这个模块介绍语音识别的解码器,主要是WFST的解码器。更多本系列文章请点击微软Edx语音识别课程。
目录
Introduction
给定一个标签序列(比如phone),声学模型会输出声学得分。对于每一帧输入,它会计算不同标签的相对得分。这样每一个标签序列都对应一个得分。
语音模型计算词序列的得分。对于词典里的每一个合法的词序列,它都会计算一个语言模型得分。
把两者联系起来的是解码图(decoding graph)。它是一个函数,其输入是合法的声学标签序列,输出是对应的词序列及其语言模型得分。
加权有限状态转换器
在这个课程了,我们使用的解码器是基于加权有限状态转换器(WFST)。
有限状态机(Finite state automata, FSA)是一种紧凑的图结构,它定义了一个字符串的集合并且可以高效的搜索(判断某个字符串是否属于这个结合)。
有限状态转换器(Finite state transducers, FST)是类似的,但是它除了判断某个输入字符串是否属于集合,而且还能输出另外一个字符串。
FSA和FST都可以带上权值,也就是每个FSA的字符串,或者FST里的每一对字符串都有一个数值类的权值。
在本课程里,我们会介绍语音识别的各个模块使用WFST来编码从而可以实现高效解码搜索的技术。
文法(Grammar)和有限状态接收器(Finite State Acceptor)
假设我们要构建一个很简单的语音识别系统,用户只能说下面5个短语中的某一个(或者任意多次的组合重复),那么我们可以使用FSA来表示。这个5个短语为:
any thinking
some thinking
anything king
something king
thinking
这个系统的词典总共有6个词:
any
anything
king
some
something
thinking
描述只有5个短语的FSA如下图所示。
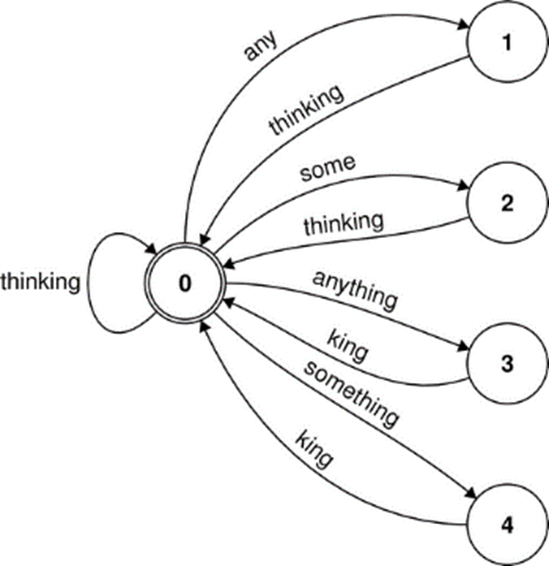 图:简单文法的FSA
图:简单文法的FSA
短语是编码为图中的路径,它从初始状态开始,结束于终止状态。路径的每一条边都是一个词。FSA用图来表示的方法为:
- 所有的路径都从id为0的初始状态开始,而结束状态(可能多个)用两个圆圈的点表示。
- 边是有向边,每条边上有一个词(符号)。
- FSA的边上只有一个输入符号。FST的边上有输入和输出两个符号,用冒号(:)分开
- 边的权重默认是0,除非特殊标出。
为了使用OpenFST编译这个图,我需要首先定义一个符号表,用于把符号(词)映射成整数。OpenFST要求特殊符号<eps>表示空的输入,它的ID是0。
