目录
本章内容包括:
- 了解限制应用性能的因素
- 评估硬件组件的性能限制
- 测量应用程序的当前性能
程序员资源是稀缺的。你需要有针对性地分配这些资源,以获得最大的影响。如果你不了解应用程序的性能特性和计划运行的硬件,该如何做到这一点呢?本章旨在解决这个问题。通过测量硬件和应用程序的性能,你可以确定将开发时间花在哪里最为有效。
注意:我们鼓励你跟随本章的练习一起学习。练习可以在以下网址找到:https://github.com/EssentialsofParallelComputing/Chapter3。
3.1 了解应用程序的潜在性能限制
计算科学家仍然认为浮点运算(flops)是主要的性能限制因素。虽然在过去这可能是事实,但在现代架构中,flops 很少会成为性能的瓶颈。限制因素可以是带宽或延迟。带宽是数据通过系统中某条路径的最佳传输速率。若要带宽成为限制,代码应采用流处理方法,这通常需要内存是连续的并且所有值都被使用。当无法使用流处理方法时,延迟才是更合适的限制因素。延迟是传输第一个字节或数据字所需的时间。以下列出了一些可能的硬件性能限制:
- Flops(浮点运算)
- Ops(包括所有类型的计算机指令的操作)
- 内存带宽
- 内存延迟
- 指令队列(指令缓存)
- 网络
- 磁盘
我们可以将所有这些限制分为两大类:速度(speed)和传输量(feed)。速度指的是操作的执行速度,包括所有类型的计算机操作。但要执行这些操作,必须先获取数据,这就是传输量的作用。传输量包括通过缓存层次结构的内存带宽以及网络和磁盘带宽。对于不能实现流处理行为的应用程序,内存、网络和磁盘传输的延迟更为重要。延迟时间可能比带宽时间慢几个数量级。应用程序是否受限于延迟还是流处理带宽,最大的因素之一是编程的质量。将数据组织成可以以流模式消耗的方式可以带来显著的速度提升。
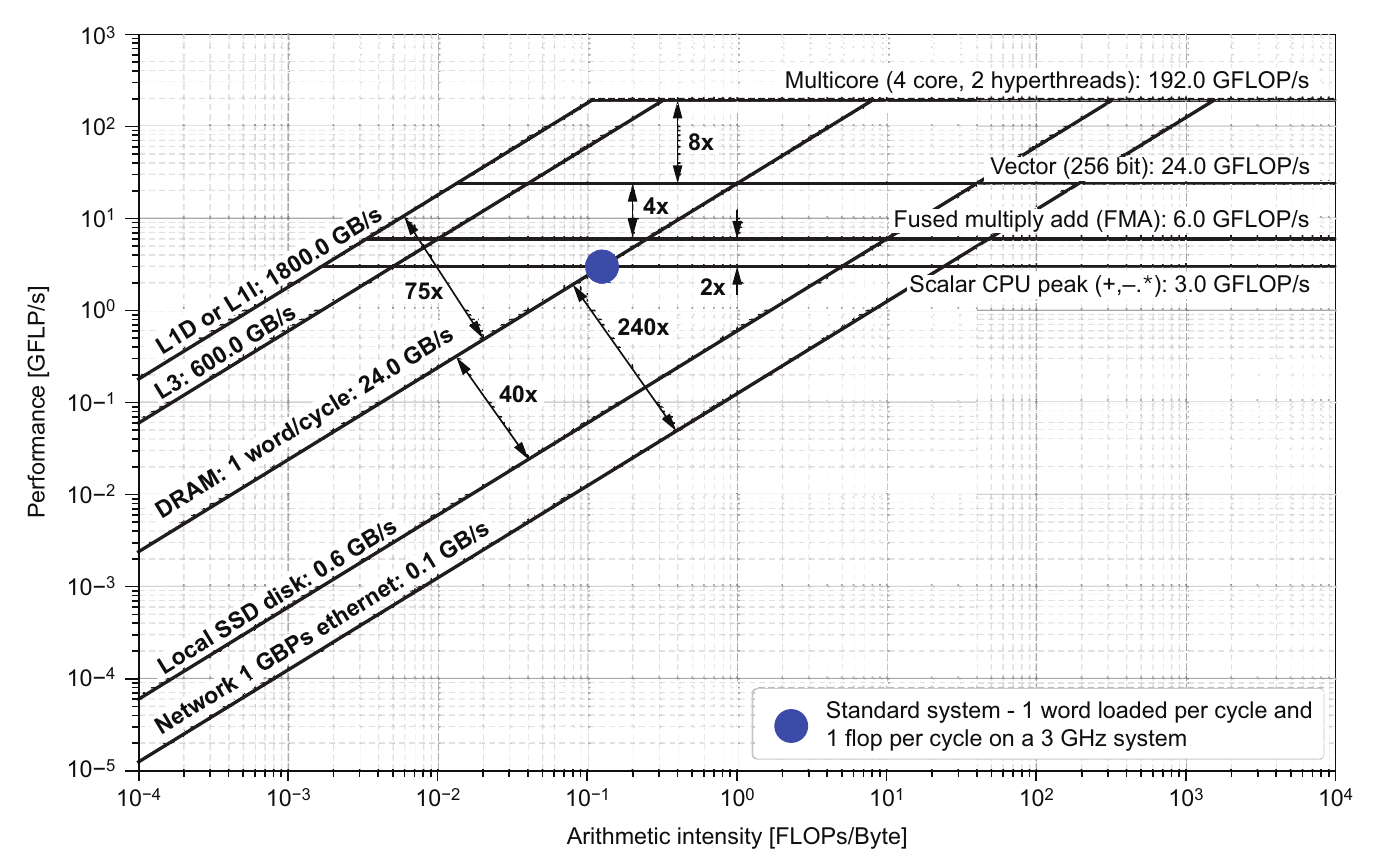 图 3.1 供给和速度在屋顶线图(roofline)上的显示。传统的标量 CPU 靠近每周期加载 1 个字和每周期 1 个浮点运算(flop),如阴影圆圈所示。浮点运算能力增加的倍数是由于融合乘加(fused multiply-add)指令、矢量化、多核和超线程。内存移动的相对速度也显示在图中。我们将在 3.2.4 节中进一步讨论屋顶线图。
图 3.1 供给和速度在屋顶线图(roofline)上的显示。传统的标量 CPU 靠近每周期加载 1 个字和每周期 1 个浮点运算(flop),如阴影圆圈所示。浮点运算能力增加的倍数是由于融合乘加(fused multiply-add)指令、矢量化、多核和超线程。内存移动的相对速度也显示在图中。我们将在 3.2.4 节中进一步讨论屋顶线图。
图 3.1 显示了不同硬件组件的相对性能。让我们以大点标记的每周期加载 1 个字和每周期 1 个浮点运算(flop)为起点。大多数标量算术操作(如加法、减法和乘法)可以在一个周期内完成。除法操作可能需要 3-5 个周期。在一些算术混合中,通过融合乘加指令可以实现每周期 2 个浮点运算。通过矢量单元和多核处理器,算术操作的数量可以进一步增加。硬件进步主要通过并行性大大提高了每周期的浮点运算能力。
观察斜率内存限制,我们看到通过更深层次的缓存层次结构增加的性能意味着只有当数据位于 L1 缓存(通常约 32 KiB)中时,内存访问才能匹配操作速度的提升。但如果我们只有这么少的数据,就不会太担心所需的时间。我们真正希望的是处理只能容纳在主内存(DRAM)甚至磁盘或网络中的大量数据。最终结果是,处理器的浮点运算能力增加的速度远快于内存带宽。这导致了许多机器平衡的数量级,大约是每加载 8 字节数据字有 50 个浮点运算能力。为了理解这对应用程序的影响,我们测量其算术强度。
- 算术强度(Arithmetic intensity):在应用程序中,衡量每次内存操作执行的浮点运算次数,内存操作可以是以字节或数据字为单位(一个数据字对于双精度是 8 字节,对于单精度是 4 字节)。
- 机器平衡(Machine balance):表示计算硬件中可执行的总浮点运算次数除以内存带宽。
大多数应用程序的算术强度接近每加载一个字执行一个浮点运算(flop),但也有一些应用程序具有更高的算术强度。一个经典的高算术强度应用程序示例是使用稠密矩阵求解器来解方程组。这类求解器在过去的应用中比现在更为常见。Linpack 基准测试使用这种操作的核心代码来代表这一类应用程序。Peise 报告称这个基准测试的算术强度为 62.5 flops/字(详见附录 A,Peise,2017,第 201 页)。这足以使大多数系统达到浮点运算能力的最大值。Linpack 基准测试在最大计算系统排名中的广泛使用,已成为当前机器设计追求高 flop 与内存加载比率的主要原因之一。
对于许多应用程序来说,即使达到内存带宽限制也可能是困难的。要理解内存带宽,需要对内存层次结构和架构有一定的了解。在内存和 CPU 之间的多个缓存有助于隐藏较慢的主内存(见 3.2.3 节中的图 3.5)。数据在内存层次结构中以称为缓存行的块进行传输。如果内存不是以连续的、可预测的方式访问,就无法实现完整的内存带宽。仅在以行顺序存储的二维数据结构中按列访问数据,会以行长度跨越内存。这可能导致每个缓存行中只使用一个值。这种数据访问模式的内存带宽粗略估计为流带宽的 1/8(每 8 个缓存值中只使用 1 个)。可以通过定义非连续带宽($B_{nc}$)来概括其他缓存使用更多的情况,该带宽以缓存使用率($U_{cache}$)和经验带宽($B_E$)表示:
\[B_{nc} = U_{cache} × B_E = \text{Average Percentage of Cache Used} \times \text{Empirical Bandwidth}\]还有其他可能的性能限制。指令缓存可能无法足够快地加载指令以保持处理器核心忙碌。整数运算也比通常认为的更频繁地成为限制因素,尤其是在高维数组中索引计算变得更加复杂。
对于需要大量网络或磁盘操作的应用程序(如大数据、分布式计算或消息传递),网络和磁盘硬件限制可能是最严重的问题。要了解这些设备性能限制的量级,可以考虑这样一个经验法则:在高性能计算机网络上传输第一个字节所需的时间内,你可以在单个处理器核心上执行超过 1,000 次浮点运算。标准机械磁盘系统对于第一个字节的传输速度慢了好几个数量级,这导致了当今文件系统高度异步的缓冲操作以及固态存储设备的引入。
示例
你的图像检测应用程序需要处理大量数据。目前这些数据通过网络传输并存储到磁盘进行处理。你的团队评估了性能限制,决定尝试消除存储到磁盘的中间步骤作为不必要的操作。团队中的一位成员建议你可以几乎免费地进行额外的浮点运算,因此团队应该考虑一个更复杂的算法。但你认为波模拟代码的限制因素是内存带宽。你将一个任务添加到项目计划中,以测量性能并确认你的猜测。
3.2 确定硬件能力:基准测试
一旦你准备好了应用程序和测试套件,就可以开始对目标生产运行的硬件进行特征分析。为此,你需要为硬件开发一个概念模型,使你能够理解其性能。性能可以通过以下几个指标来表征:
- 执行浮点运算的速率(FLOPs/s)
- 在不同内存层次之间移动数据的速率(GB/s)
- 应用程序使用的能量速率(瓦特)
这些概念模型允许你估计计算硬件各个组件的理论峰值性能。在这些模型中使用的指标以及你要优化的指标,取决于你和你的团队在应用程序中重视的内容。为了补充这个概念模型,你还可以对目标硬件进行实证测量。实证测量使用微基准测试应用程序进行。微基准测试的一个例子是用于带宽受限情况的 STREAM 基准测试。
3.2.1 用于收集系统特征的工具
在确定硬件性能时,我们使用理论和实证测量的混合方法。虽然理论值提供了性能的上限,但实证测量确认了在接近实际操作条件下简化内核中可以实现的性能。
获得硬件性能规格其实出乎意料地困难。处理器型号的爆炸性增长以及面向更广泛公众的市场和媒体评论,往往掩盖了技术细节。以下是一些好的资源:
- 对于英特尔处理器,访问:https://ark.intel.com
- 对于 AMD 处理器,访问:https://www.amd.com/en/products/specifications/processors
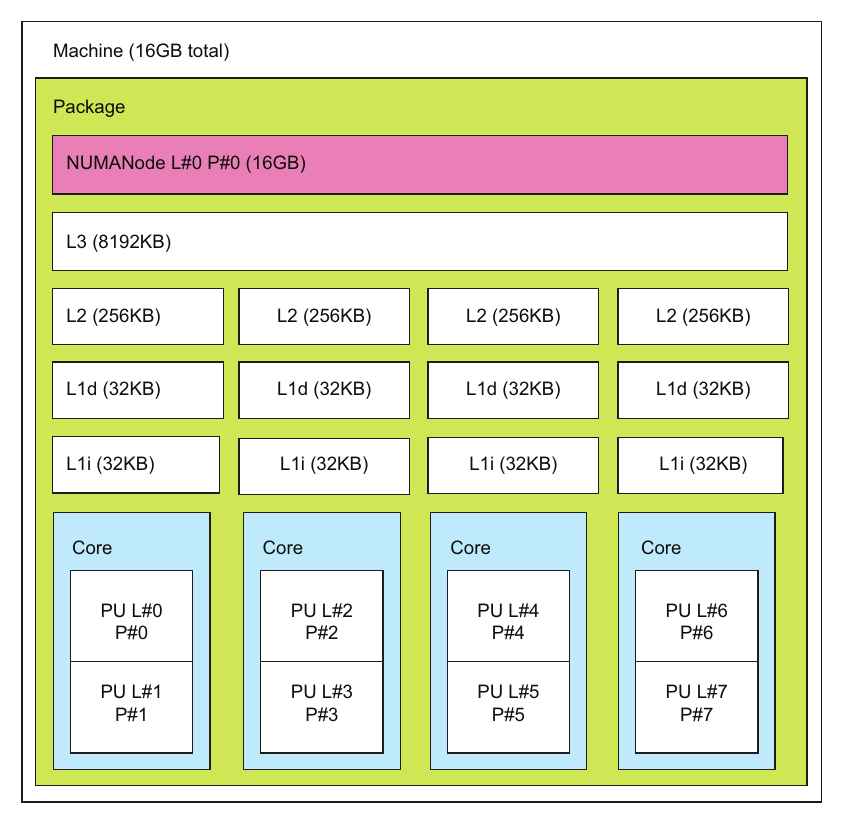 图3.2 使用 lstopo 命令显示的 Mac 笔记本电脑硬件拓扑图
图3.2 使用 lstopo 命令显示的 Mac 笔记本电脑硬件拓扑图
理解你运行的硬件的最佳工具之一是 lstopo 程序。它捆绑在几乎每个 MPI 发行版中附带的 hwloc 软件包中。此命令输出系统硬件的图形视图。图 3.2 显示了 Mac 笔记本电脑的输出。输出可以是图形或文本格式的。要获得图 3.2 中的图片,目前需要自定义安装 hwloc 和 cairo 软件包以启用 X11 界面。文本版本可以通过标准软件包管理器安装来工作。只要你能显示 X11 窗口,Linux 和 Unix 版本的 hwloc 通常也能正常工作。hwloc 软件包中正在添加一个新命令 netloc,用于显示网络连接。
为了安装cairo v1.16.0
- 去https://www.cairographics.org/releases/下载
- 配置安装:
./configure --with-x --prefix=/usr/local
make
make install
为了安装
- 去https://github.com/open-mpi/hwloc.git clone代码
- 配置安装:
./configure --prefix=/usr/local
make
make install
一些其他探测硬件详细信息的命令有 Linux 系统上的 lscpu,Windows 上的 wmic,以及 Mac 上的 sysctl 或 system_profiler。Linux 的 lscpu 命令输出从 /proc/cpuinfo 文件汇总的信息。您可以通过直接查看 /proc/cpuinfo 文件来查看每个逻辑核心的完整信息。lscpu 命令和 /proc/cpuinfo 文件中的信息有助于确定处理器数量、处理器型号、缓存大小和系统的时钟频率。标志位包含有关芯片矢量指令集的重要信息。在图 3.3 中,我们看到 AVX2 和各种形式的 SSE 矢量指令集是可用的。我们将在第 6 章进一步讨论矢量指令集。
 图 3.3 Linux 桌面上的 lscpu 输出,显示了一个具有 AVX2 指令的 4 核 i5-6500 CPU @ 3.2 GHz
图 3.3 Linux 桌面上的 lscpu 输出,显示了一个具有 AVX2 指令的 4 核 i5-6500 CPU @ 3.2 GHz
获取 PCI 总线设备的信息也很有帮助,特别是用于识别图形处理器的数量和类型。lspci 命令报告所有设备(图 3.4)。从图中的输出中,我们可以看到有一个 GPU,它是 NVIDIA GeForce GTX 960。
 图 3.4 来自 Linux 桌面的 lspci 命令输出,显示了一个 NVIDIA GeForce GTX 960 GPU。
