这个模块介绍语言模型。读者可以参考语言模型教程。更多本系列文章请点击微软Edx语音识别课程。
目录
Introduction
这个模块介绍语言模型的基本概念——也就是语音识别系统计算先验概率$P(W)$的部分。回忆一下语音识别系统的基本公式,我们组合声学模型概率$P(O \vert W)$和语言模型概率$P(W)$来寻找最可能的假设:
\[\hat{W} = argmax_{W} P( O | W) P(W)\]因此,语言模型(或者简称LM)包含了词序列的先验概率,即使我们没有听到实际的语音也可以计算它。传统的文法(比如正则文法、上下文无关文法)通过硬编码的规则来定义哪些句子是合乎语法的哪些是不合乎的(就像C语言编译器检查C程序是否合乎语法一样),现在更主流的方法是使用概率的模型,它会给更可能的句子更高的概率而不太可能的句子较低的概率,但是即使很罕见的句子也可能有极小的概率(因为没有人知道说话人实际会说什么东西,他甚至会说完全不合乎语法的句子)。而且统计模型的这些概率不是有语言学专家来指定这些概率。和声学模型一样,我们通过大量的数据来估计模型的参数。因此我们通过实际的训练数据的统计来觉得哪些词序列在某个特定的语言、场景和应用下更加可能。
注意:在语言模型里我们说的句子是一段utterance的词序列,它不一定是完全语法正确的句子,甚至不一定完整。
N-gram语言模型
Vocabulary
我们需要计算每个句子的概率,一个句子就是一个词的序列:
\[W = w_1 w_2 \ldots w_n\]这里n是词的个数,理论上是没有上限的。为了简化问题,我们首先假定词的个数是有限的,也就是LM的词典是一个有限集合。注意:LM的词典也是语音识别系统的词典——我们不可能识别一个语言模型里没有的词。
词典之外的词叫做未登录(OOV)词。如果出现了一个OOV,那么至少会出现一个语音识别错误,因此我们需要选择合适的词典来尽量减少OOV。一个常见的策略是从数据中估计每个词出现的先验概率,然后选择概率高的词。也就是说,我们选择训练数据中出现频率最高的那些词。词典越大,OOV就越小,识别的准确率(可能,但不一定,因为加入很罕见的词反而会降低准确率,因为这些罕见可能会和正常的词混淆)会更高;但是太大的词典会导致模型过大,从而训练和解码速度变慢。
马尔科夫分解和N-Gram
即使词典是有限的,我们仍然会面对句子长度(理论上)无限的问题,因此我们不可能穷尽所有的可能(类似类似的概率分布函数)。而且即使我们理论上可以这么做,其效果也是很差的,因为很多句子在训练数据中不可能一字不差的出现。
我们可以使用和声学建模类似的trick来解决这些问题:使用链式法则把句子的概率分解成很多条件概率的乘积,然后使用马尔科夫假设把条件(历史)限制在有限的长度上。
\[P(W) = P(w_1) \times P(w_2 |w_1) \times P(w_3 | w_1 w_2) \times \ldots \times P(w_n | w_1 \ldots w_{n-1})\]限制我们使用一阶的马尔科夫假设,假设一个词的概率只依赖于之前的一个词(history):
\[P(W) = P(w_1) \times P(w_2 |w_1) \times P(w_3 | w_2) \times \ldots \times P(w_n | w_{n-1})\]注意每个词值依赖于前面的那个词,也就是我们使用了一阶的马尔科夫模型。但是在语言模型里,我们不太喜欢使用这个术语,在这里我们喜欢叫它bigram模型,英文在统计的时候只考虑相邻两个词。类似的,二阶马尔科夫模型对应trigram,它是根据前面两个词来预测当前词。
上面这种方法的推广就是N-gram模型,也就是每个词依赖于前面的N-1个词。从trigram的效果要比bigram好很多,但是再增加N效果就不那么明显了,而且模型的大小(参数)增加的很多。因此在实践中我们很少使用4-gram或者5-gram。在本模块的实验里我们使用trigram,而在其它部分为了简化概念我们大部分时候使用bigram为例子。但是这些理论对于N-gram都是适用的。
句子开始和结束
为了让我们的N-gram语言模型能够对所有有限长的句子都赋予一个概率,我们面临一个小问题:怎么建模句子的结束?一种办法是我们有一个模型来建模句子的长度n,但是更加简单的办法是引入一个特殊的句子结束标签</s>来表示句子的结束。从生成模型的角度来说,我们先预测第一个词,然后用第一个词预测第二个词(假设是bigram),然后用第二个词预测第三个词,……,直到遇到</s>,我们结束这个过程。这样的模型能够保证所有可能句子的概率加起来是1,也就是一个合法的概率分布。
但是前面一个问题就是预测第一个词没有history,虽然我们记为$p(w_1)$,但是它不是词$w_1$出现的概率,而是词$w_1$出现在第一个位置的概率!为了统一记号,我们引入一个特殊的句子开始标签<s>,这样记为$p(w_1 \vert <s>)$,它表示词$w_1$出现在<s>后的概率,也就是$w_1$出现在第一个位置的概率。
有了这两个特殊的”词”,我们的概率公式就更加简单:
\[P(W) = P(w_1 | <s>) \times P(w_2 |w_1) \times \ldots \times P(w_n | w_{n-1}) \times P(</s> | w_n)\]N-gram的概率估计
N-gram的条件概率可以简单的统计其相对频率来得到。假设$c(w_1 \dots w_k)$是k-gram $w_1 \dots w_k$出现的频次。那么”bites”出现在”dog”之后的概率为:
\[P(bites| dog) = { c(dog\ bites) \over c(dog) }\]请读者证明:
\[P(bites | dog ) + P(bite | dog) + P(wags | dog) + \cdots\]的和为1,也就是dog为条件的所有概率加起来是1,从而保证这确实是一个合法的概率分布。
更加一般的,k-gram的概率可以使用如下公式来估计:
\[P(w_k | w_1 \ldots w_{k-1}) = { c(w_1 \ldots w_k) \over c(w_1 \ldots w_{k-1})}\]N-gram的平滑和打折
上面的相对频次估计有一个很严重的问题:在训练数据中没有出现过的N-gram的概率是0。训练数据是有限的,它不可能覆盖所有可能的N-gram。此外对于语音识别系统来说,说话人一边思考一边说话,很多都不完全合乎语法。
因此我们需要给那些没有在训练数据中出现过的N-gram非零的概率,这可以通过语言模型平滑来实现。这是语言模型研究的一个重要子课题,wiki列举了常见的平滑方法,这些方法大部分都在SRILM里又被实现。我们这里只讨论一种方法——Witten-Bell平滑。选择它的原因有二:首先它比较容易理解和实现;其次和其它更复杂的方法相比它不需要那么多对数据分布的附加假设,因此它也更加鲁棒。
Witten-Bell平滑的基本思想是把未出现过的词也加入计数。那么有多少”未出现”过的词呢?这似乎有的困难:它都没出现,我怎么知道呢?Witten-Bell平滑是这么处理的:在训练数据里,第一次出现某个词前,它是未出现过的。因此对于训练数据来说,未出现过的词的个数就是训练数据中出现的词的个数,因此对于1-gram,我们可以这样估计其概率:
\[\hat{P}(w)={c(w) \over c(.)+V}\]这里$c(w)$是词w出现的词数,而$c(.)$是所有词出现的词数和(也就是训练数据的长度),V是第一个词出现的词的个数,也就是词典的大小。和未平滑相比,分母多了一个V,因此所有出现过的词的概率加起来是小于1的。因此这种平滑叫做打折(discount),把见过的n-gram的概率打个折扣,多出来的概率分给未见过的词。未见过的词的概率是:
