本文回顾语音识别的统计框架,这是目前state-of-the art识别技术的基础。因为这个领域的发展很快,这里只介绍用于大词汇量连续语音识别的标准技术,包括连续概率密度的HMM,上下文相关的音子建模,n-gram语言模型和时间同步的(time-synchronous)Viterbi beam搜索以及对于Viterbi搜索的改进以便获取多个解码结果(N-best和Lattice)。因为有很多文献介绍理论和实现的技术,因此我们这里只是做一个回顾,重点会介绍Viterbi搜索的技术。
本文的内容是后面介绍的基于WFST的语音识别的基础。因此在介绍基于WFST框架的系统前需要先介绍这些内容。
目录
语音识别的统计框架
统计语音识别系统使用噪声信道(noise-signal)模型,如下图所示。
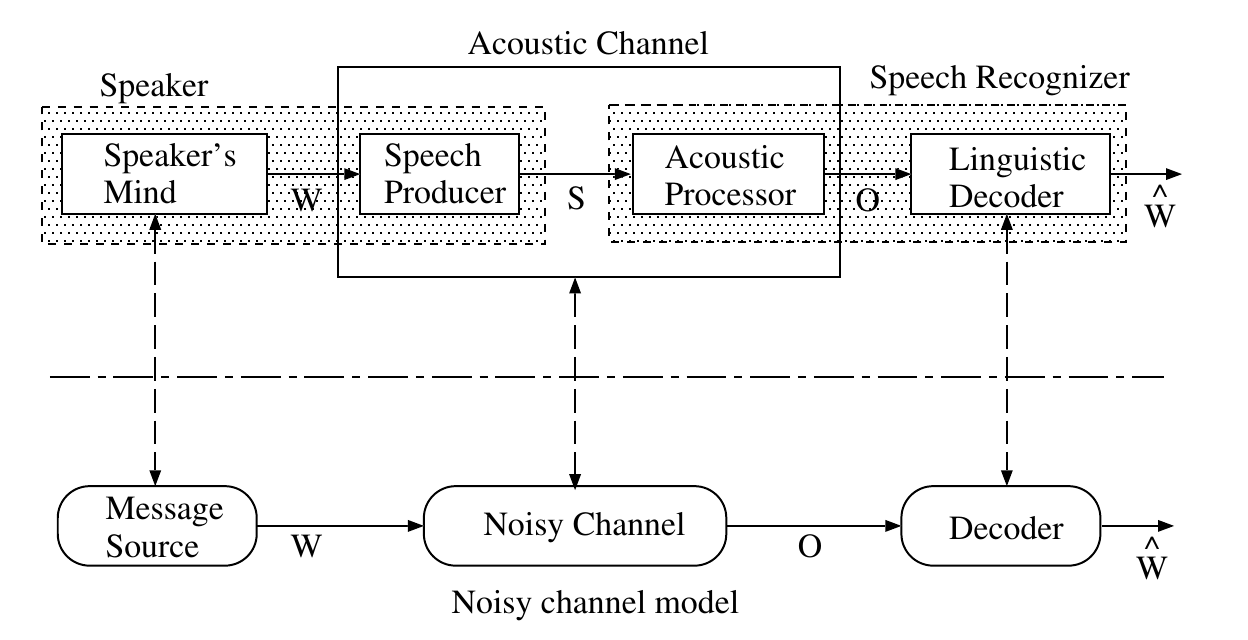 图:噪声信道模型
图:噪声信道模型
语音识别的过程包括一个说话人和一个语音识别系统。受话人想好了要说的词序列$W$,这是信号源(Source)。$W$被送到一个声学信道(有噪声),这个声学信道包括说话人的发音器官等,把词序列转换成声学信号$S$,然后通过信道传播到语音识别系统后变成特征向量序列$O$。解码器试图从特征向量序列$O$恢复原始词序列$W$,它恢复得到的是$\hat{W}$。在这个模型里声学特征提取和解码器属于语音识别系统。
根据信息论,给定输入$O$,解码器在所有可能的词序列集合$\mathcal{W}$里选择最可能的词序列$\hat{W}$,也就是:
\[\hat{W}=\underset{W \in \mathcal{W}}{argmax}P(W|O)\]上式是根据观察,选择后验概率最大(maximum a posteriori (MAP))的词序列,因此基于上式的解码器也叫MAP解码器。根据贝叶斯公式:
\[P(W|O)=\frac{P(O|W)P(W)}{P(O)}\]因此
\[\hat{W}=\underset{W \in \mathcal{W}}{argmax} P(O|W)P(W)\]其中$P(O \vert W)$是词序列产生声学观察$O$的似然概率,而$P(W)$是词序列$W$的先验概率。$P(O)$是观察$O$的先验概率,因为$W$与它无关,因此可以忽略。
因此我们的解码器在搜索$\hat{W}$的时候值考虑$p(O \vert W)P(W)$,我们通常把建模$P(O \vert W)$的模型叫做声学(Acoustic)模型,而$P(W)$叫做语言模型。由于贝叶斯公式,我们有独立的声学模型$P(O \vert W)$和语言模型$P(W)$,解码器在解码的时候会同时考虑所有可能的词序列,然后在其中找出声学模型得分和语言模型得分都很高的$\hat{W}$。
根据这个统计模型,典型的语音识别系统如下图所示。
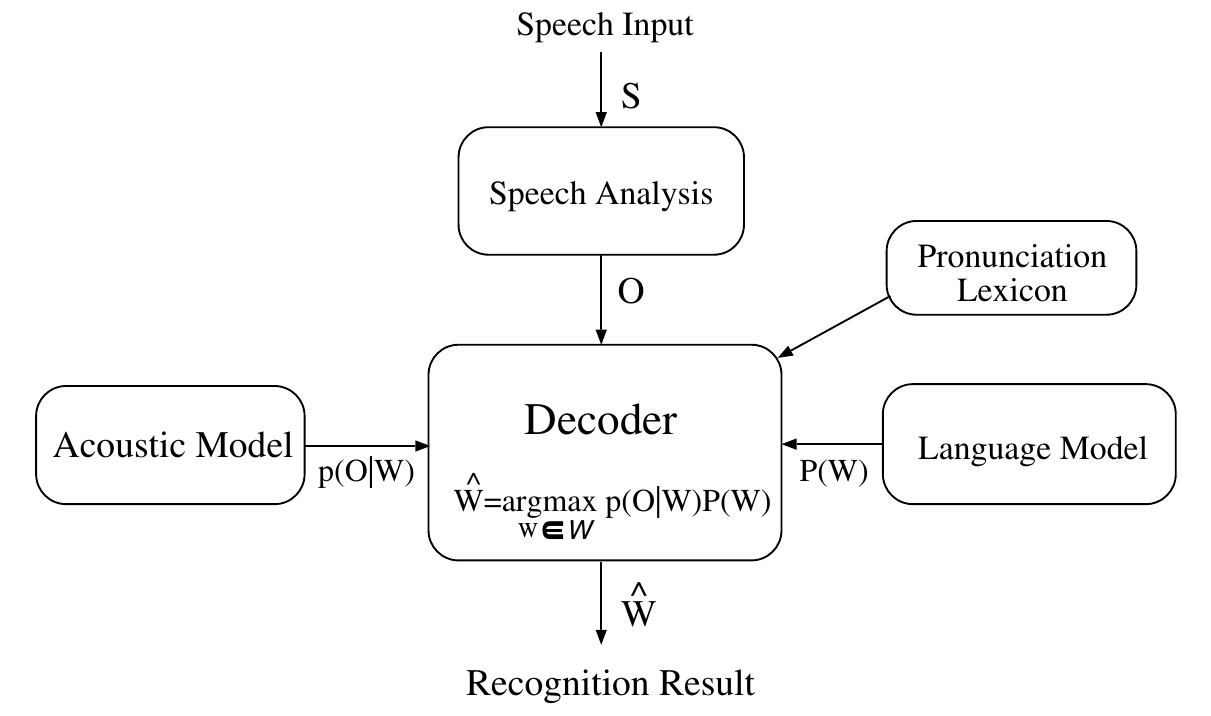 图:连续语音识别系统
图:连续语音识别系统
语音波形$S$首先通过语音信号处理模块变成特征向量序列$O$,然后解码器使用声学模型和语言模型搜索最可能的词序列。因为我们通常是使用subword的phone来作为声学模型的基本单元,并且使用HMM来建模每一个phone,因此我们还需要一个发音词典(Lexicon)来告诉模型一个词是由哪些phone组成,从而把phone的HMM拼接成词的HMM。
语音信号处理
语音信号处理的目标是从输入的波形中提取特征向量序列,这个特征向量序列需要提取时候phone分类的特征。因为语音信号是短时平稳信号,因此语音信号被切分成很短(比如10ms)的帧,然后对这一帧进行分析。比如,通过16kHz的采样只是,信号会使用高通滤波器进行于pre-emphasize,然后进行傅里叶分析得到功率谱。接着使用24个美尔滤波器组对功率谱进行分析并且用log对其范围进行压缩,最后使用离散余弦变换(DCT)得到MFCC特征。前12个MFCC系数以及信号的log能量拼起来得到13维的特征。我们通常是25ms的窗口作为一帧,每次往后帧移10ms(从而有15ms的重叠)。此外,因为语音信号长时间是时变的系统,所以我们还通过Delta和Delta-Delta分别得到13维的动态特征,加起来总共39维特征。
除了使用Delta的特征,我们也可以使用 Linear Discriminant Analysis(LDA)和Heteroscedastic LDA (HLDA)这样的有监督的降维技术,也可以使用神经网络提取特征。不过本文的重点不是特征提取,有兴趣的读者可以上网搜索相关资料。
最终我们得到的特征向量序列为$O=o_1, o_2, …, o_T$,其中$o_t$是第t帧对于的特征向量,而$T$是特征向量序列的长度。
声学模型
声学模型需要使用统计模型来计算声学似然概率$p(O \vert W)$。如果是$O$是说话人说的词序列$W$对应的观察序列,则这个模型应该输出较大的概率。反之,如果$O$不是说话人说的$W$对应的观察,则模型应该输出较小的概率。
HMM
HMM在语音识别的声学模型中被广泛使用。HMM被用于建模非平稳(non-stationary)的信号。语音显然是非平稳的信号,它包括的语言学信息是随着时间变化的频谱模式。比如,词”hello”,它的频谱模式在发4个不同音素/h/,/ae/, /l/ 和 /ou/时会明显不同,但是每一个音素又可以被看成一个平稳的信号。而HMM通过状态的切换来建模这种变化,而同一个状态下的模型是平稳的。
下图是一个从左到右(left-to-right)的HMM,它通常在语音识别系统里用来建模一个phone。这个HMM有三个状态,每个状态可以停留在当前状态,也可以跳转到下一个状态。HMM最左边的状态是初始状态,最右边的是终止状态。在每个时刻,根据当前的状态都会有一个概率分布来建模当前状态输出当前观察的概率。状态本身是不可观察的,是隐藏的。不同的状态表示了不同phone的不同发音阶段,它受说话人、说话方式以及录音环境影响。
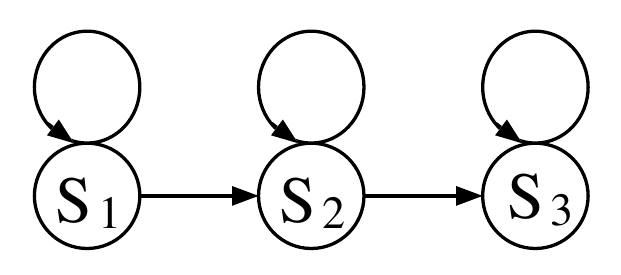 图:HMM
图:HMM
注意:HMM本身并不建模某个状态下”发射”某个观察的概率。这需要通过一个额外的模型来建模,在传统的语音识别系统里通常是高斯混合模型(GMM),在最新的系统里使用深度神经网络来建模。
HMM的定义为:
\[\theta=(\mathcal{S},\mathcal{Y},\mathcal{A}, \mathcal{B}, \mathcal{\Pi}, \mathcal{F})\]其中:
$\mathcal{S}$:状态集
$\mathcal{Y}$:输出符号集合,可能是连续的集合
$\mathcal{A}$:状态转移矩阵,$\mathcal{A} = {a_{\sigma s}}$,$a_{\sigma s}$表示从状态$\sigma$跳转到状态$s$的概率,它满足$\sum_s a_{\sigma s}=1$。
$\mathcal{B}$:输出概率分布。$\mathcal{B} = {b_s(x)}$,$b_s(x)$表示状态s下随机变量x的概率密度函数,它满足$\int_{-\infty}^{\infty}b_s(x)dx=1$。
$\mathcal{\Pi}$,初始状态概率分布,$\mathcal{\Pi}={\pi_s}$,$\pi_s$表示初始处于状态s的概率。它满足$\sum_s\pi_s=1$
$\mathcal{F}$,终止状态的集合。
这些参数可以使用训练数据基于最大似然准则进行估计。
假设训练数据有N个utterance,$O_1^N=\{O_1,…,O_N\}$,对应的transcription是$W_1^N=\{W_1,…,W_N\}$,所有的phone的HMM的参数集合为$\Theta$,则训练数据集上的似然为:
\[L(\Theta | O_1^N, W_1^N)=\prod_{n=1}^N p(O_n|W_n;\Theta)\]其中$p(O_n \vert W_n;\Theta)$表示声学似然,它是参数$\Theta$的函数。我们也可以使用其它准则比如MMI或者MPE进行训练,这里不做展开。
在语音识别中,输出符号$Y$通常是一个连续空间的特征向量,因此对于每一个状态$s$,我们都需要一个概率密度函数$b_s(x)$来描述这个状态的输出概率(反射概率)。这种HMM叫做连续密度HMM。
计算声学似然
HMM模型的声学似然可以使用前向算法来计算。给定HMM模型$\mathcal{M}$和特征向量序列$O=o_1,o_2,…,o_T$,声学似然(也就是给定模型产生观察序列的概率)的定义为:
\[\begin{split} p(O|\mathcal{M}) & = \sum_S P(O, S| \mathcal{M}) \\ & = \sum_S \pi_{s_1}b_{s_1}(o_1) a_{s_1s_2}b_{s_2}(o_2)...a_{s_{T-1}s_T}b_{s_T}(o_T) \end{split}\]上式中$S=s_1s_2…s_T$是状态序列,其中$s_t$表示t时刻的状态。上面的公式需要遍历所有可能的状态序列,它的计算量是非常大的。因为它具有最优子结构性质,因此可以使用动态规划来求解:
\[\begin{split} \alpha(1,s) & = \pi_sb_s(o_1) \\ \alpha(t,s) & = \sum_{\sigma \in \mathcal{S}} \alpha(t-1, \sigma) a_{\sigma s}b_s(o_t) \end{split}\]前向概率$\alpha(t,s)$表示t时刻处于状态s并且观察序列为$o_1…o_t$的概率,也就是$p(o_1,…,o_t,s_t=s \vert \mathcal{M})$。最后我们可以计算似然:
\[p(O|\mathcal{M})=\sum_{s \in \mathcal{F}} \alpha(T, s)\]对于上图的HMM,前向概率会沿着下图所示的trellis进行计算。
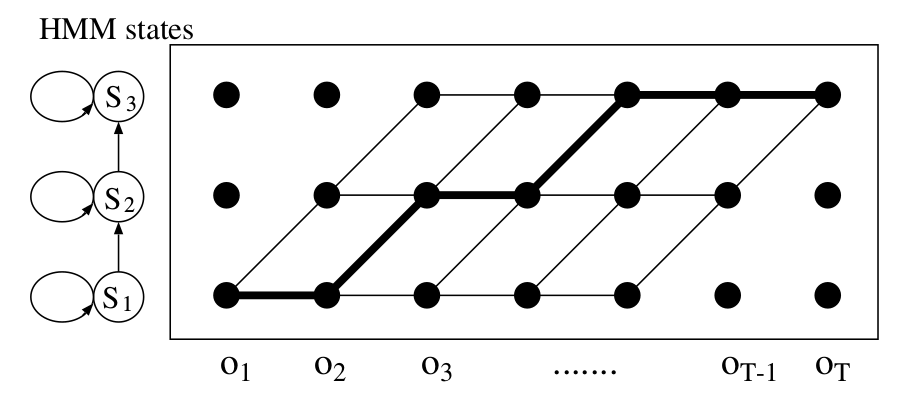 图:前向计算的Trellis
图:前向计算的Trellis
trellis表示从初始状态到终止状态的所有可能路径,每一条路径代表状态序列和特征向量序列的一种对齐方式。trellis里的每一条边代表的状态跳转概率都会计算,点上的发射概率也会计算。而$\alpha(t, s)$通过求和前一个时刻的所有状态的前向概率和跳转概率的乘积,也就是$\alpha(t-1,\sigma)a_{\sigma s}$,最后再乘以发射概率$b_s(o_t)$。
在解码时,通常使用Viterbi算法而不是前向算法。Viterbi算法只记录概率最大的路径:
\[\begin{split} \tilde{P}(O|\mathcal{M}) &=\max_S P(O,S| \mathcal{M}) \\ & = \max_S \pi_{s_1}b_{s_1}(o_1) a_{s_1s_2}b_{s_2}(o_2)...a_{s_{T-1}s_T}b_{s_T}(o_T) \end{split}\]上式和前向算法很类似,只是把$\sum$换成了max。类似的,递推公式为:
\[\begin{split} \tilde{\alpha}(1,s) & = \pi_sb_s(o_1) \\ \tilde{\alpha}(t,s) & = \max_{\sigma \in \mathcal{S}} \alpha(t-1, \sigma) a_{\sigma s}b_s(o_t) \end{split}\]以及:
\[\tilde{p}(O|\mathcal{M})=\max_{s \in \mathcal{F}} \alpha(T, s)\]其中$\tilde{\alpha}(t,s)$表示t时刻处于状态s的所有路径中概率最大的那个。$\tilde{p}(O \vert \mathcal{M})$叫做Viterbi得分。对应最大概率的路径叫做Viterbi路径。
在实际的实现时,我们通常把概率映射到log域,这样概率的相乘变成log概率的相加,这可以防止下溢。虽然Viterbi得分不是准确的似然概率,但是我们可以用它来作为近似。而且如果我们在Viterbi算法的每个$\tilde{\alpha}(t,s)$都记录max函数最大的那个状态(进来的状态),那么通过回溯我们就可以找到最优的状态序列。
输出概率分布
HMM根据状态的输出概率的类型分为离散和连续的HMM。为了使用离散的HMM建模语音单元(比如phone),我们通常需要对连续的特征进行向量量化(Vector Quantization/VQ)从而把无限的可能值变成离散的有限的值。而现在更加流行使用连续的HMM,这时每个状态对于一个连续的随机变量(向量),我们需要一个概率密度函数函数来描述它。而在语音识别里,最常见的就是多变量的高斯混合模型。
给定一个输出向量$x$,它的概率密度(不是概率,但是可以认为是未归一化的概率)为:
\[\begin{split} b_i(x) & = \sum_{m=1}^{M_i}c_{im} \mathcal{N}(x|\mu_{im}, \Sigma_{im}) \\ \mathcal{N}(x|\mu_{im}, \Sigma_{im}) & = \frac{1}{\sqrt{(2\pi)^P |\Sigma_{im}}}exp\{-\frac{1}{2}(x-\mu_{im})^T\Sigma_{im}^{-1}(x-\mu_{im})\} \end{split}\]其中$\mathcal{N}(x \vert \mu_{im}, \Sigma_{im})$是状态i的第m个高斯分量的分布,$\mu_{im}$会 $\Sigma_{im}$分别高斯分布的均值和协方差矩阵。$c_{im}$是第m个分量的混合权重(mixture weight),它满足:
\[\sum_{m=1}^{M_i}c_{im}=1\]$M_i$是第i个状态的高斯分量个数,$P$是特征(观察)向量的维数。
为了简化,我们通常假设高斯分量的每个特征是独立的,也就是协方差矩阵是对角矩阵,则上式可以简化为:
\[\mathcal{N}(x|\mu_{im}, \Sigma_{im})=\prod_{p=1}^P \frac{1}{2\pi \sigma_{imp}^2} exp\{ -\frac{(x_p-\mu_{imp})^2}{2 \sigma_{imp}^2} \}\]其中$\mu_{im}$和$\sigma_{imp}^2$是状态i的第m个高斯分量的第p维的均值和方差。$\sigma_{imp}^2$是对角协方差矩阵$\Sigma_{im}$的对角线上的第p个值。
子词(subword)建模和发音词典
给定一个词序列$W$和一个特征向量序列$O$,我们可以使用前面的前向算法或者Viterbi算法计算声学似然$P(O \vert W)$。但是可能的词序列是无穷的,我们不可能为每一个词序列都建立一个HMM模型。同样的,词的数量也非常多(通常至少几万),我们也不可能为每一个词都建立一个模型。因此在实际应用中我们使用更细粒度的子词单元,比如phone或者音节(syllable),来建立HMM模型,然后根据词和子词单元的关系,把相关的子词单元的HMM拼接起来就得到词的HMM,再把词的HMM拼接起来就得到词序列的HMM。
比如使用的是phone,那么我们需要知道一个词是怎么由phone组成的,这就是发音词典的作用。
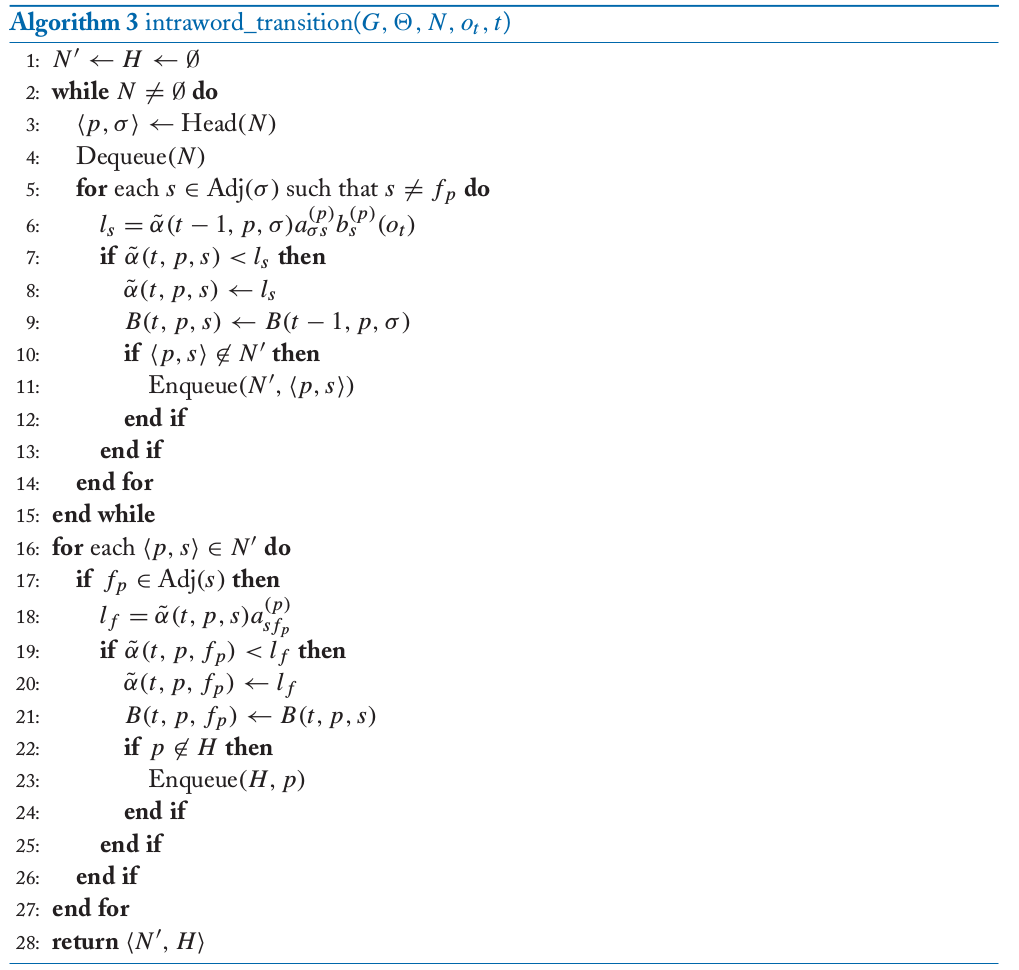