图 3.4 来自 Linux 桌面的 lspci 命令输出,显示了一个 NVIDIA GeForce GTX 960 GPU。
3.2.2 计算理论最大flops
对于一台配备 Intel Core i7-7920HQ 处理器的 2017 年中期 MacBook Pro 笔记本电脑,我们来计算一下理论最大 flops($F_T$)。这是一款 4 核处理器,名义频率为 3.1 GHz,支持超线程技术。通过其 Turbo Boost 功能,在使用四个处理器时可达到 3.7 GHz,在使用单个处理器时可达到 4.1 GHz。理论最大 flops($F_T$)的计算公式为:
\[F_T = C_v \times f_c \times I_c = \text{Virtual Cores} \times \text{Clock Rate} \times \text{Flops/Cycle}\]核心数包括了超线程技术(hyperthreads)的影响,使得物理核心数($C_h$)看起来像更多虚拟或逻辑核心($C_v$)。在这里,我们有两个超线程技术,使得虚拟处理器数量看起来是八个。时钟频率是所有处理器工作时的 Turbo Boost 频率。对于该处理器,它是 3.7 GHz。最后,每周期 flops(或更一般地说是每周期指令数 $I_c$)包括可以由矢量单元执行的同时操作数量。
要确定可以执行的操作数量,我们将矢量宽度(VW)除以位大小($W_{bits}$)。我们还将融合乘加(FMA)指令作为每周期两个操作的另一个因素。在方程中,我们将其称为融合操作($F_{ops}$)。对于这款特定的处理器,我们得到以下计算结果。

3.2.3 内存层次结构和理论内存带宽
对于大多数大型计算问题,我们可以假设存在需要通过高速缓存层次结构从主存储器加载的大型数组(见图 3.5)。随着处理速度相对于主存储器访问时间的增加,内存层次结构随着时间的推移变得更加深层,增加了更多级别的缓存来补偿这种增加。
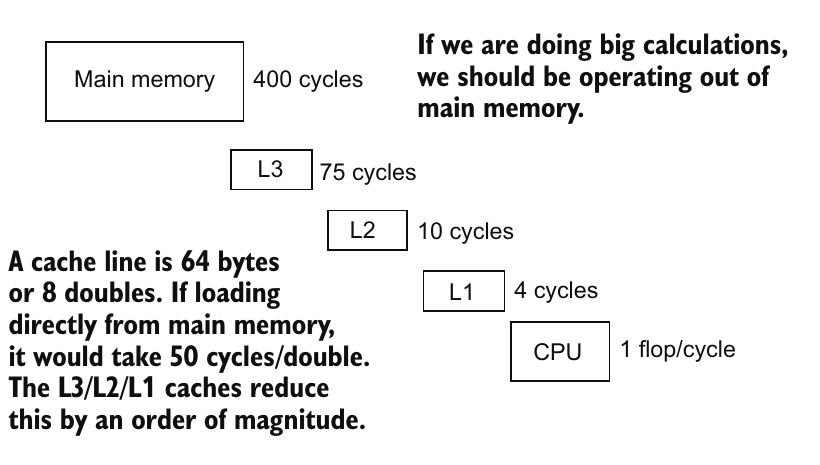 图3.5 内存层次结构和访问时间。内存被加载到缓存行中,并在缓存系统的每个级别上存储以供重复使用。
图3.5 内存层次结构和访问时间。内存被加载到缓存行中,并在缓存系统的每个级别上存储以供重复使用。
我们可以使用内存芯片规格来计算主存储器的理论内存带宽。一般的公式是:
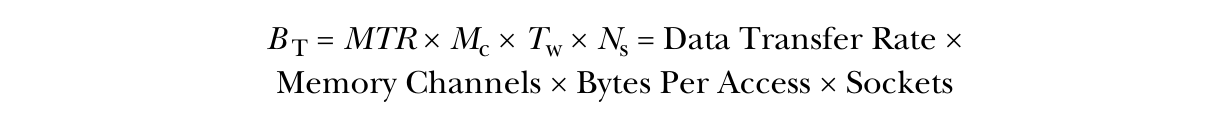
处理器安装在主板(motherboard)上的插槽(socket)中。主板是计算机的主要系统板,插槽是处理器插入的位置。大多数主板都是单插槽的,只能安装一个处理器。双插槽主板在高性能计算系统中更常见。双插槽主板可以安装两个处理器,从而提供更多的处理核心和更大的内存带宽。
数据或内存传输速率(MTR)通常以每秒百万次传输(MT/s)为单位。双倍数据率(DDR)内存在周期的顶部和底部进行两次传输,每个周期进行两次交易。这意味着内存总线时钟速率是传输速率的一半(以 MHz 计)。内存传输宽度(Tw)为 64 位,并且因为每字节有 8 位,因此传输 8 个字节。大多数桌面和笔记本架构上都有两个内存通道(Mc)。如果在两个内存通道上安装内存,将获得更好的带宽,但这意味着您不能简单地购买另一个 DRAM 模块并插入它。您将不得不用更大的模块替换所有模块。
对于 2017 年款 MacBook Pro 使用 LPDDR3-2133 内存并具有两个通道的情况,可以从内存传输速率(MTR)2133 MT/s、通道数(Mc)和主板上插槽数目计算出理论内存带宽($B_T$):
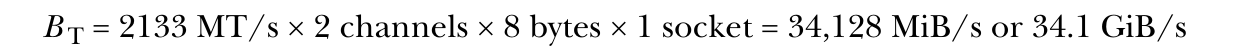
由于内存层次结构的其他影响,实际可达到的内存带宽低于理论带宽。您会发现用于估计内存层次结构影响的复杂理论模型,但这超出了我们在简化的处理器模型中要考虑的范围。为此,我们将转向对 CPU 带宽的实际测量。
3.2.4 经验性测量带宽和FLOPs
经验性带宽是衡量内存从主内存加载到处理器的最快速率的测量。如果请求单个字节的内存,从CPU寄存器中检索需要1个周期。如果它不在CPU寄存器中,它来自L1缓存。如果不在L1缓存中,则L1缓存会从L2中加载,依此类推到主内存。如果它一直到达主内存,对于单个字节的内存,可能需要大约400个时钟周期。从每个内存级别读取第一个字节的数据所需的时间称为内存延迟。一旦值在更高的缓存级别中,它就可以更快地检索,直到被逐出(evicted)该缓存级别。如果所有内存必须逐字节加载,这将非常缓慢。因此,当加载一个字节的内存时,会同时加载一整块数据(称为缓存行)。如果随后访问附近的值,这些值就已经在更高的缓存级别中了。
缓存行、缓存大小和缓存级别的数量被设置得尽可能接近主内存的理论带宽。如果我们尽可能快地加载连续数据以最大限度利用缓存,我们就可以得到CPU的最大可能数据传输速率。这种最大数据传输速率称为内存带宽。要确定内存带宽,我们可以测量读取和写入大型数组所需的时间。根据以下经验性测量结果,测得的带宽约为22 GiB/s。这个测得的带宽将用于下一章节中的简单性能模型中。
用于测量带宽的两种不同方法是:STREAM Benchmark 和由 Empirical Roofline Toolkit 测得的屋顶线模型。STREAM Benchmark 是约翰·麦卡尔平(John McCalpin)约于1995年创建的,用于支持他的论点,即内存带宽比峰值浮点性能更重要。相比之下,屋顶线模型(参见边栏中标题为“使用 Empirical Roofline Toolkit 测量带宽”的图以及本节后面的讨论)将内存带宽限制和峰值 FLOPs 率整合到一个单一图中,图中显示了每个性能限制的区域。Empirical Roofline Toolkit 是由劳伦斯伯克利国家实验室创建的,用于测量和绘制屋顶线模型。
