本文介绍Neural Style Transfer。更多文章请点击深度学习理论与实战:提高篇。
目录
简介
有把Neural Style Transfer翻译成”神经风格迁移”的,但是总感觉”神经”这词有些怪怪的,翻译成神经网络风格迁移可能好一点,但是英文里并没有出现Network一词,因此还是保留英文名字吧。
虽然深度学习最近比较火,在很多行业都有应用,但是并不为大众所关注。让大家关注深度学习和AI的是一些大家能看到的应用,比如AlphaGo下围棋,OpenAI玩Dota。这些事件更多的是让大众了解人工智能的最新进展,引起大家的关注和思考,但是并不能让大家”使用”它们。而基于Neural Style Transfer的一些App如Prisma真正让大家”玩”了一下深度学习的技术。虽然现在看起来只是昙花一现的流行,但是确实让大家真正的用了深度学习的技术。
原理
Neural Style Transfer认为画家的作品包含两部分内容——内容(Content)和风格(Style),而拍摄的照片只有内容。我们人类是很容易可以识别一幅画的内容同时也能识别其风格,也就是说我们可以把一幅画的内容和风格分割开来。
深度卷积网络通过层次化的表示,每一层建立在前一层的基础上,因此逐层学习到越来越高层,越来越抽象的特征。
如下图所示,在下面的内容重建(Content Reconstruction)部分,我们发现底层的网络可以重建出原始图像的细节,而到高层(比如第五层)网络学到的是更加高层和抽象的特征,因此无法重建细节。这是符合我们的期望的——高层的网络丢弃掉了和识别物体无关的一些细节,它们更加关注图片的内容和而不是像素级的细节。这使得它的识别会更加准确。因此我们也可以把高层的特征叫做内容特征(Content Features)。
那风格(Style)怎么提取出来呢?我们可以认为高层网络的每一个Filter都提取了一种特征,从内容的角度来说它们是不同的。而风格是于具体内容无关的一种作者个性化的特征,因此它是存在于不同的Filter之中的。换句话说就是,作者的风格是一致的,不管Filter的内容是什么,都会有风格特征包含其中。因此提取风格就要找不同Filter的共同点。具体来说,它是通过计算同一层的Filter的相关性来提取风格特征的。如下图的上半部分所示,通过计算同一层Filter的相关性,我们可以提取多种不同尺度(scale)的风格特征。
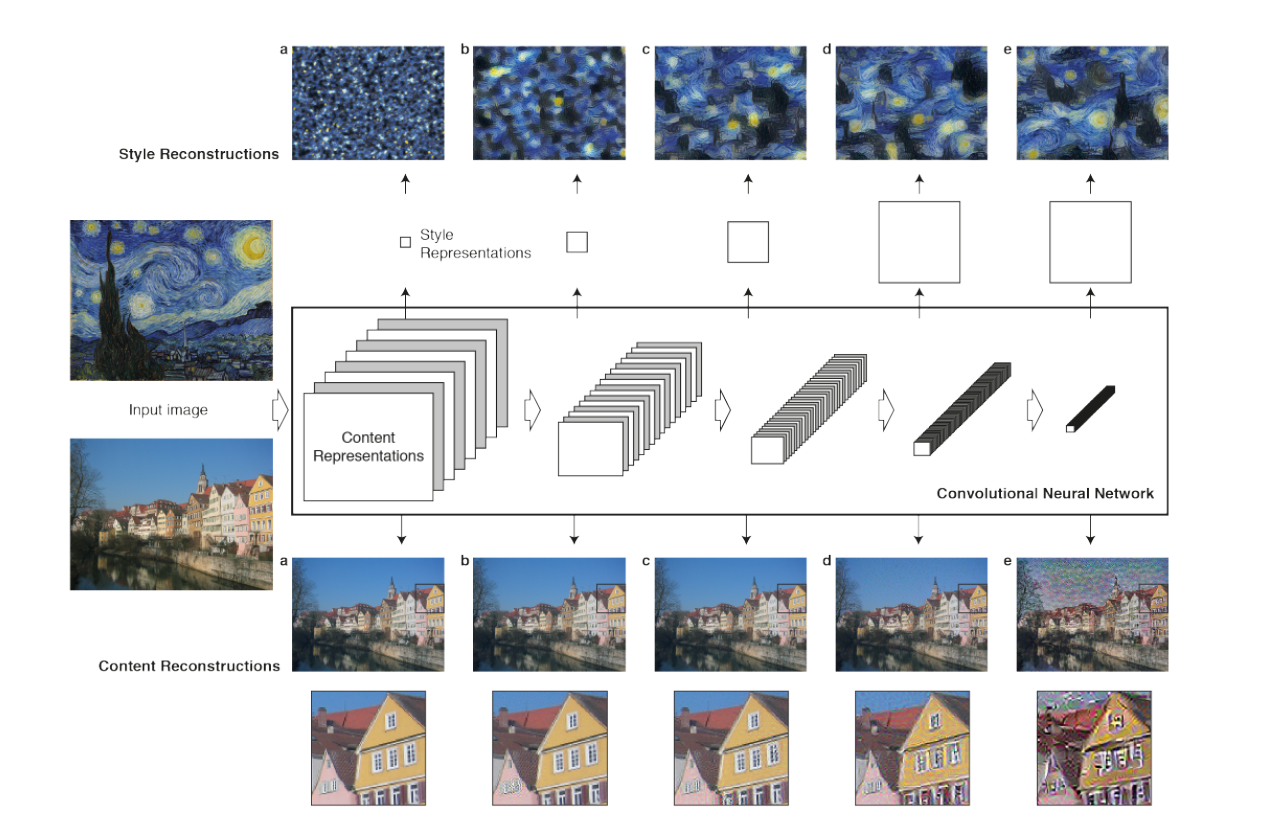 图:卷积网络的层次表示
图:卷积网络的层次表示
通过上面的方式,给定一幅画(比如梵高的作品),我们可以提取其风格特征,再给定一张风景照片(没有风格),我们可以把风格特征融合到这种风景照片中,这就是所谓的Neural Style Transfer。如下图所示,左图是原始的风景照片,右图是混入了毕加索风格后的照片,右图的左下是用于提取风格的毕加索的作品。
 |
 |
|---|---|
| 德国图宾根(Tübingen)Neckarfront 的风景照片 | 混入毕加索(Picasso)风格之后的图片 |
下面我们来介绍Neural Style Transfer的具体实现方法。给定一副画和一张照片,我们可以用卷积神经网络提取画里的风格特征和照片的内容特征。这就是我们期望得到的风格和内容,那怎么把它们两张混合起来呢?风格和内容并不是同一种东西,不能颜色那样直接混合。本文使用的是用梯度下降的方法逐步修改图像的方法。