比如词”go”由/g/和/ou/两个phone组成。那么”go”的HMM就可以由这两个phone拼接起来,如下图所示:
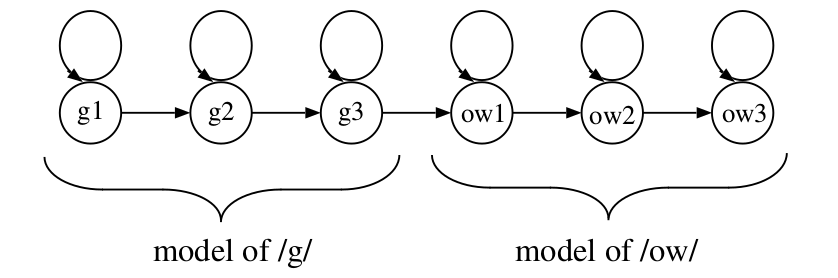 图:go的HMM由子词单元/g/和/ow/的HMM拼接起来
图:go的HMM由子词单元/g/和/ow/的HMM拼接起来
有了上面的HMM,我们就可以计算$p(O \vert W =”go”)$了。
下图是”go”的HMM在计算某个特征向量序列概率时的trellis,图中粗线是Viterbi路径。因为我们知道状态属于哪一个phone,因此我们通过Viterbi路径估计phone的边界。比如在下图的虚线所示,第6帧和第7帧是区分/g/和/ou/的最可能边界。因此拼接的HMM使用Viterbi算法可以自动得到语音的对齐(所谓的force alignment),也就是知道每一帧属于哪个phone。
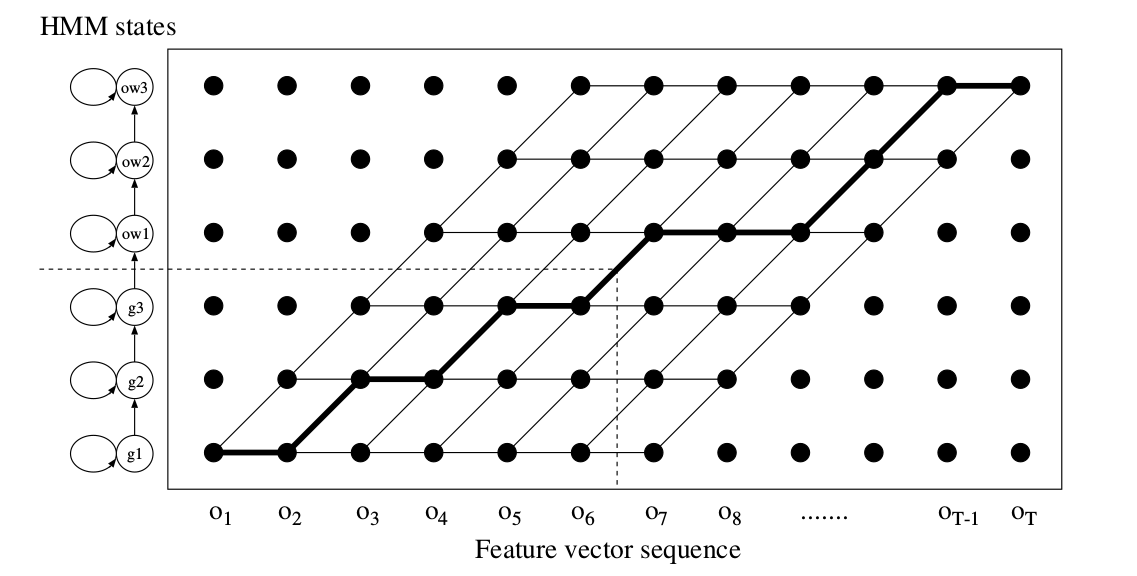 图:go的HMM的Trellis
图:go的HMM的Trellis
上下文相关的phone建模
对于声学模型建模来说,寻找字词(subword)单元是一个由来已久的问题。目前,上下文相关的(context-dependent)phone模型是最广为使用并且非常游戏的方法。一个phone的声学特征并不是稳定的,它是受其前后其它的phone的影响的,这就是所谓的协同发音(coarticulation)。比如在sketch (/s k eh ch/)和fox (/f ao k s/)里的k的发音是不同的。因此一个phone会有很多发音变体(allophone),它是受上下文影响的。使用上下文相关phone的HMM模型是建模一个phone的发音变体的一种有效方法。
一个上下文相关的phone可以写成(s)k(eh),它表示k的左边是/s/而右边是/eh/。对于这种依赖前面和后面各一个phone的叫做triphone。因此也词”hello”包含(sil)h(ae)、(h)ae(l)、(ae)l(ou)、(l)ou(sil)这4个triphone,我们这里假设词的开始和结束都有silence(/sil/)。因为”hello”前面和后面可能还有其它的词,因此(sil)h(ae)可能要改成前一个词最后的phone;类似的可能需要把(l)ou(sil)的sil改成下一个词开始的phone。这种能跨越词边界的triphone叫做cross-word triphone。虽然cross-word triphone增加了模型的复杂度,但是它能够得到更好的识别结果。
在使用上下文相关的模型时,参数共享(parameter tying)是很常见的技巧。上下文相关的phone的数量会比上下文无关的phone多很多。比如假设我们有40个phone,那么理论上有$40^3=64,000$个可能的triphone。虽然训练数据里不会出现所有的triphone,但出现的triphone的数量仍然会很大。此外还会有一些没有在训练数据中出现的triphone会出现在测试数据中。
Tied-state triphone模型可以让一些状态共享输出概率(pdf)。我们可以使用phone决策树来把triphone聚类到树的叶子节点,而且没见过的triphone最终也会落到某个叶子节点上,从而可以解决训练数据中未见过的triphone的问题。
在构建决策树之前,我们需要基于语音学准备一些yes-no的问题。比如“它的左边是否是一个元音”、“它的右边是否鼻音”等等。然后使用如下图所示的决策树算法来分裂。
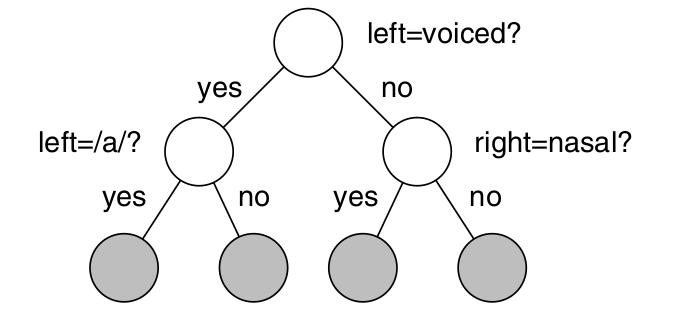 图:Phonetic决策树
图:Phonetic决策树
首先是把中心phone相同的triphone都放在树根,然后从所有的问题里选择一个问题——这个问题可以让训练数据的似然概率最大。从而把一个节点分裂成两个子节点。这个过程会持续下去,直到似然概率不再增长或者树的节点树足够多。
最后每一个triphone都会落在某个叶子节点里,也就是每个叶子节点就是一个聚类,同一个聚类里的triphone的pdf是共享的,通常我们用一个GMM来建模这个pdf。
语言模型
语言模型用于定义语音识别引擎可以识别的词序列(哪些词序列是合乎语法的,哪些不符合),有些语言模型还可以给不同的词序列不同的概率。这个概率表明某个词序列出现的可能性。使用了语言模型之后,哪些不合法语法或者概率很低(不太可能出现)的词序列就可以在解码的时候被排除掉。
有限状态文法(Finite State Grammar)
如果我们可以非常置信的预测系统可能说的内容,那么我们可以手动设计语言模型。有限状态文法(Finite-State Grammar/FSG)是一种常用的手动设计文法的工具。有很多中表示FSG的方法。比如,把每一个词当成一个状态,下一个词表示为边。下图展示了一个FSG的例子,这是一个用于控制机器人的语音指令的语言模型,它的每个点表示一个词,而点之间的有向边表示可能的状态跳转。没有标签的节点表示空状态。最左边的点表示初始状态而双圆圈的节点表示结束状态。上面的文法可以识别”go straight and turn left.”。因此FSG很适合在较小的任务里。
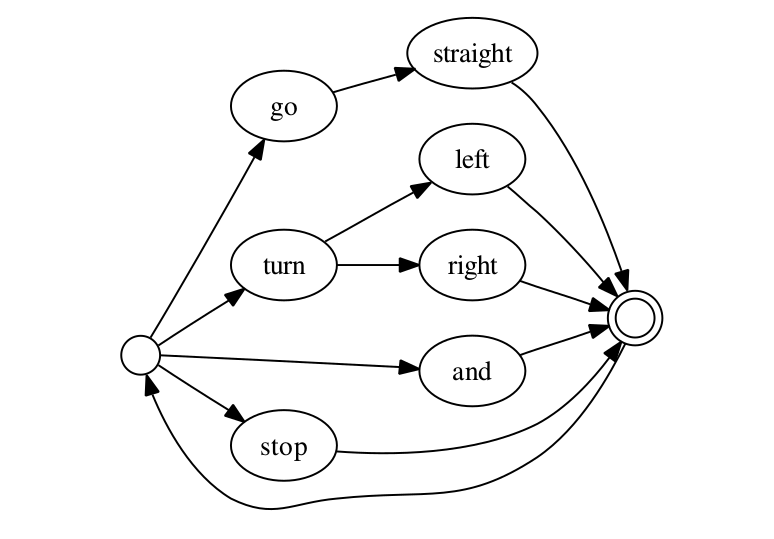 图:有限状态文法
图:有限状态文法
另外一种FSG的表示方法把词标签放到边上。这两种方法是等价的并且可以互相转换。
N-gram模型
我们通常需要识别的词汇量都非常大,而且语音识别的文字都是口语化的文字,因此很多的句子并不符合语法,所有很多因此手工设计文法是不可能的。因此我们更常用的是统计语言模型,而n-gram语言模型是最常用的统计语言模型。
N-gram表示连续出现的n个词,对于最常见的1-gram、2-gram和3-gram,我们特意给它们起名为uni-gram、bi-gram和tri-gram。在语音识别系统里,我们使用的n通常是3或者4。
假设一个长度为M的词序列为$w_1,w_2,…,w_M$,我们把它记为$w_1^M$,它其中的从i开始到j结束(包含j)的子序列记为$w_i^j$。给定$w_1^M$,它的概率可以表示为条件概率的乘积:
\[\begin{split} P(W) &= P(w_1)P(w_2|w_1)...P(w_M|w_1^{M-1}) \\ &= \prod_{m=1}^MP(w_m|w_1^{m-1}) \end{split}\]在n-gram模型里,概率$P(w_m \vert w_1^{m-1})$可以近似为$P(w_m \vert w_{m-n+1}^{m-1})$,也就是第m个词只依赖与之前的n-1个词。注意:如果$m-n+1<1$,比如$P(w_1 \vert w_{-1}w_0)$,则我们把下标小于1的词去掉,也就是变成$P(w_1)$。因此,上式可以近似为:
\[P(W) \approx \prod_{m=1}^MP(w_m|w_{m-n+1}^{m-1})\]n-gram模型可以看做是n-1阶的马尔科夫模型,它的每个状态只依赖于之前的n-1个时刻,而与更久之前的历史无关。
假设$w_1^n$表示一个n-gram $w_1,…,w_n$,那么我们可以这样最大似然估计条件概率$P(w_n \vert w_1^{n-1})$:
\[P(w_n \vert w_1^{n-1}) = \frac{C(w_1^{n})}{C(w_1^{n-1})}\]上式中$C(w_1^{n})$表示n-gram $w_1^{n}$出现的次数,而$C(w_1^{n-1})$表示(n-1)-gram $w_1^{n-1}$出现的次数。
如果某个n-gram在训练数据里没有出现,则它的概率就为零。但是没在训练数据中出现并不代表它不可能在实际(测试)数据中出现,因此n-gram的一个很大的问题就是怎么做平滑——让训练数据里没有出现的n-gram也有一定的概率。