STREAM Benchmark 测量读取和写入大型数组的时间。为此,有四种变体,取决于CPU在读取数据时对数据进行的操作:复制(copy)、缩放(scale)、加法(add)和三项运算(triad)的测量。复制不进行浮点运算,缩放和加法进行一次算术操作,三项运算进行两次。这些每个都会稍微不同地测量数据从主内存加载的最大速率,当每个数据值仅使用一次时。在这种情况下,FLOP 率受到内存加载速度的限制。

以下练习演示了如何使用 STREAM Benchmark 测量给定 CPU 的带宽。
练习:使用 STREAM Benchmark 测量带宽
英特尔的科学家 Jeff Hammond 将 McCalpin 的 STREAM Benchmark 代码放入了一个 Git 代码库,以便更方便地使用。我们在这个示例中使用他的版本。要访问该代码,请执行以下步骤:
- 克隆镜像:https://github.com/jeffhammond/STREAM.git
- 编辑 makefile 并更改编译行为
CFLAGS = -O3 -march=native -fstrict-aliasing -ftree-vectorize -fopenmp -DSTREAM_ARRAY_SIZE=80000000 -DNTIMES=20
以下是2017年款 Mac 笔记本电脑的结果:

我们可以从四种测量中选择最佳带宽作为我们的最大带宽的经验值。
如果计算可以重用缓存中的数据,就可以实现更高的 FLOP 率。如果我们假设所有正在操作的数据都在 CPU 寄存器或者可能是 L1 缓存中,那么最大的 FLOP 率由 CPU 的时钟频率和每个周期可以执行多少个 FLOP 决定。这是在前面示例中计算的理论最大 FLOP 率。
现在我们可以将这两者结合起来创建屋顶线模型的图。屋顶线模型的垂直轴是每秒 FLOP 数,水平轴是算术强度。对于高算术强度,即 FLOP 数相对于加载的数据很多的情况,理论最大 FLOP 率是限制因素。这在图上产生了最大 FLOP 率的水平线。随着算术强度的降低,内存加载时间开始主导,我们就无法达到最大的理论 FLOP。这时就会在屋顶线模型中产生倾斜的屋顶,其中可达到的 FLOP 率随着算术强度的下降而下降。图的右侧的水平线和左侧的倾斜线形成了具有屋顶形状的特征,因此被称为屋顶线模型或图。您可以为 CPU 甚至 GPU(如下面的练习所示)确定屋顶线图。
练习:使用经验 Roofline Toolkit 测量带宽
在进行此练习之前,安装 OpenMPI 或 MPICH 以获得一个可用的 MPI。安装 gnuplot v4.2 和 Python v3.0。在 Mac 上,下载 GCC 编译器以替换默认编译器。这些安装可以使用包管理器完成(Mac 上使用 brew,Ubuntu Linux 上使用 apt 或 synaptic)。
1.克隆 Roofline Toolkit:
git clone https://bitbucket.org/berkeleylab/cs-roofline-toolkit.git
2.输入:
cd cs-roofline-toolkit/Empirical_Roofline_Tool-1.1.0
cp Config/config.madonna.lbl.gov.01 Config/MacLaptop2017
3.编辑 Config/MacLaptop2017 文件。(下图显示了2017年款 Mac 笔记本电脑的文件。)
4.运行测试:
./ert Config/MacLaptop2017
5.查看 Results.MacLaptop2017/Run.001/roofline.ps 文件。
【译注:原书使用的是intel的编译器,我使用的是gcc,所以需要修改,使用gcc可以请参考https://github.com/essentialsofparallelcomputing/Chapter3/issues/4】
下图显示了 2017 年款 Mac 笔记本电脑的 Roofline。最大 flops 的经验测量值略高于我们通过分析计算得出的值。这可能是由于短时间内较高的时钟频率。尝试不同的配置参数,例如关闭向量化或运行一个进程,可以帮助确定您是否拥有正确的硬件规格。斜线表示在不同算术强度下的带宽限制。由于这些是通过经验确定的,每条斜线的标签可能不正确,并且可能存在多余的线条。
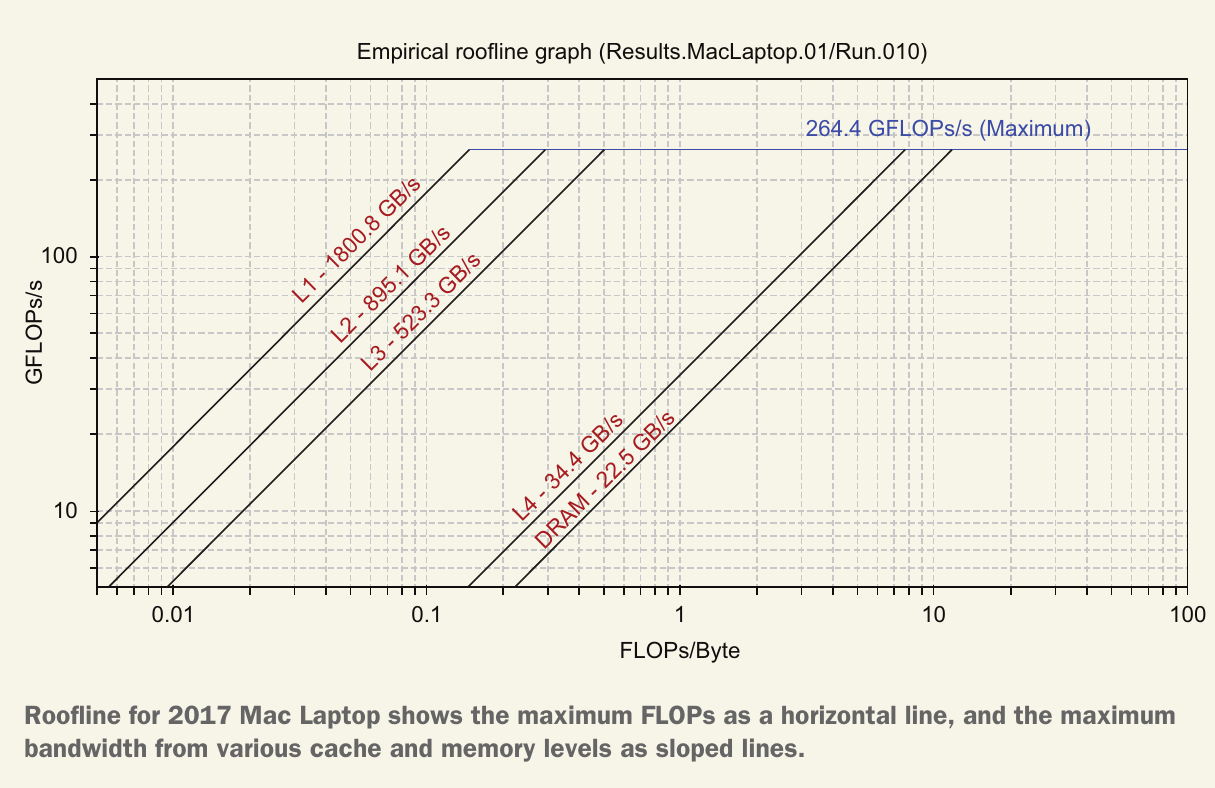
通过这两个经验测量,我们得出缓存层次结构的最大带宽约为 22 MB/s,约为 DRAM 芯片理论带宽的 65%(22 GiB/s / 34.1 GiB/s)。
3.2.5 计算浮点运算与带宽之间的机器平衡
现在我们可以确定机器平衡。机器平衡是浮点运算次数(Flops)除以内存带宽。我们可以像这样计算理论机器平衡(MB T)和经验机器平衡(MB E):

在上一节的屋顶线图中,机器平衡是DRAM带宽线与水平浮点运算上限线的交点。我们看到这个交点略高于10 Flops/Byte。乘以8会得到机器平衡高于80 Flops/word。通过这些不同的方法,我们得到了机器平衡的几种不同估算,但对于大多数应用来说,结论是我们处于带宽受限的状态。
