本文介绍动态规划算法,详细介绍策略评估、策略提升、策略迭代和价值迭代等算法,并且每个算法都会有示例代码。
更多本系列文章请点击强化学习简介系列文章。更多内容请点击深度学习理论与实战:提高篇。
目录
- 简介
- 策略评估(Policy Evaluation)
- 策略评估代码示例
- 策略提升(Policy Improvement)
- 策略迭代(Policy Iteration)
- 策略迭代代码示例
- 价值迭代(Value Iteration)
- 价值迭代代码示例
- 通用策略迭代(Generalized Policy Iteration/GPI)
简介
动态规划是一种算法,对于简单的MDP问题可以用它来求解最优解。但是实际问题很少能用到这种算法,因为它的假设很难满足以及它计算复杂度太高了。不过学习这种算法依然很有用处,因为后面介绍的方法都想达到动态规划一样的效果,只不过它们能降低计算复杂度并且在非理想的环境下也可以使用。
这一节我们假设MDP是有限的,包括状态、行为和Reward,并且环境完全由$p(s’,r|s,a)$确定。如果读者学习过计算机的算法课程,可能也会学到动态规划算法,它的基本思想是:一个”大”的问题的最优解,可以分解成一些小的问题,并且把小问题的的最优解的组合起来得到大问题的最优解。本书后文很多算法都是动态规划算法。
使用动态规划来解决强化学习问题的核心是使用价值函数来搜索好的策略。如果有了最优价值函数(不管是状态价值函数还是状态价值函数),我们就可以用它来计算最优的策略。最优价值函数满足如下的贝尔曼方程:
\[v_*(s)=\max_a \mathbb{E}[R_{t+1}+\gamma v_*(S_{t+1})|S_t=s,A_t=a]\ =\max_a\sum_{s',r}p(s',r|s,a)[r+\gamma v_*(s')]\]我们来理解一下这个公式,在状态s下最优的价值是什么呢?我们遍历所有可能的行为a,得到Reward值$R_{t+1}$然后进入新的状态$S_{t+1}$。这个过程由$p(s’,r|s,a)$确定,所以加一个$\mathbb{E}$。当t+1时刻我们处于$S_{t+1}$时,我们仍然要遵循最优的策略,所以第二项是$\gamma v_*(S_{t+1})$。把$\mathbb{E}$根据期望的定义展开成求和就得到第二个等号。Q的贝尔曼方程也是类似的:
\[q_*(s,a)=\mathbb{E}[R_{t+1}+\gamma \max_{a'}q_*(S_{t+1},a')|S_t=s,A_t=a]\ =\sum_{s',r}p(s',r|s,a)[r+\gamma \max_{a'}q_*(S_{t+1},a')]\]我们同样可以这样解读:在状态s采取a,Agent会得到$R_{t+1}$和进入状态$S_{t+1}$,在这个状态时我们有很多选择,但是我们要选择最大的那个a’。而动态规划就是根据上面的贝尔曼方程来得到迭代更新的算法。
策略评估(Policy Evaluation)
首先我们来计算一个给定的策略的价值函数$v_\pi(s)$,这叫策略评估(Policy Evaltuion),有时我们也把这个问题叫做预测(Prediction)问题。
\[\begin{split} v_\pi(s) & \equiv \mathbb{E}_\pi[G_t|S_t=s] \\ & =\mathbb{E}_\pi[R_{t+1} + \gamma G_{t+1}|S_t=s] \\ & =\mathbb{E}_\pi[R_{t+1} + \gamma v_\pi(S_{t+1})|S_t=s] \\ & =\sum_a \pi(a|s)\sum_{s',r}p(s',r|s,a)[r+\gamma v_\pi(s')] \end{split}\]其中$\pi(a|s)$是给定策略$\pi$时,在状态s下采取行为a的概率。公式的期望\(\mathbb{E}_\pi\)说明是在策略$\pi$下变量$R_{t+1}$和$G_{t+1}$的概率。
如果环境的动力系统($p(s’,r|s,a)$)是完全已知的,而策略$\pi(a|s)$也是已知的情况下,我们可以通过线性方程直接解出$v_\pi(s)$。因为假设状态s有n种可能,那么就是n个变量,n个等式的线性方程,可以证明,如果$\gamma < 1$,则方程有唯一解。这是一个线性代数的问题,但是这里我们会介绍一种迭代算法,这和梯度下降的思路有一些类似。因为迭代算法更容易推广到动态规划之外的算法,所以我们需要学习这种方法。下图是算法的伪代码:
 图:策略评估算法伪代码
