本文通过图解的方式总结了R-CNN、Fast R-CNN、Faster R-CNN和Mask R-CNN。更多文章请点击深度学习理论与实战:提高篇。
目录
前面逐个的介绍了Fast R-CNN、Faster R-CNN和Mask R-CNN这一系列算法,这里再通过的图片总结一下它们的演进过程。这些图片来自这篇文章。
R-CNN
首先是R-CNN,如下图所示。它的输入是一种图片,通过Region Proposal之后得到3个候选区域。由于区域大小不同,所以需要缩放(wrap)成固定的大小,然后使用CNN来进行分类和Bounding box回归。注意原始论文只用CNN来提取特征,用SVM来分类,用另外一个单独的模型来回归,但这个图是改进的版本,直接用神经网络来进行分类和回归。它预测的时候每一个候选区域都需要用CNN来提取特征,速度慢。
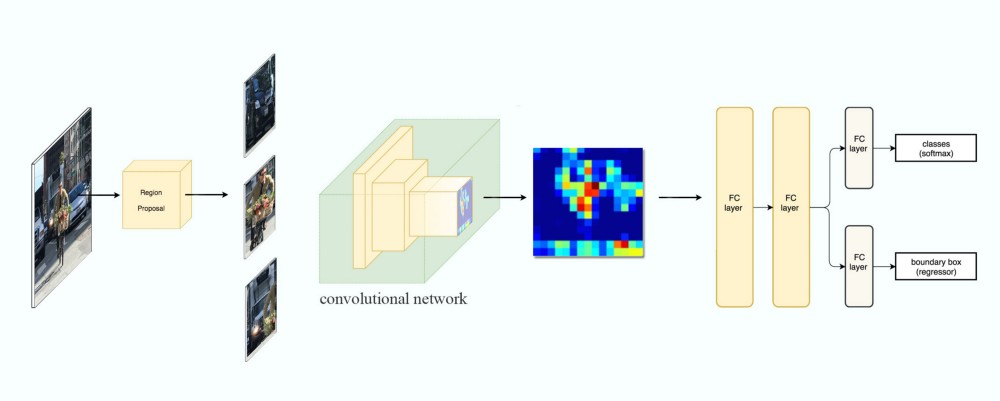 图:R-CNN Family之R-CNN
图:R-CNN Family之R-CNN
网络流图如下图所示,这里的分类器和回归也是原始论文的SVM和单独的回归模型。
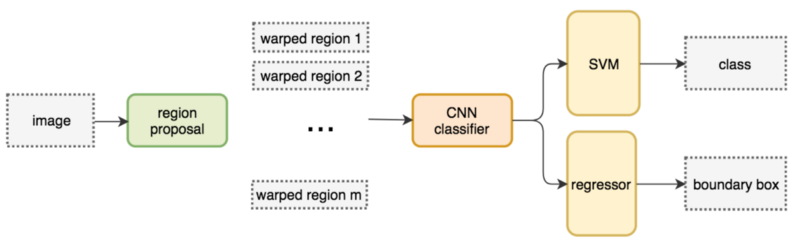 图:R-CNN Family之R-CNN
图:R-CNN Family之R-CNN
Fast R-CNN
