本文介绍XLNet的代码的Fine-tuning部分,需要首先阅读第一部分、第二部分和第三部分,读者阅读前需要了解XLNet的原理,不熟悉的读者请先阅读XLNet原理。
目录
- 运行
- main函数
- StsbProcessor
- file_based_convert_examples_to_features
- convert_single_example
- file_based_input_fn_builder
- get_model_fn
- get_regression_loss
- XLNetModel
- Attention Mask的不同
- two stream attention的区别
- rel_multihead_attn
- get_pooled_out
- modeling.summarize_sequence
- regression_loss
- pretraining和finetuning的区别
运行
注意:即使batch大小为1,用XLNet-Large模型进行Fine-tuning需要16GB的内存,因此很难在普通(8GB)的GPU上训练大的模型。如果真的需要Fine-tuning,建议参考renatoviolin的repo,它使用了一些技巧来减少内存,比如使用16位的浮点数,减少最大序列长度等等。相信读者了解了原始的XLNet代码再去阅读这个修改也会比较容易。下表是16GB内存的GPU可以训练的模型的序列长度和batch大小对应关系。如果出现内存不够,那么可以使用XLNET-Base模型或者减少batch大小或者序列长度,但是batch大小变小会让训练速度变慢,而序列长度变短可能会影响模型的效果。
| System | Seq Length | Max Batch Size |
|---|---|---|
XLNet-Base |
64 | 120 |
| … | 128 | 56 |
| … | 256 | 24 |
| … | 512 | 8 |
XLNet-Large |
64 | 16 |
| … | 128 | 8 |
| … | 256 | 2 |
| … | 512 | 1 |
我这里是使用16GB的CPU来Fine-Tuning XLNET-Large模型,因为只是为了阅读代码和调试,所以不太关注其训练速度。
并且这里只使用STS-B任务来介绍fine-tuning的代码。STS-B的数据是GLUE的一部分,可以使用这个脚本下载,读者也可以参考这里。STS-B的数据示例为:
$ head train.tsv
index genre filename year old_index source1 source2 sentence1 sentence2 score
0 main-captions MSRvid 2012test 0001 none none A plane is taking off. An air plane is taking off. 5.000
1 main-captions MSRvid 2012test 0004 none none A man is playing a large flute. A man is playing a flute. 3.800
2 main-captions MSRvid 2012test 0005 none none A man is spreading shreded cheese on a pizza. A man is spreading shredded cheese on an uncooked pizza. 3.800
3 main-captions MSRvid 2012test 0006 none none Three men are playing chess. Two men are playing chess. 2.600
4 main-captions MSRvid 2012test 0009 none none A man is playing the cello. A man seated is playing the cello. 4.250
5 main-captions MSRvid 2012test 0011 none none Some men are fighting. Two men are fighting. 4.250
6 main-captions MSRvid 2012test 0012 none none A man is smoking. A man is skating.0.500
7 main-captions MSRvid 2012test 0013 none none The man is playing the piano. The man is playing the guitar. 1.600
8 main-captions MSRvid 2012test 0014 none none A man is playing on a guitar and singing.A woman is playing an acoustic guitar and singing. 2.200
最重要的列是sentence1、sentence2和score,分别表示输入的两个句子以及它们的相似度得分。因此这个任务的输入是两个句子,输出是一个0-5的得分,这是一个回归问题。
运行的代码为(如果读者的CPU/GPU没有16GB,那么可以把batch大小减少一些:
python run_classifier.py \
--do_train=True \
--do_eval=False \
--task_name=sts-b \
--data_dir=/home/lili/data/glue_data/STS-B \
--output_dir=proc_data/sts-b \
--model_dir=exp/sts-b \
--uncased=False \
--spiece_model_file=/home/lili/data/xlnet_cased_L-24_H-1024_A-16/spiece.model \
--model_config_path=/home/lili/data/xlnet_cased_L-24_H-1024_A-16/xlnet_config.json \
--init_checkpoint=/home/lili/data/xlnet_cased_L-24_H-1024_A-16/xlnet_model.ckpt \
--max_seq_length=128 \
--train_batch_size=8 \
--num_hosts=1 \
--num_core_per_host=1 \
--learning_rate=5e-5 \
--train_steps=1200 \
--warmup_steps=120 \
--save_steps=600 \
--is_regression=True \
