本文的内容主要是翻译文档Feature extraction,介绍Kaldi的特征提取。更多本系列文章请点击Kaldi文档解读。
目录
Introduction
Kaldi的特征提取和读取波形文件的代码会提取标准的MFCC和PLP特征,它会设置合理的默认值并且提供很多人都可能要微调的选项(比如mel滤波器组的bin的个数,最大和最小的频率范围等等)。代码值能读取pcm格式的.wav文件。这些文件的后缀通常是.wav或者.pcm(有些.pcm后缀其实是sphere文件,需要用工具转成wav)。如果用户的录音不是wav文件,那么需要自行用命令行工具转换。因为LDC的数据很多是sphere格式,所以我们提供了安装sph2pipe工具的脚本。
命令行工具compute-mfcc-feats和compute-plp-feats分别用于计算MFCC和PLP特征。不带参数运行它们,就会输出帮助。
计算MFCC特征
下面我们介绍命令行工具compute-mfcc-feats计算MFCC特征的过程。这个程序需要两个参数:用于读取.wav文件的rspecifier(key是utterance id)和一个wspecifier来把特征写出去(key也是utterance id);更多解释请参考The Table concept和Specifying Table formats: wspecifiers and rspecifiers。通常输出的是一个ark文件,它包含了所有wav的特征,为了快速通过key定位,我们还需要一个对于的索引scp文件,详细可以参考Writing an archive and a script file simultaneously。这个程序并不增加delta特征(需要的话参考命令行工具add-deltas)。对于立体声,它可以通过--channel选项来指定通道(比如--channel=0或者--channel=1)。
MFCC的计算是通过Mfcc来实现计算的,它有一个Compute函数来根据wav计算特征。
MFCC的计算过程如下:
- 计算wav文件的帧数(默认帧长25ms,帧移10ms)
- 对于每一帧:
- 抽取这一帧的数据,进行可选的dithering(添加微小的随机噪声),preemphasis和直流去除(均值为零),然后乘以一个窗口函数(比如Hamming窗)
- 计算能量(如果是使用log能量而不是MFCC第一个系数作为特征的话)
- FFT然后计算功率谱
- 计算每一个bin的能量;也就是23个有重叠的三角形滤波器,这些滤波器在美尔尺度上是均匀步长的。
- 计算log能量,然后进行DCT,保留13个系数,如果第一个使用能量,那么用前面计算的能量替换第一个系数。
- 可选的提升(lifting)倒谱,把它缩放的合适的范围。
