目录
- 2.1 开发一个新项目:准备阶段
- 2.2 分析(Profiling):探究系统能力与应用性能之间的差距
- 2.3 规划:成功的基础
- 2.4 实现:一切发生的地方
- 2.5 提交:以质量为核心收尾
- 2.6 深入探索
- 总结
本章涵盖了以下内容:
- 并行项目的规划步骤
- 版本控制和团队开发工作流程
- 理解性能能力和限制
- 制定并行化常规的计划
开发一个并行应用程序或使现有应用程序并行运行,一开始可能会感到具有挑战性。经常,对并行性新手的开发者不确定从哪里开始以及可能遇到什么问题。本章着重介绍了一个用于开发并行应用程序的工作流模型,如图2.1所示。这个模型为您提供了开始工作和如何保持开发并行应用程序进展的上下文。一般来说,最好是逐步实现并行性,这样如果遇到问题,就可以撤销最近的几个提交。这种模式适合敏捷项目管理技术。
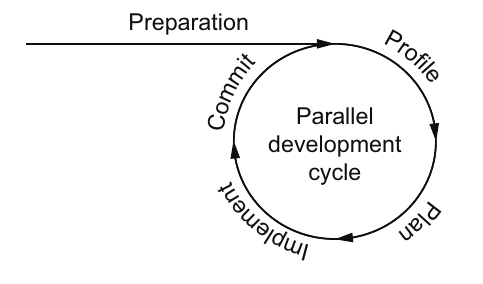 图2.1我们建议的并行开发工作流程从准备应用程序开始,然后重复四个步骤逐步并行化应用程序。这个工作流程特别适合敏捷项目管理技术。
图2.1我们建议的并行开发工作流程从准备应用程序开始,然后重复四个步骤逐步并行化应用程序。这个工作流程特别适合敏捷项目管理技术。
假设您被分配了一个新项目,需要加速并使空间网格中的应用程序并行化,如图1.9所示(Krakatau火山示例)。这可能是图像检测算法、火山灰尘模拟、结果海啸波模型,或者这三者的组合。您可以采取哪些步骤来成功实现并行化项目呢?
只是跳入项目是很诱人的。但是如果没有思考和准备,您大大降低了成功的机会。首先,您将需要为这个并行化工作制定一个项目计划,所以我们从这里开始,概述这个工作流程中的步骤。然后,随着本章的进行,我们将深入研究每个步骤,重点关注并行项目的典型特征。
快速开发:并行工作流程
首先,您需要为快速开发准备您的团队和应用程序。因为您有一个现有的串行应用程序,可以在图1.9的空间网格上运行,所以可能会有许多小的变更,并频繁进行测试以确保结果不变。代码准备包括设置版本控制、开发测试套件,以及确保代码质量和可移植性。团队准备将围绕着开发程序的流程展开。正如往常一样,项目管理将解决任务管理和范围控制的问题。
为了为开发周期做好准备,您需要确定可用计算资源的能力、应用程序的需求以及性能要求。系统基准测试有助于确定计算资源的限制,而性能分析有助于了解应用程序的需求和最昂贵的计算内核(computational kernels)。计算内核是指应用程序中既计算密集又概念上独立的部分。
通过内核分析,您将计划并行化例程和实施变更的任务。实施阶段仅在例程并行化并且代码保持可移植性和正确性时才算完成。满足这些要求后,将变更提交到版本控制系统。提交增量变更后,流程再次从应用程序和内核分析开始。
2.1 开发一个新项目:准备阶段
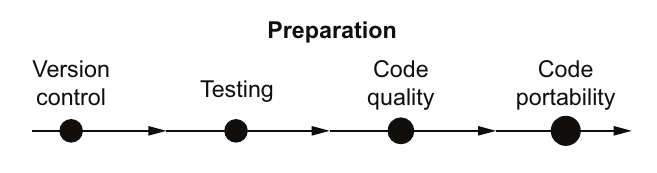 图2.2 推荐的准备组件解决了并行代码开发中重要的问题。
图2.2 推荐的准备组件解决了并行代码开发中重要的问题。
图2.2展示了准备步骤中推荐的组件。这些是已被证明对并行化项目特别重要的项目。
在这个阶段,你需要设置版本控制,为你的应用程序开发测试套件,并清理现有的代码。版本控制允许你跟踪应用程序随时间变化的更改。它允许你快速撤销错误,并在以后的日期跟踪代码中的错误。测试套件允许你在每次对代码进行更改时验证应用程序的正确性。当与版本控制结合使用时,这可以成为快速开发应用程序的强大设置。
有了版本控制和代码测试,现在你可以着手清理你的代码了。良好的代码易于修改和扩展,并且不会展示不可预测的行为。通过模块化和检查内存问题可以确保良好、干净的代码。模块化意味着你将内核实现为独立的子程序或函数,具有明确定义的输入和输出。内存问题可以包括内存泄漏、越界内存访问和未初始化内存的使用。从预测性和质量性代码开始并行化工作有助于快速进展和可预测的开发周期。如果最初的结果是由于编程错误而产生的,那么很难匹配你的串行代码。
最后,你会希望确保你的代码是可移植的。这意味着多个编译器可以编译你的代码。拥有并保持编译器的可移植性允许你的应用程序瞄准额外的平台,超出你目前可能考虑的那个平台。此外,经验表明,开发与多个编译器配合工作的代码有助于在提交到代码版本历史之前发现错误。随着高性能计算领域的快速变化,可移植性使你能够更快地适应变化。
对于复杂代码,准备时间与实际并行化的时间相比并不少见。将这些准备工作纳入项目范围和时间估算中可以避免对项目进展的挫败感。在本章中,我们假设你是从一个串行或原型应用程序开始的。然而,即使你已经开始并行化你的代码,你仍然可以从这种工作流策略中受益。接下来,我们将讨论项目准备的四个组成部分。
2.1.1 版本控制:为并行代码创建安全保险库
在并行化过程中发生许多变化是不可避免的,你可能会突然发现代码出现故障或返回不同的结果。能够通过备份到一个可工作的版本来从这种情况中恢复是至关重要的。