接下来我们根据代码的执行顺序来分析fine-tuning相关的代码。
main函数
下面是fine-tuning的主要代码,结构比较清晰,请参考注释。
def main(_):
processors = {
'sts-b': StsbProcessor,
}
task_name = FLAGS.task_name.lower()
# 数据读取的类
processor = processors[task_name]()
label_list = processor.get_labels() if not FLAGS.is_regression else None
# WordPiece "分词"
sp = spm.SentencePieceProcessor()
sp.Load(FLAGS.spiece_model_file)
def tokenize_fn(text):
text = preprocess_text(text, lower=FLAGS.uncased)
return encode_ids(sp, text)
run_config = model_utils.configure_tpu(FLAGS)
# 核心的model function
model_fn = get_model_fn(len(label_list) if label_list is not None else None)
spm_basename = os.path.basename(FLAGS.spiece_model_file)
if FLAGS.use_tpu:
# 这里是GPU/CPU
else:
# 构造Estimator
estimator = tf.estimator.Estimator(
model_fn=model_fn,
config=run_config)
if FLAGS.do_train:
# 读取训练数据
train_examples = processor.get_train_examples(FLAGS.data_dir)
np.random.shuffle(train_examples)
# 把训练数据保存到TFRecord文件
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenize_fn,
train_file, FLAGS.num_passes)
# Estimator需要的input function
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
# 训练(fine-tuning)
estimator.train(input_fn=train_input_fn, max_steps=FLAGS.train_steps)
StsbProcessor
这个类负责读取训练数据,读者如果希望用自己的训练数据,则可以参考这个类。这个类和BERT的Processor是基本类似的,读者也可以参考DataProcessor。
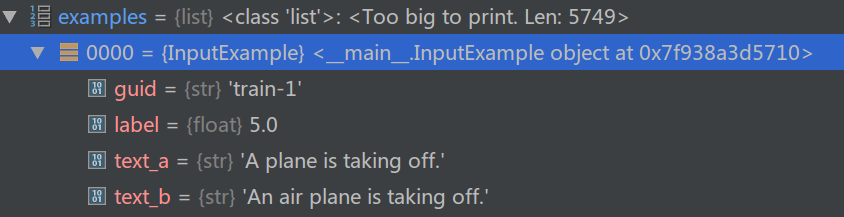
它的核心代码是_create_examples函数,作用就是读取前面介绍的STS-B数据文件,完整代码在这里。它最终返回的是一个list,list的每一个元素是InputExample对象,比如第一个数据为:
file_based_convert_examples_to_features
这个函数把InputExample变成InputFeatures对象,然后使用TFRecordWriter存到TFRecord文件里。这个函数的核心部分是调用convert_single_example函数把输入字符串进行WordPiece”分词”、转换成ID,处理Segment和padding等工作。它的代码和BERT的也非常类似,完整的代码在这里。
convert_single_example
这个函数的输出是一个InputFeatures对象,其中input_ids是Token的ID,如果长度不够max_seq_length,则会在开头的位置padding 0,两个句子之间用[SEP]分开,最后一个Token是特殊的[CLS]。这和BERT是相反的,BERT的[CLS]在最开头,原因在XLNet原理部分介绍过了。input_mask的长度为max_seq_length,值为0表示这个位置是真实的Token,而1表示这是一个Padding的Token。segment_ids表示这个Token属于哪个Segment,总共有SEG_ID_A、SEG_ID_B、SEG_ID_CLS、SEG_ID_SEP和SEG_ID_PAD五个值,分布表示Token属于第一个句子、第二个句子、特殊的CLS、特殊的SEP和padding。
label_id是这个训练数据的标签,对于分类任务来说,这是一个整数ID,对于STS-B这样的回归任务来说,它是一个浮点数,比如第一个训练数据的label_id是4.2,表示两个句子的相似程度(5为最相似,0最不相似)。
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenize_fn):
"""把一个`InputExample`对象变成一个`InputFeatures`对象"""
if isinstance(example, PaddingInputExample):
return InputFeatures(
input_ids=[0] * max_seq_length,
input_mask=[1] * max_seq_length,
segment_ids=[0] * max_seq_length,
label_id=0,
is_real_example=False)
# 如果是分类,把分类名字变成id,这里是回归,label_list是None
if label_list is not None:
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
# WordPiece分词,变成ID
# 比如第一个例子的输出为 [276, 60, 28495, 1407, 22, 21142, 3622, 25, 7524, 25, 4618]
tokens_a = tokenize_fn(example.text_a)
tokens_b = None
if example.text_b:
# 第二个句子的分词
tokens_b = tokenize_fn(example.text_b)
if tokens_b:
# 如果太长,则截取掉一些,使得tokens_a加tokens_b的Token个数小于等于max_seq_length-3
# 预留的3个Token是两个[SEP]和一个[CLS]。
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# 如果只有一个句子则只需要预留两个Token:[SEP]和[CLS]。
