本文介绍基于神经网络的依存句法分析算法,包括基本原理和代码示例。更多文章请点击深度学习理论与实战:提高篇。
目录
- A Fast and Accurate Dependency Parser using Neural Networks
- 代码实现
- Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations
下面我们讨论怎么用深度学习来改进依存句法分析,根据前面的介绍,基于转换的贪心的算法核心是一个分类器。我们前面介绍的代码使用了简单的感知器作为分类器,使用了很多人工提取的特征。我们也介绍过,传统机器学习的问题是需要手工提取特征,另外这些特征都是稀疏的indicator特征。我们可以使用深度学习来改进,通过Embedding能够解决数据稀疏的问题。
A Fast and Accurate Dependency Parser using Neural Networks
我们首先来学习Manning等人的这篇文章,它的算法非常简单也容易实现。它还是基于转换的贪心算法,使用深度神经网络来做分类。在Stanford数据集上UAS能达到92%,这在现在当然不算特别好的结果(最近的模型能到95%以上),但是在当时主流的方法还是使用传统的机器学习,需要大量的人工特征,而且需要使用更加复杂的比如基于图的算法而不是基于转换的贪心算法。因此它当时的效果是非常不错的,而且模型简单,预测(parse)的速度非常快。下面我们详细的来阅读这篇论文,并用代码实现它。
背景简介
我们这里简单的回顾一下基于转换的算法,前面的依存句法分析已经详细的介绍过了,我们这里只是把一些知识再回顾一下,让读者熟悉这篇论文的记号。
这里使用的是arc-standard算法,它的一个配置(configuration)定义为c=(s, b, A)。其中s是一个栈,b是一个buffer(队列),A是已经parse得到的边(依存关系,包括label)。初始配置的s=[ROOT], $b=[w_1,…,w_n]$,$A=\Phi $。一个配置是终止(terminal)配置的条件是:buffer为空并且s里只有ROOT。$s_i$从栈顶往下的第i个元素,因此$s_1$是栈顶的元素。$b_i$是buffer的第i个元素。arc-standard算法定义了3种操作:
- LEFT-ARC(l) 往A里添加边$s_1 \rightarrow s_2$,边的label是l,然后把$s_2$从栈中删除。这个操作要求$\vert s \vert \ge 2$
- RIGHT-ARC(l) 往A里添加边$s_2 \rightarrow s_1$,边的label是l,然后把$s_1$从栈中删除。这个操作要求$\vert s \vert \ge 2$
- SHIFT 把$b_1$移到s的顶部。这个操作要求$\vert b \vert \ge 1$
对于带label的版本,总共有$\vert \mathcal{T} \vert =2N_l+1$个不同的操作,这里$N_l$是不同label的数量。下图是一个例子,左上是正确的依存关系;右上是parse过程中的一个配置。下边是一个正确的操作序列和配置的变化。
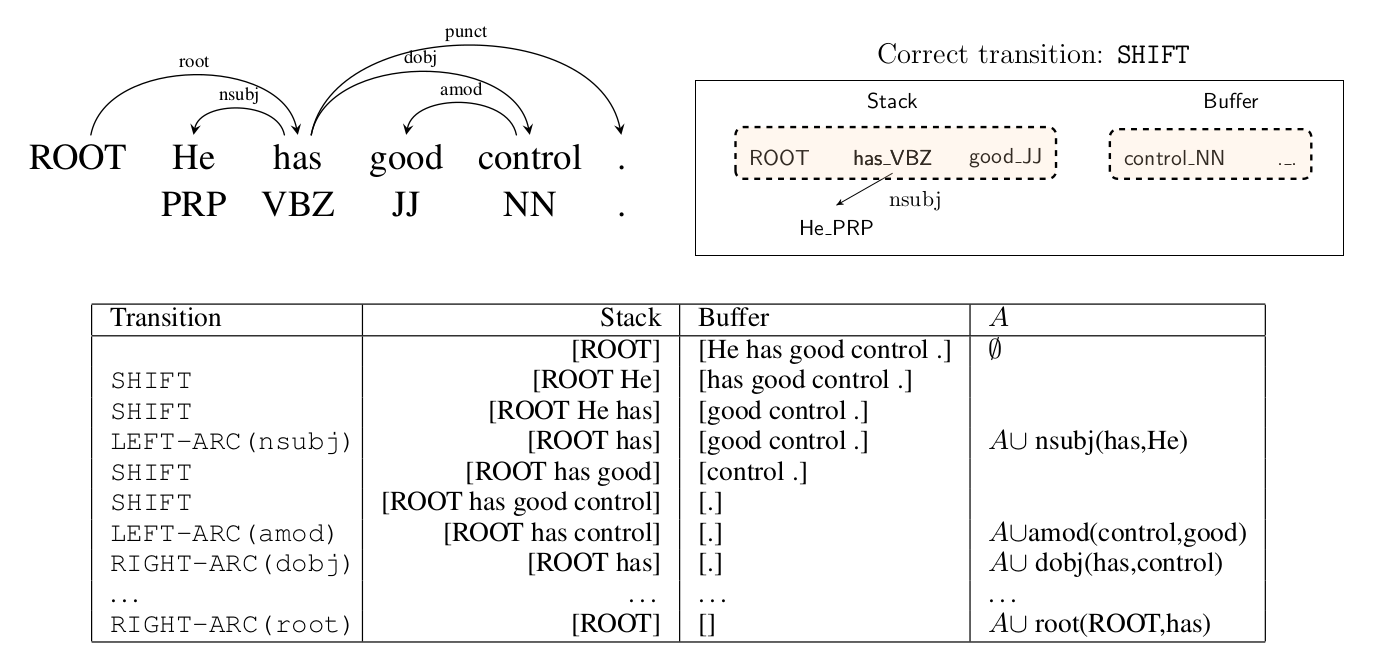 图:基于转换的parsing示例。左上是正确的依存分析,右上是一个配置;下是正确的操作序列
图:基于转换的parsing示例。左上是正确的依存分析,右上是一个配置;下是正确的操作序列
对于贪心的parser来说,输入是一个配置,输出是$\vert \mathcal{T} \vert $中的一个。这是一个分类问题,输入的配置里有很多有用的信息,传统的机器学习会手工提取很多特征,就像我们在前面的例子里介绍的那样,它们的缺点我们也介绍过来,那么接下来就是怎么用神经网络来改进这个分类器了。
基于神经网络的parser
基于神经网络的parser如下图所示。对于一个配置,我们首先抽取一些相关的词、词性和已经parse的关系的label。词的集合是$S^w$,词性的集合是$S^t$,label的集合是$S^l$。并且假设这些集合的大小分别是$n_w,n_t,n_l$。假设$S^w=[w_1,…,w_{n_w}]$,我们对这$n_w$个词都进行Embedding,这样得到$x^w=[e_{w_1}^w, e_{w_2}^w, …, e_{w_{n_w}}^w]$,类似的,我们可以得到$x^t$和$x^l$,然后我们把$x_w,w^t,w^l$接入全连接网络,并且使用3次方的激活函数得到:
\[h=(W_1^wx^w+W_1^tx^t+W_1^lx^l+b_1)^3\]然后再加一个全连接层,激活是softmax,得到分类的概率:
\[p = softmax(W_2 h)\]通常我们会对词进行Embedding,但是作者认为对词性和label进行Embedding也是有必要的,比如词性,NN和NNS会有相似的性质。$S^w$有18个词,分别是栈顶和buffer头部的3个词:$s_1,s_2,s_3,b_1,b_2,b_3$;$s_1$和$s_2$最左的2个孩子,最右的2个孩子;$s_1$和$s_2$最左孩子的最左孩子(这是孩子的孩子!),最右孩子的最右孩子。6+8+4=18。
为了方便,我们用记号$lc_1 (s_1)$表示栈顶($s_1$)元素的最左的孩子,而$lc_2 (s_1)$示栈顶($s_1$)元素的第二左的孩子。类似的用$rc_1,rc_2$表示最右和第二右的孩子。因此最左孩子的最左孩子可以这样表示$lc_1(lc_1(s_1))$。
$S^t$有18个词性,是和$S^w$对应的。而$S^l$有12=8+4个,因为$s_1,s_2,s_3,b_1,b_2,b_3$并没有label。我们抽取的label是来自与边(孩子),比如$s_1$和它最左的2个孩子会对应两条边。因此label总共可以抽取8+4=12个。
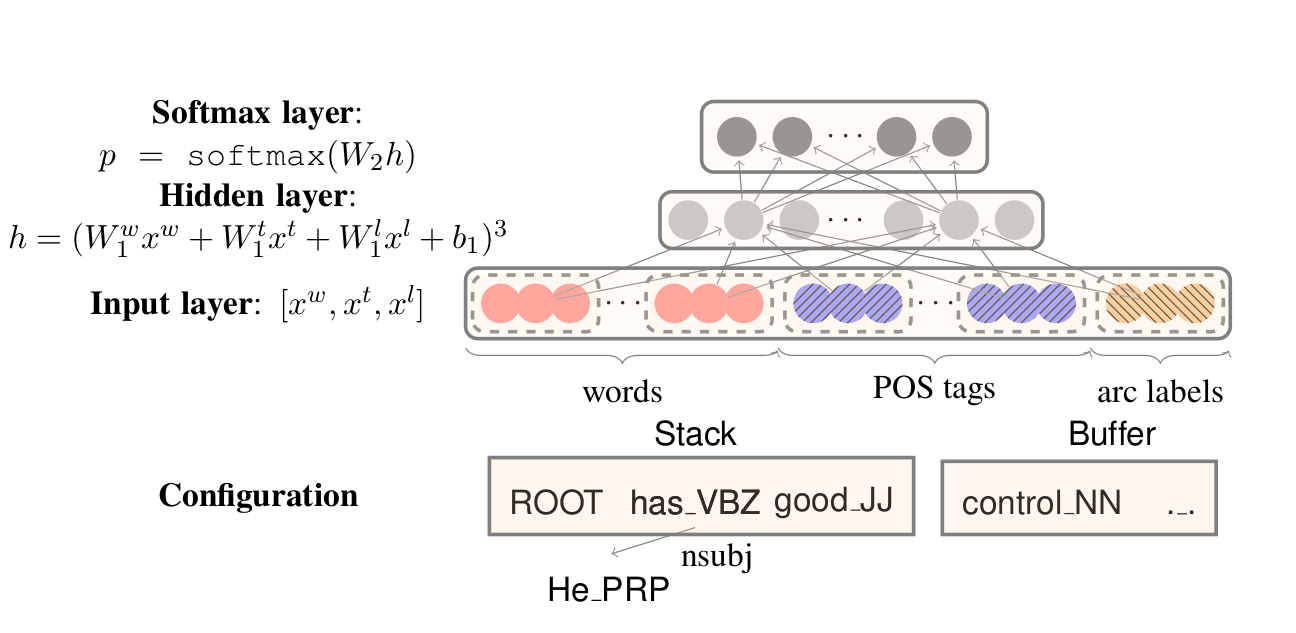 图:网络结构
图:网络结构
代码实现
接下来我们介绍”A Fast and Accurate Dependency Parser using Neural Networks”的代码实现。完整代码在这里。
运行
运行代码需要python2.7+tensorflow(>=1.2)。训练的代码是python parser_model.py。接下来我们阅读一下其中关键的代码,从而更加深入的理解论文。
数据表示
输入的数据格式为conll格式,比如下面的例子:
1 Some _ DET DT _ 2 advmod _ _
2 4,300 _ NUM CD _ 3 nummod _ _
3 institutions _ NOUN NNS _ 5 nsubj _ _
4 are _ VERB VBP _ 5 cop _ _
5 part _ NOUN NN _ 0 root _ _
6 of _ ADP IN _ 9 case _ _
7 the _ DET DT _ 9 det _ _
8 pension _ NOUN NN _ 9 compound _ _
9 fund _ NOUN NN _ 5 nmod _ _
10 . _ PUNCT . _ 5 punct _ _
代码用类Sentence表示一个句子,Token表示一个词,一个Sentence包含多个Token。我们先看Token。
class Token(object):
def __init__(self, token_id, word, pos, dep, head_id):
self.token_id = token_id # token index
self.word = word.lower() if SettingsConfig.is_lower else word
self.pos = pos_prefix + pos
self.dep = dep_prefix + dep
self.head_id = head_id # head token index
self.predicted_head_id = None
self.left_children = list()
self.right_children = list()
-
token_id是这个Token在句子中的位置,比如Some是0(输入文件下标是1开始的,这里会减一从而便于程序处理)、4,300是1。
-
word就是这个词,会把它变成小写。
-
pos是词性,比如NN,存储的时候会假设前缀变成”<p>:NN”。
-