注意 在开始任何并行化工作之前,请检查你的应用程序中是否已经有了版本控制。
在我们的情景中,对于你的图像检测项目,你发现已经有了一个版本控制系统。但火山灰模型从未使用过任何版本控制。当你深入研究时,你发现实际上有四个不同版本的火山灰代码在各个开发者的目录中。当有一个版本控制系统在运作时,你可能需要审查团队日常操作所使用的流程。也许团队认为切换到“拉取请求”模型是个好主意,在提交之前,将更改提交供其他团队成员审查。或者你和你的团队可能认为直接提交的“推送”模型更符合并行任务的快速、小型提交。在推送模型中,提交直接在没有审查的情况下直接提交到存储库。在我们的火山灰应用程序的例子中,没有版本控制,首要任务是设法在开发者之间控制代码的不受控制的分歧。
有许多版本控制的选项。如果你没有其他偏好,我们建议使用Git,这是最常见的分布式版本控制系统。分布式版本控制系统允许多个存储库数据库,而不是单个中心化系统,这在中心化版本控制中使用。分布式版本控制对于开源项目和开发者在笔记本电脑上工作、在远程位置工作或其他不与网络连接或接近中央存储库的情况下工作的情况都是有利的。在当今的开发环境中,这是一个巨大的优势。但它也带来了额外复杂性的代价。中心化版本控制仍然很受欢迎,并且更适用于企业环境,因为所有关于源代码的信息只存在一个地方。中心化控制还提供了更好的安全性和对专有软件的保护。
有许多关于如何使用Git的好书、博客和其他资源;我们在本章末尾列出了一些。我们还在第17章列出了一些其他常见的版本控制系统。这些包括免费的分布式版本控制系统,如Mercurial和Git,商业系统如PerForce和ClearCase,以及用于中心化版本控制的CVS和SVN。无论使用哪种系统,你和你的团队都应该经常提交。以下情景在并行任务中特别常见:
- 我在添加下一个小改变后就会提交……
- 只是再加一个……然后突然代码不起作用了。
- 现在提交已经太晚了!
这种情况经常发生在我身上。因此,我试图通过定期提交来避免这个问题。
提示 如果你不想在主存储库中有很多小的提交,你可以使用一些版本控制系统(如Git)折叠这些提交,或者你可以为自己维护一个临时的版本控制系统。
提交消息是提交作者可以传达正在处理的任务以及为什么进行了某些更改的地方,无论是为了自己还是为当前或将来的团队成员。每个团队对于这些消息应该有多详细的偏好不同;我们建议在你的提交消息中尽可能多地使用细节。这是你今天通过勤奋避免以后混乱的机会。
总的来说,提交消息包括一个摘要和一个正文。摘要提供一个简短的陈述,清楚地指示了这个提交覆盖了哪些新的变化。此外,如果你使用一个问题跟踪系统,摘要行将引用该系统中的一个问题号。最后,正文包含了大部分关于提交的“为什么”和“如何”的信息。
提交信息示例
- 糟糕的提交信息:
- 修复了一个错误
- 良好的提交信息:
- 修复了在OpenMP版本的模糊运算符中出现的竞态条件
- 优秀的提交信息:
- [Issue #21] 修复了在OpenMP版本的模糊运算符中出现的竞态条件。竞态条件导致了GCC、Intel和PGI编译器之间的结果不一致。为了修复这个问题,引入了OMP BARRIER,强制线程在计算加权模具和之前进行同步。确认代码在GCC、Intel和PGI编译器上编译和运行,并且产生了一致的结果。
第一个信息实际上没有帮助任何人理解修复了什么错误。第二个信息有助于定位解决与模糊运算符中竞态条件相关的问题。最后一个信息在外部问题跟踪系统中引用了问题编号 (#21),并在第一行提供了提交摘要。提交正文,即摘要下的两个要点,提供了具体需要做什么以及为什么要做的更多细节,并向其他开发人员表明您在提交之前花时间测试了您的版本。
有了版本控制计划,并且团队开发流程至少达成了初步一致后,我们就可以继续下一步了。
2.1.2 测试套件:创建健壮、可靠应用程序的第一步
测试套件是一组用于检验应用程序部分功能的问题,确保相关代码部分仍然有效。除了最简单的代码,测试套件对所有代码都是必需的。每次修改后,你都应该进行测试以确保得到的结果是相同的。这听起来很简单,但一些代码在使用不同的编译器和处理器数量时,可能会得到略有不同的结果。
示例:用于验证结果的Krakatau情景测试
你的项目有一个海浪模拟应用程序,可以生成经过验证的结果。经过验证的结果是与实验或现实数据进行比较的模拟结果。经过验证的模拟代码非常有价值。你不希望在并行化代码时失去这些价值。
在我们的情景中,你和你的团队使用了两种不同的编译器进行开发和生产。第一种是GNU编译器集合(GCC)中的C编译器,这是一种普及的、免费提供的编译器,分发在所有Linux发行版和许多其他操作系统中。C编译器在口语中被称为GCC编译器。你的应用程序还使用了商业提供的Intel C编译器。
下图显示了用于预测波高和总质量的验证测试问题的假设结果。根据使用的编译器和模拟中使用的处理器数量,输出会略有不同。
 哪些使用不同编译器和处理器数量进行计算的差异是可以接受的?
哪些使用不同编译器和处理器数量进行计算的差异是可以接受的?