\[P(unseenword)={V \over c(.)+V}\]注意:未出现的词有很多个,它们的概率加起来是上面的概率,而不是每一个概率都是上面的值(否则加起来大于一了)。下一节我们会介绍未出现过的词怎么分配这些概率。
从1-gram推广到k-gram是类似的:
\[\hat{P}(w_k|w_1…w_{k−1}) = {c(w_1…w_k) \over c(w_1…w_{k−1})+V(w_1…w_{k−1}⋅)}\]其中$c(w_1…w_{k-1})$是k-1 gram出现的次数,而$V(w_1…w_{k−1}⋅)$是$w_1…w_{k−1}$之后的不同词的个数。
比如训练数据为:
a b c a b d a b d
则$c(ab)=3$,而$V(ab⋅)=\vert {c, d, d} \vert=2$。也就是ab之后出现的词为[c,d,d],不同的词只有[c,d]两个。
N-gram的回退(back-off)
前面通过打折可以留出一部分概率给未见过的N-gram使用,但是未见过的N-gram很多,它们怎么分配这些概率呢?这是本节要讨论的话题。
一种最常见的想法就是平均的分配,比如我们使用前面介绍的Witten-Bell方法,考虑trigram,假设history “white dog”,而且假设训练数据中只出现过”white dog barks”一次,除此之外没有任何地方出现过”white dog”。如果不平滑,则$\hat{P}(barked \vert white\ dog)=1$,而其它的$\hat{P}(\text{其它词} \vert white\ dog)=0$。使用了Witten-Bell打折之后,
\[\hat{P}(barked|white\ dog) = {c(white\ dog\ barked) \over c(white\ dog)+V(white\ dog⋅)} = {2\over2+1} = {2\over3}\]因此还剩下1/3的概率分给$\hat{P}(\text{其它词} \vert white\ dog)$。最简单的就是平均分配,比如处理barks之外还有10个词,那么每个词分到的概率就是1/30,也就是$\hat{P}(\text{其它词} \vert white\ dog)={1 \over 30}$。这显然不太好,另外一个很容易想到的就是根据这10个词的词频(也就是1-gram)来分配,这个想法的理由是:某个词出现的频率高,那么它就应该多分一些概率。但是它有一个问题,比如the是一个高频词,但是在history为”white dog”的时候它出现的概率并不大;而eat虽然不高频,但是它出现在”white dog”的后面的Giallo更大一些。
因此我们在分配概率的时候要考虑其history(context),如果”white dog”后面出现the的概率大,那么它分配的概率就大。但是训练数据中并没有”white dog the”,那怎么办呢?这里可以使用reduced context,我们把history “white dog”变成”dog”,也就是我们根据$\hat{P}(the \vert dog)$和$\hat{P}(eat \vert dog)$的来分配这1/3的概率。如果”dog the”还没有出现呢?我们的$\hat{P}(⋅\vert dog)$也会打折,这样$\hat{P}(the \vert dog)$还可以从这里打折的概率里用1-gram $\hat{P}(the)$再次分配一个(很小)的概率。这个过程是递归的:如果3-gram没有出现,那么用2-gram从打折的概率那里分配(较小的)概率,如果2-gram还没有,那么就从2-gram的打折里用1-gram去分配(更小的)概率。这种方法就叫回退(backoff)。
\[{\hat{P}}_{\text{bo}}\left( w_{k} \right|w_{1}\ldots w_{k - 1}) = \ \left\{ \begin{matrix} \hat{P}\left( w_{k} \right|w_{1}\ldots w_{k - 1}),\ \ \ c(w_{1}\ldots w_{k}) > 0 \\ {\hat{P}}_{\text{bo}}\left( w_{k} \right|w_{2}\ldots w_{k - 1})\ \alpha(w_{2}\ldots w_{k - 1}),\ \ c\left( w_{1}\ldots w_{k} \right) = 0 \\ \end{matrix} \right.\\]\(\hat{P}_{bo}\)是所有N-gram的打折后的概率。如果某个N-gram在训练数据中出现过,那么就可以使用打折(包括Witten-Bell)方法计算其概率。如果没有出现,那么把history变短,计算\(\hat{P}_{bo}(⋅ \vert w_2…w_{k−1})\),然后乘以\(\alpha(w_{2}\ldots w_{k - 1})\),也就是\(w_{2}\ldots w_{k - 1}\)这个history打折多出来的那些概率。注意$\alpha$并不是自由的参数,所有的N-gram的概率估计出来之后,它就固定了,它只是一个归一化用的常量。
语言模型的评价方法
给定两个语言模型A和B,我们怎么判定哪个更好呢?直觉上讲,对于一个测试数据集,如果模型A总是比B给出更高的概率,那么A就比B好,因为它预测的更准。假设测试数据的一个句子为$w_{1}\ldots w_{n}$,则模型预测的概率为:
\[P\left( w_{1}\ldots w_{n} \right) = P\left( w_{1}| < s > \right) \times P\left( w_{2} \right|\ w_{1}) \times P\left( w_{3} \right|\ w_{2}) \times \ldots \times P( < /s > \ |\ w_{n})\]因为这个概率很小,相乘很容易下溢,因此我们对它取log:
\[\log{\ P(w_{1}\ldots w_{n})} = \log{P(w_{1}| < s > )} + \log{P\left( w_{2} \right|\ w_{1})} + \ldots + \log{P( < /s > \ |\ w_{n})}\]上面的对数概率通常也叫对数似然函数,因为概率总是小于1的,因此对数似然总是小于0,我们取负号把它变成正数,然后在除以句子长度求平均,就得到:
\[- \frac{1}{n}\log{P(w_{1}\ldots w_{n})}\]上面的这个指标就是熵。假设我们用一些bit来编码所有的word,为了减少一个句子的编码后的bit的大小,我们会用更少的位来编码高频的词,用更长的位来编码低频的词。而熵就等于最优编码方法编码这个句子的平均bit位数。
另外一种衡量模型好坏的指标是词概率的平均倒数,也就是perplexity(PPL)。因此如果平均来说每个词的概率是1/100,则PPL是100。它的计算公式为:
\[\sqrt[n]{\frac{1}{P(w_{1}\ldots w_{n})}} = {P(w_{1}\ldots w_{n})}^{- \frac{1}{n}}\]如果我们对上式取log,就会发现它正好等于熵。因此$PPL=2^{\text{熵}}$。因此,对于这几个指标和模型的好坏关系如下:
似然概率越大 ↔ 熵越小 ↔ PPL越低 ↔ 模型越好
