本文翻译DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning。
目录
摘要
我们推出了我们的第一代推理模型:DeepSeek-R1-Zero 和 DeepSeek-R1。
DeepSeek-R1-Zero 是一个通过大规模强化学习 (RL) 训练而成的模型,没有将监督微调 (SFT) 作为预备步骤,但展示了卓越的推理能力。通过 RL,DeepSeek-R1-Zero 自然而然地涌现出许多强大而有趣的推理行为。然而,它也遇到了可读性差和语言混用等挑战。为了解决这些问题并进一步提升推理性能,我们引入了 DeepSeek-R1,它在 RL 之前融入了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上取得了与 OpenAI-o1-1217 相当的性能。为了支持研究社区,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1,以及六个基于 Qwen 和 Llama 从 DeepSeek-R1 蒸馏而来的密集模型(1.5B、7B、8B、14B、32B、70B)。
1. 引言
近年来,大型语言模型(LLMs)正经历着快速迭代和演进(Anthropic,2024;Google,2024;OpenAI,2024a),逐步缩小与通用人工智能(AGI)的差距。
近期,后训练(post-training)已成为整个训练流程中的一个重要组成部分。它被证明能够提高推理任务的准确性,与社会价值观对齐,并适应用户偏好,同时相较于预训练,仅需要相对较少的计算资源。在推理能力方面,OpenAI 的 o1 (OpenAI, 2024b) 系列模型首次引入了通过增加思维链推理过程长度来实现的推理时缩放(inference-time scaling)。这种方法在数学、编码和科学推理等各种推理任务中取得了显著的改进。然而,有效的测试时缩放(test-time scaling)的挑战仍然是研究社区的一个悬而未决的问题。之前的几项工作探索了各种方法,包括基于过程的奖励模型(Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023)、强化学习(Kumar et al., 2024)以及蒙特卡洛树搜索和 Beam Search 等搜索算法(Feng et al., 2024; Trinh et al., 2024; Xin et al., 2024)。然而,这些方法都未能实现与 OpenAI o1 系列模型相当的通用推理性能。
在本文中,我们迈出了第一步,旨在利用纯强化学习(RL)来提升语言模型的推理能力。我们的目标是探索 LLM 在没有任何监督数据的情况下发展推理能力的潜力,专注于通过纯 RL 过程实现其自我演化。具体来说,我们使用 DeepSeek-V3-Base 作为基础模型,并采用 GRPO (Shao et al., 2024) 作为 RL 框架来提高模型在推理方面的性能。在训练过程中,DeepSeek-R1-Zero 自然而然地涌现出许多强大而有趣的推理行为。经过数千步 RL 训练后,DeepSeek-R1-Zero 在推理基准测试中表现出卓越的性能。例如,AIME 2024 上的 pass@1 分数从 15.6% 提高到 71.0%,并且通过多数投票,分数进一步提高到 86.7%,与 OpenAI-o1-0912 的性能相匹配。
然而,DeepSeek-R1-Zero 遇到了诸如可读性差和语言混用等挑战。为了解决这些问题并进一步提升推理性能,我们引入了 DeepSeek-R1,它整合了少量冷启动数据和多阶段训练管线。具体而言,我们首先收集数千条冷启动数据来微调 DeepSeek-V3-Base 模型。之后,我们像 DeepSeek-R1-Zero 一样执行面向推理的 RL。当 RL 过程接近收敛时,我们通过对 RL 检查点进行拒绝采样来创建新的 SFT 数据,并结合 DeepSeek-V3 在写作、事实问答和自我认知等领域的监督数据,然后重新训练 DeepSeek-V3-Base 模型。在新数据上微调后,该检查点会经历额外的 RL 过程,同时考虑到所有场景的提示。经过这些步骤,我们获得了名为 DeepSeek-R1 的检查点,其性能与 OpenAI-o1-1217 不相上下。