在这个示例中,程序报告的两个指标存在差异。在没有额外信息的情况下,很难确定哪个是正确的,哪些解决方案中的变异是可以接受的。一般来说,程序输出的差异可能是由于以下原因:
- 编译器或编译器版本的变化
- 硬件的变化
- 编译器优化或编译器或编译器版本之间的微小差异
- 操作顺序的变化,特别是由于代码并行化
在接下来的部分中,我们将讨论这些差异可能出现的原因,如何确定哪些变异是合理的,以及如何设计测试以在提交到你的代码库之前捕捉到真正的错误。
理解由于并行处理导致的结果变化
并行处理过程本质上改变了操作的顺序,从而略微修改了数值结果。但并行处理中的错误也会产生细微的差异。在并行代码开发中理解这一点非常重要,因为我们需要与单处理器运行进行比较,以确定我们的并行代码是否正确。在第5.7节中,我们将讨论如何通过全局求和技术来减少数值误差,使并行处理错误更加明显。
对于我们的测试套件,我们需要一个能够在小误差范围内比较数值字段的工具。过去,测试套件开发人员必须为此目的创建一个工具,但近年来市场上出现了一些数值差异工具。其中两个工具是:
- Numdiff(https://www.nongnu.org/numdiff/)
- Ndiff(https://www.math.utah.edu/~beebe/software/ndiff/)
或者,如果你的代码以HDF5或NetCDF文件格式输出其状态,这些格式自带的工具允许你在不同容差范围内比较文件中存储的值。
HDF5® 是最初称为分层数据格式(Hierarchical Data Format)现称为HDF的软件的第5版,可从HDF Group(https://www.hdfgroup.org/)免费下载,是一种用于输出大数据文件的常见格式。
NetCDF或网络通用数据格式(Network Common Data Form)是气候和地球科学界使用的另一种格式。NetCDF的当前版本建立在HDF5之上。你可以在Unidata项目中心的网站(https://www.unidata.ucar.edu/software/netcdf/)找到这些库和数据格式。
这两种文件格式都使用二进制数据以提高速度和效率。二进制数据是数据的机器表示形式。虽然这种格式对你我来说看起来像乱码,但HDF5有一些有用的工具可以让我们查看其中的内容。h5ls工具列出文件中的对象,例如所有数据数组的名称。h5dump工具转储每个对象或数组中的数据。最重要的是,h5diff工具比较两个HDF文件并报告超过数值容差的差异。HDF5和NetCDF以及其他并行输入/输出(I/O)主题将在第16章中详细讨论。
使用 CMake 和 CTest 自动测试代码
近年来,许多测试系统应运而生。其中包括 CTest、Google Test、pFUnit Test 等等。你可以在第17章找到关于这些工具的更多信息。现在,让我们看看使用 CTest 和 ndiff 创建的系统。
CTest 是 CMake 系统的一个组件。CMake 是一个配置系统,能够将生成的 makefile 适配到不同的系统和编译器中。将 CTest 测试系统集成到 CMake 中,将两者紧密结合成一个统一的系统。这为开发人员提供了很多便利。使用 CTest 实施测试的过程相对容易。单个测试可以编写成任意命令序列。将这些测试集成到 CMake 系统中需要在 CMakeLists.txt 中添加以下内容:
enable_testing()
add_test(<testname> <executable name> <arguments to executable>)
然后你可以通过 make test、ctest 或 ctest -R mpi(其中 mpi 是一个运行匹配测试名称的正则表达式)来调用测试。
让我们通过一个示例来演示如何使用 CTest 系统创建测试。
示例:CTest 先决条件
你需要安装 MPI、CMake 和 ndiff 来运行这个示例。对于 MPI(消息传递接口),我们将在 Mac 上使用 OpenMPI 4.0.0 和 CMake 3.13.3(包括 CTest),在 Ubuntu 上使用旧版本。我们将使用安装在 Mac 上的 GCC 编译器版本 8,而不是默认的编译器。然后通过包管理器安装 OpenMPI、CMake 和 GCC(GNU 编译器集合)。我们将在 Mac 上使用 Homebrew,在 Ubuntu Linux 上使用 Apt 和 Synaptic。确保从 libopenmpi-dev 获取开发头文件(如果这些文件从运行时中分离出来)。手动安装 ndiff,可以从 https://www.math.utah.edu/~beebe/software/ndiff/ 下载该工具,并运行 ./configure、make 和 make install。
制作两个源文件,如清单2.1所示,以创建该简单测试系统的应用程序。我们将使用一个计时器在串行和并行程序中产生小的输出差异。请注意,你可以在 https://github.com/EssentialsofParallelComputing/Chapter2 找到本章的源代码。
TimeIt.c:
#include <unistd.h>
#include <stdio.h>
#include <time.h>
int main(int argc, char *argv[]){
struct timespec tstart, tstop, tresult;
// Start timer, call sleep and stop timer
clock_gettime(CLOCK_MONOTONIC, &tstart);
sleep(10);
clock_gettime(CLOCK_MONOTONIC, &tstop);
// Timer has two values for resolution and prevent overflows
tresult.tv_sec = tstop.tv_sec - tstart.tv_sec;
tresult.tv_nsec = tstop.tv_nsec - tstart.tv_nsec;
// Print calculated time from timers
printf("Elapsed time is %f secs\n", (double)tresult.tv_sec +
(double)tresult.tv_nsec*1.0e-9);
}
MPITimeIt.c:
#include <unistd.h>
#include <stdio.h>
#include <mpi.h>
int main(int argc, char *argv[]){
int mype;
// Initialize MPI and get processor rank
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &mype);
double t1, t2;
// Start timer, call sleep and stop timer
t1 = MPI_Wtime();
sleep(10);
t2 = MPI_Wtime();
// Print timing output from first processor
if (mype == 0) printf( "Elapsed time is %f secs\n", t2 - t1 );
// Shutdown MPI
MPI_Finalize();
}
现在你需要一个测试脚本来运行这些应用程序,并生成一些不同的输出文件。运行这些脚本后,应对输出进行数值比较。以下是你可以放在名为 mympiapp.ctest 文件中的过程示例。你应该运行 chmod +x 使其可执行。
#!/bin/sh
# Run a serial test
./TimeIt > run0.out
# Run the first MPI test on 1 processor
mpirun -n 1 ./MPITimeIt > run1.out
# Run the second MPI test on 2 processors
mpirun -n 2 ./MPITimeIt > run2.out
# Compare the output for the two MPI jobs with a tolerance of 1%
# Reduce the tolerance to 1.0e-5 to get test to fail
ndiff --relative-error 1.0e-2 run1.out run2.out
# Capture the status set by the ndiff command
test1=$?
