本文是论文Foundation Models for Weather and Climate Data Understanding: A Comprehensive Survey的翻译。
目录
- Abstract
- Introduction
- 2 Related work and differences
- 3 背景和初步
- 4 天气和气候的基本结构
- 5 概览和分类
- 6 天气和气候的模型
- 7 应用
- 8 资源
- 9 挑战、展望和机遇
- 10 基础模型的Insight
- 总结
Abstract
随着人工智能(AI)的快速发展,地球和大气科学领域越来越多地采用数据驱动的模型,这些模型由深度学习(DL)的不断发展推动。具体而言,DL技术被广泛应用于解码地球系统的混沌和非线性方面,并通过理解天气和气候数据来应对气候挑战。最近通过DL在更窄的时空尺度内的特定任务上取得了创新性能。大型模型的崛起,特别是大型语言模型(LLMs),已经实现了可以产生显著结果的微调过程,从而推动了通用AI的进步。然而,我们仍在探索为天气和气候打造通用AI的初级阶段。在这项调查中,我们提供了对专门为天气和气候数据量身定制的最新AI方法的全面而及时的概述,重点关注时间序列和文本数据。我们的主要覆盖范围包括四个关键方面:天气和气候数据类型,主要模型架构,模型范围和应用以及天气和气候的数据集。此外,与创建和应用基础模型以理解天气和气候数据相关的领域的挑战,我们深入探讨了当前面临的挑战,并提出了未来研究的详细方案。这种全面的方法使从业者具备了必要的知识,可以在这一领域取得实质性进展。我们的调查概述了针对天气和气候数据理解的大型数据驱动模型的最新突破,强调了坚实的基础、当前的进展、实际应用、关键资源和未来研究机会。
Introduction
概念1 天气和气候是具有显著差异的概念,在空间和时间尺度、变异性和可预测性方面有着明显的区别。两者之间的不同可以阐明如下:
- 时间尺度。天气涉及大气条件的即时状态,通常在短期时间框架内。相反,气候代表了长期天气模式的统计摘要。
- 空间尺度。天气表示特定位置的大气条件,而气候则涵盖了在一个区域内在长时间内典型天气模式的全面摘要。
- 变异性。天气表现出快速而频繁的变化,而气候变化以更慢的速度发生,并包括天气模式的长期变化。
- 可预测性。天气预报专注于预测未来几天或更短时间尺度的天气条件。相比之下,气候预测旨在预测未来几个月到几十年的气候趋势。
气候变化描绘了全球气温和天气模式在长时间内的显著变化。目前,我们的星球正在经历极端自然现象的激增,例如干旱[1]、洪水[1]、地震[3]、热浪[4]和强降雨[5],这些现象都受到不断加剧的气候变化的推动。进一步加剧这些挑战的是对生态系统的警报,来自不断上升的全球变暖和海平面下降[6]、[7]。鉴于本世纪地表温度预计将增加,我们预见这些极端现象的严重程度和频率将加剧[8]。
利用先进的气候建模和预测技术,将大量大气和地表变量整合在一起,包括大气条件、海洋环流、陆地生态系统和生物圈相互作用,可以增强我们对气候变化的理解[9]、[10]。这些见解可以指导制定量身定制的减缓策略[11]。长期而准确的海平面变化预测可以加强沿海城市的城市规划和灾害应对能力[12]、[13]、[14]。短期内,对降雨、温度和湿度的精确预测可以提高人类活动的安全性,包括农业规划和交通安排[15]、[16]、[17]。
传统上,一般环流模型(GCMs)[18]和数值天气预报模型(NWPs)[19]、[20]、[21]一直是研究气候变化趋势和预测未来天气和气候情景的首选工具。这些模型整合了主要的地球系统组成部分,包括大气、地表和海洋,以模拟地球系统的多维动态。它们通过复杂的物理方程,如大气动力学,识别这些组成部分之间的潜在非线性关联,生成在广泛的物理参数范围内的预测[22]。
然而,尽管这些模型已经取得了相当成熟的发展,但在数值上受限的天气预测模型仍然面临着许多挑战和局限性。其中之一是它们对局部地理特征的过度简化表现[23],因为它们经常无法捕捉到局部地形的复杂细微差异,而这对区域天气和气候模式产生了重要影响。另一个障碍是有效整合来自不同来源的观测数据,如气象站、雷达和卫星[8]。传统模型在将这些具有不同空间和时间分辨率的数据纳入其建模框架中时经常遇到困难。此外,它们需要大量的计算资源来处理众多的物理约束[24]。地球系统的复杂性和规模要求进行大量的计算,这对计算能力和效率提出了挑战。
人工智能技术的快速发展为天气和气候建模引入了经济高效、直接简化的解决方案策略。特别是,机器学习(ML)和深度学习(DL)技术可以识别天气和气候数据中潜在的趋势表示,避开了对复杂物理关系的需求。最初,ML技术仅在与大规模、时间跨度较长的物理模型相比具有有限能力的情况下,为天气和气候状况的短期局部预测而少量使用。然而,在过去的十年中,数据驱动的深度学习方法在天气和气候研究中应用呈现指数级增长,这得益于全球天气和气候数据的爆炸式扩展。利用丰富的数据资源和计算技术的进步,这些模型正在改变气候科学。利用大量数据,深度学习模型揭示了隐藏在气候变量中的复杂非线性关系,从而以增强的精确度捕捉气候系统的动态性和复杂性。然而,这些模型通常针对特定任务设计,并用特定格式的数据进行训练,例如区域天气预报或微观尺度的降尺度。对训练数据源的表示方式的差异导致了对理解天气和气候数据的数据驱动深度学习模型的过度分割功能。因此,为模拟全球天气和气候系统而微调的通用气候模型的开发带来了重大挑战。
大规模模型的迅速出现和快速发展为包括自然语言处理(NLP)、计算机视觉(CV)[32]、机器人技术[33]以及涵盖生命科学[34]、[35]、[36]、[37]、[38]等多个领域带来了显著的收益。特别是在NLP领域,大型模型或大型语言模型(LLMs)正在迅速发展,它们是在大规模语料库上进行训练,并针对各种下游任务进行微调[39]、[40]、[41]。在计算机视觉领域,通过在大量自然图像上进行训练的大型视觉模型[42]、[43]、[44]展示了出色的零样本能力[45]、[46]。这些模型在各种任务中表现出色的原因在于它们的大量参数和大规模的预训练数据。例如,GPT-3[47]、[48]拥有几乎是GPT-2[49]的120倍参数,使其能够更有力地从更少的样本中学习,而GPT-4[50]的参数数量不到GPT-3的十分之一,却在文本生成和图像理解方面表现出色。大型语言模型的迅速崛起重新定义了深度学习的前进道路,尽管无监督/半监督学习和迁移学习等领域长期以来已经有了不断发展。一个值得注意的例子是视觉语言大型模型[46]、[51]、[52]、[53],如CLIP[46],它是在大量自然图像文本上进行训练并进行微调以在图像分割[54]、[55]、[56]和视频字幕生成[57]、[58]等任务中取得了有前景的结果。近期,大型模型扩展到语音[59]、[60]、物理[61]和数学分析[62]等领域,推动了基础科学和专业领域的进展。
这里讨论了预训练基础模型的突破性成功,它使自然语言处理(NLP)和计算机视觉(CV)领域大大接近实现通用人工智能(AI)的目标。这种进步引发了一个有趣的问题:预训练基础模型的成功让NLP和CV领域朝着实现通用AI迈出了重要一步,这不禁让人思考:是否可能开发一个通用的基础模型,用于理解天气和气候数据,并有效地解决许多相关任务?
基于预训练模型的理论,ClimaX引入了一种创新方法,致力于开发一个天气和气候基础模型。它利用Transformer对大规模的天气和气候数据进行预训练,产生了一个灵活的基础模型,擅长于短期到中期的预测、气候预测和降分辨率。Pangu-Weather和W-MAE通过使用丰富的数据对全球气候系统进行建模,展示出强大的气候预测能力。然而,大规模、通用性的气候模型探索面临着重大障碍。主要挑战之一是缺乏大规模、多样化和高质量的训练数据集。现有数据集(更多细节见表4)存在着不一致的测量、时空偏差和功能受限等问题,阻碍了全面、多功能的大规模基础模型的进展。此外,这些模型的计算需求增加了另一个复杂性维度,所需的基础设施在资源有限的环境中可能难以实现。理想情况下,一个天气/气候基础模型应该能够无缝处理多源观测数据,并且结合地理特征的详细表示来生成更精确的天气和气候趋势模拟。不幸的是,对于当前的天气和气候基础模型来说,这仍然是一个未知领域。此外,这些模型的可解释性问题,通常被认为是“黑匣子”,也是一个重要关注点。在与天气和气候相关的任务中,错误的预测可能对生态系统和社会造成严重影响,因此对解释性的需求尤为突出。尽管对于理解天气和气候数据方面已经取得了显著进展和潜力,但上述发展大规模基础模型的独特挑战,需要集中研究(更多细节见第9节)。这强调了对这个新兴领域进展的全面审查的必要性。
在本文中,我们对专门设计用于天气和气候数据的数据驱动模型进行了全面回顾。我们的调查涵盖了各种数据类型、模型架构、应用领域和典型任务的大规模基础模型/任务特定模型。这个回顾扩大了从天气和气候数据中获得的见解的范围,鼓励新颖策略,并促进在天气和气候领域中大型模型的跨应用。通过利用大规模模型中的DL技术,我们旨在揭示复杂的气候模式,增强预测能力,并加深对气候系统的理解,从而使社会更有效地适应气候变化带来的挑战。我们的贡献总结如下:
-
这篇论文是我们目前为止对大规模和任务特定的天气和气候数据理解模型的最全面和现代化的调查。它涵盖了时间序列、视频流和文本序列等领域的最新发展,并为读者提供了一份全面和当前的概述,同时深入探讨了不同方法论的细微差异,从而使读者对这一领域有了全面而现代的理解。
-
系统性和深入的分类。我们引入并讨论了一种有组织和详细的分类方式,将现有的相关研究分为两大类:大型气候基础模型和任务特定的气候模型。此外,我们根据底层模型架构进行了进一步的分类,包括RNNs、Transformers、GANs、Diffusion模型和图神经网络。随后,我们根据模型的应用领域和具体任务进行了进一步划分,并详细解释了这些任务的定义。这种多维分类为读者提供了一个连贯的路线图。
-
丰富的资源汇编。我们已经收集了大量与天气和气候科学领域相关的数据集和开源实现。每个数据集都附有详尽的描述,包括其结构、相关任务以及直接的超链接,以便快速访问。这个汇编是未来研究和开发在这一领域的宝贵资源。
-
未来展望和研究机会。我们勾画了几条有前途的未来探索路径。这些观点涉及各个领域,包括数据后处理、模型架构、可解释性、隐私和训练范式等。这种讨论使读者对该领域的现状有了复杂的理解,并为未来探索提供了潜在的途径。
-
为设计提供的见解。我们讨论并指出了有前途的天气和气候基础模型的重要设计元素。这些设计组件包括时间和空间尺度的选择、数据集选择、数据表示和模型设计、学习策略以及评估方案。遵循这种系统性的设计流程使从业者能够快速理解设计原则,并构建稳健的天气和气候基础模型,从而促进天气和气候领域的快速发展。
论文结构。本调查的剩余部分结构如下:第2节详细说明了我们调查与其他相关研究之间的区别。第3节为读者提供了关于基础模型、天气和气候数据的主要描述以及相关任务的基本知识。第4节详细介绍了天气和气候任务的重要模型的核心架构。第6节,我们总结了当前用于天气和气候任务的主要模型分类的简介,包括气候基础模型和任务特定模型。本节提供了在探索各种独立方法的复杂性之前对领域的整体视角。第5节简要介绍了气候基础模型和任务特定模型,并根据不同的模型架构进一步对任务特定模型进行了分层。随后,第7节对专门用于特定天气和气候任务的数据驱动深度学习模型进行了广泛探讨。鉴于天气和气候数据集缺乏统一和全面的索引,第8节提供了一个详尽的数据集资源和介绍集合,旨在为读者提供便利和高效。第9节详细说明了目前妨碍天气和气候基础模型发展的挑战,以及该领域未来的潜在方向。第10节提出了一个关于构建天气和气象基础模型的潜在蓝图,有助于从业者的思考和实施,并促进气候基础模型的发展。最后,第11节对调查内容进行了总结和结论性的评论。
2 Related work and differences
虽然已经有许多广泛的调查从各种角度对天气和气候相关数据进行了建模,但它们没有强调天气数据的广谱范围(broad-spectrum)。例如,Ren等人进行了一项关于基于深度学习的天气预测的调查,重点是神经网络架构设计以及空间和时间尺度,但它忽略了与天气数据爆炸时代相关的模型。Fang等人和Jones等人在特定情境下,即极端天气条件和气候对洪水风险的影响中,对基于深度学习的天气预测进行了回顾,但没有涉及与气候数据有关的模型。相反,Bochenek等人和Jaseena等人专门讨论和总结了关于普通时间序列的机器学习/深度学习作品。Chen等人提供了关于天气和气候中机器学习方法的调查,但重点仍然局限于预测任务。此外,Molina等人主要强调了机器学习在气候建模中的应用,如气候变化模型中的可预测性来源、特征检测、极端天气和气候预测、观测模型整合、降尺度和偏差校正。Materia主要集中于回顾使用机器学习技术进行极端天气检测和理解的文献。这些调查缺乏对基础模型在理解天气数据方面应用的彻底调查。Mukkavilli等人讨论了大型模型在天气和气候任务中的应用以及架构设计,这与我们的努力类似,但并未包含更详细的任务特定模型和更广泛的数据模态。总体而言,这些调查也缺乏对基于深度学习的天气数据理解模型的结构化描述和详尽讨论,以及充分的资源(数据集、开源模型和工具等),这些资源要么未提供,要么在可用性上受到限制。鉴于大规模模型在视觉、音频和文本等领域的增多,我们此次调查的目的是提供对天气数据理解的大规模模型的全面和最新概述,以及对相关任务特定模型进行结构化描述、综合和讨论,以建立天气和气候基础模型设计的坚实基础。我们的目标不仅仅是记录最新进展;我们还关注可用资源、实际应用和潜在研究方向。下表总结了我们的调查与其他类似评论之间的差异。
3 背景和初步
本研究旨在回顾实施数据驱动模型的最新进展,重点是深度学习技术,以解决天气和气候任务。其目标是阐明发展专门用于天气和气候数据理解的基础模型的潜在路径。我们将注意力集中在天气和气候领域的两个主要模型类别上:大规模基础模型和任务特定模型。在这一部分中,我们首先讨论这两种模型类型,阐明它们的区别和联系。随后,我们描述天气和气候相关的数据类型和不同领域的代表性任务。最后,我们介绍了在天气和气候任务中广泛采用的四种基础模型架构。