$ cat Vocabulary.sym
< eps> 0
any 1
anything 2
king 3
some 4
something 5
thinking 6
我们还需要使用文本的方式来定义FST(FSA可以看成特殊的FST,它的输出符号和输入一样)。如下所示,每一行表示一条边,每行一般4列(其实还有有第五列表示weight,默认是0),分别表示边的起点的ID,终点,输入符号和输出符号。OpenFST要求第一行的第一列是初始状态,而最后一行的第一列是终止状态,最后一行只有两列,最后一行的第二列是终止状态的weight。比如下面的例子:
$ cat Grammar.tfst
0 1 any any
1 0 thinking thinking
0 2 some some
2 0 thinking thinking
0 3 anything anything
3 0 king king
0 4 something something
4 0 king king
0 0 thinking thinking
0 0
为了把文本格式的FST编译成OpenFst内部的”二进制”格式的FST,我们需要使用fstcompile工具:
fstcompile --isymbols=vocabulary.sym --osymbols=vocabulary.sym \
--keep_isymbols --keep_osymbols Grammar.tfst Grammar.fst
fstcompile的第一个参数是输入的文本格式的FST,这里是Grammar.tfst。第二个参数是输出文件,这里是Grammar.fst。选项--isymbols=vocabulary.sym和--osymbols=vocabulary.sym指定输入和输出的符号表。而--keep_isymbols的作用是在编译后的fst文件里把输入符号表也保存一份,这样编译后的FST就不依赖于--isymbols指定的文件了。--keep_osymbols的作用也是类似的,它说明需要把输出符号表保存在编译后的文件了。
发音词典,有限状态转换器
对于语音识别系统,我们需要关联一种类型的符号序列和另一种类型的符号序列。比如,词序列可以分解为phone的序列,而phone的序列有对于声学模型标签的序列。
对于我们的六个词的发音词典如下表所示。发音词典的作用是把词映射成phone的序列。一个FST可以用来表示一个发音词典,它的输入是phone的序列,输出是词序列。