选项里指定的最小频率--low-freq和最大频率--high-freq用于控制三角形滤波器组的频率范围。默认的最小频率是0,最大频率是Nyquist频率,也就是采样频率的一半,我们也可以自己指定这两个值。比如对于16KHz采样的语音,我们可以指定 --low-freq=20 and --high-freq=7800
Kaldi的特征提取和HTK有一些不同,大部分不同来自于默认值的设置。如果使用选项--htk-compat=true,并且参数设置是正确的,那么得到的特征会非常接近HTK的特征。最大的差异是Kaldi不支持能量的max归一化。这是因为我们希望特征的计算是无状态的,这样我们就可以逐帧的计算特征。compute-mfcc-feats有一个选项--subtract-mean,它用于减去特征的均值。这里使用的是每一个utterance的均值;也有基于说话人所有utterance的归一化方法(参考cepstral mean and variance normalization)。
计算PLP特征
PLP特征的前面步骤和MFCC特殊。我们以后会增加更多文档,现在如果读者想了解的话请参考Perceptual linear predictive (PLP) analysis of speech。
特征级别的声道长度归一化(Vocal Tract Length Normalization, VTLN)
VTLN简介
对VTLN感兴趣的读者可以参考这篇论文或者Using VTLN for broadcast news transcription。
我们这里只是介绍VTLN的基本概念,Kaldi实现的是Linear VTLN,感兴趣的读者也可以参考Linear VTLN的文档。我们这里不用考虑最优的scale factor $\alpha$是怎么找出来的,只需要知道它的作用就行了。
VTLN是一种最简单和常用的说话人归一化(Speaker Normalization)技术。不同的说话人的差异可以分为内部的(intrinsic)和外部的(extrinsic)两大类。外部的大致可以认为是”后天”学习的,比如说话人的文化和情感等。而内部的是”先天”的,比如每个人的声道的解剖学结构不一样。我们这里讨论的VTLN就是第一种,也就是不同说话人的声道的长度是不同的。
根据语音学的研究,声道的长度会决定其共振(resonance)的特性。共振峰(Formants),是频谱包络的峰值(局部最大值),是和声道的共振特性密切相关的。
