本文是论文ZeRO: Memory Optimizations Toward Training Trillion Parameter Models的解读。
目录
- Abstract
- Extended Introduction
- 相关工作
- 内存都去哪了?
- ZeRO:洞察和概览
- Deep Dive into ZeRo-DP
- Deep Dive into ZeRO-R
- ZeRO-DP的网络通信分析
- ZeRO-R的通信量
- 实验
- ZeRO-DP的补充信息
Abstract
训练大的模型越来重要,但是当前(这篇论文发表时)的数据并行和模型并行训练方法存在很多问题,无法把大的模型放到有限的显存里,同时还保持较高的性能。本文提出了Zero Redundancy Optimizer(ZeRO)来优化内存,不但可以更快的训练模型,而且还可以训练更大的模型。ZeRO消除了数据并行和模型并行中的冗余内存使用同时维持较低的网络通信和较大的计算粒度,从而让我们通过增加GPU就可以近乎线性的横向扩展系统的性能。
Extended Introduction
随着模型越来越大,训练这些模型面临很大的挑战——这些大模型显然无法放到一个设备(比如GPU或者TPU)上,因此简单的增加设备并不能扩展。基本的数据并行(Data Parallelism, DP)不能减少每个设备的内存,在32GB的先看上训练1.4B的模型就会OOM。其它的方法比如流水线并行(Pipeline Parallelism, PP)和模型并行(Model Parallelism, MP),CPU-offloading等,都必须在功能、可用性、内存和计算/通信效率上做出权衡。但是这些因素对于训练速度和规模都同样重要。
在这些现存的解决方案中,MP可能是最有前景的。当前(2019)最大的模型是11B的T5模型,Megatron-LM 8.3B等都是用MP。但是MP的扩展能力也就到此为止了。MP垂直的切分模型,把每一层的参数和计算划分到多个设备上,【每一层都需要all-gather】,因此需要大量的通信。它适合GPU间通信速度非常块的单机【GPU之间两两都可能有nvlink连接】,但是当机器变多时,效率就急剧下降。我们测试了40B的Megatron-LM,使用的是2台DGX-2服务器,发现每个V100卡只有5TFlops(这是硬件峰值的5%)。
怎么解决这些问题呢?为了得到答案,我们分析了现存系统内存的使用情况并且把它们分成两类:1) 对于大模型,内存的主要部分用于模型状态(model states)包括优化器的状态(比如冲量和方差),梯度和参数。2) 其余的内存包括激活,临时缓存和不可用的内存碎片,我们把这些成为residual状态。我们开发了ZeRO——Zero Redundancy Optimizer——来优化这两类内存的利用效率从而获得很高的计算和通信效率。下面我们来看看这两类问题是什么以及怎么解决。