3.3 描述你的应用程序:性能剖析
现在你已经对硬件可以达到的性能有了一些了解,你需要确定你的应用程序的性能特征。此外,你还应理解不同子程序和函数之间的依赖关系。
示例:剖析克拉卡图海啸波模拟
你决定剖析你的波模拟应用程序,看看时间花在哪里,并决定如何并行化和加速代码。一些高保真模拟可能需要几天时间运行,所以你的团队希望了解如何通过OpenMP和向量化来提高性能。你决定研究一个类似的迷你应用程序CloverLeaf,它求解可压缩流体动力学(compressible fluid dynamics)方程。这些方程比你的波模拟应用程序中的方程稍微复杂一点。CloverLeaf有多个并行语言版本。对于这个剖析研究,你的团队希望比较串行版本和使用OpenMP和向量化的并行版本。理解CloverLeaf的性能为剖析你的串行波模拟代码的第二步提供了一个良好的参考框架。
3.3.1 性能剖析工具
我们将重点介绍能够生成高层次视图并提供额外信息或上下文的剖析工具。虽然有很多剖析工具,但许多工具提供的信息过多,难以消化。如果时间允许,你可能想探索第17.3节中列出的其他剖析工具。我们还将介绍一些免费和商业的工具,以便你根据可用资源选择合适的工具。
请记住,你的目标是确定最佳的并行化应用程序的时间点,而不是了解当前性能的每一个细节。容易犯的错误是要么完全不使用这些工具,要么迷失在工具和数据中。
使用调用图进行热点和依赖分析
我们将从能够突出热点(Hot Spots)并图形化显示各子程序之间关系的工具开始。热点是执行过程中占用最多时间的内核。此外,调用图(Call Graph)是一个显示哪个例程调用其他例程的图表。我们可以合并这两组信息,得到更强大的组合,如下一个练习中所示。
有许多工具可以生成调用图,包括valgrind的cachegrind工具。Cachegrind的调用图既突出了热点又显示了子程序的依赖关系。这种类型的图对于规划开发活动以避免合并冲突非常有用。一种常见策略是将任务分配给团队,以确保每个团队成员完成的工作在单个调用栈中进行。以下练习展示了如何使用Valgrind工具套件和Callgrind生成调用图。Valgrind套件中的另一个工具KCacheGrind或QCacheGrind则显示结果。它们之间的唯一区别在于一个使用X11图形,另一个使用Qt图形。
练习:使用Cachegrind生成调用图
在这个练习中,第一步是使用Callgrind工具生成一个调用图文件,然后用KCacheGrind可视化它。
1.使用包管理器安装Valgrind和KCacheGrind或QCacheGrind
2.从https://github.com/UK-MAC/CloverLeaf下载CloverLeaf迷你应用程序
git clone --recursive https://github.com/UK-MAC/CloverLeaf.git
3.构建CloverLeaf的串行版本
cd CloverLeaf/CloverLeaf_Serial
make COMPILER=GNU IEEE=1 C_OPTIONS="-g -fno-tree-vectorize" \
OPTIONS="-g -fno-tree-vectorize"
4.使用Callgrind工具运行Valgrind
cp InputDecks/clover_bm256_short.in clover.in
编辑clover.in并将cycles从87改为10
valgrind --tool=callgrind -v ./clover_leaf
5.启动QCacheGrind
qcachegrind
6.在QCacheGrind GUI中加载特定的callgrind.out.XXX文件
7.右键单击调用图并更改图像设置
下图显示了CloverLeaf的调用图。调用图中的每个框显示了内核的名称及其在调用栈中每一级所消耗的时间百分比。调用栈是调用代码当前位置的例程链。当每个例程调用一个子例程时,它将其地址推入栈中。在例程结束时,程序在返回之前调用例程时简单地从栈中弹出地址。树的每个其他“叶子”都有它们自己的调用栈。调用栈描述了“叶子”例程中变量通过调用链传递的数据源层次结构。时间可以是独占的,即每个例程排除它调用的例程的时间,也可以是包含的,即包括所有下一级例程的时间。侧边栏标题为“使用经验屋顶线工具包测量带宽”的图中显示的时间是包含的,每一级包括其下的各级,总和在主例程处为100%。
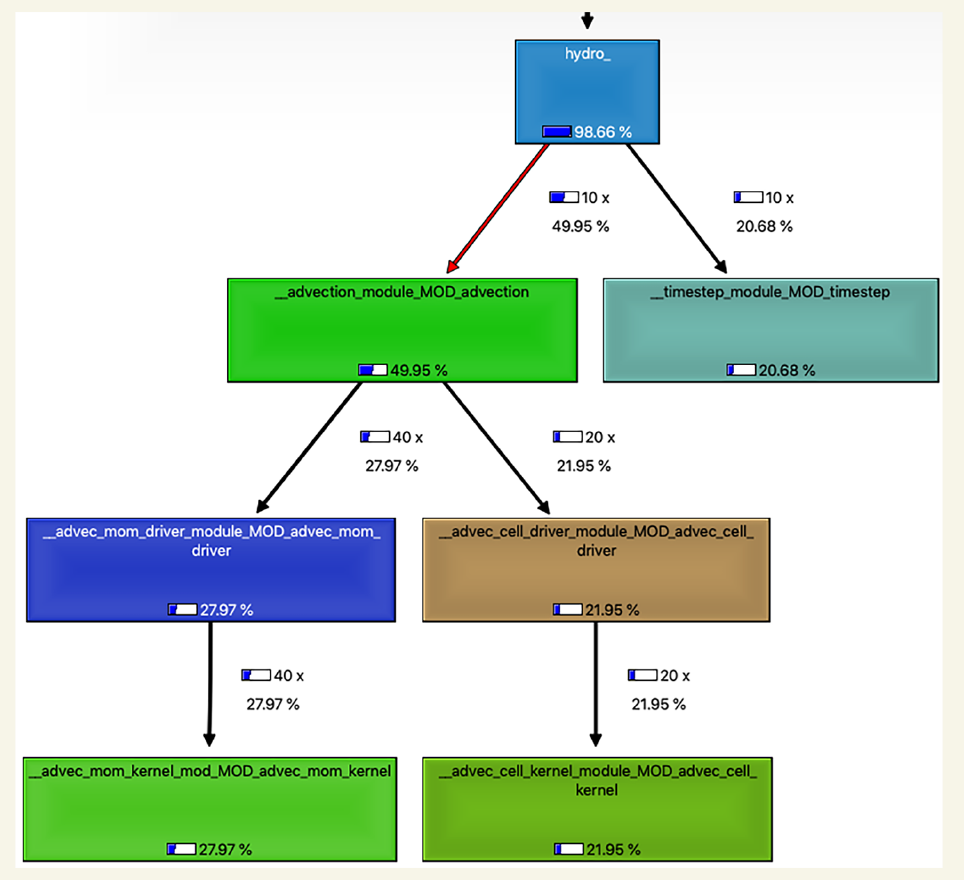
在图中,显示了最耗时的例程的调用层次结构,以及调用次数和运行时间的百分比。我们可以从中看到,大部分运行时间都在将材料和能量从一个单元移动到另一个单元的对流例程中。我们需要将工作重点放在这里。调用图还帮助我们追踪源代码中的路径。
另一个有用的剖析工具是Intel® Advisor。这是一款商业工具,具有帮助最大化应用程序性能的功能。Intel Advisor是Parallel Studio套件的一部分,该套件还包含Intel编译器、Intel Inspector和VTune。在https://software.intel.com/en-us/qualify-for-free-software/student 上有学生、教育者、开源开发者和试用版许可证的选项。这些Intel工具也已在OneAPI套件中免费发布,网址为https://software.intel.com/en-us/oneapi。最近,Intel Advisor添加了一个结合屋顶线模型的剖析功能。让我们来看看它的实际操作。【译注:OneAPI是免费的】