# Compare the output for the serial job and the 2 processor MPI run with a tolerance of 1%
ndiff --relative-error 1.0e-2 run0.out run2.out
# Capture the status set by the ndiff command
test2=$?
# Exit with the cumulative status code so CTest can report pass or fail
exit "$(($test1+$test2))"
这个测试首先在第5行以0.1%的容差比较1和2个处理器的并行作业的输出。然后在第7行将串行运行与2个处理器的并行作业进行比较。要使测试失败,可以尝试将容差减小到1.0e–5。CTest 使用第9行的退出代码报告通过或失败。将一堆 CTest 文件添加到测试套件中的最简单方法是使用一个循环,找到所有以 .ctest 结尾的文件并将这些文件添加到 CTest 列表中。以下是一个包含创建两个应用程序的附加指令的 CMakeLists.txt 文件示例:
cmake_minimum_required (VERSION 3.20)
project (TimeIt)
# Enables CTest functionality in CMake
enable_testing()
# CMake has a built-in routine to find most MPI packages
# Defines MPI_FOUND if found
# MPI_INCLUDE_PATH (being replaced by MPI_<lang>_INCLUDE_PATH)
# MPI_LIBRARIES (being replaced by MPI_<lang>_LIBRARIES)
find_package(MPI)
message("MPI FOUND: ${MPI_FOUND}")
# Adds build targets of TimeIt and MPITimeIt with source code file(s) TimeIt.c and MPITimeIt.c
add_executable(TimeIt TimeIt.c)
add_executable(MPITimeIt MPITimeIt.c)
# Need an include path to the mpi.h file and to the MPI library
target_include_directories(MPITimeIt PUBLIC ${MPI_INCLUDE_PATH})
target_link_libraries(MPITimeIt ${MPI_LIBRARIES})
# This gets all files with the extension 'ctest' and adds it to the test list for CTest
# The ctest file needs to be executable or explicitly launched with the 'sh' command as below
file(GLOB TESTFILES RELATIVE "${CMAKE_CURRENT_SOURCE_DIR}" "*.ctest")
foreach(TESTFILE ${TESTFILES})
add_test(NAME ${TESTFILE} WORKING_DIRECTORY ${CMAKE_BINARY_DIR}
COMMAND sh ${CMAKE_CURRENT_SOURCE_DIR}/${TESTFILE})
endforeach()
# A custom command, distclean, to remove files that are created
add_custom_target(distclean COMMAND rm -rf CMakeCache.txt CMakeFiles
CTestTestfile.cmake Makefile Testing cmake_install.cmake)
第6行的 find_package(MPI) 命令定义了 MPI_FOUND、MPI_INCLUDE_PATH 和 MPI_LIBRARIES。这些变量包括新版本 CMake 中的 MPI_<lang>INCLUDE_PATH 和 MPI<lang>_LIBRARIES,以便为 C、C++ 和 Fortran 提供不同的路径。现在只需运行测试:
mkdir build && cd build
cmake ..
make
make test
或者
ctest
运行的结果类似:
Test project /media/lili/mydisk/codes/EssentialsOfParallelComputing/Chapter2/Listing1/build
Start 1: mympiapp.ctest
1/1 Test #1: mympiapp.ctest ................... Passed 30.37 sec
100% tests passed, 0 tests failed out of 1
Total Test time (real) = 30.37 sec
这个测试基于 sleep 函数和定时器,因此可能会通过,也可能不会通过。测试结果位于 Testing/Temporary/* 中。
在这个测试中,我们比较了应用程序各次运行之间的输出。通常的做法是保存其中一次运行的标准文件,并将其与测试脚本一起存储以进行比较。这个比较可以检测出会导致应用程序新版本与早期版本结果不同的变化。当这种情况发生时,这是一个危险信号;检查新版本是否仍然正确。如果是这样,你应该更新标准文件。
你的测试套件应尽可能地测试代码的各个部分。度量代码覆盖率可以量化测试套件完成任务的程度,这以源代码行数的百分比表示。测试开发人员常说,没有测试的代码部分是有问题的,因为即使现在没有问题,将来也会有。在并行化代码时所做的所有更改中,出错是不可避免的。虽然高代码覆盖率很重要,但对于我们的并行化工作来说,更关键的是对并行化部分进行测试。许多编译器都有生成代码覆盖率统计的功能。对于 GCC,gcov 是分析工具;对于 Intel,是 Codec。我们将看看 GCC 的工作原理。