优化模型状态占用的内存
训练时模型状态占用了大部分内存,但是现存的方法不过是DP还是MP都没有提供令人满意的解决方案。DP的计算/通信效率很高,但是内存的效率很低。具体来说,DP会把整个模型状态都复制到每一个计算设备上,这就导致了冗余的内存使用。而MP通过划分使得不同设备只保存部分模型状态,但是由于划分过于细粒度,从而导致计算效率不高。基于如上观察,本文提出了ZeRO-DP,它通过划分模型状态到不同设备从而节约内存,同时保持计算的粒度从而提供计算/通信效率。ZeRO-DP分为3个主要的优化阶段,分别对应优化器状态、梯度和参数的划分。
- 优化器状态划分($P_{os}$):4倍内存的减少,通信量和DP一样
- 增加梯度划分($P_{os+g}$):8倍内存的减少,通信量和DP一样
- 增加参数的划分($P_{os+g+p}$):内存的减少和并行度$N_d$成线性关系。
- 比如总共有64个GPU($N_d=64$),那么就会减少64倍内存。但是通信量会增加50%。
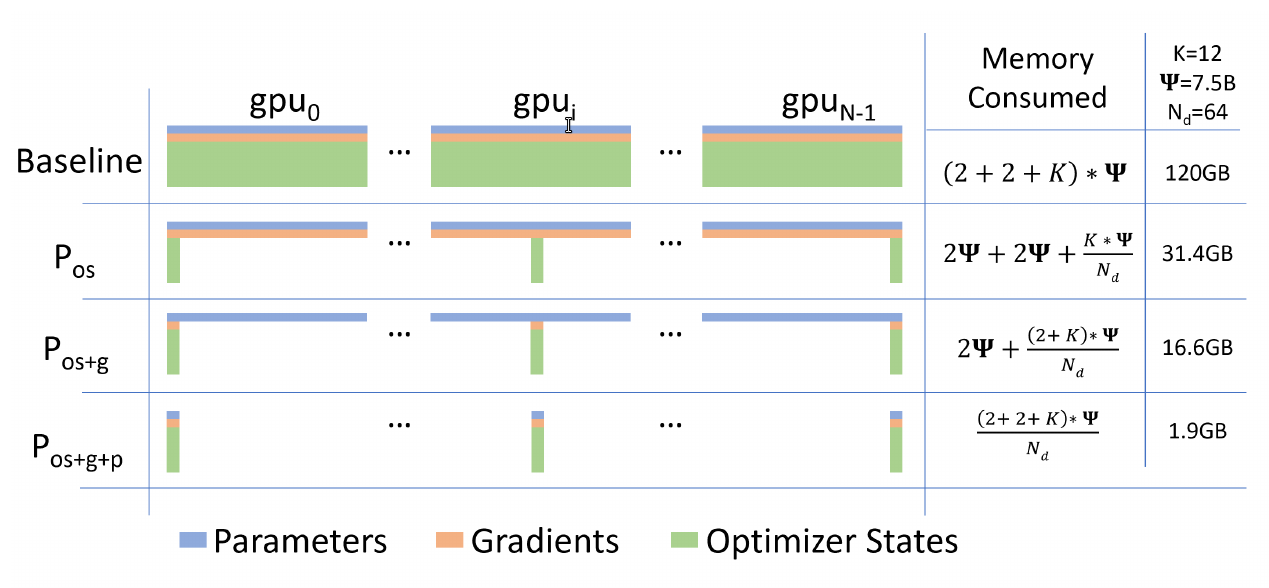
上图的例子中,假设模型的参数$\Psi=7.5B$,$N_d=64$,并且假设K是优化器状态的内存乘子,对于Adam来说是$K=12$。 对于Baseline(DP)来说,每个GPU都需要保存全部的参数、梯度和优化器状态,假设都用float16,因此总内存是$(2+2+K)* \Psi$。对于上面的具体数值就是120GB。 对于$P_{os}$来说,它把$K * \Psi$的内存划分到$N_d$个GPU上,因此每个GPU上的内存为$2\Psi+2\Psi+\frac{K* \Psi}{N_d}$,代入上面的值就是31.4GB。对于$P_{os+g}$来说,它把$K * \Psi + 2 * \Psi$的优化器状态和梯度划分到$N_d$个GPU上,每个GPU为$2\Psi + \frac{(2+K)* \psi}{N_d}$,这里的具体值为16.6GB。最后$P_{os+g+p}$把所有的状态都划分,因此每个为$\frac{(2+2+K)* \Psi}{N_d}$,这里的例子就是1.9GB。
优化Residual状态内存
当ZeRO-DP解决了模型状态的内存效率之后,Residual状态就成了第二个瓶颈。我们开发了ZeRO-R来优化Residual状态。
-
对于激活(前向计算结果用于后向梯度计算),activation checkpoint有帮助但是对于大模型来说还不够大。因此ZeRO-R会找出并且移除重复的激活并且对它们进行划分。另外在需要的时候也会把激活offload到CPU上。
-
ZeRO-R为临时缓存定义合适的大小,从而使得内存和计算效率达到平衡。