3.1 基础模型
基础模型(FMs)起源于预先训练的大规模语言模型(LLMs),通过微调策略具有广泛的能力来处理各种下游任务。这些模型构成了一个多才多艺的类别,与任务特定模型分开,因为它们有能力适应各种下游任务并整合异构表示。FMs 的优势可以分为两类:
跨模态表示
这个类别涉及多模态模型,包括视觉-语言模型(VLMs)。这些模型合并并对齐语言和视觉模态,展示了模态统一的重要潜力。一个典型的例子是 CLIP(对比语言-图像预训练),它使用对比学习方法同时在文本和图像数据上进行训练。它在下游任务上展示了相当强的零样本学习(ZSL)和少样本学习(FSL)能力。另一个创新型模型是 SAM(Segment Anything Model),它将提示概念应用于视觉任务,产生了出色的零样本分割性能。类似的模型还有 InstructBLIP、CoCa、BEIT-3、InstructGPT 和 LLaMa 等,进一步扩展了跨模态基础模型的范围,适应了更广泛的任务和模态表示。在天气预测和气候变化应用中,数据通常具有大规模和多模态特征,例如雷达观测、卫星图像、地面观测站和组织化的格网数据等。这些特征为开发用于天气和气候任务的数据驱动 FMs 提供了动力。
推理和互动
FMs 展示了卓越的推理和规划能力,例如 CoT、ToT 和 GoT 等模型,以及任务规划代理。这个类别还涉及操作和交流的能力。本研究强调了数据驱动 FMs 在天气和气候任务中的应用。然而,这个领域仍然未被开发,为创新提供了丰富的机会。
3.2 任务特定模型
与前面提到的FMs相反,大多数用于天气和气候的DL模型主要是领域特定的(例如,全球/区域降水预测、极端天气理解、气候模型降尺度)。本调查根据时间序列任务的性质将这些任务特定模型分为两类:(1)基于时间序列的天气和气候分析;(2)基于时空序列的天气和气候分析。我们还为气候文本数据划定了一个领域:气候文本分析任务。
基于时间序列的天气和气候分析。这个类别主要包括利用时间序列数据进行天气和气候分析的 DL 模型。这些模型通常利用来自单个气象站的气象时间序列数据,以确定过去观测中一个或多个变量之间的序列关系,从而促进对特定天气变量未来趋势的预测。
天气预测的一个经典数据驱动模型是自回归移动平均(ARIMA),它通过差分操作使非平稳数据变为平稳,随后利用自回归和移动平均的组合来建模时间序列。由于天气数据中通常存在显著的季节性,例如温度和降雨的波动(fluctuations),开发了季节性 ARIMA(SARIMA)和具有外生变量的季节性 ARIMA(SARIMAX)来建模天气序列,基于季节性自回归/移动平均原理。向量自回归(VAR)作为一种替代方法,能够同时建模和预测多个相关变量。基于深度学习的模型,例如递归神经网络(RNNs)系列、基于卷积神经网络(CNN)的架构以及基于 Transformer 的模型(例如,Informer、Autoformer、Crossformer、ETSFormer、Reformer、FEDformer)在处理非平稳时间序列时表现出优异的性能。这些模型特别有用,因为它们不依赖额外的统计知识,并且在长期预测中非常高效。
基于时空序列的天气和气候分析。另一个关注的领域是利用时空序列进行天气和气候分析的 DL 模型。与时间序列数据不同,时空数据涵盖了多个位置随时间变化的天气变量观测,允许提取复杂的时空模式。在这种情况下,连续的雷达回波或卫星图像代表独立的天气时间也被视为时空序列。
为分析用于天气和气候分析的时空序列而设计的数据驱动模型通常需要捕捉时间和空间相关性。例如,卷积 LSTM(Convolutional LSTM)是 LSTM 的一个变种,将卷积操作整合到 LSTM 中以捕获额外的空间相关性。3D 卷积神经网络(3D-CNNs)经常用于同时考虑序列的时空相关性。时空图神经网络(Spatio-Temporal Graph Neural Networks)和其他基于图的结构有效地将不同的空间信息编码到图中,捕捉天气变量的空间相关性和时间趋势。Transformer 模型利用自注意力机制评估不同位置和时间点在做出预测时的重要性。最近在这一领域的进展还涉及到生成式 AI,例如生成对抗网络和扩散模型,用于基于时空序列进行天气预测和气候变化预测,因其出色的生成质量而备受青睐。
3.3 天气和气候数据的类型
对天气和气候的研究通常需要探索时间和文本数据。这些任务的主要目标涉及识别历史天气模式与未来变化之间的关系,这些模式通常由众多气象变量表征。这个过程还包括从文本序列中提取特定特征以辅助详细的后续分析。在这些情景下,我们的讨论主要围绕三种主要的数据类型展开:时间序列、时空和文本数据。在天气和气候分析的背景下,时间序列可以广泛分为两种类型:单变量和多变量。单变量时间序列可以用单个观测点的日均温度来表示,而多变量时间序列可能包括从同一观测点收集的日降水量和湿度数据。在这里,我们首先讨论单变量/多变量时间序列的定义。正式地,我们遵循Ref. [110]中关于时间序列数据的定义,以下是我们总结的内容。
定义 3.1(时间序列数据)。对于单点观测来说,单变量时间序列仅由气象变量(例如温度)$x = {x_1, x_2 , x_3 , …, x_T } \in R^T$ 组成,它是按时间顺序索引的 T 个时间步的序列,其中 $x_t \in R$是时间序列在 t 时刻的变量值。包含不同气候变量(例如温度、湿度、降水量等)的多变量时间序列 $X = {x_1 , x_2, x_3 , …, x_T } \in R^{T \times D}$ 是一个按时间顺序索引的 T 个时间步的序列,但具有 D 个维度(变量),其中 $x \in R^D$ 表示 t 时刻时间序列在 D 个通道上的值。
全球气候数据通常表示为时空序列,即具有时间(变化趋势)和空间维度(地理位置)的混沌相关性。我们定义了两种不同的时空序列:单变量时空序列和多变量时空序列。它们都是按时间和空间维度组织的数据点序列。
定义 3.2(时空序列)。对于单变量时空序列,遵循定义 2.1,在地球系统上存在 N 个点,在每个点上都有一个时间序列 $x = \{x_1 , x_2 , x_3 , …, x_T \} \in R^T$ ,其中 $x_t \in R$,时空序列被构建为 $X_u = \{x_1, x_2 , x_3 , …, x_N \} \in R^{T \times N}$ 。类似地,对于多变量时空序列,序列可以表示为 $X_{mu} = \{X_1 , X_2 , X_3 , …, X_N \} \in R^{T \times D \times N}$ ,其中 $X_N$ 表示第 N 个空间点上的多变量时间序列。
值得注意的是,图形结构通常用于构建时空序列,例如时空图(STGs)、时间知识图(TKGs)、视频流等。在本次调查中,我们主要关注上述类别,它们具有很高的代表性,并与当前基于时空序列的天气预测和气候分析任务紧密相关。我们首先遵循参考文献中对 STGs 和 TKGs 进行定义,如下所示。
定义 3.3(Spatio-Temporal Graphs, 时空图)。一个时空图 $G = \{G_1 , G_2 , G_3 , …, G_T \}$ 表示一系列按时间顺序索引的 T 个静态图快照(也称为时间步),其中 $G_t = (V_t , e_t )$ 表示第 t 个时间步的快照;$V_t$ 和 $e_t$ 分别是时间 t 时刻的节点和边的集合。邻接矩阵表示图中节点之间的关联,节点特征矩阵定义为 $A_t \in R^{N \times N}$ 和 $X_t \in R^{N \times D}$ ,其中 $A_t = \{a^t_{i,j}\}$,如果节点 i 和 j 之间有边,则 $a^t_{i,j} \ne 0$。此外,$N = \vert V_t \vert$ 表示节点数量,D 表示节点特征的维度。
定义 3.4(时间知识图)。遵循 STGs 的定义,一个时间知识图 $G = \{G_1 , G_2 , G_3 , …, G_T \}$ 是一系列按时间顺序索引的 T 个知识图快照,其中 $G_t = (e_t mR_t )$ 是第 t 个时间步的快照,包含时间 t 时刻的实体和关系集。具体来说,$e_t$ 包含主体和客体实体,$R_t$ 表示它们之间的关系集。在时间知识图中,实体和关系可能具有不同的特征,用 X ∈ R|εt|×De 和 Xrt ∈ R|R|×Dr 表示,其中 De 和 Dr 是特征维度。
时空视频流属于一种时空序列,它们被表示为按时间顺序组织的规则空间形状和序列。在天气预测和气候分析任务中,表示特定气候事件的区域连续气象雷达回波和卫星图像属于这种类型,我们根据时空序列的定义对时空视频流进行定义,如下所示。
定义 3.5(时空视频流)。假设一个时空视频流 V = {F1 , F2 , F3 , …, FT } 是一个包含 T 个按时间顺序索引的连续帧的集合,其中 Ft 表示第 t 个帧(或时间步)。每个帧被视为一个像素矩阵,可以表示为 $F_t \in R^{C \times H \times W}$ ,其中 C、H、W 分别表示通道、高度和宽度。
定义 3.6(文本序列)。设 S 是一个文本序列,其中序列中的每个元素代表一个单词或字符。文本序列可以表示为 $S = \{x_1 , x_2, . . . , x_n \}$,其中 $x_i$ 表示序列中的第 i 个元素。文本序列的长度,记为 (N),可以定义为 $N = \vert S \vert $,其中 | · | 表示序列中元素的基数或数量。此外,文本序列中的每个元素可以表示为一个独热编码向量,记为 X 。对于序列中的第 i 个元素,其独热编码向量 Xi 是长度为 M 的二进制向量,其中 M 表示文本语料库中唯一单词或字符的总数。独热编码向量 $X_i$ 在词汇表中对应单词或字符的索引位置上的值为 1,其他位置为 0。
3.4 主流的天气和气候任务
基于上述定义,我们将介绍与上述数据类型和结构相关的代表性天气和气候分析任务。
天气/气候时间序列任务。时间序列分析是天气和气候研究的基础。研究人员经常利用这种方法从序列数据中提取气象趋势,将这些趋势投影到指定时间跨度内的多个变量值上,进行细致的分析。这个全面的任务包括三个子任务:预测、分类和填补(Imputation)。在预测任务中,主要目标是根据历史观测精确预测未来指定时间窗口内的特定变量。这个任务可以根据预测窗口的大小分为短期预测(通常跨越几个小时到几天)和长期预测(一周或更长)。短期天气预测通常用于即时天气预报和城市规划,而长期预测主要用于气候研究、农业和能源部门。接着,分类任务旨在根据大气观测的历史时间表将不同的气象现象(如干旱强度)进行分类。最后,填补任务旨在填补系列中的缺失值。这个任务利用系列中嵌入的潜在信息,考虑可能来自传感器故障或严重气候事件等因素的数据间隙。
基于图结构的任务。基于图结构的气候变化主流任务是预测。我们探索基于图结构的任务,这些任务涉及到之前提到的STG和TKG。STG和TKG是用于表示和推理关于时空信息的扩展,将时间、空间和实体之间的关系融合到统一的图结构中。预测任务旨在根据历史观测和模型预测推断未来时空点的天气条件。这些任务涉及多个变量,如温度、湿度和气压(barometric),以及时间和空间维度。空间-时间地图预测任务的关键挑战在于如何有效地捕获和建模时空依赖关系,以及如何处理数据的不确定性和缺失。
空间-时间视频流任务。视频数据在气候变化和天气预测的研究中起着至关重要的作用。在气象学的背景下,空间-时间视频流通常表现为描述固定时期内天气波动的帧序列。这些序列可能包括常规形状的雷达图像、卫星图像和其他类型的与天气相关的视觉数据。因此,对空间-时间视频流数据的主要兴趣在于预测任务,即基于一系列过去连续帧预测未来图像。在这个背景下的典型任务包括基于雷达回波的即将(imminent)降雨预测或卫星图像的外推(extrapolation)。
气候文本任务。对气候文本数据进行分析,即气候文本分析,旨在提炼重要的模式和洞察力。这个过程包括几个子任务,包括情感分析、主题建模、信息提取和趋势分析。情感分析致力于感知气候文本数据中所包含的情感或观点(例如,公众对气候变化的看法)。相反,主题建模旨在识别和分类气候文本中涉及的基本主题或话题,从而促进对关键关注领域的全面理解。信息提取包括从气候文本中提取特定细节,如极端天气事件的发生或气候政策的具体内容。最后,趋势分析集中于确定和分析气候文本中的趋势,有助于监测公众对话、科学研究或政策讨论随时间的变化。总体而言,这些任务汇聚在对气候问题的更深入理解上。收集到的见解可以启发决策机制、政策制定以及增强公众认知的倡议。
考虑到前述的各种天气和气候数据类型,我们现在将详细介绍与天气和气候分析相关的各种任务。注意,由于其与其他子任务密切相关,我们已省略了对气候文本分析任务的详细概述和定义,并改为采用前述的气候任务作为气候文本分析定义的替代。各任务的简要描述如下:
预测任务。这些任务涵盖从几小时(即时预报)到几天和几周(短期和中期预测)的时间跨度。它们可能包括大陆国家、县或城市的区域预报。亚季节至季节性预测涉及在未来2周到2个月之间预测天气,弥合了天气预报和季节气候预测之间的差距,对于灾害缓解至关重要。
降水即时预报任务。降水即时预报是一种用于预测未来几小时内降水的气象预报技术。与传统的天气预报不同,它专注于降水的短期变化,通常在几分钟到几小时的时间尺度上进行预测。该任务利用雷达系统、卫星、气象观测设施和数值模型的数据,结合图像处理技术,通过实时监测和分析大气云和降水系统,预测未来短时间内降水的分布、强度和移动。因此,我们将其从一般预测任务中分离出来。
尺度下调任务。由于全球气候模型的粗略空间分辨率,它们只能提供在本地或区域尺度上的气候状况的一般估计。模拟通常显示出与观测数据趋势不符的系统偏差。尺度下调气候模型旨在通过将这些气候信息与观测到的本地气候条件相关联,从全球气候预测中生成具有本地精确性的气候信息。这个过程增强了数据的空间和时间分辨率,使其更适合于本地和区域分析。