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[:max_seq_length - 2]
tokens = []
segment_ids = []
for token in tokens_a:
tokens.append(token)
segment_ids.append(SEG_ID_A)
tokens.append(SEP_ID)
segment_ids.append(SEG_ID_A)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(SEG_ID_B)
tokens.append(SEP_ID)
segment_ids.append(SEG_ID_B)
tokens.append(CLS_ID)
segment_ids.append(SEG_ID_CLS)
input_ids = tokens
# 0代表真正的Token,而1代表padding
input_mask = [0] * len(input_ids)
# 如果长度不够max_seq_length
# 则用0做padding,对应的segment_id是SEG_ID_PAD
if len(input_ids) < max_seq_length:
delta_len = max_seq_length - len(input_ids)
input_ids = [0] * delta_len + input_ids
input_mask = [1] * delta_len + input_mask
segment_ids = [SEG_ID_PAD] * delta_len + segment_ids
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
if label_list is not None:
label_id = label_map[example.label]
else:
label_id = example.label
if ex_index < 5:
# 输出前5个数据用于调试
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: {} (id = {})".format(example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id)
return feature
file_based_input_fn_builder
这个函数定义读取TFRecord文件的operation,得到Dataset对象。然后构造Estimator需要的input function。关于Estimator的更多内容,读者可以参考官方文档。也可以参考作者的《深度学习理论与实战:基础篇》的第六章,里面详细的介绍了Tensorflow的基础知识。
def file_based_input_fn_builder(input_file, seq_length, is_training,
drop_remainder):
"""创建传给Estimator的闭包函数`input_fn`"""
name_to_features = {
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.float32),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
"label_ids": tf.FixedLenFeature([], tf.int64),
"is_real_example": tf.FixedLenFeature([], tf.int64),
}
# 如果分类,label_ids是int64;而如果是回归,label_ids是float32
if FLAGS.is_regression:
name_to_features["label_ids"] = tf.FixedLenFeature([], tf.float32)
tf.logging.info("Input tfrecord file {}".format(input_file))
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
example = tf.parse_single_example(record, name_to_features)
# tf.Example只支持tf.int64,但是TPU只支持tf.int32
# 所以把int64转成int32
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.cast(t, tf.int32)
example[name] = t
return example
def input_fn(params, input_context=None):
"""这是实际的input function"""
if FLAGS.use_tpu:
batch_size = params["batch_size"]
elif is_training:
batch_size = FLAGS.train_batch_size
elif FLAGS.do_eval:
batch_size = FLAGS.eval_batch_size
else:
batch_size = FLAGS.predict_batch_size
d = tf.data.TFRecordDataset(input_file)
# 把数据集shard到多个设备上,这里我们只有一个GPU
if input_context is not None:
tf.logging.info("Input pipeline id %d out of %d",
input_context.input_pipeline_id, input_context.num_replicas_in_sync)
d = d.shard(input_context.num_input_pipelines,
input_context.input_pipeline_id)
# 如果训练,我们会shuffle并且重复
# 对于eval,就不需要了
if is_training:
d = d.shuffle(buffer_size=FLAGS.shuffle_buffer)
d = d.repeat()
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
接下来Estimator的train方法会调用get_model_fn函数的model_fn来构造model function。
get_model_fn
def get_model_fn(n_class):
def model_fn(features, labels, mode, params):
