这个模块介绍声学模型。完全不熟悉的读者可以先阅读基于HMM的语音识别(一)、基于HMM的语音识别(二)、基于HMM的语音识别(三)、深度学习在语音识别中的应用和PyTorch-Kaldi简介之原理回顾。更多本系列文章请点击微软Edx语音识别课程。
目录
- Introduction
- 马尔科夫链
- HMM
- HMM在语音识别中的应用
- subword单元的选择
- 使用神经网络的声学模型
- 生成帧基本的senone标签
- 训练前馈深度神经网络
- 训练RNN
- 其它循环网络结构
- 区分性(discriminative)训练
- 神经网络声学模型的解码
- Lab3
Introduction
在这个模块,我们会讨论语音识别引擎里的声学(acoustic)模型。在今天的主流语音识别系统中,声学模型是一个混合(hybrid)模型,它包括用于序列跳转的隐马尔可夫模型(HMM)和根据当前帧来预测状态的深度神经网络。HMM是用于建模离散时间序列的常见模型,它在语音识别中已经使用了几十年了。
马尔科夫链
在研究HMM之前,我们先简单的回顾一下马尔科夫链。马尔科夫链是建模随机过程的一种方法。在马尔科夫链里,离散的事件通过一些状态来建模。状态之间的跳转是通过一个随机过程来控制。
让我们来看一个例子。对于一个预测天气的应用,状态可能是”Sunny(s)”, “Partly Cloud(p)”, “Cloudy(c)”, 和”Raining(r)”。如果我们像计算一个5天的天气预报,比如P(p,p,c,r,s),我们可以使用贝叶斯公式来把联合概率分解成一系列条件概率:
\[p(X1,X2,X3,X4,X5)=p(X5|X4,X3,X2,X1)p(X4|X3,X2,X1)\\ p(X3|X2,X1)p(X2|X1)p(X1)\]我们假设这是一阶马尔科夫模型,也就是某一天的天气只依赖于前一天的天气,也就是:
\[p(X_i|X_1,\ldots,X_{i-1})=p(X_i|X_{i-1})\]使用上面的一阶假设,上面的概率可以简化为:
\[\begin{split} p(X1,X2,X3,X4,X5) & =p(X5|X4)p(X4|X3)p(X3|X2)p(X2|X1)p(X1) \\ & =p(X_1)\prod_{i=2}^5p(X_i|X_{i-1}) \end{split}\]因此,马尔科夫链的关键元素是状态的定义以及它们之间的跳转概率$p(X_i \vert X_{i−1})$——它表示的从一个状态跳转到另外一个状态(包括自己)的概率。
比如,天气预报的马尔科夫链可能如下图所示:
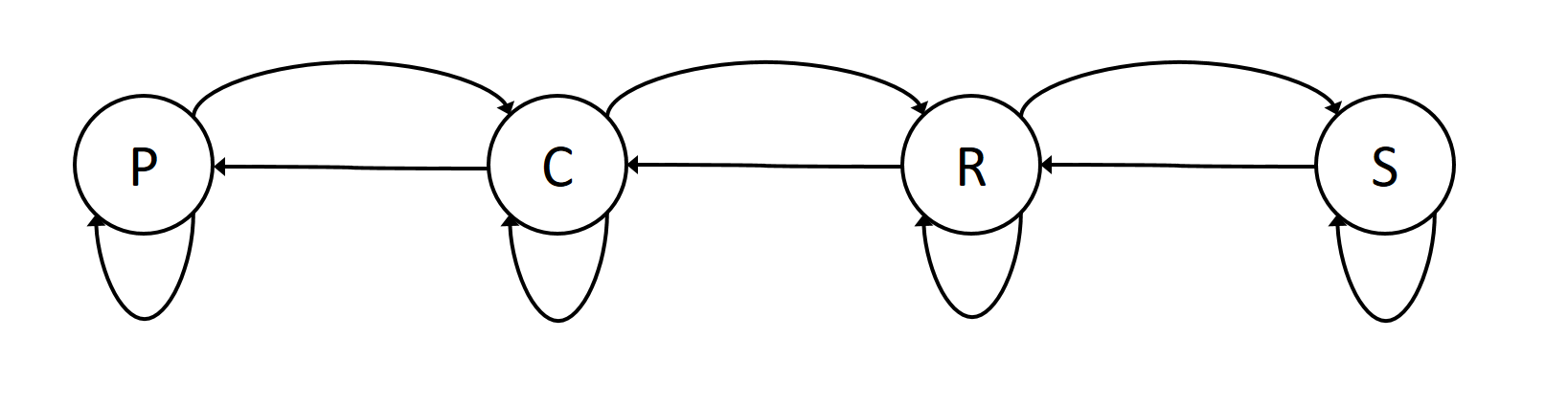 图:马尔科夫链
图:马尔科夫链
注意:除了跳转概率$p(X_i \vert X_{i−1})$,我们还需要知道初始状态的概率分布$p(X_1)$。我们假设初始状态的分布为:
\[p(p)=\pi_p, p(c)=\pi_c, p(r)=\pi_r, p(s)=\pi_s\]有了状态的跳转概率和初始状态的概率,我们就可以计算P(p,p,c,r,s):
\[p(p,p,c,r,s) = p(s|r,c,p,p) p(r|c,p,p) p(c|p,p) p(p|p) p(p) \\ = p(s|r) p(r|c) p(c|p) p(p|p) p(p)\]HMM
前面介绍的马尔科夫链也叫做可观测的(observable)马尔科夫模型。这是因为这些状态是可以观察的,比如是否下雨。而HMM模型的不同在于它的状态是不可观察的,或者说状态与观察不是确定性的关系。这使得HMM是有双重的随机性。状态之间的跳转是随机的,而某个状态下的观察也是随机的。我们可以把前面的天气预报的马尔科夫链变成HMM,状态之间的跳转还是像之前的马尔科夫链,但是在某个状态下我们观察到天气也是随机的。
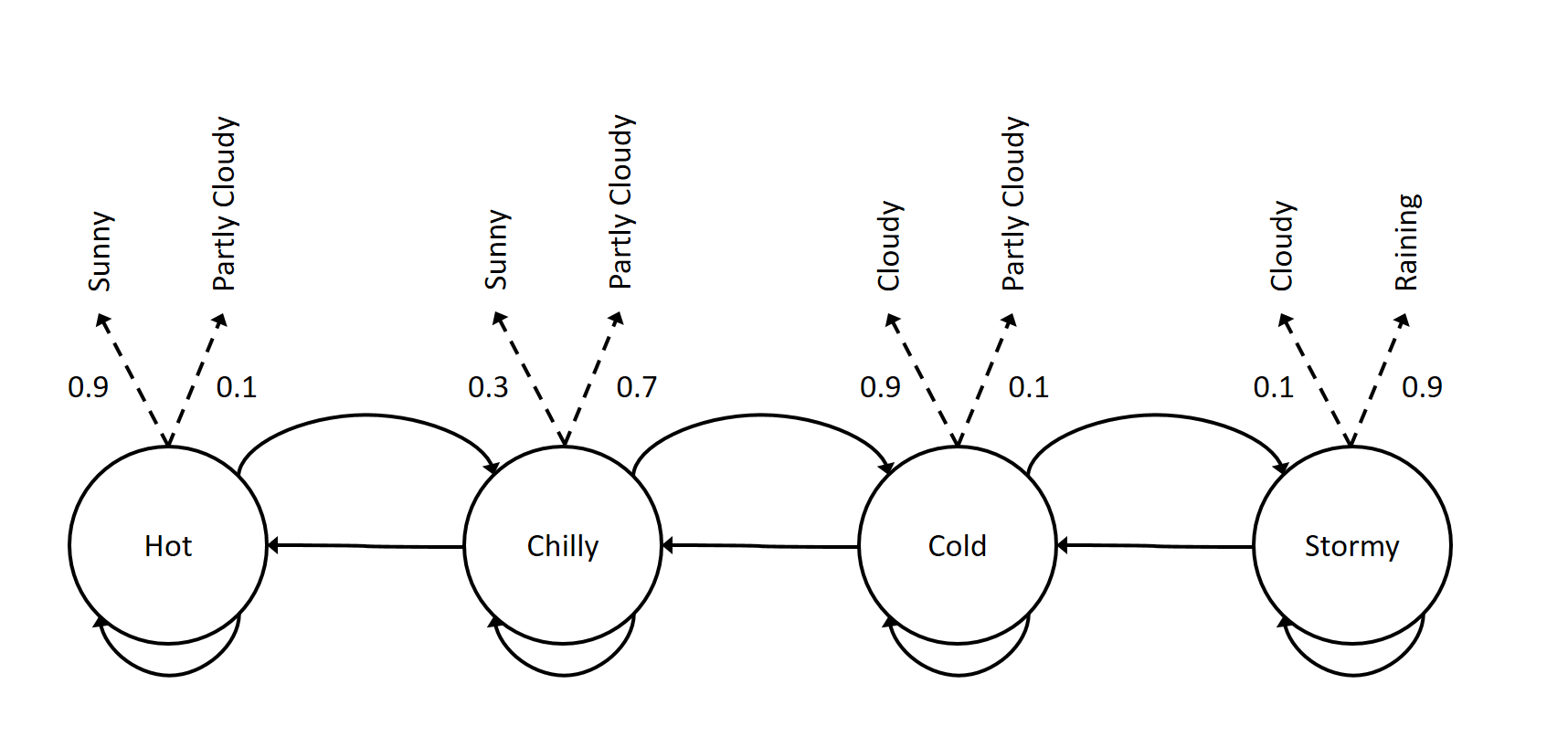 图:天气预报的HMM
图:天气预报的HMM
如上图所示,我们的状态”可能”是”Hot”、”Chilly”、”Cold”和”Stormy”,而观察是”Sunny(s)”, “Partly Cloud(p)”, “Cloudy(c)”, 和”Raining(r)”。状态是看不到的,因此状态的名字也是没有什么意义的,只不过我们猜测这个状态可能的物理意义而已。把状态的名字从”Hot”改成”1”并没有什么不同。
一个N状态的HMM由如下概率定义:
- 转移(跳转)概率矩阵A,其中$a_{ij}$表示从状态i跳转到j的概率。
- 发射概率B,其中\(B=\left\{b_i(x)\right\},\left\{i= 1,2,\ldots, N \right\}\),其中$b_i(x)$表示状态i下出现观察x的概率。
- 初始概率,\(\pi=\left\{\pi_1, \pi_2, \ldots, \pi_N\right\}\),表示初始状态的概率分布。
我们可以把HMM紧凑的记为\(\Phi = \left\{A, B, \pi\right\}\)。
HMM有三个主要的问题,下面我们简单的介绍一下。
似然计算
给定一个模型(的参数)和观察序列,怎么计算模型生成这个观察训练的概率?
这可以通过简单的穷尽所有隐状态序列的组合来计算,但是这样的实现复杂度是$O(N^T)$。更为高效的算法是前向算法,这是一种动态规划算法,它的时间复杂度是$O(N^2T)$,详细介绍读者可以参考基于HMM的语音识别(一)。
解码算法
给定一个模型和观察训练,怎么计算最可能的状态序列?这个问题可以使用著名的Viterbi算法来解决。详细介绍读者可以参考基于HMM的语音识别(一)。
学习算法
给定一个模型的定义和一个观察序列(或者很多观察序列),怎么跳转模型的参数$\Phi$?这个问题可以使用Baum-Welch算法来解决,它包括了前向和后向算法。
前向算法的一个副产品是可以计算t时刻状态为i并且从开始到t时刻观察序列的联合概率分布;而后向算法的副产品是可以计算出t时刻为i并且t+1时刻到T的观察的条件概率分布。把这两个概率结合起来就可以计算给定整个观察序列的条件下t时刻状态为i的概率。
有了上面的状态占有概率,我们就可以使用EM(Baum-Welch)算法来迭代的跳转模型的参数使得模型生成这个观察序列的概率不断提高,直到收敛到一个局部最优值。
详细介绍读者可以参考基于HMM的语音识别(一)。
HMM在语音识别中的应用
在语音识别中,HMM用于建模subword级别(比如音素)的声学建模。通常我们使用3个状态的HMM来建模一个音素,它们分别表示音素的开始、中间和结束。每个状态可以跳转到自己也可以跳转到下一个状态(但是不能往后跳转)。
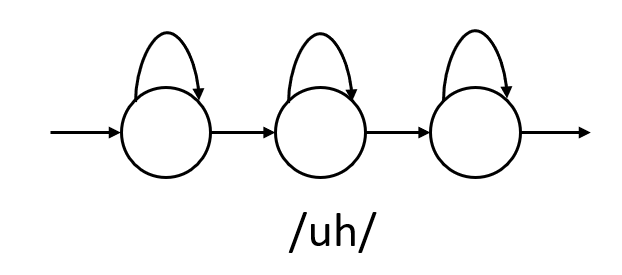 图:音素/uh/的HMM
图:音素/uh/的HMM
而一个词是有一个或者多个音素组成,因此它的HMM由组成它的音素的HMM拼接起来。比如下图所示,”cup”是由3个音素组成:
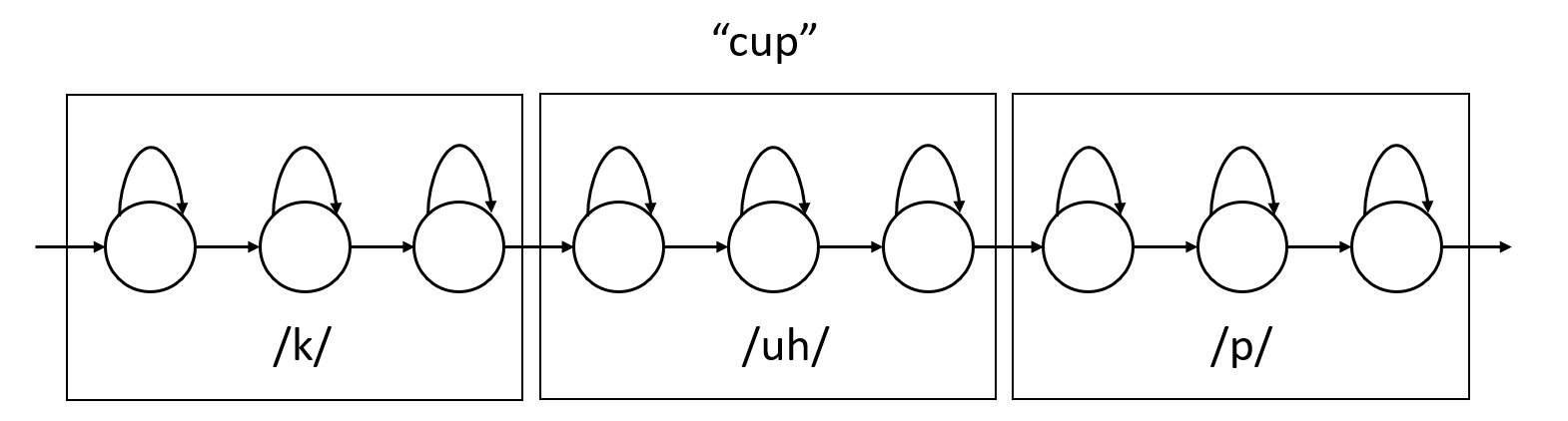 图:词”cpu”的HMM
图:词”cpu”的HMM