偏差校正任务。在天气和气候应用中,偏差校正是至关重要的。它旨在最小化或消除模型输出和观测数据中的系统性偏差,这些偏差是由于天气模型的不确定性和测量误差造成的。在天气预报中,偏差校正通过调整温度和降水等变量以匹配实际观测数据,从而提高模型预测的准确性。在气候研究中,偏差校正对齐气候模型输出和观测数据至关重要,有助于准确分析气候变化趋势、评估模型性能和可靠地预测未来气候变化。可以使用多种方法进行偏差校正,包括统计学、机器学习和深度学习技术,根据具体应用和数据特征调整方法。通过最小化或消除系统性偏差,偏差校正提高了天气和气候数据的质量和可靠性。
天气模式理解任务。这个任务旨在分析天气数据,理解天气模式和气候系统的变化和趋势。它涉及对天气系统的各个要素进行建模和分析,如气压、温度、湿度、风速和风向,以揭示它们之间的关系和互动。其目标是识别和解释不同的天气模式,如气旋(cyclones)、锋面和高压系统,并推断它们对天气变化和极端天气事件的影响。通过更深入地了解天气模式,我们可以增进对天气预报和气候变化的认识,为决策者和研究人员提供更准确和全面的天气系统信息。
4 天气和气候的基本结构
到天气和气候任务中存在的不同类型的数据,我们主要考虑使用卷积神经网络(CNNs)、循环神经网络(RNNs)、图神经网络(GNNs)、Transformer(Transformers)、生成对抗网络(GANs)和扩散模型来挖掘这些数据中的复杂相关性。在这份调查中,我们主要关注循环神经网络、Transformer、生成对抗网络、图神经网络和扩散模型。考虑到天气和气候数据的特殊表示,我们在讨论图神经网络时重点关注时空图神经网络。
4.1 循环神经网络
循环神经网络(RNNs)是一种专门处理序列数据的神经网络架构。在RNNs中,信息在所有时间上传递,使得RNN能够利用先前的信息影响后续的输出。RNNs是深度学习中的基本模块,在语言建模、时间序列分析等许多序列相关任务中被广泛使用。RNNs也是将深度学习技术用于天气和气候建模的先驱者之一。通用RNN的更新规则可以表示为:
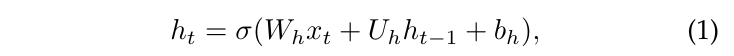
其中$h_t$是第t个时间步的隐藏状态,$x_t$是第t个时间步的输入,$W_h$和$U_h$是权重矩阵,$b_h$是偏置,σ是非线性激活函数,如tanh或ReLU。
然而,普通的RNNs在实践中经常遇到梯度消失和梯度爆炸的问题,使得处理长序列变得困难。为了解决这个问题,一些改进的RNN结构已经被提出,如长短期记忆网络(LSTM)和门控循环单元(GRU)。ConvLSTM和ConvGRU是引入卷积操作到LSTM和GRU中的变体,使它们能够处理空间结构化数据,如图像或视频,它们通常被用来处理天气时空序列数据,如雷达回波或卫星图像序列。在这些模型中,全连接操作被卷积操作取代。例如,ConvLSTM的更新规则可以表示为:
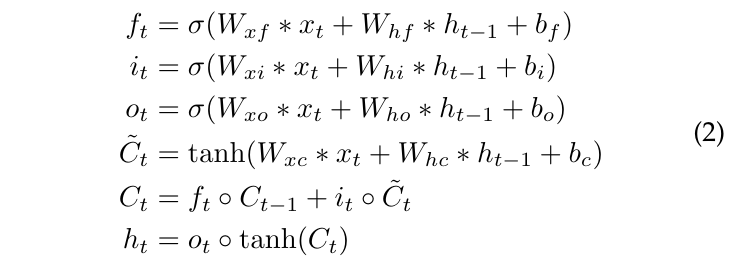
其中\(f_t, i_t、o_t,\tilde{C}_t\)分别是遗忘门、输入门、输出门和候选记忆单元,∗表示卷积操作,◦表示Hadamard乘积。ConvGRU的更新规则可以表示为:
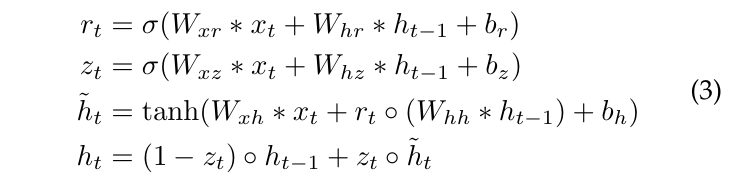
其中$r_t$和$z_t$分别是重置门和更新门。这些门控机制使ConvGRU能够更有效地处理长时间依赖关系。这些公式显示了ConvGRU首先在每个时间步计算重置门和更新门,然后计算候选隐藏状态\(\tilde{h}_t\),最后计算新的隐藏状态$h_t$。更新门$z_t$在计算新的隐藏状态时起到确定使用多少个新的候选隐藏状态的作用。
4.2 扩散模型
扩散模型(Diffusion Models,DMs)在计算机视觉、自然语言处理等领域取得了显著的成就,这是由于它们在模拟复杂、高维数据分布方面的有效性。扩散模型包括一类概率生成模型,在其核心是扩散过程的原则,这些原则是描述粒子随时间连续随机运动的随机过程。这些过程模拟了空间或时间扩散,其中粒子倾向于从高浓度区域向较低密度区域转移,促进了数量的逐渐融合或混合。主要概念涉及进行一系列扩散步骤,每个步骤更新数据的概率分布。这是通过将高斯噪声结合到当前数据样本中并迭代地进行改进来完成的。每个扩散步骤中的噪声添加扰动了数据点,而迭代改进引导这些扰动点逐渐收敛到目标分布。这种迭代过程类似于数据空间中的随机游走,其中随机扰动在模型的引导下最终导致生成符合目标分布的新数据点。
数学上,扩散模型描述了一个从数据开始到噪声结束的马尔可夫链。我们将数据表示为x,噪声表示为z。该马尔可夫链具有以下形式:
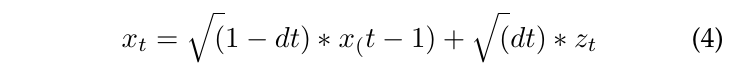
其中$z_t$是从标准高斯分布中抽样得到的,dt是一个小的时间步长,t是当前步骤。扩散模型的目标是学习该马尔可夫链的逆向转换,即从噪声生成数据。这是通过估计条件分布$p(x_{t-1} \vert x_t)$并从中抽样来完成的。经过足够的步骤,马尔可夫链将把噪声z转换成数据x。
4.3 Transformer
Transformer是一种深度学习模型,已经成为应用于自然语言处理和其他序列到序列任务(例如,天气预报)的最新技术大型模型的关键基础设施。其关键在于其能够处理输入序列的任何部分与输出序列的任何部分之间的依赖关系,而无需像循环神经网络(RNNs)那样依赖序列的顺序。基础的Transformer采用编码器-解码器架构,其中编码器和解码器都由一系列堆叠的块组成。每个Transformer层由一个自注意层和一个全连接的前馈网络(FFN)组成。此外,解码器块在自注意层之上增加了一个额外的交叉注意力层,以捕获来自编码器的信息。为了促进信息流动并缓解梯度消失问题,在每个层之间实现了残差连接和层归一化模块。
多头自注意力。Transformer架构的核心是自注意力机制。这种机制在捕获输入序列内部关系方面起着关键作用。它通过计算每个元素与序列中其他元素的注意力分数来实现这一点。然后利用这些分数为输入序列分配权重,从而生成一个新的加权序列。自注意力机制的公式如下:
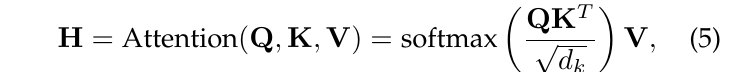
其中$d_k$表示key的维度,$Q \in R^{n \times d_k}$ ,$K \in R^{m \times d_k}$ ,$V \in R^{m \times d_v}$ 分别是query矩阵、key矩阵和value矩阵,它们是相同输入序列 $X \in R^{n \times d}$(或上一层的特征矩阵)的线性变换,基于三个权重矩阵 $W_q \in R^{d \times d_k}$ ,$W_k \in R^{d \times d_k}$ ,$W_v \in R^{d \times d_v}$
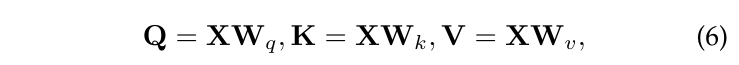
注意力得分通过计算查询矩阵和密钥矩阵的点积得到,然后除以$\sqrt{d_k}$进行缩放,最后通过softmax进行归一化。
Transformer使用多头自注意力,具有多组Q(i) ,K(i) ,V(i),每组对应一个不同的线性变换矩阵 $W_q^{(i)} \in R^{d \times d_k}$ ,$W_k^{(i)} \in R^{d \times d_k}$ ,$W_v^{(i)} \in R^{d \times d_k}$ ,其中$d_h$被设置为$\frac{d_v}{h}$,h是头数。多头自注意力的最终输出通过将一系列$H_i$的连接投影到具有新权重矩阵$W_{proj} \in R^{d_v \times d_{proj}}$ 的新特征空间中来获得,如下所示:
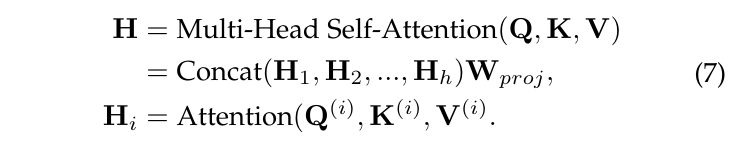
对于解码器,还有一个额外的掩码机制,防止查询向量关注尚未解码的未来位置。此外,还有一个额外的交叉注意力层,它跟随自注意力层,在这里Q是从解码器中上一层的输出派生的,而K和V是从编码器的最后一层的输出转换而来。它设计为在编码时避免预测真实标签,同时考虑来自编码器的信息。
完全连接的前馈层。在注意力层之后的完全连接的前馈层由线性变换和非线性激活函数组成。设输入矩阵为 $X \in R^{n \times d_i}$ ,前馈层的输出为
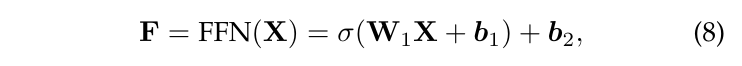
其中σ(·)表示激活函数,$W_1 \in R^{d_i \times d_m}$ ,$b_1 \in R^{d_m}$ ,$W_2 \in R^{d_m \times d_o}$ ,$b_2 \in R^{d_o}$ 是可学习的参数。
残差连接和归一化。在每个注意力层和每个前馈层之后,都会应用残差连接和层归一化。它们有助于在模型非常深时保留信息,从而保证模型的性能。形式上,给定一个神经层 f(·),残差连接和归一化层定义为:
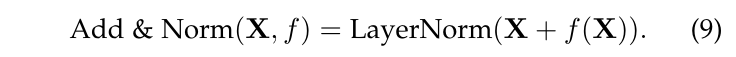
变换器层。变换器模型的设计使得整个序列可以进行并行处理,消除了类似RNN中顺序处理元素的需要。这种并行处理增强了其处理长序列的效率。通过利用多层自注意力机制,变换器模型有效地捕捉了序列中的长距离依赖关系,这对于涉及翻译、总结和其他序列到序列操作至关重要。
4.4 生成对抗网络
生成对抗网络(GANs)旨在通过对抗过程训练生成模型,已广泛应用于图像生成、超分辨率、风格转移和基于图像的天气预测等领域。GANs的基本概念涉及通过对抗训练两个神经网络:一个生成器G和一个判别器D。生成器G的目标是学习潜在的数据分布并相应地生成新样本。判别器D的目标是区分生成器生成的样本和真实样本。在训练过程中,生成器旨在生成能有效欺骗判别器的样本,而判别器则努力增强区分真实样本和生成样本的能力。这个过程可以看作是一个二人零和博弈,最终导致一个平衡状态,其中判别器无法区分生成器生成的样本和真实样本。
GANs的目标函数可以表达为以下优化问题:
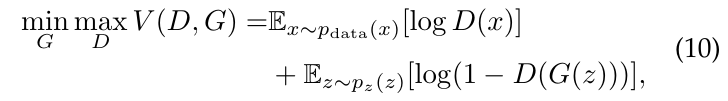
其中x是来自真实数据分布$p_{data}$的样本,z是来自某个先验噪声分布$p_z$的样本,G(z)是使用噪声样本z生成的样本,$D_x$是判别器对样本x(真实样本或生成样本)是否为真实样本的估计。GANs的训练通常涉及交替优化这个目标函数的两部分。首先,固定生成器并优化判别器。然后,固定判别器并优化生成器。这个过程重复进行直到达到某种平衡状态,在这种平衡状态下,生成器生成的样本应该无法被判别器与真实样本区分开来。
4.5 时空图神经网络
时空图神经网络(STGNNs)是机器学习中的一个概念,它利用图结构结合空间和时间信息。它特别适用于分析具有空间和时间依赖性的数据。在STGNN中,基本概念涉及将数据表示为一个图,其中每个节点表示一个空间位置,边捕捉空间连接性。此外,每个节点还包含时间信息,表示不同时间步骤中变量的状态。
空间图结构。设G = (V, E)表示表示空间连接的图,其中V是表示空间位置的节点集合,E是表示空间关系的边集合。每个节点$v_i$表示相应位置i的特征向量$x_i$。
时间信息。设$X = {x^t_i}$表示时间t时所有位置的特征向量集合。每个特征向量$x^t_i$表示位置i和时间t时变量的状态。
时空图卷积。STGNN通过图卷积操作结合了空间和时间信息,捕捉了不同位置和时间步骤之间的变量关系。时空图卷积可以表示为:
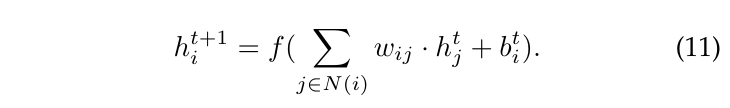
这里,$h_i^{t+1}$表示节点i在时间t + 1时的更新特征向量,N(i)表示节点i的邻居集合,捕捉了位置之间的空间连接,$w_{ij}$表示节点i和其邻居j之间的权重,表示它们关系的强度,$h^t_j$表示时间t时邻居节点j的特征向量。$b^t_i$是时间t时节点i的偏置项。f(·)表示激活函数,如ReLU或Sigmoid,逐元素地应用于加权输入的和。时空图卷积操作结合了空间连接性和时间依赖性,有效捕捉了数据中的演变模式和关系。
5 概览和分类
在这一部分,我们提供了对于天气和气候深度学习模型的概述和分类。我们的调查沿着三个主要维度展开:数据类型、模型架构和应用领域。相关工作的详细摘要可以在表格 3 中找到。根据应用范围,我们将现有文献主要分为两大类:大型基础模型和特定任务的天气和气候模型。考虑到天气/气候基础模型的任务通用性,我们在高层次上讨论它们,没有进一步细分。
对于特定任务的天气/气候模型,我们根据具体的基础架构进行分类,以帮助读者按照模型架构索引和引用特定的工作,包括循环神经网络、生成对抗网络、变换器、扩散模型和图神经网络。随后,在应用层面,我们将现有文献根据特定的数据类别分为两大类:用于天气和气候的时间序列和用于天气和气候的文本。
在第一类别中,我们根据应用领域将现有文献进一步分解为六个主要类别:预测、降水短时预报、空间降尺度、数据同化、偏差校正和天气模式理解。对于第二类别,我们将其探讨为一个通用主题(气候文本分析),不将其细分为不同的子任务。这是因为这些通常源自预训练的大型语言模型,并且具体的任务特征通常基于下游数据集而不是模型本身来描述。
6 天气和气候的模型
在这一部分,我们将深入探讨用于天气和气候数据理解的基础模型和特定任务模型的进展。具有代表性方法的分类和详细信息可以在表 3 中找到。
6.1 用于天气和气候的基础模型
在自然语言处理 [47]、[82]、[200] 和计算机视觉 [45]、[46] 领域基础模型的蓬勃发展引起了对用于天气和气候数据理解的基础模型的研究兴趣。通过预训练策略创建的大型基础模型可以大幅增强基于人工智能的气候模型的泛化能力,并可针对特定的下游任务进行微调。这些模型的预训练需要大规模的序列数据,通常不是从普通的时间序列数据中获取。