| Pronunciation | Word |
|---|---|
| EH N IY | any |
| EH N IY TH IH NG | anything |
| K IH NG | king |
| S AH M | some |
| S AH M TH IH NG | something |
| TH IH NG K IH NG | thinking |
最简单的构建FST的方法就是每一个词一条从初始状态到结束状态的路径。在第一个phone的时候就输出词,然后后面都输出$\epsilon$。如下所示:
0 1 EH any
1 2 N <eps>
2 0 IY<eps>
0 3 EH anything
3 4 N <eps>
4 5 IY <eps>
5 6 TH <eps>
6 7 IH <eps>
7 0 NG <eps>
0 8 K king
8 9 IH <eps>
9 0 NG <eps>
……
比如词”any”由三个phone “EH N IY”组成,那么我们从初始状态0开始,通过第一个phone “EH”进入状态1,同时输出any。接着后面的”N”和”IY”都输出$\epsilon$,并且最后一个phone跳到初始状态0。当然这是一个非确定的FST,初始状态0遇到”EH”可以同时进入状态1和进入状态3,但是如果输入是”EH N IY”,那么成功的路径只能是”0->1->2->0”。
我们可以把公共的前缀合并起来,如下图所示:
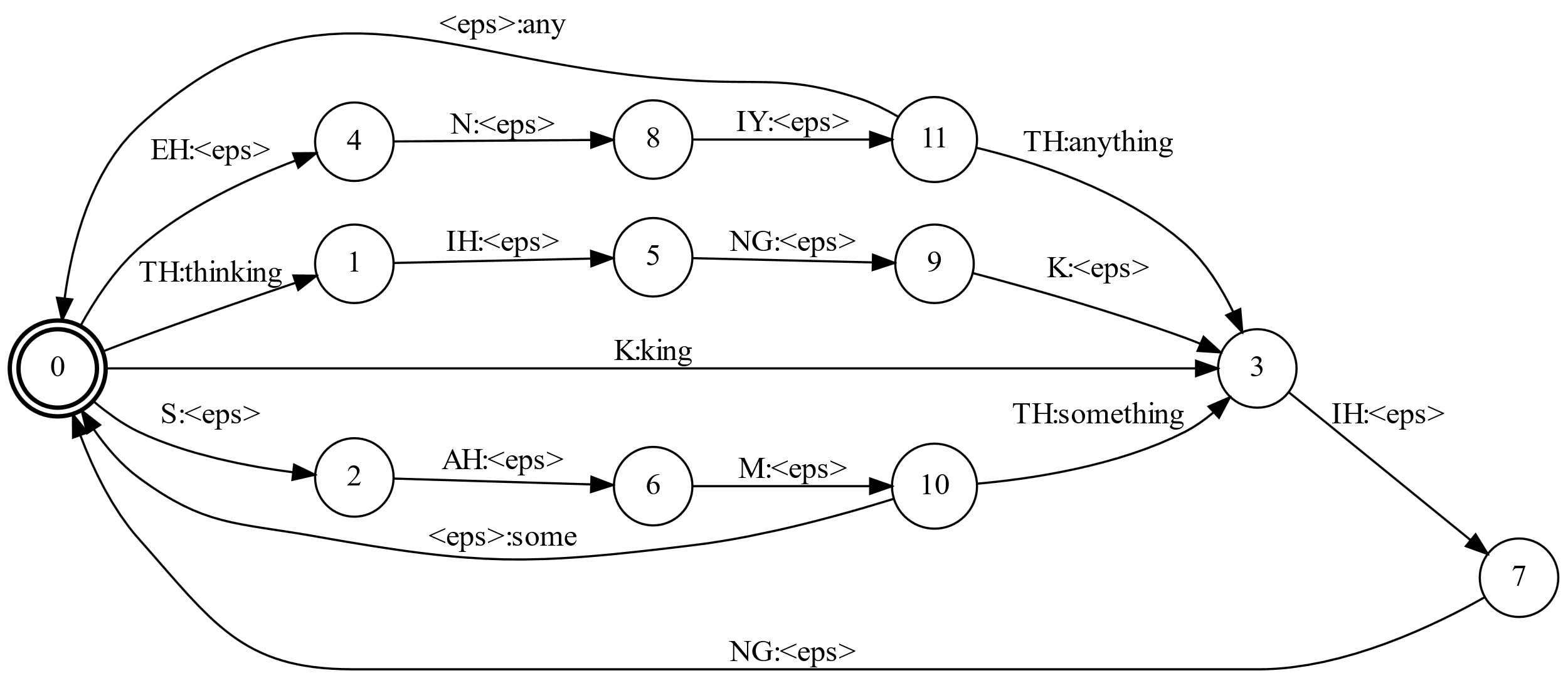 图:确定性的发音词典
图:确定性的发音词典
我们还是来看phone序列”EH N IY”,这次遇到EH输出空字符$\epsilon$,说明”EH”开头的词多于一个(any和anything),接着遇到”N”还是输出$\epsilon$,接着遇到”IY”还是输出$\epsilon$。这个时候没有输入了,但是状态11并不是结束状态。如果状态11没有$\epsilon$跳转,那么识别识别,但是状态11可以通过$\epsilon$跳转到状态0,0是一个终止状态(两层的圆圈),而且状态11到0的边的输出是”any”,因此对于输入”EH N IY”,FST的输出是”any”。
另外比如输入是”K IH NG”,状态0遇到”K”就可以输出”KING”了,因为只有这个词的开始是”K”。当然如果输入是”K EH”,那么就识别不了。
上面的图除了把公共前缀合并之外,公共的后缀也合并了。比如”IH NG”同时被”K IH NG”(king)和”TH IH NG K IH NG”(thinking)使用。