head_id是这个词的head词,下标已经减一了,比如Some的head_id是1(4,300),表示4,300->some这条边。
-
dep是依赖关系的label,比如advmod,存储是也会加上前缀变成”
:advmod",表示4,300->some边上的label是advmod。
类Sentence的构造函数为:
class Sentence(object):
def __init__(self, tokens):
self.Root = Token(-1, ROOT, ROOT, ROOT, -1)
self.tokens = tokens
self.buff = [token for token in self.tokens]
self.stack = [self.Root]
self.dependencies = []
self.predicted_dependencies = []
一个Sentence的第一个Token是特殊的ROOT。buff初始化为句子中的所有词,stack初始化为Root。dependencies数组存储每个节点真实依赖的Token,而predicted_dependencies存储模型预测的依赖。注意,这里的实现和前面不同,这里存储的是Token本身而不是下标(指针)。因此我们可以看出,Sentence不只是包含Tokens,而且还包含了s,b和A,因此Sentence可以理解为句子当前的配置。
FeatureExtractor
这个类的作用就是根据当前配置找到论文里定义的集合$S^w,S^t,S^l$。
class FeatureExtractor(object):
def extract_for_current_state(self, sentence, word2idx, pos2idx, dep2idx):
direct_tokens = self.extract_from_stack_and_buffer(sentence, num_words=3)
children_tokens = self.extract_children_from_stack(sentence, num_stack_words=2)
word_features = []
pos_features = []
dep_features = []
# Word features -> 18
word_features.extend(map(lambda x: x.word, direct_tokens))
word_features.extend(map(lambda x: x.word, children_tokens))
# pos features -> 18
pos_features.extend(map(lambda x: x.pos, direct_tokens))
pos_features.extend(map(lambda x: x.pos, children_tokens))
# dep features -> 12 (only children)
dep_features.extend(map(lambda x: x.dep, children_tokens))
word_input_ids = [word2idx[word] if word in word2idx else word2idx[UNK_TOKEN.word]
for word in word_features]
pos_input_ids = [pos2idx[pos] if pos in pos2idx else pos2idx[UNK_TOKEN.pos]
for pos in pos_features]
dep_input_ids = [dep2idx[dep] if dep in dep2idx else dep2idx[UNK_TOKEN.dep]
for dep in dep_features]
return [word_input_ids, pos_input_ids, dep_input_ids] # 48 features
这个函数首先调用self.extract_from_stack_and_buffer(sentence, num_words=3)首先得到$s_0,s_1,s_2$和$b_0,b_1,b_2$。 然后调用self.extract_children_from_stack(sentence, num_stack_words=2),这个函数得到$s_0,s_1$的12个孩子。
注意这里实际我们得到的是18个Token,因此我们很容易得到18个词和词性,以及12个label,最后我们把它们都变成id。变成id的时候有可能出现训练数据中没有见过词,把没见过的词都变成一个特殊的UNK词。
下面是extract_from_stack_and_buffer的代码,比较简单:
def extract_from_stack_and_buffer(self, sentence, num_words=3):
tokens = []
tokens.extend([NULL_TOKEN for _ in range(num_words - len(sentence.stack))])
tokens.extend(sentence.stack[-num_words:])
tokens.extend(sentence.buff[:num_words])
tokens.extend([NULL_TOKEN for _ in range(num_words - len(sentence.buff))])
return tokens # 6 features
里面的编程小技巧也可以学习一下,比如要去栈顶的num_words个词,我们可以用stack[-num_words:],但是如果stack里不够num_words呢?那么我们需要在前面补num_words - len(sentence.stack)个NULL_TOKEN。
def extract_children_from_stack(self, sentence, num_stack_words=2):
children_tokens = []
for i in range(num_stack_words):
if len(sentence.stack) > i:
lc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "left", 1)
rc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "right", 1)
lc1 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 1, "left", 1)
if lc0 != NULL_TOKEN else NULL_TOKEN
rc1 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 1, "right", 1)
if rc0 != NULL_TOKEN else NULL_TOKEN
llc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "left", 2)
if lc0 != NULL_TOKEN else NULL_TOKEN
rrc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "right", 2)
if rc0 != NULL_TOKEN else NULL_TOKEN
children_tokens.extend([lc0, rc0, lc1, rc1, llc0, rrc0])
else:
[children_tokens.append(NULL_TOKEN) for _ in range(6)]
return children_tokens # 12 features
extract_children_from_stack用于抽取12个孩子。代码都是类似的,我们看其中一个:
llc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "left", 2)
if lc0 != NULL_TOKEN else NULL_TOKEN
如果不熟悉Python的这种写法的读者可以认为它等价于:
if lc0 != NULL_TOKEN:
llc0 = sentence.get_child_by_index_and_depth(sentence.stack[-i - 1], 0, "left", 2)
else:
llc0 = NULL_TOKEN
如果stack[-1](i=0的时候)没有左孩子(lc0 == NULL_TOKE),那么显然不可能有左孩子的左孩子,否则调用get_child_by_index_and_depth,参数是stack[-1],0,”left”和2。这个函数可以找到左孩子的左孩子。
def get_child_by_index_and_depth(self, token, index, direction, depth): # Get child token
if depth == 0:
return token
if direction == "left":
if len(token.left_children) > index:
return self.get_child_by_index_and_depth(
self.tokens[token.left_children[index]],
index, direction, depth - 1)
return NULL_TOKEN
else:
if len(token.right_children) > index:
return self.get_child_by_index_and_depth(
self.tokens[token.right_children[::-1][index]],
index, direction, depth - 1)
return NULL_TOKEN
这是一个递归函数,depth是递归的深度,index参数表示最左(或者最右)的第index个孩子。比如下面的树(每个节点我们只画它的left孩子):
a
/ | \
/ | \
b c d
/
/
e
get_child_by_index_and_depth(a, 0, “left”,1)会返回b,get_child_by_index_and_depth(a, 1, “left”,1)返回c。而get_child_by_index_and_depth(a, 0, “left”,2)会返回e。
当然我们可以没有必要实现这么复杂的函数,只需要实现get-left-child(indx)和get-right-child(index)就行了,如果要找最左孩子的最左孩子,那么可以get-left-child(get-left-child(a))。
生成训练数据
接下来就需要生成用于训练模型的训练数据了,训练数据的输入是从某个配置提取的特征,而输出是操作。这里是通过create_instances_for_data函数来实现的。
def create_instances_for_data(self, data, word2idx, pos2idx, dep2idx):
lables = []
word_inputs = []
pos_inputs = []
dep_inputs = []
for i, sentence in enumerate(data):
num_words = len(sentence.tokens)
for _ in range(num_words * 2):
word_input, pos_input, dep_input =
self.extract_for_current_state(sentence, word2idx, pos2idx, dep2idx)
legal_labels = sentence.get_legal_labels()
curr_transition = sentence.get_transition_from_current_state()
if curr_transition is None:
break
assert legal_labels[curr_transition] == 1
# Update left/right children
if curr_transition != 2:
sentence.update_child_dependencies(curr_transition)
sentence.update_state_by_transition(curr_transition)
lables.append(curr_transition)
word_inputs.append(word_input)
pos_inputs.append(pos_input)
dep_inputs.append(dep_input)
else:
sentence.reset_to_initial_state()
# reset stack and buffer to default state
sentence.reset_to_initial_state()
targets = np.zeros((len(lables), self.model_config.num_classes), dtype=np.int32)
targets[np.arange(len(targets)), lables] = 1
return [word_inputs, pos_inputs, dep_inputs], targets
代码第一个for循环遍历每一个句子,第二个循环处理每一个句子。根据之前的介绍,长度为n的句子需要执行2n次操作。对于内层循环,首先根据sentence当前的状态得到18个词,18个词性和12个label,这可以通过调用之前我们介绍过的extract_for_current_state。
word_input, pos_input, dep_input = self.extract_for_current_state(sentence, word2idx, pos2idx, dep2idx)
接着调用sentence.get_legal_labels()得到当前状态下的合法操作。这个函数非常简单:
def get_legal_labels(self):
labels = ([1] if len(self.stack) > 2 else [0])
labels += ([1] if len(self.stack) >= 2 else [0])
labels += [1] if len(self.buff) > 0 else [0]
return labels
它返回长度为3的list,分别表示是否可以LEFT-ARC、RIGHT-ARC和SHIFT,比如[0,0,1]表示只能SHIFT。LEFT-ARC要求stack有3个元素,因为ROOT总是在栈底,并且不可能有ROOT <- XX。而RIGHT-ARC值需要3个元素,因为可以 ROOT -> XX。接着调用sentence.get_transition_from_current_state()得到”正确”的操作:
def get_transition_from_current_state(self): # logic to get next transition
if len(self.stack) < 2:
return 2 # shift
stack_token_0 = self.stack[-1]
stack_token_1 = self.stack[-2]
if stack_token_1.token_id >= 0 and stack_token_1.head_id == stack_token_0.token_id:
# left arc
return 0
elif stack_token_1.token_id >= -1 and stack_token_0.head_id == stack_token_1.token_id \
and stack_token_0.token_id not in map(lambda x: x.head_id, self.buff):
return 1 # right arc
else:
return 2 if len(self.buff) != 0 else None
这个函数实现静态的oracle。如果stack小于2个元素,那么只能SHIFT。如果stack[-2] <- stack[-1]并且stack[-2]不是ROOT,那么就可以ARC-LEFT。