考虑到计算效率和及时气候预测的需求,Pathak 等人提出了 FOUR-CAST NET [136],这是一个基于 Vision Transformer 和自适应傅里叶神经网络操作器 (AFNO) [201] 的气候预训练基础模型,用于高分辨率预测和快速推理。其训练过程包括自监督的预训练和基于预训练模型的自回归微调。PANGU-WEATHER [63] 是一个利用 3D 地球特定 Transformer 的数据驱动模型,以其快速、精准的全球预测和出色的性能而著称。它根据当前状态描述的五个上空(upper-air)变量和四个表面变量在 0.25° 水平格网上的 13 个垂直层次上,预测随时间变化的大气状态。另一方面,CLIMAX [25] 引入了基础建模概念到气象预测中,其全监督的预训练基于 Transformer。它提出了变量消歧和变量聚合策略,用于合并和揭示不同高度的不同天气变化之间的潜在关系,为适应各种下游任务(包括全球/区域/季节性预测、气候制图和空间降尺度任务)提供了有前景的灵活性。FENG WU [138] 从多模态、多任务角度独特设计的深度学习架构解决了中期预测问题。它具有一个特定于模型的解码器和一个交叉模态融合 Transformer,在不确定性损失的监督下以区域自适应的方式平衡不同预测器的优化。考虑到前述大型模型是通过完全监督的方法进行训练的,W-MAE [64] 则采用基于掩码自动编码器 (MAE) [202]、[203] 的无监督训练方法来训练气象预测模型,这可以通过各种数据源进行下游任务的微调。MetePFL [24] 和 FedWing [154] 还提出了基于 Prompt 的联邦学习 [204] 来训练大型基础模型,大幅降低了跨地区协作模型训练的成本,同时保障数据隐私。LLM 的快速发展导致了处理天气和气候任务的模型不再局限于视觉或时间序列模型。基于 LLM 的 OCEANGPT [197] 提出了一种处理各种海洋相关任务的方法。除了用于预测和模拟的基础模型之外,CLIMATE BERT [195] 是一个基于 NLP 的用于处理气候相关文本的基础模型。它是在来自新闻文章、研究论文和公司气候报告等各种来源的 200 万个气候相关段落上进行训练的。
在天气和气候分析领域,特定任务模型已被用于各种具体任务。本节将重点介绍天气和气候特定任务模型的进展,着重讨论以下主要架构:RNNs、Transformers、GANs、Diffusion Models 和 Graph Neural Networks (GNNs)。
循环神经网络 (RNNs)。RNNs 是许多天气预测模型的支柱 [85]、[97]、[145]、[175]、[206]、[207]、[208]、[209]、[210]、[211]、[212]、[213]。除了基于 RNNs 架构的天气和气候预测模型外,融合 RNN 和其他机制的混合模型也越来越受到关注 [146]、[147]、[214]、[215]、[216]、[217]。例如,将 Swin Transformer [218] 与 RNN 融合产生了 SwinVRNN [147] 等模型,充分利用了两种架构的优势。此外,将 SwinRNN 与生成模型融合导致了扩散模型 SwinRDM [146] 和 GAN [216]、[217]。除此之外,还引入了基于物理信息的方法 [219]。与此同时,随着基于 Transformer 的时空提取的发展,RNN 架构和 Transformer 模型的整合也逐渐增加,以解决这个问题 [214]、[215]。
扩散模型 (Diffusion Models)。标准的扩散模型包括前向噪声过程和后向去噪过程,广泛应用于气象和气候环境中学习数据分布和生成数据表示 [146]、[147]、[150]、[152]、[177]、[220]、[221]、[222]、[223] [164]、[224]。例如,SwinRDM [146] 将 SwinRNN [147] 和扩散模型融合,实现了高分辨率的天气预报。但值得注意的是,扩散模型在天气和气候研究中的应用仍处于起步阶段。
生成对抗网络 (GANs)。GANs 在图像生成任务中被广泛应用,从生成手写数字 [225] 到生成大规模图像数据集 [226]、[227]。它们在天气和气候任务中通常用于时空视频流预测 [228]、[229],旨在生成逼真且时间连贯的序列,并在它们之间匹配高维数据分布。因此,基于 GAN 的架构在天气和气候预测任务中常用于生成预测的未来帧,尽可能与真实情况一致 [84]、[230]、[231]、[232] [167] [170]、[216]、[217]、[233]、[234]、[235]、[236]、[237] [238]、[239]。这些混合模型通常引入额外的物理约束以提高天气和气候建模的准确性 [229]、[240]、[241]、[242]、[243]、[244]、[245]、[246]、[247]、[248]。
Transformer。基于 Transformer 的模型由于其强大的长序列建模能力而被广泛用于与时间序列相关的任务,包括应对天气和气候变化 [149]。它专注于天气和气候应用中的短期/长期预测任务,并可分为两类:前者侧重于单一气象层面的天气和气候一/二维预测,例如全球或区域天气变量趋势的预测,以及后者侧重于多维预测,例如基于雷达回波图像 [249]、卫星云图像 [250] 和多层大气状态的外推,从而有助于理解该地区的天气模式。对于第一类别,Transformer 用于进行短期和长期预测,通过位置编码和自注意机制对不同时点的变量之间的依赖关系进行建模 [178]、[251]、[252]、[253]、[254]、[255]。至于第二类别,Transformer 预计要建立不同大气压力下气象变量的复杂多层时空关系,这种类型的 Transformer 结果通常基于数据本身的特性(大气压力、时空相关性、变量相关性等)而受到挑战 [25]、[63]、[64]、[138]、[148]。受 NLP 和 CV 领域的启发,Transformer 结构还被重新设计用于大规模天气和气候基础模型的发展 [25]、[63]、[138]。此外,在基于 NLP 的气候文本分析领域,Transformer 是一个通用的架构 [196]、[196]、[198]、[199]、[256]、[257]、[258]、[259]。
图神经网络(Graph Neural Network) 在天气和气候领域,许多研究探讨了图神经网络的应用,特别是空间-时间图神经网络,因其能够建立地球系统潜在的空间-时间关系而备受关注。两种常见的应用包括空间-时间序列预测和天气预报中的空间-时间视频流预测。在空间-时间序列预测中,图神经网络用于建模天气数据中的时空依赖关系和相关性。这涉及根据不同位置的历史观测来预测未来的天气条件。图结构用于捕获节点之间的空间关系,而时间依赖关系则通过循环或卷积层来建模。在空间-时间视频流预测中,图神经网络被用来预测未来天气条件的视频形式。这涉及预测天气模式随时间的演变,同时考虑空间和时间依赖关系。
7 应用
本节概述了主要的深度学习模型,按其在天气和气候分析中的应用进行分类。这些应用包括预测、降水现在预测、降尺度、偏差校正、数据同化、气候文本分析和天气模式理解。
7.1 预测
准确的天气和气候预测对环境和社会规划至关重要。在发展健壮的深度学习方法方面取得了重大进展,这些方法可以建模历史和未来天气模式之间的非线性关系。本节主要关注基于时间序列和时空序列的天气和气候预测任务的进展。在这些任务中最常见的是基于RNN的架构,由于其自回归(AR)结构,被广泛使用。例如,DWFH引入了导电(conductive)长期和短期记忆模型,以增强数据驱动的深度天气预测模型。参考文献[212]将LSTM和自适应神经模糊推理系统(ANFIS)融合,用于大气压力预测。SwinRDM引入SwinRNN作为高分辨率天气预测的基本组件,并使用扩散模型以实现0.25度的高分辨率天气预测。此外,SWINVRNN采用基于循环神经网络的架构以及变化损失来改进长期天气预报。此外,变压器,特别是Vision Transformer,在基于时空序列的天气和气候预测中也被广泛使用,因为它在使用Patch机制和自注意力机制来建模图像区域之间的潜在关系方面表现出色。FOUR CAST NET在各种天气预测任务中表现出色,达到了0.25°的分辨率。这一成就基于Vision Transformer(ViT)和自适应傅立叶神经网络算子(AFNO)。POET引入分层集成变压器以增强全球范围内的中期集合天气预报。TELE -VIT集成了精细的局部尺度和全球尺度输入,并将地球视为一个相互连接的系统,用于季节性野火预测。大型模型在考虑超大规模、高分辨率全球中期预报任务时突然出现。PANGU WEATHER是一个基于3D地球特定变压器的数据驱动模型,以其快速准确的全球预测而受到赞誉。FENGWU从多模态、多任务的角度解决了中期预测问题,采用了精心设计的深度学习架构,具有模型特定的解码器和交叉模态融合变压器,通过不确定性损失进行学习,以平衡区域自适应方式中不同预测器的优化。FuXi级联了立方嵌入和U变压器,并使用39年的高分辨率分析数据进行训练。它的预测性能与ECMWF EM相当,时间分辨率为6小时,空间分辨率为0.25°,可以进行15天的预报。FuXi-Extreme模型采用了噪声扩散概率模型(DDPM)来改进FuXi模型生成的表面预报数据,在5天的预报中增强极端降雨/风预报。作为一个多用途的基础模型,CLIMAX将基于变压器的全面监督预训练引入到天气预测领域,并提出了变量标记和变量聚合策略,以融合和挖掘不同高度的不同天气变化之间的潜在关系,使其具有非常有前途的灵活性,适应不同的下游任务,包括全球/区域/季节性预测,以及气候制图和降尺度任务。虽然上述模型是基于全面监督的预训练进行训练的,但W-MAE利用基于掩码自动编码器(MAE)的方法进行了自监督训练,可以通过不同的数据源进行微调,以适应下游任务。
生成式人工智能在气候和天气预测领域正在崭露头角,近期报道了几种有前景的方法。例如,SEEDS利用一系列精细调整的集成模拟器生成概率性天气预报。这些预测类似于推断过程中提供的天气状态的“种子”,有两种不同的集成模拟器生成两种不同的事件预测。然而,这种方法背后的自回归机制,类似于扩散模型训练中使用的RNN架构,在长期预测任务中容易出现不稳定性和特征消散。与此相反,Dyfussion使用原始初始条件,而PDE-Refiner通过迭代观察来增强基于扩散过程的预测,以捕捉数据中可能不会立即显现的低振幅信息。DITTO采用独特的方法,在初始和最终时间步之间生成连续插值,并在前向过程中使用时间火花而不是增量噪声。TemperatureGAN是一个有条件的GAN,考虑了月份、位置和地面以上的大气温度预测的小时分辨率。此外,整合物理信息约束的GAN被用于模拟海洋系统,从而增强气候预测能力。例如,参考文献描述了基于GAN的模型,学习了数值模型中地表和地下温度之间的潜在物理关系。通过使用观测数据对模型参数进行后续校准,预测性能得到了增强。PGnet是一个生成神经网络模型,使用掩码矩阵来识别初始物理阶段生成的低质量预测区域。生成神经网络然后使用这个掩码作为第二阶段的细粒度预测的先验。WGC-LSTM利用图卷积来捕捉空间关系,并将其与LSTM结合起来,同时考虑空间和时间关系。
考虑到大气要素、地表变量和地球系统内精确地球坐标之间的复杂相互关系,大量的研究利用基于图的方法进行天气和气候预测任务。例如,KEISLER GRAPH NEURAL NETWORK利用图神经网络架构实现天气预测。它使用一个编码器将原始的1°纬度/经度网格映射到一个二十面体网格上,对这个网格进行消息传递计算,然后解码回纬度/经度空间。GRAPH-CAST也利用基于GNN的框架进行天气预测,尽管分辨率更高、灵活性更强。它是基于图方法的天气和气候预测的首个大规模基础模型。GRAPHINO是一个全球空间GNN,专门设计用于季节性预测任务,包括对厄尔尼诺 - 南方涛动(ENSO)现象的预测。该模型首先构建一个初始图,将网格单元作为节点,并根据地理位置之间的连接性学习边。此外,GE-STDGN采用基于进化多目标优化(EMO)算法的图结构学习和优化方法,称为图进化。这增强了模型分析复杂节点相关性以进行时空天气序列预测的能力。HiSTGNN具有自适应图学习模块,构建了一个自学习的层次图。该图由表示区域特定信息的全局图和封装每个区域内气象变量的本地图组成。该模型通过图卷积和具有扩张初始的门控时间卷积来有效地识别隐藏的空间依赖关系和多样的长期天气模式。最后,WeKG-MF通过从Météo-France发布的开放天气观测中构建知识图来构建一个新颖的方法。该模型建立在一个语义模式之上,用于包含气象观测知识的各种下游场景。
7.2 降水预测
降水预测领域通过应用深度学习技术取得了显著的进步,包括CNNs,RNNs和Transformers等方法。这些方法在处理时空数据方面表现出了卓越的能力,这在地球系统观测中是一种常见的数据格式。
CONVLSTM [97]在将深度学习整合到处理降水邻近预报中方面是开创性的,有效地将CNN和LSTM结合起来处理时空雷达数据。随后的模型,如PREDRNN [209]和E3D-LSTM [210],同样在LSTM和CNN架构中融入了时空数据,以提取长期的高阶相关性。PHYD-NET [279]将偏微分方程(PDE)约束引入到其理论空间中。METNET [165]及其后续版本,METNET-2和METNET-3 [281],提出了基于ConvLSTM和先进CNN的架构,从而使得降水预报能够有效地提前12小时。
在视觉领域中,Transformers的崛起使得基于时空视频流数据的降雨预测方法受益匪浅。例如,PTCT [173]将原始帧分成多个补丁,以消除归纳偏差的约束。它还应用3D时间卷积来有效捕捉短期依赖关系。Preformer [176]模型提出了一个编码器-翻译器-解码器架构,其中编码器整合了来自多个元素的空间特征,翻译器模拟了时空动态,解码器将时空信息结合起来进行未来降水预测。Rainformer [171]引入了全局特征提取单元和门融合单元(GFUs)来平衡局部和全局特征的融合,从而实现了高效的降雨预测。TEMPEE [107]提出了基于Transformer架构的时空编码器和解码器的并行使用,在处理非平稳时空序列的无自回归策略中取得了有希望的结果。这显著提高了降水预测的准确性。基于Cuboid Attention的EARTH FORMER模型 [172]被用于地球系统预测,包括降水预测和ENSO。