图:策略评估算法伪代码
这个算法过程如下:首先把所有的$V_0(s)$都初始化成0,然后根据$V_0$计算$V_1$,…,一直继续下去直到收敛。根据$V_k(s)$计算$V_{k+1}(s)$的公式如下:
\[V_{k+1}(s)=\sum_a\pi(a|s)\sum_{s',r}p(s',r|s,a)[r+\gamma V_k(s')]\]这个迭代算法的证明本书从略,有兴趣的读者可以参考这里。我们可以看一下收敛的时候,$V_{k+1}=V_k, \Delta=0$,那么上面的迭代公式正好就是贝尔曼方程!有了上面的迭代算法,任何给定的策略$\pi$,我们都可以计算出它的价值函数。
策略评估代码示例
接下来我们用代码来实现上面的算法,在介绍具体算法之前,先介绍Grid World。
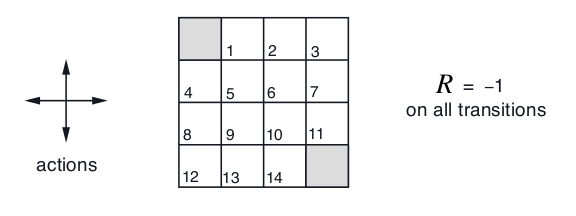 图:Grid World
图:Grid World
如上图所示,非终止状态共有14个$\mathcal{S}=\{1,2,…,14\}$,每个状态下都可以采取4个Action,$\mathcal{A}=\{up, down, left, right\}$,这些Action会确定(概率为1)的把Agent带到相应的位置,如果碰到墙了那就保持状态不变。因此$p(6, −1 | 5, right) = 1$, $p(7, −1 |7, right) = 1$,$p(10, r | 5, right) = 0$。左上和右下是结束状态(迷宫出口),如果没到结束状态,则reward是-1,因此这个任务期望Agent尽快找到出口。注意:$p(6, −1 | 5, right) = 1$的意思是如果处于状态5并且Action是right,那么它一定会进入状态6并且reward是-1。因为概率和为1,因此$p(6,1.5|5, right)=0$,$p(4,-1|5,right)=0$。
我们首先实现这个Environment,代码在envs/gridworld.py,本系列完整代码在这里。
gridworld.py
import numpy as np
import sys
from gym.envs.toy_text import discrete
UP = 0
RIGHT = 1
DOWN = 2
LEFT = 3
class GridworldEnv(discrete.DiscreteEnv):
"""
Grid World environment。
Agent在一个MxNd的网格里,目标是尽快走到最上角或者右下角
例如, 一个4x4的网格如下:
T o o o
o x o o
o o o o
o o o T
x是Agent当前的位置。T是结束状态。
"""
metadata = {'render.modes': ['human', 'ansi']}
def __init__(self, shape=[4,4]):
if not isinstance(shape, (list, tuple)) or not len(shape) == 2:
raise ValueError('shape argument must be a list/tuple of length 2')
self.shape = shape
nS = np.prod(shape)
nA = 4
MAX_Y = shape[0]
MAX_X = shape[1]
P = {}
grid = np.arange(nS).reshape(shape)
it = np.nditer(grid, flags=['multi_index'])
while not it.finished:
s = it.iterindex
y, x = it.multi_index
P[s] = {a : [] for a in range(nA)}
is_done = lambda s: s == 0 or s == (nS - 1)
reward = 0.0 if is_done(s) else -1.0
# We're stuck in a terminal state
if is_done(s):
P[s][UP] = [(1.0, s, reward, True)]
P[s][RIGHT] = [(1.0, s, reward, True)]
P[s][DOWN] = [(1.0, s, reward, True)]
P[s][LEFT] = [(1.0, s, reward, True)]
# Not a terminal state
else:
ns_up = s if y == 0 else s - MAX_X
ns_right = s if x == (MAX_X - 1) else s + 1
ns_down = s if y == (MAX_Y - 1) else s + MAX_X
ns_left = s if x == 0 else s - 1
P[s][UP] = [(1.0, ns_up, reward, is_done(ns_up))]
P[s][RIGHT] = [(1.0, ns_right, reward, is_done(ns_right))]
P[s][DOWN] = [(1.0, ns_down, reward, is_done(ns_down))]
P[s][LEFT] = [(1.0, ns_left, reward, is_done(ns_left))]
it.iternext()
# Initial state distribution is uniform
isd = np.ones(nS) / nS
# We expose the model of the environment for educational purposes
# This should not be used in any model-free learning algorithm
self.P = P
super(GridworldEnv, self).__init__(nS, nA, P, isd)
def _render(self, mode='human', close=False):
if close:
return
outfile = StringIO() if mode == 'ansi' else sys.stdout
grid = np.arange(self.nS).reshape(self.shape)
it = np.nditer(grid, flags=['multi_index'])
while not it.finished:
s = it.iterindex
y, x = it.multi_index
if self.s == s:
output = " x "
elif s == 0 or s == self.nS - 1:
output = " T "
else:
output = " o "
if x == 0:
output = output.lstrip()
if x == self.shape[1] - 1:
output = output.rstrip()
outfile.write(output)
if x == self.shape[1] - 1:
outfile.write("\n")
it.iternext()
代码非常易读,最主要的几点如下:
- 这个类继承了discrete.DiscreteEnv,因此构造函数需要调用父类的构造函数。
- metadata = {‘render.modes’: [‘human’, ‘ansi’]}。
OpenAI Gym的Env对象需要实现render,也就是把当前的状态“画”出来,这样便于调试和展示。最常见的“画”法是rgb_array,也就是一幅位图。这里使用了简单的ansi方式,直接通过字符的方式输出到控制台。比如:
T o o o
o x o o
o o o o
o o o T
它表示Agent现在处于第二行第二列。
- 系统的动力系统由env.P确定,它的值就是上面我们描述的概率。
Policy Evaluation.ipynb
使用Jupyter Notebook打开Policy Evaluation.ipynb。给定策略计算价值函数的是policy_eval函数,Python代码和伪代码几乎一样:
def policy_eval(policy, env, discount_factor=1.0, theta=0.00001):
"""
Evaluate a policy given an environment and a full description of the environment's dynamics.
Args:
policy: shape是[S, A]的矩阵,表示策略
env: OpenAI env对象。 env.P表示环境的转移概率。
每一个元素env.P[s][a]是一个四元组:(prob, next_state, reward, done)
theta: 如果所有状态的改变都小于它就停止迭代算法
discount_factor: 打折音子gamma.