似然概率越小 ↔ 熵越大 ↔ PPL越高 ↔ 模型越差
对于N-gram模型的处理
剪枝(pruning)
N-gram语言模型会存储训练数据里的N-gram的统计信息,每一个N-gram的信息都是模型的一个参数。这样随着训练数据的增加,出现的N-gram的数量也会迅速增大。如果某个N-gram的概率可以由回退机制比较好的近似,那么我们是可以删除掉这个N-gram从而减少参数的个数。
那么删除哪些N-gram呢?我们可以使用熵(或者PPL)来指导这个过程。如果删除前后熵没有太大变化(没有超过一个阈值),那么就可以删除。删除一个N-gram后模型需要重新归一化(重新计算回退系数)。
为了上算法更加高效,我们不需要使用一个单独的测试集来估计熵(的变化)。我们可以使用模型本身,它已经包含了计算上的全部信息。这样就可以实现一个高效的剪枝算法,读者可以参考Entropy-based Pruning of Backoff Language Models。
插值(Interpolation)
假设我们训练了两个语言模型,它们计算的概率分别是$P_1$和$P_2$。我们怎么融合这两个N-gram模型来得到更好的模型呢?一种办法是把这两个模型的训练数据混合到一起重新训练一个模型。这显然不太方便,而且还可能带来新问题。比如这两个训练集的大小差别很大,一个很大一个很小,那么很小的数据集基本就被淹没了。这在实际情况中经常遇到:我们有很多通用的数据,但是我们的领域数据很少。从任务的角度来说,领域的数据更加重要。显然我们需要赋予领域的数据更大的”权重”。
因此更好的办法是直接把两个模型通过插值来融合。插值就是我们加权平均它们的概率:
\[\hat{P}\left( w_{k} \right|w_{1}\ldots w_{k - 1}) = \lambda\ {\hat{P}}_{1}\left( w_{k} \right|w_{1}\ldots w_{k - 1}) + (1 - \lambda)\ {\hat{P}}_{2}\left( w_{k} \right|w_{1}\ldots w_{k - 1})\]参数$\lambda$控制模型的相对重要性。如果它接近1,则第一个模型占据主导地位;反之它接近0则第二个模型更加重要。$\lambda$的最优值是一个超参数,我们可以使用一部分预先留出来的数据来估计它的最优值。
我们也可以对多于两个语言模型进行插值:M个模型需要M个权重$\lambda_{1},\ \lambda_{2},\ldots,\ \lambda_{M}$,同时需要保证$\lambda_{1} + \ \lambda_{2}, + \ \ldots + \ \lambda_{M} = 1$。它们加起来等于1的目的是保证插值后的概率分布是一个合法的概率分布函数。
模型合并
虽然模型插值不需要重新训练模型,但是它有一个很大的缺点:需要保存多个模型,这意味着需要更大的磁盘和内存,并且计算速度也更慢。
幸运的是,对于backoff的N-gram模型的插值,我们可以把它们合并成一个模型,而且合并后的模型的概率能很好的近似插值的模型。合并的步骤为:
for k=1,...,N:
for all ngrams w1…wk
把w1…wk插入新模型(合并后的模型)
根据插值公式计算P^(wk|w1…wk−1)
end
对于新的模型重新计算k-1的回退系数
end
高级模型
类(class-based)语言模型
本节我们讨论一些语言模型的高级话题。语言模型的方法在不断演化,这是一个很active的研究方向。根据Estimation of Gap Between Current Language Models and Human Performance的估计,目前最好模型的PPL仍然比人类要差(大)两到三倍,因此还有很长的路要走。
N-gram模型的一个很大缺点就是它把所有的词都看成完全不同的东西。因此,对于某一个词,模型需要足够多的训练数据才能比较准确的估计其概率。但是人类不是这样使用语言的。我们知道’Tuesday’和’Wednesday’在句法和语义上都有某种类似的属性。即使训练数据中可能没有出现过’store open Tuesday’,但是因为训练数据中出现过’store open Wednesday’,所以我们还是能够给前者比较高的概率。也就是说,我们需要考虑词的这种相似性。
类语言模型把类似的词组成词类,然后计算N-gram统计量的时候使用词类标签来替代词。因此如果我们定义一个’WEEKDAY’的词类,它包含’Monday’, ‘Tuesday’, …, ‘Friday’,则N-gram ‘store open Tuesday’会被当成’store open WEEKDAY’。因此:
\[P(\text{Tuesday}|\text{store open})=P(\text{WEEKDAY}|\text{store open})P(\text{Tuesday}|\text{WEEKDAY})\]而类成员概率(class membership probabilities)$P(\text{Tuesday} \vert \text{WEEKDAY})$可以从训练数据中估计,也可以根据经验设置为平均值(因为我们先验的认为周一和周日出现的概率是相同的)。
那么怎么得到词类呢?一种是利用先验知识,通常是应用的领域知识。比如我们为一个旅行的app做一个语言模型,我们需要识别目的城市的名字(比如’Tahiti’, ‘Oslo’)、航班信息以及周几(周一到周日)。不管训练数据多大,它也不可能出现所有的城市和航班信息。因此我们可以根据先验知识平均的认为每个城市的类成员概率都是一样,也可以根据城市的热度来按比例的分配这个概率(而不是训练数据的概率)。有的实体是两个及其以上的词,比如’Los Angeles’,这是需要修改类语言模型,读者可以参考Word-Phrase-Entity Language Models: Getting More Mileage out of N-grams。
另一种方法就是纯数据驱动的方法,而不需要人或者领域的知识。比如我们可以先定义多少个类别,然后搜索所有的词和类别的映射关系(每一种映射就是一种聚类),然后找出PPL最小的那种聚类。当然穷举的计算复杂度是不可行的,有一些算法来解决计算的问题,读者可以参考Class-Based n-gram Models of Natural Language。
神经网络语言模型
神经网络的方法在很多领域成为主流,包括前面我们介绍的声学模型。类似的,神经网络也可以用于语言模型建模,并且如果有足够多的数据,它的效果比N-gram更好。
神经网络语言模型可以克服N-gram模型的两个缺点。第一个缺点就是无法泛化到类似的词,比如即使训练数据中”store open Wednesday”出现很多次,但是只要”store open Tuesday”没有在训练数据中出现,那么它的概率就很小。我们前面看到类语言模型尝试解决这个问题,但是它又带来一个新问题:怎么定义词类。最早的神经网络语言模型来自2003年的论文A Neural Probabilistic Language Model,因为这种网络是前馈神经网络,所以这个语言模型也叫作前馈网络语言模型。它通过引入一个Embedding层来把一个离散的词标签映射到一个稠密的向量空间,从而实现相似的词可以共享类似的上下文的目的。
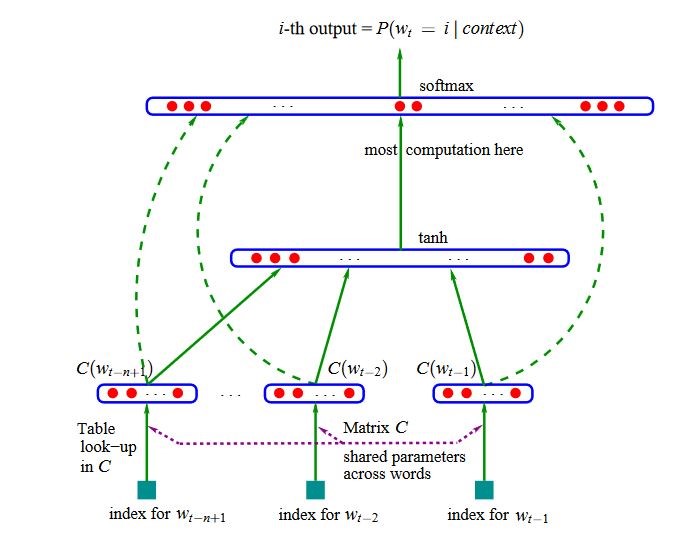 图:神经网络语言模型
图:神经网络语言模型