考虑到来自其他模式知识的指导作用,引入了多模式时空任务。MM-RNN [174]引入基本知识来指导降水预测,强制约束要求降水运动遵循基本的大气运动规律,以实现准确预测。STIN [175]利用时空特定的过滤器从多模式气象数据中生成降水预报。最近,将降水预测视为不确定性评估问题,也受益于成功应用扩散建模。
最近,将降水预测视为不确定性评估问题,也受益于成功应用生成建模。DGMR采用对抗训练方法生成清晰准确的邻近(proximity)预报,解决了模糊预测问题。另一方面,DMSF-GAN [84]完全避开自回归策略,基于对抗训练和纯CNN架构来解决特征随时间分散的问题。PCT-CYCLE GAN [170]利用具有前向和后向时间动态的两个生成器网络生成时间因果关系。每个生成器网络根据时间依赖雷达学习降水数据上的众多一对一映射,以逼近代表每个方向的时间动态的映射函数。MPL-GAN [167]采用多路径学习策略提高了生成序列的多样性,同时提供准确的预测。此外,为了同时处理不确定性并增强特定领域的标准,PreDiff [177]采用两阶段概率时空预测管道,结合明确的知识控制机制,强制预测符合特定领域的物理约束。这通过估计每个去噪步骤中施加的约束的偏差,并相应挑战过拟合分布来实现。GED [169],也称为生成集成扩散,利用扩散模型生成一组可能的天气场景,然后通过后处理网络将其融合成概率预测。参考文献 [231]利用基于雷达的深度学习模型进行熟练的短期降水预测,在1536x1280 km区域实现了一致的显示预测。
引入物理约束和图关系可以提高模型的效率和准确性。参考文献 [240]引入了具有物理信息约束的生成对抗网络,以改善日降水场的局部分布和空间结构。CNGAT [168]融合空间和时间信息,以改进雷达定量降水估计(RQPE)。降水估计区域被划分为子区域,被视为节点形成输入图。然后,所有节点根据降水估计的时间均值雷达反射率进行分类,并采用注意机制。
7.3 Downscaling
实现精确、细粒度的天气预报需要高空间分辨率的数据。然而,大多数全球天气预报模型受到数据的可用性和规模的限制,导致对约为5.625°空间分辨率(相当于约625公里的网格点间距)的数据过度依赖。尽管存在这些限制,但数据量仍然相当可观。例如,ERA5系统以0.25°空间分辨率的数据规模是约15TB,是5.625°空间分辨率数据的数十倍。高空间分辨率的数据提供了对复杂大气过程和不同天气系统之间相互作用的更细粒度的表示。解决这个问题的一种策略是提高天气数据的空间分辨率,这个过程被称为超分辨率(SR)[284],[285]。SR可以增强网格数据的分辨率,在效果上超过了传统的插值方法。一种流行的基于DL的SR模型,U-Net,利用协同的编码器-解码器结构从低分辨率输入生成高分辨率输出[286],[287],[288]。在半监督学习领域,生成对抗网络(GANs)已经展示了提高对更复杂结构和细节表示的潜力[164],[217],[236],[237],[289],[290],[291],[292]。典型的过程包括训练生成器学习低分辨率和高分辨率网格数据或图像之间的潜在映射。例如,Stengel等人提出了一种对抗性DL方法,将全球气候模型中的风速和太阳辐射的预测超分辨到足够的尺度以进行可再生能源资源评估,从而将风能和太阳能数据的分辨率提高近50倍[292]。最近的研究采用了多样的策略,如正则化流和神经操作符。自监督学习方法也被用于对低分辨率网格天气数据进行降尺度处理。例如,预先训练的基础模型CLIMAX [25]允许对分辨率进行微调降尺度处理。González等人提出了一种基于多变量物理硬约束的降尺度策略,确保了变量集之间的物理关系[161]。
物理约束的基于DL的方法也被提出以通过外部调整提高模型的性能[156],[157],[158],[162],[163],[293],[294]。例如,MeshfreeFlowNet [156]采用了一个物理信息的模型,将偏微分方程(PDEs)作为正则化项引入损失函数,实现了时空降尺度。Harder等人[158]是第一个应用硬约束技术在气候变化数据集中实现细粒度降尺度输出的研究。此外,还采用了对比学习[285]和Betrays DL模型[159]等策略。
针对DL-based降尺度方法缺乏解释性的问题,Gong等人探讨了在气候模型降尺度策略中基础CNNs的解释性,为可信赖的降尺度模型打开了大门[273]。Bano等人从多模式视角分析了降尺度问题,开发了基于CNNs的降尺度预测集成(DeepESD)模型,用于欧洲EUR-44i(0.5°)领域的温度和降水,基于八个全球环流模型[160]。这是CNNs在生成基于完美预报方法的降尺度多模式集成中的第一个应用,可以量化气候变化信号中的模型不确定性。
引入不确定性建模还允许在DL-based模型中实现降尺度收益,显著提高了效率和重建分辨率。Res-Diff [164]采用了一个基于两步扩散模型的方法。第一步中,U-Net回归预测均值,而第二步中,扩散模型预测残差,从而实现了公里级大气降尺度。然而,应该注意的是,在天气和气候领域使用扩散模型仍处于探索阶段。Ref. [223]也采用了类似的操作,利用扩散模型进行云层覆盖和高分辨率太阳能预测的超分辨率扩散模型。
7.4 偏差校正
天气预报中的偏差校正传统上依赖于统计方法。随着时间的推移,这些技术已经发展,采用了深度置信网络和支持向量机等机器学习策略。数据的出现和普及进一步催化了向深度学习方法的转变,包括长短期记忆(LSTM)和卷积神经网络(CNN)。这些方法在缓解常见的与天气相关的偏差方面起到了重要作用。
DL-Corrector-Remapper技术是一种显著的方法,它能够从FourCastNet系统中纠正、重新映射和微调格点均匀预报。这一过程通过AFNO方法使其能够直接与非均匀、稀疏的观测地面真实数据进行比较。超分辨率深度残差网络(SRDRN)已被用于气候下尺度化和偏差校正。该网络利用堆叠的大气环流模式并提取空间特征,有效地减小了偏差并校正了相对于观测数据的空间依赖性。
在一个有趣的应用中,无监督的图像到图像转换(UNIT)网络利用非配对图像翻译来进行偏差校正。这种方法为偏差缓解提供了一种新的视角。Hess等人提出了一种后处理技术,利用物理约束的生成对抗网络(cGAN)来同时校正最先进的CMIP6级地球系统模型中的局部频率分布和空间模式中的偏差。
最近,开发了WeatherGNN模型,该模型利用图神经网络在一个全面的框架内进行。该模型学习了天气和地理之间的复杂关系,捕获了格点之间的气象交互作用和空间依赖关系。这种方法为偏差校正提供了一个强大而复杂的工具。这些进展展示了深度学习方法在优化天气预测系统方面的潜力。
7.5 数据同化
数据同化(DA)是高级数值天气预报系统的关键组成部分。这些系统不仅预测未来状态,还会整合观测数据以建立初始状态,指导模型的轨迹到达未来状态。这个复杂的过程在计算上要求很高,因此是一个活跃的研究领域。现有的方法通常依赖于简化假设,比如线性性,这增加了该领域的挑战。然而,将深度学习整合到数据同化中正在得到认可,并取得了令人鼓舞的研究成果。例如,OCEANFOURCAST利用神经算子与基于Transformer的架构,受到FOURCASTNET的启发,在海洋建模中支持基于共轭梯度的数据同化。此外,Bocquet等人创新地将数据同化、机器学习和期望最大化相结合,对混沌动力学进行贝叶斯推理,实现了地球物理流的观测数据同化重建。关于数据同化的深入评估,我们建议读者参考Geer的工作。
7.6 气候文本分析
大规模语言模型(LLMs)的快速发展为气候文本分析提供了新的视角。Hershcovich等人介绍了一个气候表现模型卡片,旨在为需要最少实验设置和相关计算机硬件信息的实际应用提供支持。一种名为CLIMATE BERT的语言模型是基于DISTILL ROBERTA开发的,专门用于分析气候导向文本。这个多功能模型可以应用于各种任务,如检测与气候相关的内容,辨别气候相关段落的情感,识别承诺和行动相关内容,区分特定和非特定的气候相关文本,并根据气候相关金融披露任务组(TCFD)的建议将气候相关内容归类为四个类别之一。CLIMATE BERT的进一步改进可见于Garrido-Merchán等人的研究中,他们利用ClimaText对模型进行了微调,用于分析与气候变化相关的金融风险披露。一个扩展版本,CLIMATE BERT-NETZERO,被设计用于分类给定文本是否包含净零或减排目标。Krishnan等人在他们的CLIMATE NLP项目中使用CLIMATE BERT,使用从Twitter和Facebook收集的数据分析公众对气候变化的情感。Auzepy等人提出利用预训练LLMs的零-shot能力来评估TCFD报告。然而,这种方法并非没有挑战。预训练LLMs通常缺乏最新信息,并倾向于使用不精确的语言,这在气候变化领域中是一个显著的劣势,因为准确性至关重要。为了缓解这一问题,Kraus等人结合了来自ClimateWatch的排放数据,并利用一般的Google搜索来增强语言模型。Vaghefi等人将来自政府间气候变化专门委员会的第六次评估报告(IPCC AR6)的信息整合到GPT-4中,为在气候科学领域实现对话型AI奠定了基础。在气候和健康的交叉领域,CLIMED BERT被开发用于各种应用,包括理解气候和健康相关概念、事实核查、关系提取和生成对健康对政策文本影响的证据。此外,Bi等人提出了基于LLM(例如Llama和GPT3.5)的OceanGPT,用于处理与海洋相关的特定任务,如海洋文本分析和智能水下代理指令。
7.7 天气模式理解
与天气预报相反,天气模式理解更倾向于对气候变化进行定性分析。通过整合来自再分析数据集的预测,我们可以更有效地量化未来天气事件的潜在影响。传统的数值方法虽然成本高昂,但依赖于手工制作的特征,如锋面、热带气旋、外热带气旋和大气河流,使用基于经验知识的启发式检测算法。然而,具有更明显特征的天气模式,如龙卷风和台风,可能更易于模式检测和预测,因为它们具有特征性特征。例如,台风的眼和周围的雨带呈现出明显的模式。这种模式检测和预测可能比在标准训练中预测一般大气状态更有优势。一种方法可能是利用时空视频流数据,如雷达反射率数据和天气卫星云图像。这种从时空天气视频流数据到预测的转变为天气模式理解提供了一种更动态和直观的方法。
基于深度学习技术的天气模式理解通常需要大规模的、有标注的样本。在一项研究中,Kashinath等人创建了一个适用于25km CAM5.1模型中热带气旋(TC)检测的数据集。他们使用基于DL的分割算法对TC和大气河流进行了精细和快速的分割。Racah等人扩展了这个数据集,使用3D-CNN来检测和准确定位TC、外热带气旋(ERCs)、大气河流和热带低压系统。此外,Sobash等人结合了CNN和逻辑回归(LR)来检测每六小时的动态预报中的龙卷风和区域或高分辨率天气预报中的湍流条件。除了从大规模再分析数据集中检测不同的天气模式外,先进的人工智能模型经常用于研究气象现象的演变过程。这些包括在区域背景下的台风生成和消散,以及热带气旋的运动轨迹。接下来,我们将进行一次文献回顾和讨论,重点关注气候现象和极端天气事件领域的天气模式理解。
7.7.1 气候现象理解和预测
我们主要讨论全球尺度下三个主要气候现象/表示,包括厄尔尼诺 - 南方涛动、气候临界点和马登 - 朱利安振荡。
厄尔尼诺 - 南方涛动。厄尔尼诺现象源于强烈的海洋 - 大气相互作用,表现为海表温度升高(SST)、赤道太平洋热金属线水平化以及热带太平洋沃克环流减弱。与其反向阶段拉尼娜一起,它构成了厄尔尼诺 - 南方涛动(ENSO)循环。这个周期持续2到7年,是全球气候年际变化的主要驱动因素,经常与全球气候和社会经济的重大影响相关。因此,准确的ENSO预测具有至关重要的科学和实际意义。已经提出了几种方法来增强ENSO预测。参考文献[178]采用基于Transformer的架构,考虑气象变量之间的长期相关性。参考文献[306]提出了一种用于多年ENSO预测的时空Transformer。ENSO-GTC [181]应用全球海温之间潜在的全球性联系。参考文献[65],[66]开发了一种可解释的深度学习模型用于ENSO预测。参考文献[179]介绍了一种综合的深度学习模型用于ENSO,该模型将季节性融入气候数据中以增强预测波动。关于基于深度学习的ENSO预测的全面回顾和调查可以在参考文献[268],[307]中找到。
气候临界点。气候临界点指的是气候系统中的关键阈值,在这些阈值上,系统对某些变化或外部作用发生显著且不可逆转的变化。这些转变可能引发气候系统的重大变化,包括海洋环流模式的改变、冰川融化加速以及气候带迁移。超越这些临界点可能会破坏气候系统的长期平衡,引发更严重的气候变化。TIP-GAN [243]是一种基于生成对抗网络(GAN)的模型,旨在识别地球系统模型中的潜在气候临界点,特别强调诱发大西洋经向翻转环流(AMOC)崩溃。此外,还提出了一种神经符号问答程序翻译器,NS-QAPT,作为一种神经符号方法,用于增强深度学习气候模拟在气候临界点检测中的可解释性和可理解性。进一步相关的研究可以在参考文献[310],[311]中找到。
麦登-朱利安振荡。麦登-朱利安振荡(MJO)[312],[313]是一种主要观测在赤道附近的大气环流现象。它以赤道地区对流(convection)活动和降水的规律振荡为特征,典型持续时间为20至90天。MJO对全球天气和气候系统产生重大影响,影响降水模式、风场以及热带气旋的形成和演变。因此,理解和预测MJO对准确的降水预测和灾害预防至关重要,从而有效管理和减轻潜在风险。DK-STN [184]利用时空知识嵌入,显著提高了ANN方法的预测准确性,同时保持了高效性和稳定性。有关更多相关作品,请参阅参考文献[8]。
7.7.4 极端天气预测与理解
极端天气预测与理解主要涉及DL模型在预测和理解四个关键极端天气事件方面的应用:极端温度、干旱、气旋和极端降水。