因此一个高质量的发音词典非常重要,所谓的发音词典就是定义每个词由哪些音素组成。在深度学习流行之前,HMM的发射概率通常使用GMM模型来建模:
\[p(x|s)=\sum_m w_m {\mathcal N}(x;\mu_m, \Sigma_m)\]这里${\mathcal N}(x;\mu_m,\Sigma_m)$是一个高斯分布,而$w_m$是混合的权重,它满足$\sum_m w_m=1$。因此,每个状态都对应它自己的GMM。我们可以使用Baum-Welch在估计HMM跳转概率的同时估计所有GMM的参数,包括均值、协方差矩阵和混合的权重。
现在流行的语音系统不再使用GMM而是使用一个神经网络模型模型,它的输入是当前帧的特征向量(可能还要加上前后一些帧的特征),输出是每个音素的概率。比如我们有40个音素,每个音素有3个状态,那么神经网络的输出是40x3=120。
这种声学模型叫做”混合”系统或者成为HMM-DNN系统,这有别于之前的HMM-GMM模型,但是HMM模型还在被使用。
subword单元的选择
在前面,我们介绍词的HMM是由音素的HMM通过发音词典的定义拼接起来的。这种音素被称为上下文无关的phone,或者简称CI phone。但是由于协同发音现象的存在,一个音素的发音是依赖于它前后的其它音素的。比如/ah/在”bat”中的发音是和”cap”里不同的。
因此,为了更好的建模我们通常使用上下文相关的phone,或者说CD phone。因此”bat”里的ah我们表示为/b-ah+t/,它表示ah的左边是b,而右边是t。类似的”cap”里的ah表示为/k-ah+p/。
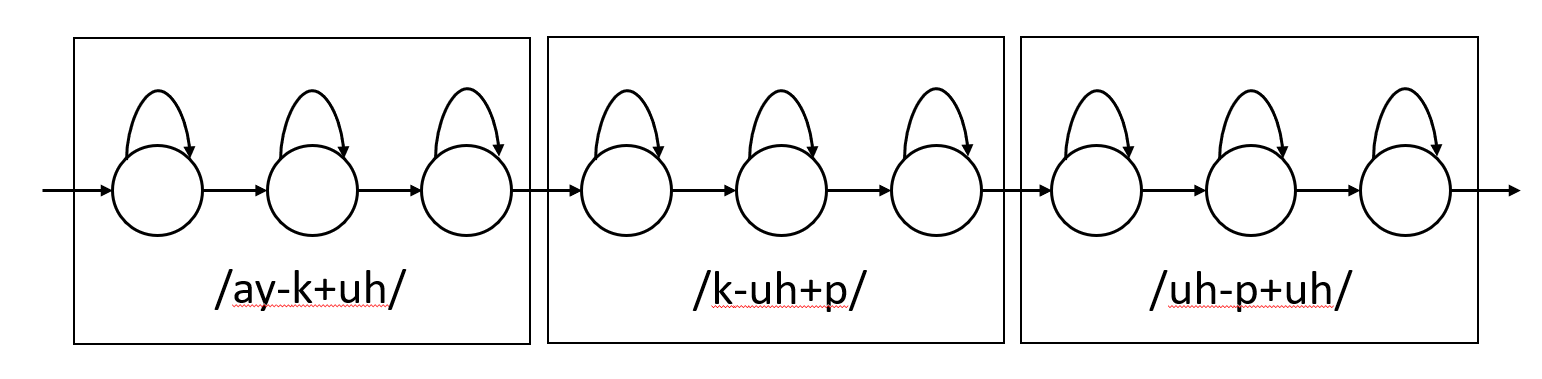 图:词的HMM
图:词的HMM
因为上面的CD phone使用连续的3个phone,因此被成为triphone。也有一些系统使用更长的上下文,比如前后共5个phone,虽然这种系统不太常见,
当使用CI phone的时候,状态的数量是可控的:N个phone乘以P个状态。对于英语来说通常是40个phone,每个phone3个状态,因此总共120个状态。但是我们使用triphone时,它的数量就会爆炸,理论上的triphone的状态个数为$N^3$(实际训练数据中出现的没有这么多,但是也是一个数量级的),那么总共的状态数就是$40^3 \times 3=192,000$。
这会导致两个问题:
- 每个triphone的训练数据很少
- 某些triphone甚至都没有在训练数据中出现过
解决这个问题的常见方法是把比较类似的triphone聚类到一起,让它们共享参数,这就是所谓的tied状态或者说共享的状态。这种tied的状态叫做senone,它是把聚类在一起的triphone的数据都放到一起训练处理的状态。
triphone状态的聚类通常使用决策树来实现。通常属于同一个CI phone都有triphone都是放到一棵决策树里聚类,也就是说决策树的数量等于CI phone的数量。
聚类过程如下:
- 把所有属于同一个CI phone的triphone的同一个状态都放到一棵决策树的根节点。比如把所有/*-p+*/的第2个状态都放到一起。
- 通过语言学的yes-no问题来不断的分裂这棵树,问题可能类似”左边的context是不是一个后元音?”或者”右边是不是浊音?”,我们选择问题的依据是使得训练数据上的似然增加最大的问题。
- 一直分裂直到似然步骤增加或者树的节点数超过某个阈值。这事属于同一个叶子的triphone就是一个senone,它们的参数是共享的。
上面的过程能够解决前面的两个问题。首先通过状态的共享,使得每个senone使得训练数据增多,从而使得参数的估计更加鲁棒。其次一个在训练数据中没有出现的triphone最终都可以通过问题走到某个叶子节点,我们可以认为这个叶子节点的状态和这个triphone的状态是类似的,这样可以解决第二个问题。
几乎所有的主流语音是不相同都使用上下文相关的phone。通常一个生产基本的系统包含10,000个senone。这比120个CI的状态多但是又比没有聚类的192,000个状态少很多。
使用神经网络的声学模型
语音识别在最近今年最大的突破就是使用神经网络来替代GMM进行声学建模。在这里神经网络的输入是特征(当前帧加上前后一些帧的特征),输出是senone的概率。但是我们的训练数据标注只是标注词序列,因此我们还需要一个传统的GMM模型来强制对齐得到每一帧对应的senone,这样才有训练数据。
有了训练数据之后,这就是一个简单的分类任务了,我们可以使用交叉熵损失函数,它的定义为:
\[E = -\sum_{i=1}^M t_m \log(y_m)\]这里$t_m$是分类标签的one-hot表示,$y_m$是softmax层的输出。
生成帧基本的senone标签
前面提到过为了训练神经网络的分类器,我们需要训练数据——输入是每一个时刻的特征,输出是这个时刻的senone。但是我们标注的数据只是到句子级别,我们不可能(成本太高)标注每一个时刻的senone。
为了获得每一帧的senone标签,我们使用强制对齐算法。强制对齐还是一个Viterbi解码算法,但是把搜索路径限制在能够产生正确句子的这些路径里。强制对齐会产生一条最可能的状态序列,因此就可以得到每一帧的senone标签。
强制对齐需要一个现成的语音识别系统,通常使用HMM-GMM来作为初始系统,当然训练完一个神经网络分类器后可以用HMM-DNN来做新的强制对齐,然后产生新的对齐(应该更好)然后训练新的神经网络分类器。
强制对齐的输出通常是一个文件,对于每一个utterance标注出每一帧的senone标签,当然为了简化,只需要标注每一个senone的开始和结束帧就行。不同的工具的格式都不相同。HTK是一个很流行的工具,在HTK里定义了一种MLF个数的文件,它是强制对齐的结果。下图是一个MLF文件的片段,它对于的utterance是”good morning”。
 图:MLF示例
图:MLF示例
每一列的含义为:
- 开始时间(单位为100ns)
- 结束时间(单位为100ns)
- Senone ID
- 这一帧的声学模型得分
- triphone
- 这个triphone HMM的得分,因此不是每一列都有,值出现在triphone的第一个状态
- 对应的词(词出现在第一个phone的地方)
我们以第4行为例,它代表triphone sil-g+uh的第一个状态,它的开始时间是3.45s,结束时间是3.55s。这个状态的Senone ID是g_s2_6,这一帧的声学得分是8.03(-log)。第5行是sil-g+uh的第二个状态,而第6行是第三状态。这三个状态合起来就是sil-g+uh,这个triphone的HMM的声学得分在第一个状态(第4行)里列出,是27.68。
有了这个文件,我们就能知道每一帧对于的senone标签(ID),就可以训练神经网络的分类器了。
训练前馈深度神经网络
最简单和常见的用于声学模型的神经网络是全连接的前馈神经网络。网上有很多介绍了,我们这里只介绍与声学模型有关的关键点。