如上图所示,神经网络的输入是当前词的前N-1个词,每个词是one-hot的编码。输出是预测当前词的概率。它的关键是输入的one-hot的向量通过一个所有词都共享的Embedding矩阵把这个高维稀疏的one-hot向量变换成低维稠密的向量。这样的好处是如果两个词经常出现在类似的上下文(比如Wednesday和Tuesday),那么它们的向量也就是类似的。虽然在训练数据中”store open Tuesday”很少出现,但是在其它的时候这两个词的上下文很类似,因此它也能学到Wednesday和Tuesday的向量是类似的,因此store open预测Wednesday和Tuesday的概率也是差不多的。通过上面的共享Embedding矩阵,就能解决N-gram的第一个问题。
N-gram的第二个问题就是不能依赖太长的历史,比如句子”I was born in France, ………………….., So I can spoken fluent (French/English/Chinese)”。如果只看很短的历史”spoken fluent”,那么这三个词的概率是差不多的,但是如果看到更久一起的France,那么就知道French的概率会更大一些。
前面的神经网络语言模型和N-gram是类似的,只能看前N-1个词。为了解决这个问题,我们可以使用循环神经网络。读者可以参考循环神经网络简介。我们这里就不详细介绍了。
Lab
环境
本实验需要在shell(bash)环境下使用SRILM来构建N-gram语言模型。本实验构建的语言模型会在后面的解码部分被用到。
我们首先进入到Lab4的目录:
cd M4_Language_Modeling
$ pwd
/home/lili/codes/Speech-Recognition/M4_Language_Modeling
设置环境变量,从而可以使用SRILM的命令:
export PATH=$PWD/srilm/bin/i686-m64:$PWD/srilm/bin:$PATH
如果是Cygwin(windows),请使用:
export PATH=$PWD/srilm/bin/cygwin64:$PWD/srilm/bin:$PATH
为了测试环境是否ok,可以执行如下命令,如果没有错误信息,那么就是好的。
$ ngram-count -write-vocab -
-pau-
</s>
<s>
<unk>
$ compute-oov-rate < /dev/null
OOV tokens: 0 / 0 (0.00%) excluding fragments: 0 / 0 (0.00%)
OOV types: 0 / 0 (0.00%) excluding fragments: 0 / 0 (0.00%)
除此之外,我们还需要wget、sort、head、wc、sed、gawk和perl,这些工具一般系统已经装好了,没有的话请自行安装。
准备数据
我们讲使用训练声学模型的数据的transcript,其中dev和test分布用来作为训练语言模型的开发集和测试集。因为我们最终要识别的录音是dev和test的录音,因此用它们的文本作为语言模型的开发集和测试集是非常合适的。注意:语言模型的训练不需要”标注”的数据,它只需要一个一个的句子就行了,因此我们可以很容易的获取大量的训练数据,但是这些训练数据的领域可能和我们语音识别应用的领域可能不同。而应用领域的数据通常比较少,后面的实验会介绍一些方法来解决这个问题。
统计data下文件的行数
$ ls data/
ami-dev.txt ami-test.txt ami-train.min3.vocab ami-train.txt dev.txt test.txt
$ wc -wl data/dev.txt data/test.txt
466 10841 data/dev.txt
261 5236 data/test.txt
727 16077 总用量
我们会使用data/dev.txt来作为语言模型的开发集,而data/test.txt作为测试集。
查看这些文件
$ head -n 3 data/*.txt
==> data/ami-dev.txt <==
uhhuh
uh do we know if there will be a lot of people coming across the hall in terms of security stuff if we can i mean my idea is to put the photocopier and the fax in the hall
um
==> data/ami-test.txt <==
you mean maybe you should break the wall between the men's room and the women's room sorry
==> data/ami-train.txt <==
okay
does anyone want to see uh steve's feedback from the specification
right
==> data/dev.txt <==
a laudable regard for the honor of the first proselyte has countenanced the belief the hope the wish that the ebionites or at least the nazarenes were distinguished only by their obstinate perseverance in the practice of the mosaic rites
their churches have disappeared their books are obliterated their obscure freedom might allow a latitude of faith and the softness of their infant creed would be variously moulded by the zeal or prudence of three hundred years
yet the most charitable criticism must refuse these sectaries any knowledge of the pure and proper divinity of christ
==> data/test.txt <==
when we took our seats at the breakfast table it was with the feeling of being no longer looked upon as connected in any way with this case
instantly they absorbed all my attention though i dared not give them a direct look and continued to observe them only in the glass
yes and a very respectable one
文件很大,因此我们用head命令查看前几行。
我们会发现所有的数据都是小写的,而且没有标点。这是因为说话的时候不会说标点,另外没有首字母大小这些的目的也是为了与之前的发音词典匹配。这些文本的预处理工作叫做文本归一化(text normalization),通常包括去掉标点、处理大小写、纠正拼写错误以及标准化一些词(比如MR. 归一化成MISTER)。这是需要花很多时间的dirty work,我们可以借助sed或者perl这样的工具。
英文怎么处理数据与数据源、领域习惯和工具有关,我们这里不介绍。