首先我们需要定义两个Loss——内容的Loss和风格的Loss。或者说给定两个内容(特征),我们可以计算它们的相似度;给定两个风格(特征),我们也可以计算它们的相似度。有了这两个Loss之后,理论上我们可以”遍历”所有可能的图像(实际不可能,比如28x28的灰度图,理论上有$2^256>10^75$个不同图像),然后分别用神经网络提取其内容和风格特征,然后计算它们和我们想要的内容和风格特征的Loss,选择最小的那个。当然这两个Loss不可能同时为零,那么我们需要选择它们的加权和较小的。如果我们期望内容更相似,那么我们可以求和时给内容Loss更大的权重;而如果我们期望风格更相似,那么可以给风格Loss更大的权重。
但是上面的方法只是理论上的,实际是不可能这样做的。下面我们介绍实际可行的做法。
我们把照片再次输入神经网络,当然可以同时计算这个照片的风格和内容,显然这个时候内容就是我们想要的,但是风格完全不同。显然这个时候是有Loss的(内容Loss是零但是风格Loss很大)。我们可以把图片看成变量(参数),而神经网络的参数是固定的。我们可以把Loss看成是图片的函数,因此我们可以使用梯度下降的方法求Loss对每一个像素的梯度,然后微调每一个像素使得Loss变小。
最后剩下的问题就是怎么定义内容特征和风格特征并且定义内容Loss和风格Loss了。
首先我们介绍一些论文中用到的符号。我们假设第l个卷积层有$N_l$个Filter(Feature map),它的大小$M_l$是Feature Map的width x height。第l层一共有$N_l \times M_l$个输出,我们把它记为矩阵$F^l \in R^{N_l \times M_l}$。因此$F^l_{ij}$表示第i个Feature Map的第j个元素(我们把二维的Feature Map矩阵展开成一共一维的向量)。
有了$F^l_{ij}$,我们可以定义内容Loss如下:
\[\mathcal{L}_{content}(\vec{p}, \vec{x}, l)=\frac{1}{2}\sum_{i,j} (F^l_{ij}-P^l_{ij})^2 \\ \mathcal{L}_{content}(\vec{p}, \vec{x}) =\sum_l \mathcal{L}_{content}(\vec{p}, \vec{x}, l)\]其中$\vec{p}$是提供内容的图片,而$j\vec{x}$是当前正在生成的图片。$F^l$是$\vec{x}$对应的第l层特征矩阵,而$P^l$是原始图片$\vec{p}$对应的特征矩阵。为了得到风格特征,我们需要求第l层所有特征矩阵的Gram矩阵(相关矩阵)$G^l$:
\[G^l_{ij}=\sum_k F^l_{ik}F^l_{jk}\]Gram矩阵$G^l$的大小$N_l \times N_l$,计算相关(Correlation)是统计和信号处理中的常见技巧。有了$G^l$之后,我们也可以定义两个照片风格的Loss:
\[E_l=\frac{1}{4N_l^2M_l^2} \sum_{i,j}(G^l_{ij}-A^l_{ij})^2 \\ \mathcal{L}_{style}=\sum_l E_l\]其中$G^l$和$A^l$是$\vec{x}$和$\vec{p}$的Gram矩阵。最后我们定义总的Loss:
\[\mathcal{L}_{total}=\alpha \mathcal{L}_{content} + \beta \mathcal{L}_{style}\]代码
Neural Style Transfer有很多开源实现,比较流行的包括jcjohnson的Torch/lua实现,Anishathalye的Tensorflow实现。为了简单,我们使用PyTorch Tutorial的例子,Tutorial的作者是Alexis Jacq和Winston Herring,感谢他们授权本书使用。
简介
本教程实现Leon A. Gatys等人的Neural-Style算法。这个算法可以根据输入照片产生艺术家效果的新照片,并且内容看起来还是老照片的内容。这个算法有3个输入:输入图片、内容图片和风格图片。我们使用梯度下降算法逐渐修改输入图像,使得前面定义的Loss越来越小,从而使得最新的输入图像在内容和风格上都更像输入的内容图片和风格图片。
基本原理
我们需要定义两个距离,其中之一是$D_C$,用于计算两个图片内容的距离;另外一个就是$D_s$,用于计算两个图片风格上的差异。接下来我们我们有一个输入图片,我们逐渐的用梯度下降修改其内容,使得这两个距离都尽量小。
导入package
首先是import需要用到的package:
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
import torchvision.models as models
import copy
接下来我们根据机器是否有GPU选择合适的device,这里会根据函数torch.cuda.is_available() 来判断是否有GPU。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
这样我们在定义了变量或者模型之后会用to(device)把它放到合适的位置。
加载图片
我们首先需要加载图片,对它们进行缩放等操作。代码如下:
# 如果没有GPU,选择较小的尺寸。
imsize = 512 if torch.cuda.is_available() else 128 # use small size if no gpu
loader = transforms.Compose([
transforms.Resize(imsize), # 缩放
transforms.ToTensor()]) # 变成torch tensor
def image_loader(image_name):
image = Image.open(image_name)
# 必须有个batch维度,因此用unsqueeze(0)增加一个batch维度。
# 如果是CPU,那么loader得到的是(3, 128, 128),unsqueeze之后变成(1, 3, 128, 123)
image = loader(image).unsqueeze(0)
return image.to(device, torch.float)
style_img = image_loader("./picasso.jpg")