回退平滑(backoff smoothing)
回退平滑是一种平滑技术,它可以把训练数据中出现的n-gram的一部分概率让出来给没见过的n-gram。那这部分多出来的概率怎么分配呢?回退平滑的想法就是按照退化后的n-gram概率分配。比如$P(w_3 \vert w_1w_2)$和$P(w_4 \vert w_1w_2)$在训练数据中都没有出现过,又假设其它的3-gram都出现过,并且它们让出0.001的概率给这两个3-gram,那么它们两个怎么分配这0.001的概率呢?一种方法当然是平分,但是这并不好,回退的思想是用$P(w_3 \vert w_2)$和$P(w_4 \vert w_2)$来比例来分配,比如$P(w_3 \vert w_2)$是0.01而$P(w_4 \vert w_2)$是0.02,则它们应该按照1:2的比例来分配0.001的概率。
回退平滑的计算公式为:
\[P(w_n|w_1^{n-1})=\begin{cases}P^*(w_n|w_1^{n-1}) \;\; \text{if }C(w_1^{n-1})>0 \\ \alpha(w_1^{n-1}) P(w_n|w_2^{n-1}) \text{ if }C(w_1^{n-1})=0\end{cases}\]上式中$P^*(w_n \vert w_1^{n-1})$是打折后的概率,也就是对于训练数据中出现过的n-gram的最大似然概率打一些折扣,多出来的概率让那些没出现的来分。$\alpha(w_1^{n-1})$是回退的概率,它可以这样计算:
\[\alpha(w_1^{n-1})=\frac{1-\underset{w_n:C(w_n)>0}{\sum} P^*(w_n|w_1^{n-1})}{1-\underset{w_n:C(w_n)=0}{\sum}P^*(w_n|w_2^{n-1})}\]最后一个问题就是怎么样打折,这里简单介绍Good-Turing打折,它的计算方法为:
\[P^*(w_n|w_1^{n-1})=\frac{C^*(w_1^{n})}{C(w_1^{n-1})}\]其中打折的计算$C^*(w_1^{n})$的计算方法为:
\[C^*(x)=(C(x)+1) \frac{N_{C(x)+1}}{N_{C(x)}}\]其中$N_r$表示出现次数为r的n-gram的个数。
举个例子,比如训练数据中abc出现了4次,那么原始的C(abc)=4。而在Good-Turing里\(C^*(abc)=(4+1) \frac{N_5}{N_4}\),其中$N_5$表示出现了5次的n-gram的个数,而$N_4$表示出现了4次的n-gram的次数(当然abc会为$N_4$贡献一分)。
解码器
解码器是一个程序,它根据公式使用声学模型和语言模型在搜索空间里寻找最可能的词序列$\hat{W}$。直接搜索是不可行的,因为搜索空间太大:我们需要遍历所有的词序列W,计算$P(W)$和$P(O \vert W)$。在实践中,极为高效的一趟的Viterbi算法被广泛使用。
连续语音识别的Viterbi算法
假设句子W由$M_W$个词组成,$W=w_1…w_{M_W}$。则:
\[\begin{split} \hat{W} &= \underset{W \in \mathcal{W}}{argmax}\left \{\sum_{S \in \mathcal{S}_W}p(O, S|W )P (W ) \right \} \\ &= \underset{W \in \mathcal{W}}{argmax} \left \{\sum_{S \in \mathcal{S}_W} \prod_{m=1}^{M_W} p(o_{t_{m-1}+1}^{t_m}, s_{t_{m-1}+1}^{t_m}|w_m)P(w_m|w_1^{m-1}) \right \} \end{split}\]其中$p(o_t^\tau , s_t^\tau \vert w)$表示词w沿着状态序列$s_t…s_\tau$生成语音片段$o_t…o_\tau$的概率。$S_W$表示词序列W可以对应的所有合法的状态序列。$t_m$表示词$w_m$对应的观察的最后一帧的下标,因此$t_{m-1}+1…t_m$是$w_m$对应的全部观察序列。这当然也要求$t_m$是$w_m$对应的HMM的终止状态,而$t_{m-1}+1$是HMM的初始状态。
我们可以使用Viterbi概率来近似上式中大括号里的概率,这样可以把求和变成max:
\[\begin{split} \hat{W} &= \underset{W \in \mathcal{W}}{argmax}\left \{\sum_{S \in \mathcal{S}_W}p(O, S|W )P (W ) \right \} \\ &= \underset{W \in \mathcal{W}}{argmax} \left \{\underset{S \in \mathcal{S}_W}{max} \prod_{m=1}^{M_W} p(o_{t_{m-1}+1}^{t_m}, s_{t_{m-1}+1}^{t_m}|w_m)P(w_m|w_1^{m-1}) \right \} \\ &= \underset{W \in \mathcal{W}}{argmax} \left \{\underset{T \in \mathcal{T}_W}{max} \prod_{m=1}^{M_W} \tilde{p}(o_{t_{m-1}+1}^{t_m}|w_m)P(w_m|w_1^{m-1}) \right \} \end{split}\]其中\(\mathcal{T}_W\)代表词序列W的所有可能的结束帧的序列(或者间接的表示了一种对齐方式)。也就是说\(T \in \mathcal{T}_W\)是一个时间序列$t_1…t_{M_W}$,表示了词序列$w_1…w_{M_W}$每一个词的最后一帧的时间。
之前我们介绍过的Viterbi算法可以高效的计算一个词的最优状态序列及其概率。但是上式的max是对所有词,也就是需要遍历所有可能的词序列。为了避免遍历,可以扩展之前的Viterbi算法,在词之间(inter-word)增加状态跳转,并且这个跳转会把语言模型的得分编码进去。词间能否跳转可以使用FSG这样的语言模型来定义,此外n-gram语言模型也可以认为是带概率的FSG(PFSG),因此也是可以的。
这个HMM大致有$\vert \bar{\mathcal{S}} \vert \times \vert \mathcal{Q} \vert$个状态,其中$\vert \bar{\mathcal{S}} \vert$是每个词的HMM的平均状态数,而$\vert \mathcal{Q} \vert$是FSG的状态数。我们可以任务FSG里每一个状态就是一个词,状态之间的边表示可以从一个词跳到另一个词(如果是PFSG则还有一个概率),我们把每个状态展开成这个词对应的HMM,就得到了大的HMM。
一个PFSG是一个7-元组:
\[G = (\mathcal{Q} , \mathcal{V} , \mathcal{E} , \mathcal{I} , \mathcal{F} , P , \pi)\]其中:
- $\mathcal{Q}$是状态集合
- $\mathcal{V}$是词典,也就是词的集合
- $\mathcal{E} \subseteq \mathcal{Q} \times \mathcal{Q}$是状态转移集合
- $\mathcal{I} \subseteq \mathcal{Q}$是初始状态集合
- $\mathcal{F} \subseteq \mathcal{Q}$是终止状态集合