如果有stack[-2] -> stack[-1]并且stack[-1]的不是buff里其它节点的head,那么就可以ARC-RIGHT。这段代码比之前的判断更加简单。因为一个点只有一条入边,而已经有stack[-2] -> stack[-1]了,因此stack[-1]已经有入边了,那么只需要判断stack[-1]的出边是否都处理完了就行,因此可以变量buffer里的所有节点,看看是否有节点的head是stack[-1]。最后如果buffer里还有元素,就可以SHIFT,否则就返回None。
接下来如果是LEFT-ARC或者RIGHT-ARC,则需要修改配置(Sentence)的A。
def update_child_dependencies(self, curr_transition):
if curr_transition == 0:
head = self.stack[-1]
dependent = self.stack[-2]
elif curr_transition == 1:
head = self.stack[-2]
dependent = self.stack[-1]
if head.token_id > dependent.token_id:
head.left_children.append(dependent.token_id)
head.left_children.sort()
else:
head.right_children.append(dependent.token_id)
head.right_children.sort()
这个函数首先根据操作是LEFT-ARC还是RIGHT-ARC找到head和dependent,然后再判断head和dependent的左右位置关系把dependent加到head的左孩子或者右孩子集合里。最后对修改过的左孩子集合或者右孩子集合排序,这样方便get_child_by_index_and_depth找最左或者最右的孩子。
接着调用sentence.update_state_by_transition(curr_transition)“执行”这个操作,最后把(word_input, pos_input, dep_input)作为输入,curr_transition作为输出,得到一个训练数据。
# updates stack, buffer and dependencies
def update_state_by_transition(self, transition, gold=True):
if transition is not None:
if transition == 2: # shift
self.stack.append(self.buff[0])
self.buff = self.buff[1:] if len(self.buff) > 1 else []
elif transition == 0: # left arc
self.dependencies.append((self.stack[-1], self.stack[-2])) if gold else
self.predicted_dependencies.append( (self.stack[-1], self.stack[-2]))
self.stack = self.stack[:-2] + self.stack[-1:]
elif transition == 1: # right arc
self.dependencies.append((self.stack[-2], self.stack[-1])) if gold else
self.predicted_dependencies.append((self.stack[-2], self.stack[-1]))
self.stack = self.stack[:-1]
这里有一个参数gold,如果gold为True,那么依存关系加到dependencies里作为参考答案,否则认为是模型预测的操作,依存关系加到predicted_dependencies。
不熟悉Python的读者可能会对下面的代码有些困惑:
self.dependencies.append((self.stack[-1], self.stack[-2])) if gold else
self.predicted_dependencies.append((self.stack[-1], self.stack[-2]))
它其实就是:
if gold:
self.dependencies.append((self.stack[-1], self.stack[-2]))
else:
self.predicted_dependencies.append((self.stack[-1], self.stack[-2]))
神经网络的构建
神经网络的代码主要在ParserModel和它的基类Model里,Model的构造函数会调用build函数。
def build(self):
self.add_placeholders()
self.pred = self.add_cube_prediction_op()
self.loss = self.add_loss_op(self.pred)
self.accuracy = self.add_accuracy_op(self.pred)
self.train_op = self.add_training_op(self.loss)
这个函数会调用add_placeholders定义用于输入和输出的PlaceHolder,add_cube_prediction_op根据输入计算输出,而add_loss_op根据输出和正确分类计算loss。add_accuracy_op计算分类的准确率,最后add_training_op返回用于每一个batch训练的operation。下面我们逐个来阅读其代码。
def add_placeholders(self):
with tf.variable_scope("input_placeholders"):
self.word_input_placeholder = tf.placeholder(
shape=[None, self.config.word_features_types],
dtype=tf.int32, name="batch_word_indices")
self.pos_input_placeholder = tf.placeholder(
shape=[None, self.config.pos_features_types],
dtype=tf.int32, name="batch_pos_indices")
self.dep_input_placeholder = tf.placeholder(
shape=[None, self.config.dep_features_types],
dtype=tf.int32, name="batch_dep_indices")
with tf.variable_scope("label_placeholders"):
self.labels_placeholder = tf.placeholder(shape=[None, self.config.num_classes],
dtype=tf.float32, name="batch_one_hot_targets")
with tf.variable_scope("regularization"):
self.dropout_placeholder = tf.placeholder(shape=(), dtype=tf.float32, name="dropout")
输入是3个placeholder,分别是18个词,18个词性和12个label。输出是分类的个数,如果不考虑依存关系的,那么输出的大小是3。最后定义了一个dropout的placeholder,用于控制dropout。
def add_cube_prediction_op(self):
_, word_embeddings, pos_embeddings, dep_embeddings = self.add_embedding()
with tf.variable_scope("layer_connections"):
with tf.variable_scope("layer_1"):
w11 = random_uniform_initializer((self.config.word_features_types *
self.config.embedding_dim,
self.config.l1_hidden_size), "w11",
0.01, trainable=True)