content_img = image_loader("./dancing.jpg")
接下来我们把这两张图片显示出来:
unloader = transforms.ToPILImage() # 为了显示转换成PIL image
plt.ion()
def imshow(tensor, title=None):
image = tensor.cpu().clone() # 因为显示是需要把batch去掉,为了避免修改,我们clone一份。
image = image.squeeze(0) # 去掉batch维度
image = unloader(image)
plt.imshow(image)
if title is not None:
plt.title(title)
plt.pause(0.001) # 等一下以便plot更新
plt.figure()
imshow(style_img, title='Style Image')
plt.figure()
imshow(content_img, title='Content Image')
如下图所示,左边是提供风格的图片,右边是提供内容的图片。
 |
 |
|---|---|
| 提供风格的图片 | 提供内容的图片 |
损失函数
假设输入图片是X,内容图片是C,第L层的内容损失是$\left\vert F_{XL}-F_{CL} \right\vert^2$。我们可以用nn.MSELoss来计算它。ContentLoss的代码如下:
class ContentLoss(nn.Module):
def __init__(self, target):
super(ContentLoss, self).__init__()
self.target = target.detach()
def forward(self, input):
self.loss = F.mse_loss(input, self.target)
return input
注意ContentLoss并不是PyTorch里的损失函数,它只是一个普通的Module。它的forward会计算Loss,并且保持到self里,并且它的forward的输出就是它的输入。因此把一个ContentLoss接到一个卷积层(为了后面的引用我们把它叫做conv)后面只是会计算ContentLoss的值而已,并不改变输入的内容。
我们在计算ContentLoss时需要传入target,也就是内容图片的conv层的输出,这个值是不变的(在这里,神经网络参数是固定的,只有图片x是会改变的),因此可以作为参数传入,我们后面会介绍怎么传入。另外为了防止F.mse_loss(input, self.target)在反向计算是计算target的梯度(这是不不必要的,因为target是个固定值,我们要的是求loss对input的梯度从而传导到X,而不需要传导给C)。所以我们使用target.detach()告诉PyTorch计算梯度的时候去掉target。
StyleLoss也是类似的,只不过计算更加复杂一点,需要计算Gram矩阵。我们首先来看它的代码:
def gram_matrix(input):
a, b, c, d = input.size() # a=batch size(=1)