Returns:
V(s),长度为env.nS的向量。
"""
# 初始化为零
V = np.zeros(env.nS)
while True:
delta = 0
# For each state, perform a "full backup"
for s in range(env.nS):
v = 0
# Look at the possible next actions
for a, action_prob in enumerate(policy[s]):
# For each action, look at the possible next states...
for prob, next_state, reward, done in env.P[s][a]:
# Calculate the expected value
v += action_prob * prob * (reward + discount_factor * V[next_state])
# How much our value function changed (across any states)
delta = max(delta, np.abs(v - V[s]))
V[s] = v
# Stop evaluating once our value function change is below a threshold
if delta < theta:
break
return np.array(V)
接下来的cell,我们定义一个随机的策略,然后使用上面的函数来计算这个策略的价值函数:
random_policy = np.ones([env.nS, env.nA]) / env.nA
v = policy_eval(random_policy, env)
策略提升(Policy Improvement)
我们计算$\pi$的价值函数$v_\pi$的目的是为了找到“更好”的策略。对于给定的策略$\pi$和状态s,我们知道$v_\pi(s)$。如果假设原来的策略是确定的,那么原来的策略是遇到s,会用概率$\pi(a|s)$来选择行为a’,同时我们也知道在状态s下采取a并且在后续也使用策略$\pi$的价值(期望的长期回报)是:
\[q_\pi(s,a)=\mathbb{E}_\pi[R_{t+1}+\gamma _\pi(S_{t+1})|S_t=s,A_t=a]\ =\sum_{s',r}p(s',r|s,a)[r+\gamma v_\pi(s')]\]如果这个行为a的价值$q_\pi(s,a)>v_\pi(s)$,那么我们可以这样构造一个新的策略:在状态s时采取固定的策略a,之后的策略和原来的一样。凭直觉是正确的,那怎么证明呢?这个问题可以通过策略提升定理(Policy Improvement Theorem)证明。
策略提升定理
假设$\pi$和$\pi’$是两个确定的策略(一个状态s下只有一个行为a的概率是1,其余是0),如果对于所有的$s \in \mathcal{S}$都有:
\[q_\pi(s,\pi'(s)) \ge v_\pi(s)\]那么策略$\pi’$比$\pi$要“好”,也就是对于所有的$s \in \mathcal{S}$:
\[v_{\pi'}(s) \ge v_\pi(s)\]并且如果第一个不等式是严格大于,那么第二个不等式也是严格大于,也就是$\pi’$一定比$\pi$更好(而不是一样)。
如果这个定理成立,那就证明了我们前面结论,因为我们新的策略在s的时候采取的满足$q_\pi(s,a) \ge v_\pi(s)$,而其它的状态s’都是一样的,因此新的策略会更好。当然上面的新策略是随便选择一个满足条件的行为a,但更好的办法是从所有可能的a里选择$q_\pi(s,a)$最大的那个a,此外我们可以改变所有s的策略,而不是一个s,这个改进版本就是我们最终用到的策略提升算法。如果所有的状态,当前的a已经是$q_\pi(s,a)$中最大的那个呢?那说明当前策略已经是最优的策略了。下面我们来证明这个定理:
\[\begin{split} & v_\pi(s) \le q_\pi(s, \pi'(s)) \\ & \text{t时刻使用策略}\pi', \text{t+1时刻之后还是用策略}\pi \\ & =\mathbb{E}_{\pi'}[R_{t+1}+\gamma v_\pi(S_{t+1})|S_t=s] \\ & \text{用前面的假设} \\ & \le \mathbb{E}_{\pi'}[R_{t+1}+\gamma q_\pi(S_{t+1}, \pi'(S_{t+1}))|S_t=s] \\ & =\mathbb{E}_{\pi'}[R_{t+1}+\gamma \mathbb{E}_{\pi'}[R_{t+2}+\gamma v_\pi(S_{t+2})]|S_t=s] \\ & =\mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+\gamma^2v_\pi(S_{t+2})|S_t=s] \\ & \le \mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\gamma^3v_\pi(S_{t+3})|S_t=s] \\ & ... \\ & \le \mathbb{E}_{\pi'}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\gamma^3 R_{t+4}...+|S_t=s] \\ & =v_{\pi'}(s) \end{split}\]上面的证明就是不停的应用假设条件,里面有一点就是$E_\pi{E_\pi X}=E_\pi X$,因为求一次期望之后就和$\pi$无关了,可以认为是常量了。