使用 GCC 进行代码覆盖率测试
- 在编译和链接时添加标志 -fprofile-arcs 和 -ftest-coverage
- 在一系列测试上运行已插桩的可执行文件
- 运行 gcov <source.c> 以获取每个文件的覆盖率
注意:对于使用 CMake 构建的项目,源文件名需要额外添加一个 .c 扩展名;例如,gcov CMakeFiles/stream_triad.dir/stream_triad.c.c 处理 CMake 添加的扩展名。
- 你将得到类似如下的输出:
88.89% of 9 source lines executed in file <source>.c Creating <source>.c.gcov
gcov 输出文件包含一个列表,每行前面附有执行次数。
理解不同类型的代码测试
还有不同类型的测试系统。在本节中,我们将涵盖以下类型:
- 回归测试——定期运行以防止代码退化。通常使用 cron 作业调度程序在指定时间运行,通常是每晚或每周。
- 单元测试——在开发过程中测试子例程或其他小部分代码的操作。
- 持续集成测试——越来越受欢迎,这些测试在代码提交时自动触发运行。
- 提交测试——一小组可以从命令行运行的测试,时间相对较短,用于在提交前进行测试。
所有这些测试类型对于一个项目都很重要,不应该只依赖其中一种,正如图2.3所示,这些测试应结合使用。对于并行应用程序,测试尤其重要,因为在开发周期的早期发现错误意味着你不会在运行 6 小时后调试 1,000 个处理器。
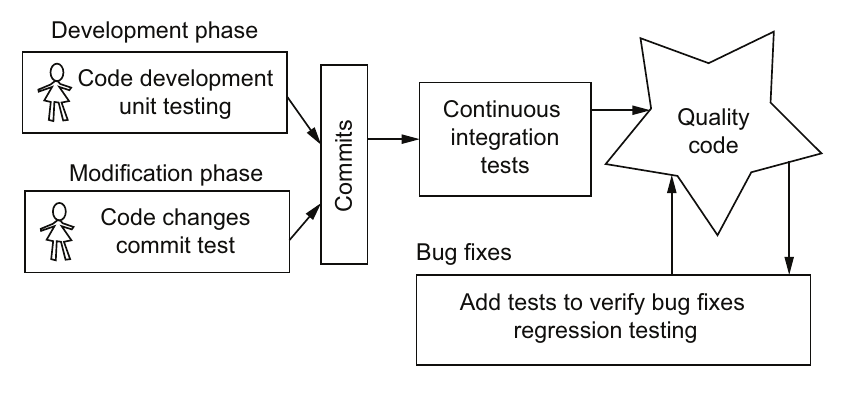 图2.3 不同的测试类型针对代码开发的不同部分,以创建始终可以发布的高质量代码
图2.3 不同的测试类型针对代码开发的不同部分,以创建始终可以发布的高质量代码
单元测试最好在开发代码时创建。单元测试的真正爱好者使用测试驱动开发(TDD),先创建测试,然后编写代码以通过这些测试。在并行代码开发中包含这些类型的测试,包括在并行语言和实现中测试其操作。在这个层面上识别问题更容易解决。
提交测试是你应该在项目中首先添加的测试,以便在代码修改阶段大量使用。这些测试应该测试代码中的所有例程。通过随时可用的这些测试,团队成员可以在提交到代码库之前运行这些测试。我们建议开发人员在提交之前从命令行调用这些测试,例如 Bash 或 Python 脚本,或 Makefile。
示例:使用 CMake 和 CTest 的提交测试开发工作流程
为了在 CMakeLists.txt 中进行提交测试,创建以下列表中显示的三个文件。使用前面测试中的 Timeit.c,但将睡眠间隔从10改为30。
blur_short.ctest:
#!/bin/sh
make
blur_long.ctest:
#!/bin/sh
./TimeIt
CMakeLists.txt:
cmake_minimum_required (VERSION 3.0)
project (TimeIt)
# Enables CTest functionality in CMake
enable_testing()
add_executable(TimeIt TimeIt.c)
# Add two tests, one with commit in the name
add_test(NAME blur_short_commit WORKING_DIRECTORY ${CMAKE_BINARY_DIRECTORY}
COMMAND sh ${CMAKE_CURRENT_SOURCE_DIR}/blur_short.ctest)
add_test(NAME blur_long WORKING_DIRECTORY ${CMAKE_BINARY_DIRECTORY}
COMMAND sh ${CMAKE_CURRENT_SOURCE_DIR}/blur_long.ctest)
# Custom target "commit_tests" to run all tests with commit in the name
add_custom_target(commit_tests COMMAND ctest -R commit DEPENDS TimeIt)
# A custom command, distclean, to remove files that are created
add_custom_target(distclean COMMAND rm -rf CMakeCache.txt CMakeFiles
CTestTestfile.cmake Makefile Testing cmake_install.cmake)
提交测试可以通过 ctest -R commit 或在 CMakeLists.txt 中添加的自定义目标 make commit_tests 来运行。make test 或 ctest 命令会运行所有测试,包括耗时较长的测试。提交测试命令会挑选名称中包含 commit 的测试,以获得覆盖关键功能但运行速度较快的一组测试。现在的工作流程是:
- 编辑源代码:vi mysource.c
- 构建代码:make
- 运行提交测试:make commit_tests
- 提交代码更改:git commit
如此反复。持续集成测试由提交到主代码库触发。这是防止提交不良代码的额外防护措施。测试可以与提交测试相同,也可以更广泛。顶级持续集成工具包括:
- Jenkins(https://www.jenkins.io)
- Travis CI for GitHub and Bitbucket(https://travis-ci.com)
- GitLab CI(https://about.gitlab.com/stages-devops-lifecycle/continuous-integration/)
- CircleCI(https://circleci.com)