练习:Intel® Advisor
这个练习展示了如何为CloverLeaf迷你应用程序生成roofline图。CloverLeaf是一个规则网格的可压缩流体动力学(CFD)水动力代码。
1.构建CloverLeaf的OpenMP版本:
git clone --recursive https://github.com/UK-MAC/CloverLeaf.git
cd CloverLeaf/CloverLeaf_OpenMP
make COMPILER=INTEL IEEE=1 C_OPTIONS="-g -xHost" OPTIONS="-g -xHost"
或
make COMPILER=GNU IEEE=1 C_OPTIONS="-g -march=native" OPTIONS="-g -march=native"
2.在Intel Advisor工具中运行应用程序:
cp InputDecks/clover_bm256_short.in clover.in
advixe-gui
3.设置可执行文件为CloverLeaf_OpenMP目录中的clover_leaf。工作目录可以设置为应用程序目录或CloverLeaf_OpenMP。 a. 对于GUI操作,选择Start Survey Analysis下拉菜单并选择Start Roofline Analysis b. 在命令行中输入以下命令:
advixe-cl --collect roofline --project-dir ./advixe_proj -- ./clover_leaf
4.启动GUI并点击文件夹图标以加载运行数据。
5.要查看结果,点击Survey and Roofline,然后点击性能结果顶部面板最左侧的区域(垂直文本为roofline)。
下图显示了Intel Advisor分析器的摘要统计数据。它报告了大约0.11 FLOPS/字节或0.88 FLOPS/字的算术强度。浮点计算率为36 GFLOPS/s。
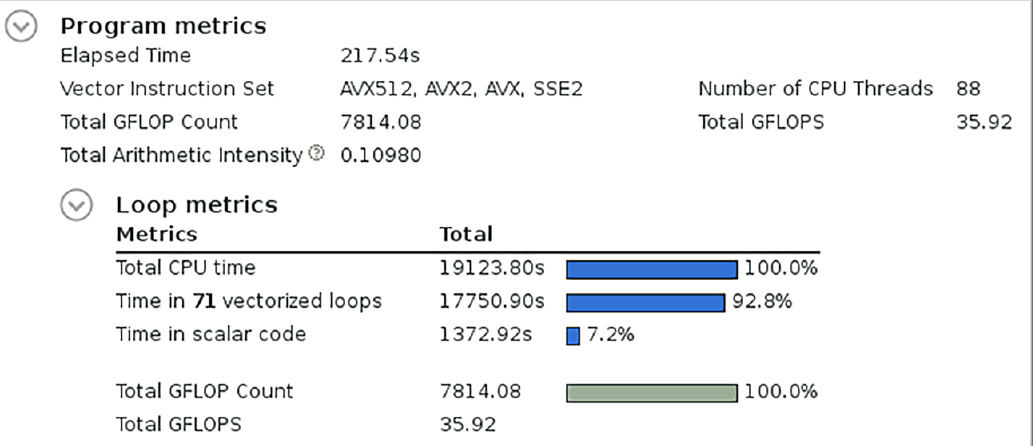
下一个图显示了CloverLeaf迷你应用程序的Intel Advisor roofline图。各种内核的性能相对于Skylake处理器的roofline性能显示为点。点的大小和颜色表示各内核的整体时间百分比。即使一眼就可以看出,该算法是带宽受限的,远离计算受限区域。由于这个迷你应用程序使用双精度,算术强度为0.01乘以8,得到的算术强度远低于1 flop/字。
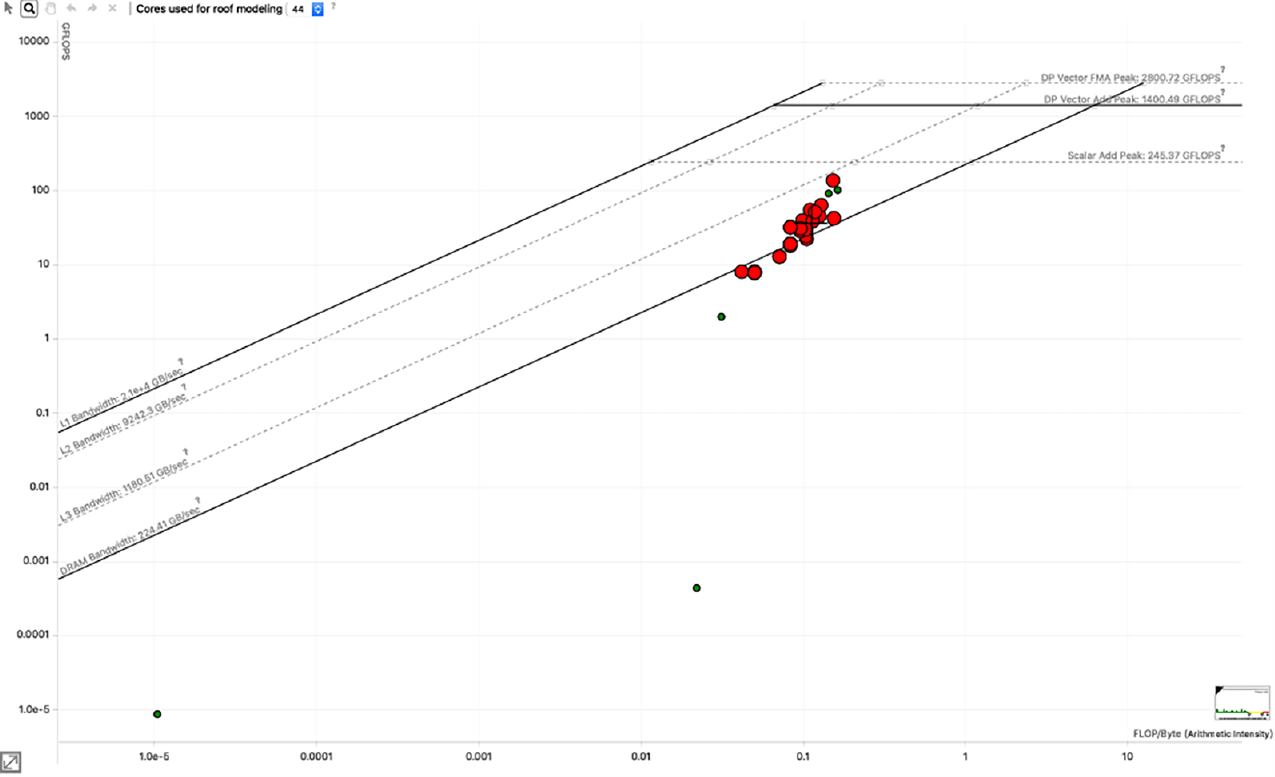
机器平衡是双精度FMA峰值和DRAM带宽的交点。
在这个图中,机器平衡高于10 flops/字节,或乘以8,高于80 flops/字,其中字大小为双精度。代码中最重要的性能部分通过与每个点关联的名称标识出来。可以通过这些点距离带宽限制的远近来确定最有改进潜力的例程。我们还可以看到,提高内核中的算术强度将有所帮助。
我们还可以使用免费的likwid工具套件来获取算术强度。Likwid是“Like I Knew What I’m Doing”(就像我知道我在做什么)的缩写,由埃尔兰根-纽伦堡大学的Treibig、Hager和Wellein编写。它是一个仅在Linux上运行的命令行工具,利用机器特定寄存器(MSR)。必须使用modprobe msr启用MSR模块。该工具使用硬件计数器来测量和报告系统的各种信息,包括运行时间、时钟频率、能量和功率使用情况,以及内存读写统计信息。
练习:使用 likwid perfctr
通过包管理器安装 likwid 或使用以下命令安装:
git clone https://github.com/RRZE-HPC/likwid.git
cd likwid
edit config.mk
make
make install
启用 MSR:
sudo modprobe msr
运行以下命令:
likwid-perfctr -C 0-87 -g MEM_DP ./clover_leaf
(在输出中,还有最小值和最大值列。为节省空间,这些列已被移除。)
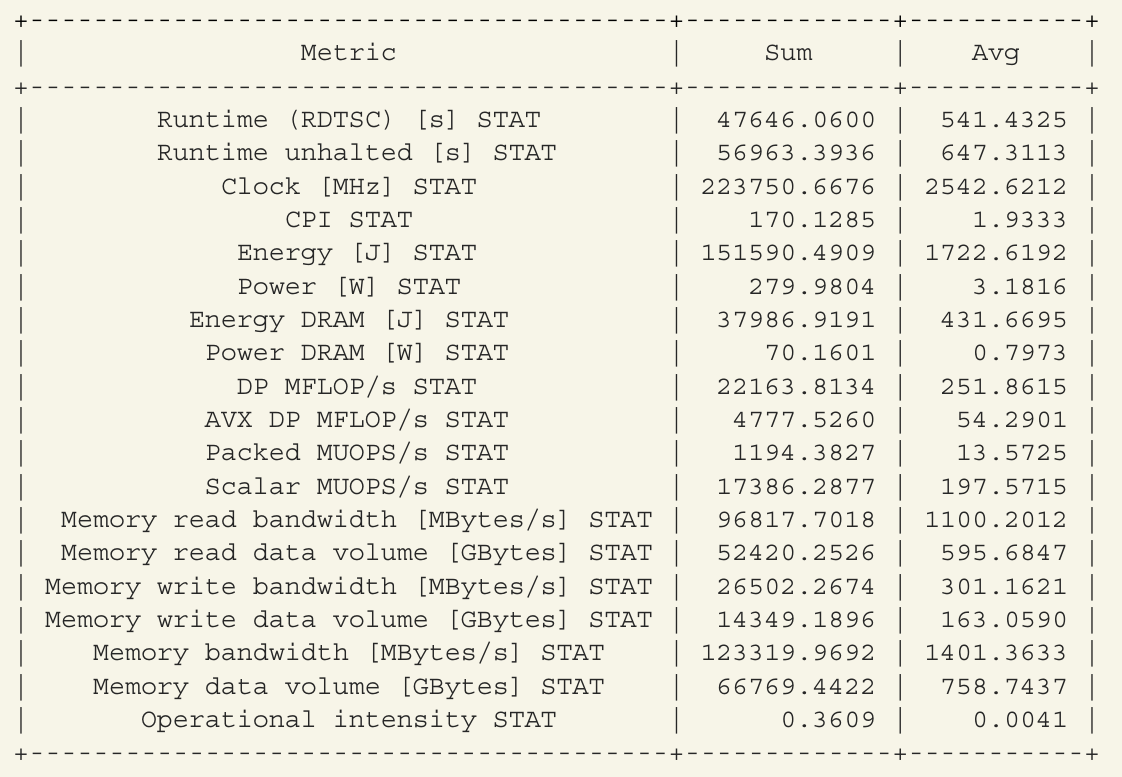
根据上面的结果,可以计算
Computation Rate = (22163.8134+4*4777.5260) = 41274 MFLOPs/sec = 41.3 GFLOPs/sec
Arithmetic Intensity = 41274/123319.9692 = .33 FLOPs/byte
Operational Intensity = .3609 FLOPs/byte
Energy = 151590.4909
Energy DRAM = 37986.9191
以上是并行计算的结果,下面是一次顺序执行的结果:
Computation Rate = 2.97 GFLOPS/sec
Operational intensity = 0.2574 FLOPS/byte
Energy = 212747.7787 Joules
Energy DRAM = 49518.7395 Joules
我们还可以使用 likwid 的输出来计算 CloverLeaf 由于并行运行所带来的能量减少。
练习:计算并行运行相对于串行运行的能量节省
能量减少计算公式如下:
能量减少 = (212747.7787 - 151590.4909) / 212747.7787 = 28.7%