虽然我们训练DNN来预测当前帧的标签,但是使用当前帧前后的一些帧是非常有帮助的。具体来说,假设当前帧的时刻是t,那么神经网络的输入是当前帧以及它前后N帧。因此如果$x_t$是t时刻的特征向量,那么神经网络的输入是:
\[X_t = [ x_{t-N}, x_{t-N-1}, \ldots, x_t, \ldots, x_{t+N-1}, x_{t+N} ]\]N通常的取值是5到11之间,这取决于训练数据的多少。上下文的窗口越大,那么它能提供更多的上下文信息但是也需要更多的模型参数和更多训练数据来训练。
通常建议使用特征向量的时间差分来增强特征,这也成为delta特征。这些delta特征可以是简单的差分也可以使用更加复杂的回归公式,比如:
\[\Delta x_t = x_{t+2} - x_{t-2}\\ \Delta^2 x_t = \Delta x_{t+2} - \Delta x_{t-2}\]我们可以把原来的一个特征变成3个$x_t, \Delta x_t, \Delta^2 x_t$,如果加上作用的N个窗口,那么特征向量的个数总共是3 * (2N+1),我们把这么多个特征向量拼接成一个大的向量输入到DNN里。
如下图所示,把这个大的向量作为DNN的输入,然后经过很多线性和激活层,最后使用softmax把它的输出变成概率。
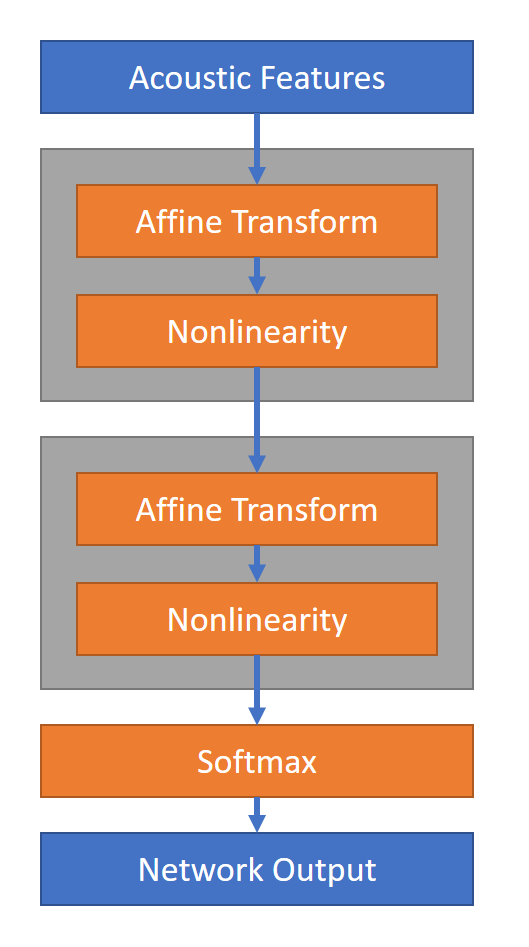 图:DNN声学模型
图:DNN声学模型
训练RNN
另一类神经网络是RNN。和前馈的DNN不同,RNN的输入是一个序列,并且它们之间有时序依赖性。有很多种不同形式的循环网络。最简单的RNN的计算为:
\[h_t^i = f(W^i h_t^{i-1} + U^i h_{t-1}^i + c^i)\]这里$f(\cdot)$是一个非线性函数比如sigmoid或者relu函数。i是网络的层,t是时间下标,输入x等价于第零层的输出, $h_t^0=x_t$。
和前馈网络不同,循环神经网络的输出不但依赖于当前时刻的输入,而且还依赖于上一个时刻的输出(隐状态)。如果你熟悉信号处理的滤波操作,一个RNN层可以看成非线性的无限冲击响应(IIR)滤波器。
对于离线的应用,我们不用考虑延迟,那么我们可以使用前后两个方向的依赖。这种网络叫做双向RNN。我们可以从前后两个方向计算t时刻的隐状态,然后把它们拼接成t时刻的隐状态:
\[\overrightarrow{h_t^i} = f\left(W_f^i h_t^{i-1} + U_f^i h_{t-1}^i + c_f^i\right) \\ \overleftarrow{h_t^i} = f\left(W_b^i h_t^{i-1} + U_b^i h_{t+1}^i + c_b^i\right) \\ h_t^i = \left[\overrightarrow{h_t^i}, \overleftarrow{h_t^i}\right]\]上式中f和b分别是前向和后向的参数。
RNN非常适合声学建模,因为它可以从中学习到特征向量序列的时序特征。为了训练RNN,训练序列的顺序必须保留。在训练普通的DNN时,我们通常已帧为单位随机打算训练数据,这样的训练更加鲁棒。但是为了训练RNN,我们就只能以utterance为单位,通一个utterance的特征序列必须保持顺序。
因为网络能够学习到数据的时间相关性,因此对于RNN来说每一帧的输入就通常不需要前后的context了。对于单向的RNN来说,因为它不能使用后面时刻的信息,因此我们还是可以输入当前帧的前后的一些context作为当前时刻的输入,但是我们不需要DNN那么长的context。而对于双向RNN来说context通常是没有必要的。
训练RNN还是可以使用和DNN相同的交叉熵损失函数,只不过它的梯度计算有些不同。因为模型的时序特性,我们通常使用反向传播算法的变体——BPTT。使用这个算法的原因是当前时刻的输出不仅受当前输入影响,同时还是之前所有时刻的影响。
和标准的反向传播算法类似,BPTT也是使用梯度下降来优化模型参数。损失函数对参数的梯度会使用链式法则。因为模型的时序特征,链式法则要求计算很多梯度的乘积。因为这些梯度没有限制,所以相乘后有可能(绝对值)非常大,这就会导致上溢,这就是所谓的梯度爆炸;也可能相乘后绝对值非常小,这就可能下溢,这就是所谓的梯度消失。为了避免这个问题,通常有两种办法:使用特殊的网络结构比如LSTM来解决这个问题;使用截断(truncated)BPTT算法,它只往前看固定长度的history。此外为了避免梯度爆炸,我们通常使用gradient clipping来直接(简单粗暴)的把梯度的绝对值限制在某个有限的范围内。
更多RNN的内容可以参考深度学习理论与实战:提高篇中的相关内容。
其它循环网络结构
为了解决梯度消失和爆炸并且学习长距离的依赖关系(截断的BPTT算法可以一定程度的解决梯度消失和爆炸,但是不能学习长距离依赖),我们可以使用LSTM。
LSTM有一个cell,它就像一个存储体一样可以保存状态信息。这个信息可以使用门的机制来保存或者擦除。门取值接近0则阻止信息通过,而取值接近1则让信息通过。输入门决定多少的信息存储cell。遗忘门决定上一个时刻的多少信息可以保存下来。而输出门决定多少的信息可以往下一个时刻传递。LSTM如下图所示。
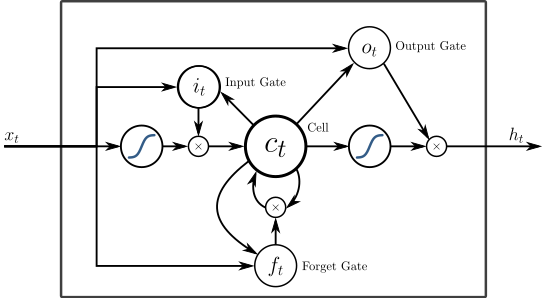 图:LSTM
图:LSTM
网络上有很多LSTM的资料,比如Colah的博客是个很好的文章。
另外一些LSTM的变体比如GRU,它简化了LSTM的隐单元,它和LSTM效果差不多,但是参数更少。
区分性(discriminative)训练
虽然RNN是一个序列的声学模型,也就是它会建模声学特征向量序列的时序特性,但是它使用的目标函数仍然是各帧独立的。举一个假想的简单例子,如下图所示。
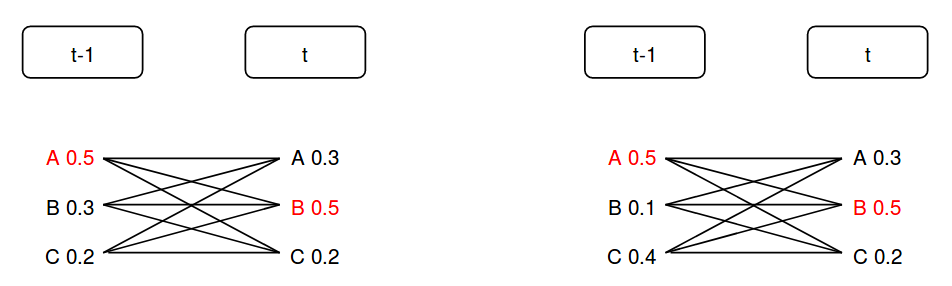 图:区分性训练
图:区分性训练
我们假设只有两帧数据,并且只有A、B和C三种状态。假设这两个时刻正确的senone标签是A和B,那么如果使用前面的交叉熵损失函数,左右两种输出的损失是一样的。但是我们来考虑一下所有的路径的概率:
| 路径 | 左边模型的概率 | 右边模型的概率 |
|---|---|---|
| AA | 0.15 | 0.15 |
| AB | 0.25 | 0.25 |
| AC | 0.10 | 0.10 |
| BA | 0.09 | 0.03 |
| BB | 0.15 | 0.05 |
| BC | 0.06 | 0.02 |
| CA | 0.06 | 0.12 |
| CB | 0.10 | 0.20 |
| CC | 0.04 | 0.08 |
我们现在来考虑解码的情况,假设最优路径是AB。先看声学模型,AB的概率是0.25;BB第一个模型的概率是0.15,第二个是0.05。如果只看声学模型,那么两个模型解码的最优路径都是AB。如果但是我们还有语言模型,假设AB的语言模型得分是1,而BB的语言模型得分是2,第一个模型输出的是BB,这是错误的,而第二个模型输出是正确的AB。