#### 是训练还是eval?
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
#### 根据输入构造XLNet模型然后返回loss。我们这里是回归,走第一个分支
# 下面会详细介绍get_regression_loss
if FLAGS.is_regression:
(total_loss, per_example_loss, logits
) = function_builder.get_regression_loss(FLAGS, features, is_training)
else:
(total_loss, per_example_loss, logits
) = function_builder.get_classification_loss(
FLAGS, features, n_class, is_training)
#### Check model parameters
num_params = sum([np.prod(v.shape) for v in tf.trainable_variables()])
tf.logging.info('#params: {}'.format(num_params))
#### 从pretraining的模型加载参数初始值
scaffold_fn = model_utils.init_from_checkpoint(FLAGS)
#### Evaluation模式(mode),而训练差不多,我们这里不介绍
if mode == tf.estimator.ModeKeys.EVAL:
# 为了阅读简洁省略了这部分代码
...............
return eval_spec
elif mode == tf.estimator.ModeKeys.PREDICT:
# 省略predict模式的代码
return output_spec
# 下面是Train模式(fine-tuning)的EstimatorSpec构造过程
#### 配置optimizer
# 得到train_op和learning_rate
train_op, learning_rate, _ = model_utils.get_train_op(FLAGS, total_loss)
monitor_dict = {}
monitor_dict["lr"] = learning_rate
#### Constucting training TPUEstimatorSpec with new cache.
if FLAGS.use_tpu:
#我们忽略TPU的代码,感兴趣的读者可以自行阅读
else:
train_spec = tf.estimator.EstimatorSpec(
mode=mode, loss=total_loss, train_op=train_op)
return train_spec
return model_fn
get_regression_loss
def get_regression_loss(
FLAGS, features, is_training):
"""回归任务的loss"""
# 每个设备的batch大小,这里是8
bsz_per_core = tf.shape(features["input_ids"])[0]
# 把batch维度放最后,转置后为(128, 8)
inp = tf.transpose(features["input_ids"], [1, 0])
# (128, 8)
seg_id = tf.transpose(features["segment_ids"], [1, 0])
# (128, 8)
inp_mask = tf.transpose(features["input_mask"], [1, 0])
# (8,)
label = tf.reshape(features["label_ids"], [bsz_per_core])
# 参考之前的(/2019/07/14/xlnet-codes2/#xlnetconfig)
xlnet_config = xlnet.XLNetConfig(json_path=FLAGS.model_config_path)
# 参考之前的(/2019/07/14/xlnet-codes2/#runconfig)
run_config = xlnet.create_run_config(is_training, True, FLAGS)
# 构造XLNetModel
xlnet_model = xlnet.XLNetModel(
xlnet_config=xlnet_config,
run_config=run_config,
input_ids=inp,
seg_ids=seg_id,
input_mask=inp_mask)
# 得到最后一层最后一个Token(CLS)的输出
summary = xlnet_model.get_pooled_out(FLAGS.summary_type, FLAGS.use_summ_proj)
with tf.variable_scope("model", reuse=tf.AUTO_REUSE):
# CLS的输出加全连接层得到输出,并且计算loss
# 后面会介绍
per_example_loss, logits = modeling.regression_loss(
hidden=summary,
labels=label,
initializer=xlnet_model.get_initializer(),
scope="regression_{}".format(FLAGS.task_name.lower()),
return_logits=True)
# 平均的loss
total_loss = tf.reduce_mean(per_example_loss)
return total_loss, per_example_loss, logits
XLNetModel
XLNetModel类在第二部分的Pretraining阶段介绍过这个函数了,我们这里对比fine-tuning和pretraining不同的地方。