-
我们发现内存碎片的主要原因是不同的tensor的生命周期不一样。ZeRO-R会基于不同tensor的生命周期来管理内存,避免碎片。
ZeRO和MP
既然ZeRO解决了DP的内存效率问题,那么MP是否还有必要?对于大模型来说,MP变得没有那么有吸引力了。因为ZeRO-DP的内存效率和MP差不太多,但是它比MP更高效——尤其式子MP没有办法均匀的切分模型时。此外,DP对于使用者来说非常简单,而为了MP,开发者可能需要对他们的代码进行修改。
虽然这么说,不过还是有一些case需要MP的:i) 当和ZeRO-R一起使用,MP可以减少超大模型的激活内存。 ii) 对于小模型,DP需要的batch可能太大,从而导致无法收敛,而MP没有batch大小的要求。我们证明了ZeRO可以和MP组合起来,达到理论的$N_d \times N_m$倍的内存减小。这使得我们可以在1024个GPU上进行16路模型并行和64路数据并行,从而训练1t参数的模型。
实现和评估
虽然用目前(2019年)最好的硬件(1K个V100 GPU)可以训练1t参数的大模型,但是时间太长(>1年)。因此我们的重点是支持100B参数的模型。我们实现和评估了ZeRO-100B——$P_{os+g}$+ZeRO-R。结果显示:
模型大小
结合MP,ZeRO-100B可以跑170B参数的模型,而显存的系统比如Megatron在超过40B后就无法扩展了。
速度
高效的内存管理提升了训练的速度和吞吐量。如下图所示,ZeRO在400个V00的集群上能够跑100B的模型能够达到每个38TFlops/GPU,从而整个集群的性能达到15 PFlops。这比SOTA提升了10倍。
扩展性
在64-400个GPU的区间,我们的系统实现了超线性的扩展。一般而已,增加一倍机器最多只能让计算加速一倍(没有任何串行的损耗),但是由于机器增多后单个节点的显存占用量变少了,从而有更多的显存用于计算,所以机器多了之后单机的性能还能再提升。
LLM训练的平民化
我们可以让研究者单机就能训练13B的模型,这不需要MP或者PP(流水线并行),从而不需要修改代码。而其它系统比如PyTorch的DDP在1.4B的模型就OOM了。
新的SOTA
相关工作
数据并行、模型并行和流水线并行
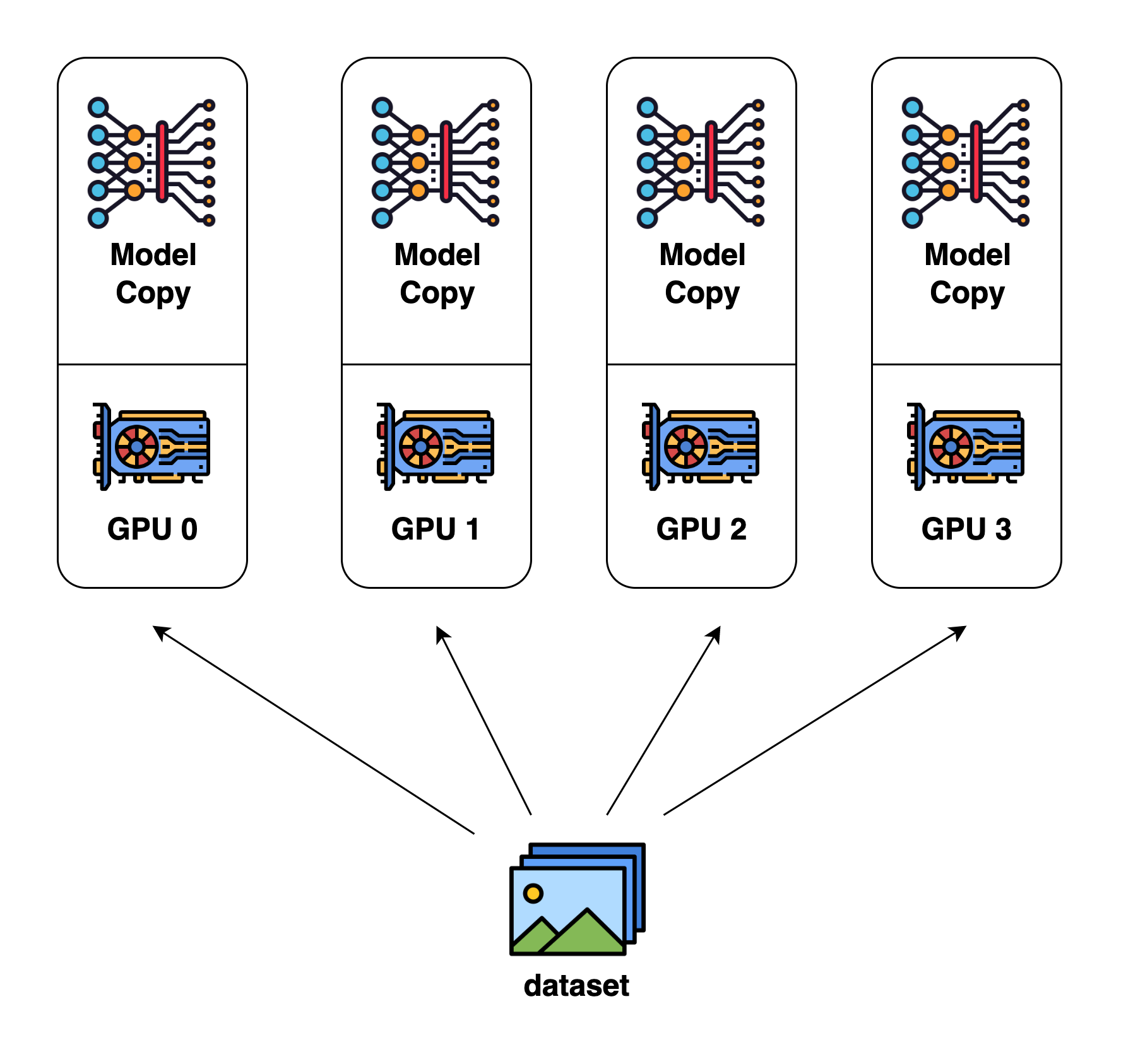
当模型可以放到一台设备上时,数据并行(DP)是最简单的并行方法。在DP里,模型参数会复制到每个设备上,每一步,一个mini-batch的数据会平均的切分成所谓的micro-batch到每台设备,最后通过all-reduce把梯度平均并且分发到所有机器。
数据并行如下图所示:
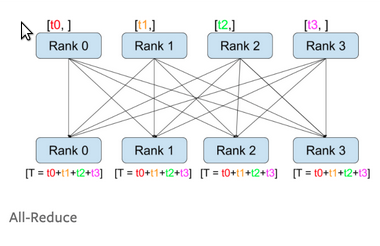