从上面的例子可以看出,我们在训练声学模型的时候不但要考虑声学模型的得分,同时也要考虑语言模型。对于那些语言模型得分高的错误路径,我们希望它的声学模型得分更低一点,这样即使它的语言模型得分高也不会”抢走”了正确的路径。另外即使所有序列的语言模型得分都是一样,区分性训练也会考虑其它”潜在对手”的得分。举个不恰当的例子,比如三个人考试,一种得分情况是”50, 30, 20”,一种得分情况是”50, 40, 10”。虽然得50分的都是第一名,但是我们会觉得第一种得分的第一名更加”稳固”,因为他比第二名多20分,而第二种得分情况第一名只比第二名多10分。
所谓的区分性训练就是考虑(简单)语言模型的情况下正确的路径序列要尽量比错误的序列分高,一种方法是让正确的路径分尽量高;另一种方法是让分数更加分散的分布在错误的路径上而不能让某一个错误路径分特别高。
有很多种区分性训练的目标(损失)函数,我们这里介绍最常见的最大互信息(maximum mutual information; MMI)目标函数。为了对比,我们首先来看普通的最大似然(ML)目标函数:
\[F_{ML}=\sum_{u=1}^UlogP_{\lambda}(X_u|M(W_u))\]上式中$X_1,…,X_U$是U个训练数据的观察训练;而$W_1,…,W_U$是正确的词序列;$\lambda$是模型的参数;$M(W_u)$表示词序列$W_u$的HMM模型。我们的目标是调整模型参数,使得$F_{MLE}$尽可能的大。
接下来我们来看MMI的目标函数,和ML相比,它是一种后验概率,也就是给定观察序列的条件下词序列的概率。因此MMI也叫条件最大似然。
\[\begin{split} F_{MMI} & =\sum_{u=1}^UlogP_{\lambda}(X_u|M(W_u)) \\ & = \sum_{u=1}^Ulog \frac {P_{\lambda}(X_u|M(W_u))P(W_u)} {\sum_{w'}P_{\lambda}(X_u|M(w'))P(w')} \end{split}\]为了使得$F_{MMI}$大,一方面我们需要使得分子尽量大,也就是正确词序列的似然概率乘以正确词序列的语言模型尽量大。同时也需要让分母尽量小,也就是其它的词序列的似然概率乘以语言模型得分尽量小。
在进行MMI训练时,我们不太可能遍历所有可能的词序列。实际我们通常遍历概率较大的那些路径,这可以在解码时通过输出Lattice来获得这些路径。这些内容在本课程不作展开讨论。
除了MMI,其它常见的区分性目标函数还包括最小因子错误(MPE)目标函数,它的计算公式为:
\[\begin{split} F_{MPE} = \sum_{u=1}^Ulog \frac {\sum_{w}P_{\lambda}(X_u|M(w))P(w)A(w,W_u)} {\sum_{w'}P_{\lambda}(X_u|M(w'))P(w')} \end{split}\]MPE的分母和MMI是完全相同的,但是分子复杂一些。MMI的分子是”正确”路径的似然概率乘以语言模型概率。而MPE考虑所有的路径的似然概率和语言模型概率,但是还需要乘以一个权重$A(w,W_u)$,它表示遍历的词序列w和正确的词序列$W_u$相比的”音子准确率”。它的意思是一个词序列的音子序列和正确的越相似,那么分就应该越高。如果定义一种特殊的”音子准确率”——音子完全正确A为1否则为0,那么MPE就退化成为MMI了。
神经网络声学模型的解码
神经网络分类器计算的是后验概率$p\left( s \right \vert x_{t})$,其中s是senone的标签。但是基于HMM的语音识别系统在解码时需要似然概率$p\left( x_{t} \middle \vert s \right)$。我们可以使用贝叶斯公式:
\[p\left( x_{t} \middle| s \right) = \frac{p\left( s \middle| x_{t} \right)p\left( x_{t} \right)}{p(s)} \propto \frac{p\left( s \middle| x_{t} \right)}{p(s)}\]因为观察的先验概率$p\left( x_{t} \right)$是一个常量,对于解码过程来说只是一个缩放,可以忽略。因此$p\left( x_{t} \middle \vert s \right)$可以表示成后验概率除以senone的先验概率$p(s)$,而$p(s)$可以从训练数据中统计出来(通过Viterbi的align得到)。
这样得到的似然概率叫做缩放后的似然,因为它不是一个真正的概率,而是对应的概率乘以了一个缩放因子。
Lab3
需要的文件
- M3_Train_AM.py
- M3_Plot_Training.py
说明
在这个实验里,我们会实验前面提取的特征以及音素的状态对齐数据(这个数据预先准备好了,不需要我们自己训练HMM-GMM来获得)来训练一个声学模型(分类器),我们会实验两种模型,DNN和RNN。
训练程序的输入是:
- lists/feat_train.rscp, lists/feat_dev.rscp
训练和开发用的特征文件,格式为RSCP。它是相对(Relative)SCP文件的缩写,而SCP在HTK里是脚本文件的意思。它只是简单的文件列表。开发集用于用于进行early-stopping从而防止过拟合。这些文件是Lab2的输出。下面是这个文件的部分内容:
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/lists$ head feat_train.rscp
1272-128104-0000.feat=.../../feat/1272-128104-0000.feat[0,583]
1272-128104-0001.feat=.../../feat/1272-128104-0001.feat[0,479]
1272-128104-0002.feat=.../../feat/1272-128104-0002.feat[0,1246]
1272-128104-0003.feat=.../../feat/1272-128104-0003.feat[0,987]
1272-128104-0005.feat=.../../feat/1272-128104-0005.feat[0,898]
1272-128104-0006.feat=.../../feat/1272-128104-0006.feat[0,561]
1272-128104-0007.feat=.../../feat/1272-128104-0007.feat[0,921]
1272-128104-0008.feat=.../../feat/1272-128104-0008.feat[0,509]
1272-128104-0009.feat=.../../feat/1272-128104-0009.feat[0,1826]
1272-128104-0010.feat=.../../feat/1272-128104-0010.feat[0,557]