- $P: \mathcal{Q} \times \mathcal{Q} \rightarrow [0, 1]$,状态转移概率函数
- $\pi: \mathcal{I} \rightarrow [0,1]$是初始状态概率分布函数
如果G是bigram语言模型,则每个状态是一个词。假设状态$p_w$代表词w的状态。则初始概率$\pi(p_w)$等于unigram概率$P(w)$。状态转移概率$P(p_w \vert p_v)$等于bigram概率$p(w \vert v)$。而对于trigram模型,每个状态是对应一个词对(两个词的history),而边上的跳转概率对应trigram概率。
现在我们来看连续语音识别的Viterbi算法,假设grammar为G而观察序列$O=o_1…o_T$。这里G的每个状态都可以展开为对应词的HMM,而词的HMM有可以由子词单元的HMM拼接起来(比如不考虑上下文时一个词可以根据发音词典得到phone的序列,而每个phone是一个HMM,拼接起来就得到词的HMM),如上图所示。
为了便于拼接,我们假设每个词的HMM模型有唯一的一个特殊开始状态和一个特殊结束状态。假设词p的HMM为$\theta_p=(\mathcal{S}_p,\mathcal{Y}_p,\mathcal{A}_p,\mathcal{B}_p,\Pi_p,\mathcal{F}_p)$。
其中\(\mathcal{A}_p=\{ a_{\sigma,s}^{(p)} \vert \sigma, s \in \mathcal{S}_p \}\)、\(\mathcal{B}_p=\{b_s(o)^{(p)} \vert s \in \mathcal{S}_p, o \in \mathcal{Y}_p\}\)以及\(\Pi_p=\{ \pi_s^{(p)} \vert s \in \mathcal{S}_p \}\)。我们把新增的开始和终止状态记为$i_p$和$f_p$,这个词的HMM对应Grammar的一个状态。此外,对于任意的\(s \in \mathcal{S}_p\),我们还引入状态转移概率$a_{i_ps}$和$a_{sf_p}$,分别表示从初始状态跳到s的概率以及s跳到终止状态的概率。对于空的(null)的状态,没有对应的HMM模型,但是我们假设它包含一个特殊的HMM——直接从初始状态$i_p$跳到结束状态$f_p$。
假设使用上图的FSG时,则完整的搜索网络如下图所示,它把FSM的每个状态(词)都展开成对应的HMM。
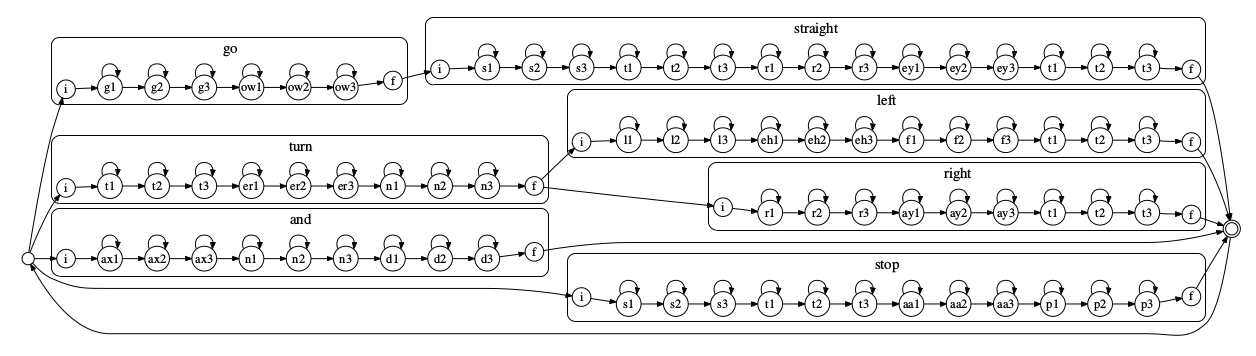 图:用于解码的搜索网络
图:用于解码的搜索网络
有了上图的解码网络(Decoding Graph)之后,我们就可以使用一趟的Viterbi算法来搜索最可能的utterance。这个算法也叫时间同步的Viterbi搜索(time-synchronous Viterbi search)算法,它是通过时间同步的方式计算如下量从而实现解码:
- $\tilde{\alpha}(t,p,s)$
- 到第t帧时,Grammar状态为p并且HMM状态为s的条件下,不完整路径的Viterbi得分。
- $B(t,p,s)$
- 一个回溯用的指针,记录t时刻处于Grammar状态p并且HMM状态s时的最可能的词序列。$B(t,p,s)$的内容是一个pair $<\tau,q>$,其中$\tau$是Grammar状态p(词)的开始帧,而q是最优状态序列里当前状态(词)之前的状态(词)。如果当前状态是第一个状态,则q=0。
计算到最后一帧之后就能通过回溯指针找到最可能的词序列。下面我们详细介绍这个计算过程。先介绍几个记号,$\text{Adj}(s)$表示状态s可以跳到的状态集合;$\text{word}(p)$表示Grammar状态p对应的词。
第一步:初始化
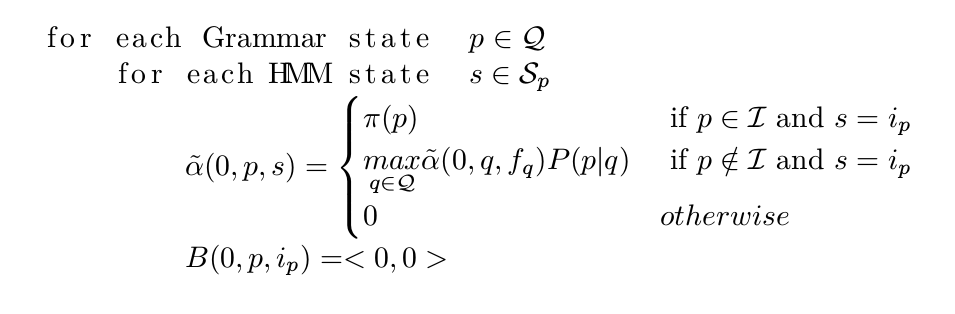 图:初始化代码
图:初始化代码
这一步的作用是初始化Viterbi得分和回溯指针。在0时刻,如果一个Grammar状态$p \in \mathcal{I}$并且s是p的初始状态$i_p$,则它的概率是$\pi(p)$。此外,如果某个Grammar状态p虽然不是初始状态,但是如果存在一个空的HMM q【$\tilde{\alpha}(0, q, f_q) \ne 0$,说明它的开始状态直接跳到结束状态,因此是空的HMM】,可以由q跳转到p,则它的初始HMM状态s也是有概率的。其它的情况(s不是HMM初始状态或者p不是Grammar的初始状态并且p也不能由Grammar的初始状态跳过去)其概率都是0。注意:$\hat{\alpha}$的计算要按照拓扑顺序来计算,如果p依赖于q,则$\tilde{\alpha}(0,q,i_q)$需要先计算出来,当然这也要求依赖是不会循环的(有向无环图)。所有的回溯指针都是<0,0>,它表示当前词的开始帧是第一帧(0)并且之前没有词了。
第二步:时间同步的处理
代码如下:

这一步进行时间同步的Viterbi得分计算和回溯指针更新。在每一个时刻t,分别处理词内和词间的跳转。词内的跳转的计算为:变量t-1时刻的所有$\tilde{\alpha}(t-1, p, \sigma)$,然后找出概率最大的哪个$\sigma$。而回溯指针复制最大的那个$\sigma$对于的内容,原因是目前仍然还是当前词(p),所以词开始的时刻以及p之前的那个词都和$B(t-1,p,\sigma^{max})$一样。而计算完t时刻之后,它有可能进入结束状态,因此我们遍历所有非结束状态$s \in (\mathcal{S}_p -{f_p})$,然后计算从这个状态跳到$f_p$的最大的概率,而回溯指针只是复制$B(t,p,s^{max})$。
根据上面第二步的计算,t时刻有可能进入$f_p$,因此就可能从$f_p$跳到一个新的Grammar状态(词)q的$q_i$,这就是词间的跳转。
词间的跳转会从上一个状态q的结束状态跳到p的初始状态(这里的记号p和q和前面是相反的),也就是$\tilde{\alpha}(t,p,i_p)$。$P(p \vert q)$是Grammar的跳转概率(比如bigram就是$P(p\vert q)$,如果是trigram则q表示之前两个词)。注意回溯指针$B(t,p,i_p)=<t,q^{max}>$,这相对于开始一个新的词,因此tuple的第一个是t,表示新词的开始时刻是t,而上一个词就是$q^{max}$。
第三步:结束
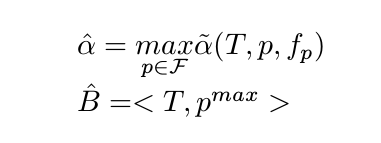
最后一个时刻T,我们选择得分最高的$\tilde{\alpha}(T,p,f_p)$,然后回溯指针是$<T,p^{max}>$。
第四步:回溯
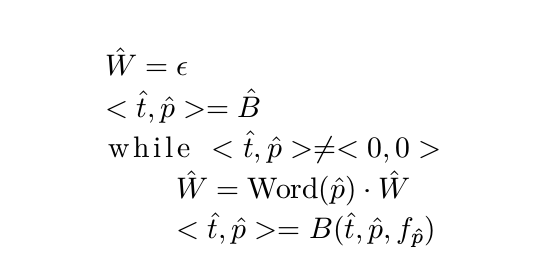
最后是回溯得到最优路径里的所有Grammar状态(词),从而得到最可能的utterance。其中$\text{Word}(\hat{p})$是得到一个Grammar状态对应的词的函数。
时间同步的Viterbi Beam搜索算法
虽然上面的算法不需要遍历所有的词序列,但是它的复杂度是$O(\vert \bar{\mathcal{S}} \vert^2 \times \vert \mathcal{Q} \vert^2 \times T)$,在大规模连续语音识别系统里,$\vert \mathcal{Q} \vert$通常非常大,因此还需要其它的办法进一步减少计算量。Beam搜索技术就是一种常见的减少计算量的方法。它在每一个时刻t都会计算到目前为止最高的得分:
\[L_t^{max}=\underset{p \in \mathcal{Q}, s \in \mathcal{S}_p}{max}\tilde{\alpha}(t,p,s)\]这个值会用来剪裁掉目前为止不太有希望(得分太低)的路径。也就是如果$\tilde{\alpha}(t,p,s)$小于$\gamma L_t^{max}$,则把这条路径标注视为不活跃(inactive),在下一帧的处理时禁止从不活跃的状态跳出。这里假设超参数$0< \gamma <1$。因为概率一般是在log空间里计算的,因此最小的得分为$log L_t^{max}-\eta$,其中$\eta=-log \gamma$,我们通常把$\eta$叫做beam width。除此之外,还有一种裁剪方法是值保留得分最高的K条路径,K也叫作beam width。我们甚至可以把两者结合起来:最多选择K条路径,但是如果K条路径里还有小于$log L_t^{max}-\eta$的路径,还是去掉。beam width需要选择合适的值,太大了就裁剪的过少,从而没有降低计算量;而太小了可能会把最优的路径过早的裁剪掉,从而找到次优解。
如果在时间同步的Viterbi算法里使用Beam裁剪,需要高效的处理不活跃路径。这种算法就是时间同步的Viterbi Beam搜索算法(time-synchronous Viterbi beam search)。
算法1

算法1和前面的时间同步的Viterbi算法基本一样。但是活跃/不活跃的状态使用队列来高效的处理。N是一个队列,其元素是活跃的<Grammar状态,HMM状态>的pair。第一行,使用算法2将初始状态对插入N。H是活跃Grammar状态的队列,这个队列包含在跨词的跳转处理时需要考虑的状态(也就是有处于终止HMM状态的Grammar状态)。$H_F$是活跃的进入终止Grammar状态的队列。队列的顺序是随意的(不要求先入先出或者优先队列),但是如果H是拓扑排序的,则计算Grammar空状态的跳转的工作量是最小的。
第二行,词间的跳转是从初始状态通过空状态来产生的。第3到7行对于每一帧都进行状态的跳转,包括词内的跳转和词间的跳转以及剪枝。第8行通过回溯得到最可能的词序列$\hat{W}$。接下来我们介绍里面的每一步。
算法2

算法2进行Viterbi搜索的初始化。第1行队列N和H都初始化为空。第3和4行把初始Grammar状态和初始HMM状态在第0帧的概率初始化为$\pi(p)$,回溯指针为空。如果Grammar状态p不是空,则把pair $<p, i_p>$插入N,如果p是空状态,它马上会跨词的跳到新的状态,因此把p插入H。
算法3
算法3处理每一帧的词内跳转。第1行队列N’和H初始化为空。第2-15行,对于活跃队列N里的$<p, \sigma>$对,遍历$\sigma$它的后续非终止状态s,然后计算$\tilde{\alpha}(t,p,s)$。如果这个得分比之前大(因为可能有多条路径最终进入<p,s>),则把<p,s>加到活跃队列N’里。
第16-27行处理到终止状态的跳转,它遍历N’里的所有活跃的状态s(对应的Grammar状态为p),如果s可以跳到终止状态$f_p$,那么更新$\tilde{\alpha}(t,p,f_p)$。如果这个得分比之前大,则把p加到H里,说明H可以在后面的词间跳转用到(因为有$<p,f_p>$了,所以可能可以从$<p,f_p>$跳到某个$<q,i_q>$)。
最后把N’和H返回。
算法4

算法4处理词间的跳转,也就是Grammar级别的状态跳转。上面算法3得到的H是所有可以进入终止HMM状态的Grammar状态集合。因此算法遍历H中的所有状态q,然后尝试词间跳转$P(p \vert q)$,这需要计算$\tilde{\alpha}(t, q, f_q )P(p \vert q)$,使用它来更新$\tilde{\alpha}(t, p, i_p)$。如果p不是空HMM($Word(p) \ne \epsilon$),则把$<p,i_p>$加入活跃状态集合H,否则说明p马上还要再词间跳转到新的Grammar状态,因此把p加入H。最后检查q是不是Grammar状态的终止状态,如果是的话把它加入$H_F$,说明如果t是最终时刻T,则可以输出结果了(如果到最终时刻T时,活跃状态<p,s>能输出的条件是$s=p_f$并且p是Grammar的终止状态)。
最终返回N和$H_F$。注意:这个函数会修改N,往里面加入通过词间跳转得到的新的活跃状态对$<p, p_i>$。
算法5

算法5裁剪掉不太有希望的活跃状态。首先计算所有活跃状态对里得分最高的$L_t^{max}$,然后把当前得分$\tilde{\alpha}(t, p, s) < \gamma L_t^{max}$的状态对<p,s>从N中删除掉。
算法6
算法6处理最后的T时刻完成后的最优路径,它通过从$H_F$里选择有可能出得分最高的$\tilde{\alpha}(T, q, f_q)$,返回<T, q>。
算法7

算法7通过回溯找到最可能的词序列,这和前面没有Beam Search的完全一样。
LVCSR里的一些实用技巧
上面介绍的时间同步的Viterbi beam搜索算法是一个解决连续语音识别的通用算法。但是把它应用到实际的LVCSR时,我们会面临计算量和搜索错误的很多问题。下面我们介绍这些问题并且给出一些解决方法。
在大部分LVCSR系统里的Grammar都使用n-gram语言模型。n-gram语言模型基本上允许任何词之间的连接(跳转)。因此从一个Grammar状态出去的边等于词典大小,比如65k。这样从每个词(Grammar)的HMM的终止状态到另一个词的初始状态的边的增多会导致活跃的状态极大的增加。这样使用Beam搜索很难减少活跃的状态,因为这些初始状态的Viterbi得分的差别只是n-gram的跳转概率,这会存在很多得分一样的活跃状态。
一种解决办法是使用发音前缀树(pronunciation prefix tree)。因为在大规模的词典里很多词的发音前缀是相同的,通过在搜索网络里共享这些前缀可以减少跳出边的数量。假设一个词典包含”start”、”stop”、”straight”和”go”。则发音前缀树如下图所示。
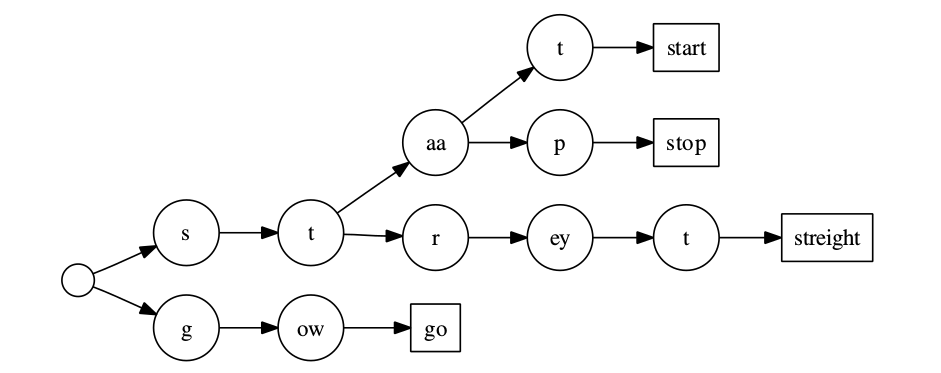 图:发音前缀树
图:发音前缀树
在搜索网络里,每一个节点都是一个phone(比如s、t和aa等)的HMM,也叶子节点链接回根节点。图中的每个长方形节点是HMM的终止状态,它用于确定从树根到叶子节点的这条路径对应哪个词(而前面不共享前缀在跳转的时候就知道是哪个词了)。通过引入这种树形结构,每个HMM状态的出边数量最多就是phone的数量,这远远小于词典的大小。因此发音前缀树能极大的在Beam搜索里减少活跃节点的数量。
但是使用前缀树也会带来一个问题:我们只有到了叶子节点的时候才知道是哪个词(而不使用的话跳转后就知道了)。因为Grammar状态跳转必须要延迟到叶子节点才能进行,因此我们需要用每一个Grammar状态来关联这棵树。对于n-gram语言模型,需要$\vert V \vert^{n-1}$棵树,而且它们都依赖于前n-1个词的历史。下图展示了一个词典只有${u,v,w}$的bigram语言模型的前缀树搜索网络。
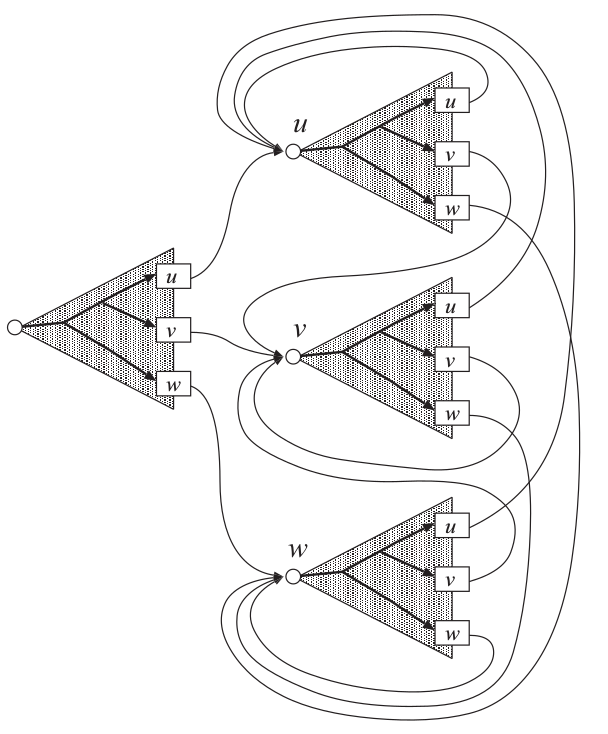 图:bigram的搜索网络
图:bigram的搜索网络
这棵树的左边是unigram树, 在Viterbi搜索的时候它会首先成为活跃节点。然后随着时间的后移,它的叶子节点变成活跃节点,从而部分识别到这个词(unigram)。接着会从这个词的终止状态跳到下一个词(目前还不知道)的初始状态,也就是跳到右边的三个棵树里,这里每棵树都代表了bigram的前一个词是什么,然后再随着时间的后移到叶子节点,识别出一个新的词得到一个bigram的跳转。最后根据叶子节点到底是u、v还是w分别跳转到对应的三棵树上。细心的读者可以会奇怪:这使得边反而增多了($\vert V \vert^n$),那为什么还要用前缀树呢?