假设输入phone序列是”EH N IY TH IH NG K IH NG”,我们可以找到两条路径:”any thinking”对应的”0, 4, 8, 11, 1, 5, 9, 3, 7, 0”和”anything king”对应的”0, 4, 8, 11, 3, 7, 0, 3, 7, 0”。也就是对于一个输入序列,存在多于一个输出序列。这种FST是非函数的,而函数的FST的一个输入最多只有一个输出序列(当然可以没有)。
有一些FST算法比如确定化(determinization)算法只有应用于函数的FST。
在语音识别系统里,导致非函数FST产生有如下原因:
-
发音词典里的同音词(两个词的发音完全一样)
-
同音的序列(比如前面的例子,”any thinking”这过两个词都没有同音的,但是组合起来就有同音的词)
-
一个声学模型的状态序列对应的phone序列不唯一。
前两个问题可以通过引入消歧符号来解决,第三个问题我们这里不讨论。
对于发音词典里的每一个词,我们都在后面增加一个消歧符号,如果两个(或者多个)词的发音相同,那么我们在它们后面加入不同的消歧符号。
| Phone Sequence | Word |
|---|---|
| EH N IY #0 | any |
| EH N IY TH IH NG #0 | anything |
| K IH NG #0 | king |
| S AH M #0 | some |
| S AH M TH IH NG #0 | something |
| TH IH NG K IH NG #0 | thinking |
加入消歧符号之后,”any thinking”的phone序列就变成了”EX N IY #0 TH IH NG K IH NG #0”,而”anything king”变成了”EX N IY TH IH NG #0 K IH NG #0”,这样它们就不同了。如果有相同发音的词,比如”read”和”red”的发音都是”R EH D”,那么我们可以把它们变成”R EH D #0”和”R EH D #1”。词典里同义词的最大个数是N个,那么我们需要#(N-1)。
另外一个解决非函数的FST的确定化的办法是把FST转换成FSA。这个过程叫做FST的编码。为了把FST编码成FSA,我们需要把每条边上的输入和输出符号融合成一个符号作为FSA的输入。这个FSA介绍的字符串是输入-输出对的序列。因为它是FSA所以一定可以确定化。确定化之后我们需要逆变换这个过程再变回成FST。