# b=feature map的数量
# (c,d)=dimensions of a f. map (N=c*d)
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
G = torch.mm(features, features.t()) # compute the gram product
# we 'normalize' the values of the gram matrix
# by dividing by the number of element in each feature maps.
return G.div(a * b * c * d)
Gram矩阵其实就是矩阵乘以它的转置,输入input可能是(1, 64, 512, 512),分布表示batch,number_featuremaps, width, height。我们首先要把它reshape成(1x64, 512x512),然后用features乘以它自己的转置,最后需要除以元素的个数,注意,这里和论文有点不同,论文是除以$4N_l^2M_l^2=4 \times 64^2 \times 512^4$。不过这并不重要,这只是一个常量,因为后面我们还会乘以一个StyleLoss的权重。
接下来就是StyleLoss的代码,除了计算loss复杂一点,结构上它和ContentLoss完全一样。
class StyleLoss(nn.Module):
def __init__(self, target_feature):
super(StyleLoss, self).__init__()
self.target = gram_matrix(target_feature).detach()
def forward(self, input):
G = gram_matrix(input)
self.loss = F.mse_loss(G, self.target)
return input
传入的target_feature来自style-image,它是固定的值,因此只需要在构造函数计算一次Gram矩阵,而输入input每次在forward都要计算Gram矩阵,然后计算loss。
导入模型
我们这里使用预训练好的VGG-19模型,PyTorch的VGG-19分为两个Sequential部分——features和classifier。前者包含卷积和pooling层,而后者包括后面的全连接层。我们这里默认使用conv4(第4个卷积层输出的feature map)来计算ContentLoss,使用conv1-5来计算StyleLoss(这是完全follow论文),因此我们只需要加载features部分。另外因为有些层比如dropout在训练和预测时的行为是不同的,我们这里不需要训练VGG网络的参数,所以对于VGG来说可以认为predict阶段,因此需要调用eval()方法来告诉PyTorch。
cnn = models.vgg19(pretrained=True).features.to(device).eval()
如果第一次运行它会比较慢,它需要从网络下载模型到本地。另外VGG在训练的时候对RGB三个通道做了归一化,使用的均值和方差是[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225],因此我们输入的图片也要用同样的参数做归一化。为了使用简单,我们定义了一个Normalization类来实现这个功能:
cnn_normalization_mean = torch.tensor([0.485, 0.456, 0.406]).to(device)
cnn_normalization_std = torch.tensor([0.229, 0.224, 0.225]).to(device)
class Normalization(nn.Module):
def __init__(self, mean, std):
super(Normalization, self).__init__()
# 把mean和std reshape成 [C x 1 x 1]
# 输入图片是 [B x C x H x W].
# 因此下面的forward计算可以是用broadcasting
self.mean = torch.tensor(mean).view(-1, 1, 1)
self.std = torch.tensor(std).view(-1, 1, 1)
def forward(self, img):
return (img - self.mean) / self.std
接下来是最复杂的代码部分,其实就是get_style_model_and_losses函数。在阅读其代码之前我们先来看一下vgg模型的features部分的结构:
Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
....
(33): ReLU(inplace)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
为了节省篇幅,这里只列举了部分Layer,读者可以调试代码查看完整信息。基本结构就是conv,relu,conv,relu,maxpool的循环使用。
我们有3个输入:input_img、content_img和style_img。我们先看content_img,根据默认的设置,ContentLoss只计算conv4也就是第4个卷积层。因此我们需要把content_img输入vgg网络,并且拿到conv4的输出,我们把这个输出记为target。然后”偷偷的”在conv4后面(relu4之前)增加一个ContentLoss层,这个ContentLoss层需要传入参数target。StyleLoss也是类似,只不过它需要在conv1-5的后面加入StyleLoss。
了解了这些之后我们再来阅读代码就容易了。
content_layers_default = ['conv_4']
style_layers_default = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_style_model_and_losses(cnn, normalization_mean, normalization_std,
style_img, content_img,
content_layers=content_layers_default,
style_layers=style_layers_default):
cnn = copy.deepcopy(cnn)
normalization = Normalization(normalization_mean, normalization_std).to(device)
content_losses = []
style_losses = []
model = nn.Sequential(normalization)
i = 0 # increment every time we see a conv
for layer in cnn.children():