前面说了,我们最终使用的策略是“贪心”的策略,对于所有的s,我们都选择$q_\pi(s,a)$最大的那个a。具体用数学语言来描述就是:
\[\begin{split} \pi'(s) & \equiv arg\max_a q_\pi(s,a) \\ & =arg\max_a \mathbb{E}[R_{t+1}+\gamma v_\pi(S_{t+1})|S_t=s,A_t=a] \\ & =arg\max_a \sum_{s',r}p(s',r|s,a)[r, v_\pi(s')] \end{split}\]上面的$\mathbb{E}$是没有下标$\pi$的,因为给定$S_t=s,A_t=a$时,$R_{t+1}$和$S_{t+1}$是与$\pi$无关的。当$\pi$和$\pi’$一样好的时候,$v_\pi(s)=v_{\pi’}(s)$,我们代入上面第一个等式得到:
\[\begin{split} v_{\pi'}(s) & =\max_a\mathbb{E}[R_{t+1}+\gamma v_{\pi'}(S_{t+1})|S_t=s,A_t=a] \\ & =max_a\sum_{s',r}p(s',r|s,a)[r'+\gamma v_{\pi'}(s')] \end{split}\]这就是贝尔曼方程,因此如果策略无法提升时就说明我们找到了最优的策略。前面证明的是确定策略的提升,对于随机的策略,也有类似的结论。如果$arg\max_aq_\pi(s,a)$有多个a对应的值都是最大值,那么我们可以随便选择哪个策略。比如$q(s,1)=q(s,2)=max_aq(s,a)$,那么提升的策略可以是$p(r,s’|s,1)=1$,也可以是$p(r_1,s_1’|s,1)=0.4, p(r_2,s_2’|s,2)=0.6$。只要它们的概率加起来等于1就行了。策略提升的代码会和下一节一起实现。
策略迭代(Policy Iteration)
有了前面两节的结论,那么我们可以使用如下方法得到最优策略:随机生成初始策略$\pi_0$,然后用策略评估得到$v_{\pi_0}$,然后用策略提升得到$\pi_1$,然后不断重复这个过程就可以得到最优的策略:
\[\pi_0 \rightarrow v_{\pi_0} \rightarrow \pi_1 \rightarrow v_{\pi_1} \ \rightarrow \pi_2 \rightarrow ... \rightarrow \pi_* \rightarrow v_*\]上面的过程就是策略迭代(Policy Iteration)。由于有限MDP的策略个数是有限的,因此上面的算法最终会在有限步结束。算法伪代码如下图所示。
 图:策略迭代算法伪代码
图:策略迭代算法伪代码
策略迭代代码示例
我们仍然使用Grid World任务来演示策略迭代算法的实现。用Jupyter notebook打开Policy Iteration.ipynb。
def policy_improvement(env, policy_eval_fn=policy_eval, discount_factor=1.0):
"""
策略迭代算法
参数:
env: OpenAI环境
policy_eval_fn: 策略评估函数,可以用上一个cell的函数,它有3个参数:policy, env, discount_factor.
discount_factor: 大致因子gamma
返回:
一个二元组(policy, V).
policy是最优策略,它是一个矩阵,大小是[S, A] ,表示状态s采取行为a的概率
V是最优价值函数
"""
# 初始化策略是随机策略,也就是状态s下采取所有行为a的概率是一样的。
policy = np.ones([env.nS, env.nA]) / env.nA
while True:
# 评估当前策略
V = policy_eval_fn(policy, env, discount_factor)
policy_stable = True
# For each state...
for s in range(env.nS):
# 当前策略下最好的action,也就是伪代码里的old-action
chosen_a = np.argmax(policy[s])
# 往后看一步找最好的action,如果有多个最好的,随便选一个
action_values = np.zeros(env.nA)
for a in range(env.nA):
for prob, next_state, reward, done in env.P[s][a]:
action_values[a] += prob * (reward + discount_factor * V[next_state])
best_a = np.argmax(action_values)
