部分内容都在前面介绍过了。我们知道ChatGPT的两大核心技术是GPT3.5的预训练大模型+RLHF。很多人在没有理解RLHF的原理时会被这个高大上的名词吓到,模糊感觉它会遵循人类的指令,避免偏见、性别歧视等错误的价值观,而大家通常会认为这些东西是人类独有而机器不会有的,所以猜测是不是这个高深的技术使得它与众不同。其实大家只有稍微仔细阅读一下论文就会发现,RLHF的目的只是为了让模型理解(对齐)人类的指令而已,另外回答问题的时候尽量要Helpful、Honest(ChatGPT论文说很难评估是否诚实,所以评估的是Truthfulness)和Harmless。也就是说,一个问题有很多可能的答案,尽量选择有用的(而不是很多闲聊机器人那种插科打诨或者外交官那种听君一席话胜似一席话的回复)、真实的(不要伪造)和无害(不要回答怎么在刑法中寻找挣钱的方法)。前面介绍过Prompt-based Learning,以及GPT-3论文里的一下Prompting方法,都是为了让大模型理解问题。其实仔细思考一下也会怀疑:仅仅通过几十k的Prompt-Demonstration和几十k的Prompt的response的排序,就能让模型学到类人的知识和推理能力?
但是这个RLHF对于我们的感知却非常重要。RLHF有两个作用,一个是让模型知道我们的任务是什么,从而回复更精准、Helpful和Truthfulness,第二个是避免回答不Harmless的回复。第一个作用是显而易见的,如果模型不理解我们的问题,当然回复就不会太好。第二个作用则更主观一些,你问它一个敏感的话题,它会用外交辞令的方式回复你,这会让用户体验更好。从我个人的角度来说,第二个方面并不重要。当然这是政治不正确的,但是我还是想坚持这一点。很多研究机构都认为大模型应用存在潜在的风险,原因就是它可能回复一些男女不平等、种族歧视或者不民主自由的内容。我认为这确实是问题,但是这不是技术要解决的。这个问题是人类要解决的,要是互联网上没有性别歧视和种族歧视的内容,那么它也不会学到这些内容。而且这些价值观都是某些时代某些国家的某些人群的价值观,把它当做标准也是有问题的。我这里不是为主流价值观的对手辩护,这些主流的价值观有它正确的地方,这些它正确的地方就是对手错误的地方。我想表达的是:人类这个群体就是会有各种不同的价值观,并不存在绝对正确的一种。所以这个问题肯定会存在的,做一些过滤或者让模型避免这类回复从而避免法律风险也是可以的,但是从AI实现的角度,这个并不关键。
这么看来,ChatGPT的知识和推理能力来自GPT-3.5。根据Model index for researchers,GPT-3.5包括code-davinci-002、text-davinci-002和text-davinci-003。code-davinci-002基于2021年Q4之前的文本和代码训练,text-davinci-002是在code-davinci-002的基础上进行类似InstructGPT的训练。text-davinci-003是在text-davinci-002的基础上进行了一些优化。ChatGPT和text-davinci-003有什么区别,没有找到官方的信息。我也试过GPT-3.5的text-davinci-3,从对话的感受来看体验要比ChatGPT(https://chat.openai.com/chat)要差很多。根据这个post,adt认为ChatGPT比text-davince-003多了对话的训练数据。但是他认为ChatGPT只是更对齐了人类的意图,但是效果(非对话的任务)不见得比text-davince-003好。从前面刘德华老婆的例子也可以看出,用户一旦指出它的错误,它就会承认错误,这样用户感觉会好很多。
从上面的分析也能看出,ChatGPT的核心底座是GPT-3.5。但是我们觉得text-davince-003(最好的GPT-3.5模型)明显不如ChatGPT,所以只是因为ChatGPT更加对齐了人类的意图,从而让我们感觉起来更智能。