接下来是Fast R-CNN,如下图所示。它不需要对每个Region Proposal都进行特征提取,而是对整个图片进行一次特征提取,然后每个RoI找到对于的特征区域。由于每个RoI大小不一样,因此得到的特征区域也是不一样,所有需要通过一个RoI Pool层把它们变成大小一样,之后就没有什么不同了。
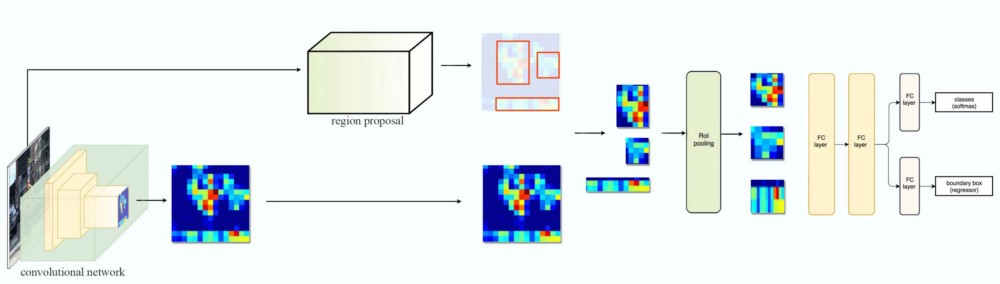 图:R-CNN Family之Fast R-CNN
图:R-CNN Family之Fast R-CNN
网络流图如下图所示:
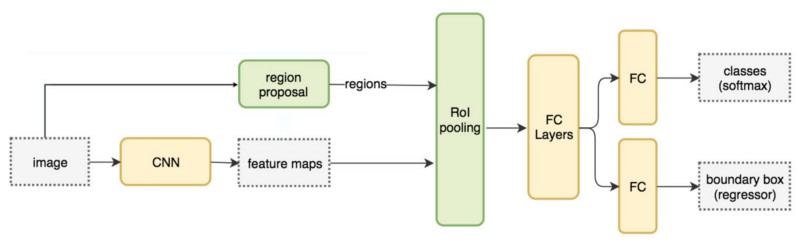 图:R-CNN Family之Fast R-CNN
图:R-CNN Family之Fast R-CNN
RoI Pooling如下图所示,注意这里和前面介绍的稍有出入,前面哪个狗狗图片在RoI Pooling时20/7=2了,这里5x7的的要Pooling成2x2。如果按照之前的方法,应该每个格子都是2x3的,然后第5行和第7列被忽略。这里的方法稍微不同,它切分的4个格子大小都不同,分别是2x3、2x4、3x3和3x4的,这样的好处是利用了所有的信息。这在检测上会有帮助,但前者的实现上更简单一点。
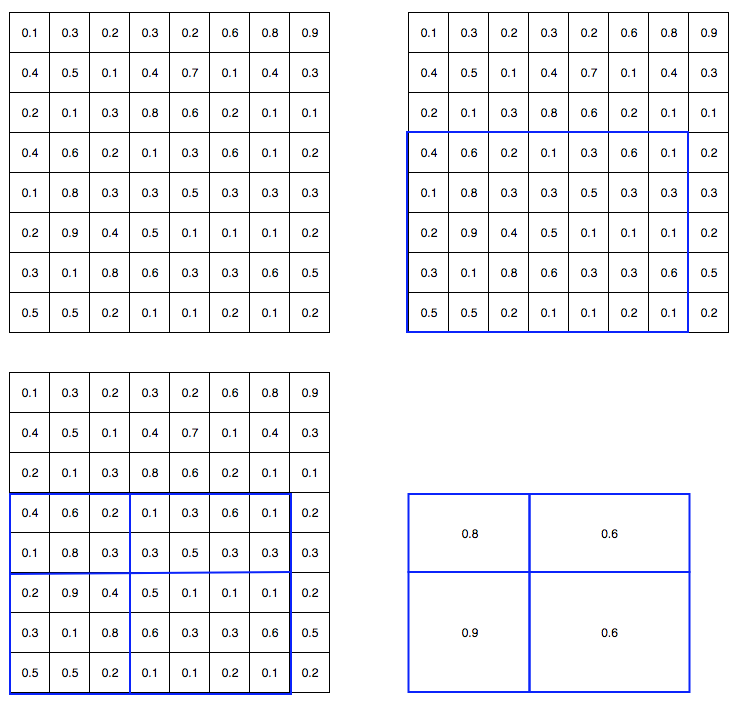 图:R-CNN Family之RoI Pooling
图:R-CNN Family之RoI Pooling