1272-128104-0000是utterance的id,它对应的特征文件的(相对)路径是../feat/1272-128104-0000.feat。我们可以把多个wav的特征放到一个.feat文件里,所以后面的[0,583]表示开始和结束帧。我们这里都是一个wav文件对应一个feat文件。
- am/feat_mean.ascii, am/feat_invstddev.ascii
来自训练数据的特征的全局矩阵和precison(逆标准差),也是Lab2的输出。
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/am$ head feat_mean.ascii
-2.919659685974384e-18
2.6895413354526914e-17
1.1225642911903567e-17
-1.290888005604958e-17
-7.668256929894009e-18
1.282128320120786e-17
5.681433105359057e-18
-5.895127045597928e-19
-1.055930635279509e-18
8.438261541002666e-19
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/am$ head feat_invstddev.ascii
0.660715173912793
0.7023766123007734
0.5484047071809811
0.4658540835511212
0.45702270701906805
0.47391065135412674
0.4644688113915111
0.4555758927655162
0.46129416349632707
0.4704301406803074
- am/labels_all.cimlf
音素和状态的对齐文件,这是MLF格式,参考前面的介绍。这个文件是HMM-GMM模型强制对齐后得到的,因此这里也提供好了。
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/am$ head -n 20 labels_all.cimlf
#!MLF!#
#!MLF!#
"2086-149220-0029.lab"
0 2500000 sil_s2 -1779.570068 sil -4409.295410 !silence
2500000 2900000 sil_s4 -361.139191
2900000 3900000 sil_s2 -975.873169
3900000 5200000 sil_s4 -1291.427002
5200000 5600000 ay_s2 -446.330902 th-ay+ch -748.439758 i
5600000 5700000 ay_s3 -105.397713
5700000 5900000 ay_s4 -196.711136
5900000 6100000 k_s2 -181.114380 hh-k+aa -787.464050 can
6100000 6700000 k_s3 -516.135864
6700000 6800000 k_s4 -90.213844
6800000 6900000 ah_s2 -87.603935 k-ah+m -266.183533
6900000 7000000 ah_s3 -90.501427
7000000 7100000 ah_s4 -88.078186
7100000 7200000 n_s2 -83.467957 ae-n+aa -507.740692
7200000 7500000 n_s3 -259.140686
7500000 7700000 n_s4 -165.132050
7700000 7800000 ah_s2 -86.116051 ng-ah+s -266.532501 assure
- am/labels.ciphones
phoneme的状态符号,是神经网络声学模型的输出。它有120行,代表120个分类(0代表第一个分类……119代表最后一个分类)。
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/am$ head labels.ciphones
aa_s2
aa_s3
aa_s4
ae_s2
ae_s3
ae_s4
ah_s2
ah_s3
ah_s4
ao_s2
- am/labels_ciprior.ascii 每个senone类别的先验概率,这是通过训练数据中简单统计出来的。
上面的RSCP文件和全局的矩阵和precision文件是LAB生成的,其余的文件是从github clone下来就有的。
第一部分 训练DNN声学模型
我们已经提供了可以运行的程序M3_Train_AM.py。
$ python M3_Train_AM.py –-type DNN
这个DNN的超参数是:
- 4个隐层,每个隐层512个神经元
- 输出是120维的
- 输入向量是当前时刻为中心的23帧(如果不够就padding零),左右各11帧
- minibatch 256
- 使用冲量的SGD算法,learning rate是1e-04。
- 一个epoch训练所以训练数据一次,总共训练100个epoch
- 每5个epoch在开发集上进行验证
在带GTX 965M GPU的笔记本电脑上,训练的速度是63,000 samples/sec或者说20sec/epoch。因此100个epoch大概需要30分钟。最后输出的信息为(这是作者的结果):
lili@lili-Precision-7720:~/codes/Speech-Recognition/Experiments/am/DNN$ tail log
Minibatch[1001-2000]: loss = 1.038773 * 256000, metric = 32.78% * 256000;
Minibatch[2001-3000]: loss = 1.038587 * 256000, metric = 32.78% * 256000;
Minibatch[3001-4000]: loss = 1.045352 * 256000, metric = 32.96% * 256000;
Finished Epoch[99 of 100]: [CE_Training] loss = 1.040477 * 1257216, metric = 32.83% * 1257216 9.578s (131260.8 samples/s);
Minibatch[ 1-1000]: loss = 1.031116 * 256000, metric = 32.56% * 256000;
Minibatch[1001-2000]: loss = 1.031200 * 256000, metric = 32.53% * 256000;