HMM状态的Transducer
HMM状态的Transducer H把声学模型状态的序列映射成phone标签的序列。和发音词典类似,这个映射可以用一张表来描述:
| 声学标签序列 | Phone |
|---|---|
| AH_s2 AH_s3 AH_s4 | AH |
| EH_s2 EH_s3 EH_s4 | EH |
| IH_s2 IH_s3 IH_s4 | IH |
| IY_s2 IY_s3 IY_s4 | IY |
| K_s2 K_s3 K_s4 | K |
| N_s2 N_s3 N_s4 | N |
| NG_s2 NG_s3 NG_s4 | NG |
| S_s2 S_s3 S_s4 | S |
| TH_s2 TH_s3 TH_s4 | TH |
| M_s2 M_s3 M_s4 | M |
| #0 | #0 |
我们模型的结构是:每个phone都是3个声学标签(三状态)的序列。它们分别表示phone的开始、中间和结束。对于大规模语音识别系统的声学模型通常会包含更多的声学标签,这些标签会考虑它周围的phone(声学上下文)。本课程不结束上下文相关的模型。
注意上表需要包含来自发音词典的消歧符号。Transducer H必须使得phone序列里的消歧符号被映射为声学标签序列里的对应消歧符号。
包含上表10个中3个phone的HMM如下图所示。每个phone的模型都是一个环,HMM状态的名字(比如AH_s2)出现在输入端,而输出端是对应的phone(比如AH)。其它7个phone的结构也是类似的。
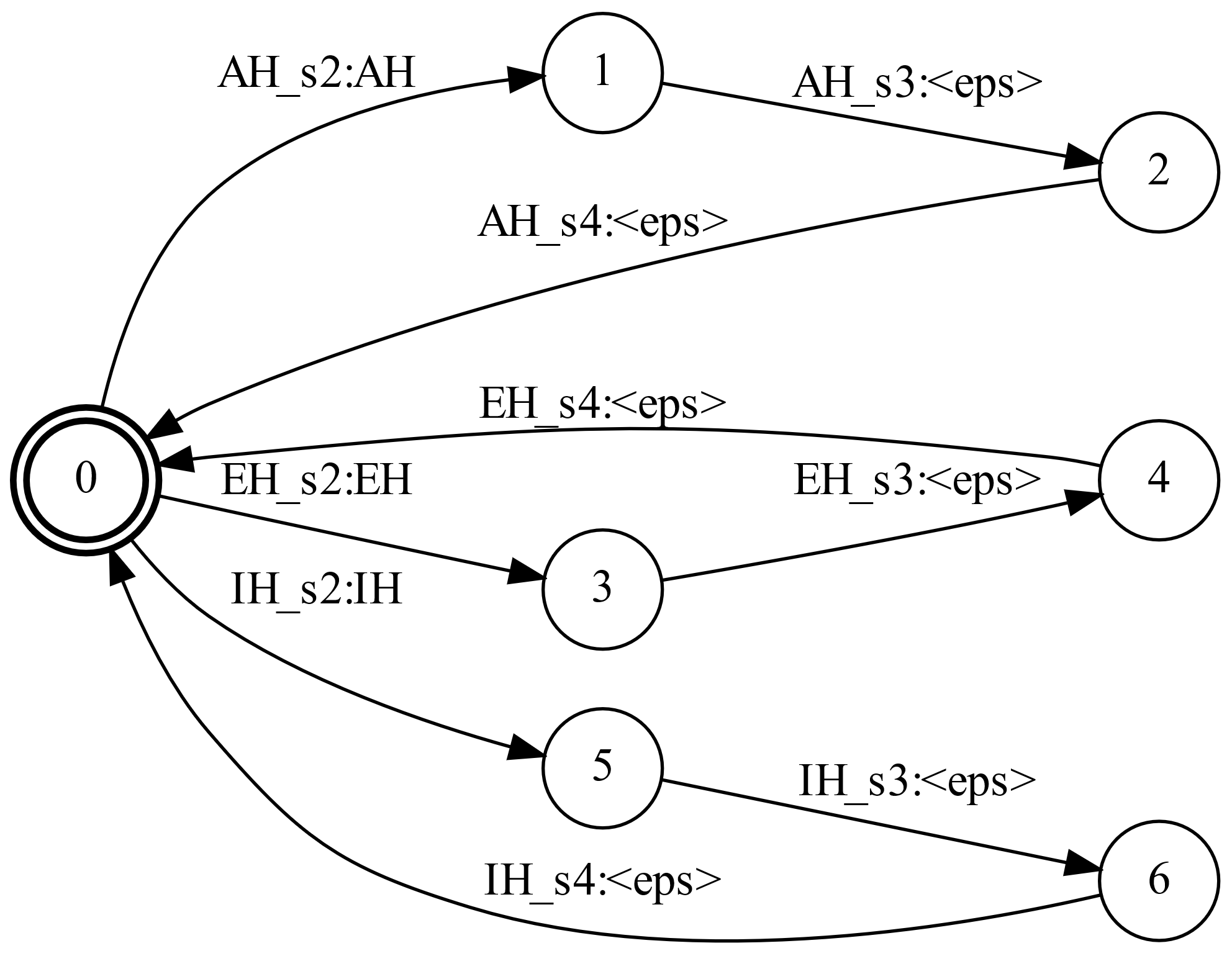 图:H示例
图:H示例
WFST和WFSA
WFSA是一个特殊的FSA:对于每一个接受的序列都会赋予一个得分。也就是每个它接受的字符串都会映射到一个得分。发音词典对应的FST可能会词的每一个发音变体都赋予不同的权重。而一个语言模型的FST对于它接受的每一个词序列都会赋予一个相对的概率。
n-gram WFST
n-gram语言模型,可以近似的用WFSA来表示,为了简化,对于训练数据中不存在的n-gram由于backoff得到的概率会使用特殊的跳转来表示。我们下面来看一个简化版的语言模型:
-0.03195206 half an hour # 这是trigram概率
-1.020315 half an -1.11897 # 这是回退概率
-1.172884 an hour # 这是bigram概率
-1.265547 an old # 这是bigram概率