虽然边增多了,但是这种树状的结构在Viterbi Beam搜索时非常高效,可以极大减少活跃的节点数。当然它的缺点就是存储这个搜索网络的空间变大了。我们无法把整个网络一次性放到内存里,所以解决办法就是增量的构造这个搜索网络,在需要的时候on-the-fly的构造搜索网络。当然这解决了内存的问题,但是每次都重新构造网络也会带来很多不必要的overhead开销。
为了解决这个问题,可以在网络里引入back-off跳转(后面在构造n-gram的WFST也会用到类似的技巧)。如果在训练数据中没有出现某个bigram,则这两个词直接的跳转是回退得到的概率,那么可以跳到一个unigram的状态。对于bigram,不使用这个技巧的可能跳转为$\vert V \vert^2$,而实际训练数据中很多词的组合是不会出现的,因此可以极大的减少边的数量。引入back-off跳转的搜索网络示例如下图所示。
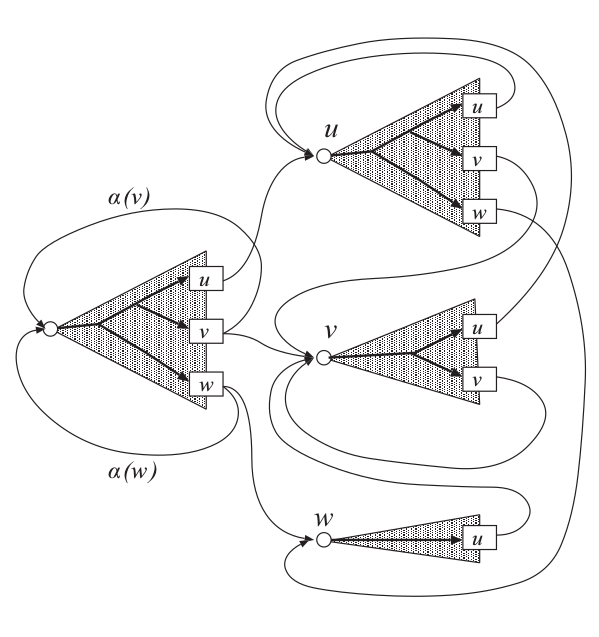 图:有back-off跳转的bigram的搜索网络
图:有back-off跳转的bigram的搜索网络
上图的bigram没有$P(w|v), P(v|w), P(w|w)$,因此我们看到w只能跳到u,如果它想跳到w或者v的话,它只能通过back-off跳转跳到unigram的树根。如果读者还是不太能理解back-off的话请先理解N-gram的回退、语言模型教程之后再来阅读本段内容。
但是这又带来一个新的问题(有点像程序员修复一个bug又引入一个新的bug):即使某个n-gram在训练数据中出现过,它也可以使用back-off,也就是说存在两条路径得到同一个n-gram。比如上图中,如果$P(u|v) < \alpha(v)P(u)$(当然通常回退的概率要小于非回退的概率,但是也不排除这种可能性),则即使bigram $P(u \vert v)$存在,搜索算法也会寻找得分更高的路径$\alpha(v)P(u)$。虽说$P(u|v) > \alpha(v)P(u)$通常是成立的,从而最终识别的文字是正确的,但是两条路径的得分加上去也会让得分有一些问题。
前面的算法3和算法4必须扩展此案使用基于前缀树的搜索网络。原因是每个Grammar状态有一棵前缀树,但是这棵树对应的不是一个词的HMM(而是这个history的很多词)。这棵树有多个HMM的终止状态,每个都对应一个词。这种情况下,我们必须在词内(inter-word)的函数里考虑从每一个终止状态到初始(树根)HMM状态的跳转。在这个初始状态里,需要选择最大的得分。本文不会详细介绍基于前缀树的搜索算法,感兴趣的读者可以参考A word graph algorithm for large vocabulary continuous speech recognition。
另外一个问题就是n-gram的概率要到叶子节点才能知道。这可能会导致裁剪的错误。通常来说,在Beam搜索的时候越早把语言模型得分加进去越好,因为解码器可以尽快找到有希望的路径而把它们作为候选路径。因为在到底叶子节点之前无法确定哪个词从而加入正确的语言模型得分,一个look-ahead的得分通常用来近似真实的得分。一种计算方法是:计算当前节点可以到达的最大的n-gram概率。这可以在每个跳转上带上一个分解的(factored)语言模型得分。对于history为h的前缀树,从节点i到节点j的分解得分为:
\[P(j|i,h)=\frac{max_{w \in \Omega(j)}P(w|h)}{max_{v \in \Omega(i)}P(v|h)}\]其中,$\Omega(j)$表示从j可以到达的词(叶子)。从树根到叶子节点的累加的分解得分等于对应叶子节点的语言模型得分。
上下文相关(context dependent)phone的搜索网络
前面提到过,上下文相关的phone模型在合成词的模型时要保证上下文信息的正确性。发音前缀树在构造的时候也需要考虑每个phone节点是上下文相关的并且彼此之间需要一致。下图展示了一个示例的triphone的前缀树,它的前一个词是start。
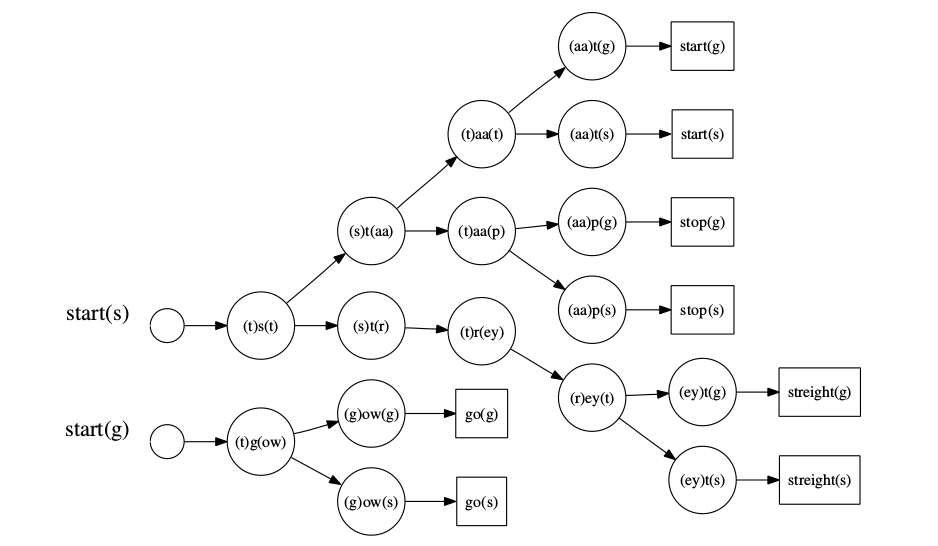 图:基于triphone的发音前缀树,它的前一个词是start
图:基于triphone的发音前缀树,它的前一个词是start
图中每个节点都是一个triphone,也就是说它依赖与之前和之后的一个phone。如上图所示,根节点和叶子节点也都依赖上下文,即前一个词的结束的phone和下一个词开始的phone。在处理词间跳转的时候,解码器需要正确的处理phone的上下文依赖。
start(g)表示history为start,并且它的下一个词的phone是g的前缀树。比如”start go go go”,start后面是g(go)。因此第一个是(t)g(ow),t是start的最后一个t,(t)g(ow)是从前一个词start跳过来的。接着是(g)ow(g),进入叶子节点go(g),它表示叶子节点是词go,并且下一个词的开始phone是g。另外一条路径是(t)g(ow)->(g)ow(s),它进入叶子节点go(s),它对应的可能词序列是”start go streight”。
Lattice生成和N-Best搜索
前面介绍的Viterbi搜索可以找到最可能的词序列。但是有时候我们需要找到多个比较可能的序列而不是仅仅一个。因为语音信号是有歧义的,仅凭声学和语言模型得分很难避免语音识别错误。因此,如果语音识别系统能输出多个高分的序列,应用可以使用额外的信息(比如当前app的状态或者对话的主题)选择更可能的词序列。
此外,多个假设(hypothese)输出在多趟(multi-pass)解码、区分性(discriminative)训练、无监督的自适应和置信度估计都需要多个输出。在多趟解码时,首先用简单的模型计算多个可能的候选路径,然后再使用更复杂的模型在这些候选里挑选最可能的路径。在区分性训练里,多个高得分的路径用于计算loss,它表示识别错误的风险大小。在无监督的自适应里,多个路径会被当着参考的transcript来微调模型参数。在实践中发现使用多个假设比使用最高分的假设的效果要好。在置信度估计时最优路径的得分和其它较优路径得分的比值可以看做一种置信度。
因为多个假设输出有这么多应用,所以它是语音识别引擎最重要的功能之一。
多个假设的输出通常用word lattice或者N-best列表来表示。N-best列表就是N条最有可能的路径的列表,它们的得分是从高到底降序排列。wordlattice是一个有向无环图,图的每一条边表示一个词而点表示带时间信息的词边界(word boundary)。从初始节点到终止节点的路径就对应一个词序列的输出,因此这个有向无环图有多条路径也就是多个输出。下图是word lattice和N-best列表的示例。