温故而知新,我们再来看一下这个类的构造函数的参数,读者可以对比一下fine-tuning节点参数不同的地方。
- xlnet_config: XLNetConfig,XLNet模型结构的超参数,比如层数,head数量等等
- run_config: RunConfig,运行时的超参数,包括dropout、初始范围等等。
- input_ids: int32 Tensor,shape是[len, bsz], 输入token的ID
- seg_ids: int32 Tensor,shape是[len, bsz], 输入的segment ID
- input_mask: float32 Tensor,shape是[len, bsz], 输入的mask,0是真正的tokens而1是padding的
- mems: list,每个元素是float32 Tensors,shape是[mem_len, bsz, d_model], 上一个batch的memory。fine-tuning为None
- perm_mask: float32 Tensor,shape是[len, len, bsz]。
- 如果perm_mask[i, j, k] = 0,则batch k的第i个Token可以attend to j
- 如果perm_mask[i, j, k] = 1, 则batch k的第i个Token不可以attend to j
- 如果是None,则每个位置都可以attend to 所有其它位置(包括自己)。fine-tuning为None
- target_mapping: float32 Tensor,shape是[num_predict, len, bsz]。fine-tuning为None
- 如果target_mapping[i, j, k] = 1,则batch k的第i个要预测的是第j个Token,这是一种one-hot表示
- 只是在pretraining的partial prediction时使用,finetuning时设置为None
- inp_q: float32 Tensor,shape是[len, bsz]。fine-tuning为None
- 需要计算loss的(Mask的位置)为1,不需要的值为0,只在pretraining使用,finetuning时应为None
上面的构造函数核心的代码其实只有一行:
(self.output, self.new_mems, self.lookup_table) = modeling.transformer_xl(**tfm_args)
其余的代码在第二部分基本已经介绍过了,读者可以从这里开始阅读。下面我只介绍fine-tuning和pretraining不同的地方。
Attention Mask的不同
bsz = tf.shape(inp_k)[1]
qlen = tf.shape(inp_k)[0]
mlen = tf.shape(mems[0])[0] if mems is not None else 0
klen = mlen + qlen
##### Attention mask
# causal attention mask
if attn_type == 'uni':
attn_mask = _create_mask(qlen, mlen, tf_float, same_length)
attn_mask = attn_mask[:, :, None, None]
elif attn_type == 'bi':
attn_mask = None
else:
raise ValueError('Unsupported attention type: {}'.format(attn_type))
# data mask: input mask & perm mask
if input_mask is not None and perm_mask is not None:
data_mask = input_mask[None] + perm_mask
elif input_mask is not None and perm_mask is None:
data_mask = input_mask[None]
elif input_mask is None and perm_mask is not None:
data_mask = perm_mask
else:
data_mask = None
if data_mask is not None:
# all mems can be attended to
mems_mask = tf.zeros([tf.shape(data_mask)[0], mlen, bsz],
dtype=tf_float)
data_mask = tf.concat([mems_mask, data_mask], 1)
if attn_mask is None:
attn_mask = data_mask[:, :, :, None]
else:
attn_mask += data_mask[:, :, :, None]
if attn_mask is not None:
attn_mask = tf.cast(attn_mask > 0, dtype=tf_float)
if attn_mask is not None:
non_tgt_mask = -tf.eye(qlen, dtype=tf_float)
non_tgt_mask = tf.concat([tf.zeros([qlen, mlen], dtype=tf_float),
non_tgt_mask], axis=-1)
non_tgt_mask = tf.cast((attn_mask + non_tgt_mask[:, :, None, None]) > 0,
dtype=tf_float)
else:
non_tgt_mask = None
在fine-tuning阶段,没有了cache,因此mlen(memory的length)为0。
two stream attention的区别