DRAM 能量减少 = (49518.7395 - 37986.9191) / 49518.7395 = 23.2%
使用 LIKWID-PERFCTR 标记对代码的特定部分进行性能分析
可以在 likwid 中使用标记来获取单个或多个代码段的性能。这一功能将在下一章的第 4.2 节中使用。
- 使用 -DLIKWID_PERFMON -I
/include 编译代码 - 使用 -L
/lib 和 -llikwid 进行链接 - 将列表 3.1 中的代码行插入到您的代码中
LIKWID_MARKER_INIT;
LIKWID_MARKER_THREADINIT;
LIKWID_MARKER_REGISTER("Compute")
LIKWID_MARKER_START("Compute");
// ... Your code to measure
LIKWID_MARKER_STOP("Compute");
LIKWID_MARKER_CLOSE;
生成您自己的 Roofline 图
Charlene Yang(NERSC)创建并发布了一个用于生成 Roofline 图的 Python 脚本。这对于使用您的探索数据生成高质量的自定义图形非常方便。对于这些示例,您可能需要安装 anaconda3 软件包。它包含 matplotlib 库和 Jupyter notebook 支持。使用以下代码,可以使用 Python 和 matplotlib 自定义 Roofline 图:
git clone https://github.com/cyanguwa/nersc-roofline.git
cd nersc-roofline/Plotting
modify data.txt
python plot_roofline.py data.txt
我们将在几个练习中使用该绘图脚本的修改版本。在第一个练习中,我们将 Roofline 绘图脚本的一部分嵌入到 Jupyter notebook 中。Jupyter notebooks(https://jupyter.org/install.html)允许您将 Markdown 文档与 Python 代码交替使用,提供互动体验。我们使用它来动态计算理论硬件性能,然后创建一个 Roofline 图,以显示您的算术强度和性能。
绘制这个算术强度和计算速率的结果如图 3.6 所示。图中绘制了串行和并行运行的 Roofline 图。并行运行速度大约快 15 倍,并且具有稍高的操作(算术)强度。
【译注:这个只是用python来画图,理论硬件性能是通过手动设置一些参数来估计,实际性能是通过前面的工具跑出来的。感兴趣的读者请参考https://github.com/essentialsofparallelcomputing/Chapter3/blob/master/JupyterNotebook/HardwarePlatformCharaterization.ipynb,只需要安装notebook和matplotlab就可以运行。 】
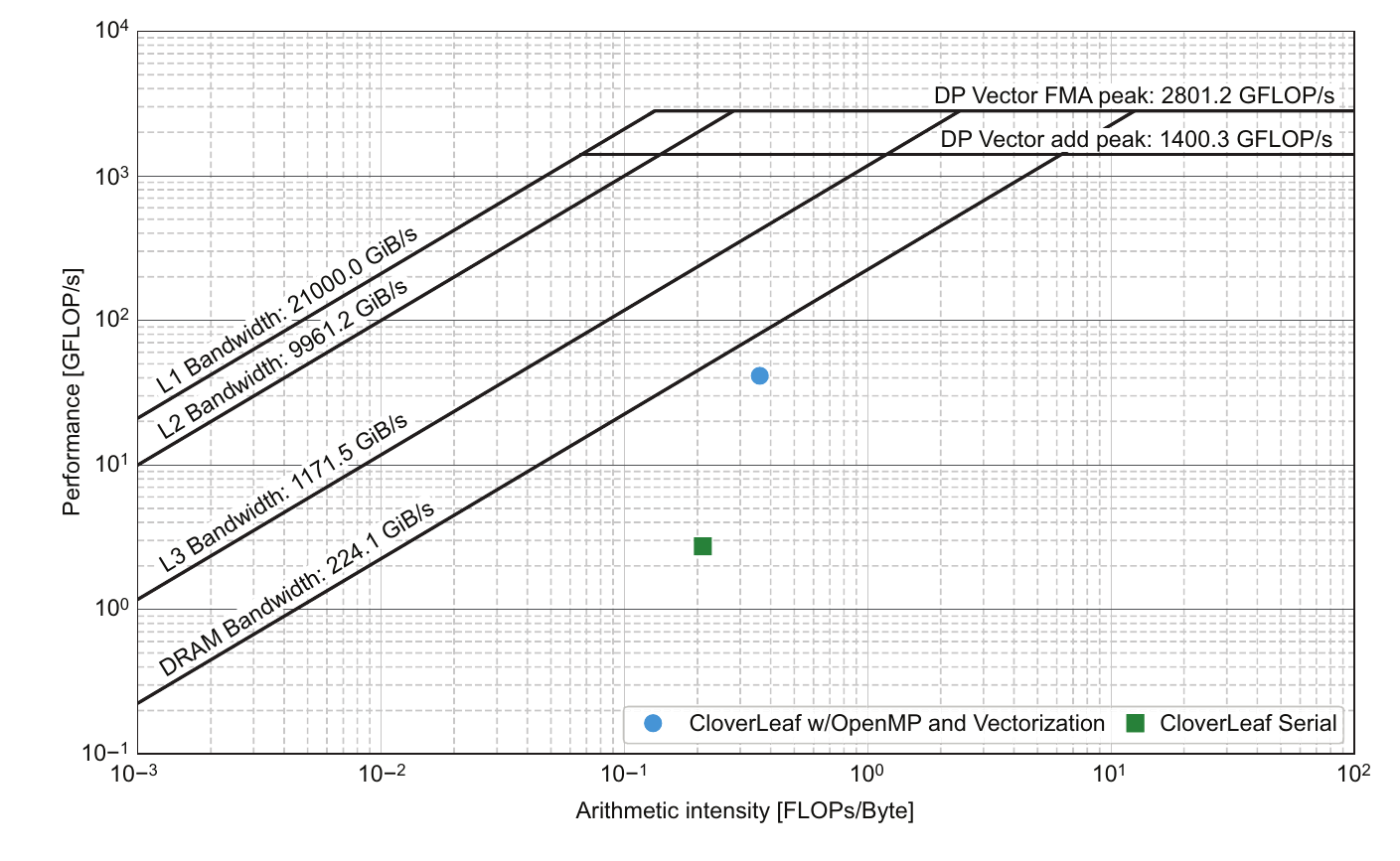 图 3.6 Skylake Gold 处理器上 Clover Leaf 的整体性能
图 3.6 Skylake Gold 处理器上 Clover Leaf 的整体性能
还有一些其他工具可以测量算术强度。Intel® 软件开发仿真器 (SDE) 软件包(https://software.intel.com/en-us/articles/intel-software-development-emulator)生成了大量可用于计算算术强度的信息。Intel® VtuneTM 性能工具(Parallel Studio 软件包的一部分)也可以用来收集性能信息。
当我们比较 Intel Advisor 和 likwid 的结果时,算术强度存在差异。计算操作的方式有很多种,例如在加载整个缓存行时计算操作,或只计算所使用的数据。同样,计数器可以计算整个向量宽度,而不仅仅是使用的部分。一些工具只计算浮点操作,而其他工具则计算不同类型的操作(例如整数操作)。
3.3.2 处理器时钟频率和能耗的经验测量
现代处理器具备许多硬件性能计数器和控制功能。这些功能包括处理器频率、温度、功率等。新兴的软件应用和库使得获取这些信息更加容易。这些应用不仅减轻了编程难度,还帮助绕过了需要提升权限的要求,使得数据对普通用户更为可及。这是一个受欢迎的发展,因为程序员无法优化他们看不到的数据。
由于积极的处理器频率管理,处理器很少处于其标称频率设置。当处理器空闲时,时钟频率会降低,而在繁忙时会增加到涡轮增压模式。两个简单的交互命令可以查看处理器频率的行为:
watch -n 1 "lscpu | grep MHz"
watch -n 1 "grep MHz /proc/cpuinfo"
likwid 工具套件也有一个命令行工具 likwid-powermeter,可以查看处理器频率和功率统计数据。likwid-perfctr 工具在总结报告中也会报告一些这些统计数据。另一个方便的小应用是 Intel® Power Gadget,提供 Mac 和 Windows 版本,以及一个功能有限的 Linux 版本。它可以绘制频率、功率、温度和利用率的图表。
CLAMR 迷你应用(http://www.github.com/LANL/CLAMR.git)正在开发一个小型库 PowerStats,该库可以在应用程序内部跟踪能量和频率,并在运行结束时报告。目前,PowerStats 在 Mac 上使用 Intel Power Gadget 库接口工作。类似的功能正在为 Linux 系统开发。应用程序代码只需添加几个调用,如以下列表所示。