# 贪心的更新policy[s],最佳的a概率是1,其余的0.
if chosen_a != best_a:
policy_stable = False
policy[s] = np.eye(env.nA)[best_a]
if policy_stable:
return policy, V
读者可以对照伪代码阅读上面的算法,其中最关键的代码是:
for a in range(env.nA):
for prob, next_state, reward, done in env.P[s][a]:
action_values[a] += prob * (reward + discount_factor * V[next_state])
best_a = np.argmax(action_values)
读者可以对照公式$\pi(s) \leftarrow arg\max_a\sum_{s’,r}p(s’,r|s,a)[r+\gamma V(s’)]$,首先计算所有的\(action \_ values[a]=\sum_{s',r}p(s',r\|s,a)[r+\gamma V(s')]\),然后选择最大的那一个。回忆一下,env.P[s][a]返回的是所有的($p(s’,r|s,a), s’, r, done$),也就是给定s和a,所有可能的状态s’和奖励r的组合。
还有一点需要注意的就是:我们并没有“显示”的定义当前策略(或者新策略),我们只需要更新policy[s][a]就行了。如果状态是s,那么当前的策略就是从中选择值最大的下标a。最后我们使用策略迭代来求最优策略与最优价值函数:
policy, v = policy_improvement(env)
我们发现它找到了最优的策略:
Reshaped Grid Policy (0=Up, 1=Right, 2=Down, 3=Left):
[[U L L D]
[U U U D]
[U U R D]
[U R R U]]
同时它也找到了最优的价值函数:
[[ 0. -1. -2. -3.]
[-1. -2. -3. -2.]
[-2. -3. -2. -1.]
[-3. -2. -1. 0.]]
价值迭代(Value Iteration)
策略迭代的一个问题就是每一次策略的提升都需要计算新策略的价值$v_\pi$,计算一个策略的价值本身又需要一次迭代算法。我们有必要精确的知道$v_\pi$吗?实际上可能是不需要的,假设策略评估需要100次迭代,那么我们能否只迭代50次就开始策略提升呢?答案是肯定的。更加极端的是只进行一次策略评估就进行策略提升,这就是本节的算法——价值迭代。因为只有一次策略评估,我们可以把它整合到策略提升的公式里,这样看起来我们一种在更新价值,所以这个算法就叫价值迭代:
\[\begin{split} v_{k+1}(s) & \equiv \max_a \mathbb{E}[R_{t+1}+\gamma v_k(S_{t+1})|S_t=s,A_t=a] \\ & =\max_a\sum_{s',r}p(s',r|s,a)[r+\gamma v_k(s')] \end{split}\]它的算法伪代码如下图所示。
 图:价值迭代算法伪代码
图:价值迭代算法伪代码
价值迭代代码示例
完整代码在Value Iteration.ipynb。主要代码如下:
def value_iteration(env, theta=0.0001, discount_factor=1.0):
"""