all-reduce操作如下图,比如每个机器都计算了各自micro-batch的梯度,然后需要加起来,然后分发给每台机器。这样每台机器用相同的梯度更新参数,从而保持同步。
当模型太大无法放到一台设备的内存中时,模型并行和流水线并行会把模型切分到不同的设备上。其中模型并行是垂直的切分方式(竖着把一层切成很多小块),而流水线并行是水平的切分,为了避免限制,通常把一个mini-batch切分多个micro-batch,从而把闲置的资源利用起来。
模型并行如下图所示:
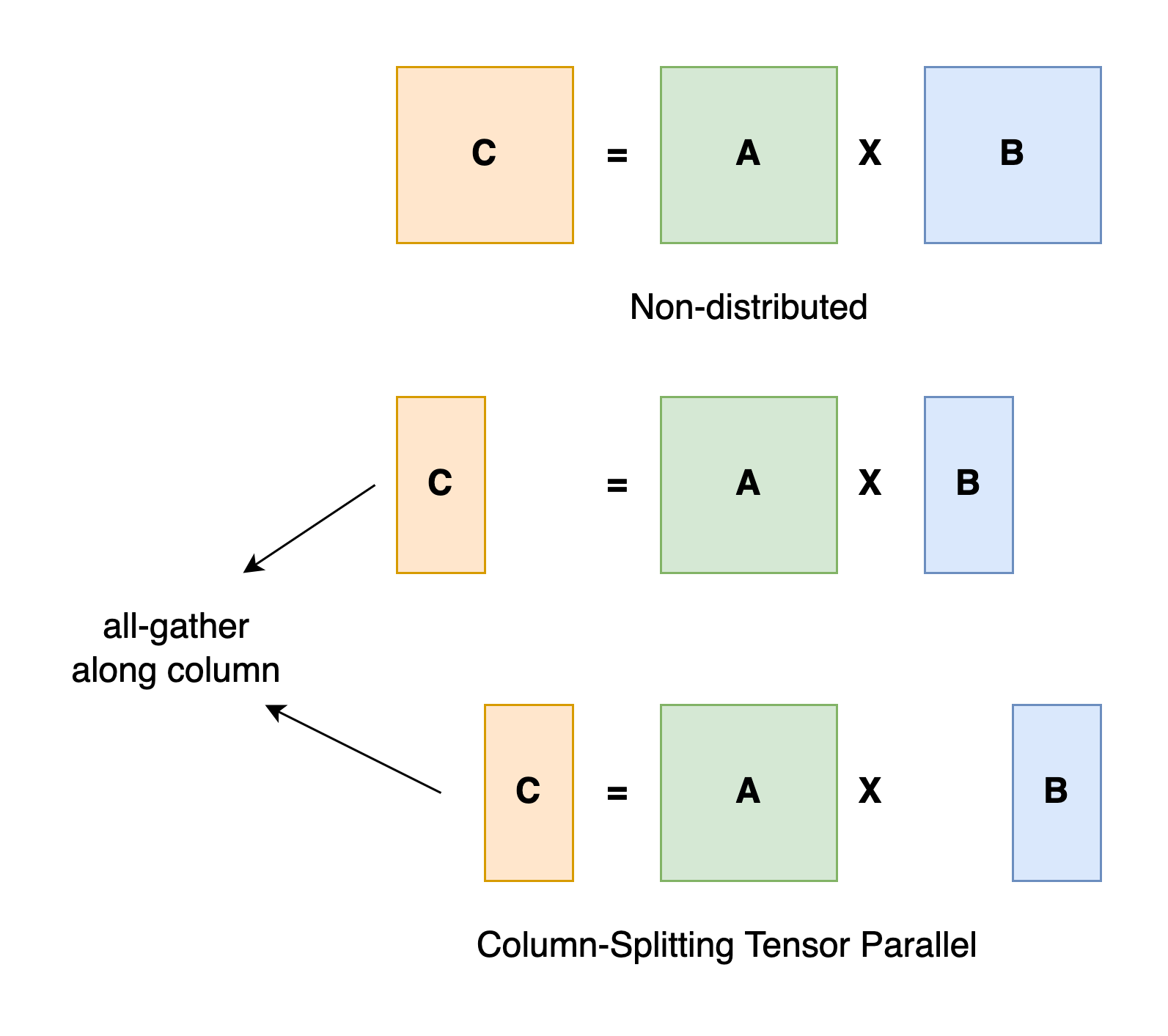
它垂直切分第二个矩阵,从而使得 $AB = A \times [B_1, B_2] = [AB_1,AB_2]$。
没有优化的水平模型并行如下:
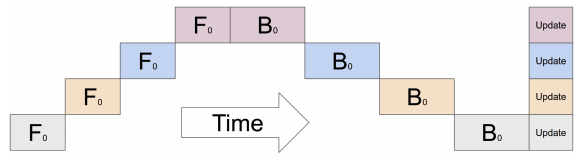
我们可以发现每次只有一个设备在计算,其余的设备都在闲置。而流水线并行如下图所示:
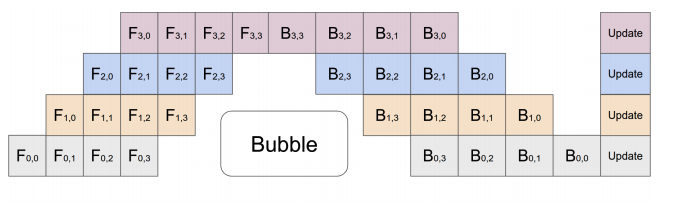
我们可以发现,第一个设备在计算$F_{0,0}$,这个时候大家都在等着,但是当第一个设备计算完后在第二个设备计算$F_{1,0}$的时候,第一个设备没有闲着,它开始计算第二个micro-batch的$F_{0,1}了。类似的,当第三个设备计算$F_{2,0}$的时候,第一个设备开始计算第三个micro-batch而第二个设备计算第二个micor-batch。
PP的效率虽然比MP高,但是由于水平切分,有些操作如batch-norm无法简单的实现。
减少内存的非并行方法
减少激活内存
常见用于减少激活内存的方法包括压缩、激活检查点(activation checkpointing)和存活分析(live analysis),这些技术和ZeRO是并行的,ZeRO也可以利用这些技术。因为后面会提及,我们这里稍微介绍一些激活检查点技术。它也被叫做梯度检查点(gradient checkpoint),但这其实不对,因为保存的是激活函数的结果。
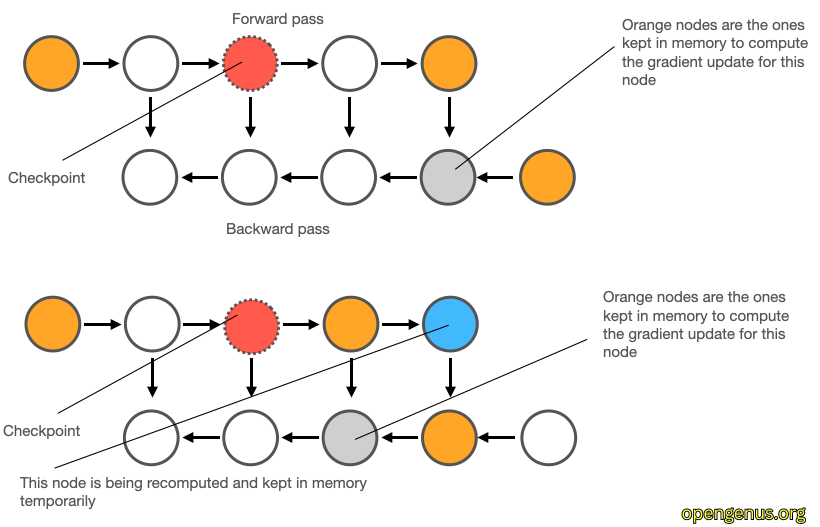
如上图,我们在前向的时候假设计算出3个激活,为了节省空间,我们只保留中间那个橘红色的。到了反向时需要最后那个蓝色的激活,这个时候就可以根据橘红色的重新计算。这其实是一种用时间换空间的策略。
CPU Offload
当GPU内存不够时,可以把它们offload的CPU内存,然后需要的时候再加载进去。
更加内存友好的优化器
像Adam这样的自适应优化器比较鲁棒,但是占用的内存也比较大。研究节省内存的优化器也能减少内存。不过这些方法也是和ZeRO并行的,因为不管怎么样,模型的参数和梯度总是需要的,而且即使优化器的状态占用更少的内存,通过ZeRO也能使它们变得更小。
内存都去哪了?