我们进一步探索了从 DeepSeek-R1 到更小密集模型的蒸馏。使用 Qwen2.5-32B (Qwen, 2024b) 作为基础模型,从 DeepSeek-R1 直接蒸馏的性能优于在其上应用 RL。这表明,由更大的基础模型发现的推理模式对于提高推理能力至关重要。我们开源了蒸馏后的 Qwen 和 Llama (Dubey et al., 2024) 系列模型。值得注意的是,我们蒸馏后的 14B 模型大幅优于最先进的开源 QwQ-32B-Preview (Qwen, 2024a),而蒸馏后的 32B 和 70B 模型在密集模型中的推理基准测试上创下了新纪录。
1.1 贡献
后训练:在基础模型上进行大规模强化学习
- 我们直接对基础模型应用 RL,而不依赖监督微调 (SFT) 作为初步步骤。这种方法允许模型探索思维链 (CoT) 来解决复杂问题,从而开发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展示了自我验证、反思和生成长 CoT 等能力,标志着研究社区的一个重要里程碑。值得注意的是,这是第一项开放研究,验证了 LLMs 的推理能力可以纯粹通过 RL 激励,而无需 SFT。这一突破为该领域的未来发展铺平了道路。
- 我们介绍了开发 DeepSeek-R1 的流程。该流程包含两个 RL 阶段,旨在发现改进的推理模式并与人类偏好对齐,以及两个 SFT 阶段,作为模型推理和非推理能力的种子。我们相信该流程将通过创建更好的模型造福行业。
蒸馏:小模型也能强大
- 我们证明了大模型的推理模式可以蒸馏到小模型中,与在小模型上通过 RL 发现的推理模式相比,取得了更好的性能。开源的 DeepSeek-R1 及其 API 将有助于研究社区未来蒸馏出更好的小模型。
- 使用 DeepSeek-R1 生成的推理数据,我们微调了研究社区广泛使用的多个密集模型。评估结果表明,蒸馏后的小型密集模型在基准测试中表现出色。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上达到 55.5%,超越了 QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上得分 72.6%,在 MATH-500 上得分 94.3%,在 LiveCodeBench 上得分 57.2%。这些结果显著优于之前的开源模型,并与 o1-mini 相当。我们向社区开源了基于 Qwen2.5 和 Llama3 系列的蒸馏 1.5B、7B、8B、14B、32B 和 70B 检查点。
1.2 评估结果摘要
- 推理任务:
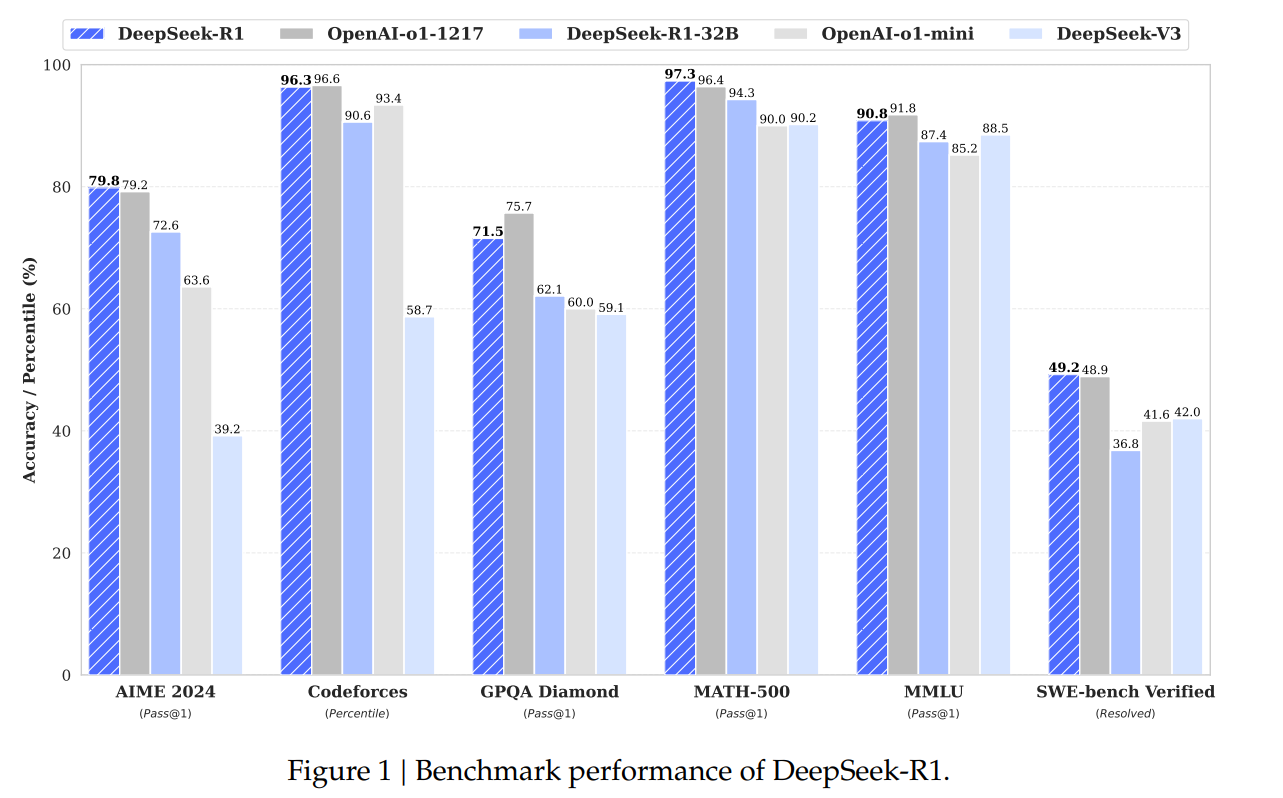
- DeepSeek-R1 在 AIME 2024 上实现了 79.8% 的 Pass@1 分数,略微超越了 OpenAI-o1-1217。在 MATH-500 上,它取得了令人印象深刻的 97.3% 分数,与 OpenAI-o1-1217 持平,并显著优于其他模型。
- 在编码相关任务中,DeepSeek-R1 展示了代码竞赛任务的专家级水平,在 Codeforces 上达到了 2,029 的 Elo 等级,超越了 96.3% 的人类参赛者。对于工程相关任务,DeepSeek-R1 表现略优于 DeepSeek-V3,这有助于开发人员在实际任务中。
- 知识:在 MMLU、MMLU-Pro 和 GPQA Diamond 等基准测试中,DeepSeek-R1 取得了突出结果,显著优于 DeepSeek-V3,MMLU 得分 90.8%,MMLU-Pro 得分 84.0%,GPQA Diamond 得分 71.5%。虽然其性能在这些基准测试中略低于 OpenAI-o1-1217,但 DeepSeek-R1 超越了其他闭源模型,展示了其在教育任务中的竞争优势。在事实基准 SimpleQA 上,DeepSeek-R1 优于 DeepSeek-V3,展示了其处理基于事实查询的能力。观察到类似趋势,OpenAI-o1 在此基准上超越了 4o。