Faster R-CNN
接下来是Faster R-CNN,如下图所示。它要解决的是Region Proposal慢的问题,因此引入了单独的RPN网络来进行Region Proposal。
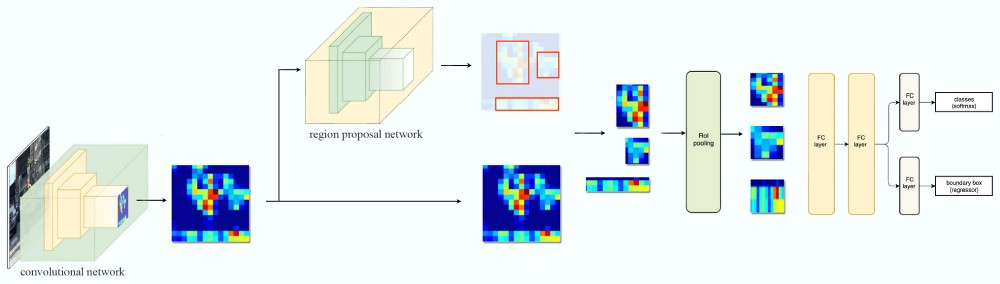 图:R-CNN Family之Faster R-CNN
图:R-CNN Family之Faster R-CNN
它的网络流图如下:
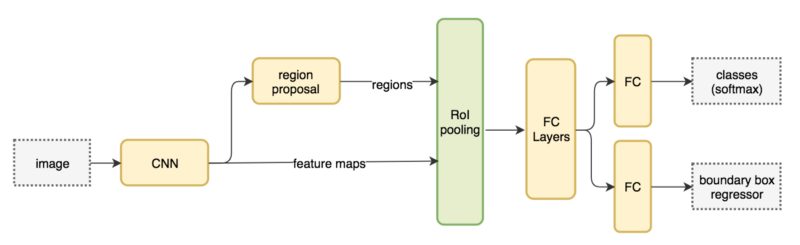 图:R-CNN Family之Faster R-CNN
图:R-CNN Family之Faster R-CNN
RPN如下图所示。对于3x3的特征映射,我们使用卷积网络把它变成256的特征向量,然后再分别产生2k和4k的输出,分别代表k个Region Proposal。其中4个只代表区域位置,另外2个值代表它存在物体的可能性(Objectness),其实用一个值也行(输出sigmoid),这里使用了softmax的方式。
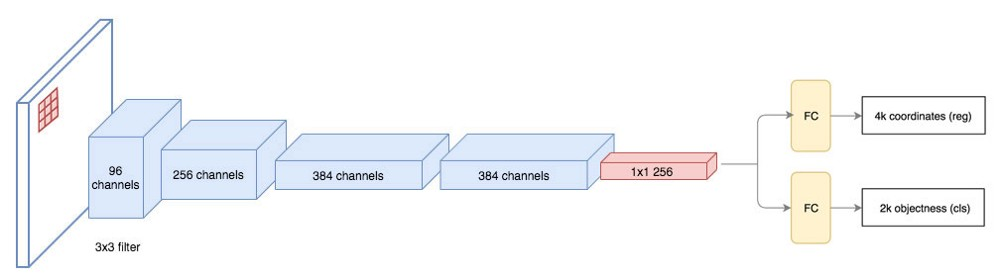 图:RPN
图:RPN
对于特征映射里的每一个点,我们都用一个3x3的filter去提取256维向量,3x3的filter看起来很小,但是实际对应的原始图片可能是很大的一个区域。