模型状态:优化器状态、梯度和参数
大部分内存都用于模型状态。比如Adam优化器,它会保存两个状态:i)时间平滑的冲量(momentum) ii) 梯度的方差。
SOTA的模型都使用混合精度训练,这样可以用速度更快的fp16运算替代fp32运算,而且还可以利用GPU(V100之后)的tensorcore来加速16位的梯度更新。在混合精度训练里,在前向之前会把fp32的模型的参数转换成fp16,然后计算fp16的激活,接着计算fp16梯度,最后把fp16更新到fp32的参数里,同时优化器更新fp32的状态(冲量和方差),具体如下图所示:
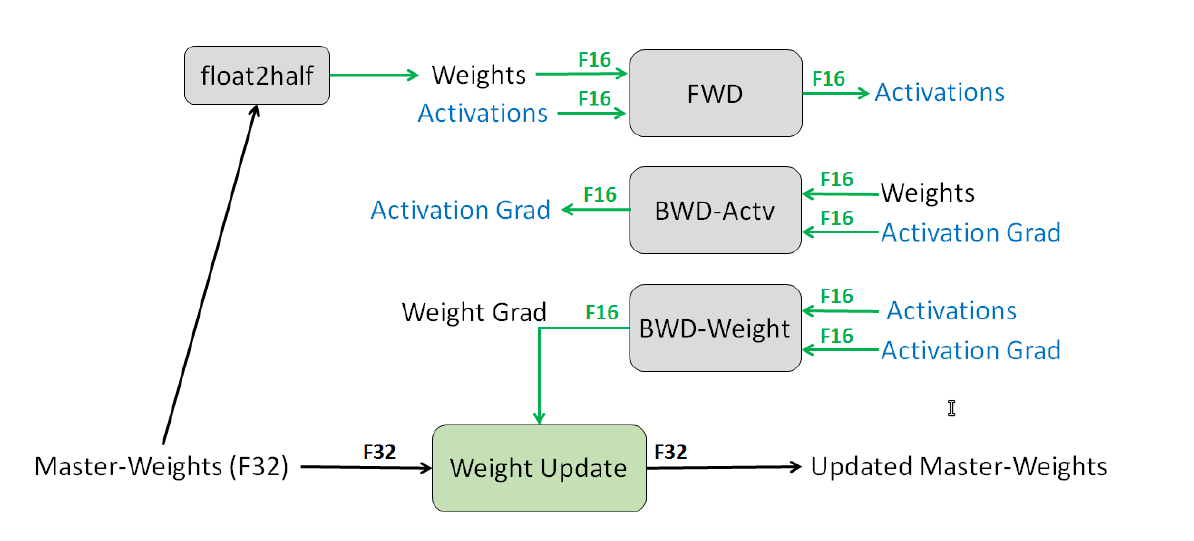
关于TensorCore这里我们就不介绍了,有兴趣的读者可以参考Understanding Tensor Cores,后面我们有空再单独介绍。我们现在只需要知道它是一个专用于fp32 <- fp16 x fp16 + fp32的Cores,而且一次可以计算多个(比如V100一次计算4x4)。很显然,这非常适合于fp16的梯度的更新参数。另外要回答的问题是为什么可以用fp16替代fp32而不会降低训练的效果(现在甚至有fp8/fp4的训练),这里也不介绍,感兴趣的读者请参考Mixed Precision Training。本篇文章这里我们只讨论内存相关的话题。下面我们来计算一下Adam基于混合精度训练需要的内存。
假设模型的参数为$\Psi$,首先它需要fp16的参数拷贝和fp16的梯度,这需要$2\Psi + 2\Psi=4\Psi$ 个byte。此外,它需要保存fp32的master参数、冲量和方差,这3个量都需要$4\Psi$的内存。假设K是优化器状态的内存乘子,那么Adam的$K=12$,总共需要$4\Psi+K\Psi=16\Psi$ 个byte。如果是GPT-2模型,它有1.5b参数,则总的内存是$16 \times 1.5b bytes=24GB$。
Residual内存
激活
训练时激活也会占据大量内存。比如1.5B的GPT-2,在batch是32,序列长度为1k时的激活是60GB。使用Activation checkpointing技术,这是一种时间换空间的方法,也就是不保存全部激活,而是在需要的时候重新计算。这可以把激活内存降低到8GB,但是代价是增加了33%的计算量。
临时缓冲区
比如梯度的all-reduce操作,它需要把来自其它节点的梯度收集过来一起计算,这些内存也不小。梯度虽然可以用fp16,但是有些计算可能需要fp32。比如1.5B参数的模型,可能需要6GB的缓冲区。
内存碎片
由于内存都是动态申请和释放,这会造成很多碎片。在大模型训练时尤其严重,我们(论文作者)在极端的情况下发现30%内存剩余的情况下仍然OOM的例子。
ZeRO:洞察和概览
ZeRO有两个优化目标:i) ZeRO-DP优化模型状态的内存 ii) ZeRO-R减少residual内存。注意:我们优化的目标是要保留计算的效率,因此简单的把GPU内存缓存到CPU上这种方案就没有意义(也是有意义的,这就是下文的ZeRO-offload,当然要在尽量保存效率的情况下做offload)。
ZeRO-DP
ZeRO-DP主要有3个关键洞察:
a) DP比MP的效率更高是因为MP降低了计算的粒度并且增加了通信。
b) DP的内存效率很低,因为每个设备都拥有一份完整的参数拷贝,而MP通过划分,使得每个设备只有部分参数。
c) DP和MP都会保留完整的优化器状态和梯度,但是在计算的某些阶段并不需要完整的数据。
基于以上洞察,ZeRO-DP能够在保持训练效率的同时降低内存的使用。这是怎么做到的呢?ZeRO-DP会把模型状态也进行划分而不是完整的复制(具体参考下一节)并且使用动态通信机制来利用模型状态内在的时间特性从而减少通信量(参考后面的章节)。
ZeRO-R
减少激活内存
两个关键洞察:
a) MP会划分模型状态,但是通常需要复制激活。比如我们把一个层切分到两个GPU上,那么最后需要通过all_gather让每个GPU都获得完整的激活才能进行下一步,具体参考上图。
b) 对于GPT-2或者更大的模型,算术强度(arithmetic intensity,定义为每次迭代的计算量除以每次迭代的activation checkpoint数)非常大。并且是随着隐单元的大小线性增长,这使得即使带宽非常有限时主要的瓶颈也是在计算而不是内存传输。
ZeRO通过划分消除MP里的激活冗余,并且在需要的时候通过allgather操作重新获得完整拷贝。因此激活内存随着MP并行度的增加而成比例下降。对于特别大的模型,ZeRO甚至可以把激活offload到CPU上。