- 其他:DeepSeek-R1 还在广泛的任务中表现出色,包括创意写作、通用问答、编辑、摘要等。它在 AlpacaEval 2.0 上取得了令人印象深刻的 87.6% 长度控制胜率,在 ArenaHard 上取得了 92.3% 的胜率,展示了其智能处理非考试导向查询的强大能力。此外,DeepSeek-R1 在需要长上下文理解的任务中表现出色,在长上下文基准测试中大幅优于 DeepSeek-V3。
2. 方法
2.1 概述
以往的工作严重依赖大量监督数据来提升模型性能。在这项研究中,我们证明了即使不将监督微调(SFT)作为冷启动,推理能力也可以通过大规模强化学习(RL)显著提高。此外,通过加入少量冷启动数据,性能可以进一步提升。在以下章节中,我们将介绍:(1) DeepSeek-R1-Zero,它直接将 RL 应用于基础模型,不使用任何 SFT 数据;(2) DeepSeek-R1,它从一个用数千个长思维链(CoT)示例微调的检查点开始应用 RL;(3) 将 DeepSeek-R1 的推理能力蒸馏到小型密集模型中。
2.2 DeepSeek-R1-Zero:在基础模型上进行强化学习
强化学习在推理任务中表现出显著的有效性,正如我们之前的工作(Shao et al., 2024; Wang et al., 2023)所证明的那样。然而,这些工作严重依赖于监督数据,而这些数据的收集耗时费力。在本节中,我们探索 LLMs 在没有任何监督数据的情况下发展推理能力的潜力,重点关注其通过纯强化学习过程的自我演化。我们将首先简要概述我们的 RL 算法,然后展示一些令人兴奋的结果,希望这能为社区提供宝贵的见解。
2.2.1 强化学习算法
组相对策略优化 为了节省 RL 的训练成本,我们采用了组相对策略优化 (GRPO) (Shao et al., 2024),它摒弃了通常与策略模型大小相同的评论家模型,而是从组分数中估计基线。具体来说,对于每个问题 $q$,GRPO 从旧策略 $\pi_{\theta_{old}}$ 中采样一组输出 ${o_1, o_2, \dots, o_G}$,然后通过最大化以下目标来优化策略模型 $\pi_{\theta}$:
\[J_{GRPO}(\theta) = E[q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)] \\ \frac{1}{G} \sum_{i=1}^G \left[ \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)} A_i, \text{clip}\left(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon\right) A_i \right) - \beta D_{KL}(\pi_{\theta}||\pi_{ref}) \right], \quad (1)\] \[D_{KL}(\pi_{\theta}||\pi_{ref}) = \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} - \log \frac{\pi_{ref}(o_i|q)}{\pi_{\theta}(o_i|q)} - 1, \quad (2)\]其中 $\epsilon$ 和 $\beta$ 是超参数,$A_i$ 是优势,使用与每组输出对应的奖励组 ${r_1, r_2, \dots, r_G}$ 计算:
\[A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \dots, r_G\})}{\text{std}(\{r_1, r_2, \dots, r_G\})}. \quad (3)\]- 显示Disqus评论(需要科学上网)