这个模块介绍课程相关的信息。更多本系列文章请点击微软Edx语音识别课程。
目录
Welcome
视频Before We Start
介绍和吹嘘微软的宏伟目标,看看就可以了。
视频Welcome
介绍4个老师,看看就行了。
Welcome
再次热烈欢迎大家来上课!
关于课程
概览和Schedule
《语音识别系统》是一个高级(复杂有难度的)课程,总共需要4周,总共需要12-16个小时来完成。学习这个课程需要安装一些软件,请参考”开始实验”部分。学习者需要一些Python编程的基础、概率统计和基本的机器学习知识。
Schedule
《语音识别系统》是一个学生可以自己制定学习计划的课程,它有6个模块(module)组成。我们期望大致需要花费16个小时来完成课程,当然不同的学生会有不同的情况。课程的作业是比较开放式的,因此学生们可能会花费多于或者少于16个小时的时间。我们鼓励你完全理解课程的内容。你投入的时间越多,收获也越多。
模块结构
课程分为6个模块,每个模块涵盖语音识别过程的一个步骤。
模块1-6包括多个教学的内容、视频和小测试(注:小测试必须花99$才能看,因为这是用来考核打分用的,我没有参加因此不介绍)。每个模块包含一个测试,每个测试12分,因此课堂测试总共12x6=72分。剩下有一个最后的测试28分,总结100分。
模块概览
模块1 | 背景和基础知识
模块2 | 语音信号处理
模块3 | 声学模型
模块4 | 语言模型
模块5 | 解码器
模块6 | 高级声学模型
实验准备
为了后续课程,我们首先需要准备实验环境。下图是不同模块的实验需要依赖的软件和数据。
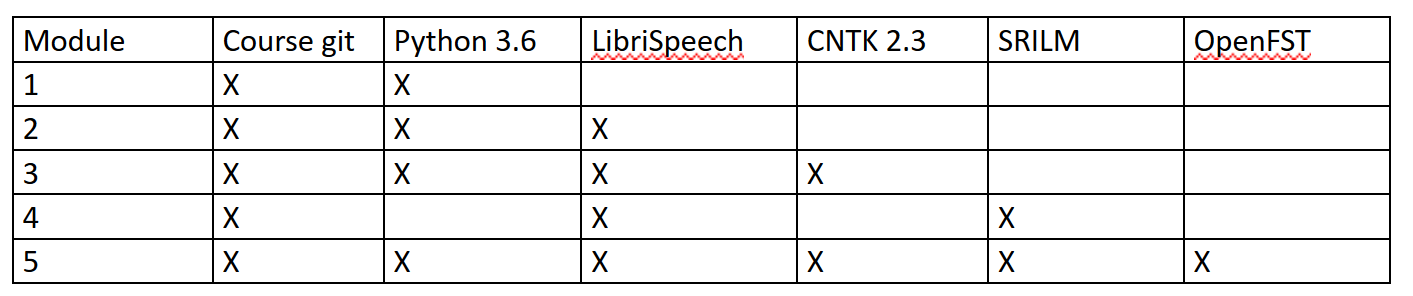
获得代码
git clone https://github.com/MicrosoftLearning/Speech-Recognition
下载数据和安装软件
我们需要安装Python3.6和CNTK2.3,这两个版本都经过测试。作者安装的是CNTK2.6,也是可以工作的。具体的安装请参考官网。
下载LibriSpeech的dev数据,这是下载链接 。
我们把它解压到Speech-Recognition下,因为代码很多地方都假设LibriSpeech的数据在这个位置,所以不要放到别的地方,最终的目录结构类似于:
lili@lili-Precision-7720:~/codes/Speech-Recognition$ ls
Experiments M1_Introduction M3_Acoustic_Modeling M5_Decoding
LibriSpeech M2_Speech_Signal_Processing M4_Language_Modeling
OpenFst请在这里下载,然后自己编译。另外语言模型部分需要SRILM,不过一般不需要安装,在前面git clone的里面就带了,如果有问题可以去这里下载,注意它的版权。
- 显示Disqus评论(需要科学上网)