管理临时缓冲区
ZeRO-R使用固定大小的缓冲区,避免临时缓冲区太大。
管理碎片
内存碎片是由于短期存活的内存对象和长期存活的内存对象的交织造成的。在前向阶段,激活checkpoint是长期存活的,而重新计算的激活是短期的。相似的,在反向阶段,激活梯度是短期的而参数的梯度是一直要保留的。基于如上洞察,ZeRO进行on-the-fly的内存碎片整理:把长期存活的激活checkpoint和梯度放到连续的内存缓冲区里。
Deep Dive into ZeRo-DP
$P_{os}$:优化器状态划分
对于并行度为$N_d$的DP,我们把优化器的状态划分成$N_d$份,每个设备值保留一份内次,这样的话每个设备只需要保存和更新$\frac{1}{N_d}$的状态和参数。最后通过allgather操作来使得每个设备获得完整的参数以便进行下一轮计算。
通过这个方法,我们可以把内存从$4\Psi+K\Psi$变成$4\Psi+\frac{K\Psi}{N_d}$。比如7.5B参数的模型,原始的DP需要120GB内存,而$P_{os}$只需要31.4GB。如果$N_d$足够大,那么$4\Psi+\frac{K\Psi}{N_d} \approx 4\Psi$。也就是从$16\Psi$降到$4\Psi$,实现4倍的内存减少。
$P_{g}$:梯度划分
类似的,每个设备不需要完整的梯度来更新参数,它只需要保留它那一份梯度。注意:在这个阶段,参数还是没有划分,这要等到下一个阶段才会切分,不过这不妨碍每个人只计算更新部分参数,然后通过all-gather来拷贝。注意:在混合精度训练里,我们把fp32的参数叫做优化器的状态,而拷贝的fp16才叫做用于计算的参数。fp32的参数在上一步就以及切分了。
通过梯度划分,每个设备的内存变为$2\Psi + \frac{14}{N_d} \approx 2\Psi$。这相比原始的DP实现8倍的内存减少。
$P_{p}$:参数划分
最后一个阶段,我们把用于计算的fp16也可以进行划分,不过这样每一层前向计算都需要通过allgather收集完整参数。计算效率会下降。当然如果碰到特别大的模型,比如Llama 2 70B,光计算参数就是140GB,不可能放到一台设备上,那么就需要这个阶段的划分。否则还是尽量不要用。
通过这个方法,内存进一步降低$\frac{16\Psi}{N_d}$。比如7.5B的模型在$P_{os+p+g}$后如果进行64路DP,那么单卡的内存只有1.9GB。
模型大小
上面讲得很抽象,我们拿一些具体的例子看一下三种划分策略可以节省的内存。
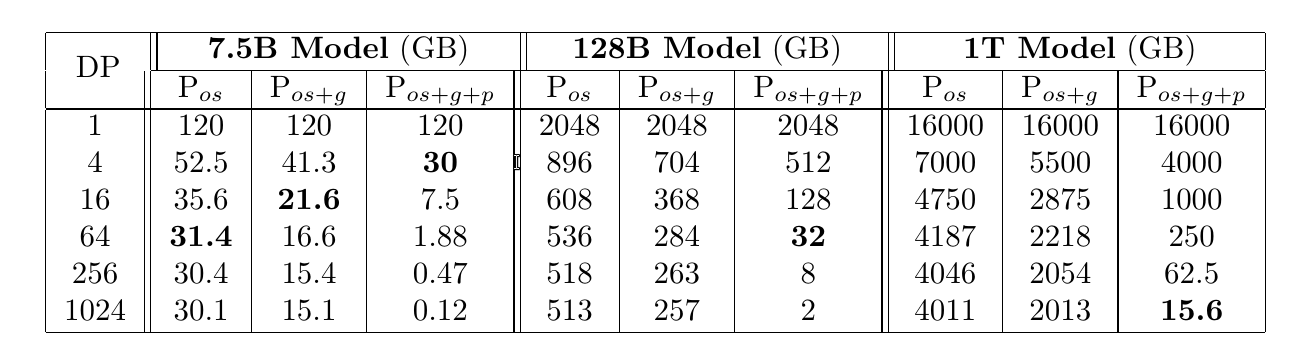
上面的表格很清楚,不过我想补充一点,那就是标粗的部分。比如7.5B的模型,64张卡就可以使得$P_{os}$的单卡内存在32GB以内(当时最好的V100只有32GB内存),因此如果你有64张V100,那么用$P_{os}$是效率最高的。当然你说我没那么多卡,我只有16张V100,那么你可以使用$P_{os+g}$。你要抬杠说我只有4张,那么可以用$P_{os+g+p}$,当然这是最慢的(单机效率)。当然你想训练128B的模型,那你就不可能用$P_{os}$或者$P_{os+g}$了,因为光是计算的fp16参数就是256GB里。你至少得有64张V100。或者你再等几年,等英伟达造出512GB显存的卡才行。(另外一条路是fp8/fp4训练,目前还在探索阶段。另外还有一条路就是cpu offload,后面会讲) 最后如果你想训练1T参数的模型,那么你至少得1024张v100。
补充一点,现在大家一般把$P_{os}$叫做ZeRO-stage1,$P_{os+g}$叫做ZeRO-stage2,$P_{os+g+p}$叫做ZeRO-stage3。
当然现在的A100和H100都是80GB最大显存,但是基本计算原则是类似的。
Deep Dive into ZeRO-R
$P_a$:划分激活checkpoint
前面介绍过,MP有冗余的激活。ZeRO会把激活也划分成$N_d$个小块分给每个设备。当需要的时候再通过all-gather操作收集完整的。我们把这个优化版本叫做$P_a$,它是完全与激活checkpoint兼容的。也就是说如果不使用激活checkpoint,那么每个设备的激活是总激活的$\frac{1}{N_d}$。如果我们使用激活checkpoint,每隔M层保留一个checkpoint,那么每个设备的激活内存降低$\frac{1}{N_dM}$。