w12 = random_uniform_initializer((self.config.pos_features_types *
self.config.embedding_dim,
self.config.l1_hidden_size), "w12",
0.01, trainable=True)
w13 = random_uniform_initializer((self.config.dep_features_types *
self.config.embedding_dim,
self.config.l1_hidden_size), "w13",
0.01, trainable=True)
b1 = random_uniform_initializer((self.config.l1_hidden_size,), "bias1",
0.01, trainable=True)
# for visualization
preactivations = tf.pow(tf.add_n([tf.matmul(word_embeddings, w11),
tf.matmul(pos_embeddings, w12),
tf.matmul(dep_embeddings, w13)]) + b1, 3, name="preactivations")
tf.summary.histogram("preactivations", preactivations)
h1 = tf.nn.dropout(preactivations,
keep_prob=self.dropout_placeholder,
name="output_activations")
with tf.variable_scope("layer_2"):
w2 = random_uniform_initializer(
(self.config.l1_hidden_size, self.config.l2_hidden_size),
"w2", 0.01, trainable=True)
b2 = random_uniform_initializer((self.config.l2_hidden_size,), "bias2",
0.01, trainable=True)
h2 = tf.nn.relu(tf.add(tf.matmul(h1, w2), b2), name="activations")
with tf.variable_scope("layer_3"):
w3 = random_uniform_initializer(
(self.config.l2_hidden_size, self.config.num_classes), "w3",
0.01, trainable=True)
b3 = random_uniform_initializer((self.config.num_classes,),
"bias3", 0.01, trainable=True)
with tf.variable_scope("predictions"):
predictions = tf.add(tf.matmul(h2, w3), b3, name="prediction_logits")
return predictions
代码非常简单,请读者对照论文阅读,唯一和一般网络不同的是:第一层的激活函数是三次方函数,而不是通常用的ReLU或者sigmoid。此外,它也会一开始就调用add_embedding把词、词性和label进行Embedding。然后是定义损失函数:
def add_loss_op(self, pred):
tvars = tf.trainable_variables()
without_bias_tvars = [tvar for tvar in tvars if 'bias' not in tvar.name]
with tf.variable_scope("loss"):
cross_entropy_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
labels=self.labels_placeholder, logits=pred), name="batch_xentropy_loss")
l2_loss = tf.multiply(self.config.reg_val, self.l2_loss_sum(without_bias_tvars),
name="l2_loss")
loss = tf.add(cross_entropy_loss, l2_loss, name="total_batch_loss")
tf.summary.scalar("batch_loss", loss)
return loss
除了计算模型输出pred的交叉熵loss之外,还计算了网络参数(bias除外)的L2正则项的loss。为了找到bias,前面网络定义时给所有的bias名字都是定义为bias1,bias2…,然后从所有trainable_variables去掉名字包含”bias”的变量。
def add_accuracy_op(self, pred):
with tf.variable_scope("accuracy"):
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(pred, axis=1),
tf.argmax(self.labels_placeholder, axis=1)), dtype=tf.float32),
name="curr_batch_accuracy")
return accuracy
add_accuracy_op非常简单,就是用argmax寻找预测的下标和参考答案labels_placeholder对比得到准确率。
def add_training_op(self, loss):
with tf.variable_scope("optimizer"):
optimizer = tf.train.AdamOptimizer(learning_rate=self.config.lr, name="adam_optimizer")
tvars = tf.trainable_variables()
grad_tvars = optimizer.compute_gradients(loss, tvars)
self.write_gradient_summaries(grad_tvars)
train_op = optimizer.apply_gradients(grad_tvars)
return train_op
add_training_op函数定义AdamOptimizer,为了统计梯度的summary,这里使用了compute_gradients和apply_gradients。最后返回用于训练的train_op。
训练
训练的代码在函数fit里:
def fit(self, sess, saver, config, dataset, train_writer, valid_writer, merged):
best_valid_UAS = 0
for epoch in range(config.n_epochs):
print "Epoch {:} out of {:}".format(epoch + 1, self.config.n_epochs)
summary, loss = self.run_epoch(sess, config, dataset, train_writer, merged)
if (epoch + 1) % dataset.model_config.run_valid_after_epochs == 0:
valid_UAS = self.run_valid_epoch(sess, dataset)
valid_UAS_summary = tf.summary.scalar("valid_UAS",
tf.constant(valid_UAS, dtype=tf.float32))
valid_writer.add_summary(sess.run(valid_UAS_summary), epoch + 1)
if valid_UAS > best_valid_UAS:
best_valid_UAS = valid_UAS
if saver:
print "New best dev UAS! Saving model.."