-1.642946 an instant # 这是bigram概率
-1.698012 an end # 这是bigram概率
用WFST来表示如下图所示:
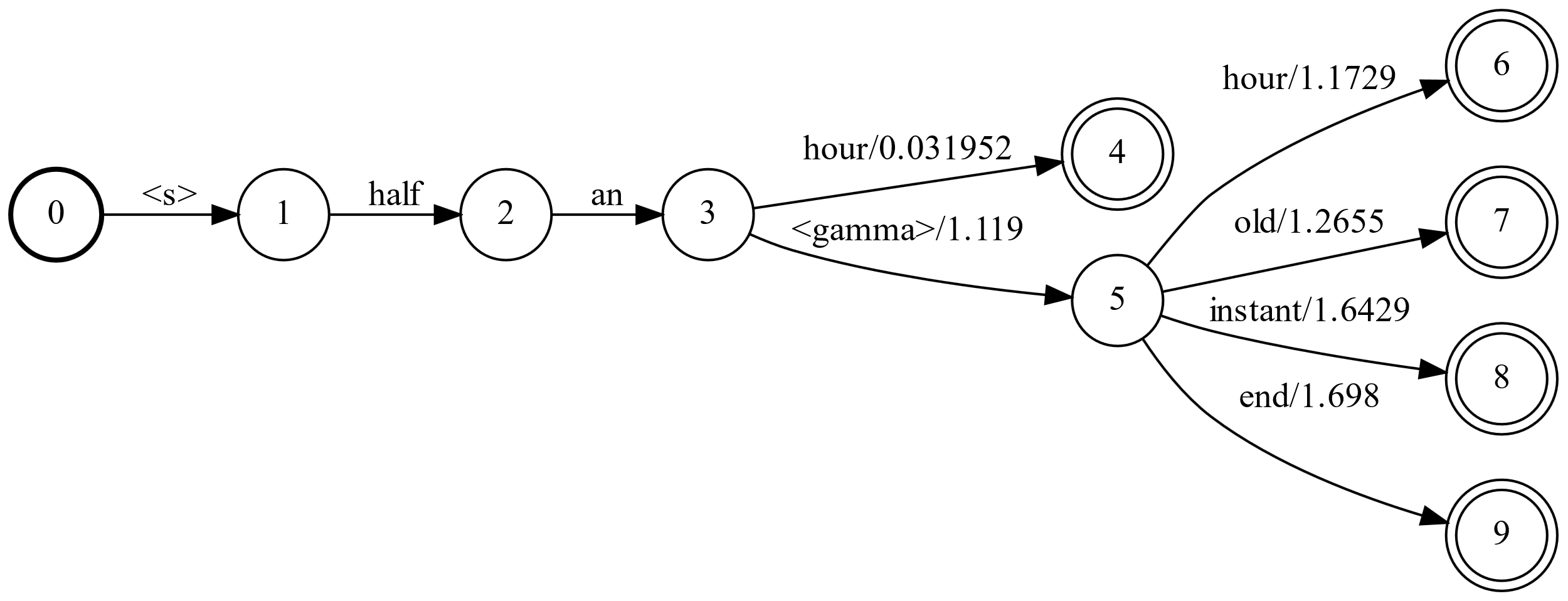 图:n-gram的WFST
图:n-gram的WFST
在上图中,前3个状态表示开始、half和an。因为训练数据中有”half an hour”,因此从状态3到4编码了$p(hour \vert \text{half an})$。状态3表示context是”half an”,而状态4表示context”an hour”。
即使训练数据中没有”half an old/instant/end”,但是根据backoff,它们仍然有一定的概率。因此从3有一条backoff的边,概率比较小(-1.11897),然后进入状态5,接着根据bigram可以计算bigram的概率。
比如要计算句子P(old |half an)的概率,因为没有trigram “half an old”,所以回退到$P_{\text{backoff}}(\text{half an}) \times P(old \vert an)$,因此路径就是3->5->7。
WFST的复合(Composition)
最后我们关注一下FST的复合算法。和代数函数的复合类似,FST的复合也是通过把一个FST的输出作为另一个的输入来合并两个FST。如果第一个WFST把字符串A映射为B并且weight是x,第二个把B映射为C并且weight是y,则复合后的FST把A映射为C并且weight是x+y。
解码图(Decoding Graph)
我们需要一个解码图,它能把声学模型状态序列映射成词序列。
在第二和第三个模块,我们知道语音识别的问题可以使用WFST来编码如下模型:
-
文法(Grammar)G可以是一个FSA,它编码了所有可以接受的字符串;也可以是一个WFSA,它可以编码n-gram语言模型。
-
发音词典L是一个WFST,它把phone的序列(包括消歧符号)映射为词序列。
-
HMM transducer H,它把HMM状态(senone标签)序列映射为HMM模型名字(phone或者triphone)的序列。
除此之外,还有一个WFST把上下文相关的triphone映射为上下文无关的phone序列,这通常叫做C,不过本课程不讨论。
为了把声学模型的状态序列映射为词序列,需要依次对输入用H、C、L和G来处理。这可以在解码的时候来完成,但是这些WFST的复合可以离线先做好,这样解码器就会变得简单。