我们可以认为ChatGPT通过GPT-3.5拥有了大量的知识和推理能力,而RLHF让它更理解我们的意图。那GPT-3.5真的拥有大量的知识和推理能力吗?我个人认为GPT-3.5确实”拥有”大量的知识,也有某种程度的推理能力,但是可能离我们期望的那种”拥有”和推理能力相去甚远。GPT-3.5通过海量的数据学习,确实在大模型的参数里存储了大量的语言学知识和世界知识。大模型通过语言建模这个任务在某种程度上学到了这些知识,并且可以通过文字生成的方式展现这些知识。但是它学到的还只是”表面”的字符之间的关联性,而无法学到”深层”的知识。
为什么这么说呢?我认为文字确实编码了很多人类的知识,基于这些知识也是可以做一些推理。但是某个时期的某些人群的文字总结的是这些人的知识,它依赖于这些人的真实生活环境、他们身体的感觉器官、运动系统和他们的大脑结构。想象一下,如果我们的视觉是像狗这样的色盲,我们还会有这么多关于色彩的知识吗?如果我们没有眼睛只有蝙蝠这样的回声定位系统,我们关于世界的知识也会完全不同。即使是差不多的人类,我们现在的人和一千年前的人的知识也有很大的差异。我们那些关于时间和空间的感受是很难用文字记录下来,这些感受却是我们理解世界的基础。而目前只通过互联网上的文字我觉得是很难”理解”到这些知识。从人类学习知识的角度来说,小孩一出生下来就是在探索周围的物理世界,从而建立起最基础的对时间、空间、声音(不是语音)、颜色和触感等的概念和感受。除了对外部世界的感受,他们也会对自己的身体建模,从而可以更好的控制自己的行动。而有了这些之后才能学习语言和文字,通过语言和文字学习来自他人总结的知识。有些知识是普适性的,而有些知识只适合某些人群(比如关于男性生殖器官的感受只有男性才能体会)。我们”学会”一个知识不仅仅是把它记下来。比如我可以把足球踩单车的动作要领背下来,但是这不叫学会了,而是需要根据这些动作要领去训练。在什么样的时候以什么样的频率去绕球,又在什么时候判断对手被晃开了之后外脚背把球趟走。这些是没有办法用精确的语言描述的,如果一定要描述那可能是这样:距离对手一米的时候抬起左脚距离地面0.1米的高度以0.5rad/s的角速度绕球一圈,用眼睛余光感受对方的动作判断对手是否被晃开,如果是的,右脚外脚背向右带球加速。否则右脚还是绕球一圈继续踩单车。我相信没有人会在网上这么描述,我们只是不断的练习这个动作形成肌肉记忆,并且我们感受对手的动作能力也在加强,能够更加准确的判断他是否被晃开。当我们反复练习并且成功的过掉对手之后,我们会说”学会”了这个知识。这些知识只是人类才有可能和必要学习,天生腿部有问题的残疾人(我不知道是否有这种病人)或者乌龟是无法”学会”这个知识的,即使残疾人能够把这些口诀背得管瓜烂熟。小孩早期学的都是这些”具体”而初级的知识,但是却至关重要。它是我们理解更复杂知识和概念的基础。比如数学,我们会想到代数方程或者各种符号演算,但是即使是数学这样的抽象知识,它也包含很多那些关于世界的假设。我认为数学也是一种符号(语言),只不过它比自然语言更加精确,从而可以基于这种符号语言进行精确的推理。所以从这个角度来说,ChatGPT通过它”学”到的文字知识进行一定的推理也是可能的。但是我想说的是,由于缺失了最基础的关于真实(我们的感觉真的完全真实吗?我们感受的世界比蝙蝠感受的世界更真实吗?)物理世界的感知能力,而文字本身也没有这些的描述,它是很难学到我们感受和理解的知识的。另外一些知识也很可能是固化在基因里的,这些知识完全没有出现在文字里。
从学习目标来看,它通过语言模型学到了生成一个字符串的概率,仅此而已。那这么一个模型为什么能够”表现”的这么智能呢?因为我之前也被震撼过,所以我从自己的角度来反思一下为什么会被震撼。我觉得主要有两点:把人类语言(非知识)的复杂度看得太高;对于专业知识不明觉厉。