回归测试通常通过 cron 作业在夜间运行。这意味着测试套件可以比其他类型的测试套件更广泛。这些测试可能时间较长,但应在早晨报告前完成。由于运行时间较长和报告的周期性,通常会在回归测试中运行额外的测试,例如内存检查和代码覆盖率。回归测试的结果通常会随时间跟踪,“通过墙”被认为是项目健康状况的标志。
理想测试系统的进一步要求
尽管前面描述的测试系统对于大多数用途已经足够,但对于较大的高性能计算(HPC)项目,还有更多有用的功能。这些类型的HPC项目可能拥有庞大的测试套件,并可能需要在批处理系统中运行以访问更大的资源。
协作测试系统(CTS)就是为这些需求开发的一个系统示例,其项目地址为:https://sourceforge.net/projects/ctsproject/。它使用Perl脚本在一组固定的测试服务器(通常为10台)上并行启动测试到批处理系统中。每个测试完成后,会启动下一个测试,从而避免一次性向系统提交大量作业。CTS系统还能自动检测批处理系统和MPI类型,并为每个系统调整脚本。报告系统使用cron作业在夜间早期启动测试。跨平台报告会在早上启动,然后发送出去。
示例:用于HPC项目的Krakatau场景测试套件
在审查您的应用程序后,您发现图像检测应用程序有大量用户。因此,您的团队决定在每次提交之前设置广泛的回归测试,以避免对用户造成影响。运行时间较长的内存正确性测试在夜间进行,性能每周跟踪一次。海洋波浪模拟是新的,用户较少,但您希望确保验证问题继续给出相同的答案。由于它的运行时间太长,无法作为提交测试,因此您运行缩短版本,并每周运行完整版本。
对于这两个应用程序,设置了持续集成测试,以构建代码并运行一些较小的测试。灰烬羽流模型刚开始开发,因此您决定使用单元测试检查每个新添加的代码段。
2.1.3 寻找并修复内存问题
良好的代码质量至关重要。并行化常常会暴露任何代码缺陷;这些缺陷可能是未初始化的内存或内存覆盖问题。
- 未初始化内存 是指在其值被设置之前就被访问的内存。当您为程序分配内存时,该内存位置可能包含任何值。如果在设置之前使用这些值,会导致不可预测的行为。
- 内存覆盖 发生在数据写入到不属于某个变量的内存位置时。这种情况的一个例子是超出数组或字符串边界进行写操作。
为了捕捉这些问题,我们建议使用内存正确性工具来彻底检查您的代码。其中最好的工具之一是免费提供的Valgrind程序。Valgrind是一个在机器码级别运行的仪器框架,通过合成CPU执行指令。在Valgrind的框架下开发了许多工具。第一步是在您的系统上使用包管理器安装Valgrind。如果您运行的是最新版本的macOS,可能需要几个月时间才能将Valgrind移植到新内核。最好的方法是使用另一台计算机运行Valgrind,或者使用较旧版本的macOS,或者启动一个虚拟机或Docker镜像。
要运行Valgrind,请像往常一样执行您的程序,只需在前面加上valgrind命令。对于MPI作业,valgrind命令放在mpirun之后和可执行文件名称之前。Valgrind与GCC编译器搭配使用效果最佳,因为GCC开发团队采纳了它,并致力于消除可能会混淆诊断输出的假阳性结果。建议在使用Intel编译器时,禁用矢量化编译,以避免关于矢量指令的警告。您还可以尝试第17.5节中列出的其他内存正确性工具。
使用 Valgrind Memcheck 查找内存问题
Memcheck 工具是 Valgrind 工具套件中的默认工具。它拦截每一条指令,并检查各种类型的内存错误,在运行的开始、期间和结束时生成诊断信息。这会使运行速度减慢一个数量级。如果您以前没有使用过它,请做好准备迎接大量输出。一个内存错误可能会导致许多其他错误。最好的策略是从第一个错误开始,修复它,然后再次运行。要了解 Valgrind 的工作原理,请尝试清单2.2中的示例代码【译注:应该是2.3】。要执行 Valgrind,请在可执行文件名称前插入 valgrind 命令,如下所示:
valgrind <./my_app>
或者
mpirun -n 2 valgrind <./myapp>
#include <stdlib.h>
int main(int argc, char *argv[]){
int ipos, ival;
int *iarray = (int *) malloc(10*sizeof(int));
if (argc == 2) ival = atoi(argv[1]);
for (int i = 0; i<=10; i++){ iarray[i] = ipos; }
for (int i = 0; i<=10; i++){
if (ival == iarray[i]) ipos = i;
}
}
使用 gcc -g -o test test.c 编译此代码,然后使用 valgrind –leak-check=full ./test 运行它。Valgrind 的输出会夹杂在程序的输出中,可以通过前缀的双等号(==)来识别。以下显示了该示例输出中的一些重要部分:
valgrind --leak-check=full ./test 2
==14324== Invalid write of size 4
==14324== at 0x400590: main (test.c:7)
==14324==
==14324== Conditional jump or move depends on uninitialized value(s)
==14324== at 0x4005BE: main (test.c:9)
==14324==
==14324== Invalid read of size 4
==14324== at 0x4005B9: main (test.c:9)
==14324==
==14324== 40 bytes in 1 blocks are definitely lost in loss record 1 of 1
==14324== at 0x4C29C23: malloc (vg_replace_malloc.c:299)
==14324== by 0x40054F: main (test.c:5)
此输出显示了关于几个内存错误的报告。最难理解的是未初始化内存报告。Valgrind 在第9行报告错误,当时一个未初始化的值被用于决策。实际上错误出现在第7行,在那里 iarray 被设置为 ipos,而 ipos 没有被赋值。在更复杂的程序中,确定错误的来源可能需要仔细分析。