with tf.variable_scope('layer_{}'.format(i)):
if inp_q is not None:
output_h, output_g = two_stream_rel_attn(
h=output_h,
g=output_g,
r=pos_emb,
r_w_bias=r_w_bias if not untie_r else r_w_bias[i],
r_r_bias=r_r_bias if not untie_r else r_r_bias[i],
seg_mat=seg_mat,
r_s_bias=r_s_bias_i,
seg_embed=seg_embed_i,
attn_mask_h=non_tgt_mask,
attn_mask_g=attn_mask,
mems=mems[i],
target_mapping=target_mapping,
d_model=d_model,
n_head=n_head,
d_head=d_head,
dropout=dropout,
dropatt=dropatt,
is_training=is_training,
kernel_initializer=initializer)
reuse = True
else:
reuse = False
output_h = rel_multihead_attn(
h=output_h,
r=pos_emb,
r_w_bias=r_w_bias if not untie_r else r_w_bias[i],
r_r_bias=r_r_bias if not untie_r else r_r_bias[i],
seg_mat=seg_mat,
r_s_bias=r_s_bias_i,
seg_embed=seg_embed_i,
attn_mask=non_tgt_mask,
mems=mems[i],
d_model=d_model,
n_head=n_head,
d_head=d_head,
dropout=dropout,
dropatt=dropatt,
is_training=is_training,
kernel_initializer=initializer,
reuse=reuse)
如果是pretraining,使用的是two stream的Attention,这是XLNet的核心创新点。但是对于finetuning来说,使用的是和BERT类似的普通的Self-Attention。它通过调用rel_multihead_attn而不是之前的two_stream_rel_attn。
rel_multihead_attn
def rel_multihead_attn(h, r, r_w_bias, r_r_bias, seg_mat, r_s_bias, seg_embed,
attn_mask, mems, d_model, n_head, d_head, dropout,
dropatt, is_training, kernel_initializer,
scope='rel_attn', reuse=None):
"""Multi-head attention with relative positional encoding."""
scale = 1 / (d_head ** 0.5)
with tf.variable_scope(scope, reuse=reuse):
if mems is not None and mems.shape.ndims > 1:
cat = tf.concat([mems, h], 0)
else:
cat = h
# content heads
q_head_h = head_projection(
h, d_model, n_head, d_head, kernel_initializer, 'q')
k_head_h = head_projection(
cat, d_model, n_head, d_head, kernel_initializer, 'k')
v_head_h = head_projection(
cat, d_model, n_head, d_head, kernel_initializer, 'v')
# positional heads
k_head_r = head_projection(
r, d_model, n_head, d_head, kernel_initializer, 'r')
# core attention ops
attn_vec = rel_attn_core(
q_head_h, k_head_h, v_head_h, k_head_r, seg_embed, seg_mat, r_w_bias,
r_r_bias, r_s_bias, attn_mask, dropatt, is_training, scale)
# post processing
output = post_attention(h, attn_vec, d_model, n_head, d_head, dropout,
is_training, kernel_initializer)
return output
这个函数实现标准的Transformer的Self-Attenion,没有Mask,因此每个词都可以Attend to 其它任何词。和BERT的区别是位置编码的差别,这里使用的是相对位置编码。
到此为止,fine-tuning的XLNet模型的构造就介绍完成了,下面我们返回model_fn函数,看loss的构造。
get_pooled_out
def get_pooled_out(self, summary_type, use_summ_proj=True):
"""
参数:
summary_type: 字符串, "last", "first", "mean", 或者 "attn"
use_summ_proj: bool, 是否在pooling的时候做一个线性投影变换
返回:
float32 Tensor in shape [bsz, d_model], the pooled representation.