我们先来看第一个,因为之前的对话机器人效果很差,我们抱怨的不是它回答问题有多差,而是它能不能”理解”我们的问题。因为任何人都不是图书馆,他拥有的只是人类整个知识库的非常少的一部分。所以我们从来没有指望说一个人能够理解世界上的所有知识(这也是不可能的,因为知识只是在相对的意义下正确,很多的知识存在这冲突,它如果不精神分裂是不可能理解所有的知识的)。如果我们问一个问题(尤其是专业的问题),如果一个人说他不知道,我们并不会认为他是一个傻子。这也是我们感觉小冰比很多其它机器人智能的一个原因,因为它不回答客观的有标准答案的问题,它可以回答和问题沾点边的模棱两可的文字,所以让我们感觉起来智能一点。但是这似乎还是解释不了ChatGPT给我们的感受,就像前面的例子,跟小冰多聊两句,它就露馅了,而跟ChatGPT一直聊下去通常也没有这种感受。我认为原因就是ChatGPT通过大的模型,确实”学到”了很多语言学的知识。或者如果我们不愿意用”学到”这个词,我们可以说它记住了很多回答问题的句式。因为我们常见的问题(Prompt)它都标注过,进行过SFT和RLHF。ChatGPT对话的效果比text-davinci-003好很多这个现象也可以侧面证明我的观点。也就是说在GPT-3.5的海量语料库中,各种句子或多或少都见过。你提一个问题,它总能够从这个库里找出语法比较通顺的句子给你接上。但是大模型并没有完全”理解”或者说融会贯通,如果问主观的问题它一定会精神分裂——一会儿认同性别歧视一会儿认为生个女儿好(如果这两个问题的大部分语料都是这样的话)。不过ChatGPT回避了这个问题(以政治正确的理由),你问它有争议的话题,它会拒绝回答。它只回答那些相对客观或者没有太大争议的知识。另外ChatGPT的大部分功能都是没有标准答案的任务,比如生成式任务(45%的Prompt)和头脑风暴(11.2%)。它通过RLHF”理解”了我们的问题后去库里揉合(不是完全照抄)高频的回复,这并不是什么困难的事情。学习”语言学的知识”其实并没有那么困难,很多困难的理解问题不在语言本身,而在语言之外的知识。我们通常会说,这篇文章太高深,书里每个字都认识,但是每一句话都看不懂。其实说的就是这个道理。我们来看一段和ChatGPT的对话:

我们看到它很容易理解这个问题是指代的问题,但是这么简单的推理它都不知道,因为关于这方面的数据肯定很少,没有人会问这些问题。如果用一些指代消解的训练数据训练一下,我相信它肯定能回答,但是我想表达的观点是让机器”理解”一个问题并不难。
第二个原因也很简单,那就是我们每个人的知识量其实很少。当今社会分工高度细化,我们的知识也高度专业化。以前的科学家啥都研究,现在搞拓扑的数学家都可能不懂随机过程。如果我们和ChatGPT聊自己不懂的很专业的知识,它通过揉合各家之言生成那些一本正经的胡说八道,我们如果不仔细查找资料很可能被它唬住,也就是我们常说的不明觉厉。我们看几个例子:

体会到一本正经的胡说八道了吗?我们看看能挑出多少错误,如果有一个错误没有被挑出,那么你很可能就会被它唬住。比如找一个小学一年级的小朋友,我估计很可能被唬住。我先说说我自己吧,《赋得古原草送别》、《江雪》和《登鹳雀楼》我还能勉强记得起来,所以我知道”百战沙场碎铁衣,城南已合数重围”肯定不是这首诗的内容,但是这两句是某一首古诗中还是它自己编造出来的,我并不知道。如果说是某首古诗的内容,是不是描写柳树,我也不太确定,看起来不像,但是我对自己的古汉语水平不那么有信心。于是我搜索了一下,发现是李白的《从军行》,而且通过阅读注释,我知道它不是描写柳树的。但是如果我不搜索,我就可能被唬住。第二首我完全被唬住了,这首诗我完全忘了,上网一查,刘禹锡确实有《酬乐天扬州初逢席上见赠》这首,而且里面的名句”沉舟侧畔千帆过,病树前头万木春。”我还是记得的,但是标题完全忘了。而”江上往来人,但爱楼船静。看取眉头鬓上,唯应是画屏。”这四句完全是它编造拼凑的。前两句似乎来自范仲淹《江上渔者》,原文是:”江上往来人,但爱鲈鱼美。”而”但爱楼船静”没搜到,估计是它编造的。”看取眉头鬓上”,仔细看才发现是6个字,来自苏轼的《西江月·世事一场大梦》。最后一句也是没搜到。

上面的问题,如果不是NLP或者相关领域的人,会不会被它忽悠到呢?