Minibatch[2001-3000]: loss = 1.038292 * 256000, metric = 32.84% * 256000;
Minibatch[3001-4000]: loss = 1.038667 * 256000, metric = 32.83% * 256000;
Finished Epoch[100 of 100]: [CE_Training] loss = 1.036563 * 1257104, metric = 32.71% * 1257104 9.429s (133323.2 samples/s);
Finished Evaluation [20]: Minibatch[1-11573]: metric = 44.37% * 370331;
在训练数据上的交叉熵loss是1.04左右,帧错误率(senone分类错误率)为32.7%,在开发集上的帧错误率是44%左右。
训练完成后我们可以使用M3_Plot_Training.py来绘图,这个程序的输入是CNTK的log。绘制的是损失和帧错误率随这epoch的变化曲线。
$ python M3_Plot_Training.py --log ../Experiments/am/DNN/log
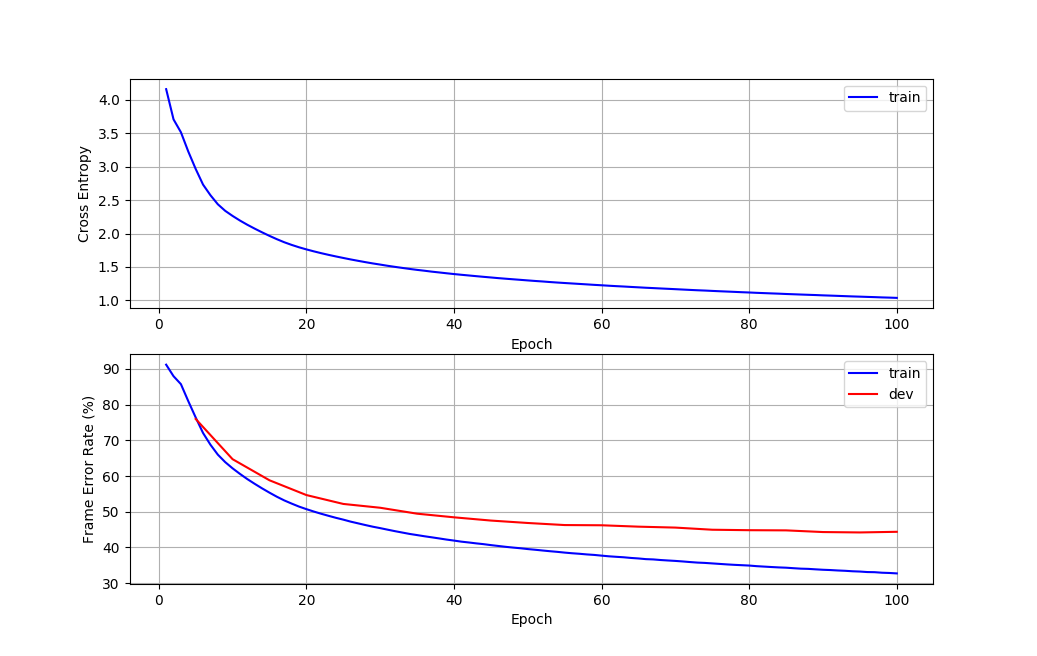
从图中我们发现模型还没有过拟合,因此如果继续多训练一些epoch应该还会有一些提高。读者可以调整超参数来得到更好的模型,可以尝试的超参数包括:
- DNN的层数
- 每层隐单元个数
- Learning rate
- Minibatch大小
- epochs数量
- SGD之外的算法(参考CNTK的文档,可以尝试Adam或者AdaGrad等其它learner)
第二部分 训练RNN模型
使用下面的命令训练:
$ python M3_Train_AM.py –-type BLSTM
因为LSTM的参数较多,训练速度会慢很多,我们这里只训练10个epoch就可以得到和DNN差不多的效果。
代码阅读
这里是使用CNTK实现的DNN和RNN,不了解的读者可以参考官网教程,熟悉其它框架(比如Tensorflow或者PyTorch)的读者只需要学习Quick tour for those familiar with other deep learning toolkits就行了,其实读者也可以用其它框架来实现声学模型。因为我们的目的是不是学习CNTK,所以这里只是大致介绍代码的结构,不会细节的介绍CNTK的内容。
create_network
这是最主要的函数,它的作用是构建网络结构。它的主要代码为:
def create_network(feature_dim = 40, num_classes=256, feature_mean_file=None, feature_inv_stddev_file=None,
feature_norm_files = None, label_prior_file = None, context=(0,0), model_type=None):
def MyMeanVarNorm(feature_mean_file, feature_inv_stddev_file):
m = C.reshape(load_ascii_vector(feature_mean_file,'feature_mean'), shape=(1, feature_dim))
s = C.reshape(load_ascii_vector(feature_inv_stddev_file,'feature_invstddev'), shape=(1,feature_dim))
def _func(operand):
return C.reshape(C.element_times(C.reshape(operand,shape=(1+context[0]+context[1], feature_dim)) - m, s),
shape=operand.shape)
return _func
def MyDNNLayer(hidden_size=128, num_layers=2):
return C.layers.Sequential([
C.layers.For(range(num_layers), lambda: C.layers.Dense(hidden_size, activation=C.sigmoid))
])
def MyBLSTMLayer(hidden_size=128, num_layers=2):
W = C.Parameter((C.InferredDimension, hidden_size), init=C.he_normal(1.0), name='rnn_parameters')
def _func(operand):
return C.optimized_rnnstack(operand, weights=W, hidden_size=hidden_size,
num_layers=num_layers, bidirectional=True, recurrent_op='lstm' )
return _func
# Input variables denoting the features and label data
feature_var = C.sequence.input_variable(feature_dim * (1+context[0]+context[1]))
label_var = C.sequence.input_variable(num_classes)
feature_norm = MyMeanVarNorm(feature_mean_file, feature_inv_stddev_file)(feature_var)
label_prior = load_ascii_vector(label_prior_file, 'label_prior')
log_prior = C.log(label_prior)
if (model_type=="DNN"):
net = MyDNNLayer(512,4)(feature_norm)
elif (model_type=="BLSTM"):
net = MyBLSTMLayer(512,2)(feature_norm)
else:
raise RuntimeError("model_type must be DNN or BLSTM")
out = C.layers.Dense(num_classes, init=C.he_normal(scale=1/3))(net)
# loss and metric
ce = C.cross_entropy_with_softmax(out, label_var)
pe = C.classification_error(out, label_var)
ScaledLogLikelihood = C.minus(out, log_prior, name='ScaledLogLikelihood')