2.1.4 提高代码的可移植性
最后一个代码准备要求是提高代码在更广泛的编译器和操作系统上的可移植性。可移植性始于基础的 HPC 语言,通常是 C、C++ 或 Fortran。每种语言都保持编译器实现的标准,并且定期发布新的标准版本。但这并不意味着编译器能够迅速实现这些标准。通常,从标准发布到编译器供应商全面实现之间的滞后时间会很长。例如,Polyhedron Solutions 网站(http://mng.bz/yYne)报告,没有任何 Linux Fortran 编译器完全实现 2008 年标准,且不到一半的编译器完全实现 2003 年标准。当然,关键在于编译器是否实现了您所需的功能。C 和 C++ 编译器在新标准的实现方面通常更为及时,但滞后时间仍可能给积极开发的团队带来问题。此外,即使功能被实现了,这也不意味着这些功能在各种设置中都能正常工作。
使用多种编译器进行编译有助于检测编码错误或识别代码在语言解释方面的“边缘”情况。可移植性在使用在特定环境中效果最佳的工具时提供了灵活性。例如,Valgrind 最适合与 GCC 配合使用,但线程正确性工具 Intel® Inspector 最适合在应用程序使用 Intel 编译器进行编译时使用。可移植性在使用并行语言时也有帮助。例如,CUDA Fortran 仅在 PGI 编译器上可用。当前 GPU 指令集语言 OpenACC 和 OpenMP(带有目标指令)的实现仅在少数编译器上可用。幸运的是,MPI 和 CPU 的 OpenMP 在许多编译器和系统上广泛可用。我们需要明确的是,OpenMP 有三种不同的功能:1)通过 SIMD 指令进行矢量化,2)原始 OpenMP 模型中的 CPU 线程化,3)通过新目标指令将任务卸载到加速器(通常是 GPU)。
示例:Krakatau 场景与代码可移植性 您的图像检测应用程序仅能在 GCC 编译器上编译。您的并行项目添加了 OpenMP 线程化。您的团队决定让它在 Intel 编译器上编译,以便使用 Intel Inspector 查找线程竞争条件。灰烬羽流模拟程序是用 Fortran 编写的,目标是在 GPU 上运行。基于您对当前 GPU 语言的研究,您决定将 PGI 作为开发编译器之一,以便使用 CUDA Fortran。
2.2 分析(Profiling):探究系统能力与应用性能之间的差距
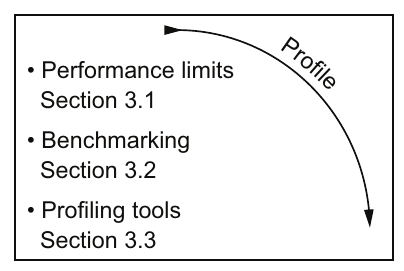 图2.4 分析步骤的目的是确定需要处理的应用程序代码中最重要的部分。
图2.4 分析步骤的目的是确定需要处理的应用程序代码中最重要的部分。
分析(图2.4)确定硬件性能能力并将其与您的应用程序性能进行比较。能力与当前性能之间的差距揭示了性能改进的潜力。
分析过程的第一部分是确定限制您应用程序性能的因素。我们将在第3.1节详细说明应用程序可能的性能限制。简而言之,今天大多数应用程序受到内存带宽或与内存带宽密切相关的限制。一些应用程序可能受到可用浮点运算(flops)的限制。我们将在第3.2节介绍计算理论性能限制的方法。我们还将描述能够测量该硬件限制下可实现性能的基准测试程序。
一旦了解了潜在性能,就可以对您的应用程序进行分析。我们将在第3.3节介绍使用一些分析工具的过程。您的应用程序当前性能与硬件能力之间的差距将成为并行化下一步改进的目标。
2.3 规划:成功的基础
在掌握了有关您的应用程序和目标平台的信息后,现在是时候将一些细节纳入计划中。图2.5显示了这一步的一些部分。由于并行化所需的努力,在开始实施步骤之前进行研究是明智的。
 图2.5 规划步骤为成功的项目奠定基础。
图2.5 规划步骤为成功的项目奠定基础。
很可能过去曾遇到过类似的问题。近年来,您会发现许多关于并行化项目和技术的研究文章。但信息最丰富的来源之一是发布的基准测试和迷你应用程序(mini-apps)。通过迷你应用程序,您不仅可以获得研究资料,还可以研究实际的代码。
2.3.1 基准测试和迷你应用程序探索
高性能计算社区已经开发了许多用于基准测试系统、性能实验和算法开发的基准测试、核心和示例应用程序。我们将在第17.4节列出其中一些。您可以使用基准测试来帮助选择最适合您应用程序的硬件,而迷你应用程序则提供了关于最佳算法和编码技术的帮助。
基准测试旨在突出硬件性能的特定特征。现在您对您应用程序的性能限制有了一定的了解,应该查看与您情况最相关的基准测试。如果您在大型数组上进行线性访问计算,那么流基准测试就很适合。如果您的核心是迭代矩阵求解器,那么高性能共轭梯度(HPCG)基准测试可能更好。迷你应用程序更专注于一类科学应用程序中常见的操作或模式。
值得看看这些基准测试或迷你应用程序是否与您正在开发的并行应用程序相似。如果是这样,研究这些相似操作可以节省大量工作。通常,这些代码已经进行了大量工作,探索如何获得最佳性能,移植到其他并行语言和平台,或者量化性能特征。
目前,基准测试和迷你应用程序主要来自科学计算领域。我们将在我们的示例中使用其中一些,并鼓励您将其用于您的实验和示例代码。这些示例中展示了许多关键操作和并行实现。
示例:Ghost 单元更新 许多基于网格的应用程序在分布式内存实现中将其网格分布到处理器之间(请参见图1.13)。因此,这些应用程序需要使用相邻处理器的值更新其网格的边界。这个操作称为 ghost 单元更新。Richard Barrett 在 Sandia National Laboratories 开发了 MiniGhost 迷你应用程序,用于尝试以不同方式执行此类操作。MiniGhost 迷你应用程序是可在 https://mantevo.org/default.php 上找到的 Mantevo 迷你应用程序套件的一部分。
2.3.2 核心数据结构的设计和代码模块化
数据结构的设计对您的应用程序有着长远的影响。这是需要事先做出的决定之一,因为后期更改设计会变得困难。在第4章中,我们将讨论一些重要的考虑因素,并通过一个案例研究来演示对不同数据结构性能进行分析的过程。
首先,重点关注数据和数据移动。这是当今硬件平台的主要考虑因素。它还导致了有效的并行实现,其中对数据的仔细移动变得更加重要。如果我们考虑文件系统和网络,数据移动将主导一切。
2.3.3 算法:重新设计以支持并行化