saver.save(sess, os.path.join(DataConfig.data_dir_path,
DataConfig.model_dir, DataConfig.model_name))
# trainable variables summary -> only for training
if (epoch + 1) % dataset.model_config.write_summary_after_epochs == 0:
train_writer.add_summary(summary, global_step=epoch + 1)
代码非常简单,for循环n_epochs个epoch,调用run_epoch进行训练,然后定期调用run_valid_epoch在验证集上进行测试,如果比当前模型好,那么就保存下来。run_epoch遍历训练数据集的每一个batch,调用train_on_batch训练一个batch的数据。
def train_on_batch(self, sess, inputs_batch, labels_batch, merged):
word_inputs_batch, pos_inputs_batch, dep_inputs_batch = inputs_batch
feed = self.create_feed_dict([word_inputs_batch, pos_inputs_batch, dep_inputs_batch],
labels_batch=labels_batch,
keep_prob=self.config.keep_prob)
_, summary, loss = sess.run([self.train_op, merged, self.loss], feed_dict=feed)
return summary, loss
train_on_batch调用根据batch的输入构造feed dict,然后用session来run train_op进行训练。
验证测试
验证测试的代码在run_valid_epoch里,本来在训练里被调用,但是它比较复杂和重要,因此我们单独拿出来分析。
def run_valid_epoch(self, sess, dataset):
print "Evaluating on dev set",
self.compute_dependencies(sess, dataset.valid_data, dataset)
valid_UAS = self.get_UAS(dataset.valid_data)
print "- dev UAS: {:.2f}".format(valid_UAS * 100.0)
return valid_UAS
这个函数首先调用compute_dependencies然后调用get_UAS得到在验证集上的UAS。光看这个函数很难明白,我们先来看compute_dependencies。下面是这个函数的主要代码:
def compute_dependencies(self, sess, data, dataset):
sentences = data
rem_sentences = [sentence for sentence in sentences]
[sentence.clear_prediction_dependencies() for sentence in sentences]
[sentence.clear_children_info() for sentence in sentences]
while len(rem_sentences) != 0:
curr_batch_size = min(dataset.model_config.batch_size, len(rem_sentences))
batch_sentences = rem_sentences[:curr_batch_size]
enable_features = [0 if len(sentence.stack) == 1 and len(sentence.buff) == 0 else 1
for sentence in batch_sentences]
enable_count = np.count_nonzero(enable_features)
while enable_count > 0:
curr_sentences = [sentence for i, sentence in enumerate(batch_sentences) if
enable_features[i] == 1]
curr_inputs = [
dataset.feature_extractor.extract_for_current_state(sentence, dataset.word2idx,
dataset.pos2idx, dataset.dep2idx) for sentence in curr_sentences]
word_inputs_batch = [curr_inputs[i][0] for i in range(len(curr_inputs))]
pos_inputs_batch = [curr_inputs[i][1] for i in range(len(curr_inputs))]
dep_inputs_batch = [curr_inputs[i][2] for i in range(len(curr_inputs))]
predictions = sess.run(self.pred,
feed_dict=self.create_feed_dict([word_inputs_batch, pos_inputs_batch,
dep_inputs_batch]))
legal_labels = np.asarray([sentence.get_legal_labels() for sentence in curr_sentences],
dtype=np.float32)
legal_transitions = np.argmax(predictions + 1000 * legal_labels, axis=1)
# update left/right children so can be used for next feature vector
[sentence.update_child_dependencies(transition) for (sentence, transition) in
zip(curr_sentences, legal_transitions) if transition != 2]
# update state
[sentence.update_state_by_transition(legal_transition, gold=False)
for (sentence, legal_transition) in zip(curr_sentences, legal_transitions)]
enable_features = [0 if len(sentence.stack) == 1 and len(sentence.buff) == 0 else 1
for sentence in batch_sentences]
enable_count = np.count_nonzero(enable_features)
# Reset stack and buffer
[sentence.reset_to_initial_state() for sentence in batch_sentences]
rem_sentences = rem_sentences[curr_batch_size:]
compute_dependencies的输入是测试集合里的所有句子。如果输入只有一个句子,那么我们需要做的事情是:当Sentence当前的配置不是结束状态,那么用模型预测当前配置的操作,执行操作并修改配置(stack, buff和predicted_dependencies)。当Sentence进入结束状态,我们就得到了一个parse结果(存放在predicted_dependencies)。然后就可以用UAS的公式计算了。
一个一个计算太慢,我们希望一次给定一个batch的句子进行处理。但是这有一个问题,不同句子的长度不同,进入结束状态的时刻也不同,因此每处理一个时刻,就需要把结束状态的句子从待处理列表里删除掉。多个Epoch会遍历一个Sentence多次,因此首先把Sentence里的信息清除掉
[sentence.clear_prediction_dependencies() for sentence in sentences]
[sentence.clear_children_info() for sentence in sentences]
rem_sentences是待处理的句子,一开始为所有测试句子,第一个while循环退出的条件是它为空。
while len(rem_sentences) != 0:
curr_batch_size = min(dataset.model_config.batch_size, len(rem_sentences))
batch_sentences = rem_sentences[:curr_batch_size]
enable_features = [0 if len(sentence.stack) == 1 and len(sentence.buff) == 0 else 1
for sentence in batch_sentences]
enable_count = np.count_nonzero(enable_features)
如果待处理的句子不空,那么取一个batch(curr_batch_size)的片段到batch_sentences。enable_features判断这个batch的句子哪些当前的配置是结束了。第二个循环的判断条件是这个batch里还有一些句子没有进入结束配置。第二个while循环首先取出没有进入结束配置的句子:
while enable_count > 0: # 如果还有句子没有进入结束配置
# enable_features[i] == 1说明句子i还没有结束,需要继续parsing
curr_sentences = [sentence for i, sentence in enumerate(batch_sentences)
if enable_features[i] == 1]
接下来的代码对这些句子进行特征提取:
curr_inputs = [dataset.feature_extractor.