if isinstance(layer, nn.Conv2d):
i += 1
name = 'conv_{}'.format(i)
elif isinstance(layer, nn.ReLU):
name = 'relu_{}'.format(i)
layer = nn.ReLU(inplace=False)
elif isinstance(layer, nn.MaxPool2d):
name = 'pool_{}'.format(i)
elif isinstance(layer, nn.BatchNorm2d):
name = 'bn_{}'.format(i)
else:
raise RuntimeError('Unrecognized layer: {}'
.format(layer.__class__.__name__))
model.add_module(name, layer)
if name in content_layers:
target = model(content_img).detach()
content_loss = ContentLoss(target)
model.add_module("content_loss_{}".format(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
target_feature = model(style_img).detach()
style_loss = StyleLoss(target_feature)
model.add_module("style_loss_{}".format(i), style_loss)
style_losses.append(style_loss)
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[:(i + 1)]
return model, style_losses, content_losses
我们需要修改vgg(cnn),所以首先是把cnn深度拷贝一份。我们再构造一个Normalization层,把它加入新构造的nn.Sequential对象model。
接着我们遍历vgg的所有Layer(children),它们是Conv2d,ReLU,Conv2d,ReLU, MaxPool2d,…。我们把这些层加到我们的model这个Sequential里。如果这个Layer是Conv2d,我们会给Layer计数器i加一,从而得到正确的Layer的名字,因此我们得到的Layer名字分别是conv1, relu1, conv2, relu2, pool2…。
注意这里对于ReLU是构造了一个新的layer = nn.ReLU(inplace=False),因为默认为了效率ReLu都是inplace的计算,它直接修改上一层(Conv2D)的输出,但是现在我们在ReLu后面插入了ContentLayer/StyleLayer,这就有问题,因此我们需要用新的非inplace计算的ReLu层。因为ReLU层没有参数,因此直接构造就行(如果是有参数的Layer,那还得把参数复制过去)。
接下来判断name是否是conv4,如果是则在它后面增加一个ContentLayer。构造ContentLayer的时候需要把content_img的conv4的输出传入,因此调用target = model(content_img).detach()。因为当前model是增加了conv4,因此model(content_img)得到的就是conv4的输出,因为conent_img不参与梯度下降计算,因此需要detach。
StyleLayer的处理也是完全类似的逻辑。当把vgg的所有Layer遍历之后,我们得到如下的model:
Sequential(
(0): Normalization()
(conv_1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_1): StyleLoss()
(relu_1): ReLU()
(conv_2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_2): StyleLoss()
(relu_2): ReLU()
(pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv_3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_3): StyleLoss()
(relu_3): ReLU()
(conv_4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(content_loss_4): ContentLoss()
(style_loss_4): StyleLoss()
(relu_4): ReLU()
(pool_4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv_5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_5): StyleLoss()
(relu_5): ReLU()
(conv_6): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
.................
(conv_16): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu_16): ReLU()
(pool_16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
给定输入input_img、content_img和style_img,我们其实只需要计算到style_loss_5就行了,conv_6以及之后的层是没有必要计算的。因此下面的代码:
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[:(i + 1)]
从model的最后一层往前遍历,找到最后一个StyleLoss或者ContentLoss,然后把它之后的都去掉。最终得到的model是:
Sequential(
(0): Normalization()
(conv_1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_1): StyleLoss()
(relu_1): ReLU()
(conv_2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_2): StyleLoss()
(relu_2): ReLU()
(pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv_3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_3): StyleLoss()
(relu_3): ReLU()