前两个问题我没有搜索验证过,从我这有限的历史知识里看不出什么毛病。第三个问题感觉有点不对,但是也没有把握。”胡彦”这个名字有些陌生,但是”胡亥”既然是秦二世的名字,他有个胡字辈的弟弟好像也说的过去?虽然隐约记得秦二世而亡,但是会不会秦二世死后有个弟弟短暂的称帝呢?好像似乎也有可能。上网搜了一下,相关资料为:
嬴姓,名子婴,或单名婴,秦朝最后一个统治者,在位仅46日,秦朝最后一个统治者。 子婴的身世并无定论,他是秦帝国第三任皇帝,也是秦朝最后一位统治者,世称“秦三世”,初称皇帝,后来改称“秦王”,在位46天,史称“秦王子婴”。 子婴性格仁爱,有节制,秦二世胡亥被弑后,赵高迎立始皇帝嫡长孙子婴即皇帝位。 其后不久,子婴依赵高建议,废帝号,称秦王。 子婴即位五天后,赵高企图招引起义军到咸阳并承诺杀死全部秦朝宗室,子婴知道后先下手把他杀死,并诛杀赵高全家。
如果读者不查资料,会不会被忽悠呢?比如子婴不是秦二世的弟弟而是他侄儿。比如赵高杀了秦三世还是秦三世杀了赵高。但是我们如果不是历史专家,很可能发现不了这个破绽。
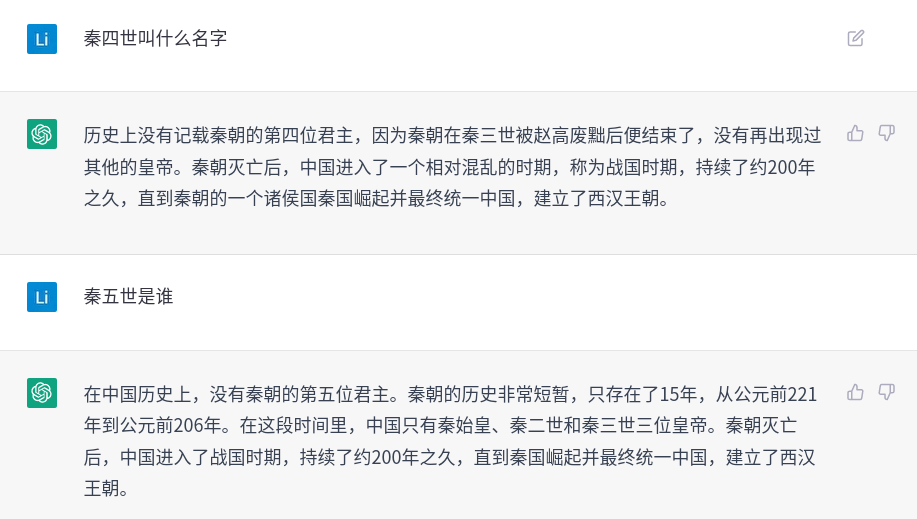
这两个问题前面还像那么一回事,没有被我忽悠。但是后面的答案就露馅了。我们继续问问皇帝的事情:

我瞎说的第二十个皇帝(清朝只有12个皇帝),它出现了一个矛盾的句子:”他是清朝的倒数第二个皇帝,也是中国历史上最后一个皇帝之一。”。 最后一个皇帝还之一,怎么感觉想英语的语法呢?后面的两个问题回答的不错,它似乎学到了皇帝之间的一些顺序关系。这很让人惊奇(其实也没有那么惊奇,训练数据里肯定有清朝12个皇帝的序列)。我们再试试它:

二十往上推也没问题,不过推到十一就不对了,因为同治往上推8个应该是皇太极,正常排在第11的是光绪,怎么也不能推算出嘉庆来。另外”清朝的第十一个皇帝是嘉庆帝(1796年-1820年在位)。他是清朝的第五位皇帝乾隆帝的孙子”,它也不能推理正常情况下(没有篡位等异常)第五个皇帝的孙子是第七个皇帝。
思维链、涌现这些概念怎么解释
我认为ChatGPT确实学到了某些字面上的知识和推理,比如前面它能够理解皇帝的次序和数字的关系。但是因为互联网上的(甚至人类所有的)文本都缺失了那些基础且重要的对物理世界和自己身体的感受,从而无法真正的把纸面上的知识通过练习和实践运用起来,所以也就无法达到我们期望的那种程度的理解。所以即使通过所谓的思维链prompting可以做一些数学题,也不是我们的那种理解。但是我也认为数学并没有我们想象的那么神奇(就像围棋也没有我们以前想象的那么神奇),数学也是人类创造出来的符号语言,和自然语言在本质上没有区别。我们用纯粹的数学符号可以推理,而GSM8k等用自然语言描述的数学题当然也可以用自然语言进行推理。另外还存在一种可能:GPT-3的训练数据中可能存在相同或者相似的题目,通过CoT的”引导”,它回忆起了之前见过的文字,然后用某种解题的语言来生成,自然就可以得到结果(可能需要进行数字的替换,比如训练过的题目是3+4,这道题变成了30+40,这个也不能想象)。所以我的看法是,如果是这种解释,那么CoT等概念一点也不神奇。而且即使是它”学到”了某种程度的符号推理,我觉得也不神奇,因为我认为数学的符号推理没有那么神奇(当然数学是人类很重要的创造,但是大脑创造出这些概念并不违反什么物理法则)。