极端温度。这些通常表现为强烈、持续且频繁的热浪 [74],对人类活动和生态环境带来巨大挑战。极端温度事件通常被定义为连续几天的温度变量超过特定阈值或使用包含振幅、持续时间和频率的累积指标来评估。基于数据驱动的气候模型,如随机森林和XGBoost,已经在极端温度预测任务中展示了有效性。此外,由于它们能够捕获时空表示,卷积神经网络、循环神经网络和Transformer在极端温度预测中得到广泛应用。
干旱。干旱在各种时空尺度上发生,并涉及多种触发机制,这使得清晰而全面的定义变得复杂 [314]。它们代表了一种极其复杂的自然灾害。最近的研究倾向于使用基于地理空间气象数据的AI算法 [315]进行长期干旱预测,例如在[180],[182],[316]中。例如,参考文献[180]提出了一维CNN结合GRU用于蒸散发预测,使模型能够更好地捕获时间序列数据中的依赖关系。与此同时,参考文献[316]结合了CNN和LSTM用于提前一个月预测干旱。关于AI在干旱预测中的应用的更全面的审查可以在参考文献[180],[317]中找到。然而,大多数现有研究都集中在地理方面,这使得模型的性能严重依赖于特定的研究条件,如研究区域、干旱指数或考虑的输入变量。这种依赖性使得很难将一个研究的主要发现推广到另一个研究。
气旋和极端降水在热度和一些中纬度地区,天气尺度的气旋是一些最极端的天气事件,由于大雨、强风和风暴潮造成了重大经济损失 [318]。证据表明,气候变化可能会加剧这些极端事件的严重程度,即使不会增加其频率 [299]。然而,在亚季节性到数十年的时间尺度上预测它们的变异仍然是一个挑战 [319]。大雨事件并不总是与气旋或锋面等大尺度天气系统相关联;许多具有影响力的事件与短暂的、小尺度的严重对流事件相关。这些极端事件对操作气候预测系统构成更大的挑战,因为它们的空间分辨率太粗糙,无法捕捉对流的明确表示。在大多数分析极端降水的地区,数值气候预测系统对极端降水的技能在几天后显著下降。已经应用AI技术从多个角度改进气旋和大雨事件的预测。目标是通过确定大尺度驱动因素与极端事件发生之间的关系,提高数值预测系统(例如季节性预测)在表示极端天气事件方面的技能。这种方法已应用于大尺度极端事件,如热带或副热带气旋,或直接应用于降水场 [320],[321]。De Burgh-Day & Leibnberg [322]提出了系统模型消融研究作为解决DL模型可解释性问题的潜在方法,同时保持其良好技能。此外,一些基于DL的策略旨在通过气象图像外推来处理气旋和极端降水的预测(请参阅“降水预测”部分),另一些则专注于通过获得高分辨率观测来改进模型输出,以增强与气旋相关的降水或风场的表示,而不是直接执行预测任务 [323],[324](请参阅第7节)。
8 资源
在这一部分,我们列出与天气和气候变化分析相关的主要数据集和工具,旨在简化从业者对它们的获取。
8.1 数据集
这一部分对应用于数据驱动的天气和气候研究的数据集进行分类。这些数据集有助于天气时间序列分析、天气时空序列分析、天气时空视频流分析和气候文本分析。我们将它们分为两类:天气和气候序列数据以及气候文本数据。值得注意的是,这些数据集没有特定的顺序。
8.1.1 天气和气候序列数据
这一小节集中介绍与天气和气候序列相关的数据集,包括时间序列、时空序列、时空视频流和多模态序列数据。
CMIP6是耦合模型比较项目第6阶段(CMCP Phase 6)的模拟数据汇编。它涵盖了地球系统中各种不同的气候变量,如降水、温度、蒸散发(evapotranspiration)等。这些数据来自150多个气候模型,跨越了150多年(1850-2015)。它可用于预测ENSO现象和常见气候变量。
ERA5被广泛用于训练和基准数据驱动的天气和气候预测、降尺度和预测模型。由欧洲中期天气预报中心(ECMWF)管理,定期更新。ERA5包含了从1979年至今的0.25°网格上的小时数据,涵盖37个不同的压力层次,以及各种地表气候变量,总计近40万个数据点,分辨率为721×1440。
HCOSD3由气候与应用前沿研究所(ICAR)提供,是CMIP数据集的精炼子集。代表历史气候观测和模拟数据集,包括来自CMIP5/6模型的历史模拟数据和来自近一个世纪历史观测的同化数据,重构自美国SODA模型。每个样本包含气象和空间变量,如海表温度异常、热含量异常(T300)、纬向风异常和经向风异常,数据维度为(年份,月份,纬度,经度)。训练数据提供了对应月份的Nino3.4指数标记数据。测试数据包括了从多个国际海洋数据同化结果中随机选择的12个时间序列。
Extreme-ERA5 [90]是由Climate-Learn从ERA5构建的一个子集,旨在评估数据驱动模型在极端天气条件下的预测能力。它包含了各种极端天气事件,这些事件由气候变量超过了本地阈值定义(例如,由于海平面温度异常导致的热浪和寒冷突变)。该数据集涵盖了1979年至2018年的时间段,其中1979年至2015年被视为训练数据集。
PRISM [90]是一个数据集,包含了众多观测的大气变量,包括但不限于美国本土地区的温度和降水情况。该数据集由俄勒冈州立大学的PRISM气候组织维护,时间跨度从1895年至今。在其最高分辨率下,它提供了基于4公里 x 4公里网格单元的每日数据,形成了一个621 x 1405的矩阵。
DroughtED [314]是一个干旱预测数据集,结合了美国大陆地区180个日常天气观测和所有3,108个县的地理位置元数据。它包括了来自NASA全球能源资源(电力)预测计划的气象实时和历史数据,变量包括降水、地表压力、相对湿度、露点/霜点、风速和每日分辨率的温度测量。过去的干旱观测也包括在内,并按照美国干旱监测分类(USDM)进行了并行分类,包括无干旱(none)、异常干旱(D0)、中度干旱(D1)、严重干旱(D2)、极端干旱(D3)和异常干旱(D4)。此外,考虑到干旱是一个季节性现象,数据集中还包括了季节特征。此外,还包括了地点度量,包括每个站点的地形坡度、梯度和海拔高度,以及每个站点的土地利用情况(例如,雨养农田或森林土地)以及土壤质量,如毒性或营养利用。
Digital Typhoon [327]是一个基于图像的数据集,用于热带气旋的长期时空建模。它是从日本静止卫星系列Himawari的全面卫星图像存档中创建的,从Himawari-1到Himawari-9。数据集包括了1,099个台风和189,364张图片。地理上,它覆盖了发生在西北太平洋地区的所有台风记录,时间跨度从1978年至2022年。该数据集的时间分辨率为一小时,空间分辨率为5公里。
EarthNet2021 [332]是一个大型地球表面预测数据集,用于极端夏季预测和季节循环预测。它包含了来自Sentinel 2(高时空分辨率地球卫星)Class 2A图像的32,000多个样本,以及源自E-OBS观测数据集的每日气候数据,该数据集包含了来自欧洲多个站点的天气的插值地面真实观测,覆盖了2018年的全年数据。
ClimateNet [301]是一个专为极端天气事件的高精度分析而设计的开放和专家标记的数据集。它着重捕捉高分辨率气候模型输出中的热带气旋和大气河流,并模拟了从1996年到2010年的近期历史时期。这个数据集对于机器学习和气候研究中的各种应用非常有价值,如迁移学习、课程学习、主动学习、时空分割、概率分割和假设检验。
IowaRain [328]主要来源于基于美国国家气象局的气象监测雷达网络的定量降水估计系统(QPES)的Iowa Flood Center。它覆盖了爱荷华州地区,时间跨度从2016年到2019年底。数据集中的每个事件都包括一组2D降水率图,以及有关事件规模(即数据集中降水率图的数量)和事件开始日期的信息。该数据集专门设计用于预测区域性降水事件。
ExtremeWeather [302]是一个旨在促进极端天气事件的检测、定位和理解的综合数据集。它基于CAM5后处理模拟,这是一种广泛用于全球气候模拟的大气3D模型。数据集侧重于极端天气事件,并提供25公里的空间分辨率。全球大气状态的每个快照都表示为一个768×1152的网格,包括表面温度、表面压力、降水、纬向风、经向风、湿度、云量和水汽等16个模拟气候变量。数据集的时间跨度为1979年至2005年,时间分辨率为3小时。它共包含78,840个样本,捕捉了四种类型的极端天气事件:热带低压(TD)、热带气旋(TC)、温带气旋(ETC)和大气河流(AR)。每场风暴的中心被视为标记边界框坐标的参考点。值得注意的是,数据集包括39,420个带标签的图像,为训练和分析提供了有价值的注释。
KoMet [333]是专门在韩国收集的数据集合。它利用了来自GDAPS-KIM的输入数据,这是一种全球数值天气预报模型,为各种大气变量提供每小时预报。该数据集侧重于降水预测,具有12×12公里的空间分辨率,导致空间尺寸为65×50。数据集包括两种类型的变量:压力水平变量和表面变量。这些变量提供了有价值的信息,用于预测和理解韩国的降水模式。在样本分布方面,数据集中约87.24%的样本被分类为“无降雨”,表示没有观测到降水的情况。约11.57%的样本对应于降雨条件,而1.19%表示极端降雨事件。
Germany [334]是在西德收集的降水预测数据集。它涵盖了从2011年到2018年的时期,重点关注降水预测。该数据集的输入数据源自COSMO-DE-EPS预报,提供了代表不同大气状态的143个变量。该数据集的输入数据具有36×36的空间分辨率,表示用于表示大气条件的网格大小。表示降水预测的输出数据具有更高的分辨率,为72×72。在样本分布方面,数据集中约85.10%的样本被分类为“无雨”,表示没有观测到降水的情况。约13.80%的样本对应于降雨条件,而1.10%表示极端降雨事件。
China [335]是在中国收集的降水预测数据集,提供了每小时1公里×1公里分辨率的3小时格点降水数据,用于雨季。该数据集跨越了2020年和2021年的雨季,时间从四月到十月。此外,它还包括来自区域NWP模型的3小时前导时间预测,包括28个表面和压力水平变量,如2米温度、2米露点温度、10米u和v风分量,以及CAPE(对流有效位能)值。该数据集中的每个时间段都涵盖了一个大规模的空间区域,网格大小为430×815。
China-Precipitation/Temperature [326]是中国的高空间分辨率月降水和温度数据集,涵盖了1901年至2017年的时期。数据集包括中国主陆地区域每月的最低、最高和平均温度,以及降水数据,空间分辨率为0.5弧分钟(约1公里)。该数据集使用了Delta空间降尺度方法,从30弧分钟的Climatic Research Unit(CRU)时间序列数据集和WorldClim气候学数据集中进行了降尺度。它使用了从1951年到2016年收集的来自中国496个气象站的观测数据进行了评估。
ClimART [221]是用于模拟天气和气候模型中大气辐射传递的数据集,基于加拿大地球系统模型,包括了从现代、前工业时代到未来气候条件的1000万多个样本。这个全球快照数据集从1979年到2014年每205小时模拟一次CanESM5的当前大气状态。CanESM5将经度分离为128列,纬度分离为64列,使用高斯网格(8192 = 128 x 64列)。这导致了每年43个全球快照的数据,时间跨度为1979年至2014年,总共超过1200万列,原始数据集大小为1.5 TB。
MeteoNet [336]是用于区域性降水即时预报的多模态数据集,覆盖了法国西北部550×550公里的地理区域,跨越了2016年到2018年。该数据集的模态包括雷达回波观测、地球观测卫星图像、地面站观测、天气预报模型数据和地形图。地面观测数据具有六分钟的时间分辨率,包括由500个地面站测量的气象变量,如温度、湿度、大气压力和风速。另一方面,雷达回波是带有五分钟时间分辨率的降水雷达记录,即每小时记录12帧,包括雷达反射率和降雨估计。卫星数据以云类型(CT)每15分钟记录一次,通道(可见、红外)每小时记录一次。天气模型还包括每天生成的2个天气模型的2D参数预报。
RAIN-F [345]是一个预处理的时空对齐多模态数据集,用于短期降雨预报,包括雷达、地面观测和各种卫星数据的汇总,时间跨度为2017年到2019年,覆盖韩国半岛。具体来说,与降水变量相关的九种不同大气状态变量(一个雷达、七个地面观测和一个卫星)包含了一小时的时间分辨率。地面观测包括风向和风速、湿度、表面压力、温度、海平面压力和降水。
RAIF-F+ [337]是RAIN-F的新版本,具有新的大气变量和TB产品,也可以用于从卫星观测中检索大气变量或预测大气状态和降水,地理和时间覆盖范围与RAIN-F相同。
ENS-10 [325]是一个用于集合天气预报的后处理数据集,包括10个集合成员,跨越20年(1998年至2017年)。这些集合成员是通过扰动数值天气模拟生成的,以捕捉地球的混沌行为。为了表示大气的三维状态,ENS10在11个不同的压力级别提供了11个大气变量和最相关的地表变量,分辨率为0.5度。数据集包括T = 0、24、48小时的预报提前时间(每周两个数据点)。
SEVIR [86]是一个时间和空间对齐的图像序列集合,展示了美国连续本土(CONUS)的天气事件,由GOES-16卫星和NEXRAD雷达马赛克捕捉。包括五种不同类型的图像数据,例如GOES-16 0.6微米可见光卫星通道(vis)、6.9微米和10.7微米红外通道(ir069、ir107)、垂直积液体(vil)的雷达马赛克,以及GOES-16地球同步闪电探测仪(GLM)(lght)捕捉的总闪电闪烁。空间分辨率为0.5km、2km、2km、1km和8km,时间分辨率为5分钟(除了闪电事件),图像覆盖范围分别为768×768、192×192、192×192和384×385,对应于气象事件1403、13552、13541、20393和15115,可用于应用于天气预报、图像转换、极端天气检测、天气注释、超分辨率和其他应用。
SRAD2018是一个降水即时预报数据集,由一系列雷达回波图像组成,来自2018年天池IEEE国际数据挖掘大会(ICDM)上的全球气象人工智能挑战赛,并由深圳气象局和香港天文台收集。数据集中的每个序列包含501×501公里的区域,空间分辨率为1×1,时间分辨率为6分钟,完整序列为6小时,来自3公里高度。