(conv_4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(content_loss_4): ContentLoss()
(style_loss_4): StyleLoss()
(relu_4): ReLU()
(pool_4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv_5): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(style_loss_5): StyleLoss()
)
最后返回model, style_losses和content_losses。
梯度下降
首先我们把content_img克隆一下得到input_img:
input_img = content_img.clone()
# 当然我们也可以从随机的图片来进行梯度下降,但是用内容图片作为初始值至少能保证内容loss比较低。
# input_img = torch.randn(content_img.data.size(), device=device)
这里使用的是L-BFGS算法,本书不会详细介绍L-BFGS算法,有兴趣的读者可以参考一些相关资料(比如这篇文章)。简单来说它是拟牛顿(Quasi-Newton)方法。牛顿(Newton)优化方法除了使用梯度之外还会使用Hessian矩阵(也就是梯度的梯度),因此找到的方向更接近最优值从而收敛的更快。
如下图所示,绿色的方向是梯度下降寻找最优解的过程;而红色是牛顿方法的过程。我们发现梯度是向上弯曲的,而牛顿方法利用梯度的梯度,因此它能猜测出更短的优化路径。
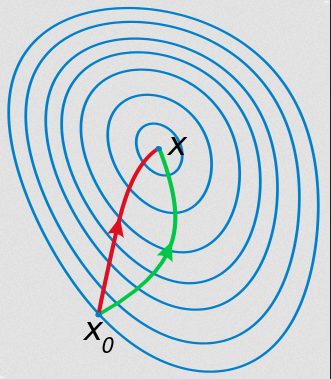 图:Newton方法 vs Gradient Descent
图:Newton方法 vs Gradient Descent
但是牛顿方法需要计算Hessian矩阵的逆,这个矩阵通常非常大,比如变量有1万个(这在神经网络里算很少的),则矩阵的大小就是1万乘以1万!而拟牛顿法不需要这么求解矩阵的拟,具体为什么这里就不介绍了。而L-BFGS就是一种拟牛顿算法,我们只需要计算初始时刻的Hessian,然后每个时刻只需要计算梯度,L-BFGS可以自动计算(当然是近似的)下一个时刻的Hessian。
PyTorch提供了L-BFGS优化器,我们这样来构造:
def get_input_optimizer(input_img):
optimizer = optim.LBFGS([input_img.requires_grad_()])
return optimizer
optim.LBFGS需要传入参数,我们这里的参数就是input_img。但是从content_img复制过来的input_img的是不参与梯度计算的,因此我们需要调用requires_grad_函数把input_img变得参与梯度计算。注意以下划线结尾的函数是一个inplace的函数。
接下来就是run_style_transfer函数,它就是不断用梯度下降修改input_img以降低Loss的过程。
def run_style_transfer(cnn, normalization_mean, normalization_std,
content_img, style_img, input_img, num_steps=300,
style_weight=1000000, content_weight=1):
print('Building the style transfer model..')
model, style_losses, content_losses = get_style_model_and_losses(cnn,
normalization_mean, normalization_std, style_img, content_img)
optimizer = get_input_optimizer(input_img)
print('Optimizing..')
run = [0]
while run[0] <= num_steps:
def closure():
...省略的代码在下面
optimizer.step(closure)
# a last correction...
input_img.data.clamp_(0, 1)
return input_img
这段代码有个很长的closure闭包函数,如果不看它,代码其实很简单。首先是构造模型和得到ContentLayer以及StyleLayer(调用get_style_model_and_losses函数)。然后是while循环,不断调用optimizer.step(closure)。注意run = [0],因为run变量需要在闭包函数closure里使用,因此需要把它放到一个list里,如果定义run=0,那么闭包里就是它的拷贝就不能修改它了。
接下来我们看closure函数,LBFGS.step需要一个闭包(函数)作为参数,这个函数就是计算当前的loss和loss对参数的梯度病返回loss,之后LBFGS就可以帮我们搞定Hessian矩阵的更新、线性搜索、更新参数等等一系列复杂的事情。
def closure():
# 图片的值必须在(0,1)之间,但是梯度下降可能得到这个范围之外的值,所有需要clamp到这个范围里
input_img.data.clamp_(0, 1)
# 清空梯度
optimizer.zero_grad()
# forward计算,从而得到SytleLoss和ContentLoss
model(input_img)
style_score = 0
content_score = 0
# 计算Loss
for sl in style_losses:
style_score += sl.loss
for cl in content_losses:
content_score += cl.loss
# Loss乘以weight
style_score *= style_weight
content_score *= content_weight
loss = style_score + content_score
# 反向求loss对input_img的梯度
loss.backward()
run[0] += 1
if run[0] % 50 == 0:
print("run {}:".format(run))
print('Style Loss : {:4f} Content Loss: {:4f}'.format(
style_score.item(), content_score.item()))
print()
# 返回loss给LBFGS
return style_score + content_score
下图是我们最终得到的图片,可以发现它确实融入了画的风格,读者也可以调整参数style_weight,尝试调整风格的比例。
 图:Nerual Style Transfer的结果
图:Nerual Style Transfer的结果
- 显示Disqus评论(需要科学上网)