下载训练数据
语言模型的训练数据我们使用librispeech的文本,我们这里直接下载已经归一化的文本:
wget http://www.openslr.org/resources/11/librispeech-lm-norm.txt.gz
$ du -sh librispeech-lm-norm.txt.gz
1.5G librispeech-lm-norm.txt.gz
这个文件有1.5G,下载会需要一点时间。
查看下载的文本
读者可能会把gz的文件解压,然后用head或者vim来查看。但是解压后文件很大,而且我们的SRILM工具可以处理压缩的文件,因此这里我们使用管道直接查看文件内容:
$ gunzip -c librispeech-lm-norm.txt.gz | head
$ gunzip -c librispeech-lm-norm.txt.gz | wc -wl
40418261 803288729
第二个命令统计训练数据有多少个词和多少行,上面的结果显示总共有4千多万行、8亿多词,这个命令需要一点时间。注意:这个文件的文本都归一化了,但是它都归一化成全大写的词。
定义词典
训练语言模型的第一步是需要定义模型的词典。我们希望这个词典使用最小的词来覆盖训练数据中的大部分Token。因此需要从训练数据中挑出最高频的一些词。
我们可以使用ngram-count这个工具来统计一个文本文件中n-gram出现的次数,而1-gram就是词的频数。比如:
ngram-count -text TEXT -order 1 -write COUNTS -tolower
-text就是统计文件TEXT,-order 1就是统计1-gram, -write COUNTS是输出到文件COUNTs,-tolower是把所有的词都变成小写。关于这个工具的更加详细文档可以参考这里。
抽取训练数据中最高频的10000个词
$ ngram-count -text librispeech-lm-norm.txt.gz -order 1 -write librispeech.1grams -tolower
上面的命令对输入文件librispeech-lm-norm.txt.gz进行1-gram统计,所有的词都变成小写,然后输出的librispeech.1grams。这个命令需要运行一段时间。
我们看一下这个1grams文件的内容:
$ head librispeech.1grams
bikes 79
schiffbauerdamm 4
pluseirs 1
diega 3
intermediating 4
caplike 3
ryot 65
cernis 4
moqui's 1
prideth 1
为了选取高频的词,我们需要对这个文件排序,排序的是第二列,而且要把第二列当成数字而不是字符串,否则会出现”12”<”2”的情况。
$ sort -k 2,2 -n -r librispeech.1grams | head -10000 > librispeech.top10k.1grams
上面使用sort对librispeech.1grams排序,-r说明是逆序(我们需要选择频次最大的),-n表示使用字符串对应的数字来排序。 -k 2,2的意思排序的key是第二列,’2,2’表示排序开始key是第二列,结束的key也是第二列,因此也就是第二列,如果是’2,3’就表示用第2列和第3列来排序。
关于sort的更详细用法感兴趣的读者可以参考Linux sort命令简介。
接着使用管道把sort的结果传给后面的head命令,从而选取频率最高的10000个词,我们来看一下这个文件的内容:
$ head librispeech.top10k.1grams
the 49059384
<s> 40418260
</s> 40418260
and 26362574
of 24795903
to 22052019
a 17811980
in 13524728
i 10609353
he 10203671
“the”竟然比如”<s>”频率都高,说明一个句子出现”the”的平均次数大于1。<s>的数目等于非空行的数量,也就是40418260,而前面我们用”wc -l”统计的行数是40418261,多出的一行是一个空行(只有一个换行),因为我们很多时候在文件的最后一行也会加换行\n。
但是我们的词典不需要词频,此外我们希望词典安装字母排序,因此我们可以用下面的命令:
cut -f 1 librispeech.top10k.1grams | sort > librispeech.top10k.vocab
这样得到的librispeech.top10k.vocab为:
$ head librispeech.top10k.vocab
a
aaron
abandon
abandoned
abbe
abbey
abbot
abe
abel
abide
统计OOV率
我们的top10k个高频词能覆盖数据的多少呢?我们可以使用compute-oov-rate工具来实现统计。
$ ngram-count -text data/dev.txt -order 1 -write dev.1grams
我们首先使用ngram-count统计data/dev.txt的1-gram。然后使用compute-oov-rate统计OOV率:
$ compute-oov-rate librispeech.top10k.vocab dev.1grams
OOV tokens: 625 / 10841 (5.77%) excluding fragments: 625 / 10841 (5.77%)
OOV types: 556 / 2872 (19.36%) excluding fragments: 556 / 2872 (19.36%)
compute-oov-rate需要两个参数,第一个是词典,第二个是来自ngram-count的统计结果,我们可以看到训练集的top10k词有19.36%的oov types和5.77%的oov tokens。oov types是只没见过的词,多次出现只算一次,而oov tokens会累计所有没有见过的词。
类似的我们可以对data/test.txt进行统计:
$ ngram-count -text data/test.txt -order 1 -write test.1grams
$ compute-oov-rate librispeech.top10k.vocab test.1grams
OOV tokens: 258 / 5236 (4.93%) excluding fragments: 258 / 5236 (4.93%)
OOV types: 220 / 1575 (13.97%) excluding fragments: 220 / 1575 (13.97%)
所有我们可以看到,oov type要比oov token高,因为很多没有覆盖的type非常低频。我们再来看一下训练数据上的统计:
$ compute-oov-rate librispeech.top10k.vocab librispeech.1grams
OOV tokens: 52454701 / 803288729 (6.53%) excluding fragments: 52454701 / 803288729 (6.53%)
OOV types: 963675 / 973673 (98.97%) excluding fragments: 963675 / 973673 (98.97%)
训练数据上的oov type非常高,也就是说我们用1.03%的高频词覆盖了93.5%的数据,98.97%的低频词的出现次数只占总数的6.53%!