另外如果模型超级大,我们还可以把激活的checkpoint给offload到cpu上,这个版本叫$P_{a+cpu}$。在我们训练100B模型的例子里,假设batch大小是32,序列长度是1024,MP的并行度是16,我们每个Transformer层只保留一个激活的checkpoint,这会消耗33GB的内存(光这就超过了V100的显存)。通过使用$P_a$,我们是它降到$33/16 \approx 16$GB。如果使用CPU offload,那么显存里的激活几乎是零。
$C_B$:常量缓冲区
ZeRo会精心选择临时缓冲区的大小使得内存利用率和计算效率达到平和。在训练阶段,缓冲区越大越好,比如allgather的缓冲区,当然是越大越能利用好网络带宽,但是内存可能hold不住。比如3B的模型,32位的buffer就需要12GB内存。因此我们使用了固定大小的缓冲区,在保证网络效率的同时也别把内存撑爆了。
$M_D$:内存碎片
内存碎片来自于激活checkpoint和梯度计算。在前向阶段,我们会计算所有的激活,但是只有少部分checkpoint的会长期留存,其它的就扔了并且在反向时重新计算。这会让很多长期存活和短期存活的对象混杂在一起。类似的,在反向阶段,激活的梯度是短期的,而参数的梯度是长期的。这也会造成大量碎片。
少量的碎片问题不大,但是大量碎片会导致两个问题:i)即使还有内存也OOM,因为没有连续的大内存可用。ii)效率问题,任何内存都是局部访问效率更高,因为不过是CPU还是GPU内部都有缓存,如果两次访问的地址相差太远,效率也会降低。
ZeRo会on-the-fly的整理碎片,并且把激活checkpoint和参数梯度复制到预留的连续区域。
ZeRO-DP的网络通信分析
虽然ZeRO-DP减少了内存,但是会不会增加网络通信呢?答案分为两部分:i)$P_{os}$和$P_g$不会增加网络开销,同时可以达到8倍的内存减少。ii) 当对参数进行分片也就是$P_p$会增加网络通信。下面我们来分析一下ZeRO-DP的网络开销。
DP的通信量
DP只有在最后需要一次allreduce来同步梯度,它的通信量是$2\Psi$。我们用图例来说明。首先看什么是allreduce:
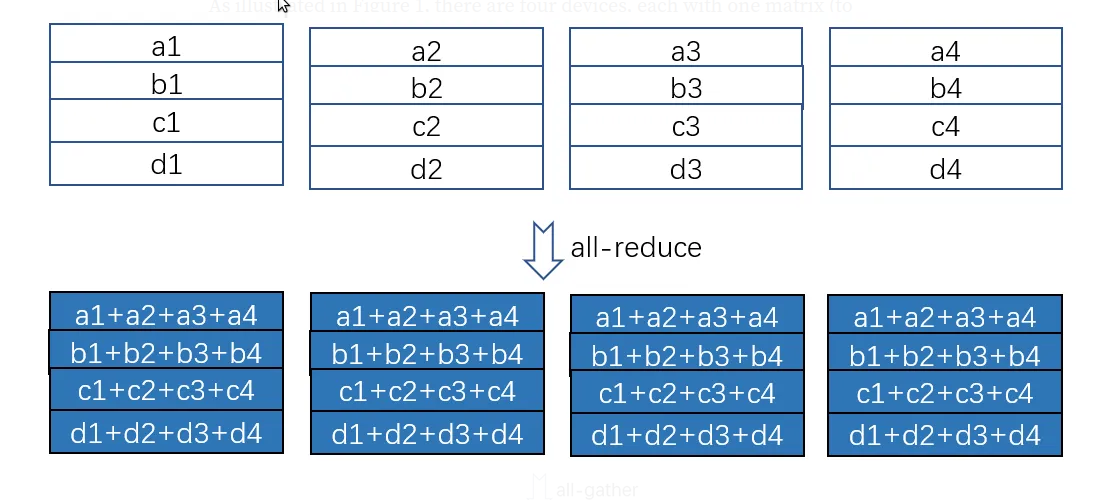
如上图所示,假设有4个worker(GPU),参数也被切分成四块(a,b,c,d),因此每个worker都会计算梯度。比如上图第一个worker计算出(a1,b1,c1,d1),第4个worker计算出(a4,b4,c4,d4)。现在我们需要对每一块reduce(求和),那么最笨的方法就是把2~4个worker的参数都传给第一个worker,然后它可以计算出所有的4个和(a1+a2+a3+a4, b1+b2+b3+b4, c1+c2+c3+c4, d1+d2+d3+d4)。同样的,我们可以把124这3个worker的参数传给第2个worker……。这样对于每个worker来说,它需要接受的数据是$(N_d-1)\times \Psi$个参数。
聪明的读者肯定会说,这也太笨了,第一个人算完了把结果复制给剩余的人就行了,没有必要让其余3个人做重复工作。没错,这样可以减少网络开销。但是有一个问题:活都让第一个人干,其余的人都干等着看笑话,第一个人心理不满还算了,关键它效率低啊。因此好的方法是:把a相关的量都发给第一个人来算;把b相关的发给第二个人来算;……。这样每个人都领一样多但又不重合的活,最后大家再分发出去就行了。这就是allreduce的实现方法:分为reduce-scatter和all-gather两步。我们还是用图来说明:
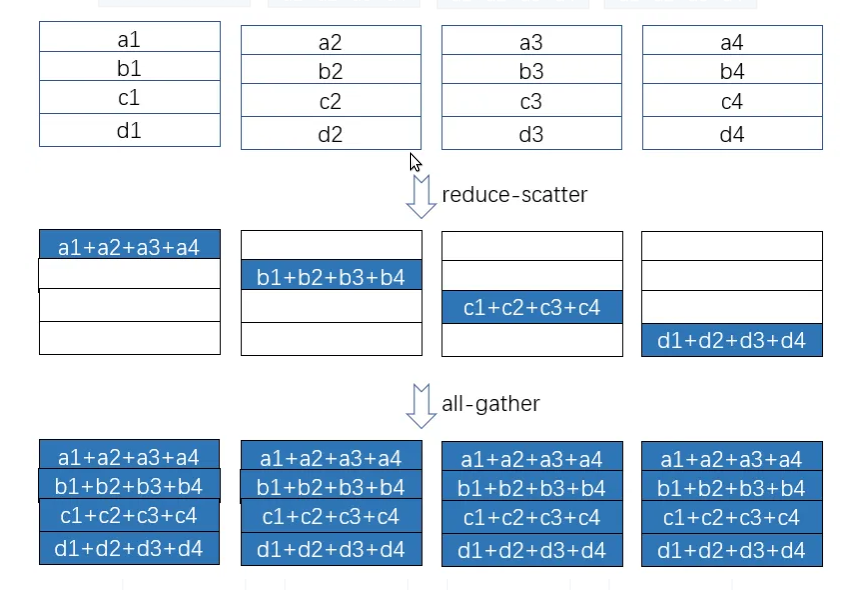
如上图所示,在reduce-scatter阶段,第一个worker需要收到$(N_d-1)\frac{\Psi}{N_d}$个变量,同时它也要发送这么多。如果我们假设网络是全双工的,那么只考虑发送就行,因此需要发送$(N_d-1)\frac{\Psi}{N_d} \approx \Psi$个变量。类似的,在第二个阶段,也需要发送和接收$(N_d-1)\frac{\Psi}{N_d}$个变量。因此需要的网络带宽大致是$2\Psi$。注意,我们需要高效的实现才能重复利用网络。比如不能在第一步2~4这三个worker都往第一个发,让它忙不过来,后面又没有数据可发。因此需要使用ring communication来优化,使得每次每个worker都只接受一个其它worker的数据。感兴趣的读者可以参考How to derive ring all-reduce’s mathematical property step by step。