extract_for_current_state(sentence, dataset.word2idx,dataset.pos2idx, dataset.dep2idx)
for sentence in curr_sentences]
word_inputs_batch = [curr_inputs[i][0] for i in range(len(curr_inputs))]
pos_inputs_batch = [curr_inputs[i][1] for i in range(len(curr_inputs))]
dep_inputs_batch = [curr_inputs[i][2] for i in range(len(curr_inputs))]
然后用模型进行预测,并且在所有合法操作中选择模型打分最高的操作:
predictions = sess.run(self.pred,
feed_dict=self.create_feed_dict([word_inputs_batch, pos_inputs_batch,
dep_inputs_batch]))
legal_labels = np.asarray([sentence.get_legal_labels() for sentence in curr_sentences],
dtype=np.float32)
legal_transitions = np.argmax(predictions + 1000 * legal_labels, axis=1)
如果用for循环写,可能是这样:
for i in range(number):
max_label = None
for j in len(legal_labels):
if legal_labels[j] and
(max_label is None or predictions[j] > predictions[max_label]):
max_label=j
这非常繁琐,循环和if也很多。这里使用了一个小技巧——argmax(predictions + 1000 * legal_labels)。如果某个操作是合法的操作,给它加上一个很大的数(1000),而非法操作不加,这样的结果就是非法的操作不可能是argmax的返回只,因此等价于在合法的操作集合里选择predictions最大的那个。
接下来就是根据上面选择的操作来执行,得到新的配置。执行完了之后再重新判断句子是否进入结束状态,如果所有句子都结束,那么循环退出,否则继续循环。
# update left/right children so can be used for next feature vector
[sentence.update_child_dependencies(transition) for (sentence, transition) in
zip(curr_sentences, legal_transitions) if transition != 2]
# update state
[sentence.update_state_by_transition(legal_transition, gold=False)
for (sentence, legal_transition) in zip(curr_sentences, legal_transitions)]
enable_features = [0 if len(sentence.stack) == 1 and len(sentence.buff) == 0 else 1 for
sentence in batch_sentences]
enable_count = np.count_nonzero(enable_features)
因此可以看成,第二重for循环的次数取决于最长的句子,如果为了提高效率,一个batch的句子的长度应该尽量接近。
Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations
基本想法
这篇文章使用双向LSTM来改进dependency parsing的效果,它可以应用到基于转换的贪心算法里也可以用到graph-based的算法里。它们的思想都是一样的,都是用双向LSTM来编码一个句子并且得到每个词的向量表示。和前面的Embedding不同,使用双向LSTM编码的句子会考虑词的上下文,因此效果会更好。当然我们也可以用后面介绍的Self-Attention机制来进一步改进词的上下文表示,也可以很容易加入无监督的数据,读者在学习后面的内容后思考怎么改进。
双向LSTM的参数也是和Dependency Parser的其它参数一起学习的,因此它学到的词的上下文表示是适合依存分析这个任务的。
具体细节
arc-hybrid系统
这篇论文使用的是arc-hybrid系统,我们之前已经介绍过了,这里会简单的回顾一下,目的是让读者熟悉用到的记号,便于理解后面的内容。