下图是HCLG复合之后的一个简单例子:
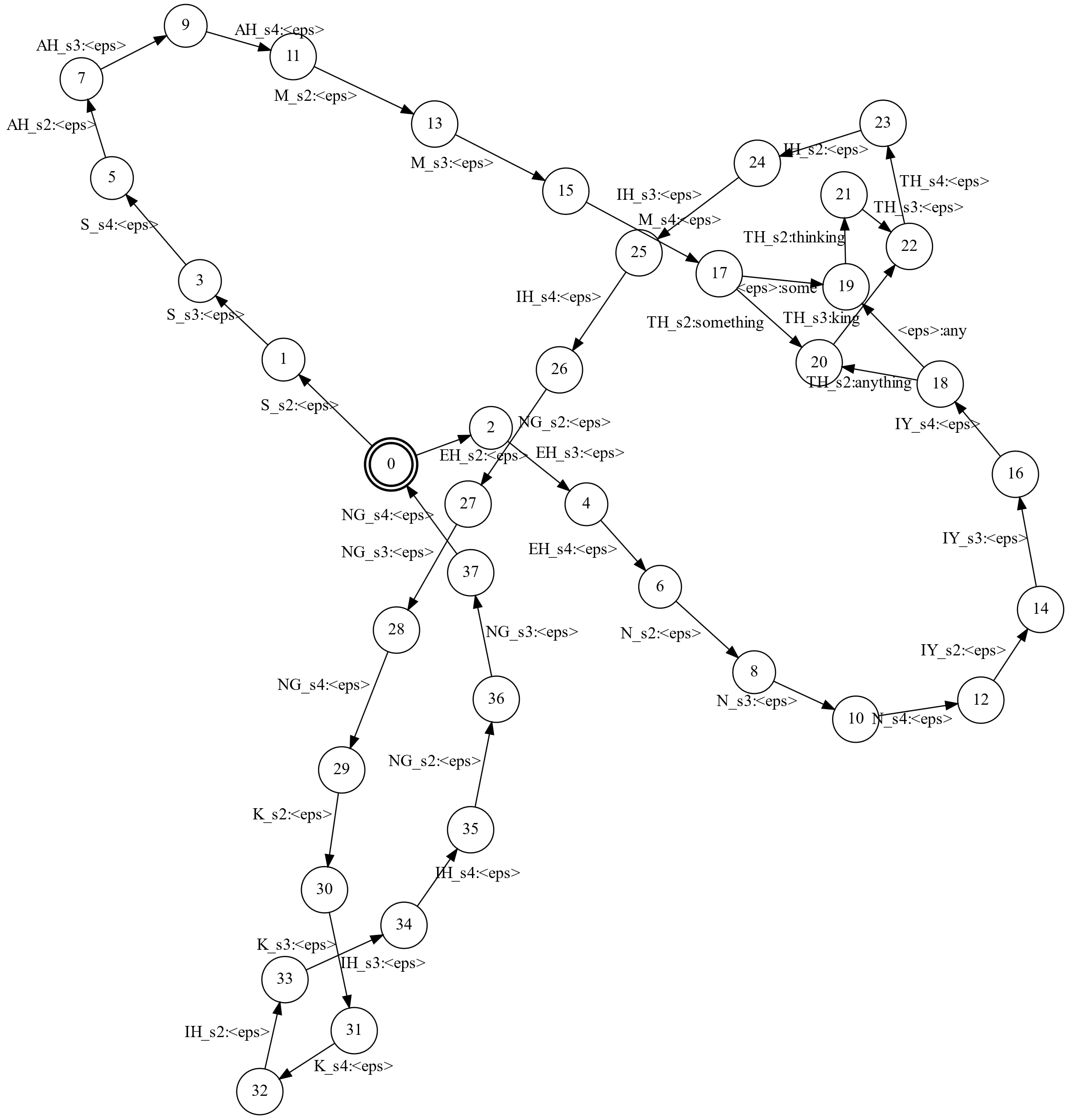 图:HCLG复合的例子
图:HCLG复合的例子
这个图看起来有一点复杂,我们可以看一条路径,如下图红线所示,它识别”some thinking”,请读者验证这条路径的输入是”S_s2 S_s3 S_s4 AH_s2 AH_s3 AH_s4 M_s2 M_s3 M_s4
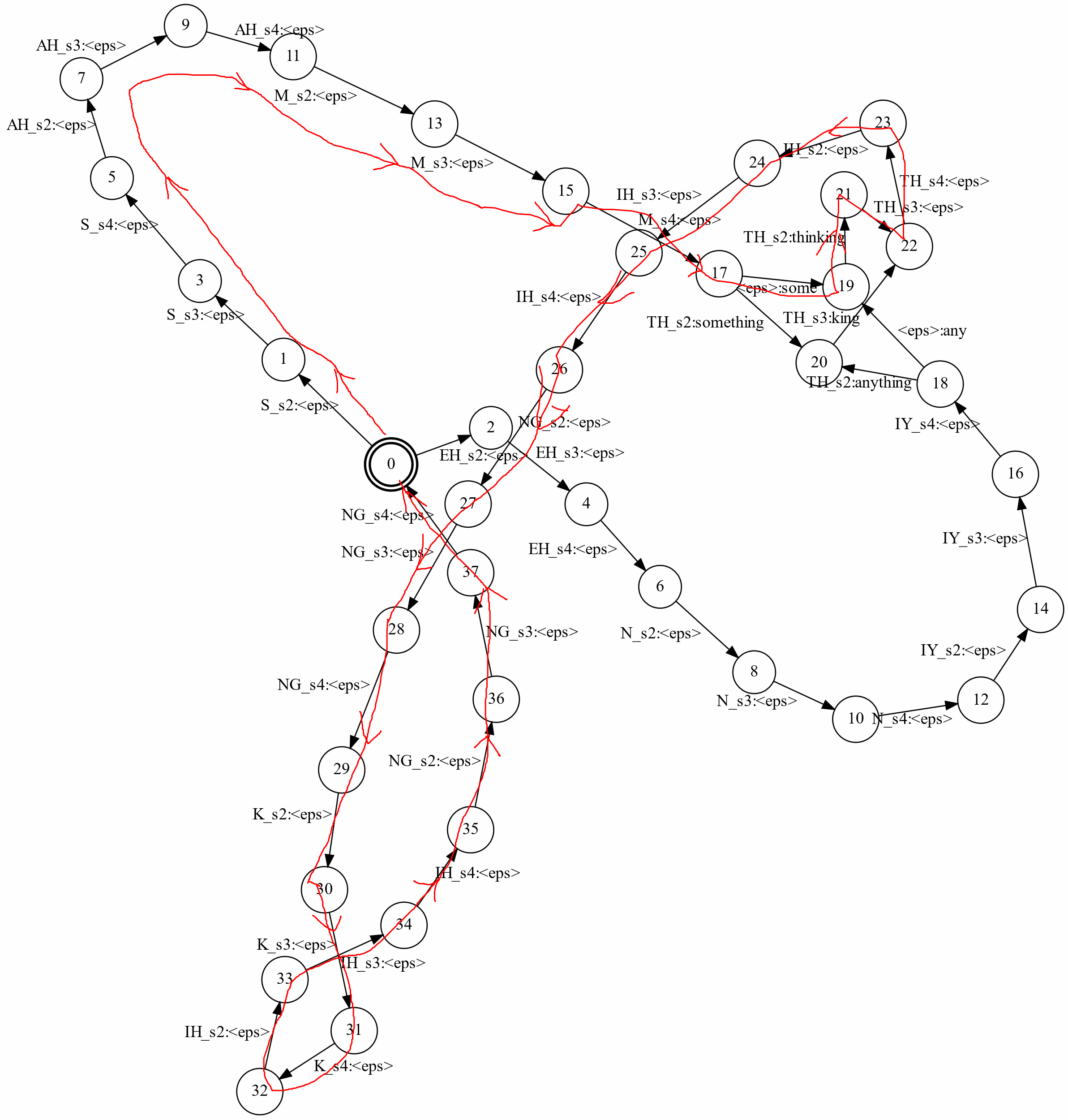 图:some thinking的路径
图:some thinking的路径
最佳的实践是从右往左复合(复合是满足结合律的,因此也可以从左往右进行),每复合一次之后都进行确定化和最小化。在下面的实验作业部分,我们提供已经复合好的$H \circ C \circ L$,剩下要做的就是创建G然后复合得到$H \circ C \circ L \circ G$。
回忆一下语言模型G的输入包含特殊的backoff符号。HCL会传递这些复合。因此,HCLG的输入复合里有这些特殊符号。此外L包含消歧符号,因此HCLG的输入也包含这些符号。因为解码器不需要这些信息,因此它们通常被替换成$\epsilon$符号,表示遍历这些边不影响输入字符串。
搜索
语音识别解码的过程就是寻找最大化语言模型得分加声学模型得分的词序列。这个词序列对应的声学状态的序列会被声学模型打出一个声学得分,而词序列也会被语言模型打出一个得分,我们的目标就是在所有的词序列里找出这两个得分相乘(取对数后变成相加,另外会加权一下)最高的词序列。
这是一个在解码图中的路径搜索算法,而一条路径的得分是解码图给它的得分(HCLG是把状态序列映射为词序列)以及声学模型的得分(状态序列下出现观察序列的概率)。这个搜索算法可以使用动态规划来寻找最短路径。因为如果最优解(最短路径)在T时刻处于状态S,那么这条路径从开始到T时刻结束于状态S也一定是一个(小问题的)最优解,因此它具有最优子结构,所以可以使用动态规划求解。
典型的帧同步的(frame synchronous)beam搜索算法分为3个阶段。对于每一个时刻(一帧)t,
- 对于每一个partial hypothesis处理非$\epsilon$的输入符号
- 因此,新产生的partial hypothesis一定有t个输入符号
- 如果两个partial hypothesis都进入同一个状态,那么只保留得分最高的那个
-