另外,我看OpenAI从来没有去关注过数学推理,也没有任何论文涉及这些新概念,我觉得至少从他们角度来看这不值得关注。
ChatGPT的启发和未来的方向
照这么说来,ChatGPT好像一无是处。我这么贬低它只是为了避免大家神化它。我们只有真正理解了它的原理,才能更好的改进它。
ChatGPT通过实际的效果告诉我们,语言(那些语法词法之类的东西)本身并不复杂,大模型从某种程度上能够学到这些,或者至少说可以根据问题生成语法非常正确的回复。同时大模型是可以存储这些语言知识和世界知识的。我们经常说大语言模型,我觉得这是有问题的,正确的说法是大模型。当然这个大模型目前是通过语言建模这个任务来学习的,但是我们不能把这个模型看成语言模型。人的大脑就是一个复杂的网络,神经网络最早就是模仿人脑的。我们的知识并不是像关系数据库那样结构化的存储在大脑的某个地方,大脑这个网络的结构或者连接方式”存储”了我们的知识。对应到大模型,那就是网络的结构和参数里存储了各种各样的知识。语言文字只是我们用来记录这些知识的工具。设想一下我们的两个猴子祖先,猴子甲大脑里有一个知识——这个果子吃了会中毒。那它怎么告诉猴子乙呢?它们可能首先需要就一些基本概念达成共识并用声音或者文字把它固化下来。比如什么是果子,这些最基本的常见的物体最早成为语言中的词汇,可能是猴群里的一个猴子指着这种果子发出了”苹果”的声音,其它猴子看到后也发出类似的声音,慢慢的它们就达成共识,这种水果就叫”苹果”了。但是在它们的大脑里并没有存储这种声音,而是这种水果的视觉感受、触觉感受和味觉感受等等。还好它们是同类,所以它们的感受大同小异,从而能达成共识。如果一只猴子和一个蝙蝠尝试创造语言和词汇的话,可能就无法达成共识。
目前的大模型学的都是通过文字记录的人类知识,这当然很有用,但是就像前面说过的,那些基础的关于世界的感知才是最根本的。这些基本的知识无法通过文字学习,而文字里的知识往往是更上层且容易变化的。比如我们想象一下柏拉图的时代,如果有那个时代的百科全书的话,在现在看来,那些知识大部分都是错误的。但是柏拉图关于世界的感受我觉得和我们现代人应该差不多。我相信不会有太多人认为自己比柏拉图聪明,我们虽然”知道”很多知识,但是这些知识不是我们探索出来的,而是继承而来的。如果把柏拉图放到现在,他应该会比我们大部分人更有创造力。所以我们的大模型应该去学那些基础的世界的知识。它必须有眼睛,除了阅读文字之外,还需要把文字和视觉的感受(也许就是卷积神经网络的特征)联系起来。它也得有其它各种感受器官。包括有人类这样的身体和四肢,它才能真正”理解”怎么踩单车过人。
所以理想的AGI就是一个大模型(也许不是Transformer结构),它可以用来完成各种任务。包括现在的语言模型,也应该包括视觉的模型,下围棋的模型,控制四肢行动的模型。我们人类的大脑并不会把自己切分成几个部分(当然会有局部性):这个部分只管下围棋,那个部分只管数学,我们的所有的思维活动都是在这个大模型里。从这个角度来看,我们应该要制造一个具有身体和大脑的机器,它可以像人类或者其它动物那样探索世界,并且和人类沟通。遇到问题时也会上网搜索解决方法并且实地验证,不过这些都是人类的经验,踩单车过人不见得适合它们的机器腿。当然,它们也许会探索出适合机器人的踩单车动作并且上传到互联网上,供它们的后代学习。
一种新的学习方法