ZeRO-DP的通信量
$P_{os+g}$的通信量
每个worker只计算并保存$\frac{1}{N_d}$的梯度,而不需要所有的梯度。因此它只需要第一步scatter-reduce就行,比如第一个worker只计算(a1+a2+a3+a4)并保存,不需要把这个结果发给另外3个人。所以它的通信量是$(N_d-1)\frac{\Psi}{N_d} \approx \Psi$。但是到每个worker更新参数的时候,还是需要把梯度allgather起来的,所以后面还是有$(N_d-1)\frac{\Psi}{N_d} \approx \Psi$的通信。所以加起来还是$2\Psi$。和DP一样。
$P_{os+g+p}$的通信量
计算的参数划分之后,每个worker只负责它那部分的参数更新。因为前向是分为$N_d$次进行了,每次只有一个worker都需要广播自己的参数给其它人,也就是$\frac{\Psi}{N_d}$。但是需要广播$N_d$次,因此也是$(N_d-1)\frac{\Psi}{N_d} \approx \Psi$($N_d$次中有一次是自己给自己广播)。所以相比DP,会多出来$\Psi$的通信量,$P_{os+g+p}$的总通信量是$3\Psi$。是DP的1.5倍。不过多出来的通信量是分成$N_d$次进行的,而且是和计算同时进行,通常可以通过prefetch的方法(也就是在第一次计算的同时广播第二次的参数),所以对于整体的性能影响不大。
ZeRO-R的通信量
我们比较激活checkpoint划分($P_a$)和MP基线的通信量,并将证明$P_a$相比MP增加的通信量不会超过MP的10%。此外,我们还叫分析$P_a$相对DP的通信量的关系从而确定由于$P_a$使得内存减少从而可以用更大的batch能够抵消网络的开销。这样我们就能知道什么时候应该使用$P_a$或者$P_{a+cpu}$。
激活checkpoint带来的开销是否能通过减少内存从而使用更大batch,这依赖与模型的大小。我们这里用当前的SOTA Megatron-LM来做一个分析示例。
对于使用了激活checkpoint的Megatron-LM模型来说,每个Transformer块前向阶段需要执行2次allreduce。重新计算时也需要统一的两次all-reduce,另外反向计算还需要两次。总计6次allreduce。因为每次allruduce的通信量是2 × message_size = 2 × seq_length × hidden _dim,所以每个block总的通信量是12 × seq_length × hidden_dim。
当使用ZeRO-R来划分激活checkpoint时,需要在冲计算每个激活checkpoint时进行一次额外的all-gather操作。一般来说,我们每个block保存一次激活checkpoint,因此$P_a$多出来的通信量是seq_length × hidden_dim。所以$P_a$相比MP增加的通信量不会超过MP的10%。
当MP和DP一起使用是,$P_a$可以减少数据并行的通信量一个数量级以上($\frac{1}{N_{MP}$的激活内存,其中$N_{MP}$是模型并行度)。从而可以让模型跑更大的batch。对于大模型来说,MP的并行度可能是16。因此可以增加16倍的batch大小。因此16倍的batch大小可以降低16被的数据并行网络开销。【比如原来的batch是10,现在变成160,那么同样跑160个样本,原来需要做16次step,现在只需要一次,因此通信量降了16倍,但是计算量并没有降低】
最后,如果$P_{a+cpu}$被使用的话,被切分的激活checkpoint还可以offload到CPU上,从而让激活的内存使用接近零,这可以让我们跑更大的batch从而减少网络通信。当然CPU和GPU之间的数据复制也可能成为瓶颈。
实验
实验部分我就不啰嗦了,感兴趣的读者请阅读原文。
ZeRO-DP的补充信息
本论文注意讲了ZeRO-DP和ZeRO-R的思路,但是并没有讲细节。【细节也很重要,但是细节没法写到论文里】如果对于DP和并行计算不熟悉的读者可能还是不太清楚怎么把优化器状态、梯度和参数进行划分并且保证能够正确计算的。如果对这些细节感兴趣的读者可以参考ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters,里面有个视频可以仔细观看,讲得非常清楚,用文字描述比较困难,我就不赘述了。最好的办法当然是阅读其源代码。但是对于大部分人来说不太可能去修改它,因此了解原理知道什么时候该用什么方法就差不多了。
- 显示Disqus评论(需要科学上网)