首先是定义MyMeanVarNorm函数,它的作用是对输入特征进行归一化,也就是减去全局的均值然后除以方差(乘以precision也就是方差的逆)。
然后是定义MyDNNLayer函数,这个函数用于构建DNN,它只有一行代码:
return C.layers.Sequential([
C.layers.For(range(num_layers), lambda: C.layers.Dense(hidden_size, activation=C.sigmoid))
])
这是CNTK的特殊语法,我们可以简单的理解为一个for循环,循环里面定义一个Dense层,CNTK会自动帮我们把这些串联起来,这有点像Pytorch的torch.nn.Sequential。
接下来是定义MyBLSTMLayer函数,它用于构建RNN,代码也会简单:
W = C.Parameter((C.InferredDimension, hidden_size), init=C.he_normal(1.0), name='rnn_parameters')
def _func(operand):
return C.optimized_rnnstack(operand, weights=W, hidden_size=hidden_size,
num_layers=num_layers, bidirectional=True, recurrent_op='lstm' )
return _func
它先定义RNN的参数W,使用he_normal(He Kaiming等人提出的方法)来初始化参数。构造LSTM主要用到optimized_rnnstack,我们这里不详细介绍。
最后的代码是定义网络,需要说明的都放到注释里了。
# 定义输入和输出
feature_var = C.sequence.input_variable(feature_dim * (1+context[0]+context[1]))
label_var = C.sequence.input_variable(num_classes)
# 对输入向量进行归一化
feature_norm = MyMeanVarNorm(feature_mean_file, feature_inv_stddev_file)(feature_var)
# senone标签的先验概率
label_prior = load_ascii_vector(label_prior_file, 'label_prior')
# 取log
log_prior = C.log(label_prior)
# 输入经过DNN或者RNN
if (model_type=="DNN"):
net = MyDNNLayer(512,4)(feature_norm)
elif (model_type=="BLSTM"):
net = MyBLSTMLayer(512,2)(feature_norm)
else:
raise RuntimeError("model_type must be DNN or BLSTM")
# 最后的线性全连接层
out = C.layers.Dense(num_classes, init=C.he_normal(scale=1/3))(net)
# 交叉熵loss
ce = C.cross_entropy_with_softmax(out, label_var)
# 分类准确率
pe = C.classification_error(out, label_var)
# 对后验概率进行scale,原来是除,现在在log域就变成减法。
ScaledLogLikelihood = C.minus(out, log_prior, name='ScaledLogLikelihood')
train_network
这个函数实现训练,它的主要代码是:
def train_network(network, features_file, labels_file, label_mapping_file,
max_epochs, minibatch_size=[256], restore=False,
log_to_file=None, num_mbs_per_log=None, gen_heartbeat=False,
profiling=False, cv_features_file = None, cv_labels_file = None,
epoch_size=None, feature_dim=None, num_classes=None,
model_path=None, context=(0,0), frame_mode=False, model_type=None):
trainer = create_trainer(network, progress_writers, epoch_size)
train_source = create_mb_source(features_file,
labels_file,
label_mapping_file,
feature_dim=feature_dim,
num_classes=num_classes,
max_sweeps=max_epochs,
context=context,
frame_mode=frame_mode)
cv_source = create_mb_source(cv_features_file,
cv_labels_file,
label_mapping_file,
feature_dim=feature_dim,
num_classes=num_classes,
max_sweeps=1,
context=context,
frame_mode=frame_mode)
train_and_test(
network=network,
trainer=trainer,
train_source=train_source,
minibatch_size=minibatch_size,
restore=restore,
model_path=model_path,
model_name=model_type + "_CE",
epoch_size=epoch_size,
cv_source=cv_source
)
它首先调用create_trainer创建一个trainer(类似于tf的Optimizer),即使不熟悉cntk,应该也能猜测出它的大意。
def create_trainer(network, progress_writers, epoch_size):
# learning rate
lr_per_sample = [1.0e-4] # transplanted schedule
mm_time_constant = [2500] * 200
lr_schedule = C.learning_rate_schedule(lr_per_sample, unit=C.learners.UnitType.sample, epoch_size=epoch_size)