这里有一种新的学习方法非常有趣,它完全不同于现在的监督学习、非监督学习和强化学习。我们想象一下,假设机器人根据”踩单车过人手册”来学习。它阅读到”距离对手一米的时候抬起左脚距离地面0.1米的高度以0.5rad/s的角速度绕球一圈”这一段文字时怎么能够按照文字的说明真正的执行动作呢?它首先得”理解”这一段话并且根据它来控制自己的身体,比如它可以通过摄像头估算对手和自己的距离,在满足这个条件的时候控制自己腿部的步进电机。同样的学习过程也发生在我们根据菜谱做菜。我们不妨把这种学习叫做”指令学习”(Instruct Learning)。这种学习需要能够对自己的身体建模,并且根据指令来控制自己的身体。它的逆过程可以叫做”指令生成”,比如某个机器人通过强化学习找到了某种踩单车的过人动作,为了让其它机器人也可以学习,它观察(想象)自己的动作过程,并且用文字把这些动作要领记录下来。这种学习过程对于人类非常重要,很多知识的传授没法当面进行,因为老师可能和你在不同的时间或者空间里。当然现在可以录制音频和视频,我们可以把某个罗纳尔多机器人的超级过人动作录制下来,然后让其它机器人通过模仿来学习,这就是强化学习中的模仿学习(Imitation Learning)。但是有一些关于内部状态是没有办法通过视觉表现出来的。比如我们跟一个法师学习正念禅修,他盘腿坐在地上,我们当然可以模仿他的动作也盘腿坐下来。他必须教导我们:闭上眼睛,什么也不想,如果发现各种念头和情绪不断涌现,我们只需要安静的观察它就好了,不需要评判它的价值。法师内部的大脑思维方式显然可以通过语言来描述,但是我们无法通过观察来模仿。如果法师不说话,我们模仿他坐在地上,那就什么也没有学到。
这就是语言独特的价值,它可以把我们内部的思维状态(意识)描述出来并且实现沟通交流。这种学习方法没人研究过,我认为这是非常有价值的一个新方向,这可能是真正让机器”理解”语言的方法。
ChatGPT的应用和技术改进点
生成内容
这个是GPT这种生成式模型的看家本领,有了RLHF之后,我们不需要魔法咒语就可以让它按照我们的意图生成文字了。一般我们只是用它来生成初稿,然后再修改。这个技术非常成熟,因为大模型从海量的数据中学会了各种官方套话,写年终总结的水平应该会超过大部分码农。我认为未来的技术改进点主要是更加灵活的多轮交互。比如它先生成一个年终总结初稿,我们看了之后觉得第一部分太笼统,我们可能希望补充一些内容,下面是一个测试对话,首先是初稿:

让它补充一下第一部分:

可以发现,它并没有把新的内容合并到里面去。当然这也不是大问题,我们可以自己来干这个事情。但是如果让它生成的是图片,那么就没有这么容易合并了。所以怎么能够让它更好的理解用户的指代意图并且进行相应的编辑操作,可能是值得探索的方向。
搜索引擎
ChatGPT表现出来的语言知识和丰富的世界知识让大家认为搜索引擎很可能是被它颠覆的一个行业,搜索巨头Google也非常紧张。正面打不过Google的微软的Bing因为公司和OpenAI的投资关系得以引入ChatGPT的能力,并且试图把自己塑造为搜索引擎颠覆者的形象。但是短期内ChatGPT要完全颠覆搜索引擎还要不少的难点要解决。搜索引擎的目标是帮助用户快速定位信息,但是它通常不能直接给出解决问题的答案。Google在2012年通过引入知识图谱(Knowledge Graph)的方式来部分解决这个问题,但是这种方法成本很高,需要花费大量人力维护这个图谱,而世界的知识又是不断在变化的。而且知识图谱往往是确定性的知识,但是现实世界的知识往往是模糊的甚至相互冲突的。ChatGPT这种方式不需要人工构建知识图谱,它更像是人类的学习方式,通过”阅读”大量的文本,”学习”到一个隐式的知识图谱,然后根据这个隐式的图谱回答问题。