价值迭代算法
参数:
env: OpenAI environment。env.P代表环境的转移概率p(s',r|s,a)
theta: Stopping threshold
discount_factor: 打折因子gamma
返回值:
二元组(policy, V)代表最优策略和最优价值函数
"""
def one_step_lookahead(state, V):
"""
给定一个状态,根据Value Iteration公式计算新的V(s)
参数:
state: 状态(int)
V: 当前的V(s),长度是env.nS
返回:
返回新的V(s)
"""
A = np.zeros(env.nA)
for a in range(env.nA):
for prob, next_state, reward, done in env.P[state][a]:
A[a] += prob * (reward + discount_factor * V[next_state])
return A
V = np.zeros(env.nS)
while True:
delta = 0
for s in range(env.nS):
# Do a one-step lookahead to find the best action
A = one_step_lookahead(s, V)
best_action_value = np.max(A)
# Calculate delta across all states seen so far
delta = max(delta, np.abs(best_action_value - V[s]))
# Update the value function
V[s] = best_action_value
# Check if we can stop
if delta < theta:
break
# Create a deterministic policy using the optimal value function
policy = np.zeros([env.nS, env.nA])
for s in range(env.nS):
# One step lookahead to find the best action for this state
A = one_step_lookahead(s, V)
best_action = np.argmax(A)
# Always take the best action
policy[s, best_action] = 1.0
return policy, V
请读者对照伪代码阅读,细节就不赘述了。
通用策略迭代(Generalized Policy Iteration/GPI)
我们可以把上述的方法总结为通用策略迭代框架(GPI),如下图右所示。策略迭代可以分为两个过程:策略评估和策略提升。它们是轮流进行的,首先进行策略评估然后用策略提升得到更好的策略。策略评估可以通过多次迭代得到准确的评估也可以通过少量(甚至一次)迭代得到粗略的评估。如如下图左所示,我们可以把GPI看成两个约束的优化问题,策略评估把它往上面那条线垂直的拉,使得我们可以更加准确的估计策略的Value;而策略提升把它往下拉,使得策略的价值不断提高。
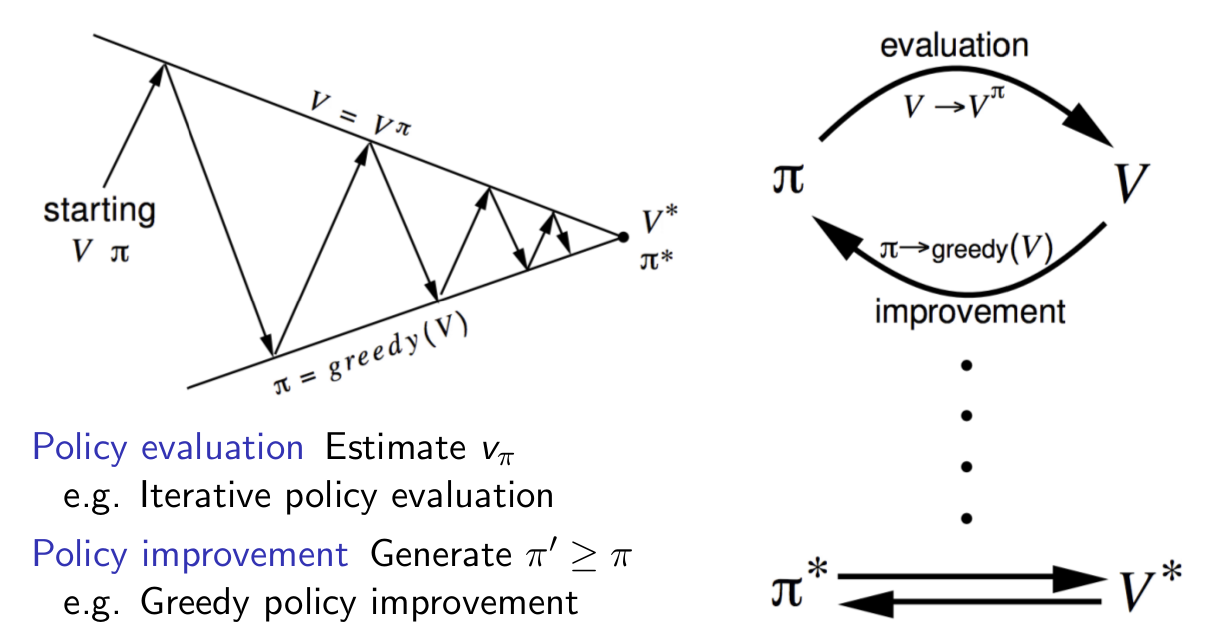 图:通用策略迭代
图:通用策略迭代
- 显示Disqus评论(需要科学上网)