为了提高语音识别的准确率,有两大类方法来解决不同说话人的差异。第一种是说话人自适应(Speaker adaptation),另一种是说话人归一化(Speaker normalization)。前者可以认为是给每个特定的人一个特殊的模型,比如我们训练的GMM模型,可以用某个说话人的数据(可以是标注的数据或者也可以是未标注的数据使用现有模型来标注)来微调GMM模型的参数,因为特定说话人的数据较少,而且我们认为(假设)说话人的差异是”一致”的(比如我的嗓门高,那么我说哪个词可能都比你高),因此可以用一个线性的变换,从而没有在微调(adaptation)数据上出现的phone也能调整。而说话人归一化试图把特定的说话人的特征归一化到一个”标准”说话人上,这样就可以使用”标准”说话人的模型了,当然并不存在什么”标准”的说话人(新闻联播的主播?),所谓的标准可能就是训练数据里大家的”平均”的情况。
那怎么实现把一个”非标准”的说话人归一化到一个”标准”的说话人呢?首先我们这里的归一化只的是频谱特征(在MFCC的Filter Bank之前)。最常见的方法就是使用一个warping函数。比如需要归一化的频谱是$X(\Omega)$,而被归一化的是$Y(\Omega)$,我们可以使用warping函数$f(\Omega)$。
所谓的warping函数可以这样理解:比如”标准”说话人说/a/的第一共振峰在1000Hz(这是我随便说的数字),而”非标准”说话人说/a/的第一共振峰在500Hz,那么f(1000)=500。或者反过来说,非标注说话人的500hz对应标注说话人的1000hz。这样说有点抽象,我们来看图。
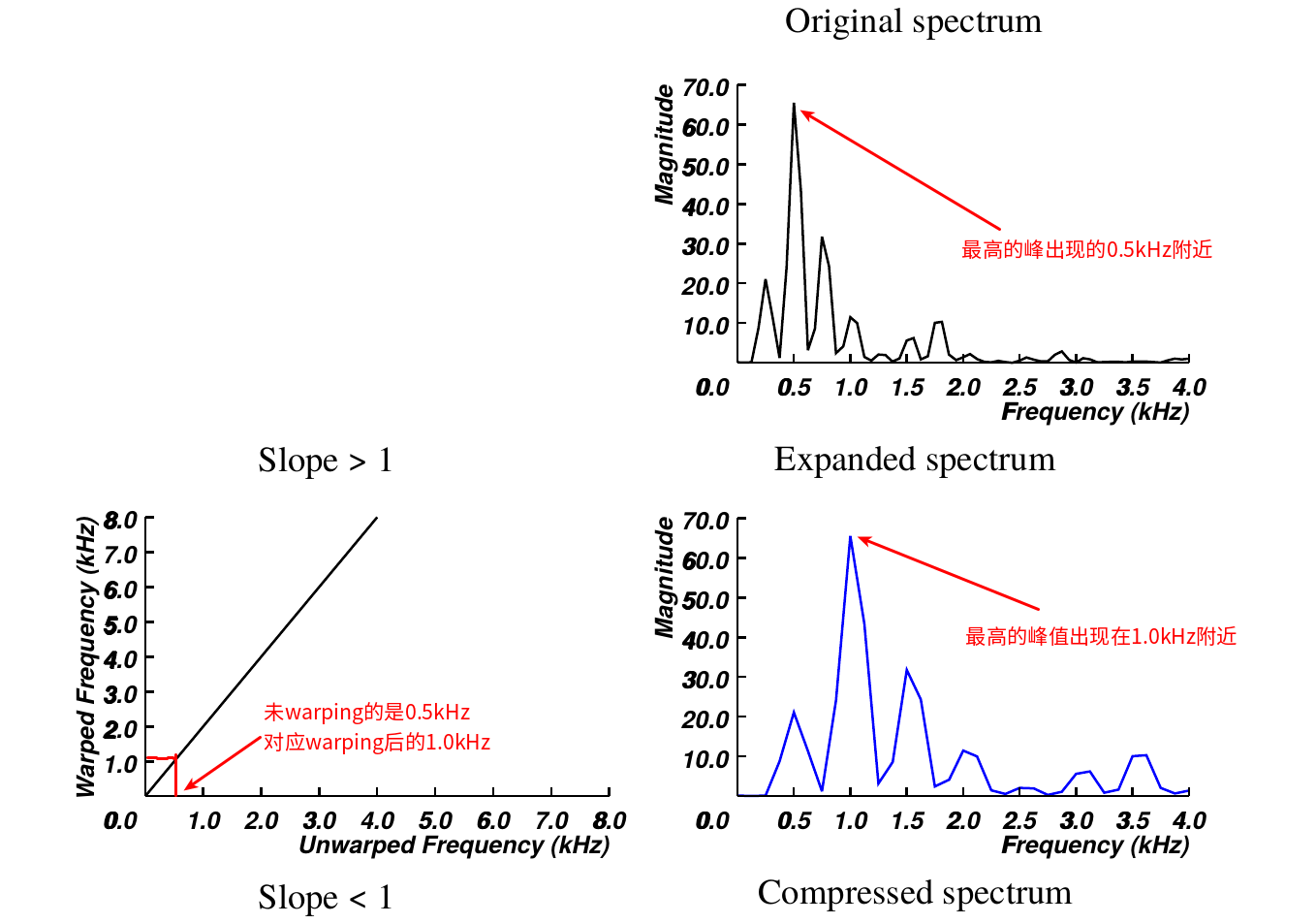 图:warping函数
图:warping函数
下面的频谱是”标准”说话人的频谱,而上面是”非标准”说话人的频谱。我们只看最高峰的情况,”标准”说话人的峰值出现在1000Hz,而”非标准”说话人的出现在500Hz。因为f(1000)=500,所有$X(f(1000))=X(500)=最高峰值$。
上图是一个”线性”的warping函数,而且斜率$2>1$,我们可以认为它把”非标准”说话人的频谱水平的拉升两倍。类似的,如果线性warping函数的斜率是0.5,那么就是把频谱压缩成原来的一半,但是频谱的形状并不改变。当然如果是非线性的warping函数,那么频谱的形状就可能变化。
压缩的例子如下图所示:
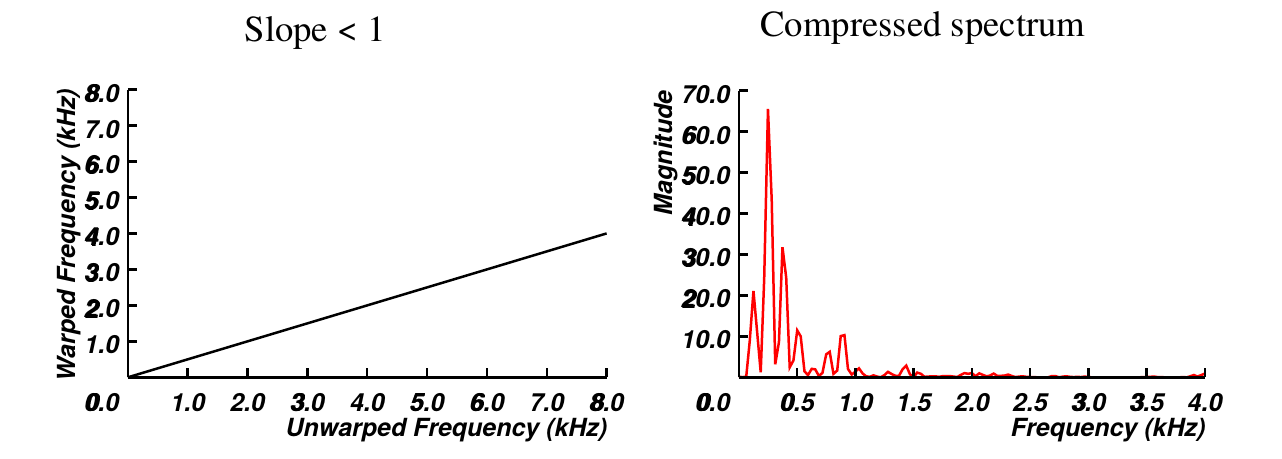 图:压缩的warping函数
图:压缩的warping函数
假设是线性的warping函数,那么每个说话人对应斜率$\alpha$应该是多少呢?有很多种估计的办法,一类是根据共振峰和声道长度的经验公式,首先估计出共振峰频率,然后”计算”出来。但是共振峰频率就很难准确估计,而且经验公式也不一定准确。还有一类方法就更加数据驱动,一般认为斜率的范围在[0.8,1.2]之间,我们可以暴力搜索$\alpha$使得变换后模型预测的似然概率更大。Kaldi使用的是后一种方法,详细的算法请参考感兴趣的读者也可以参考Linear VTLN的文档或者论文Using VTLN for broadcast news transcription。我们这里不做展开。