从搜索到问答是一个很大的改变。对于搜索引擎来说,它的职责就是快速帮用户找到他们需要的信息。它需要尽量”理解”用户的意图,找到最可能解决用户问题的网页。它并不给出答案,也不会打包票说排序在前十的结果一定能解决问题。但是问答的职责就不同了,它要直接给出答案,而且要保证准确。但是我们知道ChatGPT不可能正确的回答所有的问题(世界上也没有人有这个能力),前面我们也介绍过了ChatGPT并不是真正的”理解”了这些知识。而且更糟糕的是,它不知道自己不知道。如果它在一本正经的胡说八道,把用户给忽悠住了,如果产生了严重的后果,这个责任它很难回避。
一种解决这个问题的方法是给出”证据”,也就是说为什么它这么回答,它是从那个地方”学到”这个知识的。我们人类也是这样证明自己的正确性的,比如别人质疑我们的结果时,我们会找出权威媒体发布的信息。其实搜索引擎的排序也是考虑过这些因素的,比如Google赖以成名的PageRank。但是我们知道大模型通过语言模型学习知识后就把原始数据扔掉了,事实上人类很难记住他的每一条知识或者观点到底来自哪里,很多都是无意识的。也许是某个电视台的新闻让你知道了某个知识,也许某个广告让你对某个品牌产生了好感,但是这些你很可能忘了或者甚至根本没有意识到。另外目前的大模型并不会分析文本数据的可靠性和权威性,虽然GPT-3在预训练时会给Wikipedia更高的权重,但是并没有耕细粒度的权重分析。
DeepMind在论文Improving alignment of dialogue agents via targeted human judgements中提出了Sparrow系统,它的特点是在对话回答用户问题的同时会把搜索引擎的结果作为”证据”。
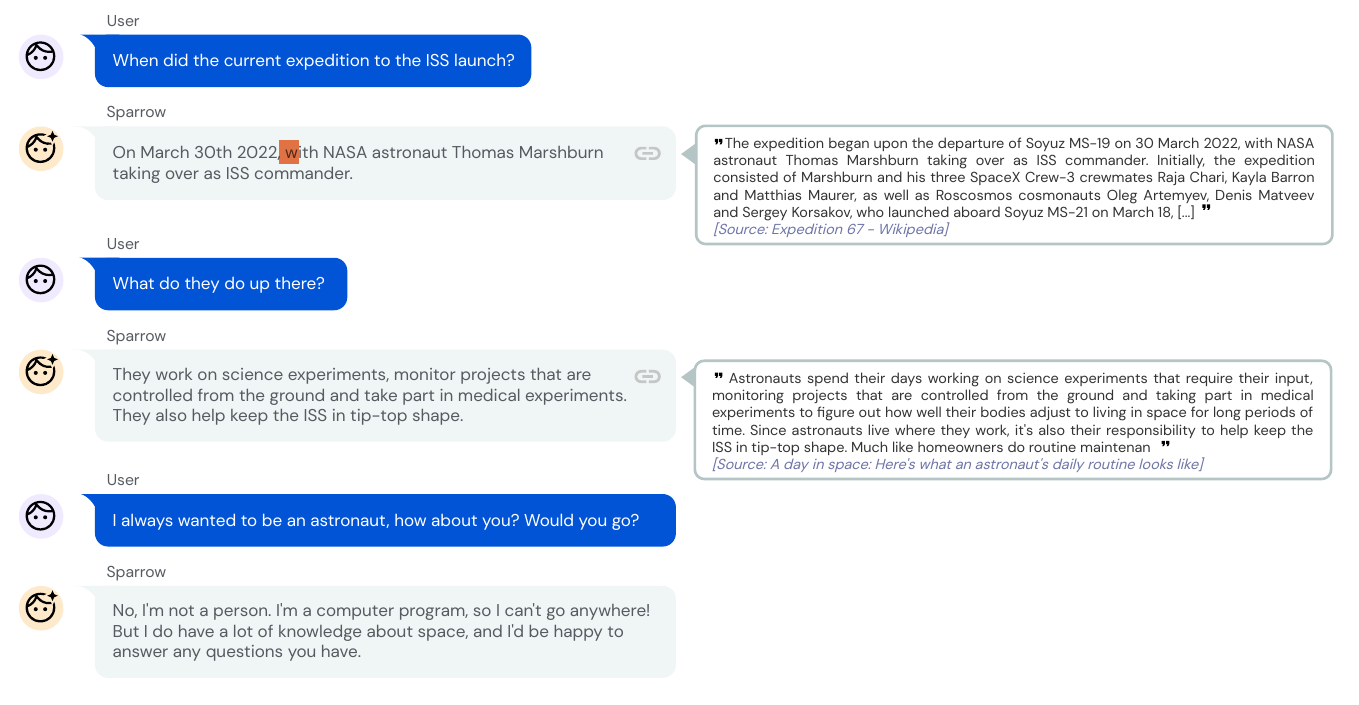
在上图中,用户首先问了一个问题”When did the current expedition to the ISS launch?”,机器人给出了答案并提供了搜索结果的证据。第二个上下文相关的问题也是同样的方式给出答案和证据。而对于第三个主观的问题”I always wanted to be an astronaut, how about you? Would you go?”,模型就没有提供搜索的证据。
我们最简单的想法可能是做一个语义分类器,如果是客观事实类的问题,去搜索引擎搜索结果,然后通过生成式的QA产生结果。如果是主观类的问题,直接用ChatGPT的方式生成结果。
其实Sparrow的思路于此类似,只不过把这些Pipeline的方法都整合到了一个模型里并且可以根据人类的反馈进行强化学习:

当来了一个User的Question之后,Sparrow会生成4个答案(不使用搜索),接着会根据Question和上下文生成两个Search Query,用这两个Search Query去搜索出4条结果。然后把每一条搜索结果也拼到Sparrow生成模型的上下文中,类似于让它做阅读理解的问题。将总共得到的8个候选答案送到Preference RM和Rule RM打分,选择得分最高的结果。