RainBench [338]是一个降水预报数据集,由欧洲中期天气预报中心模拟的卫星数据(SimSat)、ERA5再分析产品和全球降水估算的综合多卫星检索(IMAGE)组成。所有数据都经过双线性插值从原始分辨率转换为5.625的分辨率。时间跨度为2000年到2017年,时间分辨率为1小时。
KnowAir [329]是一个基于站点观测的天气预报数据集,包括中国北方的184个气象站。数据集覆盖2015年到2018年的时间跨度,时间分辨率为3小时。主要包括18个气象特征。
Weather2K [87]是一个基于站点观测数据的大规模天气预报数据集,从中国境内的1,866个地面气象站提取数据,覆盖面积达到600万平方公里,每个气象站有23个特征,其中包括三个静态变量表示地理信息,以及20个交互作用的气象变量。时间范围从2017年1月1日到2021年8月31日,时间分辨率为1小时。
NASA [24]是一个区域天气预报数据集的集合,包括三个子集,AvePRE、SurTEMP和SurUPS,分别从2012年4月1日到2016年2月28日、2019年1月3日到2022年5月2日、以及2019年1月2日到2022年7月29日。这些数据集的时间分辨率均为1小时,分别来自88、525和238个气象站。
LSDSSIMR [300]是一个用于极端天气和沙尘暴预测的大规模沙尘风暴数据库。数据源自丰云-4A(FY-4A)静止轨道卫星的多通道和沙尘标签数据,以及地球系统再分析数据。数据集涵盖了每年从2020年到2022年的3月到5月时间段,时间分辨率为15分钟,空间分辨率为4公里。气象再分析数据被整合到LSDSSIMR中用于时空预测方法。每个数据文件以HDF5格式存储,最终LSDSSIMR包含近5400个HDF5文件。
RainNet [330]是一个专为降水空间降尺度设计的大规模数据集。它包含了85个月或62424小时的数据,总共有62424对高分辨率和低分辨率降水图。高分辨率降水图大小为624x999,低分辨率图大小为208x333。这些数据涵盖了各种气象现象和降水条件,如飓风和阵风线。RainNet中的降水图对以HDF5文件存储,总计占用360GB的磁盘空间。数据来自卫星、雷达和雨量计站,涵盖了不同气象测量系统的固有工作特性。
Continental United States Wind Speeds [331]是一个气候降尺度(超分辨率)数据集,从美国国家可再生能源实验室(NREL)的风能整合国家数据库(WIND)工具包获得,重点关注美国本土。风速数据包括向西(ua)和向南(va)的风速分量,是从距离地球表面100公里的风速和方向计算得出的。WIND工具包具有2公里x1小时的时空分辨率。该数据集包含2007年至2013年以4小时为时间分辨率进行采样的数据。样本测试数据集包含2014年以4小时为时间分辨率进行采样的数据。我们将风速和方向的2D数据数组转换为对应的ua和va风速分量,并将其划分为100x100的补丁。低分辨率图像是通过按照NREL的指导方针在高分辨率数据中每隔五个数据点进行采样获得的。
Continental United States Solar Irradiance [331]是一个气候降尺度(超分辨率)数据集,从美国国家可再生能源实验室(NREL)的国家太阳辐射数据库(NSRDB)获得,重点关注美国本土。我们考虑NSRDB中的太阳辐射数据,以直接法线辐照度(DNI)和漫反射水平辐照度(DHI)为基础,时空分辨率约为4公里x1/2小时。该工作生成的太阳数据集以小时为时间分辨率,覆盖从早上6点到下午6点的时间段,时间跨度为2007年至2013年。测试数据集包含从2014年采样的数据点。提供了一个带有经纬度元数据的数据点的1D数组。我们根据经纬度元数据将这个1D数组重新排列成2D图像。这些DNI和DHI的2D数组被划分为100 x 100的补丁。低分辨率图像是通过在高分辨率数据中每隔五个数据点进行采样获得的。
8.1.2 天气和气候文本数据
本小节专注于天气文本数据集,这些数据集在主题上更偏向于气候变化相关的政策声明和文件文本。
CLIMATE-FEVER. [339] 是采用FEVER方法的数据集,包含1535个关于气候变化的真实主张。每个主张都附带有五个从维基百科中手动标注的证据句子,这些句子支持、反驳或者无法提供足够信息来验证该主张。因此,总数据集包含7675对主张-证据。此外,数据集中包含了具有挑战性的主张,涉及多个方面以及争议案例,其中既有支持证据又有反驳证据。
ClimateBERT-NetZero. [198] 是来自Net Zero Tracker Project的专家标注数据集,评估了减少和净零排放目标或类似目标(例如,零碳、气候中性或净负面)。该数据集包含了273个城市的主张、1396个公司的主张、205个国家的主张和159个地区的主张。
ClimaText. [205] 是用于气候变化主题检测的数据集,包含了标记的句子。标签通过启发式方法或手动流程生成,指示一个句子是否涉及气候变化。所有句子均来自维基百科、美国证券交易委员会(SEC)10K文件。对于维基百科,收集了6885个文档,其中715个与气候变化相关,6170个与气候变化无关。
CLIMA-INS [340] 包含了年度NAIC气候风险披露调查的调查结果,时间跨度为2012年至2021年,该调查的目的是增强关于保险公司如何管理气候相关风险和机遇的透明度,以促进更加明智的气候相关问题的合作,每个调查包含八个问题。
CLIMA-CDP [340] 由三个子集部分组成,每个部分都是由城市、公司或州填写的一系列问卷。该数据集可以执行主题分类和问题分类。用于主题分类任务的训练、开发和测试样本数分别为46.8K、8.7K和8.9K。此外,用于问答任务的训练、开发和测试样本数分别为48.2K(其中8.7K用于州,34.5K用于公司)、8.5K(其中0.9K用于州,34.5K用于公司)和9.3K(其中1.1K用于州,4.9K用于公司)。主题分类任务的类别数为12,问答任务的类别数分别为294、132和43。
CLIMATESTANCE & CLIMATEENG [341] 是一个关于气候相关文本的三元分类数据集,提取自2019年联合国气候变化框架公约期间发布的3777条推文的推文数据。每条推文都进行了两项任务的标注:立场检测和分类分类。对于立场检测,作者将每条推文标记为支持、反对或模糊的气候变化防治立场。对于分类分类,五个类别是灾害、海洋/水域、农业/林业、政治和一般。
SCIDCC [342] 通过从Science Daily网站[342]上抓取新闻文章进行策展。它包含大约11,000篇新闻文章,涵盖与气候变化相关的20个标记类别,如地震、污染和飓风。每篇文章包括标题、摘要和主体,平均长度比其他气候文本数据集要长得多(500-600字)。
8.2 工具和模型
在这个小节中,我们收集和编译了一套丰富且可用的工具和基础模型,用于建模天气和气候数据。
- OpenCastKit:一个基于FourCastNet和GraphCast的全球人工智能天气预测项目。https://github.com/HFAiLab/OpenCastKit
- GraphCast:中期全球天气预测的基础模型。https://github.com/google-deepmind/graphcast
- FourCastNet:基于AFNO的天气和气候数据的基础模型。https://github.com/NVlabs/FourCastNet
- PanGu-Weather:中期全球天气预测的基础模型。https://github.com/198808xc/Pangu-Weather
- FuXi:15天全球天气预测的预测系统。https://github.com/tpys/FuXi
- W-MAE:通过蒙版自编码器实现的无监督学习全球天气预测模型。https://github.com/Gufrannn/W-MAE
- ClimaX:涵盖预测、投影和降尺度的多功能气候基础模型。https://github.com/microsoft/ClimaX
- OceanGPT:用KnowLM训练的用于海洋科学任务的大型语言模型。https://huggingface.co/zjunlp/OceanGPT-7b
- ClimateBert:一种使能够分析气候风险披露的算法,涵盖了四个主要的TCFD类别。https://huggingface.co/climatebert
- Climate X Quantus:用于基于ML/DL的气候模型的XAI工具箱。https://github.com/philine-bommer/Climate X Quantus
9 挑战、展望和机遇
AI基础模型在天气和气候(WFMs)数据理解方面的潜在缺陷体现在许多待解决的挑战中,数据驱动模型比传统的NWP模型更容易受到影响。在本节中,我们确定了五个主要挑战领域,并提出了一些应在未来研究中认识和实施的最佳实践,同时指出了未来研究机会和前景,这些都对未来有着巨大的希望。
9.1 数据后处理
对于DL模型,数据的质量至关重要。然而,与数据相关的众多挑战对于扩展性基础模型的发展造成威胁,包括与数据质量和数量、后处理成本、历史数据稀缺、非稳态以及现有数据集的利用不足等问题。
数据质量和数量。大规模的基础模型需要全面且高质量的数据才能得到稳健的结果。尽管全球气候数据(如ERA5和CMIP)呈指数增长趋势,但同时具备大规模和高质量的通用数据集却很少见。
后处理成本。像PanGu-Weather和ClimaX这样的大型模型通常需要昂贵的后处理进行特定情景分析。例如,对极端事件的分析是一项独特的挑战。这些罕见事件在非稳态气候中越来越常见,通常由气候变量的离群值特征化。它们的发展涉及到从几周到几年的时间周期的物理过程,这使得精细注释的创建变得复杂[302]。
对现有数据集的利用不足。尽管这些大规模数据集规模庞大,但由于巨大的后处理成本,它们仍然发展不足。像WeatherBench、WeatherBench2、OceanBench和ClimateLearn这样的基准数据集,尽管包含后处理数据,但由于数据场景有限,仍处于早期发展阶段。
创建通用WFMs取决于丰富的大规模后处理数据集的可用性。这些数据集有着更深入的分析和后处理的巨大潜力,包括理解异常天气事件、整合物理模型以及高效、合理的注释。克服这些挑战是实现气候基础模型全部潜力的关键。
9.2 多模态模型的发展
时间序列数据通常会附带补充信息,包括文字描述。这在经济学和金融领域尤其有益,因为预测可以利用来自文本数据源(如新闻文章或推文)的信息,结合数字经济时间序列数据[110]。类似地,天气和气候分析可以从包括再分析数据、多模态观测数据(例如,雷达回波[84]、[107]、卫星图像[300]和地理地形特征[314]等)在内的多样模态的气候数据中获益。能够整合和学习这一丰富数据模态的模型的发展潜力可以增强预测准确性。然而,虽然已经努力开发基于多模态气象数据[86]、[314]、[337]的天气预测和气象分析模型,但这些模型往往存在局限性。它们通常局限于特定地理区域,并且难以适应广泛的气象模式。在构建多模态气候基础模型方面的一个突出挑战在于使这些模型能够学习包括时间数据的序列性质和其他气象模式的独特特征在内的联合表示。
这一挑战涵盖了理解和适应不同模态之间的不同时间和空间分辨率。例如,气象观测可能具有小时级的时间分辨率,雷达回波数据可能具有六分钟的时间分辨率和1-4公里的空间分辨率,卫星图像可能具有半小时的时间分辨率和5-12公里的空间分辨率。利用具有不同时间和空间分辨率的信息来构建强大而精确的气候基础模型是一项复杂的任务。此外,平衡和调整不同时间点收集的多模态信息以实现更精确的固定点预测和分析也是一个挑战。因此,有效整合和学习这些多样数据源的模型的发展仍然是天气和气候分析领域中具有挑战性但重要的前沿领域。
9.3 解释性和因果关系
使用AI模型进行天气和气候分析时面临的一个重要挑战是模型决策过程常常是不透明的。许多深度学习算法本质上是复杂且不透明的,使得它们的决策过程对用户来说难以理解[65],[66]。对于机器翻译和文本生成等应用来说,解释性可能并不是一个关键问题。在这些情境中,通常只要模型表现出良好的性能以满足大部分要求就足够了。然而,在天气和气候应用中,模型的解释性至关重要。非透明的黑盒模型可能会导致预测中的灾难性错误,对社会和环境可能造成严重影响。为了缓解这种解释性挑战,提出了基于可解释AI(XAI)概念的工具,如XAITools4、InterpretML5、SHAP6、LIME7和AI Explainability 3608等。这些工具旨在增加黑盒模型的透明度和可信度,包括在各个领域使用的模型(如地球科学[347](Climate X Quantus9)),并为优化表现不佳的模型提供新的见解。然而,这些解释性工具并非没有缺点,可能存在显著的偏见。在某些情况下,模型的真实表示可能更多地取决于应用程序及其设置的具体情况,这可能会使结果难以解释。这表明,气候AI的解释性洞见更多地受网络架构的影响,而不是受天气和气候数据的因果推断的影响。
除非经过恰当设计,否则天气/气候AI可能会基于非物理关系或虚假相关性进行预测。利用XAI工具从气候模型中得出因果推论的能力受到限制,这种限制指的是这些工具能够提供的有限因果性。物理引导的AI,也称为知识引导或物理启发的AI,是研究人员正在探索的一条途径,可以在预测算法上施加物理现实性并减轻虚假相关性的影响[244],[246],[248],[294]。然而,这个领域的研究仍处于初级阶段。因此,尽管在增强AI模型的解释性方面已经取得了进展,但仍存在重大挑战,强调了在这一关键领域继续进行研究和开发的必要性。
9.4 模型的泛化能力
模型的泛化能力指的是其在训练数据集的时空限制之外做出有效预测的能力。许多深度学习技术基于独立同分布(IID)训练和测试数据的假设[66]。这意味着模型训练期间计算的权重即使在未见过的数据集上也保持有效。然而,当应用于天气和气候分析时,基础模型在预测超出训练数据集范围的非IID数据时可能表现出次优性能。一个显著的例子是将基础模型用于预测其训练分布之外的极端事件。这些有偏见和异常数据通常会导致模型性能严重下降。特别是随着气候变暖改变地球的时空分布,目前描述预测变量和极端气候事件的现有关系可能在未来不再适用。