现在,您应该评估应用程序中的算法。这些算法是否可以修改为并行编码?是否有更好可扩展性的算法?例如,您的应用程序可能有一段代码只占运行时间的5%,但具有$N^2$的算法规模,而其余代码以N为规模,其中N是单元数或某些其他数据组件。随着问题规模的增长,这5%很快就会变成20%,然后甚至更高。很快它将主导运行时间。
为了识别这种问题,您可能需要对一个更大的问题进行分析,然后查看运行时间的增长而不是绝对百分比。
示例:灰尘喷射模型的数据结构
您的灰尘喷射模型处于早期开发阶段。有几种拟议的数据结构和功能步骤的分解。您的团队决定花一周时间分析这些选择,在这些选择固定在代码中之前,因为您知道以后要改变这些将会很困难。其中一个决定是使用哪种多材料数据结构,因为许多材料将只存在于网格的小区域内,是否有一种好的方法可以利用这一点。您决定探索一种稀疏数据存储数据结构以节省内存(有些在第4.3.2节中讨论)并实现更快的代码。
示例:波浪模拟代码的算法选择
波浪模拟代码的并行化工作预计将添加OpenMP和矢量化。您听说过每种并行化方法的不同实现风格。您指派两名团队成员查看最近的论文,以了解哪种方法效果最好。您的其中一名团队成员对其中一种更难的例程的并行化表示担忧,这种例程具有复杂的算法。目前的技术看起来并不容易并行化。您同意并要求团队成员研究可能与当前做法不同的替代算法。
2.4 实现:一切发生的地方
这一步是我认为是近战战斗的阶段。在战壕里,逐行、逐循环、逐例程地将代码转化为并行代码。这是您所有关于CPU和GPU上并行实现的知识发挥作用的地方。正如图2.6所示,这部分内容将在书的后面大部分章节中涵盖。关于并行编程语言的章节,即第6-8章针对CPU,第9-13章针对GPU,开启了您发展这方面专业知识的旅程。
 图2.6 规划步骤为成功的项目奠定基础。
图2.6 规划步骤为成功的项目奠定基础。
在实现步骤中,重要的是要跟踪您的总体目标。在这一点上,您可能已经决定了您的并行语言,也可能没有。即使您已经做出了选择,您也应该在深入实现时重新评估您的选择。对于您选择项目方向的一些最初考虑因素包括:
- 您的加速要求是否相当温和?您应该在第6和第7章中探索矢量化和共享内存(OpenMP)并行性。
- 您是否需要更多的内存来扩展规模?如果是这样,您将希望在第8章中探索分布式内存并行性。
- 您是否需要大幅度加速?那么,在第9-13章中探索GPU编程可能值得一试。
在这一实现步骤中的关键是将工作分解为可管理的块,并将工作分配给团队成员。既有在一种例程中获得一个数量级的加速的振奋感,也意识到总体影响很小,还有很多工作要做。坚持和团队合作对于达到目标至关重要。
示例:对并行语言的重新评估
您将OpenMP和矢量化添加到波浪模拟代码中的项目进行得很顺利。您已经为典型计算获得了一个数量级的加速。但随着应用程序加速,您的用户想要运行更大的问题,而他们没有足够的内存。您的团队开始考虑添加MPI并行性以访问更多内存可用的节点。
2.5 提交:以质量为核心收尾
提交步骤通过仔细检查来确保代码质量和可移植性得到维护,从而完成了这一部分的工作。图2.7展示了这一步骤的组成部分。这些检查的程度高度取决于应用程序的性质。对于具有许多用户的生产应用程序,测试需要更加彻底。
 图2.7 提交步骤的目标是在达到最终目标的阶梯上创建一个坚实的台阶。
图2.7 提交步骤的目标是在达到最终目标的阶梯上创建一个坚实的台阶。
注意:此时,捕捉相对较小规模的问题比在使用一千个处理器运行六天后调试复杂问题要容易得多。
团队必须全力支持提交流程并共同努力跟随它。建议召开团队会议制定所有人要遵循的程序。在改善代码质量和可移植性的初期努力中使用的流程可以被用来创建您的程序。最后,提交流程应定期重新评估并根据当前项目需求进行调整。
示例:重新评估团队的代码开发流程
您的波浪模拟应用程序团队已经为向应用程序添加OpenMP的第一个增量工作取得了进展。但现在应用程序偶尔会崩溃,并且没有任何解释。您的团队成员之一意识到这可能是由于线程竞争条件导致的。您的团队实施了一个额外的步骤,在提交流程中检查这些条件。
2.6 深入探索
本章中,我们只是浅尝了如何着手一个新项目以及可用工具的功能。要获取更多信息,请查阅以下章节中的资源并尝试一些练习。
2.6.1 额外阅读
对于今天的分布式版本控制工具,额外的专业知识对你的项目大有裨益。你团队中至少应有一名成员研究网上讨论如何使用你选择的版本控制系统的资源。如果你使用Git,下面这些Manning出版的书籍是很好的资源:
- Mike McQuaid,《Git实践》(Manning,2014年)。
- Rick Umali,《一个月学会Git》(Manning,2015年)。
在并行开发工作流程中,测试至关重要。单元测试可能是最有价值的,但也是最难实施的。Manning出版了一本关于单元测试的书,其中对单元测试进行了更为深入的讨论:
- Vladimir Khorikov,《单元测试原理、实践与模式》(Manning,2020年)。
浮点运算和精度是一个被低估的主题,尽管它对每个计算科学家都很重要。以下是关于浮点运算的一篇很好的文章和概述:
- David Goldberg,《每个计算机科学家对浮点运算应该知道的事情》(ACM Computing Surveys (CSUR),1991年,第23卷,第1期:5-48)。
总结
代码准备是并行化工作的重要部分。每个开发者都会对为项目准备代码所花费的努力感到惊讶。但这段时间是值得的,因为它是成功的并行项目的基础。 你应该提高并行代码的代码质量。代码质量必须比典型的串行代码好上一个数量级。这种对质量的需求部分原因在于在大规模调试中的困难,部分原因在于并行过程中暴露的缺陷或者仅仅是由于每行代码执行的迭代次数之多。也许这是因为遇到缺陷的概率非常小,但当一千个处理器运行代码时,出现缺陷的可能性就会增加一千倍。 分析步骤对于确定在哪里集中优化和并行化工作很重要。第三章提供了更多关于如何分析应用程序的细节。 有一个整体项目计划,以及每个开发迭代的单独计划。这两个计划都应包括一些研究,包括迷你应用程序、数据结构设计和新的并行算法,为下一步工作奠定基础。 在提交步骤中,我们需要制定流程来保持良好的代码质量。这应该是一个持续不断的努力,而不是推迟到代码投入生产或现有用户群体开始遇到大规模、长时间运行的模拟时再进行处理。
- 显示Disqus评论(需要科学上网)