注意:5%的OOV token是非常高的一个值,因为OOV的肯定识别不了,这里为了让模型小,我们选择了比较小的词典,在实际应用中的词典可能是50k这样的。
训练语言模型
接下来我们要训练语言模型了,我们还是使用ngram-count工具。这个工具一个一步完成训练,但是为了理解它的过程,我把它分成两步来操作。第一步是统计N-gram的频次,第二步是进行模型的参数估计(打折与回退等平滑)。注意:因为数据比较大,训练的机器要有10GB的内存,否则会内存不够。
统计训练数据上的所有trigram计数
下面的统计命令需要几分钟,请耐心等待。
$ ngram-count -text librispeech-lm-norm.txt.gz -tolower -order 3 -write librispeech.3grams.gz
因为输出文件比较大,我们采用压缩的格式,ngram-count会根据后缀判断是否压缩。-tolower表示进行小写归一化,而-order 3表示统计trigram。注意:输出是根据公共前缀分组的,但是词本身并没有排序。如果需要的话请用sort排序。
我们可以看一下输出文件的内容:
$ gunzip -c librispeech.3grams.gz | less
bikes 79
bikes here 1
bikes here and 1
bikes triple 1
bikes triple locked 1
bikes </s> 15
bikes invaded 1
bikes invaded one's 1
bikes sir 1
bikes sir </s> 1
bikes travelled 1
bikes travelled warily 1
bikes there 1
bikes there </s> 1
bikes are 2
bikes are good 1
使用Witten-Bell平滑
下面的命令需要几分钟的时间。
$ ngram-count -debug 1 -order 3 -vocab librispeech.top10k.vocab \
-read librispeech.3grams.gz -wbdiscount -lm librispeech.3bo.gz
using WittenBell for 1-grams
using WittenBell for 2-grams
using WittenBell for 3-grams
discarded 1 1-gram probs predicting pseudo-events
warning: distributing 1.26288e-05 left-over probability mass over all 9999 words
discarded 2 2-gram contexts containing pseudo-events
discarded 9999 2-gram probs predicting pseudo-events
discarded 29987 3-gram contexts containing pseudo-events
discarded 2198401 3-gram probs predicting pseudo-events
discarded 79019478 3-gram probs discounted to zero
writing 10000 1-grams
writing 13412395 2-grams
writing 36521492 3-grams
-debug 1让它输出一些debug信息,-order 3说明是trigram模型,-read是读取前面的3gram统计, -wbdiscount使用Witten-Bell平滑,最后输出到librispeech.3bo.gz。
我们可以查看文件内容:
$ gunzip -c librispeech.3bo.gz | less
\data\
ngram 1=10000
ngram 2=13412395
ngram 3=36521492
\1-grams:
-1.291743 </s>
-99 <s> -2.29457
-1.647608 a -1.707602
-5.228539 aaron -0.3972774
-4.795578 abandon -0.8257342
-4.538978 abandoned -0.6036708
-5.064918 abbe -0.3938949
-4.877338 abbey -0.546707
也可以先解压然后再用文本编辑器打开,注意解压很大,需要能阅读大文件的文本编辑器。
模型评估
上面我们得到的模型是arpa格式的,完整的文档在这里。
“手动”计算概率
给定句子”a model was born”,我们怎么计算born的条件概率?因为是trigram,所有实际应该计算$P(born \vert \text{model was})$。
因此我们需要寻找trigram “model was born”的统计信息,可以使用zgrep工具:
$ zgrep " model was born" librispeech.3bo.gz
没有找到,因此在训练数据中没有这个trigram,那么就应该使用回退机制计算其概率。首先我们要找到backoof概率$\alpha(\text{model was})$,这个信息可以通过zgrep来寻找:
$ zgrep -E "\smodel was" librispeech.3bo.gz | head -1
-2.001953 model was 0.02913048
在”model was”前加”\s”的目的是为了避免搜索出来”amodel was”。-2.001953是bigram概率(log)$P(was \vert model)$,而0.002913048是我们需要的backoff概率$\alpha(\text{model was})$。
接下来我们需要计算$P(born \vert was)$,我们可以这样搜索:
$ zgrep -E "\swas born" librispeech.3bo.gz | head -1
-2.597636 was born -0.4911189
因此$P(born \vert \text{model was})$的(log)概率是-2.597636,因为:
\[P(born \vert \text{model was})=\alpha(\text{model was}) \times P(born \vert was)\]因为上面的概率是log域的,因此乘法就是加法:
0.02913048 + -2.597636 = -2.568506
上面是log的概率,真正的概率是$10^{-2.568506} = 0.002700813$。
使用ngram计算
下面我们用ngram的-ppl选项来计算句子”a model was born”的概率,同时验证我们上面手动的计算方法是否正确。
$ echo "a model was born" | ngram -debug 2 -lm librispeech.3bo.gz -ppl -
reading 10000 1-grams
reading 13412395 2-grams
reading 36521492 3-grams
a model was born
p( a | <s> ) = [2gram] 0.01653415 [ -1.781618 ]
p( model | a ...) = [3gram] 0.0001548981 [ -3.809954 ]
p( was | model ...) = [3gram] 0.002774693 [ -2.556785 ]
p( born | was ...) = [2gram] 0.002700813 [ -2.568506 ]
p( </s> | born ...) = [3gram] 0.1352684 [ -0.8688038 ]
1 sentences, 4 words, 0 OOVs
0 zeroprobs, logprob= -11.58567 ppl= 207.555 ppl1= 787.8011
file -: 1 sentences, 4 words, 0 OOVs
0 zeroprobs, logprob= -11.58567 ppl= 207.555 ppl1= 787.8011
解释一下上面命令的参数,我们先看ngram,-debug 2打印调试信息;-lm指定使用的arpa语言模型, -ppl表示计算ppl,而最后一个”-“表示输入文件是来自标准输入。否则我们就需要创建一个文件,其内容是”a model was born”。这样每次测试新的句子都需要修改文件,很麻烦。我们这里使用bash的一个常见tricky,通过”-“指定我们要读取的文件的内容来自标准输入。然后通过echo和管道把要计算的句子传给ngram。
注意:ngram工具自动帮我们增加了开始和结束标签<s>和</s>。最后一行输出了整个句子的log概率和ppl。我们看p( born \vert was …)部分:
p( born | was ...) = [2gram] 0.002700813 [ -2.568506 ]
它计算的概率和我们手动计算是一样的,[2gram]的意思是它回退到了bigram。我们也可以验证一下PPL和log概率的关系:$10^{-(-11.58567/5)} = 207.555$。
计算开发集上的PPL
$ ngram -lm librispeech.3bo.gz -ppl data/dev.txt
file data/dev.txt: 466 sentences, 10841 words, 625 OOVs
0 zeroprobs, logprob= -21939 ppl= 113.1955 ppl1= 140.4475
PPL是113,oov率是625/10841 = 5.8%。
计算测试集上的PPL
$ ngram -lm librispeech.3bo.gz -ppl data/test.txt
file data/test.txt: 261 sentences, 5236 words, 258 OOVs
0 zeroprobs, logprob= -10505.09 ppl= 101.1976 ppl1= 128.9147