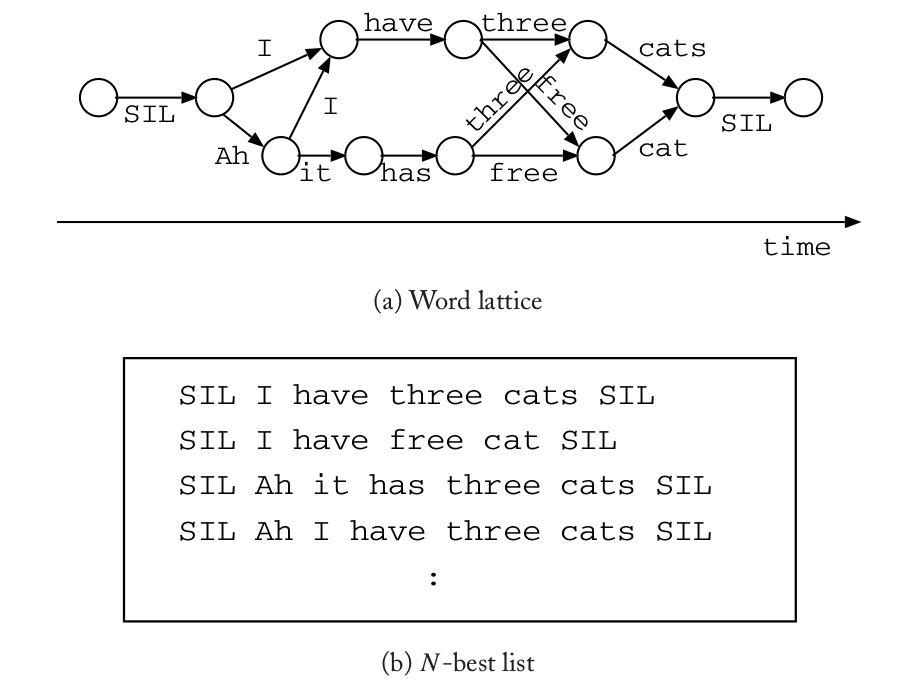 图:word lattice和N-best示例
图:word lattice和N-best示例
可以看到word lattice比N-best的表示更加紧凑。每个lattice的边对应一个词和得分;而每个lattice的节点对应一个Grammar状态和一个时间信息。N-best列表使用起来更加方便,比如parser的输入要求就是一个句子(词序列)。
word lattice可以使用时间同步的Viterbi Beam搜索算法来获得,而通过A*算法可以把word lattice转换成N-best列表。因此我们首先介绍怎么得到word lattice。
word lattice是所有被Grammar接受的词序列中在Beam搜索时得分比较高的一些序列。因此lattice的大小取决于beam的大小(width)。一般来说,lattice的点和边可以在处理词间跳转时通过保留所有的活跃状态的回溯指针来得到。这就是说,我们的回溯指针不只记录一个最高得分,而是需要记录多个较高得分。
对于标准的Viterbi算法,首先我们需要修改算法2。

我们需要把上面画红线的内容修改为:
\[B(t, p, i_p) = \{ <t,q> | q \in \mathcal{Q} \}\]也就是把最优的$q^{max}$扩展到所有的$q \in \mathcal{Q}$。
类似的,在结束的时刻也要做响应的修改。把红线的内容
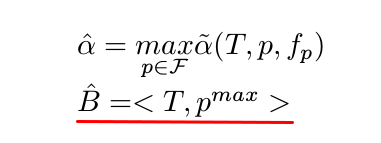
改为:
\[\hat{B} = \{ <T,p> | p \in \mathcal{F} \}\]对于Beam搜索的算法,也需要做类似的修改。首先是把算法4红线的内容

改为:
\[B(t, p, i_p ) \leftarrow B(t, p, i_p ) \cup \{<t, q> \},\]然后把算法6的红线内容
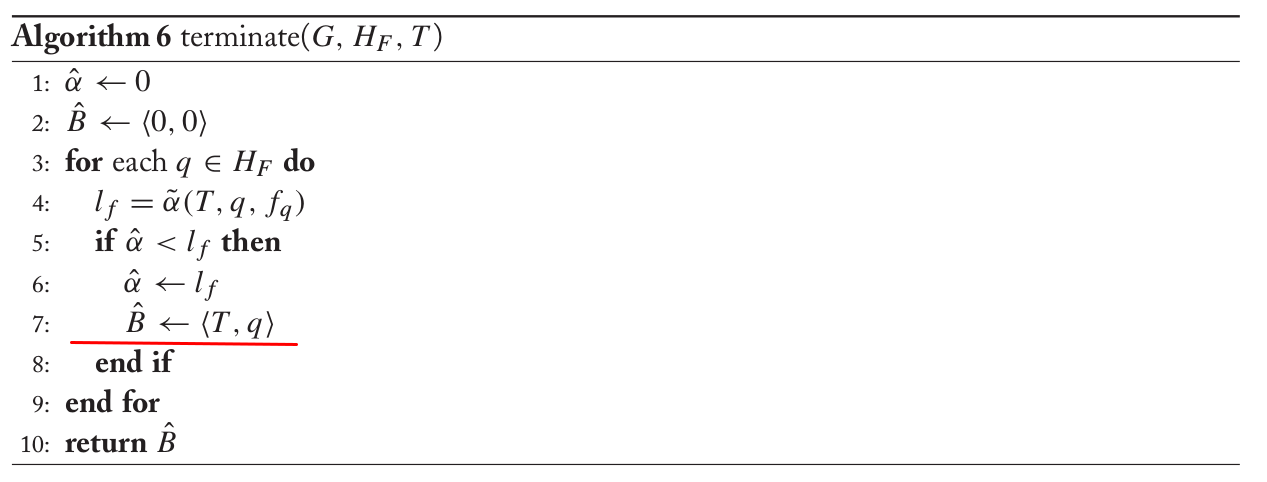
改成:
\[\hat{B} \leftarrow \hat{B} \cup \{<T, p> \}\]做了上面的修改之后,就可以使用下面的算法来生成word lattice了。

在上面的算法里,第1行首先是创建一个空的lattice L。第2行把活跃的回溯指针插入队列B。第3行创建一个空的队列C,它记录已经创建过的latice节点。注意:lattice节点定义为时间和grammar状态的pair。第4行到16行变量B直到B为空。在第5和6行首先从队列B中弹出一个回溯指针<t,p>。第7行变量$B,t,f_p$的所有回溯指针,找到$<\tau,q>$,然后把$«\tau, q>,<t, p>, Word(p), l>$加入L,其中l是这条边上的得分,它等于$\tilde{\alpha}(t,p,f_p)/\tilde{\alpha}(\tau,q,f_q)$。并且如果$<\tau,q>$没有处理过(不在C中),则把它加到B里。循环结束后,把<t,p>加到C里。
虽然上面的算法广为使用,但是它只是一种近似的算法。因为它是基于Viterbi算法,这个算法(最初)只是用于寻找最优路径,它不能保证最优路径之外的次优路径(比如得分第2高的路径)一定能通过这个算法找到。
下面我们通过一个例子来说明什么情况下这个算法不能找到次优的路径。下图是一个trellis,有3条路径分布从Grammar状态u,v和x进入Grammar状态w,但是它们进入w的时间是不同的,u和v是在$t_1$进入w,而x是$t_3$。假设粗线条(v那条)是最优路径。因为v是最优路径,所以回溯的时候也能找到u和v,所以路径uw和vw会被正确的加到lattice。但是在$t_2$时刻从x到w的跨词跳转的路径会在$t_3$时刻被丢掉,因为每个词内跳转只保留最优的路径。当然我们可以修改词内跳转算法,让它记住多条较优的路径,但是这会让内存增大(一个句子的词不多,但是帧数是很多的)并且计算量增大。
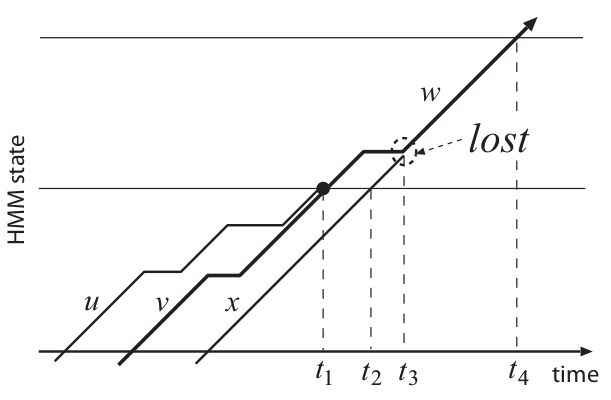 标准的Viterbi搜索
标准的Viterbi搜索
有一种办法可以有些的减少上面的这种错误。它假设一个词的最优路径的开始时间只依赖于前一个词,因此它会根据前面不同的词记录多个词内的回溯指针。这个假设叫word-pair近似,它比前面的的lattice算法要安全得多。下图在trellis空间表示的路径是依赖与前一个词的。这这个例子里,所有的路径都会被保留下来,因为w会根据之前的词来分别保存回溯指针。
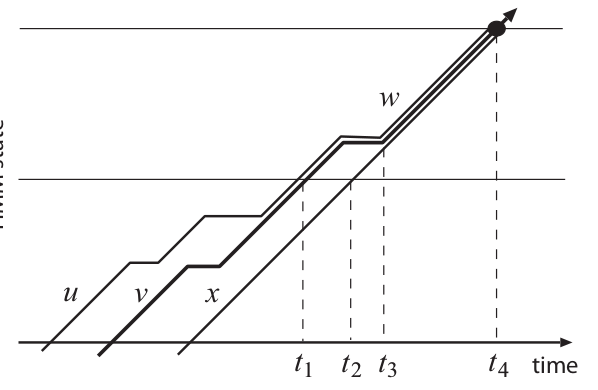 Word-conditioned搜索
Word-conditioned搜索
这种对算法的扩展可以简单的复制每一个Grammar状态p,使得对于每一个能跳到它的Grammar状态q有回溯指针来实现。虽然这会增加Viterbi算法的计算量,但是很多类型的搜索网络满足这个假设。比如上图基于前缀树的搜索网络的每棵树的Grammar状态依赖于之前的词,因此适合用来生成word lattice。但是这个图对于back-off的跳转也有词的依赖,所以不适合生成lattice。
接下来我们介绍使用A*搜索来获得N-best列表的算法,它也是从终止状态往后搜索的。这个算法和lattice的生成类似,因此也存在之前的那个问题(不保证次优路径会被找到)。

算法通过一个优先队列来保存前向得分乘以后向得分最大的词序列。第1行准备一个空的list W用于保存N-best list。第2行初始化优先队列U空。第3-5行把终止的活跃状态插入到U里,U的每一个元素是一个tuple,表示<时间,Grammar状态,词序列,前向得分,后向得分>。终止活跃状态的前向得分是$\tilde{\alpha}(t,p,f_p)$,后向得分是1,词序列是空字符串。
接下来的第6-17行是循环,直到找到N个最高得分的路径或者队列U为空了为止才退出循环。第7-9行从优先队列里弹出目前前向得分乘以后向得分最高的元素。如果对于的Grammar状态p是0,则说明这条路径W已经完成,可以把它加到$\mathcal{W}$里。如果W已经在$\mathcal{W}$里了,那么直接忽略它。否则遍历$B(t, p, f_p)$里的所有回溯指针$<\tau,q>$,然后使用计算$l=\tilde{\alpha}(t,p,f_p)/\tilde{\alpha}(\tau,q,f_q)$,从而得到新的后向得分,然后再把$<\tau, q, \text{Word}(p) · W, \tilde{\alpha}(\tau, q, f_q ), l \times β>$插入优先队列U。使用这个算法也可以从Word lattice里生成N-best list。
- 显示Disqus评论(需要科学上网)