"""
xlnet_config = self.xlnet_config
run_config = self.run_config
with tf.variable_scope("model", reuse=tf.AUTO_REUSE):
summary = modeling.summarize_sequence(
summary_type=summary_type,
hidden=self.output,
d_model=xlnet_config.d_model,
n_head=xlnet_config.n_head,
d_head=xlnet_config.d_head,
dropout=run_config.dropout,
dropatt=run_config.dropatt,
is_training=run_config.is_training,
input_mask=self.input_mask,
initializer=self.initializer,
use_proj=use_summ_proj)
return summary
我们这里调用是传入的summary_type是”last”,也就是得到最后一个Token(CLS)最后一层的输出,我们认为CLS编码了整个输入的语义。这个函数的主要代码是调用modeling.summarize_sequence。
modeling.summarize_sequence
def summarize_sequence(summary_type, hidden, d_model, n_head, d_head, dropout,
dropatt, input_mask, is_training, initializer,
scope=None, reuse=None, use_proj=True):
with tf.variable_scope(scope, 'sequnece_summary', reuse=reuse):
if summary_type == 'last':
# 返回最后一个Token的隐状态
summary = hidden[-1]
elif summary_type == 'first':
summary = hidden[0]
elif summary_type == 'mean':
summary = tf.reduce_mean(hidden, axis=0)
elif summary_type == 'attn':
# 对最后一次的所有输出再用一个self-attention进行编码,然后返回第一个位置的结果。
bsz = tf.shape(hidden)[1]
summary_bias = tf.get_variable('summary_bias', [d_model],
dtype=hidden.dtype,
initializer=initializer)
summary_bias = tf.tile(summary_bias[None, None], [1, bsz, 1])
if input_mask is not None:
input_mask = input_mask[None, :, :, None]
summary = multihead_attn(summary_bias, hidden, hidden, input_mask,
d_model, n_head, d_head, dropout, dropatt,
is_training, initializer, residual=False)
summary = summary[0]
else:
raise ValueError('Unsupported summary type {}'.format(summary_type))
# use another projection as in BERT
if use_proj:
summary = tf.layers.dense(
summary,
d_model,
activation=tf.tanh,
kernel_initializer=initializer,
name='summary')