去掉得分过低的partial hypothesis。这通常是只保留得分最高的K个hypothese或者只保留得分比最高得分相差不大的那些hypotheses(这个差值叫做Beam width)。
- 然后对于每一个新产生的partial hypothesis,处理$\epsilon$的输入符号
- 同样的,如果两个hypothesis进入同一个状态,也只保留得分高的那个
这里重要的参数是裁剪的beam width或者最高得分的K。beam width的作用是把与当前最高得分相差太大(因此看起来不太有希望是最短路径)的那些路径裁剪掉。而K是只保留得分最高的K条路径。
当然有可能最短路径在早期的某个t时刻分很低从而被裁剪掉。这就会导致搜索出的路径不是最优路径。这种情况出现的话就叫做出现了搜索错误。我们可以增大beam width或者K来减少搜索错误,但是这会让搜索变慢。
Lab 5
虽然前面的内容简单的介绍了基于WFST的解码器的基本原理,但是(至少对于没有太多语音识别经验的读者来说)我们还是很难理解它,而要读懂这里的StaticDecoder.py就更加困难的。因此在介绍代码前我会再补充一些相关的知识,读者也可以阅读这些补充资料。
最出名的是Speech Recognition with Weighted Finite State Transducers。因为文件名叫做hbka.pdf,所以很多人叫它hbka。这是Springer Handbook,作者Mohri等人是WFST算法的主要研究者,因此这篇文章几乎是必须要阅读的。但是这篇文章更多偏于WFST的理论,因此如果想仅仅阅读它就能把解码器写出来还是很有难度的(除非之前很熟悉其它的非WFST的解码器的人)。
因此这里再推荐一本书和一篇论文,后面的补充资料也大多来自于这本书和这两篇论文。
Speech Recognition Algorithms Using Weighted Finite-State Transducers这本书写得比较通俗易懂,尤其是第二章对于没有编写解码器经验的读者非常有帮助。读者如果在学校的话,一般的图书馆会有ieee的数据库,那么可以通过这个链接。如果都不能下载的话请看看CSDN下载(我只能帮到这里了!)。
Investigations on Search Methods for Speech Recognition using Weighted Finite-State Transducers是一篇博士论文,写得更加深入一些,但是相对于前面的书来说就不会那么体系化了,不过仍然非常值得一读。
- 显示Disqus评论(需要科学上网)