模型自适应
下面我们介绍怎么调整模型使得它可以用于特定的领域。通常我们的特定领域数据是比较少的,但是通用领域的数据很多。我们这个例子里使用AMI作为我们的目标领域,它是一个多人电话会议的场景。也就是多个人面对面的spontaneous的语音,而librispeech数据是朗读书籍的录音,它们的说话方式和主题都相差很大。
领域数据
我们把librispeech数据作为领域外(out-of-domain)的数据,然后用少量AMI的领域数据来调整模型,使得它适合AMI的领域。我们先来看一下AMI的数据:
$ wc -wl data/ami-*.txt
2500 26473 data/ami-dev.txt
2096 20613 data/ami-test.txt
86685 924896 data/ami-train.txt
91281 971982 总用量
我们看到AMI的数据和libirspeech相比小的多。此外还有一个准备好的词典文件,它包含频率高于3的词:
$ wc -l data/ami-train.min3.vocab
6271 data/ami-train.min3.vocab
前面libirspeech我们的词典是10k,而这里只有6k。
使用ami数据训练模型
和前面一样,只不过使用不同的训练数据和词典。
$ ngram-count -text data/ami-train.txt -tolower -order 3 -write ami.3grams.gz
$ ngram-count -debug 1 -order 3 -vocab data/ami-train.min3.vocab \
-read ami.3grams.gz -wbdiscount -lm ami.3bo.gz
using WittenBell for 1-grams
using WittenBell for 2-grams
using WittenBell for 3-grams
discarded 1 1-gram probs predicting pseudo-events
warning: distributing 0.00626447 left-over probability mass over all 6270 words
discarded 2 2-gram contexts containing pseudo-events
discarded 1210 2-gram probs predicting pseudo-events
discarded 6220 3-gram contexts containing pseudo-events
discarded 3640 3-gram probs predicting pseudo-events
discarded 398917 3-gram probs discounted to zero
writing 6271 1-grams
writing 167020 2-grams
writing 91496 3-grams
接下来测试这个模型在开发集上的PPL:
$ ngram -lm ami.3bo.gz -ppl data/ami-dev.txt
file data/ami-dev.txt: 2314 sentences, 26473 words, 1264 OOVs
0 zeroprobs, logprob= -55254.39 ppl= 101.7587 ppl1= 155.5435
在开发集上的PPL是101。
接下来我们测试一下领域外的用librispeech训练的模型在ami开发集上的PPL:
$ ngram -lm librispeech.3bo.gz -ppl data/ami-dev.txt
$ ngram -lm librispeech.3bo.gz -ppl data/ami-dev.txt
file data/ami-dev.txt: 2314 sentences, 26473 words, 3790 OOVs
0 zeroprobs, logprob= -56364.05 ppl= 179.8177 ppl1= 305.3926
OOV为3790,比前面的1264高很多,PPL是179也比前面高。这说明librispeech大量数据训练的模型比用ami少量数据的模型好。因为librispeech的领域和ami差别很大,因此即使数据多,效果也不好。
插值和合并
现在我们通过插值的方法把librispeech的模型和ami的模型融合起来,插值需要一个weight,下面会解释怎么选择最优的weight。根据经验,我们一般要给较大的权重给领域的模型,这里我们使用0.8。
我们可以通过ngram的-mix-lm和-write-lm实现模型插值和合并:
$ ngram -debug 1 -order 3 -lm ami.3bo.gz -lambda 0.8 \
-mix-lm librispeech.3bo.gz -write-lm ami+librispeech.3bo.gz
reading 6271 1-grams
reading 167020 2-grams
reading 91496 3-grams
reading 10000 1-grams
reading 13412395 2-grams
reading 36521492 3-grams
writing 12819 1-grams
writing 13481632 2-grams
writing 36558250 3-grams
-lm指定主要的模型,也就是-lambda的权重,而-mix-lm是插值的模型,-write-lm把插值的结果输出。如果我们需要插值多个模型呢?我们可以使用-mix-lm2和-mix-lambda2、-mix-lm3和-mix-lambda3……。比如:
$ ngram -order 3 \
-lm lm0.gz -lambda ${LAMBDAS[0]} \
-mix-lm lm1.gz \
-mix-lm2 lm2.gz -mix-lambda2 ${LAMBDAS[2]} \
-mix-lm3 lm3.gz -mix-lambda3 ${LAMBDAS[3]} \
-mix-lm4 lm4.gz -mix-lambda4 ${LAMBDAS[4]} \
-mix-lm5 lm5.gz -mix-lambda5 ${LAMBDAS[5]} \
-write-lm mixed_lm.gz
注:上面的代码参考了Building large LMs with SRILM。
-mix-lm的模型不需要知道插值权重,因为所以权重加起来等于1,脚本自动可以计算出来。
现在我们测试一下这个插值后的模型在开发集上的PPL:
$ ngram -lm ami+librispeech.3bo.gz -ppl data/ami-dev.txt
ngram -lm ami+librispeech.3bo.gz -ppl data/ami-dev.txt
file data/ami-dev.txt: 2314 sentences, 26473 words, 783 OOVs
0 zeroprobs, logprob= -56313.77 ppl= 102.546 ppl1= 155.6145
PPL是102,比只有ami的还差?但是我们看到OOV从1264降到了783,因为ami的开发集的某些oov在librispeech里是出现过的。因为插值后的模型的词典更大,因此它选择的分支也就越多,PPL也越大。所以在比较语言模型的PPL时一定要看它们的词典是否一样,否则它们的对比是没有意义的!
那怎么说明插值的方法是否有效呢?我们可以在插值的时候指定只使用ami的词典,把ami词典之外的ngram丢弃掉,这样就可以比较了:
$ ngram -debug 1 -order 3 -lm ami.3bo.gz -lambda 0.8 -mix-lm librispeech.3bo.gz \
-write-lm ami+librispeech.bo3.gz -vocab data/ami-train.min3.vocab -limit-vocab
reading 6271 1-grams
reading 167020 2-grams
reading 91496 3-grams
reading 10000 1-grams
discarded 6548 OOV 1-grams
reading 13412395 2-grams
discarded 9980751 OOV 2-grams
reading 36521492 3-grams
discarded 19683914 OOV 3-grams
warning: distributing 0.0257169 left-over probability mass over all 6270 words
writing 6271 1-grams
writing 3500881 2-grams
writing 16874336 3-grams
上面的命令通过-limit-vocab和-vocab告诉ngram插值的时候只使用data/ami-train.min3.vocab这个词典。我们再次用新插值的模型来计算PPL:
$ ngram -lm ami+librispeech.3bo.gz -ppl data/ami-dev.txt
file data/ami-dev.txt: 2314 sentences, 26473 words, 1264 OOVs
0 zeroprobs, logprob= -53856.04 ppl= 90.52426 ppl1= 136.8931
我们看到OOV和只用ami一样,但是PPL降到了90。
选择最优的插值参数
怎么找到最优的插值参数呢?一种办法就是暴力搜索,选择PPL最小的那个。但是这太慢了,我们可以使用更高效的算法,比如基于EM的方法。SRILM已经实现了这样的算法,下面我们用脚本来测试一下。
compute-best-mix脚本可以计算最优的插值参数,但是它需要每个模型在(开发)数据集上的PPL详细文件。所以首先我们用ngram来生成两个模型在开发集上的PPL详细文件:
$ ngram -debug 2 -order 3 -lm librispeech.3bo.gz -ppl data/ami-dev.txt > lm1.ppl