# dropout
summary = tf.layers.dropout(
summary, dropout, training=is_training,
name='dropout')
return summary
regression_loss
有了CLS最后的输出,构造回归的loss代码就非常简单了。
def regression_loss(hidden, labels, initializer, scope, reuse=None,
return_logits=False):
with tf.variable_scope(scope, reuse=reuse):
logits = tf.layers.dense(
hidden,
1,
kernel_initializer=initializer,
name='logit')
logits = tf.squeeze(logits, axis=-1)
loss = tf.square(logits - labels)
if return_logits:
return loss, logits
return loss
至此,fine-tuning的代码介绍完毕。
最后我们再来对比一下XLNet的pretraining和fine-tuning的区别。
pretraining和finetuning的区别
pretraining是XLNet最大的创新点,它通过不同顺序的语言模型分解方法来学习各种上下文信息。
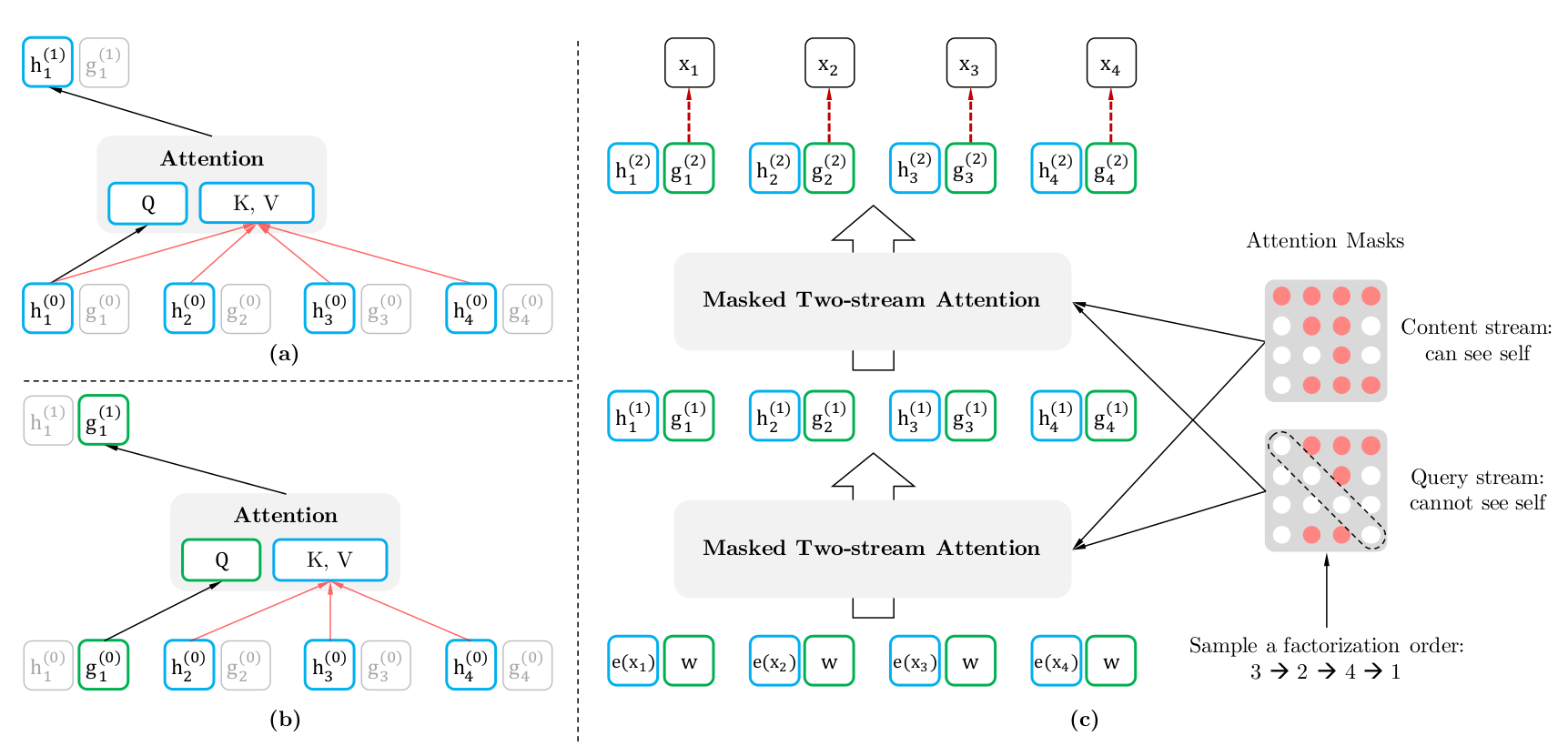 图:Two Stream排列模型的计算过程
图:Two Stream排列模型的计算过程
图的左上是Content流Attention的计算,假设排列为$3 \rightarrow 2 \rightarrow 4 \rightarrow 1$,它对应$P(X)=P(x_3)P(x_2 \vert x_3)P(x_4 \vert x_3,x_2)P(x_1 \vert x_3,x_2,x_4)$这种概率分解方法。
Content Stream类似于Transformer的Decoder:编码第3个Token的时候只能参考它自己的内容(第3行的Mask让它只能参考它自己);编码第2个Token的时候参考第3和第2个Token;编码第4个Token可以参考第2、3和4个Token;而编码1的时候可以参考所有的Token。
Query Stream根据上下文和位置来预测当前Token:首先预测第3个位置的Token(没有任何Token可以参考);然后根据第3个位置的Token预测第2个位置的Token;再根据第3和第2个位置的Token预测第一个位置的Token;最后根据2、3和4个位置的Token预测第1个位置的Token。当然,在实际的pretraining时,前面的预测第3个位置的Token没有太大意义,因为信息量太少,所有一般只让模型预测后面的Token(比如只预测第4和第1个Token)。在前面的代码我们也可以看到,实际的Mask和上图是有一些区别的,实际的Mask我们让第3和第2个Token都可以看到它们自己(第3和第2个Token),这样让它们把第3和第2个Token的语义都编码出来。具体代码可以参考perm_mask。
因为排列方式时随机的,所以XLNet模型能够学习各种方式的概率分解,从而可以利用各种上下文组合来编码一个Token的语义。
而在fine-tuning的时候,我们只使用Content Stream,并且Mask为全为0,这样每个Token都可以attend to其它所有的Token。细心的读者可能会问:fine-tuning的时候只用Content Stream,这和BERT还有什么区别呢?从fine-tuning的角度来说,确实是和BERT一样的——用整个输入的所有Token来编码当前Token的语义。但是因为在Pretraining的时候我们做了Mask,因此某个Attention head学到的是根据第3和第4个词来预测第1个词,而另外一个Attention head可能学到的是根据第2和第5个词来预测第1个词。
XLNet的代码分析就介绍完了,感谢关注!
- 显示Disqus评论(需要科学上网)