mm_schedule = C.learners.momentum_as_time_constant_schedule(mm_time_constant, epoch_size=epoch_size)
momentum_sgd_learner = C.learners.momentum_sgd(network['output'].parameters, lr_schedule, mm_schedule)
# Create trainer
return C.Trainer(network['output'], (network['ce'], network['pe']), [momentum_sgd_learner], progress_writers)
接着调用create_mb_source来读取数据,我们重点看一下这个函数。
def create_mb_source(features_file, labels_file, label_mapping_file, feature_dim, num_classes,
max_sweeps=C.io.INFINITELY_REPEAT, context=(0,0), frame_mode=False):
fd = C.io.HTKFeatureDeserializer(
C.io.StreamDefs(features=C.io.StreamDef(shape=feature_dim, context=context, scp=features_file))
)
ld = C.io.HTKMLFDeserializer(
label_mapping_file, C.io.StreamDefs(labels=C.io.StreamDef(shape=num_classes, mlf=labels_file))
)
return C.io.MinibatchSource([fd, ld], frame_mode=frame_mode, max_sweeps=max_sweeps)
首先是HTKFeatureDeserializer,它读取HTK格式的特征文件,这里指定shape为40(FBANK特征),context=[11,11]表示左右的上下文。features_file是’../Experiments/lists/feat_train.rscp’,这是Lab2生成的。生成的代码在M2_Wav2Feat_Batch.py:
feat = fe.process_utterance(x)
htk.write_htk_user_feat(feat, feat_file)
feat_rscp_line = os.path.join(rscp_dir, '..', 'feat', feat_name)
out_list.write("%s=%s[0,%d]\n" % (feat_name, feat_rscp_line,feat.shape[1]-1))
count += 1
rscp文件的每一行是一个utterance的id和特征文件的路径。
接着用HTKMLFDeserializer读取MLF格式的标注文件,获得每一个utterance的每一帧的senone标签。
fd和ld都可以看成dict,key是utterance的id,value都是list,list表示每一帧的FBANK特征序列和senone标签。因此通过MinibatchSource把它们放到一起作为训练数据,这里很重要的参数是frame_mode,如果是True,那么就可以打乱一个utterance里的帧的顺序,DNN可以这样。如果是RNN的话就必须为False,这样保证同一个utterance的是顺序的帧。max_sweeps就是epoch数,这里是100。
然后调用train_and_test来训练:
def train_and_test(network, trainer, train_source, minibatch_size, restore,
model_path, model_name, epoch_size, cv_source):
input_map = {
network['feature']: train_source.streams.features,
network['label']: train_source.streams.labels
}
cv_input_map = None if cv_source is None else {
network['feature']: cv_source.streams.features,
network['label']: cv_source.streams.labels
}
cv_checkpoint_interval = 5 # evaluate dev set after every N epochs
checkpoint_config = CheckpointConfig(frequency=epoch_size*10,
filename=os.path.join(model_path, model_name),
restore=restore,
preserve_all=True)
cv_checkpoint_config = CrossValidationConfig(cv_source,
model_inputs_to_streams=cv_input_map,
frequency=epoch_size*cv_checkpoint_interval)
# Train all minibatches
training_session(
trainer=trainer,
mb_source=train_source,
model_inputs_to_streams=input_map,
mb_size=minibatch_size_schedule(minibatch_size, epoch_size),
progress_frequency=epoch_size,
checkpoint_config=checkpoint_config,
cv_config=cv_checkpoint_config
).train()
input_map就类似于tf的feeddict,把输入特征feed进network[‘feature’],把输出标签feed进network[‘label’]。最后构造training_session对象调用它的train()进行训练。
最后是保存模型:
model = C.combine(network['ScaledLogLikelihood'],network['final_hidden'])
model.save(os.path.join(model_path,model_type + "_CE_forCTC"))
保存的模型能预测两个值ScaledLogLikelihood和final_hidden,ScaledLogLikelihood是给Lab5的基于WFST的解码器用的,也就是缩放后的似然概率。而final_hidden是给CTC用的,它是最后一层在softmax之前的向量,不过目前这个课程没有实现CTC。
- 显示Disqus评论(需要科学上网)