reading 10000 1-grams
reading 13412395 2-grams
reading 36521492 3-grams
这个ppl文件包含了计算ppl的详细信息:
$ head -50 lm1.ppl
uhhuh
p( <unk> | <s> ) = [OOV] 0 [ -inf ]
p( </s> | <unk> ...) = [1gram] 0.05108071 [ -1.291743 ]
1 sentences, 1 words, 1 OOVs
0 zeroprobs, logprob= -1.291743 ppl= 19.57686 ppl1= undefined
uh do we know if there will be a lot of people coming across the hall in terms of security stuff if we can i mean my idea is to put the photocopier and the fax in the hall
p( <unk> | <s> ) = [OOV] 0 [ -inf ]
p( do | <unk> ...) = [1gram] 0.001973127 [ -2.704845 ]
p( we | do ...) = [2gram] 0.00794844 [ -2.099718 ]
p( know | we ...) = [3gram] 0.07709495 [ -1.112974 ]
p( if | know ...) = [3gram] 0.001739762 [ -2.75951 ]
p( there | if ...) = [3gram] 0.03683351 [ -1.433757 ]
p( will | there ...) = [3gram] 0.001275695 [ -2.894253 ]
p( be | will ...) = [3gram] 0.7819563 [ -0.1068175 ]
p( a | be ...) = [3gram] 0.06429912 [ -1.191795 ]
p( lot | a ...) = [3gram] 0.00344327 [ -2.463029 ]
p( of | lot ...) = [3gram] 0.6903875 [ -0.1609071 ]
p( people | of ...) = [3gram] 0.02535887 [ -1.59587 ]
p( coming | people ...) = [3gram] 0.003904172 [ -2.408471 ]
p( across | coming ...) = [3gram] 0.004744955 [ -2.323768 ]
p( the | across ...) = [3gram] 0.507619 [ -0.2944621 ]
p( hall | the ...) = [3gram] 0.01331778 [ -1.875568 ]
p( in | hall ...) = [3gram] 0.0139884 [ -1.854232 ]
p( terms | in ...) = [2gram] 0.0002327063 [ -3.633192 ]
p( of | terms ...) = [3gram] 0.5794951 [ -0.2369502 ]
p( security | of ...) = [3gram] 0.0002009042 [ -3.697011 ]
p( stuff | security ...) = [2gram] 6.165597e-05 [ -4.210025 ]
p( if | stuff ...) = [2gram] 0.00305367 [ -2.515178 ]
p( we | if ...) = [3gram] 0.02380954 [ -1.623249 ]
p( can | we ...) = [3gram] 0.05685819 [ -1.245207 ]
p( i | can ...) = [3gram] 0.0008678308 [ -3.061565 ]
p( mean | i ...) = [3gram] 0.0007527435 [ -3.123353 ]
p( my | mean ...) = [3gram] 0.007983495 [ -2.097807 ]
p( idea | my ...) = [2gram] 0.0007232695 [ -3.1407 ]
p( is | idea ...) = [3gram] 0.1738275 [ -0.7598816 ]
p( to | is ...) = [3gram] 0.100922 [ -0.9960141 ]
p( put | to ...) = [3gram] 0.004835975 [ -2.315516 ]
p( the | put ...) = [3gram] 0.09036702 [ -1.04399 ]
p( <unk> | the ...) = [OOV] 0 [ -inf ]
p( and | <unk> ...) = [1gram] 0.03331709 [ -1.477333 ]
p( the | and ...) = [2gram] 0.07761291 [ -1.110066 ]
p( <unk> | the ...) = [OOV] 0 [ -inf ]
p( in | <unk> ...) = [1gram] 0.01709259 [ -1.767192 ]
p( the | in ...) = [2gram] 0.2916464 [ -0.5351433 ]
p( hall | the ...) = [3gram] 0.004312756 [ -2.365245 ]
p( </s> | hall ...) = [3gram] 0.1904368 [ -0.7202492 ]
1 sentences, 39 words, 3 OOVs
0 zeroprobs, logprob= -68.95484 ppl= 73.05407 ppl1= 82.30237
类似的,我们计算ami的模型的ppl文件:
$ ngram -debug 2 -order 3 -lm ami.3bo.gz -ppl data/ami-dev.txt > lm2.ppl
reading 6271 1-grams
reading 167020 2-grams
reading 91496 3-grams
有了这两个ppl文件,我们就可以计算最优的插值权重了:
$ compute-best-mix lm*.ppl > best-mix.ppl
iteration 1, lambda = (0.5 0.5), ppl = 109.309
iteration 2, lambda = (0.387377 0.612623), ppl = 104.984
iteration 3, lambda = (0.323519 0.676481), ppl = 103.53
iteration 4, lambda = (0.286997 0.713003), ppl = 103.017
iteration 5, lambda = (0.265635 0.734365), ppl = 102.83
iteration 6, lambda = (0.252893 0.747107), ppl = 102.76
iteration 7, lambda = (0.245184 0.754816), ppl = 102.734
iteration 8, lambda = (0.240476 0.759524), ppl = 102.724
iteration 9, lambda = (0.237583 0.762417), ppl = 102.72
iteration 10, lambda = (0.235798 0.764202), ppl = 102.719
iteration 11, lambda = (0.234694 0.765306), ppl = 102.718
我们来查看最后的输出:
$ cat best-mix.ppl
28004 non-oov words, best lambda (0.23401 0.76599)
pairwise cumulative lambda (1 0.76599)
也就是最优的混合参数是0.766。
模型裁剪
我们看到模型的PPL和训练数据大小的关系,训练数据越多效果越好。但是训练数据越多,模型也越大,模型太大了在使用时需要占据很多内存并且计算速度也会更慢。一种办法是根据我们对于计算资源的限制(比如内存和计算速度)选择合适量的数据训练模型,但是更好的办法是使用所有的数据来训练模型,然后根据计算资源的限制进行裁剪。
一种常见的裁剪方法来自论文Entropy-based Pruning of Backoff Language Models,SRILM也实现了这个算法。裁剪有一个-prune的选项,它表示如果PPL的相对变大(变坏)小于这个阈值就可以继续裁剪。这个选项的值通常很小,比如$10^{-8}$或者$10^{-9}。这个值越大,则裁剪的越多,模型也越小,但是PPL也越大。
下面我们用$10^{-5}$来裁剪:
ngram -debug 1 -lm librispeech.3bo.gz -prune 1e-5 -write-lm librispeech-pruned1.3bo.gz
类似的我们用$10^{-6}…10^{-10}$来裁剪,结果如下:
| prune值 | $10^{-5}$ | $10^{-6}$ | $10^{-7}$ | $10^{-8}$ | $10^{-9}$ | $10^{-10}$ | 未裁剪 |
|---|---|---|---|---|---|---|---|
| 模型大小 | 336K | 2.1M | 12M | 61M | 205M | 263M | 286M |
| 在data/dev.txt上的PPL | 258 | 178 | 136 | 118 | 113.49 | 113.21 | 113.19 |
- 显示Disqus评论(需要科学上网)