如下图所示,这是一个8x8的特征映射和3x3的filter,对于8x8特征映射的每一个点,都会输出k(图中为3,实际为9,三种scale和aspect ratio的组合)个可能候选区域。但是为了让k个输出各自学习不同形状的物体,我们用k个anchor来作为参考,因此这里输出的4个位置信息不是绝对的位置,而是相对k个anchor的位置。如下图所示,我们期望模型输出的形状也是和anchor类似的,比如anchor的aspect ratio是2:1,那么模型学习预测的物体也大致应该是类似比例的物体。
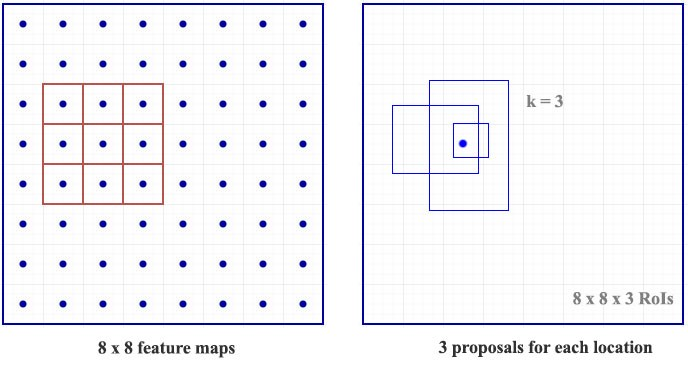 图:RPN图例
图:RPN图例
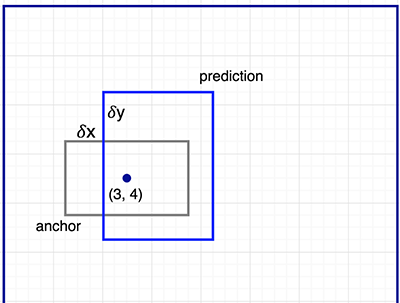 图:4k个输出是相对k个anchor的位置
图:4k个输出是相对k个anchor的位置
为了在每个位置生成(最多)k个候选区域,我们需要k个anchor,它们的中心点都是重合的,但是要求有不同的scale和aspect ratio来识别不同大小和形状的物体,如下图所示。
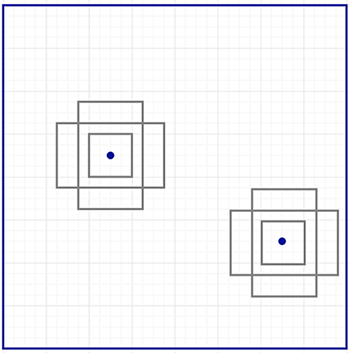 图:每个位置有k个anchor
图:每个位置有k个anchor