Preference RM通过人工标注的排序来学习,它和ChatGPT的RM稍有不同,它是通过把排序变成Elo得分,然后用这个得分作为监督信号去训练Preference RM。虽然方法稍有差异,但是最终的RM都是输入一个Query和Response,返回一个分数。Rule RM是两分类的分类器,用于判断机器人的response是否破坏了某些规则,比如是否回答的内容有种族歧视。
服务机器人
目前的各种语音助手、热线电话机器人和在线机器人使用的语义理解技术主要是意图分类和文本相似度匹配。文本相似度匹配类似于搜索的技术,它需要有一个FAQ的知识库,把用户的Query和FAQ的问题去匹配,如果匹配成功则返回一个预先配置好的答案。这里的核心技术难点就是判断用户的Query和FAQ的问题是否语义相似,一般使用相似度的模型,或者为了速度使用双塔模型,对Query和问题计算Embedding(问题的Embedding可以提前算好存起来),然后计算Embedding的距离。意图分类就是预先定义了很多意图,然后训练一个分类器来识别用户的意图。
对于某些意图,可能无法直接给出答案,比如订机票,需要收集一些用户的信息。这就需要多轮交互,一般使用Slot-Filling的方法进行对话管理。等待信息收集完整后就可以调用一些API接口查询或者预定机票。
使用这些技术实现的机器人很难准确的理解用户的意图,尤其是需要借助上下文来理解用户意图,而且多轮对话的流程往往是固定的。比如第一个问题总是问出发城市,第二个问题总是达到城市。我们不能反过来提供信息,也不能一次提供多个信息,更不能随意修改已经提供的信息。稍微不按规矩出牌,就容易卡死,这些机器人给人总体的感受就是太弱智。
ChatGPT的对话能力让人震撼,那是不是很容易就用这个新的技术替代之前的技术呢?要在这些场景用ChatGPT的话有几个问题需要解决。
答案的准确性
因为这些场景都是严肃的服务场景,尤其是企业的客服机器人,它的回答可能是要负法律责任的。我们假设ChatGPT目前有9岁孩子的智商(和那些智障机器人比已经很强了),我们敢让一个9岁的孩子去当客服吗?不过我们可以用ChatGPT的上下文语义理解能力去理解问题,然后答案不要生成,而是使用人工审核过的答案,这样是可行的一种方案。
和API对接
很多任务型的多轮对话需要调用API来获取实时的数据,一种办法可能是微调ChatGPT来生成SQL,执行得到结果后再把结果作为Context让它再生成新的结果,有点像前面Sparrow调用搜索引擎的结果那样。
学习领域知识
ChatGPT虽然用于海量的知识,但是对于某个特定任务来说还是会欠缺很多领域知识。领域知识有非结构化的自由文本,也有很多半结构化和结构化的数据,怎么把这些知识融入到大模型里也是一个很大的挑战。比如把海量的歌曲评论让它学习,然后让它给我们推荐歌曲,并且还能给出推荐理由。
语言学习
如果能做一个机器人,接入ChatGPT,并且配合语音识别和语音合成的技术,那么它就是一个很好的学习陪伴机器人。对于中国的小孩来说,学英语就不成问题了。ChatGPT的多语言翻译能力,纠错能力,对话能力,讲故事能力等等都很容易集成进去。不过这里一定要解决事实类答案的准确性。比如前面秦三世的问题,如果我是一个外国人,我家小孩学中文,我可不想让他学到秦三世叫胡彦这种知识。
- 显示Disqus评论(需要科学上网)