powerstats_init();
powerstats_sample();
powerstats_finalize();
运行后,打印出以下表格:
Processor Energy(mWh) = 94.47181
IA Energy(mWh) = 70.07562
DRAM Energy(mWh) = 3.09289
Processor Power (W) = 71.07833
IA Power (W) = 54.73608
DRAM Power (W) = 2.32194
Average Frequency = 3721.19422
Average Temperature (C) = 94.78369
Time Expended (secs) = 12.13246
3.3.3 运行时的内存跟踪
内存使用也是程序员难以直观了解的性能方面之一。你可以使用与之前列出的处理器频率相同的交互命令类型,但用于内存统计。首先,通过 top 或 ps 命令获取你的进程 ID。然后使用以下命令之一来跟踪内存使用情况:
watch -n 1 "grep VmRSS /proc/<pid>/status"
watch -n 1 "ps <pid>"
top -s 1 -p <pid>
要将其集成到你的程序中,或许是为了查看不同阶段内存的变化情况,CLAMR 中的 MemSTATS 库提供了四种不同的内存跟踪调用:
long long memstats_memused()
long long memstats_mempeak()
long long memstats_memfree()
long long memstats_memtotal()
将这些调用插入到你的程序中,以在调用点返回当前的内存统计信息。MemSTATS 是一个单一的 C 源文件和头文件,因此应该很容易集成到你的程序中。要获取源代码,请访问 http://github.com/LANL/CLAMR/ 并查找 MemSTATS 目录。它也可以在 https://github.com/EssentialsofParallelComputing/Chapter3 的代码示例中找到。
3.4 进一步探索
本章仅仅触及了这些工具的表面。欲了解更多信息,请探索附加阅读部分的资源,并尝试一些练习。
3.4.1 附加阅读
你可以在以下链接找到更多关于 STREAM 基准测试的信息和数据:
- John McCalpin. 1995. “STREAM: Sustainable Memory Bandwidth in High Performance Computers.” https://www.cs.virginia.edu/stream/.
屋顶线模型起源于劳伦斯伯克利国家实验室。他们的网站上有很多关于其使用的资源:
- “Roofline Performance Model.” https://crd.lbl.gov/departments/computer-science/PAR/research/roofline/.
3.4.2 练习
- 计算你选择的系统的理论性能。包括峰值 flops、内存带宽和机器平衡在内。
- 从 https://bitbucket.org/berkeleylab/cs-roofline-toolkit.git 下载屋顶线工具包,并测量所选系统的实际性能。
- 使用屋顶线工具包,从一个处理器开始,逐步添加优化和并行化,记录每个步骤的性能提升。
- 从 https://www.cs.virginia.edu/stream/ 下载 STREAM 基准测试,并测量所选系统的内存带宽。
- 选择第 17.1 节中列出的一个公开可用的基准测试或小型应用程序,并使用 KCacheGrind 生成调用图。
- 选择第 17.1 节中列出的一个公开可用的基准测试或小型应用程序,并使用 Intel Advisor 或 likwid 工具测量其算术强度。
- 使用本章介绍的性能工具,确定一个小型应用程序的平均处理器频率和能耗。
- 使用第 3.3.3 节中的一些工具,确定一个应用程序的内存使用情况。
本章涵盖了并行项目计划的许多必要细节。估算性能能力并使用工具提取硬件特性和应用性能信息,为计划提供了坚实具体的数据点。正确使用这些工具和技能有助于为成功的并行项目打下基础。
3.5 总结
应用程序可能存在多种性能限制。这些限制从浮点运算(flops)的峰值数量到内存带宽和硬盘读写不等。
目前计算系统上的应用程序通常更受内存带宽限制,而不是 flops。尽管这一点在二十年前就已被识别,但现在比当时预测的更为显著。然而,计算科学家在适应这一新现实方面仍然较慢。
你可以使用分析工具来测量应用程序性能,并确定优化和并行化工作的重点。本章展示了使用 Intel® Advisor、Valgrind、Callgrind 和 likwid 的示例,但还有许多其他工具,包括 Intel® VTune、Open|Speedshop (O|SS)、HPC Toolkit 或 Allinea/ARM MAP。(更完整的工具列表见第 17.3 节。)然而,最有价值的工具是那些提供可操作信息的工具,而不仅仅是数量。
你可以使用硬件性能工具和应用程序来确定能耗、处理器频率、内存使用情况等。通过使这些性能属性更加可见,可以更容易地进行优化以考虑这些因素。
- 显示Disqus评论(需要科学上网)