这些anchor预先是经过精心设计的,Faster R-CNN使用了9个anchor,3种scale,1:1、2:1和1:2三只aspect ratio。如下图所示,特征映射的每个点会产生4x9和2x9的输出,分别表示候选区域(RoI)相对anchor的位置信息和它包含目标物体的概率。
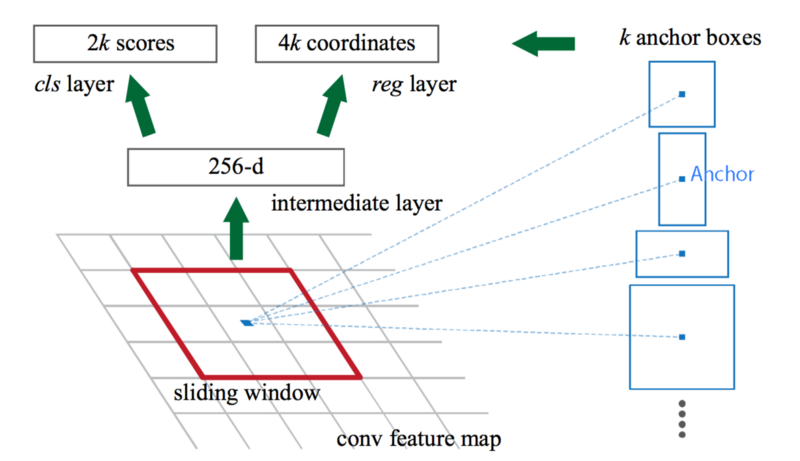 图:RPN示意图
图:RPN示意图
Mask R-CNN
Mask R-CNN如下图所示。它把RoI Pooling变成了RoI Align,然后输出多了一个分支用来预测每个像素是否属于目标物体的Mask。
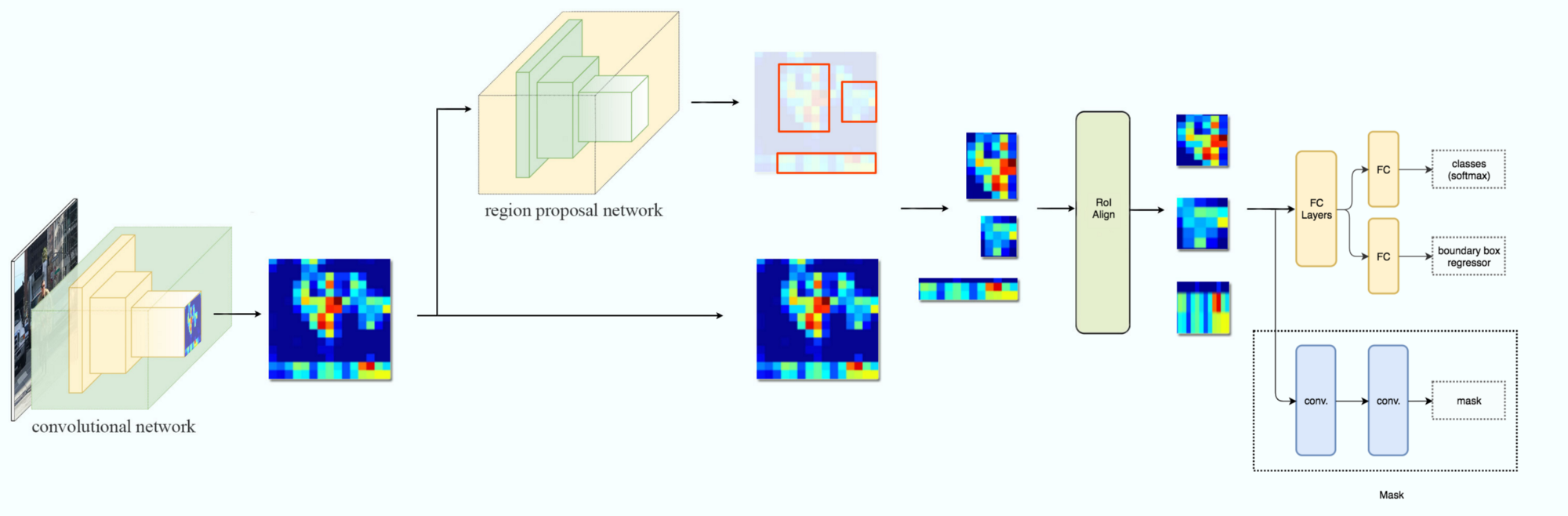 图:Mask R-CNN
图:Mask R-CNN
它的网络流图为:
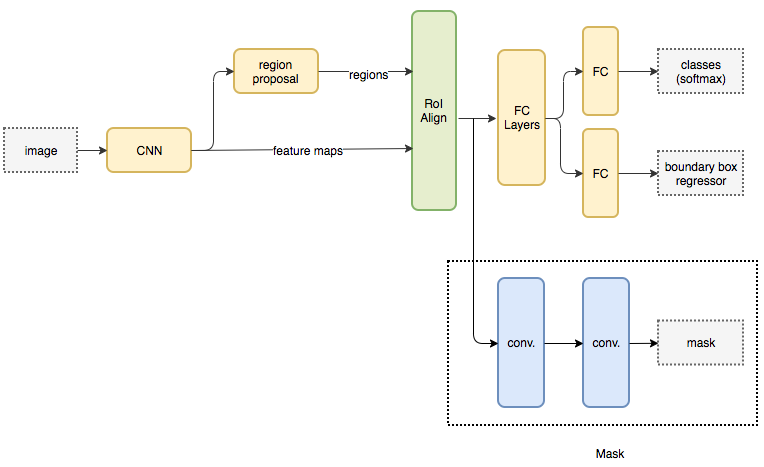 图:Mask R-CNN
得到候选区域后用于分类、回归和mask的网络叫作head(与之对应的之前的网络叫backbone),论文使用了两种head,如下图所示。
图:Mask R-CNN
得到候选区域后用于分类、回归和mask的网络叫作head(与之对应的之前的网络叫backbone),论文使用了两种head,如下图所示。
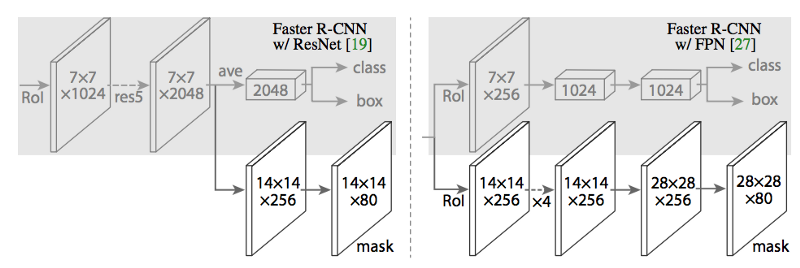 图:Mask R-CNN的两种head网络结构
图:Mask R-CNN的两种head网络结构
- 显示Disqus评论(需要科学上网)