Kaldi的特征提取里的VTLN
compute-mfcc-feats和compute-plp-feats程序有一个--vtln-warp的选项。在目前脚本里它只是用于作为初始化线性版本的VLTN的线性变换一种方法。VTLN的目的是把三角形滤波器的中心频率做一些平移。对三角形滤波器进行平移的warping函数是频域的分段线性函数。为了理解这一点,请记住下面的关系:
0 <= low-freq <= vtln-low < vtln-high < high-freq <= nyquist频率
这里,low-freq和high-freq是MFCC和PLP里的最低和最高频率。vtln-low和vtln-high是VTLN的最低和最高截取频率,它们的作用是让所有的bin都有合理的带宽。
我们实现的VTLN的warping函数是一个分段线性函数,它把一个区间[low-freq, high-freq]映射为另一个区间[low-freq, high-freq]。假设warping函数是W(f),这里f是频率。这个分段线性函数分为三段,中间(第二个)线段是最核心的部分,它把原理的频率f映射为f/scale,这里scale是VTLN warp因子(通常是0.8到1.2)。第一个线段的一个端点是low-freq,它的另一个端点和中间线段的相交,并且满足min(f, W(f)) = vtln-low。而第三个线段的的一个端点是high-freq,另一个端点和中间线段相交,并且满足max(f, W(f)) = vtln-high。
因此只有知道了low-freq、vtln-low、vtln-high、high-freq和scale,就可以确定这三条线段,从而就知道怎么把原始的一个频率归一化成另外一个频率。
注意:我们在脚本里提供的scale只是一个初始值,Kaldi会根据训练数据调整它。当然compute-mfcc-feats并不care这个只是提供的初始值还是Kaldi通过数据学习出来的,它只是在MFCC的计算是会平移Filter Bank的三角形滤波器而已。
对于16kHz采样的录音,下面是一个合理的low-freq、vtln-low、vtln-high和high-freq的一组合理取值(Kaldi作者并没有实验更多的组合,但是这组默认参数应该工作的还不错)。
| low-freq | vtln-low | vtln-high | high-freq | nyquist |
|---|---|---|---|---|
| 40 | 60 | 7200 | 7800 | 8000 |
- 显示Disqus评论(需要科学上网)