此外,气候基础模型通常在细化特定任务数据集之前在通用数据上进行预训练[25]。如果细化调整的数据包括对抗性或噪声示例,该过程可能引入漏洞。如果用于细化调整的时间数据没有经过细致管理,模型可能会从这些数据中采用偏见或缺陷,导致在实际应用中鲁棒性受损和输出不可靠。这凸显了对鲁棒泛化的迫切需求。物理启发的深度学习的出现代表了提升气候模型鲁棒泛化的一个有希望的步骤。然而,将这些模型扩展到其训练分布之外的领域仍然是一个尚未完全探索的领域。这突显了需要继续研究气候模型的泛化能力,特别是考虑到气候的快速变化和不断演变的挑战。
9.5 隐私、对抗攻击和通信
天气和气候数据通常具有很高的敏感性,涵盖了丰富的气候变量、地理信息和分布在各个地区/国家的地形细节[24],[154]。特别是雷达和卫星数据具有极高的敏感性。使用这些数据对WFMs进行训练面临着来自集中训练、隐私泄漏和对抗攻击等方面的重大挑战。
集中训练问题。模型通常会在部署到各种下游任务之前进行大量数据的预训练[25],[63],[136],[137],[138]。然而,集中训练策略可能存在问题。将来自不同地区或国家的敏感数据聚合到中央服务器上既不可靠也不实际,因为存在数据泄漏和污染的固有风险[24]。
隐私泄漏和对抗攻击。在细化调整过程中,WFMs经常会记住数据集中的具体细节,这可能会危及私人数据。污染的数据也会导致模型性能下降的风险。因此,在训练/细化调整WFMs时采用保护隐私的技术以防止隐私泄漏和减轻对抗攻击是至关重要的。
最近的研究引入了使用差分隐私(DP)技术或联合学习(FL)来训练WFMs[24],[154],有效地降低了敏感气候数据泄漏的风险[348]。然而,这些方法仍然面临通信挑战。
联合学习中的通信开销 联合学习允许不同的客户端共同训练一个全局模型,每个客户端都维护一个具有一致结构的本地复制模型。在全局聚合阶段,每个参与者将他们的本地模型参数上传到云服务器进行聚合。由于气候模型的大规模特性,这个过程导致了客户端和服务器之间通信开销的显著增加,这对计算和硬件成本构成了严重挑战。
9.6 持续学习和设备上的适应性
尽管WFMs表现出有希望的结果,但通过应用持续学习和设备上的适应性可以大幅提升它们的性能。持续学习[349],也称为终身学习或增量学习,是随着新数据出现而随时间更新模型的过程。鉴于气候和天气模式由于自然变异和人为气候变化的不断演变性质,这种方法尤其有益。它使模型能够适应这些变化,增强其预测准确性和鲁棒性。设备上的适应性[75]涉及根据部署点的本地数据定制模型。它有潜力通过调整本地气候和天气模式来提高模型性能,这些模式在全球训练数据中可能没有全面捕捉到。此外,设备上的适应性可以最小化数据传输的需求,从而提高模型的效率并保护隐私。然而,模型中持续学习和设备上的适应性的实施面临着一些挑战。这些挑战包括在持续学习期间确保模型的稳定性以及管理设备学习的计算和存储限制:
保持模型稳定性。经历学习过程的模型可能会出现所谓的“灾难性遗忘”现象,即模型在更新了新数据后可能会忘记之前学习的模式。在保持模型稳定性的同时允许其从新数据中学习是一项重大挑战。
管理计算和存储限制。设备的计算能力和存储容量固有地限制着设备上的机器学习。在资源有限的设备上部署和更新大型气候模型可能会很困难。模型压缩、高效计算和选择性模型更新的技术对于使模型的设备上适应性成为可能至关重要。
尽管存在这些障碍,持续学习和设备上的适应性为增强气候模型的性能提供了一个有希望的途径。
9.7 可再现性
在科学研究领域,可再现性是一个基石原则。使用相同的数据和方法能够再现结果,不仅强化了发现的有效性,还推动了进一步的研究和创新。然而,在气候基础模型的可再现性追求中,存在着一些巨大的挑战:
数据可用性和一致性。气候基础模型经常利用广泛的数据集,这些数据集从各种来源在较长时间内收集而来。挑战在于确保这些数据的可用性和一致性以便进行模型再现。数据可能会进行更新或更正,并且访问权限可能会波动,从而给可再现性的努力增加了复杂性。
模型复杂性。气候基础模型通常包含复杂的机器学习架构、复杂的预处理步骤和高级的训练程序。要再现这些模型,就需要全面理解所有这些方面。如果过程中的任何部分记录不足,或者特定的实现细节是专有的,那么模型的再现可能会成为一项难以逾越的任务。
计算资源。气候基础模型通常需要大量的计算资源进行训练和推断。这些模型的再现可能对于缺乏可比较资源的研究人员来说成本过高或技术上具有挑战性。这种差异可能会在可再现性方面设置障碍,并阻碍更广泛的研究社区的进展。
训练中的不确定性。许多训练过程涉及随机性因素,例如权重的随机初始化、训练数据的洗牌以及随机优化方法。这些因素可能导致稍有不同的模型和结果,即使使用相同的数据和模型架构。在这种不确定性中确保可再现性可能是具有挑战性的。
模型版本控制。随着气候基础模型的发展,会开发出新的模型版本。关键是要记录模型版本,并将其与生成的具体结果进行对齐以确保可再现性。然而,这可能会变得复杂和艰难管理,尤其是在大型合作项目中。
解决这些挑战需要整个研究社区的共同努力。这包括建立数据管理和模型文档标准,投资于开源软件和基础设施,以及培养以透明和开放为基础的研究文化。尽管这些问题很复杂,但解决它们对于气候基础模型研究的进步以及确保其利益得到广泛传播至关重要。
10 基础模型的Insight
这一部分对当前最先进(SOTA)WFMs的设计原则进行了复杂的审查。其目的是为开发具有韧性和多功能性的气候基础模型提供详尽的指南和见解。这篇论文涵盖了五个视角:功能设计、多源数据融合、数据表示、网络架构设计以及预训练/微调策略。
10.1 一模适用于所有
建立基础模型需要对任务进行慎重选择,这会影响所使用的数据、采用的训练策略、采用的微调方法以及其他相关因素。基础模型通常被视为一种万灵药,即预先训练的模型,随后用于各种特定应用任务的微调。一流的气候基础模型,如FengWu [138]和Pangu-Weather [63],优先考虑对地球系统进行系统建模,包括在不同时空尺度上对地球和大气气候变量进行预测。传统上,这些模型是使用来自广泛接受的ERA5数据集的空间分辨率数据进行训练的。相比之下,ClimaX [25]采用了一种不同的方法,即以更粗糙的分辨率对基础模型进行预训练,然后通过微调实现更精细的空间分辨率预测、映射或下采样。因此,开发天气和气候基础模型的主要技术策略包括使用大量高分辨率数据对模型进行预训练,然后通过最小的努力对其进行微调,以展示在一系列下游任务中的卓越性能。
10.2 多数据融合
天气和气候数据主要属于时空序列。我们的讨论主要围绕时空序列任务,如第8节所述。由于数据来源的多样性,包括但不限于地面站、遥感设备和基于模拟的气候产品,将多个数据源的信息融合可以明显提升基础模型的训练过程,从而提高性能。然而,数据之间存在显著的模态差异和异质性,使得多源融合操作的实现变得复杂。我们从两个主要方面提供对此的见解:时空尺度和数据模态。
时空尺度。实践者可以通过同时考虑多个时空尺度的数据,最常见的是再分析数据(见第8节),将高分辨率和低分辨率数据融合起来,以建模精细和粗糙的全球特征,从而在全球范围内实现天气和气候模型。
数据模态。天气和气候数据的模态主要集中在时间序列和文本上。鼓励多源数据融合用于天气和气候基础模型的训练,以捕获不同尺度和数据模态之间的相关知识。例如,对于稳健的全球预测模型,可以进行降水现在预报和在不同压力下融合多个中性粒子的融合。实践者可以探索多模式天气数据的同时或分阶段融合,以使基础模型受益。
10.3 数据表示和模型设计
气象和气候基础模型(WFMs)的健壮开发取决于对天气和气候统计数据的有效数据解释和表示。这个过程通常包括两个阶段:通过预训练构建初始数据表示,以及通过微调将这种表示知识应用到下游任务。考虑到每个数据点都编码了复杂的上下文信息,与自然图像的特征不同,因此需要独特的表示方法。接下来的讨论旨在回答这个领域中的两个关键问题:(1)哪些网络架构可以有效表示天气和气候数据?(2)什么策略可以改进模型,促进有效和准确的表示?
10.3.1 哪些网络架构可以有效表示天气和气候数据?
再分析的天气和气候数据集与自然图像有着显著的相似之处,最明显的是使用网格单元来划分本地语义信息。因此,几乎所有在计算机视觉中使用的网络架构都可以用于处理天气和气候网格数据,包括但不限于ResNet、U-Net、Vision Transformer、生成对抗网络(GANs)和扩散模型。
这些模型是WFMs设计的基础,例如 ClimaX、PanGu-Weather、FourCastNet、DYffusion、GraphCast 等。这些模型通过利用多样化的地球系统建模技术,努力建立不同区域、大气压力水平以及大气/地表气象变量之间更有效的关系。
因此,在考虑基础模型的架构设计时,可以从CNNs、RNNs、Transformers、Graph模型、GANs和Diffusion模型的基础架构中进行选择。在必要时,可以将这些模型结合起来增强表示能力。这些模型的详细描述可以在第6节中找到。
10.3.2 哪些策略可以增强模型并促进高效准确的表示?
天气和气候数据中潜在语义信息的准确表示取决于对数据的时间、空间和变量维度进行联合建模。增强这些模型的潜在策略包括标记化策略、位置编码、注意力机制和时间特征提取。这里我们详细讨论这四种策略:
标记化策略。“标记”一词起源于Transformer的上下文,关键操作是根据补丁大小将原始输入图像划分为小块局部语义信息 - 这个过程称为标记化。对于不规则的再分析格点天气和气候数据,缺乏分割的具体规则或定义意味着标记化选择对模型性能有着重大影响。例如,ClimaX引入了一种连贯的标记化操作,而PanGu-Weather、FuXi和FengWu使用不同的方法来编码变量。一个良好的标记化策略应该考虑不同变量的时空相关性,同时考虑不同的物理尺度,而不引入过多的复杂性。
位置编码。在Transformer中,位置编码提供了关于序列中数据点的空间信息。对于天气和气候数据,可以采用不同的位置编码策略。与固定编码相比,可学习编码提供更大的灵活性,因为它们的位置参数可以更新以增加模型的稳健性。
注意力机制。在Transformer中,注意力机制对于建模序列中不同元素之间的依赖关系至关重要。对于天气和气候数据,注意力机制可以帮助捕捉不同时间步长、地理位置和气象变量之间的关系。注意力机制的计算复杂性也需要考虑,因为许多模型在训练和推断过程中会遇到高成本和降低的速度。
时间特征提取。天气和气候数据包含时间维度,提取时间特征对于模型的准确性至关重要。可以采用各种方法来提取时间特征,然后将其用作模型输入的一部分,以帮助更好地理解和建模时间相关性。
10.4 学习策略
在大规模数据集上预训练 WFM 不仅依赖于昂贵的数据后处理,还需要大量的计算资源投入。一个典型的例子是 PanGu-Weather,其预训练需要超过 60TB 的高分辨率数据和超过 3000 GPU 天的 V100-80G [63],突显了模型的巨大规模。在本节中,我们主要探讨各种学习策略。这些策略旨在减轻计算负担,从而促进天气和气候任务的基础模型的训练和微调。
自监督学习。自监督学习(SSL)是一种无监督范式,其中模型被赋予预测其自身输入数据某些部分的任务。这种方法从数据内部生成标签,消除了对外部注释的需求。因此,SSL 可以利用大量未标记数据进行训练。在天气和气候建模领域,SSL 可以用于识别气候模式和趋势。例如,可以使用历史天气变量(如温度、湿度和风速)预测未来的气象条件。这可以通过将后续数据点投影到预先建立的时间窗口内来实现。通过这样做,模型可以理解内在的天气数据趋势和模式。SSL 的主要优势在于它能够利用大量未标记数据进行训练。此外,它还可以揭示内在的数据模式和结构,这对于天气和气候任务尤其有利 [64]。
半监督学习。半监督学习(SML)是完全监督学习(FLSL)和自监督学习(SSL)之间的一种中间方法,利用有标记和未标记的数据来训练模型。这种方法对于天气和气候预测任务尤为有利,因为标记的天气数据可能稀缺,而未标记的数据却很丰富。在 SML 中,一个流行的方法是自训练。首先,使用现有的标记数据对模型进行监督训练。随后,将该模型应用于对未标记数据进行标记预测,并将这些伪标签用于重新训练模型。这个迭代过程持续进行,直到模型的性能达到平稳。SML 的显著优势在于它能够同时利用有标记和未标记的数据进行训练。这有助于提高模型的性能,特别是当标记数据有限时,可以利用大量未标记数据。
联邦学习。联邦学习[204](FL)是一种分布式机器学习范式,其主要目标是使多个参与方能够共同训练一个模型,同时确保数据隐私和安全 [350]。在 FL 中,每个参与方在本地训练自己的模型,并仅分享模型更新,而不是原始数据。这使得 FL 在处理敏感数据时具有明显的优势,同时还允许从可能地理分散或由于隐私或其他原因无法集中的不同数据源中进行跨学习。在训练 WFMs 的过程中,应用联邦学习带来了显著的好处。首先,全球各地的气象局和研究机构拥有大量的气候数据,但由于数据所有权、隐私和安全方面的考虑,这些数据不能轻易地集中进行处理。联邦学习使得这些机构可以在不直接共享数据的情况下共同训练一个强大的天气预报模型。其次,由于天气和气候数据通常规模庞大,数据传输可能成为瓶颈。通过 FL,数据可以在本地处理和训练,只需传输模型更新,从而大大减少了数据传输需求。最后,FL 允许模型从不同地理位置和类型的气候数据中受益,增强了模型的泛化能力和准确性。目前,许多研究已将 FL 纳入到训练 WFM 的过程中 [24],[154]。
总结
总之,我们提供了一份全面且最新的针对分析天气和气候数据的数据驱动模型调查报告。我们的意图是通过系统化组织的相关模型评估,为这一不断发展的学科提供一个新的视角。我们提炼了每个类别中最显著的方法论,调查了它们各自的优势和缺点,并提出了未来探索的可行路径。这份调查旨在激发持续的兴趣,培养对天气和气候数据理解的数据驱动模型研究持久的热情。
- 显示Disqus评论(需要科学上网)