在一个arc-hybrid系统里,一个配置$c=(\sigma,\beta,T)$,其中$\sigma$是一个堆栈,$\beta$是一个buffer,而T是已经确定的依存关系集合。堆栈和buffer里存的都是句子中词的下标(指针)。给定一个句子$s=w_1…w_n,t_1…t_n$,其中$w_i$是第i个词,$t_i$是对应的词性。
初始时堆栈是空,$\beta=[1,2,…,n,ROOT]$。如果一个配置c的堆栈为空并且buffer里只有ROOT,那么它就是一个结束状态的配置,我们的parse过程结束,parse的结果在$T_c$(配置c对应的集合T)里。arc-hybrid系统包括3种操作:
\[\begin{split} SHIFT[(\sigma,b_0|\beta, T)] & = (\sigma|b_0, \beta, T) \\ LEFT_l[(\sigma|s_1|s_0, b_0|\beta,T)] & = (\sigma|s_0|b_0, \beta, T \cup \{(b_0,s_0, l)\}) \\ RIGHT_l[(\sigma|s_1|s_0, \beta, T)] & = (\sigma|s_1, \beta, T \cup \{(s_1,s_0,l) \}) \end{split}\]上式中”$b_0 \vert \beta$”的意思是buffer的开头是$b_0$并且后面的内容是$\beta$,而”$\sigma \vert s_1 \vert s_0$”的意思是堆栈的栈顶是$s_0$,在往下是$s_1$,再往下的内容是$\sigma$。
score function
score函数的输入是一个配置和一个操作,输出是一个得分,表示这个配置下采取这个操作的得分。我们这里使用神经网络来计算score函数:
\[Score_\theta(x,t)=MLP_\theta(x)[t]\]神经网络的输入是配置(提取的特征),输出是所有操作的得分(通常是softmax的概率)。
简单的特征函数
上面的x是根据配置c计算的特征$x=\Phi(c)$,假设配置c为$(… \vert s_2 \vert s_1 \vert s_0, b_0 \vert…, T)$,即栈顶3个元素是$s_0s_1s_2$,buffer的开头$b_0$,最简单的特征函数只利用这4个词的特征:
\[\begin{split} \Phi(c) = v_{s_2} ◦ v_{s_1} ◦ v_{s_1} ◦ v_{b_1} \\ v_i=BiLSTM(x_{1:n},i) \end{split}\]这个特征相当简单,我们首先对输入句子使用双向LSTM计算得到每个词的向量(双向的拼接起来),对于一个配置c,我们只考虑栈顶的3个词和buffer开头的一个词,把这4个词的BiLSTM得到的向量拼接起来作为神经网络的输入。
因为BiLSTM有两个方向,前向的LSTM编码了第1个到第i个词的信息;而后向的LSTM编码了第n个词到第i个词的信息,因此可以任务,$v_i$提供了整个句子的信息,而且是它作为$s_0$等时候的信息。而且这个BiLSTM是和神经网络的其它参数一起学习的,因此BiLSTM学到的句子编码是最适合这个任务的。
损失函数
这里是Margin-based的损失函数,Margin-based意思是让正确的得分减去错误的得分尽量大。这里使用了常见的hinge loss:
\[max(0, 1 - \underset{t_o \in G}{max}MLP(\Phi(c))[t_o] + \underset{t_p \in A\\G}{max}MLP(\Phi(c))[t_p])\]上式中,c是输入的配置,G是正确操作集合,A是所有合法操作集合。A\G是集合A减去集合G。我们可以这样读这个公式:我们期望正确操作集合的得分$MLP(\Phi(c))[t_o]$尽量大;而错误的操作集合的得分$MLP(\Phi(c)[t_p])$尽量小。如果前者比后者大1(margin)那么就没有loss,否则loss就是它们的差值。因为正确的集合和错误的集合都可能有多个操作,我们只选择得分最高的来计算loss。
Dynamic Oracle
这个我们已经介绍过了,每次Parser采样的不是gold的操作,而是所有合法操作中当前模型打分最高的操作。这样的好处是它能在学习的过程中碰到错误的配置,这样即使之前出错了仍然努力parse后面的内容。
Aggressive Exploration
为了更多的探索错误的配置,除了选择当前模型打分最高的操作,也会有一定的探索概率选择打分不那么高的操作。这类似与强化学习里的Exploration。
实验结果
实验结果如下图所示,可以看到,只使用简单的4个词的BiLSTM特征,PTB-SD数据集上就可以得到93.1的UAS。
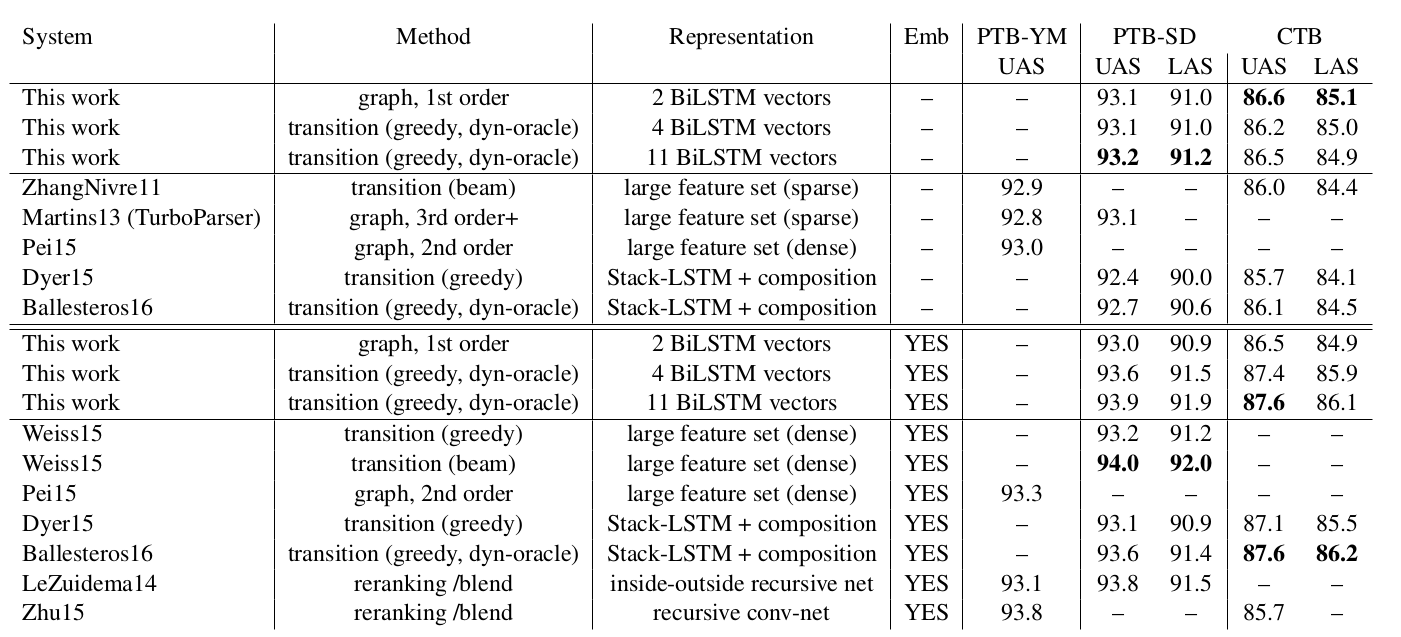 图:BiLSTM Dependency Parser实验结果
图:BiLSTM Dependency Parser实验结果
源代码
这篇论文的源代码在这里,因为是DyNet实现的,这里就不详细解读了,有兴趣的读者可以自己阅读。
- 显示Disqus评论(需要科学上网)